

La mayoría de los datos de raspado web provienen de sitios web dinámicos, como Twitter, Amazon y YouTube. Estos sitios web proporcionan una experiencia de usuario interactiva y con capacidad de respuesta basada en la entrada del usuario. Por ejemplo, cuando accede a su cuenta de YouTube, el contenido de video presentado se adapta a su entrada. Por ello, el raspado de sitios web dinámicos puede resultar más complicado, ya que los datos están sujetos a modificaciones constantes por las interacciones de los usuarios.
Para raspar datos de sitios dinámicos, es necesario utilizar técnicas avanzadas que simulen la interacción de un usuario con el sitio web, navegar y seleccionar contenido específico generado por JavaScript y gestionar solicitudes asíncronas de JavaScript y XML (AJAX).
En esta guía mostraremos cómo extraer datos de un sitio web dinámico utilizando una biblioteca de Python de código abierto llamada Selenium.
Extracción de datos de un sitio web dinámico con Selenium
Antes de comenzar a extraer datos de un sitio dinámico, es importante conocer el paquete de Python que utilizará: Selenium.
¿Qué es Selenium?
Selenium es un paquete Python de código abierto y un marco de pruebas automatizadas que permite ejecutar varias operaciones o tareas en sitios web dinámicos. Estas tareas incluyen cosas como abrir/cerrar diálogos, buscar consultas particulares en YouTube, o rellenar formularios, todo en su navegador web preferido.
Cuando se utiliza Selenium con Python, es posible controlar el navegador web y extraer automáticamente datos de sitios web dinámicos escribiendo sólo unas cuantas líneas de código Python con el paquete Selenium Python.
Ahora que ya sabe cómo funciona Selenium, empecemos.
Crear un nuevo proyecto Python
Lo primero que se debe hacer es crear un nuevo proyecto Python. Cree un directorio llamado data_scraping_project donde se almacenarán todos los datos recopilados y los archivos de código fuente. Este directorio tendrá dos subdirectorios:
scriptscontendrá todos los scripts Python que extraen y recopilan datos del sitio web dinámico.dataes donde se almacenarán todos los datos extraídos del sitio web dinámico.
Instalar paquetes Python
Después de crear el directorio data_scraping_project, deberá instalar los siguientes paquetes de Python para extraer, recopilar y guardar datos de un sitio web dinámico:
- Webdriver Manager
- pandas
Puede instalar el paquete Selenium Python ejecutando el siguiente comando pip en su terminal:
pip install selenium
Selenium utilizará el controlador binario para controlar el navegador web de su elección. Este paquete Python proporciona controladores binarios para los siguientes navegadores web soportados: Chrome, Chromium, Brave, Firefox, IE, Edge y Opera.
A continuación, ejecute el siguiente comando pip en su terminal para instalar webdriver-manager:
pip install webdriver-manager
Para instalar pandas, ejecute el siguiente comando pip:
pip install pandas
Lo que se va a raspar
Con este artículo, se raspará datos de dos lugares diferentes: un canal de YouTube llamado Programming with Mosh y Hacker News:
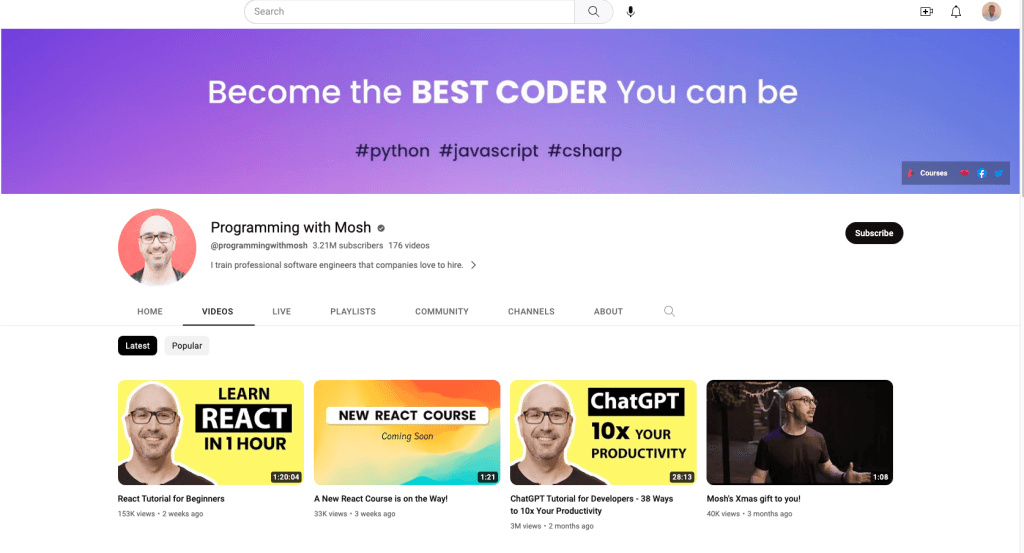
Del canal de YouTube Programming with Mosh, se obtendrá la siguiente información:
- El título del vídeo.
- El enlace o URL del vídeo.
- El enlace o URL de la imagen.
- El número de visualizaciones del vídeo en cuestión.
- La hora de publicación del vídeo.
- Los comentarios de la URL de un vídeo concreto de YouTube.
Y de Hacker News, se recopilará los siguientes datos:
- El título del artículo.
- El enlace al artículo.

Ahora que sabe lo que va a raspar, vamos a crear un nuevo script de Python (es decir, data_scraping_project/scripts/youtube_videos_list.py).
Importar paquetes Python
En primer lugar, es necesario importar los paquetes de Python que se utilizarán para raspar, recopilar y guardar los datos en un archivo CSV:
# import libraries
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd
Instanciar el Webdriver
Para instanciar el Webdriver, se debe seleccionar el navegador que utilizará Selenium (Chrome, en este caso) y, a continuación, instalar el controlador binario.
Chrome dispone de herramientas de desarrollador para mostrar el código HTML de la página web e identificar los elementos HTML que se van a raspar y recopilar los datos. Para mostrar el código HTML, es necesario hacer clic con el botón derecho del ratón en una página web del navegador Chrome y seleccionar Inspeccionar elemento.
Para instalar un controlador binario para Chrome, ejecute el siguiente código:
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
El controlador binario para Chrome se instalará en su máquina e instanciará automáticamente Webdriver.
Extracción de datos con Selenium
Para raspar datos con Selenium, es necesario definir la URL de YouTube en una simple variable Python (ie url). A partir de este enlace, se recopilan todos los datos que se han mencionado anteriormente excepto los comentarios de una URL de YouTube en particular:
# Define the URL
url = "https://www.youtube.com/@programmingwithmosh/videos"
# load the web page
driver.get(url)
# set maximum time to load the web page in seconds
driver.implicitly_wait(10)
Selenium carga automáticamente el enlace de YouTube en el navegador Chrome. Además, se especifica un intervalo de tiempo (es decir, diez segundos) para asegurarse de que la página web está completamente cargada (incluidos todos los elementos HTML). Esto ayuda a raspar datos que son renderizados por JavaScript.
Raspado de datos mediante ID y etiquetas
Uno de los beneficios de Selenium es que permite extraer datos utilizando diferentes elementos presentados en la página web, incluyendo el ID y la etiqueta.
Por ejemplo, puede utilizar el elemento ID (p. ej., post-title) o las etiquetas (p. ej., h1 y p) para extraer los datos:
<h1 id ="post-title">Introduction to data scrapping using Python</h1>
<p>You can use selenium python package to collect data from any dynamic website</p>
O si se desea extraer datos del enlace de YouTube, es posible utilizar el ID que aparece en la página web. Se abre la URL de YouTube en el navegador, se hace clic con el botón derecho y se selecciona Inspeccionar para identificar el ID. A continuación, se utiliza el ratón para ver la página e identificar el ID que contiene la lista de vídeos presentados en el canal:
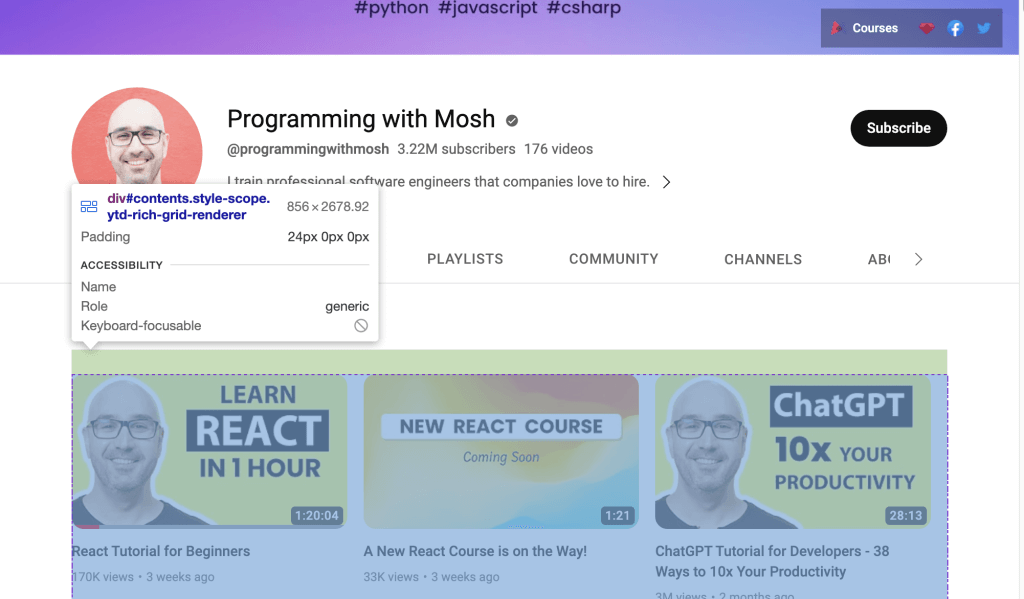
Utilice Webdriver para raspar los datos que se encuentran dentro del ID identificado. Para buscar un elemento HTML por el atributo ID, llame al método find_element() Selenium y pase By.ID como primer argumento e ID como segundo argumento.
Para recopilar el título del vídeo y el enlace del vídeo para cada vídeo, debe utilizar el atributo ID video-title-link. Como se recopilarán varios elementos HTML con este atributo ID, se deberá utilizar el método find_elements():
# collect data that are withing the id of contents
contents = driver.find_element(By.ID, "contents")
#1 Get all the by video tite link using id video-title-link
video_elements = contents.find_elements(By.ID, "video-title-link")
#2 collect title and link for each youtube video
titles = []
links = []
for video in video_elements:
#3 Extract the video title
video_title = video.get_attribute("title")
#4 append the video title
titles.append(video_title)
#5 Extract the video link
video_link = video.get_attribute("href")
#6 append the video link
links.append(video_link)
Este código realiza las siguientes tareas:
- Recopila los datos que están dentro del atributo ID del
contenido. - Recopila todos los elementos HTML que tienen un atributo ID de
video-title-linkdel objeto decontenidoWebElement. - Crea dos listas para añadir títulos y enlaces.
- Extrae el título del vídeo utilizando el método
get_attribute()y pasa eltítulo. - Añade el título del vídeo a la lista de títulos.
- Extrae el enlace del vídeo utilizando el método
get_atribute()y pasahrefcomo argumento. - Añade el enlace del vídeo a la lista de enlaces.
Para este punto, todos los títulos y enlaces de vídeo estarán en dos listas de Python: títulos y enlaces.
A continuación, se raspa el enlace de la imagen que está disponible en la página web antes de hacer clic en el enlace de vídeo de YouTube para ver el vídeo. Para raspar este enlace de imagen, es necesario encontrar todos los elementos HTML llamando al método find_elements() Selenium y pasando By.TAG_NAME como primer argumento y el nombre de la etiqueta como segundo argumento:
#1 Get all the by Tag
img_elements = contents.find_elements(By.TAG_NAME, "img")
#2 collect img link and link for each youtube video
img_links = []
for img in img_elements:
#3 Extract the img link
img_link = img.get_attribute("src")
if img_link:
#4 append the img link
img_links.append(img_link)
Este código recopila todos los elementos HTML con el nombre de etiqueta img del objeto WebElement llamado contents. También crea una lista para añadir los enlaces de imagen y la extrae utilizando el método get_attribute() y pasa src como argumento. Finalmente, añade el enlace de la imagen a la lista img_links.
También es posible utilizar el ID y el nombre de la etiqueta para extraer más datos de cada vídeo de YouTube. En la página web de la URL de YouTube, debe poderse ver el número de visualizaciones y la hora de publicación de cada vídeo que aparece en la página. Para extraer estos datos, se recopilan todos los elementos HTML que tengan un ID de metadata-line y, a continuación, se recopilan los datos de los elementos HTML con un nombre de etiqueta span:
#1 find the element with the specific ID you want to scrape
meta_data_elements = contents.find_elements(By.ID, 'metadata-line')
#2 collect data from span tag
meta_data = []
for element in meta_data_elements:
#3 collect span HTML element
span_tags = element.find_elements(By.TAG_NAME, 'span')
#4 collect span data
span_data = []
for span in span_tags:
#5 extract data for each span HMTL element.
span_data.append(span.text)
#6 append span data to the list
meta_data.append(span_data)
# print out the scraped data.
print(meta_data)
Este bloque de código recopila todos los elementos HTML que tienen un atributo ID de metadata-line del objeto WebElement contents y crea una lista para añadir datos de la etiqueta span que tendrá el número de visualizaciones y la hora de publicación.
También recopila todos los elementos HTML cuyo nombre de etiqueta es span del objeto WebElement llamado meta_data_elements y crea una lista con estos datos span. A continuación, extrae los datos de texto del elemento HTML span y los añade a la lista span_data. Por último, añade los datos de la lista span_data a meta_data.
Los datos extraídos del elemento HTML span tendrán este aspecto:

A continuación, se debe crear dos listas Python y guardar el número de visualizaciones y el tiempo de publicación por separado:
#1 Iterate over the list of lists and collect the first and second item of each sublist
views_list = []
published_list = []
for sublist in meta_data:
#2 append number of views in the views_list
views_list.append(sublist[0])
#3 append time published in the published_list
published_list.append(sublist[1])
Aquí, se crean dos listas Python que extraen datos de meta_data, y se añade el número de vistas de cada sublista a view_list y el tiempo publicado de cada sublista a published_list.
Para este punto, se ha extraído el título del vídeo, la URL de la página del vídeo, la URL de la imagen, el número de visionados y la hora de publicación del vídeo. Estos datos se pueden guardar en un pandas DataFrame utilizando el paquete pandas Python. Utilice el siguiente código para guardar los datos de la lista de títulos, enlaces, img_links, views_list, y published_list en el pandas DataFrame:
# save in pandas dataFrame
data = pd.DataFrame(
list(zip(titles, links, img_links, views_list, published_list)),
columns=['Title', 'Link', 'Img_Link', 'Views', 'Published']
)
# show the top 10 rows
data.head(10)
# export data into a csv file.
data.to_csv("../data/youtube_data.csv",index=False)
driver.quit()
Así es como deben verse los datos raspados en la DataFrame de pandas:

Estos datos guardados se exportan desde pandas a un archivo CSV llamado youtube_data.csv usando to_csv().
Ahora es posible ejecutar youtube_videos_list.py, y asegurarse de que todo funciona correctamente.
Raspado de datos usando el selector CSS
Selenium también puede extraer datos basándose en los patrones específicos de los elementos HTML utilizando el selector CSS de la página web. El selector CSS se aplica a elementos específicos según su ID, nombre de etiqueta, clase u otros atributos.
Por ejemplo, aquí, la página HTML tiene algunos elementos div, y uno de ellos tiene un nombre de clase "inline-code":
<html>
<body>
<p>Hello World!</p>
<div>Learn Data Scraping</div>
<div class="inline-code"> data scraping with Python code</div>
<div>Saving</div>
</body>
</html>
Es posible utilizar un selector CSS para encontrar el elemento HTML en una página web cuyo nombre de etiqueta es div y cuyo nombre de clase es “‘inline-code”`. Es posible aplicar este mismo enfoque para extraer comentarios de la sección de comentarios de los vídeos de YouTube.
Ahora, vamos a utilizar un selector CSS para recopilar los comentarios publicados en este vídeo de YouTube.
La sección de comentarios de YouTube está disponible bajo la siguiente etiqueta y nombre de clase:
<ytd-comment-thread-renderer class="style-scope ytd-item-section-renderer">...</tyd-comment-thread-renderer>
Vamos a crear un nuevo script (es decir, data_scraping_project/scripts/youtube_video_ comments.py). Importe todos los paquetes necesarios como antes, y añada el siguiente código para iniciar automáticamente el navegador web Chrome, navegue por la URL del vídeo de YouTube, y luego raspe los comentarios utilizando el selector CSS:
#1 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#2 Define the URL
url = "https://www.youtube.com/watch?v=hZB5bHDCmeY"
#3 Load the webpage
driver.get(url)
#4 define the CSS selector
comment_section = 'ytd-comment-thread-renderer.ytd-item-section-renderer’
#5 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, comment_section))
)
except:
driver.quit()
#6. collect HTML elements within the CSS selector
comment_blocks = driver.find_elements(By.CSS_SELECTOR,comment_section)
Este código instala el controlador de Chrome y define el enlace del vídeo de YouTube para extraer los comentarios que se han publicado. A continuación, carga la página web en el navegador y espera diez segundos hasta que estén disponibles los elementos HTML que coincidan con el selector CSS.
A continuación, recopila todos los elementos HTML de los comentarios utilizando el selector CSS llamado ytd-comment-thread-renderer.ytd-item-section-renderer y guarda todos los elementos de los comentarios en el objeto comment_blocks WebElement.
A continuación, se puede extraer el nombre de cada autor utilizando el ID author-text y el texto del comentario utilizando el ID content-text de cada comentario en el objeto comment_blocks WebElement:
#1 specify the id attribute for author and comment
author_id = 'author-text'
comment_id = 'content-text'
#2 Extract the text value for each comment and author in the list
comments = []
authors = []
for comment_element in comment_blocks:
#3 collect author for each comment
author = comment_element.find_element(By.ID, author_id)
#4 append author name
authors.append(author.text)
#5 collect comments
comment = comment_element.find_element(By.ID, comment_id)
#6 append comment text
comments.append(comment.text)
#7 save in pandas dataFrame
comments_df = pd.DataFrame(list(zip(authors, comments)), columns=['Author', 'Comment'])
#8 export data into a CSV file.
comments_df.to_csv("../data/youtube_comments_data.csv",index=False)
driver.quit()
Este código especifica el ID para el autor y el comentario. A continuación, se crea dos listas Python para añadir el nombre del autor y el texto del comentario. Recopila cada elemento HTML que tiene los atributos ID especificados del objeto WebElement y añade los datos a las listas Python.
Por último, guarda en un DataFrame de pandas los datos obtenidos y los exporta a un archivo CSV llamado youtube_comments_data.csv.
Este es el aspecto que tendrán los autores y comentarios de las diez primeras filas en un DataFrame de pandas:

Raspado de datos usando el nombre de la clase
Además de raspar datos con el selector CSS, también se puede extraer datos basándose en un nombre de clase específico. Para encontrar un elemento HTML por su atributo class name usando Selenium, se necesita llamar al método find_element() y pasar By.CLASS_NAME como primer argumento, y se debe encontrar el nombre de la clase como segundo argumento.
En esta sección, se utilizará el nombre de clase para recopilar el título y el enlace de los artículos publicados en Hacker News. En esta página web, el elemento HTML que tiene el título y el enlace de cada artículo tiene un nombre de clase titleline, como se ve en el código de la página web:
<span class="titleline"><a href="https://mullvad.net/en/browser">The Mullvad Browser</a><span class="sitebit comhead"> (<a href="from?site=mullvad.net"><span class="sitestr">mullvad.net</span></a>)</span></span></td></tr><tr><td colspan="2"></td><td class="subtext"><span class="subline">
<span class="score" id="score_35421034">302 points</span> by <a href="user?id=Foxboron" class="hnuser">Foxboron</a> <span class="age" title="2023-04-03T10:11:50"><a href="item?id=35421034">2 hours ago</a></span> <span id="unv_35421034"></span> | <a href="hide?id=35421034&auth=60e6bdf9e482441408eb9ca98f92b13ee2fac24d&goto=news" class="clicky">hide</a> | <a href="item?id=35421034">119 comments</a> </span>
Cree un nuevo script Python (por ejemplo, data_scraping_project/scripts/hacker_news.py), importe todos los paquetes necesarios y añada el siguiente código Python para extraer el título y el enlace de cada artículo publicado en la página de Hacker News:
#1 define url
hacker_news_url = 'https://news.ycombinator.com/'
#2 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 load the web page
driver.get(hacker_news_url)
#4 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'titleline'))
)
except:
driver.quit()
#5 Extract the text value for each title and link in the list
titles= []
links = []
#6 Find all the articles on the web page
story_elements = driver.find_elements(By.CLASS_NAME, 'titleline')
#7 Extract title and link for each article
for story_element in story_elements:
#8 append title to the titles list
titles.append(story_element.text)
#9 extract the URL of the article
link = story_element.find_element(By.TAG_NAME, "a")
#10 appen link to the links list
links.append(link.get_attribute("href"))
driver.quit()
Este código definirá la URL de la página web, iniciará automáticamente el navegador web Chrome y, a continuación, navegará por la URL de Hacker News. Espere diez segundos hasta que los elementos HTML que coincidan con el CLASS NAME estén disponibles.
A continuación, crea dos listas Python para añadir el título y el enlace de cada artículo. También recopila cada elemento HTML que tiene un nombre de clase titleline del objeto controlador WebElement y extrae el título y el enlace de cada artículo representado en el objeto WebElement story_elements.
Por último, el código añade el título del artículo a la lista de títulos y recopila el elemento HTML que tiene un nombre de etiqueta a del objeto story_element. Extrae el enlace utilizando el método get_attribute() y añade el enlace a la lista de enlaces.
A continuación, debe utilizar el método to_csv() de pandas para exportar los datos extraídos. Exportará tanto los títulos como los enlaces a un archivo CSV hacker_news_data.csv y guardará los datos en el directorio:
# save in pandas dataFrame
hacker_news = pd.DataFrame(list(zip(titles, links)),columns=['Title', 'Link'])
# export data into a csv file.
hacker_news.to_csv("../data/hacker_news_data.csv",index=False)
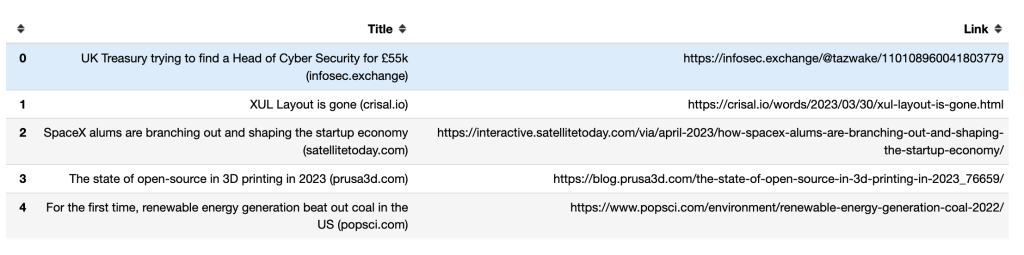
Así es como aparecen los títulos y enlaces de las cinco primeras filas en un DataFrame de pandas:
Cómo manejar scrolls infinitos
Algunas páginas web dinámicas cargan contenido adicional a medida que se desplaza hasta el final de la página. Si no se desplaza hasta el final de la página, Selenium sólo puede obtener los datos visibles en la pantalla.
Para obtener más datos, Selenium debe desplazarse hasta la parte inferior de la página, esperar a que se cargue nuevo contenido y, a continuación, obtener automáticamente los datos que desee. Por ejemplo, el siguiente script de Python se desplazará por los primeros cuarenta resultados de libros de Python y extraerá sus enlaces:
#1 import packages
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#2 Instantiate a Chrome webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 Navigate to the webpage
driver.get("https://example.com/results?search_query=python+books")
#4 instantiate a list to keep links
books_list = []
#5 Get the height of the current webpage
last_height = driver.execute_script("return document.body.scrollHeight")
#6 set target count
books_count = 40
#7 Keep scrolling down on the web page
while books_count > len(books_list):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
#8 Wait for the page to load
time.sleep(5)
#9 Calculate the new height of the page
new_height = driver.execute_script("return document.body.scrollHeight")
#10 Check if you have reached the bottom of the page
if new_height == last_height:
break
last_height = new_height
#11 Extract the data
links = driver.find_elements(By.TAG_NAME, "a")
for link in links:
#12 append extracted data
books_list.append(link.get_attribute("href"))
#13 Close the webdriver
driver.quit()
Este código importa los paquetes de Python que se utilizarán e instala y abre Chrome. A continuación, navega a la página web y crea una lista Python para añadir el enlace de cada uno de los resultados de la búsqueda.
Obtiene la altura de la página actual ejecutando el script return document.body.scrollHeight y establece el número de enlaces que se desea recopilar. Luego continúa desplazándose hacia abajo mientras el valor de la variable book_count sea mayor que la longitud de la book_list y espera cinco segundos para cargar la página.
Calcula la nueva altura de la página web ejecutando el script return document.body.scrollHeight y comprueba si ha llegado al final de la página. Si lo hace, finaliza el bucle; en caso contrario, actualizará last_height y continuará desplazándose hacia abajo. Finalmente, recopila el elemento HTML que tiene un nombre de etiqueta a del objeto WebElement y extrae y añade el enlace a la lista de enlaces. Después de recopilar los enlaces, cerrará el Webdriver.
Nota: Para que su script termine en algún momento, debe establecer un número total de elementos a raspar si la página tiene desplazamiento infinito. Si no lo hace, su código continuará ejecutándose.
Raspado web con Bright Data
Aunque es posible raspar datos con raspadores de código abierto como Selenium, suelen carecer de soporte. Además, el proceso puede ser complicado y lento. Si está buscando una solución de raspado web potente y fiable, debería considerar Bright Data.
Bright Data es una plataforma de datos web que le permite raspar datos web públicos proporcionando diferentes herramientas y servicios que incluyen soluciones de raspado web, proxies y conjuntos de datos previamente recopilados. Incluso puede utilizar el IDE Web Scraper alojado para diseñar sus propios raspadores en un entorno de codificación JavaScript.
El IDE de Web Scraper también cuenta con funciones de raspado preconfiguradas y plantillas de código para diferentes sitios web dinámicos populares, incluyendo las plantillas del raspador de Twitter, el raspador de Indeed y el raspador de Walmart. Esto significa que es fácil acelerar el desarrollo y escalar rápidamente.
Bright Data ofrece diversas opciones para dar formato a los datos, como JSON, NDJSON, CSV y Microsoft Excel. También está integrado con diferentes plataformas para que pueda entregar sus datos raspados fácilmente.
Conclusión
El raspado de datos de sitios web dinámicos requiere esfuerzo y planificación. Con Selenium, puede interactuar automáticamente con cualquier sitio web dinámico y recopilar datos de él.
Aunque es posible raspar datos con Selenium, es lento y complicado. Es por eso que se recomienda raspar sitios web dinámicos con el IDE Web Scraper. Con sus funciones de raspado y plantillas de código predefinidas, puede empezar a extraer datos de inmediato.




