

En este tutorial, demostraremos por qué Go es uno de los mejores lenguajes para raspar la web eficientemente y enseñaremos a construir un raspador Go desde cero.
Este artículo tratará sobre:
- ¿Se puede hacer raspado de datos con Go?
- Las mejores librerías Go para raspado de datos
- Construir un raspador web en Go
¿Se puede hacer raspado de datos con Go?
Go, también conocido como Golang, es un lenguaje de programación de tipado estático creado por Google. Está diseñado para ser eficiente, concurrente y fácil de escribir y mantener. Estas características han hecho de Go una elección popular en varias aplicaciones, incluyendo el raspado de datos.
En concreto, Go ofrece potentes características que resultan muy útiles cuando se trata de tareas de raspado de datos. Estas incluyen su modelo de concurrencia incorporado, que soporta el procesamiento concurrente de múltiples peticiones web. Esto convierte a Go en el lenguaje ideal para obtener grandes cantidades de datos de varios sitios web de forma eficaz. Además, la biblioteca estándar de Go incluye paquetes de cliente HTTP y de análisis HTML que pueden utilizarse para obtener páginas web, analizar HTML y extraer datos de sitios web.
Si esas capacidades y paquetes por defecto no fueran suficientes o fueran demasiado difíciles de usar, existen también varias bibliotecas Go de raspado de datos. Echemos un vistazo a las más populares.
Las mejores bibliotecas de Go Raspado de datos
Aquí hay una lista de algunas de las mejores bibliotecas de raspado de datos para Go:
- Colly: Un potente framework de raspado y rastreo de datos para Go. Proporciona una API funcional para realizar peticiones HTTP, gestionar cabeceras y analizar el DOM. Colly también admite el raspado paralelo, la limitación de velocidad y la gestión automática de cookies.
- Goquery: Una popular biblioteca de análisis de HTML en Go basada en una sintaxis similar a jQuery. Permite seleccionar elementos HTML mediante selectores CSS, manipular el DOM y extraer datos de ellos.
- Selenium: Un cliente Go del framework de pruebas web más popular. Permite automatizar navegadores web para diversas tareas, incluido el raspado de datos. En concreto, Selenium puede controlar un navegador web e indicarle que interactúe con las páginas como lo haría un usuario humano. También es capaz de realizar el raspado de datos en páginas web que utilizan JavaScript para la recuperación o representación de datos.
Requisitos previos
Antes de empezar, necesita instalar Go en su máquina. Tenga en cuenta que el procedimiento de instalación varía en función del sistema operativo.
Instalar Go en macOS
- Descargue Go.
- Abra el archivo descargado y siga las instrucciones de instalación. El paquete instalará Go en /usr/local/go y añada /usr/local/go/bin a su variable de entorno PATH.
- Reinicie las sesiones de Terminal que tenga abiertas.
Instalación de Go en Windows
- Descargue Go.
- Ejecute el archivo MSI que ha descargado y siga las instrucciones del asistente de instalación. El instalador instalará Go en C:/Archivos de programa o C:/Archivos de programa (x86) y añadirá la carpeta bin a la variable de entorno PATH.
- Cierre y vuelva a abrir cualquier ventana de comandos.
Configurar Go en Linux
- Descargue Go.
- Asegúrese de que su sistema no tiene una carpeta /usr/local/go. Si existe, elimínela:
rm -rf /usr/local/go- Extraiga el archivo descargado en /usr/local:
tar -C /usr/local -xzf goX.Y.Z.linux-amd64.tar.gzAsegúrese de sustituir X.Y.Z por la versión del paquete Go que ha descargado.
- Añadir /usr/local/go/bin a la variable de entorno PATH:
export PATH=$PATH:/usr/local/go/bin- Vuelva a cargar su PC.
Independientemente de su sistema operativo, compruebe que Go se ha instalado correctamente con el siguiente comando:
go versionEsto devolverá algo como:
go version go1.20.3Bien, ¡hecho! Ya está listo para lanzarse al raspado web con Go.
Construir un Web Scraper en Go
Mostraremos cómo construir un raspador web Go. Este script automatizado podrá recuperar automáticamente datos de la página de inicio de Bright Data. El objetivo del proceso de raspado de datos en Go será seleccionar algunos elementos HTML de la página, extraer datos de ellos y convertir los datos recogidos a un formato fácil de explorar.
En el momento de escribir estas líneas, éste es el aspecto de la página de destino:

¡Siga el tutorial paso a paso y aprenda a realizar raspado de datos en Go!
Paso 1: Configurar un proyecto Go
Es hora de inicializar el proyecto Go web scraper. Abra el terminal y cree una carpeta go-web-scraper:
mkdir go-web-scraperEste directorio contendrá el proyecto Go.
A continuación, ejecute el siguiente comando init:
go mod init web-scraperEsto inicializará un módulo web-scraper dentro de la raíz del proyecto.
El directorio go-web-scraper contendrá ahora el siguiente archivo go.mod:
module web-scraper
go 1.20Tenga en cuenta que la última línea cambia dependiendo de su versión de Go.
Ahora está preparado para empezar a escribir algo de lógica Go en su IDE. En este tutorial, vamos a utilizar Visual Studio Code. Como no soporta Go de forma nativa, primero necesita instalar la extensión Go.
Inicie VS Code, haga clic en el icono “Extensiones” de la barra de la izquierda y escriba “Go”.
Haga clic en el botón “Instalar” de la primera tarjeta para añadir la extensión Go para Visual Studio Code.
Hacer clic en “Archivo”, selecciona “Abrir carpeta…” y abra el directorio go-web-scraper.
Haz clic derecho en la sección “Explorador”, selecciona “Nuevo archivo…”, y crea un archivo scraper.go de la siguiente manera:
// scraper.go
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello, World!")
}Tengamos en cuenta que la función main() representa el punto de entrada de cualquier aplicación Go. Aquí es donde tendrá que colocar su lógica de raspado web Golang.
Visual Studio Code pedirá que instale algunos paquetes para completar la integración con Go. Instálelos todos. A continuación, ejecute el script Go lanzando el siguiente comando en el Terminal VS:
go run scraper.go
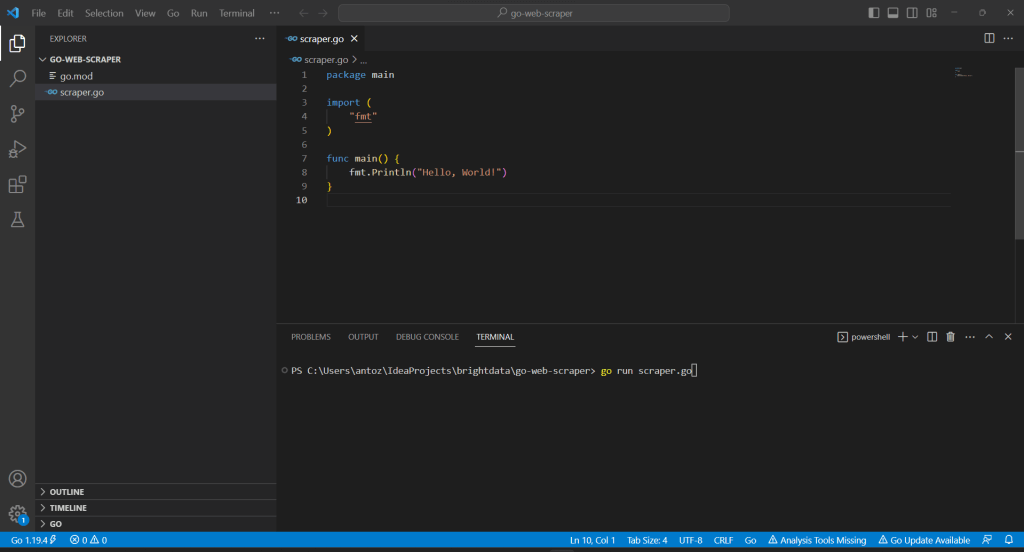
Esto imprimirá:
Hello, World!
Paso 2: Empezar con Colly
Para construir un raspador web para Go más fácilmente, se debe utilizar uno de los paquetes presentados anteriormente. Pero primero, es necesario averiguar qué librería Golang de raspado de datos se ajusta mejor a los objetivos. Para ello, visitemos el sitio web de destino, hagamos clic con el botón derecho del ratón sobre el fondo y seleccionemos la opción “Inspeccionar”. Esto abrirá las DevTools de del navegador. En la pestaña “Red”, eche un vistazo a la sección “Fetch/XHR”.

Como se puede ver arriba, la página web de destino realiza sólo unas pocas peticiones AJAX. Si se explora cada petición XHR, se observará que no devuelven ningún dato significativo. En otras palabras, el documento HTML devuelto por el servidor ya contiene todos los datos. Esto es lo que ocurre generalmente con los sitios de contenido estático.
Eso demuestra que el sitio de destino no depende de JavaScript para recuperar datos dinámicamente o para la representación. Como resultado, no necesita una biblioteca con capacidades de navegador sin interfaz gráfica (headless) para recuperar datos de la página web de destino. Todavía puede utilizar Selenium, pero eso sólo introduciría una sobrecarga de rendimiento. Por esta razón, es preferible utilizar un simple analizador HTML como Colly.
Añada Colly a las dependencias de su proyecto con:
go get github.com/gocolly/collyEste comando crea un archivo go.sum y actualiza el archivo go.mod en consecuencia.
Antes de empezar a usarlo, es necesario profundizar en algunos conceptos clave de Colly.
La entidad principal de Colly es el Collector. Este objeto permite realizar peticiones HTTP y realizar raspado de datos a través de los siguientes callbacks:
- OnRequest(): Llamada antes de realizar cualquier petición HTTP con Visit().
- OnError(): Llamada si se produce un error en una petición HTTP.
- OnResponse(): Llamada después de obtener una respuesta del servidor.
- OnHTML(): Llamado después de OnResponse(), si el servidor devolvió un documento HTML válido.
- OnScraped(): Llamada después de que todas las llamadas a OnHTML() hayan terminado.
Cada una de estas funciones toma una llamada de retorno como parámetro. Cuando se produce el evento asociado a la función, Colly ejecuta la llamada de retorno de entrada. Por lo tanto, para construir un raspador de datos en Colly, es necesario seguir un enfoque funcional basado en callbacks.
Puede inicializar un objeto Collector con la función NewCollector():
c := colly.NewCollector()
Importe Colly y cree un recopilador actualizando scraper.go como se indica a continuación:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// scraping logic...
}
Paso 3: Conectarse al sitio web de destino
Utilice Colly para conectarse a la página de destino con:
c.Visit("https://brightdata.com/")La función Visit() realiza una solicitud HTTP GET y recupera el documento HTML de destino del servidor. En detalle, dispara el evento onRequest e inicia el ciclo de vida funcional de Colly. Tenga en cuenta que Visit() debe invocarse después de registrar las demás callbacks de Colly.
Tenga en cuenta que la petición HTTP realizada por Visit() puede fallar. Cuando esto ocurre, Colly lanza el evento OnError. Las razones del fallo pueden ser cualquier cosa, desde un servidor temporalmente no disponible hasta una URL no válida. Al mismo tiempo, los web scrapers suelen fallar cuando el sitio de destino adopta medidas anti-bot. Por ejemplo, estas tecnologías suelen filtrar las solicitudes que no tienen un encabezado HTTP User-Agent válido. Consulte nuestra guía para obtener más información sobre User-Agents para raspado web.
Por defecto, Colly establece un marcador User-Agent que no coincide con los agentes utilizados por los navegadores más populares. Esto hace que las solicitudes de Colly sean fácilmente identificables por las tecnologías anti-raspado de datos. Para evitar ser bloqueado por ello, especifique una cabecera User-Agent válida en Colly como se indica a continuación:
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36Cualquier llamada a Visit() realizará ahora una petición con esa cabecera HTTP.
Su archivo debería tener ahora el siguiente aspecto:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// connect to the target site
c.Visit("https://brightdata.com/")
// scraping logic...
}
Paso 4: Inspeccionar la página
Analicemos la de la página Web de destino para definir una estrategia eficaz de recuperación de datos.
Abra la página de inicio de Bright Data en su navegador. Si echa un vistazo, verá una lista de fichas con los sectores en los que los servicios de Bright Data pueden suponer una ventaja competitiva. Es información interesante para rascar.
Haga clic con el botón derecho en una de estas tarjetas HTML y seleccione :
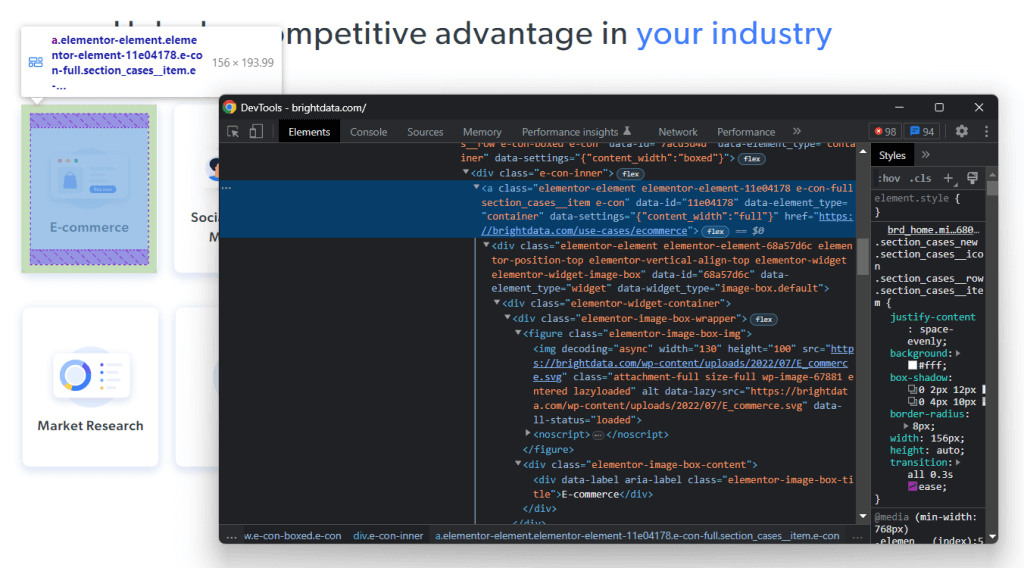
En las DevTools, se puede ver el código HTML del nodo seleccionado en el DOM. Observe que cada tarjeta de industria es un elemento HTML . En concreto, cada una contiene los dos elementos HTML clave siguientes:
- A que almacena la imagen de la ficha de industria.
- Un
presentando el nombre del campo de la industria.
Ahora, concéntrese en las clases utilizadas por los elementos HTML de interés y sus padres. Gracias a ellas, podrá definir la estrategia del selector CSS necesaria para obtener los elementos deseados.
En detalle, cada tarjeta se caracteriza por la clase section_cases__item contenida en .elementor-element-6b05593c <div>. Así, puede obtener todas las tarjetas de la industria con el siguiente el selector CSS:
.elementor-element-6b05593c .section_cases__itemDada una tarjeta, puede seleccionar sus hijos relevantes con:
.elementor-image-box-img img
.elementor-image-box-content .elementor-image-box-titleEl objetivo de raspado de datos del Go scraper es extraer la URL, la imagen y el nombre del sector de cada tarjeta.
Paso 5: Seleccionar elementos HTML con Colly
You can apply a CSS or XPath selector in Colly as follows:
c.OnHTML(".your-css-selector", func(e *colly.HTMLElement) {
// data extraction logic...
})Colly llamará a la función pasada como parámetro para cada elemento HTML que coincida con el selector CSS. En otras palabras, itera automáticamente sobre todos los elementos seleccionados.
No olvide que un recopilador puede tener varias callbacks OnHTML(). Éstas se ejecutarán en el orden en que aparezcan las instrucciones onHTML() en el código.
Paso 6: Extraer datos de una página web con Colly
Aprenda a utilizar Cooly para extraer los datos deseados de la página web HTML.
Antes de escribir la lógica de raspado de datos, se necesitan algunas estructuras de datos donde almacenar los datos extraídos. Por ejemplo, puedes utilizar un Struct para definir un tipo de datos Industry de la siguiente manera:
type Industry struct {
Url, Image, Name string
}En Go, una Struct especifica un conjunto de campos tipados que pueden ser instanciados como un objeto. Si se está familiarizado con la programación orientada a objetos, se puede pensar en una Struct como una especie de clase.
A continuación, necesitará una rebanada de tipo Industria:
var industries []IndustryLas rebanadas Go no son más que listas.
Ahora, se puede utilizar la función OnHTML() para implementar la lógica de raspado como se indica a continuación:
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url!= "" || image != "" || name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})El fragmento Go para extracción web mencionado anteriormente selecciona todas las tarjetas de industria de la página de inicio de Bright Data e itera sobre ellas. A continuación, se debe rellenar raspando la URL, la imagen y el nombre del sector asociado a cada tarjeta. Por último, cree un nuevo objeto Industria y añadirlo a la sección de industrias.
Como puede ver, ejecutar el raspado de datos en Colly es sencillo. Gracias al método Attr(), se puede extraer un atributo HTML del elemento actual. En cambio, ChildAttr() y ChildText() permiten obtener el valor del atributo y el texto de un elemento HTML hijo seleccionado mediante un selector CSS.
Asimismo, es posible recopilar datos de las páginas de detalles del sector. Todo lo que tiene que hacer es seguir los enlaces descubiertos en la página actual e implementar una nueva lógica de raspado web en consecuencia. En esto consiste el rastreo y el raspado web.
¡Bien hecho! Ahora ya sabe cómo conseguir sus objetivos de raspado de datos con Go.
Paso 7: Exportar los datos extraídos
Después de la instrucción OnHTML(), industries contendrá los datos extraídos en objetos Go. Para hacer los datos extraídos de la web más accesibles, necesita convertirlos a un formato diferente. Vea cómo exportar los datos raspados a CSV y JSON.
Tenga en cuenta que la biblioteca estándar de Go viene con capacidades avanzadas de exportación de datos. No se requiere ningún paquete externo para convertir los datos a CSV y JSON. Todo lo que se necesita es asegurarse de que el script Go contiene las siguientes importaciones:
- Para la exportación CSV:
import (
"encoding/csv"
"log"
"os"
)
- Para la exportación JSON:
import (
"encoding/json"
"log"
"os"
)Puede exportar la porción de industrias a un archivo industries.csv en Go de la siguiente manera:
// open the output CSV file
file, err := os.Create("industries.csv")
// if the file creation fails
if err != nil {
log.Fatalln("Failed to create the output CSV file", err)
}
// release the resource allocated to handle
// the file before ending the execution
defer file.Close()
// create a CSV file writer
writer := csv.NewWriter(file)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}El fragmento anterior crea un archivo CSV y lo inicializa con la fila de encabezado. A continuación, itera sobre el segmento de objetos Industry, convierte cada elemento en un segmento de cadenas y lo añade al archivo de salida. Go CSV Writer convertirá automáticamente la lista de cadenas en un nuevo registro en formato CSV.
Ejecute el script con:
go run scraper.goTras su ejecución, observará un archivo industries.csv en la carpeta raíz de su proyecto Go. Ábralo y debería ver los siguientes datos:
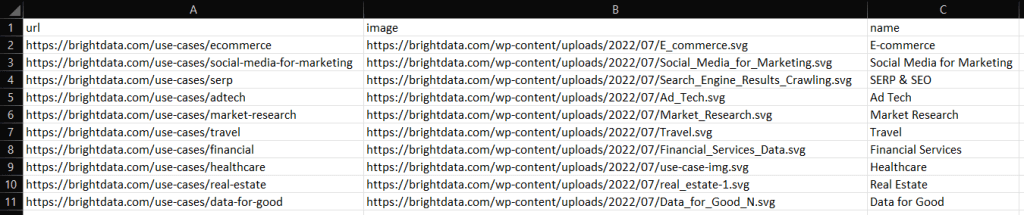
Del mismo modo, se pueden exportar las industrias a industry.json como se indica a continuación:
file, err:= os.Create("industries.json")
if err != nil {
log.Fatalln("Failed to create the output JSON file", err)
}
defer file.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
file.Write(jsonString)
This will produce the JSON file below:
[
{
"Url": "https://brightdata.com/use-cases/ecommerce",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"Name": "E-commerce"
},
// ...
{
"Url": "https://brightdata.com/use-cases/real-estate",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/real_estate-1.svg",
"Name": "Real Estate"
},
{
"Url": "https://brightdata.com/use-cases/data-for-good",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"Name": "Data for Good"
}
]¡Et voila! Ahora sabe cómo transferir los datos recopilados a un formato más útil.
Paso 8: Unirlo todo
Este es el aspecto del código completo del raspador Golang:
// scraper.go
package main
import (
"encoding/csv"
"encoding/json"
"log"
"os"
// import Colly
"github.com/gocolly/colly"
)
// definr some data structures
// to store the scraped data
type Industry struct {
Url, Image, Name string
}
func main() {
// initialize the struct slices
var industries []Industry
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url != "" && image != "" && name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
// connect to the target site
c.Visit("https://brightdata.com/")
// --- export to CSV ---
// open the output CSV file
csvFile, csvErr := os.Create("industries.csv")
// if the file creation fails
if csvErr != nil {
log.Fatalln("Failed to create the output CSV file", csvErr)
}
// release the resource allocated to handle
// the file before ending the execution
defer csvFile.Close()
// create a CSV file writer
writer := csv.NewWriter(csvFile)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
// --- export to JSON ---
// open the output JSON file
jsonFile, jsonErr := os.Create("industries.json")
if jsonErr != nil {
log.Fatalln("Failed to create the output JSON file", jsonErr)
}
defer jsonFile.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
jsonFile.Write(jsonString)
}¡En menos de 100 líneas de código, se puede construir un raspador de datos en Go!
Conclusión
En este tutorial, se ha visto por qué Go es un buen lenguaje para el raspado de datos. También, descubrió cuáles son las mejores bibliotecas de Go para raspado de datos y qué es lo que ofrecen. Luego, se mostró cómo usar Colly y la librería estándar de Go para crear una aplicación de raspado de datos. El raspador Go que se construyó aquí puede raspar datos de un objetivo verídico. Como se ha visto, el raspado de datos con Go sólo requiere unas pocas líneas de código.
Al mismo tiempo, hay que tener en cuenta que hay muchos retos a tener en cuenta cuando se extraen datos de Internet. Esta es la razón por la que muchos sitios web adoptan soluciones anti-scraping y anti-bot que pueden detectar y bloquear su script de raspado en Go. Afortunadamente, es posible construir un raspador web capaz de eludir y evitar cualquier bloqueo con el IDE para raspado web de próxima generación de Bright Data.
¿No le interesa el raspado de datos pero sí los datos web? Explore nuestros conjuntos de datos listos para usar.





