

Los proxies son direcciones IP de un servidor proxy que se conectan a Internet en su nombre. En lugar de transmitir directamente sus peticiones al sitio web que visita, cuando se conecta a Internet a través de un proxy, sus peticiones se enrutan a través del servidor proxy. Utilizar un servidor proxy es una excelente manera de salvaguardar su privacidad en línea y mejorar la seguridad:
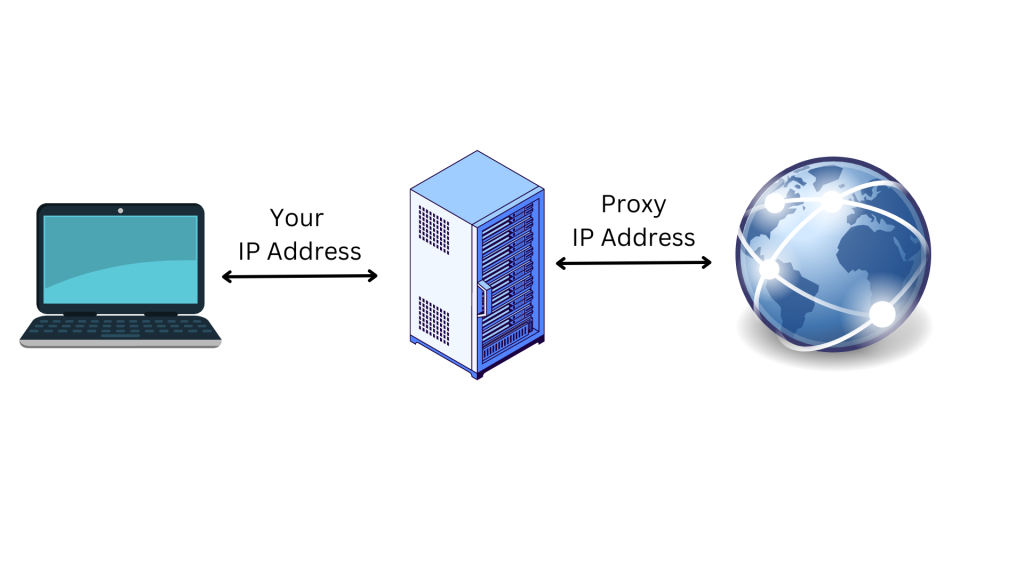
El servidor proxy actúa como un ordenador intermediario, lo que significa que su dirección IP original y su ubicación quedan ocultas para el sitio web. Esto ayuda a protegerle del rastreo en línea, de la publicidad dirigida y de ser bloqueado por el sitio web al que intenta acceder. Los proxies también ofrecen una capa adicional de seguridad al encriptar sus datos mientras viajan entre su dispositivo y el servidor proxy.
En este artículo, discutiremos más sobre proxies y cómo se pueden utilizar con las peticiones de Python. También abordaremos las razones por las que esto puede ser útil cuando se trabaja en un proyecto de raspado web.
Por qué necesita proxies cuando hace raspado web
El raspado web es un proceso automatizado para extraer datos de sitios web con diferentes propósitos, incluyendo agregación de datos, investigación de mercado y análisis de datos. Sin embargo, muchos de estos sitios web tienen restricciones que dificultan el acceso a la información deseada.
Afortunadamente, los proxies pueden ayudarle a eludir las restricciones de IP y de ubicación. Por ejemplo, en algunos casos, los sitios web ofrecen información diferente para lugares específicos, como un país o un estado. Si no se encuentra en ese lugar concreto, no podrá acceder a la información que busca sin un proxy, que puede eludir la IP y cambiar su ubicación.
Además, la mayoría de los sitios web bloquean las direcciones IP de los dispositivos que participan en actividades de raspado web. En esta situación, se puede implementar un proxy para ocultar su dirección IP y ubicación, haciendo más difícil para el sitio web identificarte y bloquearle.
También se puede utilizar varios proxies al mismo tiempo para distribuir las actividades de raspado web entre diferentes direcciones IP y acelerar el proceso de raspado web, permitiendo al raspador realizar múltiples peticiones simultáneamente.
Ahora que sabe cómo los proxies pueden ayudar cuando se trata de proyectos de raspado web, aprenderá a continuación cómo implementar un proxy en su proyecto utilizando el paquete Requests de Python.
Cómo usar un proxy con las peticiones de Python
Para utilizar un proxy con una petición Python, necesita establecer un nuevo proyecto Python en su ordenador para escribir y ejecutar los scripts Python para el raspado web. Cree un directorio (es decir, web_scrape_project) donde almacenará sus archivos de código fuente.
Todos los códigos de este tutorial están disponibles en este repositorio de GitHub.
Instalar paquetes
Después de haber creado su directorio, necesita instalar los siguientes paquetes de Python para enviar las peticiones a la página web y recopilar los enlaces.
- Beautiful Soup
Componentes de la dirección IP proxy
Antes de utilizar un proxy, lo mejor es entender sus componentes. A continuación, los tres componentes principales de un servidor proxy:
- Protocol muestra el tipo de contenido al que se puede acceder en Internet. Los protocolos más comunes son HTTP y HTTPS.
- Address indica dónde se encuentra el servidor proxy. La dirección puede ser una IP (por ejemplo,
192.167.0.1) o un nombre de host DNS (por ejemplo,proxyprovider.com). - Port sirve para dirigir el tráfico al proceso del servidor correcto cuando se ejecutan varios servicios en una misma máquina (por ejemplo, el puerto número
2000).
Utilizando estos tres componentes, una dirección IP proxy tendría el siguiente aspecto: 192.167.0.1:2000 o proxyprovider.com:2000.
Cómo establecer proxies directamente en las peticiones
Hay varias formas de establecer proxies en las peticiones de Python, y este artículo abordará tres escenarios diferentes. En este primer ejemplo, mostraremos cómo establecer proxies directamente en el módulo de peticiones.
Para empezar, es necesario importar los paquetes Requests y Beautiful Soup en su archivo Python para raspado web. A continuación, cree un directorio llamado proxies que contenga información del servidor proxy para ocultar su dirección IP al raspar la página web. Aquí, es necesario definir las conexiones HTTP y HTTPS a la URL del proxy.
También es necesario definir la variable Python para establecer la dirección URL de la página web donde desea raspar datos. Para este tutorial, la URL es https://brightdata.com/
A continuación, es necesario enviar una peticiones GET a la página web utilizando el método request.get(). El método toma dos argumentos: la URL de la página web y los proxies. A continuación, la respuesta de la página web se almacena en la variable response.
Para recopilar los enlaces, se utiliza el paquete Beautiful Soup para analizar el contenido HTML de la página web pasando response.content y html.parser como argumentos al método BeautifulSoup().
A continuación, se utiliza el método find_all() con a como argumento para encontrar todos los enlaces de la página web. Por último, se extrae el atributo href de cada enlace utilizando el método get().
A continuación, se muestra el código fuente completo para establecer proxies directamente en las peticiones:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define proxies to use.
proxies = {
'http': 'http://proxyprovider.com:2000',
'https': 'http://proxyprovider.com:2000',
}
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
Cuando se ejecuta este bloque de código, se envía una peticiones a la página web definida usando la dirección IP del proxy y luego devuelve la respuesta que contiene todos los enlaces a esa página web:

Cómo configurar proxies mediante variables de entorno
A veces, es necesario utilizar el mismo proxy para todas las peticiones a diferentes páginas web. En este caso, tiene sentido establecer variables de entorno para su proxy.
Para que las variables de entorno para el proxy estén disponibles siempre que ejecute scripts en el shell, ejecute el siguiente comando en su terminal:
export HTTP_PROXY='http://proxyprovider.com:2000'
export HTTPS_PROXY='https://proxyprovider.com:2000'
Aquí, la variable HTTP_PROXY establece el servidor proxy para las peticiones HTTP, y la variable HTTPS_PROXY establece el servidor proxy para las peticiones HTTPS.
En este punto, su código Python tiene unas pocas líneas de código y utiliza las variables de entorno cada vez que realiza las peticiones a la página web:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
Cómo Rotar Proxies Usando un Método Personalizado y un Array de Proxies
La rotación de proxies es crucial porque los sitios web suelen bloquear o restringir el acceso a bots y raspadores cuando reciben un gran número de peticiones desde la misma dirección IP. Cuando esto ocurre, los sitios web pueden sospechar de una actividad maliciosa de raspado y, en consecuencia, aplicar medidas para bloquear o limitar el acceso.
Al rotar por diferentes direcciones IP de proxy, se puede evitar ser detectado, aparecer como varios usuarios orgánicos y eludir la mayoría de las medidas contra el raspado implementadas en el sitio web.
Para rotar proxies, se necesita importar algunas librerías Python: Peticiones, Beautiful Soup y Random.
A continuación, se crea una lista de proxies para utilizar durante el proceso de rotación. Esta lista debe contener las URLs de los servidores proxy en este formato: http://proxyserver.com:port:
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
Luego se crea un método personalizado llamado get_proxy(). Este método selecciona aleatoriamente un proxy de la lista de proxies utilizando el método random.choice() y devuelve el proxy seleccionado en formato diccionario (tanto claves HTTP como HTTPS). Utilizará este método siempre que se envíe nuevas peticiones:
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
Una vez que haya creado el método get_proxy(), necesita crear un bucle que envíe un cierto número de peticiones GET utilizando los proxies rotados. En cada petición, el método get() utiliza un proxy elegido al azar especificado por el método get_proxy().
A continuación, hay que recopilar los enlaces del contenido HTML de la página web utilizando el paquete Beautiful Soup, como se explica en el primer ejemplo.
Por último, el código Python captura cualquier excepción que se produzca durante el proceso de las peticiones e imprime el mensaje de error en la consola.
Aquí está el código fuente completo de este ejemplo:
# import packages
import requests
from bs4 import BeautifulSoup
import random
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
# Send requests using rotated proxies
for i in range(10):
# Set the URL to scrape
url = 'https://brightdata.com/'
try:
# Send a GET request with a randomly chosen proxy
response = requests.get(url, proxies=get_proxy())
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
except requests.exceptions.RequestException as e:
# Handle any exceptions that may occur during the request
print(e)
Uso del servicio proxy de Bright Data con Python
Si está buscando un proxy fiable, rápido y estable para sus tareas de raspado web, no busque más allá de Bright Data, una plataforma de datos web que ofrece diferentes tipos de proxies para una amplia gama de casos de uso.
Bright Data cuenta con una amplia red de más de 400M+ monthly de IP residenciales y más de 770,000 proxies de centros de datos que proporcionan soluciones de proxy fiables y rápidas. Sus ofertas de proxy están diseñadas para ayudarle a superar los retos del raspado web, la verificación de anuncios y otras actividades en línea que requieren una recopilación de datos web anónima y eficaz.
Integrar los proxies de Bright Data en sus peticiones Python es fácil. Por ejemplo, utilice los Proxies del centro de datos para enviar las peticiones a la URL utilizada en los ejemplos anteriores.
Si aún no tiene una cuenta, suscríbase a una prueba gratuita de Bright Data y, a continuación, añada sus datos para registrar su cuenta en la plataforma.
Una vez hecho esto, siga estos pasos para crear su primer proxy:
Haga clic en Ver producto proxy en la página de bienvenida para ver los diferentes tipos de proxy que ofrece Bright Data:
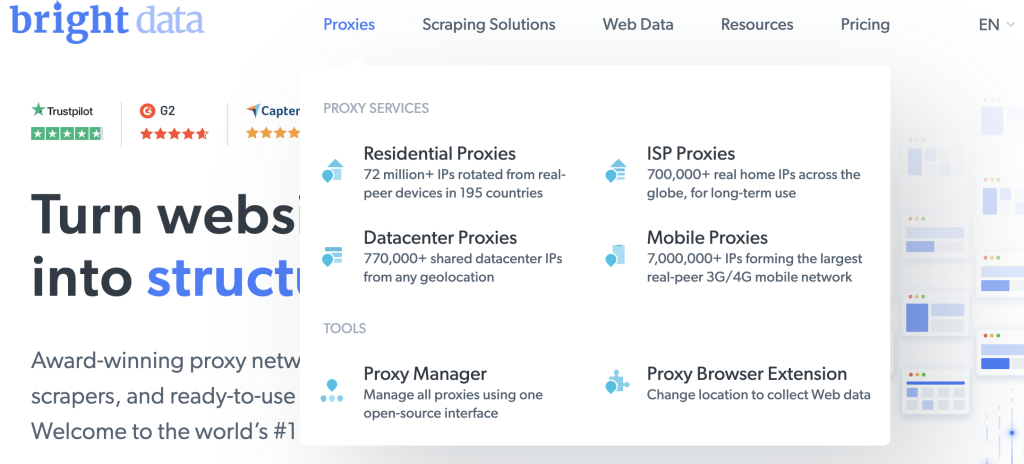
Seleccione Proxies de centro de datos para crear un nuevo proxy y, en la página siguiente, añada sus datos y guárdelo:

Una vez creado su proxy, se puede ver los parámetros importantes (es decir, host, puerto, nombre de usuario y contraseña) para empezar a acceder a él y utilizarlo:
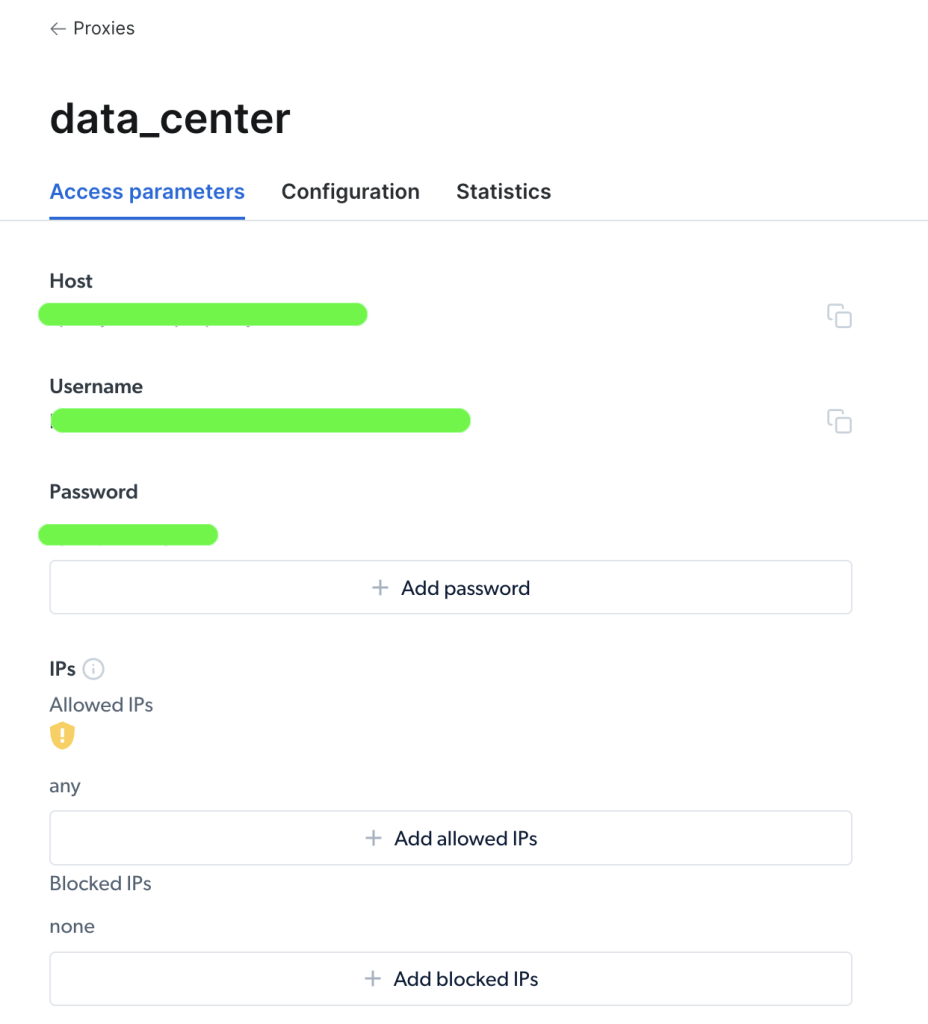
Una vez que haya accedido a su proxy, se puede utilizar la información de los parámetros para configurar la URL de su proxy y enviar las peticiones utilizando el paquete Requests Python. El formato de la URL del proxy es username-(session-id)-password@host:port.
Nota:
session-ides un número aleatorio creado utilizando un paquete de Python llamadorandom.
A continuación se muestra un ejemplo de código para definir el proxy desde Bright Data en una petición Python:
import requests
from bs4 import BeautifulSoup
import random
# Define parameters provided by Brightdata
host = 'zproxy.lum-superproxy.io'
port = 22225
username = 'username'
password = 'password'
session_id = random.random()
# format your proxy
proxy_url = ('http://{}-session-{}:{}@{}:{}'.format(username, session_id,
password, host, port))
# define your proxies in dictionary
proxies = {'http': proxy_url, 'https': proxy_url}
# Send a GET request to the website
url = "https://brightdata.com/"
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website
links = soup.find_all("a")
# Print all the links
for link in links:
print(link.get("href"))
Aquí, se importa los paquetes y se define las variables proxy host, port, username, password, y session_id. A continuación, se crea un diccionario de proxies con las claves http y https y las credenciales del proxy. Finalmente, pasa el parámetro proxies a la función requests.get() para hacer las peticiones HTTP y recopilar los enlaces de la URL.
Y ya está. Acaba de realizar con éxito peticiones utilizando el servicio proxy de Bright Data.
Conclusión
En este artículo, aprendió por qué necesita proxies así como las diferentes formas en que se puede utilizar para enviar las peticiones a una página web utilizando el paquete Requests Python.
Con la plataforma web de Bright Data, se puede obtener proxies fiables para su proyecto que cubran cualquier país o ciudad del mundo. Ofrecen múltiples formas de obtener los datos que necesita a través de varios tipos de proxies y herramientas para el raspado web que se adaptan a sus necesidades específicas.
Tanto si busca recopilar datos de estudios de mercado, supervisar las reseñas en línea o realizar un seguimiento de los precios de la competencia, Bright Data tiene los recursos que necesita para realizar el trabajo de forma rápida y eficaz.






