- Raspador de datos basado en API
Usa nuestra interfaz para crear tu solicitud de API - Automatización a escala
Crea tu propio planificador para controlar la frecuencia - Entrega
Entrega los datos a tu almacenamiento preferido o descárgalos



Raspador de la CNN
Raspa la CNN y recopila datos como la URL, el autor, el titular, los temas, la fecha de publicación, los contenidos y mucho más.
No se requiere tarjeta de crédito

- Scrape a demanda a través de API o scraper sin código
- Gerente de cuenta dedicado
- Gestión de solicitudes masivas, hasta 5K URLs
- Recuperar resultados en múltiples formatos
Confiado por 20,000+ clientes
Extrae datos de CNN sin esfuerzo

API de raspado web CNN
Usa esta API para empezar a recopilar datos con parámetros específicos

Raspador sin código CNN
Empieza a recopilar datos fácilmente con este raspador listo para usar
- Raspador basado en un panel de control
Toda la interacción se realiza dentro de nuestro panel de control - Fácil de usar
Añade tu información al raspador de datos y listo - Recupera los resultados del CP
Los resultados se pueden descargar directamente del CP
Raspadores web
Raspadores de la CNN y similares a tu disposición
Ahórrate la necesidad de desarrollar y mantener la infraestructura. Extrae grandes volúmenes de datos web de forma sencilla y garantiza la escalabilidad y la fiabilidad mediante las API de raspado de datos web o herramientas sin código.
¿Solo quieres obtener datos? Olvídate del raspado de datos.
Compra un conjunto de datos de la CNN
USO MÁS RÁPIDO
Un toque de la API. Toneladas de datos.
Descubrimiento de datos
Detectar estructuras y patrones de datos para garantizar una extracción de datos eficiente y concreta.
Gestión de solicitudes masivas
Reducir la carga del servidor y optimizar la recopilación de datos para las tareas de raspado de gran volumen.
Análisis de datos
Convertir de forma eficiente el HTML sin procesar en datos estructurados, lo que facilita la integración y el análisis de los datos.
Validación de datos
Garantizar la fiabilidad de los datos y ahorrar tiempo en las comprobaciones manuales y en el procesamiento previo.
BAJO EL CAPÓ
Nunca más te preocupes por los proxies y los CAPTCHAs
- Rotación automática de IP
- Resolución de CAPTCHA
- Rotación de agente de usuario
- Encabezados personalizados
- Renderizado de JavaScript
- Proxies residenciales
CNN Scraper API Pricing
Only pay for what’s successfully delivered. No hidden fees, no charges for failed deliveries.
Obtén un 25% de descuento en Scraper API durante 3 meses. Usa el código APIS25 al pagar.
Aceitamos esses métodos de pagamento:
Cada plan te da acceso completo - paga menos por registro a medida que escalas
Recolección de Datos
- Gestión automatizada de proxies
- Renderizado completo del navegador
- Resolución CAPTCHA
Rendimiento a escala
- Concurrencia ilimitada
- Recolección por lotes y programada
- APIs de gestión de trabajos
Entrega de datos
- Validación y descubrimiento de datos
- Análisis de datos (JSON o CSV)
- Entrega por webhook o API
Web Scraper API demo
LA MEJOR EXPERIENCIA DIGITAL
Fácil de empezar. Más fácil aún de ajustar.
Estabilidad inigualable
Asegúrate de que el rendimiento sea uniforme y de que se minimicen los fallos al confiar en la infraestructura de proxy que es líder mundial.
Extracción web simplificada
Pon tu herramienta de raspado web en automático gracias a API que están listas para funcionar, de manera que ahorras recursos y reduces el mantenimiento.
Capacidad ilimitada para ajustar la escala
Ajusta la escala de tus proyectos de raspado sin ningún problema para poder satisfacer las demandas de datos y para mantener un rendimiento óptimo.
API para acceso fluido a datos de CNN
Extracción de datos web integral, escalable y compatible
API para acceso fluido a datos de CNN
Extracción de datos web integral, escalable y compatible
Adaptado a tu flujo de trabajo
Obtén datos estructurados en archivos JSON, NDJSON o CSV mediante entrega por Webhook o API.
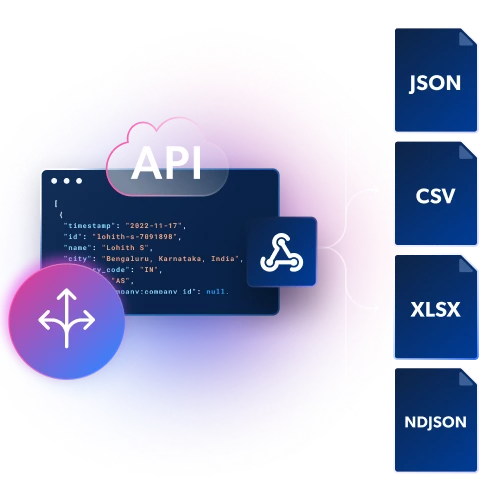
Infraestructura y desbloqueo integrados
Obtén el máximo control y flexibilidad sin mantener infraestructura de Proxy y desbloqueo. Extrae datos fácilmente desde cualquier ubicación geográfica evitando CAPTCHAs y bloqueos.

Infraestructura probada en batalla
La plataforma de Bright Data impulsa a más de 20.000 empresas en todo el mundo, ofreciendo tranquilidad con un tiempo de actividad del 99,99% y acceso a más de 150 millones de IPs reales de usuarios en 195 países.

Cumplimiento líder en la industria
Nuestras prácticas de privacidad cumplen con las leyes de protección de datos, incluido el marco regulatorio de protección de datos de la UE, el GDPR y la CCPA.

API para acceso fluido a datos de CNN
Extracción de datos web integral, escalable y compatible
FLEXIBLE
Adaptado a tu flujo de trabajo
Obtén datos estructurados en archivos JSON, NDJSON o CSV mediante entrega por Webhook o API.ESCALABLE
Infraestructura y desbloqueo integrados
Obtén el máximo control y flexibilidad sin mantener infraestructura de Proxy y desbloqueo. Extrae datos fácilmente desde cualquier ubicación geográfica evitando CAPTCHAs y bloqueos.ESTABLE
Infraestructura probada en batalla
La plataforma de Bright Data impulsa a más de 20.000 empresas en todo el mundo, ofreciendo tranquilidad con un tiempo de actividad del 99,99% y acceso a más de 150 millones de IPs reales de usuarios en 195 países.COMPATIBLE
Cumplimiento líder en la industria
Nuestras prácticas de privacidad cumplen con las leyes de protección de datos, incluido el marco regulatorio de protección de datos de la UE, el GDPR y la CCPA.Casos prácticos de la API de raspado para CNN
Scrape CNN to optimize your marketing strategy.
Use our CNN scraper to make smarter marketing decisions.
Collect CNN data to enrich your systems with fresh news.
Collect headlines, content, authors, and more from CNN.
Por qué 20,000+ clientes eligen Bright Data
100% Cumplimiento
Los datos obtenidos mediante scraping son obtenidos de forma ética y cumplen con todas las leyes de privacidad.
Soporte global 24/7
Un equipo dedicado de profesionales de datos está aquí para ayudarte.
Cobertura de datos completa
Accede a 400 million+ IPs globales para hacer scraping de datos de cualquier sitio web.
Calidad de datos inigualable
Tecnologías avanzadas y métodos de validación para datos de calidad.
Infraestructura potente
Haz scraping de datos de alto volumen sin ser bloqueado.
Soluciones personalizadas
Obtén soluciones a medida para satisfacer necesidades y objetivos únicos.
Bright Data es utilizado por las mejores marcas del mundo
Ayudamos a las empresas a crecer con una gestión de datos segura, escalable y flexible.
Desea obtener más información?
Hable con un experto para analizar sus necesidades de raspado.
Preguntas frecuentes sobre las API de raspado de la CNN
¿Qué es la API de raspado de la CNN?
La API de raspado de la CNN es una potente herramienta diseñada para automatizar la extracción de datos del sitio web de la CNN, lo que permite a los usuarios recopilar y procesar grandes volúmenes de datos de manera eficiente para distintos casos prácticos.
¿Cómo funciona la API de raspado de la CNN?
La API de raspado de la CNN funciona enviando solicitudes automatizadas al sitio web de la CNN, extrayendo los puntos de datos necesarios y entregándolos en un formato estructurado. Este proceso garantiza una recopilación de datos rápida y precisa.
¿Qué puntos de datos se pueden recopilar con la API de raspado de la CNN?
Los puntos de datos que se pueden recopilar con la API de raspado de la CNN incluyen titulares, autor, temas, fecha de publicación, contenidos, imágenes, artículos relacionados, palabras clave y mucho más.
¿La API de raspado de la CNN cumple con las normas de protección de datos?
Sí, la API de raspado de la CNN está diseñada para cumplir la normativa de protección de datos, incluidos el RGPD y la CCPA. Garantiza que todas las actividades de recopilación de datos se realicen de forma ética y legal.
¿Puedo usar la API de raspado de la CNN para analizar a la competencia?
¡Por supuesto! La API de raspado de la CNN es ideal para el análisis de la competencia, ya que te permite recopilar información sobre las actividades, tendencias y estrategias de la competencia.
¿Cómo puedo integrar la API de raspado de la CNN en mis sistemas actuales?
La API de raspado de la CNN ofrece una integración perfecta con varias plataformas y herramientas. Puedes usarla con tus canales de datos, sistemas de gestión de relaciones con el cliente o herramientas de análisis existentes para mejorar tus capacidades de procesamiento de datos.
¿Cuáles son los límites de uso de la API de raspado de la CNN?
No hay límites de uso específicos para la API de raspado de la CNN, lo que te ofrece la flexibilidad de adaptar a escala según sea necesario. Los precios comienzan desde 0,001 $ por registro, lo que garantiza una escalabilidad rentable para tus proyectos de raspado web.
¿Ofrecéis asistencia para la API de raspado de la CNN?
Sí, ofrecemos asistencia específica para la API de raspado de la CNN. Nuestro equipo de asistencia está disponible las 24 horas del día los 7 días de la semana para ayudarte con cualquier pregunta o problema que puedas tener al usar la API.
¿Qué métodos de entrega están disponibles?
S3, Google Cloud Storage, Google PubSub, Microsoft Azure Storage, Snowflake y SFTP.
¿Qué formatos de archivo están disponibles?
Archivos JSON, NDJSON, JSON lines, CSV y .gz (comprimidos).