

En esta guía aprenderás:
- Qué es la biblioteca de
uso del navegadorpara el desarrollo de agentes de IA - Por qué sus capacidades están limitadas por el navegador que controla
- Cómo superar esas limitaciones utilizando un navegador de raspado
- Cómo construir un agente de IA que opere en el navegador y evite bloqueos gracias a la integración con Scraping Browser
Sumerjámonos.
¿Qué es el uso del navegador?
Browser Use es un proyecto Python de código abierto que hace accesibles las páginas web a los agentes de IA. Identifica todos los elementos interactivos de una página web, lo que permite a los agentes realizar interacciones significativas con ellos. En resumen, la biblioteca Browser Use permite a la IA controlar e interactuar con su navegador mediante programación.
En detalle, las principales características que ofrece son:
- Potente automatización del navegador: Combina la IA avanzada con una sólida automatización del navegador para simplificar las interacciones web de los agentes de IA.
- Visión + extracción HTML: Integra la comprensión visual y la extracción de estructuras HTML para que la navegación y la toma de decisiones sean más eficaces.
- Gestión multipestaña: Puede gestionar varias pestañas del navegador, lo que abre la puerta a flujos de trabajo complejos y tareas paralelas.
- Seguimiento de elementos: Rastrea los elementos sobre los que se hace clic mediante XPath y puede repetir las acciones exactas realizadas por un LLM, garantizando la coherencia.
- Acciones personalizadas: Admite la definición de acciones personalizadas como guardar en archivos, escribir en bases de datos, enviar notificaciones o gestionar entradas humanas.
- Mecanismo de autocorrección: Viene con un sistema incorporado de gestión de errores y recuperación automática para una tubería de automatización más fiable.
- Compatibilidad con cualquier LLM: es compatible con los principales LLM a través de LangChain, incluidos GPT-4, Claude 3 y Llama 2.
Limitaciones del uso de navegadores en el desarrollo de agentes de IA
Browser Use es una tecnología innovadora que ha causado un impacto sin precedentes en la comunidad informática. No es de extrañar que el proyecto haya alcanzado más de 60.000 estrellas de GitHub en tan solo unos meses:

Por si fuera poco, el equipo que lo respalda consiguió más de 17 millones de dólares en financiación inicial, lo que dice mucho del potencial y la promesa de este proyecto.
Sin embargo, es importante reconocer que las capacidades de control del navegador ofrecidas por Browser Use no se basan en la magia. En su lugar, la biblioteca combina la entrada visual con el control de IA para automatizar los navegadores a través de Playwright, unmarco de automatización de navegadores rico en funciones que viene con ciertas limitaciones.
Como señalamos en nuestros artículos anteriores sobre el web scraping de Playwright, las limitaciones no provienen del propio marco de automatización. Al contrario, provienen de los navegadores que controla. En concreto, herramientas como Playwright lanzan navegadores con configuraciones e instrumentación especiales que permiten la automatización. El problema es que esas configuraciones también pueden exponerlos a los sistemas de detección anti-bot.
Esto se convierte en un problema importante, especialmente cuando se construyen agentes de IA que necesitan interactuar con sitios bien protegidos. Por ejemplo, supongamos que quieres utilizar Browser Use para construir un agente de IA que añada artículos específicos a un carrito de la compra en Amazon por ti. Este es el resultado que probablemente obtendrás:

Como puedes ver, el sistema anti-bot de Amazon puede detectar y detener tu automatización de IA. En concreto, la plataforma de comercio electrónico puede mostrar el desafiante CAPTCHA de Amazon o responder con la página de error “Lo sentimos, algo ha ido mal por nuestra parte”:

En estos casos, se acabó el juego para tu agente de IA. Así pues, aunque el uso del navegador es una herramienta asombrosa y potente, para aprovechar todo su potencial es necesario realizar ajustes bien pensados. El objetivo final es evitar la activación de sistemas anti-bot para que su automatización de IA pueda funcionar como desee.
Por qué un navegador de raspado es la solución
Ahora, podrías estar pensando: “¿Por qué no simplemente ajustar el navegador que controla el uso del navegador a través de Playwright, utilizando banderas especiales para reducir las posibilidades de detección?”. Efectivamente, eso es posible, y es parte de la estrategia utilizada por librerías como Playwright Stealth.
Sin embargo, eludir la detección anti-bot es mucho más complejo que mover unas cuantas banderas…
Implica factores como la reputación IP, la limitación de velocidad, la huella digital del navegador y otros aspectos avanzados. No se puede ser más astuto que los sofisticados sistemas anti-bot con un par de trucos manuales. Lo que realmente necesitas es una solución construida desde cero para ser indetectable a las defensas anti-bot y anti-scraping. Y ahí es donde entra en juego un navegador de scraping.
Las soluciones de los navegadores de scraping ofrecen funciones antidetección increíblemente eficaces. Entonces, ¿cuál es el mejor navegador antidetección del mercado? El Scraping Browser de Bright Data.
En concreto, Scraping Browser es un navegador web de nueva generación basado en la nube que ofrece:
- Huellas digitales TLS fiables para confundirse con los usuarios reales
- Escalabilidad ilimitada para el raspado de grandes volúmenes
- Rotación automática de IP, respaldada por una red de proxy IP de más de 150M
- Lógica de reintento integrada para gestionar correctamente las solicitudes fallidas.
- Capacidad para resolver CAPTCHA, listo para usar
- Un completo kit de herramientas anti-bot bypass
Scraping Browser se integra con las principales librerías de automatización de navegadores, incluyendo Playwright, Puppeteer y Selenium. Por lo tanto, es totalmente compatible con el uso del navegador, ya que esta biblioteca se basa en Playwright.
Integrando Scraping Browser en Browser Use, puedes evitar los bloqueos de Amazon que encontraste antes-o evitar bloqueos similares en cualquier otro sitio.
Cómo integrar el uso de un navegador de raspado
En esta sección del tutorial, aprenderá a integrar el uso del navegador con el Scraping Browser de Bright Data. Construiremos un agente de IA potenciado por OpenAI que pueda añadir artículos al carrito de Amazon.
Este es sólo un ejemplo para demostrar el poder de la automatización del navegador basada en IA. Tenga en cuenta que el agente de IA puede interactuar con otros sitios, según sus necesidades y objetivos. Lo que importa es que te permite ahorrar tiempo y esfuerzo significativos al realizar operaciones tediosas por ti.
En detalle, el agente de IA de Amazon que estamos a punto de construir será capaz de:
- Conéctese a Amazon utilizando una instancia remota de Scraping Browser para evitar la detección y los bloqueos.
- Leer una lista de elementos de la indicación.
- Busque, seleccione los productos correctos y añádalos a su cesta automáticamente.
- Visite el carrito y proporcione un resumen de todo el pedido.
¡Siga los siguientes pasos para ver cómo utilizar Browser Use con Scraping Browser!
Requisitos previos
Para seguir este tutorial, asegúrate de tener lo siguiente:
- Una cuenta de Bright Data.
- Una clave API de un proveedor de IA compatible, como OpenAI, Anthropic, Gemini, DeepSeek, Grok o Novita.
- Conocimientos básicos de programación asíncrona en Python y automatización de navegadores.
Si aún no tiene una cuenta de proveedor de Bright Data o AI, no se preocupe. Le explicaremos cómo crearlas en los pasos siguientes.
Paso nº 1: Configuración del proyecto
Antes de empezar, asegúrate de que tienes Python 3 instalado en tu sistema. Si no es así, descárgalo del sitio oficial y sigue las instrucciones de instalación.
Abre tu terminal y crea una nueva carpeta para tu proyecto de agente AI:
mkdir browser-use-amazon-agentLa carpeta browser-use-amazon-agent contendrá todo el código para tu agente de IA basado en Python.
Navega hasta la carpeta del proyecto y crea un entorno virtual dentro de ella:
cd browser-use-amazon-agent
python -m venv venvAhora abre la carpeta del proyecto en tu IDE de Python favorito. Visual Studio Code con la extensión Python o PyCharm Community Edition son opciones válidas.
En la carpeta browser-use-amazon-agent, crea un nuevo archivo Python llamado agent.py. La estructura de tu proyecto debería ser la siguiente:
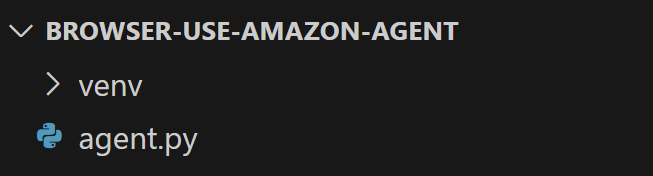
En este punto, agent.py es sólo un script vacío, pero pronto contendrá toda tu lógica de automatización del navegador de IA.
En el terminal de su IDE, active el entorno virtual. En Linux/macOS, ejecute:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venv/Scripts/activate¡Ya está todo listo! Tu entorno Python ya está listo para construir un agente de IA con Browser Use y Scraping Browser.
Paso 2: Configurar las variables de entorno Lectura
Su proyecto se integrará con servicios de terceros como Bright Data y el proveedor de IA que haya elegido. En lugar de codificar las claves API y los secretos de conexión directamente en el código Python, lo mejor es cargarlos desde variables de entorno.
Para simplificar esa tarea, utilizaremos la biblioteca python-dotenv. En el entorno virtual activado, instálala con:
pip install python-dotenvEn tu archivo agent.py, importa la librería y carga las variables de entorno con load_dotenv():
from dotenv import load_dotenv
load_dotenv()Ahora podrás leer variables desde un archivo local .env. Añádelo a tu proyecto:

Ahora puedes acceder a estas variables de entorno en tu código con esta línea de código:
env_value = os.getenv("<ENV_NAME>")No olvides importar os de la biblioteca estándar de Python:
import os¡Genial! Ya estás listo para leer de forma segura los secretos de integración con servicios de terceros desde los envs.
Paso 3: Empezar a utilizar el navegador
Con su entorno virtual activado, instale el uso del navegador:
pip install browser-useDado que la biblioteca depende de varias dependencias, esto puede tardar unos minutos. Así que ten paciencia.
Dado que browser-use utiliza Playwright bajo el capó, es posible que también necesite instalar las dependencias de navegador de Playwright. Para ello, ejecute el siguiente comando:
python -m playwright installEsto descarga los binarios necesarios del navegador y configura todo lo que Playwright necesita para funcionar correctamente.
Ahora, importa las clases requeridas desde browser-use:
from browser_use import Agent, Browser, BrowserConfigEn breve utilizaremos estas clases para construir la lógica de automatización del navegador del agente de IA.
Dado que browser-use proporciona una API asíncrona, necesitas inicializar tu agent.py con un punto de entrada asíncrono:
# other imports..
import asyncio
async def main():
# AI agent logic...
if __name__ == "__main__":
asyncio.run(main())El fragmento anterior utiliza la biblioteca asyncio de Python para ejecutar tareas asíncronas, lo que es necesario para trabajar con navegador.
Bien hecho. El siguiente paso es configurar el Scraping Browser e integrarlo en tu script.
Paso 4: Empezar con el navegador de scraping
Para obtener instrucciones generales de integración, consulte la documentación oficial de Scraping Browser. De lo contrario, siga los pasos que se indican a continuación.
Para empezar, si aún no lo ha hecho, cree una cuenta de Bright Data. Inicie sesión, vaya al panel de usuario y haga clic en el botón “Obtener productos proxy”:
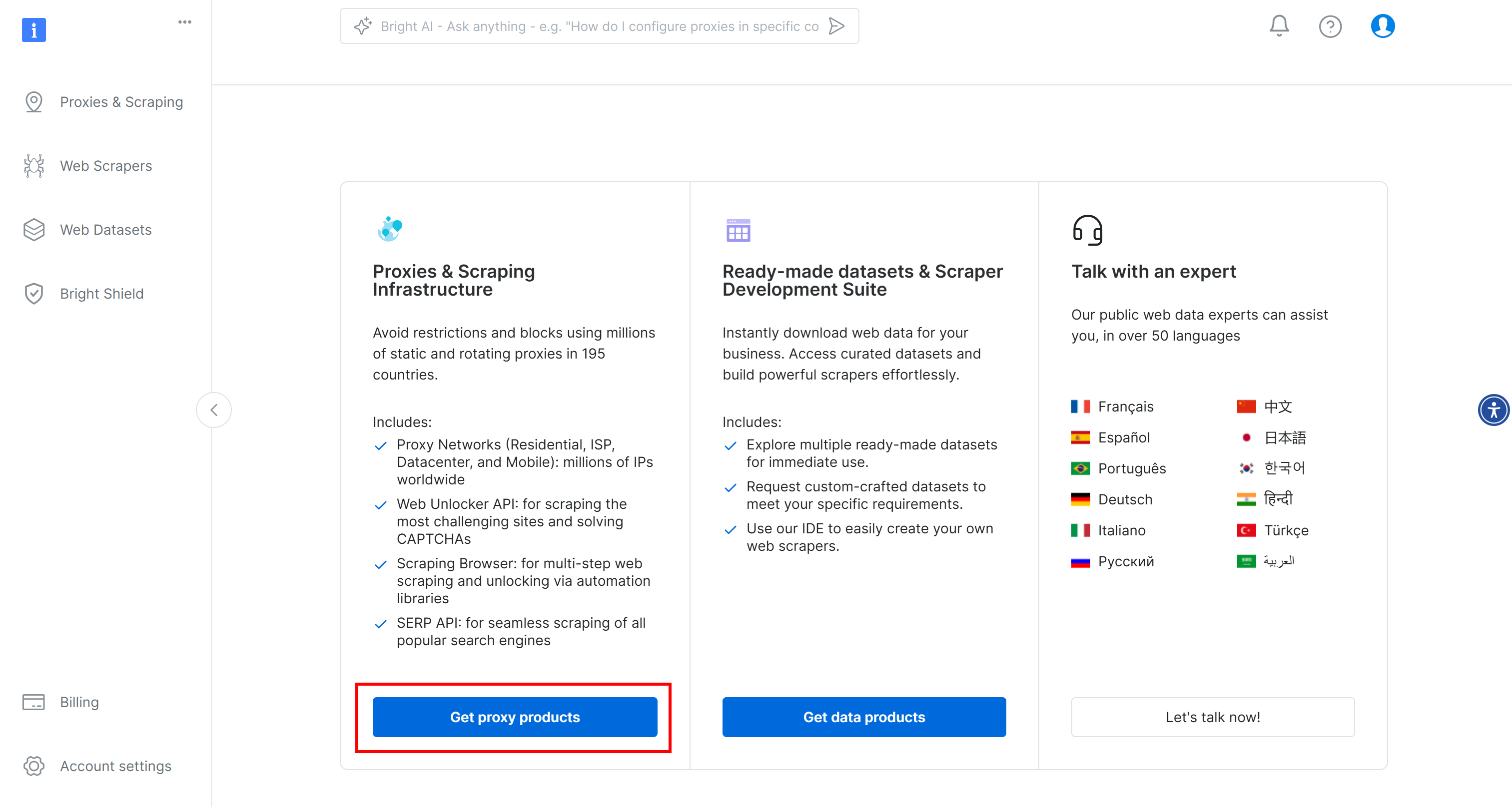
En la página “Proxies & Scraping Infrastructure”, busque la tabla “My Zones” y seleccione la fila que hace referencia al tipo de “Scraping Browser”:

Si no ve dicha fila, significa que aún no ha configurado la zona de Scraping Browser. En ese caso, desplácese hacia abajo hasta encontrar la ficha “Browser API” y pulse el botón “Empezar”:

A continuación, siga la configuración guiada para configurar el Scraping Browser por primera vez.
Una vez en la página del producto, actívelo pulsando el interruptor de encendido/apagado:

Ahora, ve a la pestaña “Configuración” y asegúrate de que tanto “Dominios Premium” como “CAPTCHA Solver” están activados para conseguir la máxima eficacia:

Cambie a la pestaña “Visión general” y copie la cadena de conexión de Playwright Scraping Browser:

Añada esta cadena de conexión a su archivo .env:
SBR_CDP_URL="<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"Sustituya por el valor que acaba de copiar.
Ahora, en tu archivo agent.py, carga la variable de entorno con:
SBR_CDP_URL = os.getenv("SBR_CDP_URL")¡Increíble! Ahora puedes usar Scraping Browser dentro del navegador. Antes de sumergirnos en eso, vamos a completar las integraciones de terceros añadiendo OpenAI a tu script.
Paso 5: Empezar con OpenAI
Descargo de responsabilidad: El siguiente paso se centra en la integración de OpenAI, pero puede adaptar fácilmente las instrucciones a continuación para cualquier otro proveedor de IA soportado por Browser Use.
Para habilitar las capacidades de IA en el navegador, necesitas una clave API válida de un proveedor de IA externo. En este caso, utilizaremos OpenAI. Si aún no has generado una clave API, sigue la guía oficial de OpenAI para crear una.
Una vez que tenga su clave, añádala a su archivo .env:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"Asegúrese de sustituir por su clave API real.
A continuación, importa la clase ChatOpenAI de langchain_openai en agent.py:
from langchain_openai import ChatOpenAITenga en cuenta que Browser Use se basa en LangChain para manejar las integraciones de IA. Por lo tanto, aunque no haya instalado explícitamente langchain_openai en su proyecto, ya está disponible para su uso. Para más orientación, lea nuestro tutorial sobre cómo integrar Bright Data en flujos de trabajo LangChain.
Configurar la integración OpenAI utilizando el modelo gpt-4o con:
llm = ChatOpenAI(model="gpt-4o")No es necesaria ninguna configuración adicional. Esto se debe a que langchain_openai leerá automáticamente la clave API de la variable de entorno OPENAI_API_KEY.
Para la integración con otros modelos o proveedores de IA, consulte la documentación oficial de uso del navegador.
Paso nº 6: Integrar Scraping Browser en el uso del navegador
Para conectarse a un navegador remoto en uso-navegador, es necesario utilizar el objetoBrowserConfig de la siguiente manera:
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)Esta configuración indica a Playwright que se conecte a la instancia remota de Bright Data Scraping Browser.
Paso 7: Definir la tarea a automatizar
Ahora es el momento de definir la tarea que desea que su agente de IA realice en el navegador utilizando lenguaje natural.
Antes de hacerlo, asegúrate de que el objetivo está claramente definido en tu mente. En este caso, supongamos que quieres que el agente de IA:
- Conéctate a Amazon.com.
- Añade la consola PlayStation 5 y el juego Astro Bot PS5 al carrito.
- Llegar a la página del carrito y generar un resumen del pedido actual.
Si sólo da esas instrucciones básicas al Navegador de uso, puede que las cosas no salgan como esperaba. Esto se debe a que algunos productos tienen varias versiones, algunas páginas pueden pedirle que adquiera un seguro adicional, algunos artículos pueden no estar disponibles, etc.
Por lo tanto, tiene sentido añadir notas adicionales para guiar las decisiones del agente de IA en estas situaciones.
Además, para mejorar el rendimiento, es útil resumir claramente con palabras los pasos más importantes.
Teniendo esto en cuenta, la tarea que debe realizar tu agente de IA en el navegador puede describirse así:
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""Observa cómo esta versión es lo suficientemente detallada como para guiar al agente de IA a través de escenarios comunes y evitar que se atasque.
¡Genial! Vea cómo lanzar esta tarea.
Paso nº 8: Iniciar la tarea de IA
Inicialice un objeto Agente de uso del navegador utilizando la definición de tareas de su agente de IA:
agent = Agent(
task=task,
llm=llm,
browser=browser,
)Ahora puede ejecutar el agente con:
await agent.run()Además, no olvide cerrar el navegador controlado por Playwright cuando finalice la tarea para liberar sus recursos:
await browser.close()¡Perfecto! La integración Browser Use + Bright Data Scraping Browser ya está completamente configurada. Todo lo que queda es poner todo junto y ejecutar el código completo.
Paso 9: Póngalo todo junto
Su archivo agent.py debe contener:
from dotenv import load_dotenv
import os
from browser_use import Agent, Browser, BrowserConfig
from browser_use.browser.context import BrowserContextConfig, BrowserContext
import asyncio
from langchain_openai import ChatOpenAI
# Load the environment variables from the .env file
load_dotenv()
async def main():
# Read the remote URL of Scraping Browser from the envs
SBR_CDP_URL = os.getenv("SBR_CDP_URL")
# Set up the AI engine
llm = ChatOpenAI(model="gpt-4o")
# Configure the browser automation to connect to a remote Scraping Browser instance
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)
# The task you want to automate in the browser
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""
# Initialize a new AI browser agent with the configured browser
agent = Agent(
task=task,
llm=llm,
browser=browser,
)
# Start the AI agent
await agent.run()
# Close the browser when the task is complete
await browser.close()
if __name__ == "__main__":
asyncio.run(main())¡Et voilà! En menos de 100 líneas de código, has construido un potente agente de IA que combina el uso del navegador con el Scraping Browser de Bright Data.
Para ejecutar su agente de IA, ejecute
python agent.pyUna vez iniciado, el navegador de uso registrará todo lo que haga. Dado que Scraping Browser se ejecuta en la nube y no hay interfaz visual, estos registros son esenciales para entender lo que está haciendo el agente.
He aquí un breve extracto de lo que podrían ser los registros:
INFO [agent] 📍 Step 1
INFO [browser] 🔌 Connecting to remote browser via CDP wss://brd-customer-hl_4bcb8ada-zone-scraping_browser:[email protected]:9222
INFO [agent] 🤷 Eval: Unknown - Task has just started, beginning with navigating to Amazon.
INFO [agent] 🧠 Memory: Step 1: Navigate to Amazon's website. Open tab to Amazon's main page.
INFO [agent] 🎯 Next goal: Navigate to Amazon's website by opening the following URL: https://www.amazon.com/.
INFO [agent] 🛠️ Action 1/1: {"go_to_url":{"url":"https://www.amazon.com/"}}
INFO [controller] 🔗 Navigated to https://www.amazon.com/
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Navigated to Amazon homepage. The search bar is available for input.
INFO [agent] 🧠 Memory: On the Amazon homepage, ready to search for items. 0 out of 2 items added to cart.
INFO [agent] 🎯 Next goal: Search for the 'PlayStation 5 (Slim) console' in the search bar.
INFO [agent] 🛠️ Action 1/2: {"input_text":{"index":2,"text":"PlayStation 5 (Slim) console"}}
INFO [agent] 🛠️ Action 2/2: {"click_element_by_index":{"index":4}}
INFO [controller] ⌨️ Input PlayStation 5 (Slim) console into index 2
INFO [agent] Something new appeared after action 1 / 2
# Omitted for brevity...
INFO [agent] 📍 Step 14
INFO [agent] 👍 Eval: Success - Extracted the order summary from the cart page.
INFO [agent] 🧠 Memory: Amazon cart page shows both items: PlayStation 5 Slim and Astro Bot PS5 game added successfully. Extracted item names, quantities, costs, subtotal, and delivery details.
INFO [agent] 🎯 Next goal: Finalize the task by summarizing the order details.
INFO [agent] 🛠️ Action 1/1: {"done":{"text":"Order Summary:nnItems in Cart:n1. Name: Astro Bot PS5n Quantity: 11n Cost: $58.95nn2. Name: PlayStation®5 console (slim)n Quantity: 1n Cost: $499.00nnSubtotal: $557.95nDelivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.nnTotal Cost: $557.95","success":true}}
INFO [agent] 📄 Result: Order Summary:
Items in Cart:
1. Name: Astro Bot PS5
Quantity: 1
Cost: $58.95
2. Name: PlayStation®5 console (slim)
Quantity: 1
Cost: $499.00
Subtotal: $557.95
Delivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.Como puedes ver, el agente de IA encontró con éxito los artículos deseados, los añadió al carrito y generó un resumen limpio. Todo ello sin bloqueos ni prohibiciones de Amazon, ¡gracias al Scraping Browser!
browser-use también incluye funciones para grabar la sesión del navegador con fines de depuración. Aunque esto todavía no funciona con el navegador remoto, si lo hiciera, verías una hipnotizante reproducción del agente de IA en acción:
Realmente hipnótico, y un emocionante vistazo a lo lejos que ha llegado la navegación asistida por IA.
Paso nº 10: Próximos pasos
El agente de IA de Amazon que hemos construido aquí es sólo un punto de partida, una prueba de concepto para mostrar lo que es posible. Para que esté listo para la producción, a continuación se presentan varias ideas de mejora:
- Conéctesea su cuenta de Amazon: Permite que el agente inicie sesión para que pueda acceder a funciones personalizadas como el historial de pedidos y las recomendaciones.
- Implantar un flujo de trabajo de compras: Amplíe el agente para completar realmente las compras. Esto incluye la selección de opciones de envío, la aplicación de códigos promocionales o tarjetas regalo y la confirmación del pago.
- Enviar una confirmación o un informe por correo electrónico: Antes de finalizar cualquier transacción de pago, el agente podría enviar por correo electrónico un resumen detallado del carrito y de las acciones previstas para que el usuario lo apruebe. De este modo, mantienes el control y añades un nivel de responsabilidad.
- Leer artículos de una lista de deseos o de entrada: Haz que el agente cargue artículos dinámicamente desde una lista de deseos de Amazon guardada, un archivo local (por ejemplo, JSON o CSV) o un punto final de API remoto.
Conclusión
En esta entrada de blog, aprendiste cómo utilizar la popular biblioteca de uso de navegación en combinación con una API de navegador de raspado para construir un agente de IA altamente eficaz en Python.
Como se ha demostrado, la combinación de Browse Use con Scraping Browser de Bright Data permite crear agentes de IA que pueden interactuar de forma fiable con prácticamente cualquier sitio web. Este es solo un ejemplo de cómo las herramientas y servicios de Bright Data pueden potenciar la automatización avanzada impulsada por IA.
Explore nuestras soluciones para el desarrollo de agentes de IA:
- Agentes autónomos de IA: Busque, acceda e interactúe con cualquier sitio web en tiempo real mediante un potente conjunto de API.
- Aplicaciones verticales de IA: cree canalizaciones de datos fiables y personalizadas para extraer datos web de fuentes específicas del sector.
- Modelos básicos: Acceda a conjuntos de datos compatibles a escala web para potenciar el preentrenamiento, la evaluación y el ajuste.
- IA multimodal: aproveche el mayor repositorio del mundo de imágenes, vídeos y audio optimizados para la IA.
- Proveedores de datos: Conéctese con proveedores de confianza para obtener conjuntos de datos de alta calidad preparados para la IA a escala.
- Paquetes de datos: Obtenga conjuntos de datos comisariados, listos para usar, estructurados, enriquecidos y anotados.
Para más información, explore nuestro centro de IA.
Cree una cuenta de Bright Data y pruebe todos nuestros productos y servicios para el desarrollo de agentes de IA.





