

En esta guía, descubrirá:
- Cómo automatizar el scraping de LinkedIn con n8n, Bright Data y OpenAI
- Cómo crear un flujo de trabajo sin código que envíe los perfiles de los candidatos directamente a su bandeja de entrada
- Por qué la combinación de Web Unlocker, ChatGPT y SMTP crea una potente herramienta de reclutamiento
Empecemos.
Primeros pasos
Puede ver este flujo de trabajo en n8n aquí. Sin embargo, para la configuración más fácil, hay algunas cosas que tenemos que hacer primero.
Autoalojamiento n8n
Este flujo de trabajo se basa en los Community Nodes de n8n. Los Community Nodes son herramientas de terceros proporcionadas por buenos samaritanos de la comunidad n8n. La mejor manera de gestionar todas estas partes móviles envolviéndolas en un contenedor Docker.
Instalación de Docker
Usando Ubuntu nativo o Ubuntu vía WSL en Windows, ejecute el siguiente comando para instalar Docker. Puedes aprender sobre la instalación de Docker para otras plataformas aquí.
sudo snap install dockerUna vez instalado Docker, crea un volumen de almacenamiento y ejecuta tu contenedor.
Creación de un contenedor n8n
sudo docker volume create n8n_data
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nInstalación de nodos comunitarios
Abre http://localhost:5678/ en tu navegador. Tendrás una versión completamente autoalojada de la aplicación web n8n ejecutándose localmente.
En la barra lateral, haz clic en los tres puntos junto a tu perfil y selecciona “configuración”.

Una vez en el menú de configuración, selecciona “Nodos comunitarios”. Esto te da acceso a las herramientas de terceros que he mencionado antes.
Haga clic en “Instalar” y verá una ventana emergente para el nodo que desea instalar. En la sección de paquetes npm, pega el siguiente paquete.
n8n-nodes-brightdataCuando estés listo, haz clic en “Instalar”.

Ahora, repita este proceso para el Generador de Documentos.
n8n-nodes-document-generator
Reiniciar el contenedor
Una vez instalados los nodos comunitarios, cierre el contenedor con ctrl+c. Ejecute el siguiente comando para reiniciar n8n.
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nImportar el flujo de trabajo
Después de la configuración, por fin estamos listos para importar ese flujo de trabajo que he mencionado antes. Ve a su página n8n y haz clic en el botón “Usar gratis”.

Debería ver una ventana emergente con varias opciones diferentes. La forma más sencilla es seleccionar “Importar plantilla a la instancia autoalojada localhost:5678”.

Introduzca o importe sus credenciales
Ahora, se le pedirá automáticamente que introduzca sus credenciales para Bright Data, OpenAI y SMTP.

Obtención de las claves API
Datos brillantes
Este flujo de trabajo utiliza Web Unlocker para realizar nuestra búsqueda. Después de registrarse en Web Unlocker, vaya a Web Unlocker Dashboard y obtenga su clave API. n8n utilizará esta clave para raspar los resultados con Bright Data.

OpenAI
Dirígete a la plataforma para desarrolladores de OpenAI y crea una cuenta si aún no lo has hecho. A continuación, haz clic en “Claves API” para generar una clave.

SMTP
Este proceso es compatible con cualquier cliente SMTP. Actualmente, estoy usando Elastic Email. Su plan gratuito es excelente para proyectos locales como este. Guarde su nombre de usuario, contraseña, servidor y puerto. Vamos a utilizar estos con n8n para automatizar su proceso de correo electrónico.

Pasos del flujo de trabajo

Cuando el usuario rellena un formulario
Cuando un usuario completa un formulario web, esto inicia nuestro flujo de trabajo. Siéntase libre de abrir este nodo y mirar los parámetros y configuraciones. Sin embargo, todo en este paso debe ser pre-configurado – no hay necesidad de editar.

Creación de la URL de LinkedIn y búsqueda de empresas
Una vez cumplimentado el formulario, iniciamos dos flujos de trabajo distintos.
Uno de ellos crea una URL de Google para buscar el perfil de LinkedIn de esta persona.

El otro hace una url de Google aparte para buscar su empresa en LinkedIn.
Ambas URLs se pasan a Web Unlocker para evitar ser bloqueadas.

Extracción de HTML de los resultados
Ahora, extraemos el HTML de nuestros resultados. Tenemos dos nodos llamados “Extraer cuerpo y título del sitio web”. Ambos extraen el título y el cuerpo de la respuesta JSON de Bright Data.

En el flujo de trabajo, estos dos pasos destacados ocurren al mismo tiempo.

Análisis de los resultados con ChatGPT
Ahora que hemos extraído el título y el cuerpo de cada búsqueda, pasamos nuestros resultados HTML a ChatGPT para su procesamiento. Cada uno de estos nodos contiene un proceso como el que ves a continuación. Definimos nuestro modelo (GPT-4o mini) y le damos un prompt para extraer nuestros datos.

Como se puede ver a continuación, Esto sucede en nuestros dos procesos simultáneamente también.
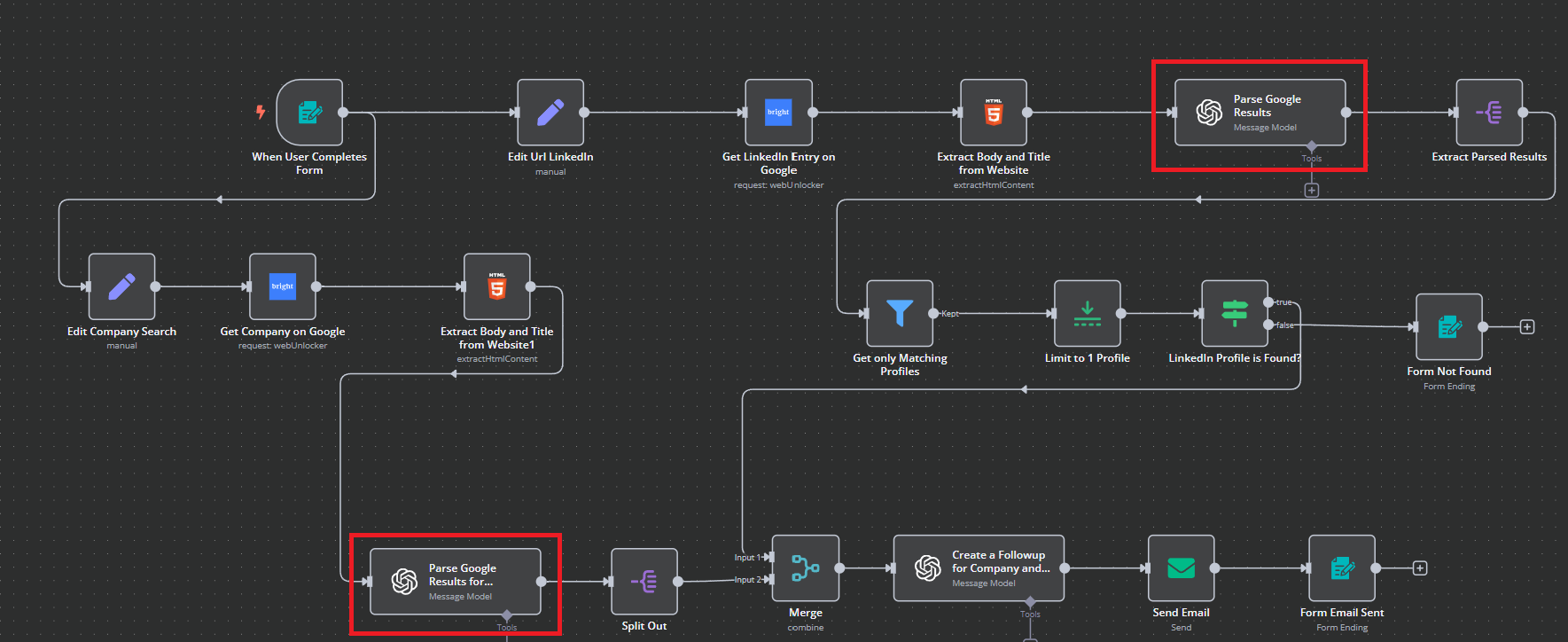
Extraer los resultados analizados y dividirlos para finalizar la búsqueda de empresas
Durante este paso, uno de nuestros flujos de trabajo independientes finaliza con una “Separación”. Cuando finaliza el flujo de trabajo “Empresa”, extraemos los resultados analizados de nuestro flujo de trabajo “Persona”.
Aquí están las instrucciones para la extracción. Como puedes ver, básicamente estamos extrayendo trozos más pequeños del cuerpo JSON más grande.

Nuestro flujo de trabajo “Empresa” ha terminado y nuestro flujo de trabajo “Persona” tiene algunos pasos que completar. El flujo de trabajo “Empresa” permanecerá en pausa hasta que estos procesos estén listos para fusionarse – aquí es donde la belleza de n8n realmente comienza a brillar… ¡programación asíncrona sin necesidad de codificación!

Limitar a 1 perfil y validar su existencia
Nuestro flujo de trabajo “Persona” filtra el resultado para utilizar sólo perfiles coincidentes. A continuación, lo limitamos a un perfil y nos aseguramos de que su perfil existe. Si no existe, lo gestionamos actualizando el formulario e informando al usuario de que no se ha encontrado el perfil.

Mientras el perfil exista, ya estamos listos para volver a fusionarnos en un flujo de trabajo único y coherente.

Fusión de los flujos de trabajo
Como puede ver a continuación, los datos de ambos flujos de trabajo se utilizan como entrada. Se fusionan en una sola salida para que la pasemos a ChatGPT por última vez.

Por fin todo está encajando. Una vez que tenemos un único flujo de trabajo, estamos listos para ejecutar los pasos finales.

Elaborar medidas de divulgación y seguimiento
Ahora, pasamos esta salida única de vuelta a ChatGPT para finalizar nuestro correo electrónico. Incluso escribe HTML personalizado para que no tengamos que preocuparnos por el código de marcado.

Cuando recibamos el código HTML, podremos enviar los resultados por correo electrónico.

Envío del correo electrónico
Abre el nodo “Send Email” para asegurarte de que tus credenciales y detalles de conexión son correctos. Como puedes ver, pasamos json.message.content.content para crear el email. Esto literalmente toma el HTML de ChatGPT y lo pega directamente en el cuerpo del correo electrónico.

Cambia el “Correo electrónico del remitente” por el correo electrónico SMTP que estés utilizando. A continuación, el correo electrónico se enviará a “Para correo electrónico”: cámbialo por tu correo electrónico personal para recibir los resultados en tu bandeja de entrada personal.

Actualización del formulario para mostrar la finalización
Por último, actualizamos el formulario para indicar al usuario que la operación se ha realizado correctamente. Si abres “Form Email Sent”, verás los diferentes parámetros para la actualización del formulario. Como puedes ver, mostramos un “Azulejo de finalización” que dice: “¡Gracias!” y un mensaje que dice: “Le hemos enviado un correo electrónico”.

Ya hemos terminado el último paso del flujo de trabajo. No dude en hacer clic en el botón “Probar flujo de trabajo” para ver cómo se ejecuta todo.

Resultados
Si decides ejecutar el flujo de trabajo, primero verás una ventana emergente que te pedirá que completes el formulario de búsqueda. Rellene el formulario y haga clic en “Obtener referencias”.

Una vez finalizado el proceso, el formulario debería parecerse al siguiente. Como puede ver, dice “¡Gracias!” y muestra nuestro mensaje de finalización.
Si abres tu bandeja de entrada, tendrás un nuevo correo electrónico con una descripción detallada de tu candidato con enlaces a su sitio web y a su perfil de LinkedIn. Debajo verás las recomendaciones de ChatGPT para el contacto y el seguimiento.

Conclusión
Con n8n, Bright Data, OpenAI y SMTP, has creado un flujo de trabajo totalmente automatizado para el scraping y la difusión de LinkedIn, sin necesidad de escribir código complejo. Esta potente configuración agiliza el proceso de contratación, ofreciendo perfiles de candidatos enriquecidos y contactos personalizados directamente en su bandeja de entrada.
Tanto si está ampliando un proceso de contratación como mejorando la generación de oportunidades, este flujo de trabajo es sólo el principio. Bright Data ofrece un conjunto completo de herramientas para llevar su automatización al siguiente nivel:
- Web Unlocker: evita los CAPTCHA, los bloqueos y la detección de bots para raspar LinkedIn y otros sitios de forma fiable.
- Proxies residenciales: Acceda a IPs de usuarios reales de todo el mundo para garantizar altas tasas de éxito y geolocalización.
- Navegador de raspado: Un navegador sin cabeza con proxy integrado, ideal para páginas con mucho JavaScript.
- API de raspado: Utilice plantillas de raspado predefinidas para extraer datos estructurados sin esfuerzo.
- Conjuntos de datos: Aproveche los conjuntos de datos ya creados sobre ofertas de empleo, datos de empresas y mucho más para enriquecer su difusión.
Suscríbase a una prueba gratuita y empiece hoy mismo a automatizar de forma más inteligente.






