

En esta guía paso a paso, aprenderá cómo raspar Reddit usando Python.
Este tutorial cubrirá:
- La nueva política de la API de Reddit
- API de Reddit vs. raspado de Reddit
- Raspado de Reddit con Selenium
Nueva política de la API de Reddit
En abril de 2023, Reddit anunció nuevas tarifas para sus APIs de datos, básicamente haciéndolo inasequible para las empresas más pequeñas. En el momento de escribir estas líneas, la tarifa de la API está fijada en 0.24 dólares por cada 1,000 llamadas. Como es de imaginar, esta cifra puede aumentar rápidamente incluso para un uso modesto. Esto es especialmente cierto teniendo en cuenta las toneladas de contenido generado por los usuarios disponibles en Reddit y la enorme cantidad de llamadas necesarias para recuperarlo. Apollo, una de las aplicaciones de terceros más utilizadas basada en la API de Reddit, se vio obligada a cerrar por este motivo.
¿Significa esto el fin de Reddit como fuente de análisis de opiniones, comentarios de usuarios y datos de tendencias? Por supuesto que no. Hay una solución que es más eficaz, menos costosa y no está sujeta a decisiones corporativas de la noche a la mañana. Esa solución se llama raspado web. Averigüemos por qué.
API de Reddit vs. Raspado de Reddit
La API de Reddit es el método oficial para obtener datos del sitio. Teniendo en cuenta los recientes cambios de política y las direcciones tomadas por la plataforma, hay buenas razones por las que el raspado de Reddit es una mejor solución:
- Rentabilidad: considerando el nuevo gasto de la API de Reddit, raspar Reddit puede ser una alternativa mucho más asequible. Crear un raspador de Reddit en Python le permite recopilar datos sin incurrir en gastos adicionales asociados al uso de la API.
- Recopilación de datos mejorada: al raspar Reddit, usted tiene la flexibilidad de personalizar el código de extracción de datos para obtener sólo la información que se ajuste a sus necesidades. Esta personalización le ayuda a superar las limitaciones en el formato de los datos, la limitación de la tasa y las restricciones de uso de la API.
- Acceso a datos no oficiales: mientras que la API de Reddit sólo proporciona acceso a una selección curada de información, el raspado proporciona acceso a cualquier dato de acceso público en el sitio.
Ahora que ya conoce por qué el raspado es una opción más eficaz que llamar a las API, veamos cómo construir un raspador de Reddit en Python. Antes de pasar al siguiente capítulo, considere explorar nuestra guía en profundidad sobre raspado web con Python.
Raspado de Reddit con Selenium
En este tutorial paso a paso, verá cómo construir un script Python de raspado web de Reddit.
Paso 1: Configuración del proyecto
Primero asegúrese de cumplir con los siguientes prerrequisitos:
- Python 3+: Descargue el instalador, haga doble clic en él y siga las instrucciones de instalación.
- Un IDE de Python: PyCharm Community Edition o Visual Studio Code con la extensión Python.
Inicialice un proyecto Python con un entorno virtual a través de los siguientes comandos:
mkdir reddit-scraper
cd reddit-scraper
python -m venv envLa carpeta reddit-scraper creada aquí es la carpeta del proyecto para su script Python.
Abrir el directorio en el IDE, crear un archivo scraper.py, e inicializarlo como se indica a continuación:
print('Hello, World!')En este momento, este script simplemente imprime “¡Hola, Mundo!” pero pronto contendrá la lógica de raspado.
Compruebe que el programa funciona pulsando el botón de ejecución de su IDE o iniciándolo:
python scraper.pyEn la terminal, debería ver:
Hello, World!¡Maravilloso! Ya tiene un proyecto Python para su raspador de Reddit.
Paso 2: Seleccionar e instalar las librerías de raspado
Como ya sabrá, Reddit es una plataforma altamente interactiva. El sitio carga y presenta nuevos datos de forma dinámica en función de cómo los usuarios interactúan con sus páginas a través de operaciones de clic y desplazamiento. Desde una perspectiva técnica, esto significa que Reddit depende en gran medida de JavaScript.
Por lo tanto, el raspado de Reddit en Python requiere una herramienta que pueda renderizar páginas web en un navegador. Aquí es donde entra Selenium. Esta herramienta permite raspar sitios web dinámicos en Python, permitiendo operaciones automatizadas en páginas web en un navegador.
Se puede añadir Selenium y el Webdriver Manager a las dependencias del proyecto con:
pip install selenium webdriver-managerEl proceso de instalación puede tardar un poco, así que tenga paciencia.
El paquete webdriver-manager no es estrictamente necesario pero se recomienda ampliamente. De esta manera evitará tener que descargar, instalar y configurar manualmente los controladores web en Selenium. La librería se encargará de todo por usted.
Integre Selenium en su archivo scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# scraping logic...
# close the browser and free up the Selenium resources
driver.quit()Este script instancia un objeto Chrome WebDriver para controlar programáticamente una ventana de Chrome.
Por defecto, Selenium abre el navegador en una nueva ventana GUI. Esto es útil para monitorizar lo que el script está haciendo en las páginas para depuración. Al mismo tiempo, cargar un navegador con su UI consume muchos recursos. Por lo tanto, se recomienda configurar Chrome para que se ejecute en modo headless. Específicamente, la opción --headless=new le indicará a Chrome que inicie sin UI detrás de escena.
¡Listo! Es hora de visitar la página objetivo de Reddit.
Paso 3: Conectarse a Reddit
Aquí se muestra cómo extraer datos del subreddit r/Technology. Siga teniendo en cuenta que cualquier otro subreddit servirá.
En detalle, supongamos que quiere raspar la página con las principales publicaciones de la semana. Esta es la URL de la página de destino:
https://www.reddit.com/r/technology/top/?t=weekGuarda esa cadena en una variable Python:
url = 'https://www.reddit.com/r/technology/top/?t=week'Luego, use Selenium para visitar la página con:
driver.get(url)La función get() ordena al navegador controlado que se conecte a la página identificada por la URL pasada como parámetro.
Este es el aspecto de su raspador web de Reddit hasta ahora:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# the URL of the target page to scrape
url = 'https://www.reddit.com/r/technology/top/?t=week'
# connect to the target URL in Selenium
driver.get(url)
# scraping logic...
# close the browser and free up the Selenium resources
driver.quit()Compruebe su script. Abrirá la ventana del navegador de abajo durante una fracción de segundo antes de cerrarla debido a la instrucción quit():

Observe el mensaje “Chrome está siendo controlado por un software de prueba automatizado”. Estupendo. Eso asegura que Selenium está funcionando correctamente en Chrome.
Paso 4: Inspección de la página de destino
Antes de pasar al código, es necesario explorar la página de destino para ver qué información ofrece y cómo se puede recuperar. En concreto, hay que identificar qué elementos HTML contienen los datos de interés e idear estrategias de selección adecuadas.
Para simular las condiciones en las que opera Selenium, que es una sesión de navegador “vainilla”, abra la página Reddit de incógnito. Haga clic con el botón derecho del ratón en cualquier sección de la página y haga clic en “Inspeccionar” para abrir Chrome DevTools:

Esta herramienta permite comprender la estructura DOM de la página. Como se puede ver, el sitio se basa en clases CSS que parecen generarse aleatoriamente en el momento de la compilación. En otras palabras, no se deben basar en ellas las estrategias de selección.

Afortunadamente, los elementos más importantes del sitio tienen atributos HTML especiales. Por ejemplo, el nodo de descripción de subreddit tiene el siguiente atributo:
data-testid="no-edit-description-block"Esta es información útil para construir una lógica de selección de elementos HTML efectiva.
Siga analizando el sitio en DevTools y familiarícese con su DOM hasta que esté listo para raspar Reddit en Python.
Paso 5: Raspado de la información principal del subreddit
Primero, crea un diccionario Python donde almacenar los datos raspados:
subreddit = {}A continuación, tenga en cuenta que puede obtener el nombre del subreddit del elemento
en la parte superior de la página:

A continuación, obtenga el nombre del subreddit:
name = driver \
.find_element(By.TAG_NAME, 'h1') \
.textComo ya debe haber notado, parte de la información general más interesante sobre el subreddit se encuentra en la barra lateral de la derecha:

Se puede obtener la descripción del texto, la fecha de creación y el número de miembros con:
description = driver \
.find_element(By.CSS_SELECTOR, '[data-testid="no-edit-description-block"]') \
.get_attribute('innerText')
creation_date = driver \
.find_element(By.CSS_SELECTOR, '.icon-cake') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText') \
.replace('Created ', '')
members = driver \
.find_element(By.CSS_SELECTOR, '[id^="IdCard--Subscribers"]') \
.find_element(By.XPATH, "preceding-sibling::*[1]") \
.get_attribute('innerText')En este caso, no puede utilizar el atributo text porque las cadenas de texto están contenidas en nodos anidados. Si utilizara .text, obtendría una cadena vacía. En su lugar, es necesario llamar al método get_attribute() para leer el atributo innerText que devuelve el contenido de texto renderizado de un nodo y sus descendientes.
Si nos fijamos en el elemento fecha de creación, nos daremos cuenta de que no hay una manera fácil de seleccionarlo. Como es el nodo que sigue al icono de la tarta, seleccione primero el icono con .icon-cake, y luego utilice la expresión XPath following-sibling::*[1] para obtener el siguiente hermano. Limpie el texto recogido para eliminar la cadena “Creado ” llamando al método replace() de Python.
Cuando se trata del elemento contador del miembro suscriptor, ocurre algo similar. La principal diferencia es que en este caso es necesario acceder al hermano precedente.
No hay que olvidar añadir los datos raspados al diccionario subreddit:
subreddit['name'] = name
subreddit['description'] = description
subreddit['creation_date'] = creation_date
subreddit['members'] = membersImprima subreddit con print(subreddit), y ya se verá:
{'name': '/r/Technology', 'description': 'Subreddit dedicated to the news and discussions about the creation and use of technology and its surrounding issues.', 'creation_date': 'Jan 25, 2008', 'members': '14.4m'}¡Perfecto! Acabamos de hacer raspado web en Python.
Paso 6: Raspado de las entradas de subreddit
Dado que un subreddit muestra varias publicaciones, ahora es necesario un conjunto para almacenar los datos recopilados:
posts = []Inspecciona un elemento HTML post:

Aquí se puede observar que se pueden seleccionar todos con el [data-testid="post-container"] Selector CSS:
post_html_elements = driver \
.find_elements(By.CSS_SELECTOR, '[data-testid="post-container"]')Iterar sobre ellos. Para cada elemento, cree un diccionario de entradas para seguir los datos de cada entrada:
for post_html_element in post_html_elements:
post = {}
# scraping logic...Inspeccione el elemento upvote:
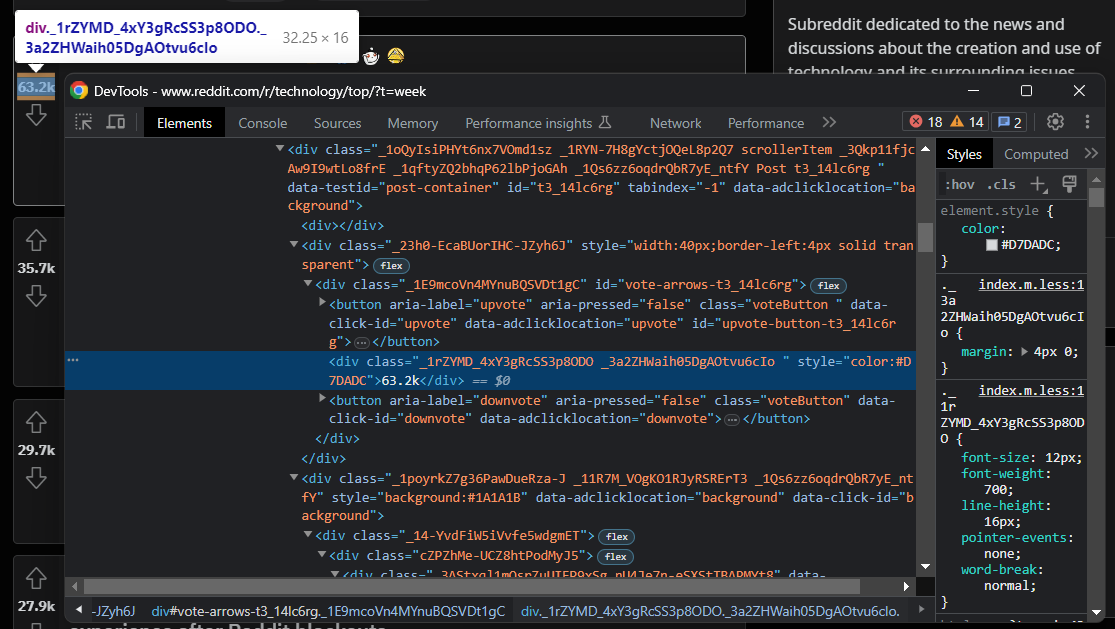
Puede recuperar esa información dentro del bucle for con:
upvotes = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="upvote"]') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText')Una vez más, lo mejor es obtener el botón upvote, que es fácil de seleccionar, y luego apuntar al siguiente hermano para recuperar la información de destino.
Inspeccione los elementos autor y título de la entrada:

Obtener estos datos es un poco más fácil:
author = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="post_author_link"]') \
.text
title = post_html_element \
.find_element(By.TAG_NAME, 'h3') \
.textA continuación, puede recopilar el número de comentarios y el enlace saliente:

try:
outbound_link = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="outbound-link"]') \
.get_attribute('href')
except NoSuchElementException:
outbound_link = None
comments = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="comments"]') \
.get_attribute('innerText') \
.replace(' Comments', '')Como el elemento outbound link es opcional, es necesario envolver la lógica de selección con un bloque try.
Añada estos datos a post y añádalos al array de posts sólo si title está presente. Esta comprobación adicional evita que se raspen las entradas con publicidad especial colocadas por Reddit:
# populate the dictionary with the retrieved data
post['upvotes'] = upvotes
post['title'] = title
post['outbound_link'] = outbound_link
post['comments'] = comments
# to avoid adding ad posts
# to the list of scraped posts
if title:
posts.append(post)Por último, añada los posts al diccionario de subreddits:
subreddit['posts'] = posts¡Bien hecho! Ya tiene todos los datos de Reddit deseados.
Paso 7: Exportar los datos raspados a JSON
Los datos recogidos están ahora dentro de un diccionario Python. Este no es el mejor formato para compartirlos con otros equipos. Para solucionarlo, es necesario exportarlos a JSON:
import json
# ...
with open('subreddit.json', 'w') as file:
json.dump(video, file)Importe json desde la Python Standard Library, cree un archivo subreddit.json con open(), y rellénelo con json.dump(). Consulte nuestra guía para obtener más información sobre cómo analizar JSON en Python.
¡Fantástico! Comenzó con datos sin procesar contenidos en una página HTML dinámica y ahora tiene datos JSON semiestructurados. Ahora ya puede ver todo el raspador de Reddit.
Paso 8: Conjuntando todo
Aquí está el script completo de scraper.py:
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import json
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# the URL of the target page to scrape
url = 'https://www.reddit.com/r/technology/top/?t=week'
# connect to the target URL in Selenium
driver.get(url)
# initialize the dictionary that will contain
# the subreddit scraped data
subreddit = {}
# subreddit scraping logic
name = driver \
.find_element(By.TAG_NAME, 'h1') \
.text
description = driver \
.find_element(By.CSS_SELECTOR, '[data-testid="no-edit-description-block"]') \
.get_attribute('innerText')
creation_date = driver \
.find_element(By.CSS_SELECTOR, '.icon-cake') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText') \
.replace('Created ', '')
members = driver \
.find_element(By.CSS_SELECTOR, '[id^="IdCard--Subscribers"]') \
.find_element(By.XPATH, "preceding-sibling::*[1]") \
.get_attribute('innerText')
# add the scraped data to the dictionary
subreddit['name'] = name
subreddit['description'] = description
subreddit['creation_date'] = creation_date
subreddit['members'] = members
# to store the post scraped data
posts = []
# retrieve the list of post HTML elements
post_html_elements = driver \
.find_elements(By.CSS_SELECTOR, '[data-testid="post-container"]')
for post_html_element in post_html_elements:
# to store the data scraped from the
# post HTML element
post = {}
# subreddit post scraping logic
upvotes = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="upvote"]') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText')
author = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="post_author_link"]') \
.text
title = post_html_element \
.find_element(By.TAG_NAME, 'h3') \
.text
try:
outbound_link = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="outbound-link"]') \
.get_attribute('href')
except NoSuchElementException:
outbound_link = None
comments = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="comments"]') \
.get_attribute('innerText') \
.replace(' Comments', '')
# populate the dictionary with the retrieved data
post['upvotes'] = upvotes
post['title'] = title
post['outbound_link'] = outbound_link
post['comments'] = comments
# to avoid adding ad posts
# to the list of scraped posts
if title:
posts.append(post)
subreddit['posts'] = posts
# close the browser and free up the Selenium resources
driver.quit()
# export the scraped data to a JSON file
with open('subreddit.json', 'w', encoding='utf-8') as file:
json.dump(subreddit, file, indent=4, ensure_ascii=False)¡Increíble! ¡Se puede construir un raspador web de Reddit en Python con poco más de 100 líneas de código!
Ejecute el script, y el siguiente archivo subreddit.json aparecerá en la carpeta raíz de su proyecto:
{
"name": "/r/Technology",
"description": "Subreddit dedicated to the news and discussions about the creation and use of technology and its surrounding issues.",
"creation_date": "Jan 25, 2008",
"members": "14.4m",
"posts": [
{
"upvotes": "63.2k",
"title": "Mojang exits Reddit, says they '\"no longer feel that Reddit is an appropriate place to post official content or refer [its] players to\".",
"outbound_link": "https://www.pcgamer.com/minecrafts-devs-exit-its-7-million-strong-subreddit-after-reddits-ham-fisted-crackdown-on-protest/",
"comments": "2.9k"
},
{
"upvotes": "35.7k",
"title": "JP Morgan accidentally deletes evidence in multi-million record retention screwup",
"outbound_link": "https://www.theregister.com/2023/06/26/jp_morgan_fined_for_deleting/",
"comments": "2.0k"
},
# omitted for brevity ...
{
"upvotes": "3.6k",
"title": "Facebook content moderators in Kenya call the work 'torture.' Their lawsuit may ripple worldwide",
"outbound_link": "https://techxplore.com/news/2023-06-facebook-content-moderators-kenya-torture.html",
"comments": "188"
},
{
"upvotes": "3.6k",
"title": "Reddit is telling protesting mods their communities ‘will not’ stay private",
"outbound_link": "https://www.theverge.com/2023/6/28/23777195/reddit-protesting-moderators-communities-subreddits-private-reopen",
"comments": "713"
}
]
}¡Felicidades! ¡Acaba de aprender a raspar Reddit en Python!
Conclusión
Raspar Reddit es una mejor manera de obtener datos que usar su API, especialmente después de las nuevas políticas. En este tutorial paso a paso, hemos explicado cómo construir un raspador en Python para recuperar datos de subreddits. Como se muestra aquí, sólo requiere unas pocas líneas de código.
Al mismo tiempo, al igual que cambiaron sus políticas de API de la noche a la mañana, Reddit podría implementar pronto estrictas medidas contra el raspado. Extraer datos de él se convertiría en una proeza, ¡pero hay una solución! Scraping Browser de Bright Data es una herramienta que puede renderizar JavaScript igual que Selenium mientras gestiona automáticamente las huellas dactilares, los CAPTCHAs y el anti raspado por usted.
Si eso no es lo suyo, hemos construido un raspador de Reddit para satisfacer sus necesidades. Gracias a esta solución fiable y fácil de usar, puede obtener todos los datos de Reddit que desee sin preocupaciones.
¿No desea lidiar con el raspado web de Reddit en absoluto pero le interesan los datos de subreddits? Adquiera un conjunto de datos de Reddit.



