

La rotación de IP mediante proxies es esencial en el raspado web, sobre todo cuando se trata de sitios web modernos que pueden imponer restricciones. Distribuir tus peticiones entre varias direcciones IP es crucial para evitar que te bloqueen o te apliquen límites de velocidad. La rotación de direcciones IP dificulta a los sitios web el rastreo y la restricción de tu actividad de raspado. Esto mejora la eficiencia y la fiabilidad de tu proceso de raspado web, lo que te permite extraer datos de manera más efectiva. El uso de proxies y direcciones IP rotativas durante la extracción web te permite evitar prohibiciones y penalizaciones basadas en IP, superar los límites de velocidad y acceder a contenido con restricciones geográficas.
Este artículo explica cómo implementar proxies en tu flujo de trabajo de raspado web para rotar las direcciones IP utilizadas. Descubrirás dónde conseguir proxies eficaces, cuáles son los consejos para la rotación de IP y cómo evitar que tu sitio web objetivo te bloquee.
Rotación de IP con Python
Un proceso de raspado habitual con Python suele utilizar una biblioteca de Python como Requests o Scrapy para acceder a un sitio web y analizar su contenido. A continuación, puedes filtrar el contenido del sitio web para obtener la información que quieres extraer. He aquí un ejemplo de un proceso de raspado típico:
import requests
url = 'http://example.com'
# Make requests
response = requests.get(url)
print(response.text)
Este proceso te brinda la información que necesitas y es adecuado para casos de un solo uso o casos en los que solo necesitas extraer los datos una vez. Sin embargo, usa la IP de tu sistema para realizar solicitudes y puede tener problemas con solicitudes repetidas o continuas en las que el sitio web limita el acceso con el tiempo.
Estos son los resultados del proceso de raspado de ejemplo:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans",
…
La mayoría de las bibliotecas de Python, como Requests o Scrapy, destinadas a extraer o realizar solicitudes web cuentan con una vía para cambiar la dirección IP utilizada para realizar estas solicitudes. Sin embargo, para aprovecharla, necesitas una lista o una fuente de direcciones IP válidas. Estas fuentes pueden ser gratuitas o comerciales, como los proxies de Bright Data.
Las opciones comerciales garantizan la validez y proporcionan herramientas prácticas para gestionar y rotar tus proxies y garantizar que no haya tiempos de inactividad en el proceso de raspado. Por ejemplo, Bright Data tiene varias categorías de proxies con precios diferentes según el caso de uso para el que están diseñados, su escalabilidad y la garantía de acceso desbloqueado a los datos solicitados:
Con proxies gratuitos, puedes crear una lista en Python que contenga proxies válidos que puedes rotar a lo largo del proceso de raspado:
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
Con esto, lo único que necesitas es un mecanismo rotatorio que seleccione diferentes direcciones IP de la lista a medida que realizas múltiples peticiones. En Python, tendría un aspecto similar a la siguiente función:
import random
import requests
def scraping_request(url):
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
print(f"Proxy currently being used: {ips['https']}")
return response.text
Este código selecciona un proxy aleatorio de tu lista cada vez que se ejecuta. El proxy se usa para las solicitudes de raspado.
Incluir un caso de error para manejar proxies inválidos daría lugar a que el código de raspado completo tuviera este aspecto:
import random
import requests
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
def scraping_request(url):
ip = random.choice(proxies)
try:
response = requests.get(url, proxies={"http": ip, "https": ip})
if response.status_code == 200:
print(f"Proxy currently being used: {ip}")
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
try:
if response.status_code == 200:
print(f"Proxy currently being used: {ips['https']}")
print(response.text)
elif response.status_code == 403:
print("Forbidden client")
elif response.status_code == 429:
print("Too many requests")
except Exception as e:
print(f"An unexpected error occurred: {e}")
scraping_request("http://example.com")
También puedes usar esta lista rotativa de proxies para realizar tus solicitudes con cualquier otro marco de raspado, como Scrapy.
Cómo raspar con Scrapy
Con Scrapy, necesitas instalar la biblioteca y crear los artefactos de proyecto necesarios antes de poder rastrear correctamente la web.
Puedes instalar Scrapy mediante el gestor de paquetes pip en tu entorno compatible con Python:
pip install Scrapy
Una vez instalado, puedes generar un proyecto de Scrapy con archivos de plantilla en tu directorio actual mediante los siguientes comandos:
scrapy startproject sampleproject
cd sampleproject
scrapy genspider samplebot example.com
Estos comandos también generan un archivo de código básico que puedes completar con un mecanismo de rotación de IP.
Abre el archivo sampleproject/spiders/samplebot.pysamplebot.py y actualízalo con el siguiente código:
import scrapy
import random
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
ip = random.randrange(0, len(proxies))
class SampleSpider(scrapy.Spider):
name = "samplebot"
allowed_domains = ["example.com"]
start_urls = ["https://example.com"]
def start_requests(self):
for url in self.start_urls:
proxy = random.choice(proxies)
yield scrapy.Request(url, meta={"proxy": f"http://{proxy}"})
request = scrapy.Request(
"http://www.example.com/index.html",
meta={"proxy": f"http://{ip}"}
)
def parse(self, response):
# Log the proxy being used in the request
proxy_used = response.meta.get("proxy")
self.logger.info(f"Proxy used: {proxy_used}")
print(response.text)
Ejecuta el siguiente comando en la parte superior del directorio del proyecto para ejecutar este script de raspado:
scrapy crawl samplebot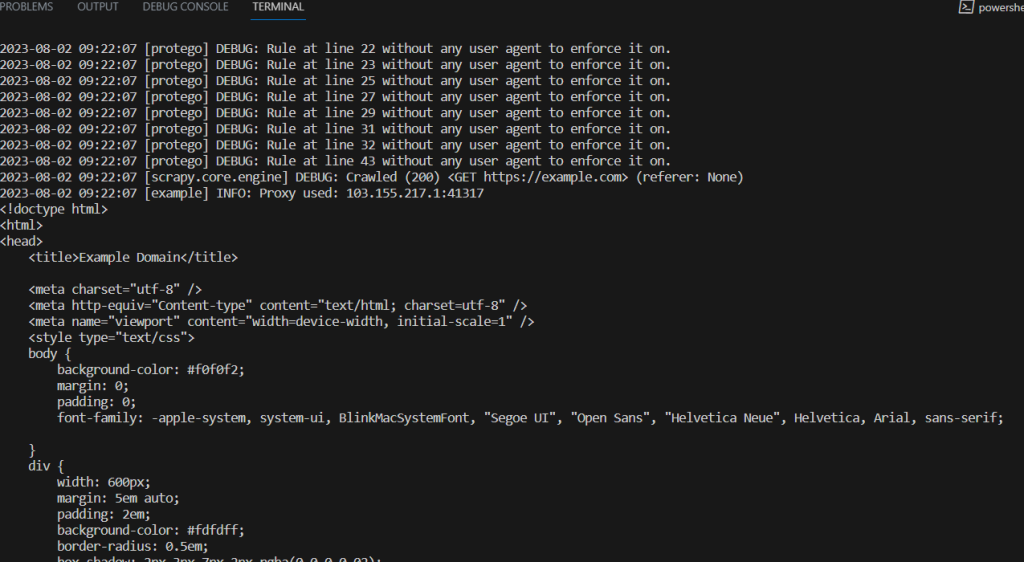
Consejos para la rotación de IP
El raspado web se ha convertido en una forma de competencia entre los sitios web y los raspadores, que inventan nuevos métodos y técnicas para obtener los datos necesarios, mientras que los sitios web encuentran nuevas formas de bloquear el acceso.
La rotación de IP es una técnica cuyo objetivo es eludir las limitaciones establecidas por los sitios web. Para maximizar la eficacia de la rotación de IP y minimizar las posibilidades de que tu sitio web objetivo te bloquee, ten en cuenta los siguientes consejos:
- Asegúrate un grupo de proxies grande y diverso: al utilizar la rotación de IP, necesitas un grupo de proxies importante con una gran cantidad de proxies y una amplia variedad de direcciones IP. Esta diversidad ayuda a lograr una rotación adecuada y reduce el riesgo de usar en exceso los proxies, lo que podría dar lugar a límites de velocidad y prohibiciones. Considera la posibilidad de usar varios proveedores de proxy con diferentes rangos de IP y ubicaciones. Además, puedes variar el tiempo y los intervalos entre tus solicitudes con tus diferentes proxies para simular mejor el comportamiento natural de los usuarios.
- Dispón de mecanismos sólidos de gestión de errores: durante el proceso de raspado web, es posible que se produzcan varios errores debido a problemas de conectividad temporales, proxies bloqueados o cambios en el sitio web de destino. Al implementar la gestión de errores en tus scripts, puedes asegurar la ejecución sin problemas de tu proceso de scraping, capturando y gestionando excepciones comunes como errores de conexión, tiempos de espera y errores de estado HTTP. Puedes configurar interruptores automáticos para detener temporalmente el proceso de raspado si se produce un gran número de errores en un breve periodo de tiempo.
- Prueba tus proxies antes de usarlos: antes de implementar tu script de raspado en producción, utiliza una muestra de tu grupo de proxies para probar la funcionalidad de rotación de IP y los mecanismos de gestión de errores en diferentes situaciones. Puedes usar sitios web de muestra para simular condiciones del mundo real y asegurarte de que tu script pueda gestionar estos casos.
- Supervisa el rendimiento y la eficiencia del proxy: supervisa con frecuencia el rendimiento de tus proxies para detectar cualquier problema, como tiempos de respuesta lentos o fallos frecuentes. Debes realizar un seguimiento de la tasa de éxito de cada proxy para identificar los ineficientes. Los proveedores de proxy, como Bright Data , ofrecen herramientas para comprobar el estado y el rendimiento de tus proxies. Al supervisar el rendimiento de los proxies, puedes cambiar rápidamente a otros más fiables y eliminar los que tienen un rendimiento inferior de tu grupo de rotación.
El raspado web es un proceso iterativo y los sitios web pueden cambiar su estructura y patrones de respuesta o implementar nuevas medidas para evitar el raspado. Supervisa con frecuencia tu proceso de raspado y adáptate a cualquier cambio para mantener la eficacia de tu trabajo de raspado.
Conclusión
Este artículo ha analizado la rotación de IP y cómo implementarla en el proceso de raspado con Python. También has recibido consejos prácticos para mantener la eficacia de tu proceso de raspado con Python.
Bright Data es tu plataforma integral para soluciones de raspado web. Proporciona proxies éticos y de alta calidad, un navegador de raspado web, un IDE para el desarrollo y los procesos de los bots de raspado, conjuntos de datos listos para usar y varias herramientas para rotar y gestionar los proxies durante el raspado.





