

En este tutorial, explorará:
- La definición de scraping de comercio electrónico y por qué es útil
- Los tipos de herramientas de scraping de comercio electrónico
- Los datos que se pueden extraer de las plataformas de comercio electrónico
- Cómo crear un script de scraping de comercio electrónico con Python
- Los retos del scraping de sitios web de comercio electrónico
¡Empecemos!
¿Qué es el Scraping web de comercio electrónico?
El scraping web de sitios de comercio electrónico es el proceso de extraer datos de plataformas minoristas en línea como Amazon, Walmart, eBay y sitios similares. Aunque se puede hacer copiando los datos manualmente, normalmente se realiza utilizando herramientas o scripts automatizados.
Los datos extraídos de los sitios de comercio electrónico pueden ayudar a las empresas, los investigadores y los desarrolladores a:
- Analizar las fluctuaciones de los precios de los productos.
- Realizar un seguimiento de las puntuaciones de las reseñas
- Identificar las tendencias del mercado
- Estudiar a la competencia
Esta información permite tomar decisiones informadas y realizar una planificación estratégica.
Tenga en cuenta que una herramienta de extracción de datos de comercio electrónico se conoce comúnmente como «Scraper» de comercio electrónico.
Tipos de scrapers de comercio electrónico
A continuación se muestra una lista de algunos de los tipos más populares de herramientas de scraping de comercio electrónico:
- Scripts personalizados: scripts adaptados para extraer datos específicos de comercio electrónico utilizando lenguajes de programación de Scraping web como Python o JavaScript.
- Scrapers sin código: herramientas fáciles de usar que permiten la extracción de datos sin necesidad de programar, ideales para usuarios sin conocimientos técnicos. Descubra los mejores scrapers sin código.
- API de Scraping web: interfaces que proporcionan datos de comercio electrónico estructurados de forma programática, a menudo compatibles con la extracción en tiempo real o a gran escala.
- Extensiones de scraping: complementos basados en el navegador que simplifican la recopilación de datos directamente desde las páginas web de comercio electrónico mientras se navega por ellas.
En este artículo, nos centraremos específicamente en la creación de un bot personalizado de Scraping web de comercio electrónico.
Datos que se pueden extraer de los sitios de comercio electrónico
Los scrapers web de comercio electrónico suelen ayudarle a recuperar los siguientes datos:
- Detalles del producto: nombres, descripciones, especificaciones e imágenes.
- Información sobre precios: precios actuales, descuentos y tendencias históricas de precios.
- Opiniones de los clientes: valoraciones, contenido de las opiniones y comentarios de los clientes.
- Categorías y etiquetas: clasificación y categorización de productos.
- Información del vendedor: nombres, valoraciones y datos de contacto del vendedor.
- Detalles de envío: costes, plazos de entrega y políticas de envío.
- Disponibilidad de existencias: niveles de inventario y notificaciones de agotamiento de existencias.
- Datos de marketing: listados de productos, estrategias de precios, promociones y descuentos de temporada.
Ahora, ¡aprende a crear un Scraper de comercio electrónico con Python!
Cómo crear un Scraper de comercio electrónico
Para crear manualmente un Scraper de comercio electrónico, primero debes familiarizarte con el sitio de destino. Inspecciona la página de destino con DevTools para:
- Comprender su estructura
- Determinar qué datos puedes extraer
- Decidir qué bibliotecas de scraping utilizar
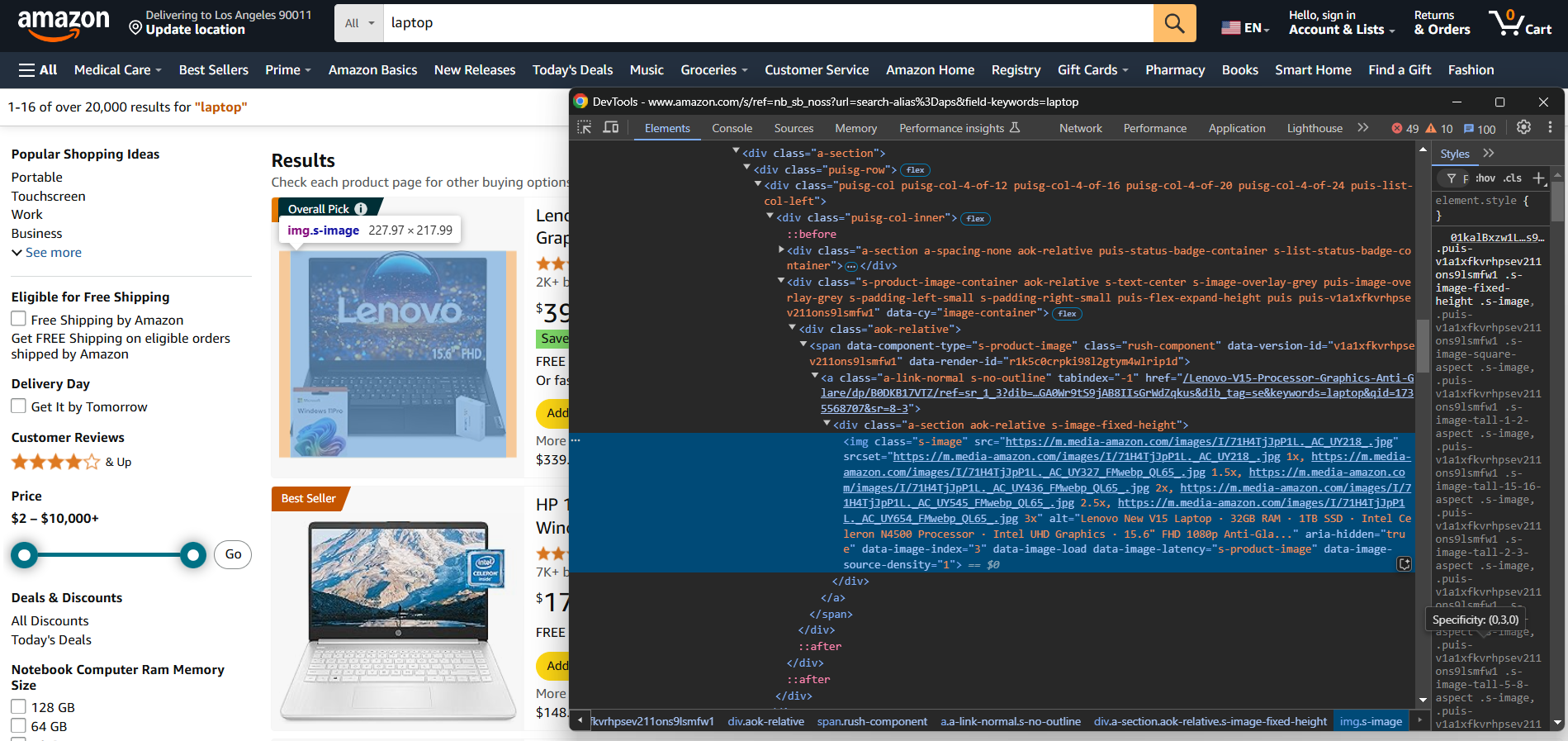
Para sitios de comercio electrónico más sencillos, las dos bibliotecas de Python siguientes son suficientes:
- Requests: para enviar solicitudes HTTP. Le ayuda a obtener el contenido HTML sin procesar de una página web.
- Beautiful Soup: para el parseo de documentos HTML y XML. Simplifica la navegación y la extracción de datos de la estructura HTML de una página. Obtenga más información en nuestra guía sobre el parseo con Beautiful Soup.
Puede instalarlas ambas con:
pip install requests beautifulsoup4
Para las plataformas de comercio electrónico que cargan datos de forma dinámica o dependen en gran medida de la representación de JavaScript, necesitará herramientas de automatización del navegador como Selenium. Para obtener más información, consulte nuestro tutorial sobre el scraping con Selenium.
Puede instalar Selenium con:
pip install selenium
A continuación, el proceso de Scraping web es el siguiente:
- Conéctese al sitio de destino: utilice Requests o Selenium para recuperar y realizar el Parseo del HTML de la página.
- Seleccione los elementos de interés: localice elementos específicos (por ejemplo, imagen del producto, precio, descripción) en la estructura HTML y selecciónelos con selectores CSS o expresiones XPath.
- Extraiga los datos: extraiga la información deseada de estos elementos HTML.
- Limpiar los datos: procesar los datos extraídos para eliminar el contenido innecesario o reformatearlos, si es necesario.
- Exportar los datos: guarde los datos limpios en el formato que prefiera, como JSON o CSV.
Las ventajas de este enfoque incluyen el control total sobre el proceso de extracción de datos y la posibilidad de personalizarlo para satisfacer requisitos específicos. Sin embargo, requiere conocimientos técnicos para su diseño y mantenimiento. Además, cada sitio de comercio electrónico necesita su propio script.
En los próximos capítulos, encontrará ejemplos de scripts de Python para extraer datos de Amazon, Walmart y eBay.
Raspado de Amazon
- Página de destino: página de búsqueda de «ordenadores portátiles» en Amazon
- URL de la página de destino: https://www.amazon.com/s?k=laptop&ref=nb_sb_noss
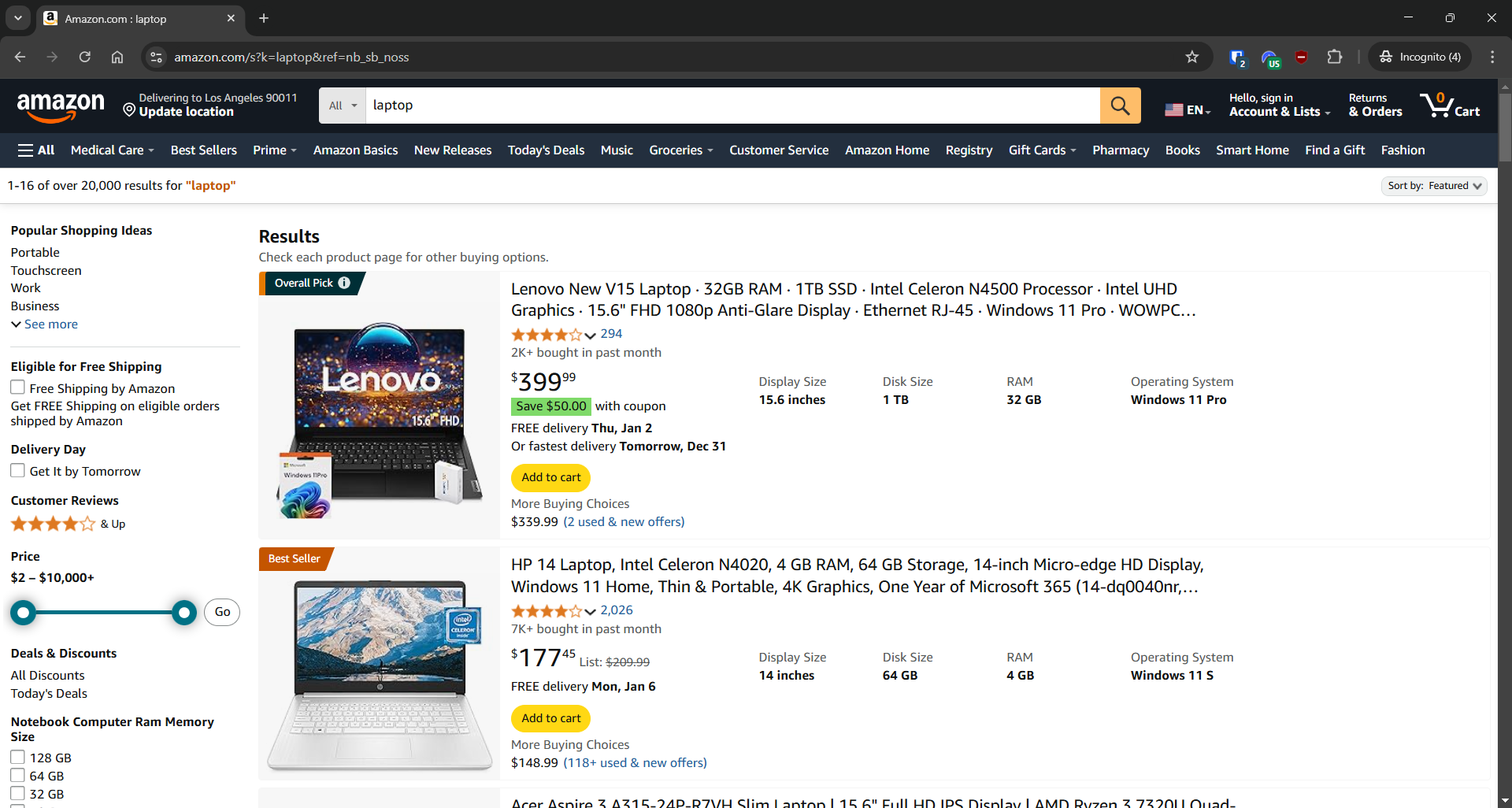
Amazon cuenta con medidas antiscraping diseñadas para bloquear las solicitudes que no proceden de un navegador. Para eludir estas restricciones, es necesario utilizar una herramienta de automatización del navegador como Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Inicializar el WebDriver
driver = webdriver.Chrome(service=Service())
# Abrir la página de inicio de Amazon en el navegador
driver.get("https://amazon.com/")
# Rellene el formulario de búsqueda
search_input_element = driver.find_element(By.ID, "twotabsearchtextbox")
search_input_element.send_keys("laptop")
# Localice el botón de búsqueda y haga clic en él
search_button_element = driver.find_element(By.ID, "nav-search-submit-button")
search_button_element.click()
# Ahora estás en la página de destino
# Dónde almacenar los datos extraídos
products = []
# Selecciona todos los elementos de producto de la página
product_elements = driver.find_elements(By.CSS_SELECTOR, "[role="listitem"][data-asin]")
# Iterar sobre ellos
for product_element in product_elements:
# Lógica de extracción
url_element = product_element.find_element(By.CSS_SELECTOR, ".a-link-normal")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h2")
name = name_element.text
elemento_imagen = elemento_producto.find_element(By.CSS_SELECTOR, "img[data-image-load]")
imagen = elemento_imagen.get_attribute("src")
# Rellenar un nuevo objeto con los datos extraídos
producto = {
"url": url,
"nombre": nombre,
"imagen": imagen
}
# Añadirlo a la lista de productos extraídos
products.append(product)
# Exportar datos a un archivo JSON
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
Ejecute el Scraper de Amazon eCommerce anterior y, si Amazon no muestra un CAPTCHA, generará el siguiente resultado:
[
{
"url": "https://www.amazon.com/A315-24P-R7VH-Display-Quad-Core-Processor-Graphics/dp/B0BS4BP8FB/ref=sr_1_3?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-3",
"name": "Ordenador portátil delgado Acer Aspire 3 A315-24P-R7VH | Pantalla IPS Full HD de 15,6" | Procesador AMD Ryzen 3 7320U de cuatro núcleos | Gráficos AMD Radeon | 8 GB de LPDDR5 | SSD NVMe de 128 GB | Wi-Fi 6 | Windows 11 Home en modo S",
"image": "https://m.media-amazon.com/images/I/61gKkYQn6lL._AC_UY218_.jpg"
},
// omitido por brevedad...
{
"url": "https://www.amazon.com/Lenovo-Newest-Flagship-Chromebook-HubxcelAccesory/dp/B0CBJ46QZX/ref=sr_1_8?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-8",
"name": "El nuevo Chromebook insignia de Lenovo, ordenador portátil delgado y ligero con pantalla táctil FHD de 14 pulgadas, procesador MediaTek Kompanio 520 de 8 núcleos, 4 GB de RAM, 64 GB de eMMC, WiFi 6, Chrome OS + HubxcelAccesory, azul abismo",
"image": "https://m.media-amazon.com/images/I/61KlKRdsQ7L._AC_UY218_.jpg"
}
]
Ten en cuenta que Amazon puede seguir mostrando un CAPTCHA y bloquear tu solicitud, incluso si la realizas a través de Selenium. En ese caso, deberías consultar SeleniumBase como alternativa. De lo contrario, sigue leyendo el artículo, ya que te presentaremos una solución definitiva.
Para obtener una guía completa, consulte nuestro tutorial detallado sobre el Scraping web de Amazon.
Rastreo de Walmart
- Página de destino: página de búsqueda «teclado» en Walmart
- URL de la página de destino: https://www.walmart.com/search?q=keyboard
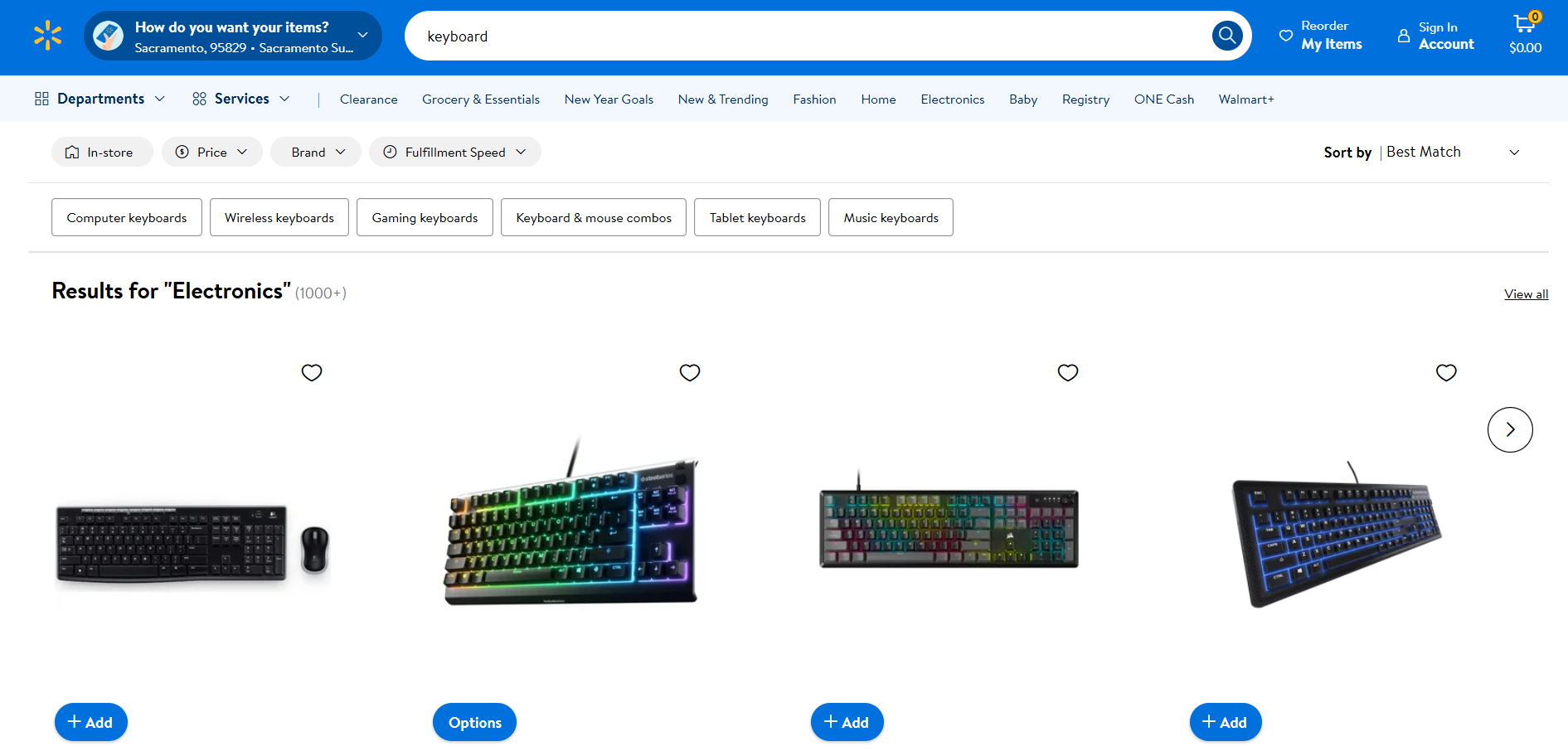
Al igual que Amazon, Walmart utiliza soluciones antibots para bloquear las solicitudes que provienen de clientes HTTP automatizados. Por lo tanto, puede extraerla con Selenium como se indica a continuación:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Inicializar el WebDriver
driver = webdriver.Chrome(service=Service())
# Navegar a la página de destino
driver.get("https://www.walmart.com/search?q=keyboard")
# Dónde almacenar los datos extraídos
products = []
# Seleccionar todos los elementos de producto de la página
product_elements = driver.find_elements(By.CSS_SELECTOR, ".carousel-4[data-testid="carousel-container"] li")
# Iterar sobre ellos
for product_element in product_elements:
# Lógica de recopilación
url_element = product_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h3")
name = name_element.get_attribute("innerText")
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-testid="productTileImage"]")
image = image_element.get_attribute("src")
# Rellenar un nuevo objeto con los datos extraídos.
product = {
"url": url,
"name": name,
"image": image
}
# Añadirlo a la lista de productos extraídos.
products.append(product)
# Exportar datos a un archivo JSON
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
Ejecute el Scraper de comercio electrónico de Walmart y obtendrá:
[
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=1&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FLogitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black%2F28540111%3FclassType%3DREGULAR%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=sAX_0l4wzWXzBji34bVpmheXU7_ETXGbDXcA9LhcshG_YbqBx24VWzt7yesHivpt1lpckuNhxQqbLidA-d8L4agqx_YPQVlj2EfM_TnEyfsSWiTEkvBaqgkaMzy6bgIZ4eC8t9-qqz7qtb7uXMz3cH92UCf5EEgQlfKwnxJ-SAF1EW1ouCjC10Ur3hELs3143xQPjxNUSUoN8FIF12fxJmTlSlTe4makoj1s2NoubYTqnlJLs3pohowJCRFT76Vl&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=REGULAR",
"name": "Logitech Wireless Combo MK270",
"image": "https://i5.walmartimages.com/seo/Logitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black_99591453-341e-4c5b-937e-b2ab9b321519.3860011d84a23ccd0732e46474590b15.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=2&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FSteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A%2F996783321%3FclassType%3DVARIANT%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=Dp3ons-xIcmPw9Ze7UUZuW3PD9Dto_vYCLjglme5vSy5Ze1p4NXg3uzApRy4mgfB-dGDchsq6FDoaZeMy6Dmeagqx_YPQVlj2EfM_TnEyfv_0r9GA9WwEd1cWbcx63Diahe72Zw6lw8suSf-OFKKH6UaiJl_8Qtpar-x0VhgrMsbqG7gDKh5DkQZql3HeMLncWSwburhSEjvpT1dXlDoWKxUrZwxZhOMry-uCqhuSb7Y6B-xZGrNPjYyel0nw11Z&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=VARIANT",
"name": "Teclado para juegos SteelSeries Apex 3 TKL RGB - Sin teclado numérico - Resistente al agua y al polvo - PC y USB-A",
"image": "https://i5.walmartimages.com/seo/SteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A_876430c2-eed8-404a-aa55-1c66193daf8e.8c617e57ba48bc49d003f917f85cb535.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
// omitido por brevedad...
{
"url": "https://www.walmart.com/ip/DEP-06-Portable-Digital-Piano-with-X-Stand/7598762909?classType=REGULAR",
"name": "Piano digital portátil Donner de 88 teclas con teclado de acción sintética, soporte en X, pedal, acompañamiento automático para principiantes, 128 tonos, 83 ritmos, compatible con USB/MIDI/Melodics, conexión inalámbrica",
"image": "https://i5.walmartimages.com/seo/DEP-06-Portable-Digital-Piano-with-X-Stand_1175fc1e-c191-4c71-9e9a-7e4a13274487.6673e0430c23d122744cfb63ccc8c155.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
}
]
Para obtener más información, lea nuestro artículo sobre el Scraping web de Walmart.
Rastreo de eBay
- Página de destino: página de búsqueda «mouse» en eBay
- URL de la página de destino: https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0
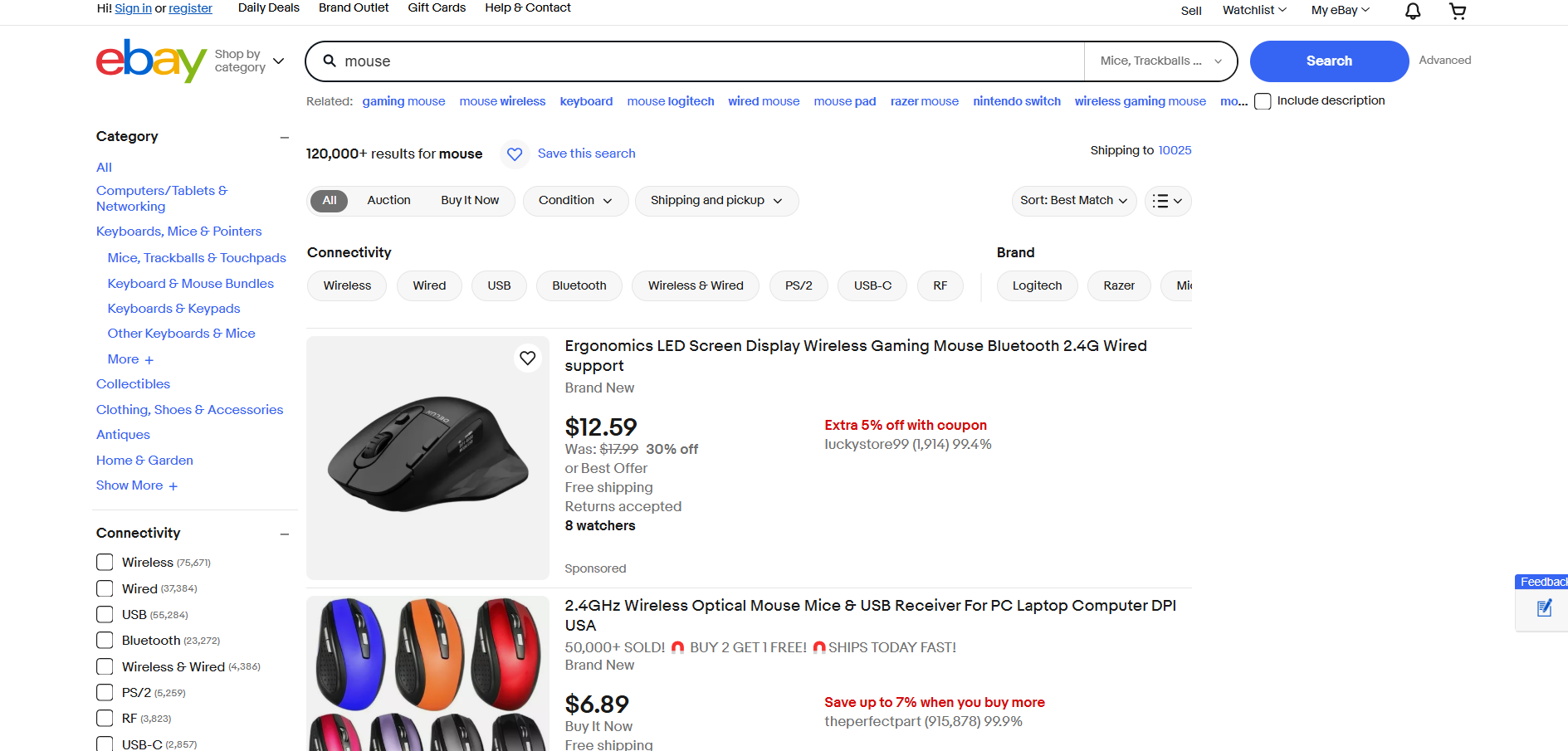
eBay no utiliza JavaScript para mostrar productos o cargar datos de forma dinámica. Por lo tanto, se puede extraer con Requests y Beautiful Soup de la siguiente manera:
import requests
from bs4 import BeautifulSoup
import json
# Página de destino
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0"
# Enviar una solicitud GET a la página de búsqueda de eBay
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# Analizar el contenido de la página con BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Dónde almacenar los datos extraídos
products = []
# Seleccionar todos los elementos de producto de la página
product_elements = soup.select("li.s-item")
# Iterar sobre ellos
for product_element in product_elements:
# Lógica de rastreo
url_element = product_element.select("a[data-interactions]")[0]
url = url_element["href"]
name_element = product_element.select("[role="heading"]")[0]
name = name_element.text
elemento_imagen = elemento_producto.select("img")[0]
imagen = elemento_imagen["src"]
# Rellenar un nuevo objeto con los datos extraídos
producto = {
"url": url,
"nombre": nombre,
"imagen": imagen
}
# Añadirlo a la lista de productos extraídos
productos.append(product)
# Exportar datos a un archivo JSON
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)Ejecuta el script de scraping web de eBay y obtendrás:
[
{
"url": "https://www.ebay.com/itm/193168148815?_skw=mouse&itmmeta=01JGC679WKT327K11R9YCGMQAN&hash=item2cf9b8094f:g:8F4AAOSw3B1drMr-&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlr8NKoodwElhyHbl4CwcBMRqdGJme95%2F3tIll4uI7QYBk4%2BUBpwVvwiXdAl2%2BcILZ9axc%2BdHSZStWWMxWVyq4JdZ6r52PrRP2aS1jUoFoJ11vL4KyH2S8R5ha71xBtDFcGA2%2BtzhTzcR7J25kxuxbyd%2Frd4YnKbTPKwhn2Q0TP8qL30BJKcj4FnJYP0zhgO4WOGgOCHQhM21%2BanVk%2Fl0eg1H8mqCU91mkgKAt8KghFmw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "Ratón óptico inalámbrico de 2,4 GHz y receptor USB para ordenador portátil PC DPI EE. UU.",
"image": "https://i.ebayimg.com/images/g/8F4AAOSw3B1drMr-/s-l500.webp"
},
{
"url": "https://www.ebay.com/itm/356159975164?_skw=mouse&itmmeta=01JGC679WKE9V782ZXT15SEPHP&hash=item52ecc9eefc:g:0ikAAOSwHStnD33Q&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlZ7pO0lYrvftkZhnT7ja625fcsjcktK0eaub2HNzEgsmo3b2VehoA4tffYdt0xiTXwHb%2BzYU4NBZ5onBh68cyKWhhMJowbRvnCwuwy2IQIRlkeijpbRtJNJPuaaiDZdV0eabGGkps8433kCR6fcX1xEodUxujoeYUjp0VP81OWcl%2BbBGd70%2Fq45HC3SXg4k%2FlK0%2FqR80yJYexSEfzUq7%2BN3Sa6Y01uCo5XPWFLHzRoSw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "Ratón inalámbrico para juegos con pantalla LED ergonómica y Bluetooth 2.4G con cable",
"image": "https://i.ebayimg.com/images/g/0ikAAOSwHStnD33Q/s-l500.webp"
},
// omitido por brevedad...
{
"url": "https://www.ebay.com/itm/116250548048?_skw=mouse&itmmeta=01JGC679WN076MJ17QJ9P4FA5J&hash=item1b11129750:g:gr8AAOSwsSFmkXG3&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKkArX38iC0VVXTpfv4BzqCegsh22yxmsDAwZAmd4RxM9JlEMfuVRoYGVZFVCeurJYwAjWd2YK3%2BNs6m5rQHZXISyWtev1lEvfVVKP4Rd5QeC2KzLgqXOvp1lWiK5b31kfujkmKjF%2BEaR1kplulwrgUvzMO%2F78F%2BFukgIAoL8dE4nRD9jo%2BieiAgIpLBUcs8AmCy5vk65gt1JGonUOncRksGYciF%2FJg6arB9%2FVOYYq7N8A%3D%3D%7Ctkp%3ABlBMULyenYaDZQ",
"name": "Razer x Sanrio Kuromi DeathAdder Gaming Mouse and Mouse Pad Combo",
"image": "https://i.ebayimg.com/images/g/gr8AAOSwsSFmkXG3/s-l500.webp"
}
]
¡Increíble! ¡Acabas de ver algunos ejemplos de scripts de Python para extraer datos de comercio electrónico!
Retos del Scraping web en el comercio electrónico y cómo superarlos
En los ejemplos anteriores, nos hemos centrado en extraer datos básicos como el nombre del producto, la URL y la URL de la imagen de algunos sitios web de comercio electrónico. Aunque esta simplicidad hace que el scraping de comercio electrónico parezca sencillo, la realidad es mucho más compleja por varias razones:
- Estructuras de página dinámicas: las plataformas de comercio electrónico actualizan con frecuencia el diseño de sus páginas, lo que requiere un mantenimiento constante de los scripts.
- Páginas de productos diversas: los diferentes productos pueden mostrar conjuntos de datos variables y utilizar diseños completamente diferentes.
- Precios dinámicos: extraer datos precisos sobre los precios puede resultar complicado debido a las ofertas temporales, los descuentos o las ofertas específicas de cada región.
Además, los principales sitios de comercio electrónico, como Amazon, emplean medidas avanzadas contra el scraping, como los CAPTCHA:
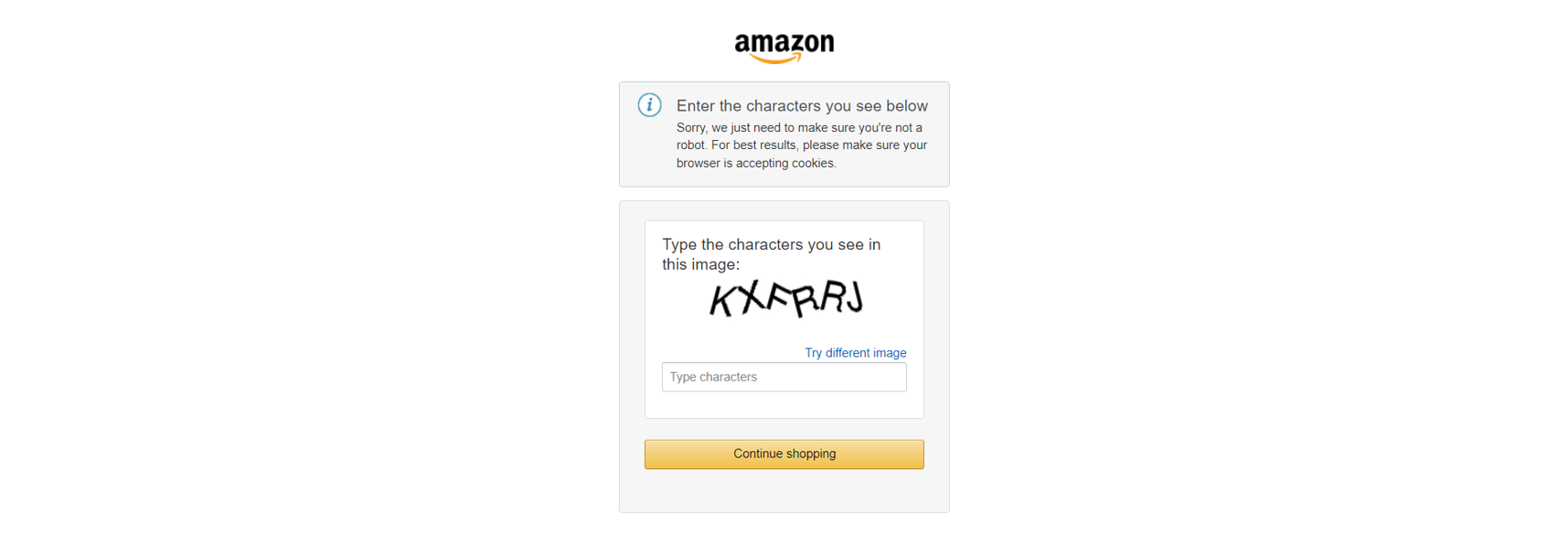
O, de forma similar, retos de JavaScript:

Para superar estos bloqueos, puede:
- Aprender técnicas avanzadas de recopilación: Lea nuestra guía sobre cómo eludir CAPTCHA con Python y eche un vistazo a los tutoriales detallados sobre recopilación para obtener consejos prácticos.
- Utilizar herramientas de automatización avanzadas: utilice herramientas robustas como Playwright Stealth para extraer datos de sitios web con mecanismos antibots.
Sin embargo, la solución más eficaz es utilizar una API dedicada al Scraper de comercio electrónico.
La API de Scraper para comercio electrónico de Bright Data es una solución fiable para extraer datos de plataformas de comercio electrónico como Amazon, Target, Walmart, Lazada, Shein, Shopee y muchas más. Entre sus principales ventajas se incluyen:
- Recupera detalles estructurados como el título del producto, el nombre del vendedor, la marca, la descripción, las reseñas, el precio inicial, la moneda, la disponibilidad, las categorías y mucho más.
- Elimine las preocupaciones relacionadas con la gestión de servidores, Proxies o evitar bloqueos de sitios web.
- Evitar interrupciones por CAPTCHAs o problemas con JavaScript.
¡Optimice hoy mismo su proceso de scraping de comercio electrónico!
Conclusión
En este artículo, ha aprendido qué es un Scraper de comercio electrónico y el tipo de datos que puede extraer de las páginas web de comercio electrónico. Por muy sofisticado que sea su script de Scraping web de comercio electrónico, la mayoría de los sitios pueden detectar la actividad automatizada y bloquearlo.
La solución es una potente API de Scraper de comercio electrónico diseñada específicamente para recuperar datos de comercio electrónico de forma fiable desde diversas plataformas. Estas API ofrecen datos estructurados y completos, entre los que se incluyen:
- API de Scraper de Amazon: rastrea Amazon y recopila datos como el título, el nombre del vendedor, la marca, la descripción, las reseñas, el precio inicial, la moneda, la disponibilidad, las categorías, el ASIN, el número de vendedores y mucho más.
- API de Scraper de eBay: recopile datos como el ASIN, el nombre del vendedor, el ID del comerciante, la URL, la URL de la imagen, la marca, la descripción general del producto, la descripción, las tallas, los colores, el precio final y mucho más.
- API Walmart Scraper: recopila datos como URL, SKU, precio, URL de la imagen, páginas relacionadas, disponible para entrega y recogida, marca, categoría, ID y descripción del producto, y mucho más.
- API de Target Scraper: recopile datos como URL, ID del producto, título, descripción, valoración, número de reseñas, precio, descuento, moneda, imágenes, nombre del vendedor, ofertas, política de envío y mucho más.
- API Lazada Scraper: extrae datos como URL, título, valoración, reseñas, precio inicial y final, moneda, imagen, nombre del vendedor, descripción del producto, SKU, colores, promociones, marca y mucho más.
- API de Shein Scraper: recopila datos como el nombre del producto, la descripción, el precio, la moneda, el color, el stock, la talla, el número de reseñas, la imagen principal, el código del país, el dominio y mucho más.
- API de Shopee Scraper: extraiga datos como URL, ID, título, valoración, reseñas, precio, moneda, existencias, favoritos, imagen, URL de la tienda, valoraciones, fecha de incorporación, seguidores, vendidos, marca y mucho más.
Para extraer datos de productos específicos, considere nuestra API Web Scraper. Si crear un Scraper no es lo suyo, explore nuestros Conjuntos de datos de comercio electrónico listos para usar.
Crea hoy mismo una cuenta gratuita en Bright Data para probar nuestras API de Scraper o explorar nuestros Conjuntos de datos.




