

En esta guía sobre análisis de datos con Python, verás:
- Por qué utilizar Python para el análisis de datos
- Bibliotecas comunes para el análisis de datos con Python
- Tutorial paso a paso para realizar análisis de datos en Python
- El proceso a seguir para analizar los datos
Sumerjámonos.
Por qué utilizar Python para el análisis de datos
El análisis de datos suele realizarse con dos lenguajes de programación principales:
En concreto, a continuación se exponen las principales razones para utilizar Python en el análisis de datos:
- Curva de aprendizaje poco pronunciada: Python tiene una sintaxis sencilla y legible, por lo que es accesible tanto para principiantes como para expertos.
- Versatilidad: Python puede manejar una gran variedad de tipos y formatos de datos, como CSV, Excel, JSON, bases de datos SQL y Parquet, entre otros. Además, es adecuado para tareas que van desde la simple limpieza de datos hasta aplicaciones complejas de aprendizaje automático y aprendizaje profundo.
- Escalabilidad: Python es escalable y puede manejar tanto pequeños conjuntos de datos como tareas de procesamiento de datos a gran escala. Por ejemplo, librerías como Dash y PySpark te ayudan a tratar Big Data sin esfuerzo.
- Apoyo de la comunidad: Python cuenta con una amplia y activa comunidad de desarrolladores y científicos de datos que contribuyen a su ecosistema.
- Aprendizaje automático e integración de IA: Python es el lenguaje de referencia para el aprendizaje automático y la IA, con bibliotecas como TensorFlow, PyTorch y Keras, que permiten realizar análisis avanzados y modelos predictivos.
- Reproducibilidad y colaboración: Los cuadernos Jupyter ayudan a compartir y reproducir fragmentos de análisis de datos, lo que es importante para la colaboración en la ciencia de datos.
- Entorno único para diferentes propósitos: Python ofrece la posibilidad de utilizar el mismo entorno para diferentes propósitos. Por ejemplo, puedes utilizar el mismo Jupyter Notebook para extraer datos de la web y luego analizarlos. En el mismo entorno, también puedes hacer predicciones con modelos de aprendizaje automático.
Bibliotecas comunes para el análisis de datos con Python
Python es muy utilizado en el campo de la analítica también por su amplio ecosistema de librerías. Aquí están las bibliotecas más comunes para el análisis de datos en Python:
- NumPy: Para cálculos numéricos y manejo de matrices multidimensionales.
- Pandas: Para manipulación y análisis de datos, especialmente con datos tabulares.
- Matplotlib y Seaborn: Para la visualización de datos y la creación de gráficos perspicaces.
- SciPy: Para computación científica y análisis estadístico avanzado.
- Plotly: Para crear gráficos animados.
Véalos en acción en la siguiente sección guiada.
Análisis de Datos con Python: Un Ejemplo Completo
Ahora ya sabe por qué utilizar Python para el análisis de datos y las bibliotecas comunes que apoyan esa tarea. Sigue este tutorial paso a paso para aprender a realizar análisis de datos con Python.
En esta sección, analizará la información sobre propiedades de Airbnb recuperada de un conjunto de datos gratuitos de Bright Data.
Requisitos
Para seguir esta guía, debe tener Python 3.6 o superior instalado en su máquina.
Paso 1: Configurar el entorno e instalar las dependencias
Supongamos que llama a la carpeta principal de su proyecto data_analysis/. Al final de este paso, la carpeta tendrá la siguiente estructura:
data_analysis/
├── analysis.ipynb
└── venv/Dónde:
analysis.ipynbes el Jupyter Notebook que contiene todo el código Python de análisis de datos.venv/contiene el entorno virtual de Python.
Puede crear el directorio del entorno virtual venv/ de la siguiente manera:
python -m venv venvPara activarlo en Windows, ejecute
venvScriptsactivateDe forma equivalente, en macOS/Linux, ejecute:
source venv/bin/activateEn el entorno virtual activado, instale todas las bibliotecas necesarias:
pip install pandas jupyter matplotlib seaborn numpyPara crear el archivo analysis.ipynb, primero debe entrar en la carpeta data_analysis/:
cd data_analysisA continuación, inicializa un nuevo Jupyter Notebook con este comando:
jupyter notebookAhora puedes acceder a tu Jupyter Notebook App en http://locahost:8888 en tu navegador.
Cree un nuevo archivo haciendo clic en la opción “Nuevo > Python 3 (ipykernel)”:
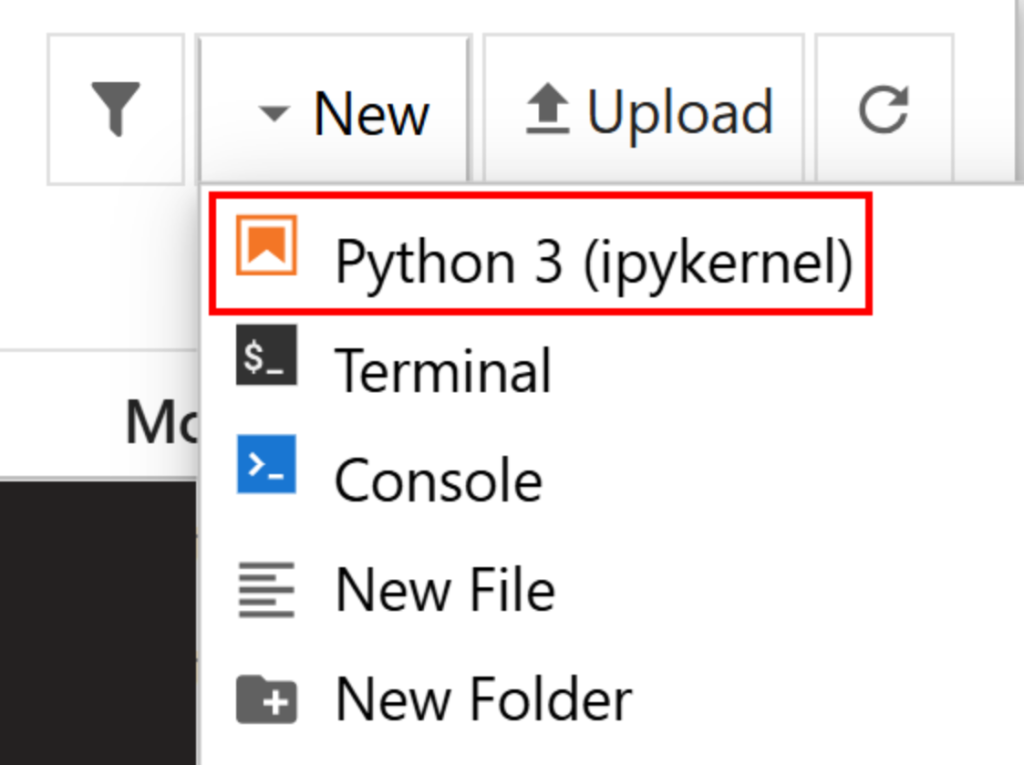
Por defecto, el nuevo archivo se llamará untitled.ipynb. Puede cambiarle el nombre en el panel de control de la siguiente manera:
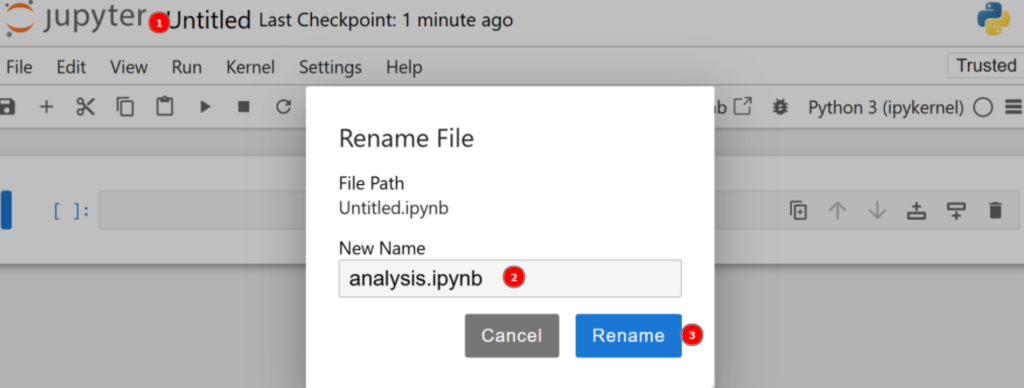
¡Genial! Ya estás preparado para el análisis de datos con Python.
Paso 2: Descargar los datos y abrirlos
El conjunto de datos utilizado para este tutorial procede del mercado de conjuntos de datos de Bright Data. Para descargarlo, regístrese gratuitamente en la plataforma y vaya a su panel de usuario. A continuación, siga la ruta “Conjuntos de datos web > Conjunto de datos” para acceder al mercado de conjuntos de datos:
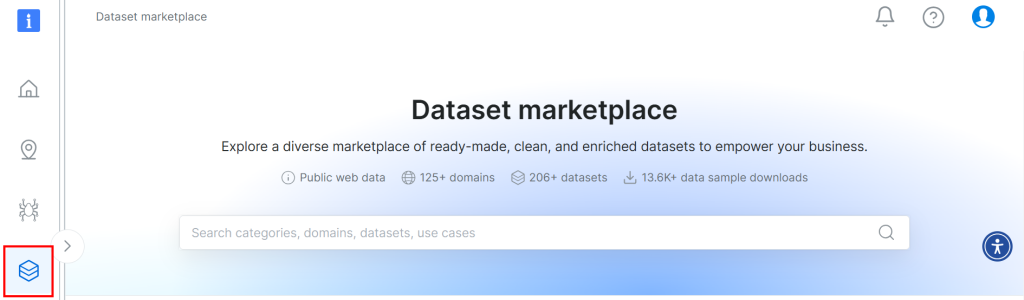
Desplácese hacia abajo y busque la tarjeta “Información sobre propiedades Airbnb”:
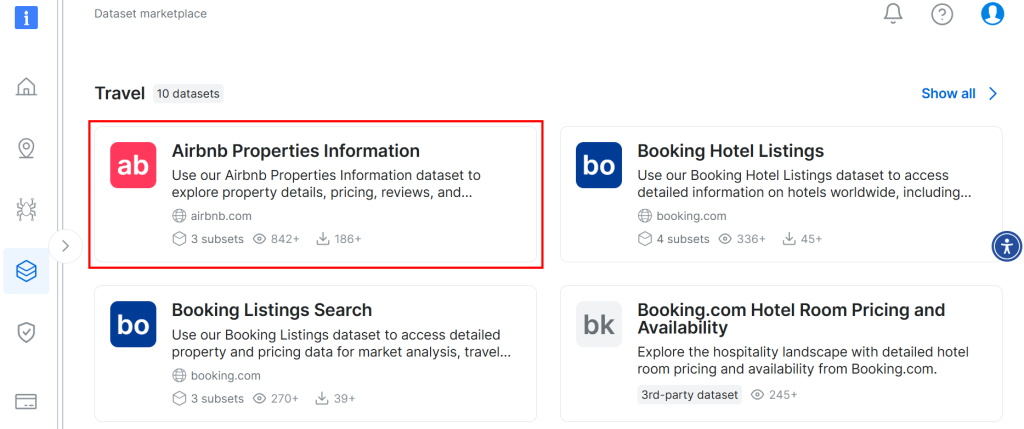
Para descargar el conjunto de datos, haga clic en la opción “Descargar muestra > Descargar como CSV”:
Ahora puede renombrar el archivo descargado, por ejemplo, como airbnb.csv. Para abrir el archivo CSV en Jupyter Notebook, escriba lo siguiente en una nueva celda:
import pandas as pd
# Open CSV
data = pd.read_csv("airbnb.csv")
# Show head
data.head()En este fragmento:
- El método
read_csv()abre el archivo CSV como un conjunto de datos pandas. - El método
head() muestra las 5 primeras filas del conjunto de datos.
A continuación se muestra el resultado esperado:
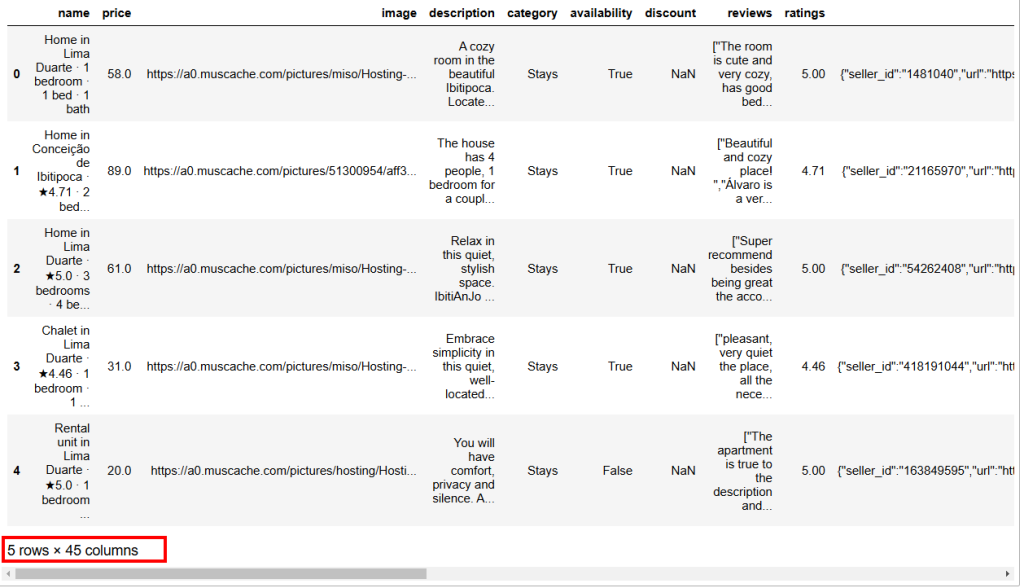
Como puede ver, este conjunto de datos tiene 45 columnas. Para verlas todas, tiene que desplazar la barra hacia la derecha. Sin embargo, en este caso, el número de columnas es elevado, y sólo desplazando la barra hacia la derecha no podrá ver todas las columnas, ya que algunas han quedado ocultas.
Para visualizar realmente todas las columnas, escriba lo siguiente en una celda aparte:
# Show all columns
pd.set_option("display.max_columns", None)
# Display the data frame
print(data)Paso 3: Gestionar los NaN
En informática, NaN significa “Not a Number” (no es un número). Al realizar análisis de datos con Python, puede encontrarse con conjuntos de datos con valores vacíos, cadenas donde debería encontrar números o celdas ya etiquetadas como NaN (véase, por ejemplo, la columna de descuento en la imagen anterior).
Como su objetivo es analizar datos, tiene que tratar los NaNcorrectamente. Tienes principalmente tres formas de hacerlo:
- Borra todas las filas que contengan
NaNs. - Sustituye
los NaNde una columna por la media calculada sobre los otros números de la misma columna. - Búsqueda de nuevos datos para enriquecer el conjunto de datos de origen.
En aras de la simplicidad, vamos a seguir el primer enfoque.
En primer lugar, debe comprobar si todos los valores de la columna de descuento son NaN. Si es así, puedes borrar toda la columna. Para comprobarlo, escribe lo siguiente en una nueva celda:
import numpy as np
is_discount_all_nan = data["discount"].isna().all()
print(f"Is the 'discount' column all NaNs? {is_discount_all_nan}")En este fragmento, el método isna().all() analiza los NaNde la columna de descuento, que se ha filtrado del conjunto de datos con data["discount"].
El resultado que obtendrás es True, lo que significa que la columna descuento ****puede ser eliminada ya que todos sus valores son NaNs. Para conseguirlo, escribe
data = data.drop(columns=["discount"])El conjunto de datos original se ha sustituido por uno nuevo sin la columna de descuento.
Ahora puedes analizar todo el conjunto de datos y ver si hay algún otro NaN en las filas de esta forma:
total_nans = data.isna().sum().sum()
print(f"Total number of NaN values in the data frame: {total_nans}")El resultado que recibirás es:
Total number of NaN values in the data frame: 1248Esto significa que hay otros 1248 NaNen el marco de datos. Para eliminar las filas que contienen al menos un NaN, escriba:
data = data.dropna()Ahora, el marco de datos no tiene NaNsy está listo para el análisis de datos de Python sin ninguna preocupación de resultados sesgados.
Para verificar que el proceso ha ido bien, puedes escribir:
print(data.isna().sum().sum())El resultado esperado es 0.
Paso 4: Exploración de datos
Antes de visualizar los datos de Airbnb, debe familiarizarse con ellos. Una buena práctica es empezar visualizando las estadísticas de su conjunto de datos de esta manera:
# Show statistics of the entire dataset
statistics = data.describe()
# Print statistics
print(statistics)Este es el resultado esperado:
price ratings lat long guests
count 182.000000 182.000000 182.000000 182.000000 182.000000
mean 147.523352 4.804505 6.754955 -68.300942 6.554945
std 156.574795 0.209834 27.795750 24.498326 3.012818
min 16.000000 4.000000 -21.837300 -106.817450 2.000000
25% 50.000000 4.710000 -21.717270 -86.628968 4.000000
50% 89.500000 4.865000 30.382710 -83.479890 6.000000
75% 180.750000 4.950000 30.398860 -43.925480 8.000000
max 1003.000000 5.000000 40.481580 -43.801300 16.000000
property_id host_number_of_reviews host_rating hosts_year
count 1.820000e+02 182.000000 182.000000 182.000000
mean 1.323460e+17 3216.879121 4.776099 7.324176
std 3.307809e+17 4812.876819 0.138849 2.583280
min 3.089381e+06 2.000000 4.290000 1.000000
25% 3.107102e+07 73.000000 4.710000 6.000000
50% 4.375321e+07 3512.000000 4.710000 9.000000
75% 4.538668e+07 3512.000000 4.890000 9.000000
max 1.242049e+18 20189.000000 5.000000 11.000000
host_response_rate total_price
count 182.000000 182.000000
mean 98.538462 859.317363
std 8.012156 1498.684990
min 25.000000 19.000000
25% 100.000000 111.500000
50% 100.000000 350.000000
75% 100.000000 934.750000
max 100.000000 13165.000000 El método describe() informa de las estadísticas relacionadas con las columnas que tienen valores numéricos. Esta es la primera forma que tiene de empezar a entender sus datos. Por ejemplo, la columna host_rating informa de las siguientes estadísticas interesantes:
- El conjunto de datos tiene un total de 182 reseñas (el valor de
recuento). - La puntuación máxima es 5, la mínima 4,29 y la media 4,77.
Aún así, las estadísticas anteriores pueden no ser satisfactorias. Por lo tanto, intente visualizar un gráfico de dispersión de la columna host_rating para ver si hay algún patrón interesante que desee investigar más adelante. A continuación se explica cómo crear un gráfico de dispersión con seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
# Define figure size
plt.figure(figsize=(15, 10))
# Plot the data
sns.scatterplot(data=data, x="host_rating", y="listing_name")
# Labeling
plt.title("HOST RATINGS SCATTERPLOT", fontsize=20)
plt.xlabel("Host ratings", fontsize=16)
plt.ylabel("Houses", fontsize=16)
# Show plot
plt.show()El fragmento anterior hace lo siguiente:
- Define el tamaño de la imagen (en pulgadas) con el método
figure(). - Crea un gráfico de dispersión utilizando seaborn a través del método
scatterplot()configurado con:Polylang placeholder do not modify
Este es el resultado esperado:
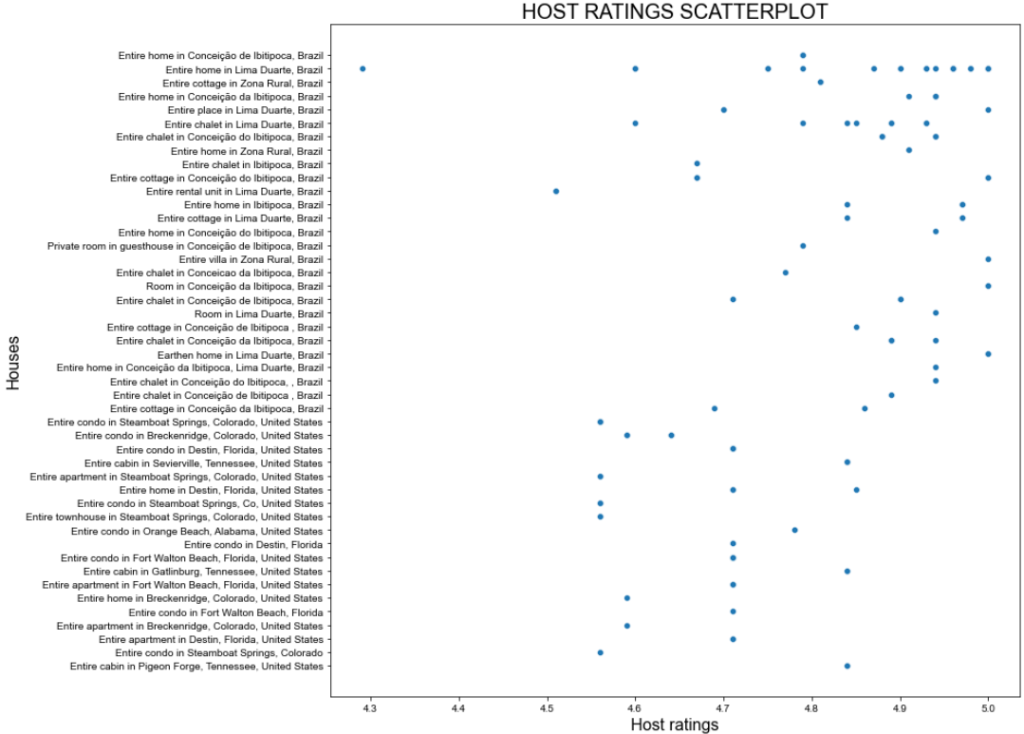
Gran argumento, ¡pero podemos hacerlo mejor!
Paso 5: Transformación y visualización de datos
El gráfico de dispersión anterior muestra que no hay un patrón particular en las valoraciones de los anfitriones. Sin embargo, la mayoría de las valoraciones son superiores a 4,7 puntos.
Imagine que está planeando unas vacaciones y quiere alojarse en uno de los mejores lugares. Una pregunta que podría hacerse es: “¿Cuánto cuesta alojarse en una casa con una calificación de al menos 4,8?”.
Para responder a esta pregunta, primero hay que transformar los datos.
La transformación que puede hacer es crear un nuevo marco de datos en el que la valoración sea superior a 4,8. Este contendrá la columna nombre_del_apartamento con los nombres de los apartamentos y la columna precio_total con sus precios.
Obtén ese subconjunto y muestra sus estadísticas con:
# Filter the DataFrame
high_ratings = data[data["host_rating"] > 4.8][["listing_name", "total_price"]]
# Caltulate and print statistics
high_ratings_statistics = high_ratings.describe()
print(high_ratings_statistics)El fragmento anterior crea un nuevo marco de datos llamado high_ratings de la siguiente manera:
data["host_rating"] > 4.8filtra los valores superiores a 4.8 en la columnahost_ratingsdel conjunto dedatos.[["nombre_listado", "precio_total"]]selecciona sólo las columnasnombre_listadoyprecio_totaldel marco de datoshigh_ratings.
A continuación se muestra el resultado esperado:
total_price
count 78.000000
mean 321.061026
std 711.340269
min 19.000000
25% 78.250000
50% 116.000000
75% 206.000000
max 4230.000000Las estadísticas muestran que el precio medio total de los apartamentos seleccionados es de 321 $, con un mínimo de 19 $ y un máximo de 4230 $. ¡Esto requiere un análisis más profundo!
Visualice un gráfico de dispersión de los precios de las casas con valoraciones altas empleando el mismo fragmento que utilizó antes. Todo lo que necesitas hacer es cambiar las variables utilizadas en el gráfico de la siguiente manera:
# Define figure size
plt.figure(figsize=(12, 8))
# Plot the data
sns.scatterplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show grid for better visualization
sns.set_style("ticks", {'axes.grid': True})
# Show plot
plt.show()Y ésta es la trama resultante:
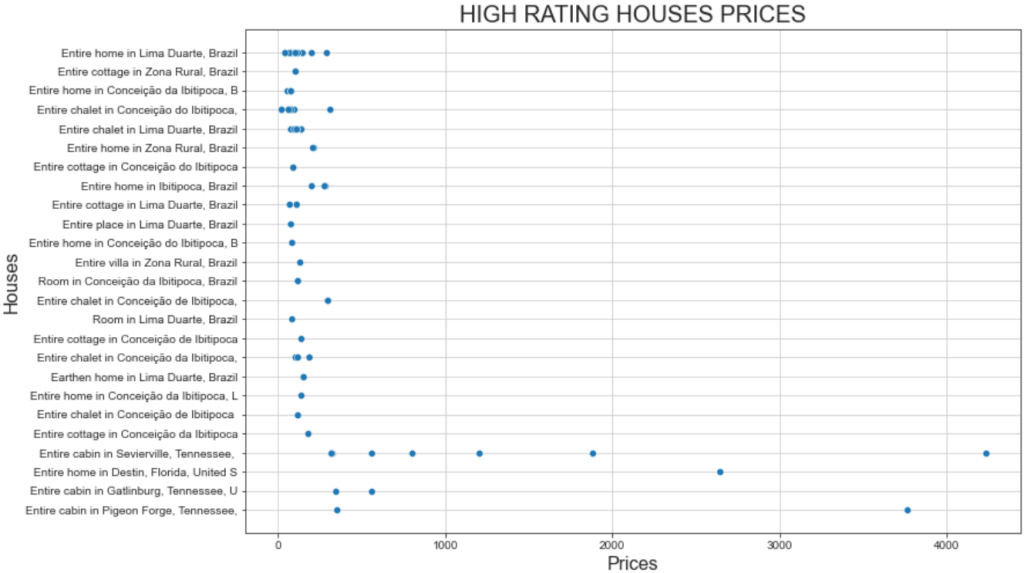
Este gráfico muestra dos hechos interesantes:
- Los precios son en su mayoría inferiores a 500 dólares.
- La “Cabaña entera en Sevierville” y la “Cabaña entera en Pigeon” presentan precios muy superiores a los 1.000 dólares.
Una forma mejor de visualizar el rango de precios es mostrando un gráfico de caja. Así es como puede hacerlo:
# Define figure size
plt.figure(figsize=(15, 10))
# Plotting the boxplot
sns.boxplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES - BOXPLOT', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show plot
plt.show()Esta vez, el gráfico resultante será:
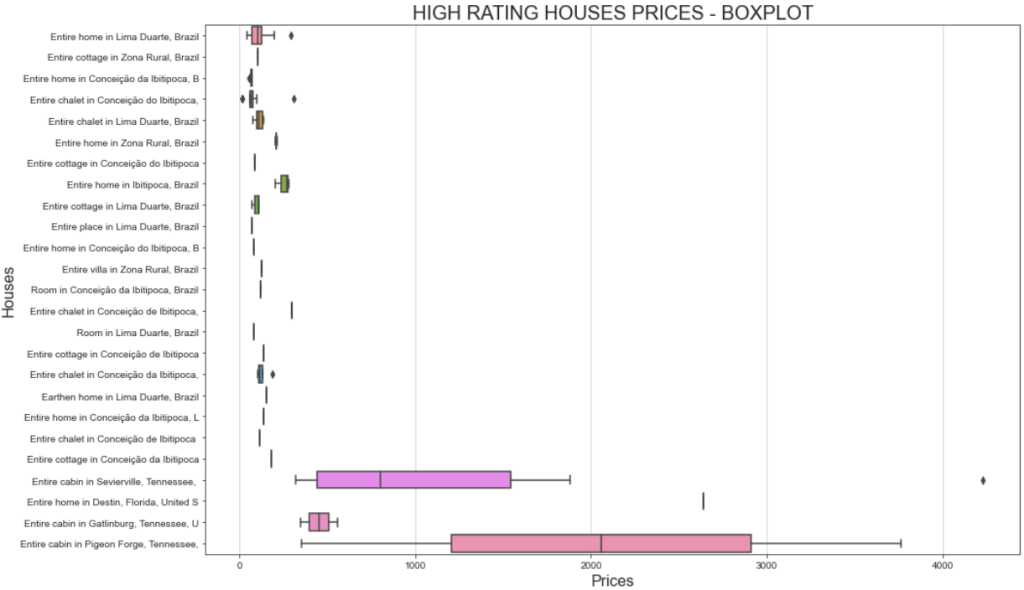
Si te preguntas por qué una misma casa puede tener costes diferentes, tienes que recordar que filtraste por las valoraciones de los usuarios. Esto significa que distintos usuarios pagaron de forma diferente y dejaron valoraciones distintas.
Además, la importante variación de precios de la “Cabaña entera en Sevierville”, que oscila entre menos de 1.000 y más de 4.000 dólares, puede deberse a la duración de la estancia. En concreto, el conjunto de datos original incluye una columna llamada travel_details, que contiene información sobre la duración de la estancia. El amplio rango de precios podría indicar que algunos usuarios alquilaron la casa durante un periodo prolongado. Un análisis más profundo utilizando Python podría ayudar a descubrir más datos al respecto.
Paso 6: Investigaciones adicionales mediante la matriz de correlaciones
El análisis de datos en Python consiste en hacerse preguntas y buscar respuestas en los datos que se tienen. Una forma eficaz de plantear estas preguntas es visualizar la matriz de correlaciones.
La matriz de correlaciones es una tabla que muestra los coeficientes de correlación de distintas variables. El coeficiente de correlación más utilizado es el coeficiente de correlación de Pearson (CCP), que mide la correlación lineal entre dos variables. Sus valores oscilan entre -1 y +1, lo que significa:
- +1: Si el valor de una variable aumenta, la otra aumenta linealmente.
- -1 : Si el valor de una variable aumenta, la otra disminuye linealmente.
- 0: No se puede decir nada sobre la relación lineal de las dos variables (requiere un análisis no lineal).
En estadística, los valores de correlación lineal definen lo siguiente:
- 0,1-0,5: baja correlación.
- 0,6-1: alta correlación.
- 0: sin correlación.
Para visualizar la matriz de correlaciones del marco de datos, puede escribir lo siguiente:
# Set the images dimensions
plt.figure(figsize=(12, 10))
# Labeling
plt.title('CORRELATION MATRIX', fontsize=20)
plt.xticks(fontsize=16) # x-axis font size
plt.yticks(fontsize=16) # y-axis font size
# Applying mask
mask = np.triu(np.ones_like(numeric_data.corr()))
dataplot = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})
#Add this code before creating the correlation matrix
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# Correlation matrix
dataplot = sns.heatmap(data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})El fragmento anterior hace lo siguiente:
- El método
np.triu()se utiliza para diagonalizar una matriz. Esto se utiliza para una mejor visualización de la matriz para que se muestre como un triángulo y no como un cuadrado. - El método
sns.heatmap()crea un mapa de calor. También se utiliza para una mejor visualización. Dentro de él, el métododata.corr()es el que realmente calcula los coeficientes de Pearson para cada columna delos datosdel marco dedatos.
A continuación se muestra el resultado que obtendrá:

La idea principal a la hora de interpretar una matriz de correlaciones es encontrar variables que tengan una alta correlación, ya que éstas serán el punto de partida para nuevos análisis más profundos. Por ejemplo:
- Las variables
latylongtienen una correlación de -0,98. Esto es de esperar, ya que la latitud y la longitud están fuertemente correlacionadas a la hora de definir una ubicación específica en la Tierra. - Las variables
host_ratingylongtienen una correlación de -0,69. Se trata de un resultado interesante, que significa que la valoración del anfitrión está muy correlacionada con la variable longitud. Así pues, parece que las casas situadas en una determinada zona del mundo tienen valoraciones de anfitrión elevadas. - Las variables
latylongtienen, respectivamente, una correlación de 0,63 y -0,69 con elprecio. Esto basta para afirmar que el precio por día está muy influido por la ubicación.
En su análisis, también debe buscar variables no correlacionadas. Por ejemplo, el coeficiente de las variables is_supperhost y precio es -0,18, lo que significa que los superhosts no tienen los precios más altos.
Ahora que los conceptos principales están claros, te toca explorar y analizar los datos.
Paso 7: Póngalo todo junto
Este es el aspecto que tendrá el Jupyter Notebook definitivo para el análisis de datos con Python:









Obsérvese la presencia de diferentes celdas, cada una con su salida.
El proceso de análisis de datos con Python
La sección anterior le ha guiado a través del proceso de análisis de datos con Python. Aunque puede haber parecido un enfoque paso a paso impulsado por la oportunidad, en realidad se construyó sobre las siguientes mejores prácticas:
- Recuperación de datos: Si tienes la suerte de tener los datos que necesitas en una base de datos, ¡qué suerte! Si no es así, tendrá que recuperarlos utilizando métodos populares de obtención de datos, comoel web scraping.
- Limpieza de datos: Manejar
NaNs, agregar datos y aplicar los primeros filtros del conjunto de datos inicial. - Exploración de datos: La exploración de datos -a veces también llamada descubrimiento de datos- esla parte más importante del análisis de datos con Python. Requiere producir gráficos básicos que te ayuden a entender cómo están estructurados tus datos o si siguen patrones particulares.
- Manipulación de datos: Después de captar las ideas principales de los datos que está analizando, tiene que manipularlos. Esta parte requiere filtrar conjuntos de datos y, a menudo, combinar más de dos conjuntos de datos en uno solo (como si se realizaran uniones de tablas en SQL).
- Visualización de datos: Esta es la parte final, en la que presentas visualmente tus datos haciendo múltiples gráficos sobre los conjuntos de datos manipulados.
Conclusión
En esta guía sobre análisis de datos con Python, has aprendido por qué deberías utilizar Python para analizar datos y qué bibliotecas comunes puedes utilizar para ello. También has recorrido un tutorial paso a paso y has aprendido el proceso a seguir si quieres realizar análisis de datos en Python.
Ya has visto que Jupyter Notebook te ayuda a crear subconjuntos de tus datos, visualizarlos y descubrir poderosas perspectivas. Todo ello manteniendo todo estructurado en el mismo entorno. Ahora bien, ¿dónde puede encontrar conjuntos de datos listos para usar? Bright Data le ayuda.
Bright Data opera una red proxy grande, rápida y fiable, utilizada por muchas empresas de la lista Fortune 500 y más de 20.000 clientes. Que se utiliza para recuperar éticamente los datos de la Web y ofrecerlos en un vasto mercado de conjuntos de datos, que incluye:
- Conjuntos de datos empresariales: Datos de fuentes clave como LinkedIn, CrunchBase, Owler y Indeed.
- Conjuntos de datos de comercio electrónico: Datos de Amazon, Walmart, Target, Zara, Zalando, Asos y muchos más.
- Conjuntos de datos inmobiliarios: Datos de sitios web como Zillow, MLS y más.
- Conjuntos de datos de redes sociales: Datos de Facebook, Instagram, YouTube y Reddit.
- Conjuntos de datos financieros: Datos de Yahoo Finanzas, Market Watch, Investopedia y más.
Cree hoy mismo una cuenta gratuita en Bright Data y explore nuestros conjuntos de datos.






