
En este tutorial aprenderás
- Qué es Cursor y por qué se ha vuelto tan popular.
- Las principales razones para agregar un servidor MCP como el de Bright Data a Cursor.
- Cómo conectar Cursor al MCP Web de Bright Data.
- Cómo lograr los mismos resultados en Visual Studio Code.
¡Vamos a sumergirnos!
¿Qué es Cursor?
Cursor es un editor de código potenciado por IA construido como una bifurcación de Visual Studio Code. Su funcionalidad principal, como la de cualquier editor de texto, es proporcionar una interfaz para escribir código. Sin embargo, lo que lo hace especial es su profunda integración con la IA.
En lugar de un autocompletado básico, Cursor utiliza LLms para entender todo tu código base y el contexto. Esto le permite ofrecer funciones inteligentes como
- Indicaciones conversacionales: Describe lo que quieres en inglés sencillo y Cursor escribirá o editará el código por ti.
- Autocompletado multilínea: Sugiere y completa bloques enteros de código, no sólo líneas sueltas.
- Refactorización basada en IA: Puede optimizar, limpiar y corregir tu código de forma inteligente basándose en el contexto de todo el proyecto.
- Ayuda a la depuración: Pide a la IA que encuentre y explique los errores de tu código.
Cursor convierte un editor de código estándar en un programador por pares proactivo y altamente inteligente. Es compatible con múltiples LLM de varios proveedores e incluye soporte integrado para herramientas a través de MCP.
Por qué añadir MCP Web de Bright Data a Cursor
Entre bastidores, Cursor se basa en modelos LLM conocidos. Aunque su integración es más profunda y está más pulida que la de la mayoría de las herramientas, sigue enfrentándose a la misma limitación central que cualquier LLM: ¡el conocimiento de IA es estático!
Después de todo, los datos de entrenamiento de IA reflejan una instantánea en el tiempo. Esto se queda obsoleto rápidamente, sobre todo en campos en rápida evolución como el desarrollo de software. Ahora, imagina dar al agente de IA de Cursor la capacidad de:
- consultar los últimos tutoriales y documentación para flujos de trabajo RAG,
- consultar guías en vivo mientras escribe código, y
- navegar por sitios web en tiempo real con la misma facilidad con la que navega por sus archivos locales.
Eso es precisamente lo que desbloquea conectando Cursor a Web MCP de Bright Data.
Web MCP ofrece acceso a más de 60 herramientas preparadas para IA, creadas para la interacción web en tiempo real y la recopilación de datos. Todas ellas se basan en la rica infraestructura de IA de Bright Data.
Incluso en el nivel gratuito, su agente Cursor ya puede acceder a dos potentes herramientas:
| Herramienta | Descripción |
|---|---|
motor_de_busqueda |
Recupere resultados de búsqueda de Google, Bing o Yandex en JSON o Markdown. |
scrape_as_markdown |
Raspe cualquier página web en formato Markdown limpio, evitando la detección de bots y CAPTCHA. |
Además, Web MCP incluye herramientas para la automatización de navegadores en la nube y la recuperación de datos estructurados de plataformas como Amazon, YouTube, LinkedIn, TikTok, Google Maps y muchas otras.
Estos son sólo algunos ejemplos de lo que se hace posible al ampliar Cursor con Web MCP de Bright Data:
- Obtenga las últimas referencias de API o tutoriales de marcos de trabajo y, a continuación, genere automáticamente código de trabajo o andamiajes de proyectos.
- Obtenga instantáneamente resultados actualizados de motores de búsqueda e incrústelos en su documentación o comentarios de código.
- Recopile datos web en tiempo real para crear modelos de prueba realistas, cuadros de mando analíticos o canalizaciones de contenido automatizadas.
Para explorar toda la gama de funciones, consulte la documentación de Bright Data MCP.
Cómo integrar Web MCP en Cursor para una experiencia de codificación de IA mejorada
En esta sección paso a paso, verá cómo conectar una instancia de servidor local de Bright Data Web MCP a Cursor. Esta configuración proporciona una experiencia de IA sobrealimentada con más de 60 herramientas disponibles directamente en su IDE.
En detalle, utilizaremos las herramientas Web MCP para crear un backend Express con una API simulada que devuelve datos reales de Amazon. Este es sólo un ejemplo de los muchos casos de uso soportados por esta integración.
Sigue las instrucciones a continuación.
Requisitos previos
Para seguir este tutorial, asegúrate de tener:
- Una cuenta de Cursor (un plan Gratuito es suficiente).
- Una cuenta de Bright Data con una clave API activa.
No se preocupe por configurar Bright Data ahora. Se le guiará a través del proceso a medida que avance en el artículo.
Una comprensión básica de cómo funciona MCP, cómo funciona Cursor, y las herramientas proporcionadas por Web MCP también será útil.
Paso #1: Comenzar con Cursor
Instale la versión de Cursor para su sistema operativo, ábrala, e ingrese con su cuenta.
Si es la primera vez que inicia la aplicación, complete el asistente de configuración.
Debería ver algo como esto:
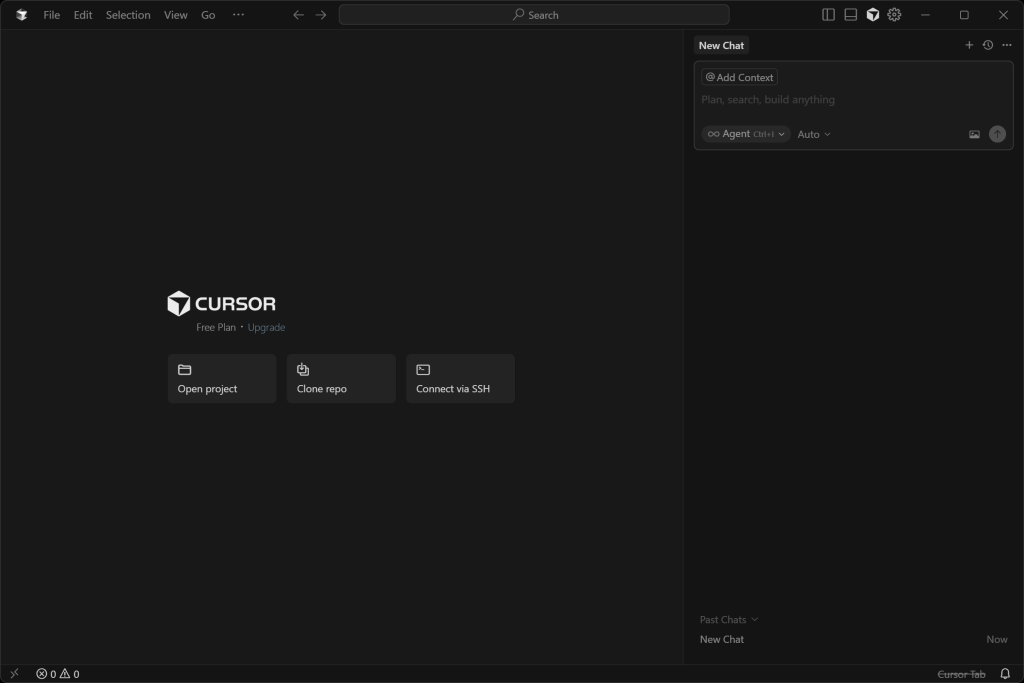
¡Genial! Ahora abre la carpeta de tu proyecto y prepárate para utilizar el agente de codificación IA incorporado, ampliado con Web MCP.
Paso #2: Configurar tu LLM
Al momento de escribir esto, Cursor utiliza el modelo Claude 4.5 por defecto (a través del modo “Auto”). Si estás de acuerdo con eso, siéntete libre de saltar a la siguiente sección. Recuerde que Claude también puede integrarse con Web MCP.
Si desea cambiar el modelo por defecto, busque “ajustes del cursor” y seleccione la opción equivalente:
En la pestaña que se abre, vaya a la pestaña “Modelos”:

Aquí puedes configurar qué agente IA de LLM Cursor debe utilizar. Ten en cuenta que los usuarios gratuitos sólo pueden elegir entre GPT-4.1 y “Auto” como modelos premium.
Para cambiar el modelo a GTP 4.1, busca “gpt”, encuentra el modelo “gpt-4.1” y habilítalo:

Si tienes una suscripción Pro o Business, puedes activar cualquier otro LLM compatible. Además, puedes incluso proporcionar tu propia clave API para el proveedor elegido.
A continuación, abre el panel “Nuevo chat” de la derecha. Haz clic en el menú desplegable “Auto”, desactívalo y selecciona la opción “gpt-4.1”:
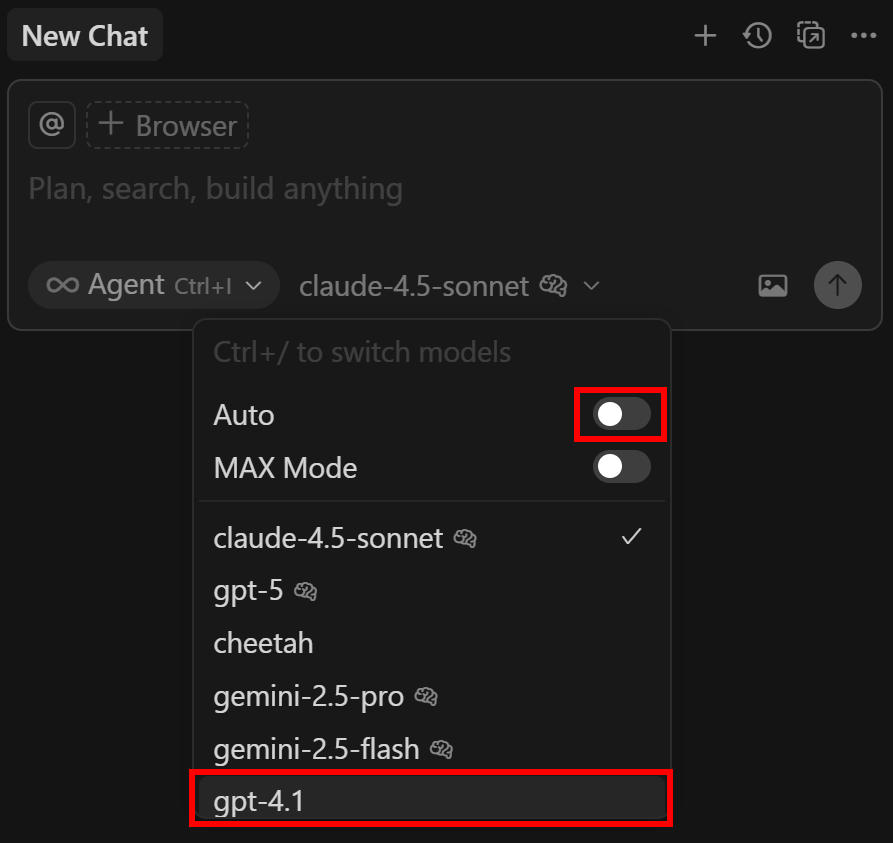
¡Bien hecho! Cursor está ahora operando a través de su LLM configurado.
Paso #3: Pruebe el MCP Web de Bright Data en su máquina
Antes de conectar Cursor al MCP Web de Bright Data, verifique que realmente puede ejecutar el servidor localmente. Esto es necesario porque el servidor MCP se configurará a través de STDIO.
Comience registrándose en Bright Data. Si ya dispone de una cuenta, simplemente inicie sesión. Para una configuración rápida, siga las instrucciones de la sección “MCP” del panel de control:
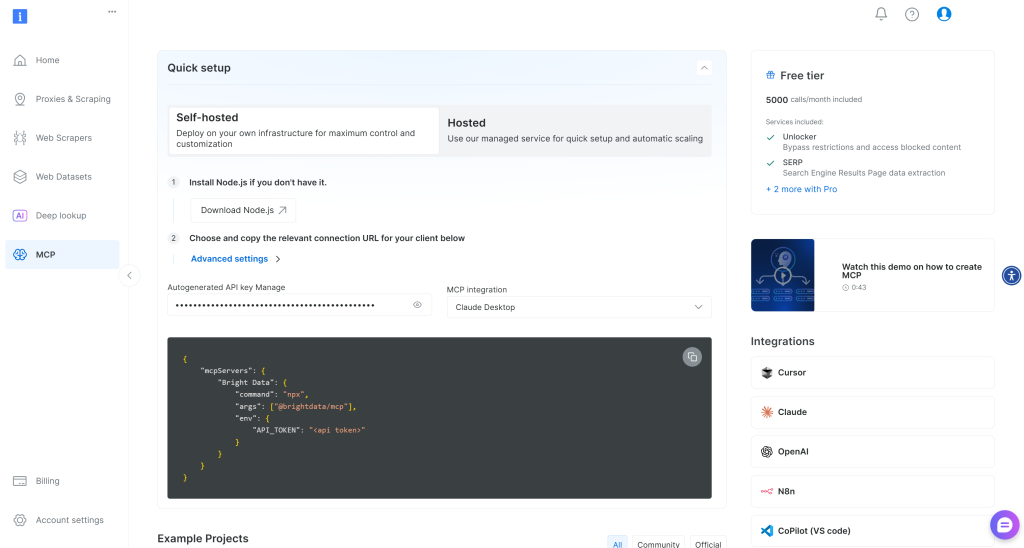
Para obtener más información, consulte las instrucciones siguientes.
En primer lugar, genere su clave API de Bright Data y guárdela en un lugar seguro. La necesitará en el siguiente paso. Asumiremos que su clave API tiene permisos de administrador, ya que esto simplifica la integración de Web MCP.
Ahora, instale el Web MCP globalmente en su máquina mediante este comando npm:
npm install -g @brightdata/mcpVerifica que el servidor MCP funciona lanzándolo:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" npx -y @brightdata/mcpO, de forma equivalente, en PowerShell
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"; npx -y @brightdata/mcpSustituya el marcador de posición <YOUR_BRIGHT_DATA_API> por su token de API de Bright Data. Estos comandos establecen la variable de entorno API_TOKEN necesaria e inician el Web MCP localmente a través del paquete @brightdata/mcp.
Si tiene éxito, debería ver una salida como ésta:

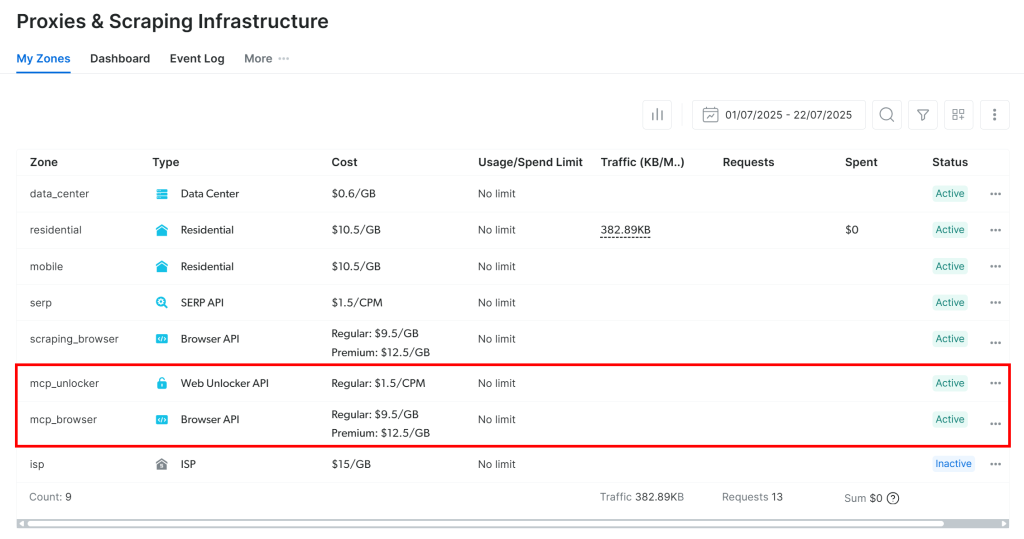
En el primer inicio, el Web MCP crea dos zonas predeterminadas en su cuenta de Bright Data:
mcp_unlocker: Una zona para Web Unlocker.mcp_browser: Una zona para Browser API.
Web MCP depende de estos dos servicios de Bright Data para sus más de 60 herramientas.
Si desea comprobar que las zonas están configuradas, vaya a la página “Proxies & Infraestructura de scraping” de su cuenta de Bright Data. Debería ver las dos Zonas en la tabla:
Nota: Si su token API no tiene permisos de administrador, las dos zonas no se crearán automáticamente. En ese caso, defínalas manualmente y establézcalas mediante variables de entorno como se explica en GitHub.
Recuerda que, en el nivel gratuito, Web MCP sólo expone las herramientas search_engine y scrape_as_markdown (y sus versiones por lotes). Para desbloquear el resto de herramientas, activa el modo Pro **estableciendo la variable de entorno PRO_MODE="true":
API_TOKEN="<TU_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpO, en Windows
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpEl modo Pro desbloquea las más de 60 herramientas, pero no está incluido en el nivel gratuito, lo que significa que incurrirá en cargos adicionales.
Estupendo. Acabas de asegurarte de que el servidor Web MCP funciona localmente. Finalice el proceso MCP, ya que está a punto de configurar Cursor para que lo inicie por usted y se conecte a él.
Paso #4: Configurar Web MCP en Cursor
Comience buscando “>mcp” y seleccionando la opción “Ver: Abrir Configuración MCP”:
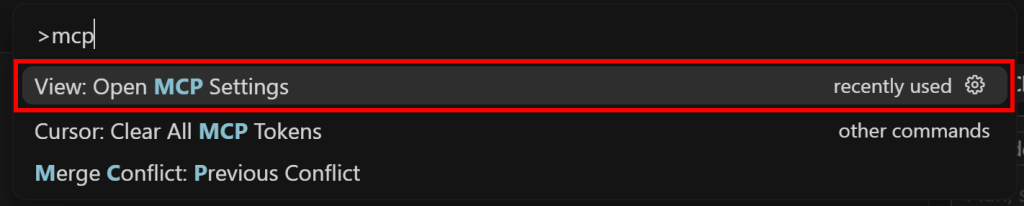
En la sección “Herramientas y MCP”, haga clic en el botón “Agregar MCP personalizado”:

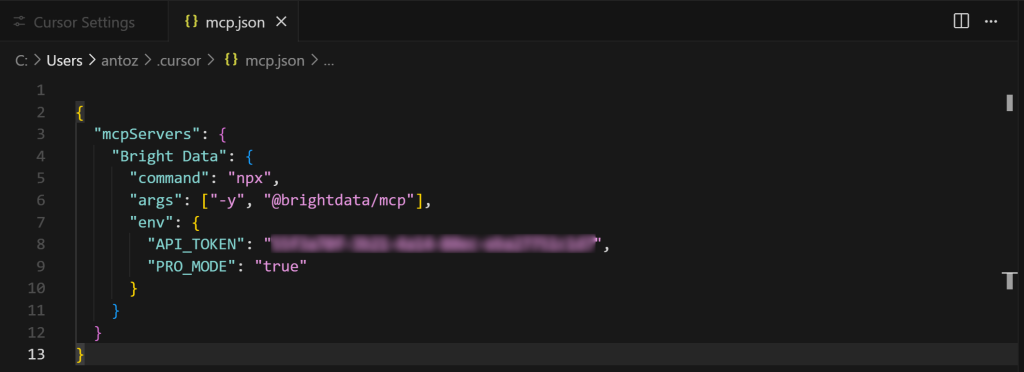
Esto abrirá el siguiente archivo de configuración mcp.json:

Como puede ver, por defecto, está vacío. Para la integración Web MCP de Bright Data, rellénelo como se indica a continuación:
{
"mcpServers": {
"Bright Data": {
"comando": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<SU_CLAVE_API_BRIGHT_DATA>",
"PRO_MODE": "true"
}
}
}
}A continuación, guarde el archivo utilizando Ctrl + S (o Cmd + S en macOS):
La configuración anterior replica el comando npx que probamos anteriormente, utilizando variables de entorno para pasar credenciales y configuraciones:
API_TOKENes necesario. Establezca la clave de API de Bright Data que generó anteriormente.PRO_MODEes opcional. Elimínelo si no tiene intención de activar el modo Pro.
En otras palabras, Cursor utilizará la configuración en mcp.json para ejecutar el comando npx visto anteriormente. Ejecutará un proceso Web MCP localmente, se conectará a él y obtendrá acceso a las herramientas expuestas.
Cierre la pestaña mcp.j son, ya que la integración Cursor + Bright Data Web MCP está completa.
Nota: Si prefiere no utilizar STDIO y desea utilizar SSE o HTTP fluido, tenga en cuenta que Web MCP de Bright Data también proporciona una opción de servidor remoto.
Paso #5: Verificar la Disponibilidad de la Herramienta desde la Integración MCP
Es hora de comprobar si Cursor se ha conectado correctamente al servidor Web MCP y puede acceder a todas sus herramientas.
Para ello, vuelva a la sección “Herramientas y MCP” en la pestaña “Configuración de Cursor”. Ahora debería ver la opción “Bright Data” configurada, con una lista de todas las herramientas disponibles:
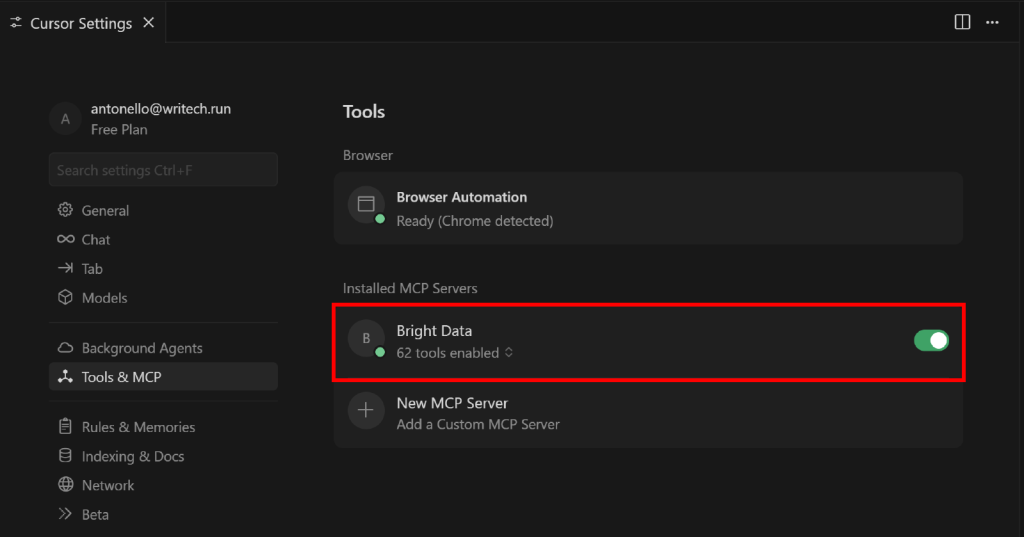
Despliegue el desplegable “N herramientas habilitadas” (donde N es el número de herramientas habilitadas) para inspeccionar todas las herramientas disponibles:
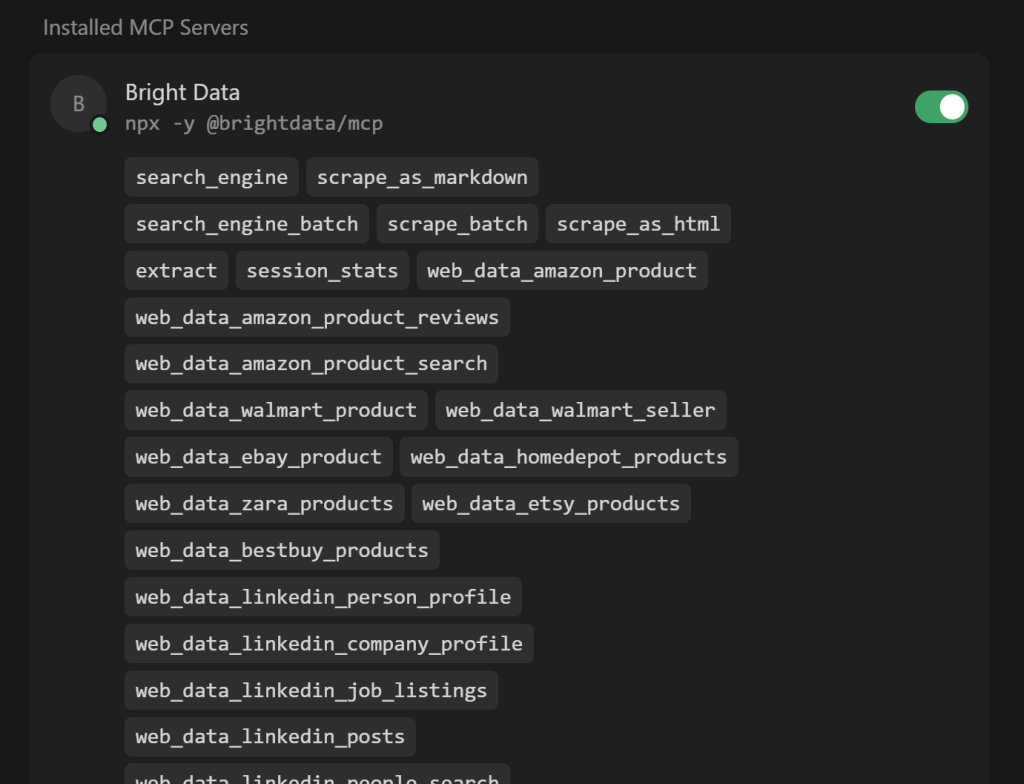
Observe que Cursor se conecta automáticamente al servidor y recupera sus más de 60 herramientas.
Si el Modo Pro está desactivado, sólo verá las 4/5 herramientas gratuitas disponibles. Aquí, también puede activar o desactivar las herramientas como prefiera. Por defecto, están todas activadas.
Una vez confirmado, cierre la pestaña “Configuración del cursor”. Prepárate para aprovechar estas herramientas y disfrutar de una experiencia de codificación potenciada por IA.
Paso #6: Ejecute una Tarea con el Agente de Codificación de IA Mejorada
Para probar las capacidades de su agente de codificación Cursor, necesita una tarea que ejercite las características de recuperación de datos web recientemente configuradas.
Por ejemplo, supongamos que estás construyendo un backend en Express.js para tu aplicación de comercio electrónico. Quieres simular una API que devuelva datos reales de productos de Amazon.
Consíguelo con una petición como esta
Raspe los datos de los siguientes productos de Amazon:
1. https://www.amazon.com/Clean-Skin-Club-Disposable-Sensitive/dp/B07PBXXNCY/
2. https://www.amazon.com/Neutrogena-Cleansing-Towelettes-Waterproof-Alcohol-Free/dp/B00U2VQZDS/
3. https://www.amazon.com/Medicube-Zero-Pore-Pads-Dual-Textured/dp/B09V7Z4TJG/
A continuación, guarda los datos extraídos en un archivo JSON local. A continuación, crea un sencillo proyecto Express.js con un endpoint que acepte un ASIN (que representa un producto de Amazon) y devuelva los datos correspondientes leídos del archivo JSON.Suponga que está operando en modo Pro. Ejecuta la petición anterior en Cursor.
Esto es lo que ocurrió a continuación, paso a paso:
- El LLM configurado en Cursor identifica
web_data_amazon_productcomo la herramienta para recuperar los datos de los productos de Amazon. - Para cada uno de los tres productos de Amazon en el prompt, se te pide permiso para ejecutar
web_data_amazon_productpara obtener los datos. - Usted concede el permiso para cada herramienta, desencadenando tareas asíncronas de recopilación de datos (que, bajo el capó, llaman al Bright Data Amazon Raspador).
- Los datos recuperados para cada producto se muestran en formato JSON.
- GPT-4.1 procesa los datos recuperados y rellena un archivo
products.jsoncon ellos. - Cursor crea la estructura del proyecto npm, definiendo
package.json, y el archivoindex.jscon la lógica del servidor Express. - Se le pide permiso para instalar las dependencias del proyecto a través de
npm install. Esto resultará en un archivopackage.json y en la carpetanode_modules/. - Se le pedirá permiso para ejecutar el servidor con
npm start.
Nota: Incluso si no se especificó explícitamente en el prompt, GPT-4.1 también decidió preguntar por la instalación de las dependencias del proyecto y la configuración del servidor. ¡Fue una buena adición!
En este ejemplo, la salida final producirá una estructura de proyecto como la siguiente:
su-proyecto/
├── node_modules/
├── index.js
├── package.json
├── package-lock.json
└── products.json¡¡¡Perfecto!!! Inspeccionemos el resultado para ver si consigue el objetivo previsto.
Paso #7: Explorar el proyecto de salida
A medida que el agente de codificación IA generaba los archivos, estos aparecían en la columna izquierda en Cursor.
Advertencia: Sus archivos pueden diferir de lo que se muestra a continuación, ya que diferentes ejecuciones de IA pueden producir diferentes resultados.
Comience por inspeccionar el archivo products.json:
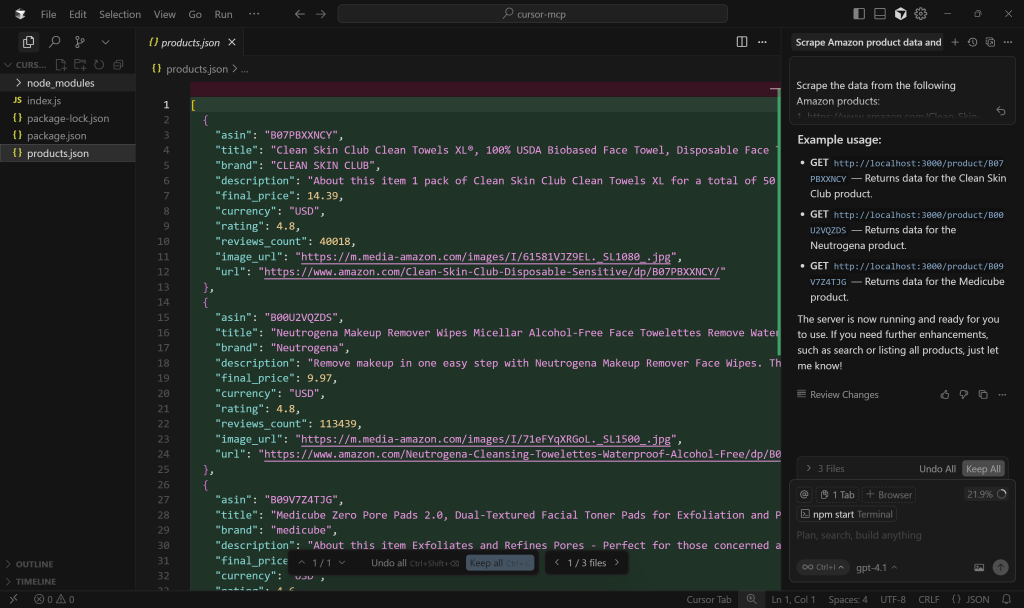
Como puede ver, contiene una versión simplificada de los datos obtenidos por la herramienta web_data_amazon_product:
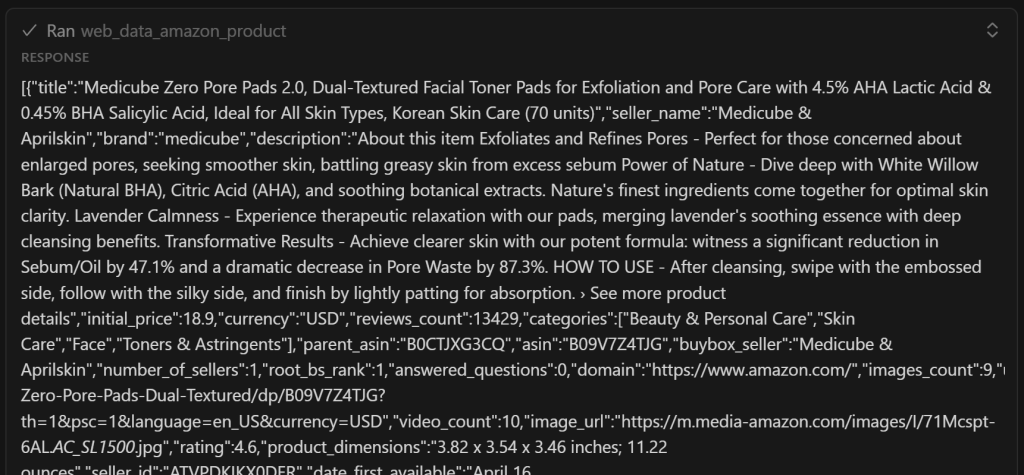
Importante: web_data_amazon_product devuelve realmente todos los datos del producto de la página de Amazon, no sólo algunos campos. Aún así, la IA decidió incluir sólo los campos más relevantes. Con un poco de optimización, puedes ordenar a la IA que incluya todos los campos si lo deseas.
A continuación, abre index.js para ver la lógica del servidor Express.js:
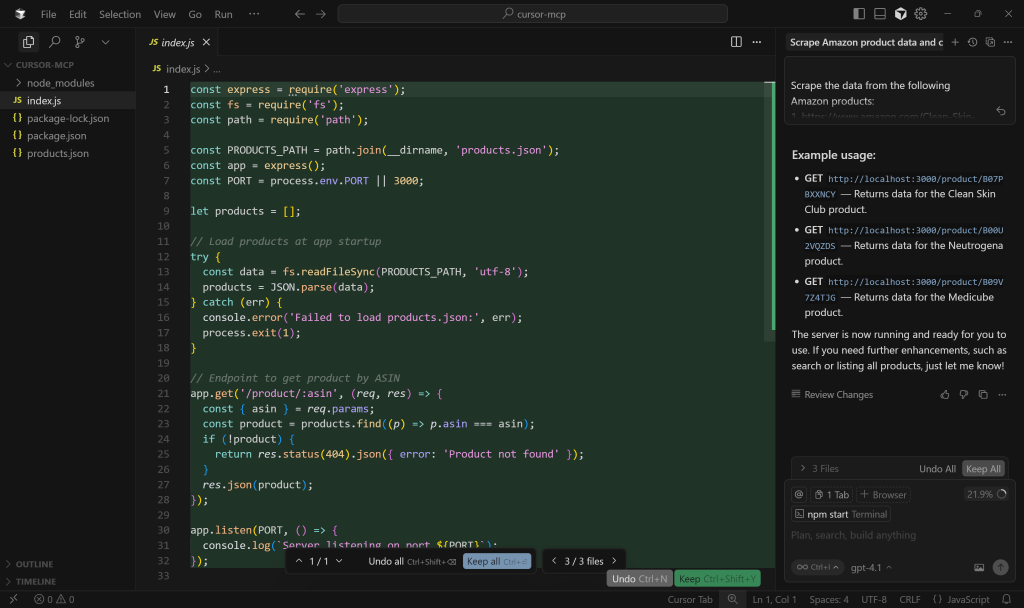
En concreto, el endpoint simulado para la recuperación de datos de productos utiliza la ruta /product/:asin.
Continúe inspeccionando los demás archivos, pero todos deberían estar bien. Así que pulsa el botón “Keep All” para confirmar la salida generada por la IA y prepárate para poner tu proyecto a prueba.
Paso #8: Probar el Proyecto Producido
Tu aplicación Express.js ya debería estar ejecutándose, ya que GPT-4.1 pidió permiso para ejecutar npm start. Si no lo ha hecho, puedes iniciarla manualmente con
npm startTu backend Express.js debería estar ejecutándose ahora en http://localhost.
A continuación, ejecuta el siguiente comando cURL para probar el endpoint GET /product/:asin:
curl "http://localhost/ product/B07PBXXNCYDonde B07PBXXNCY es el ASIN de uno de los productos de Amazon mencionados en el mensaje.
Debería ver algo parecido a esto:

¡Maravilloso! Los datos se han transferido correctamente al archivo products.json generado. El resultado corresponde a (una versión simplificada de) los datos de la página original de Amazon.
Si alguna vez has intentado obtener datos de productos de Amazon, sabes lo difícil que puede ser debido a su famoso CAPTCHA y otras medidas anti-bot. Seguramente, el GPT-4.1 vainilla por sí solo no puede recuperar datos de Amazon sobre la marcha.
Esto demuestra el poder de combinar Web MCP con Cursor. Ahora, esto era sólo un ejemplo muy simple. Sin embargo, con las más de 60 herramientas disponibles y las indicaciones correctas, ¡puedes manejar escenarios más avanzados directamente dentro de tu IDE!
¡Et voilà! Se ha creado con éxito un backend Express con un punto final de API simulado, gracias a la integración Cursor + Bright Data Web MCP.
[Extra] Enfoques Alternativos en Visual Studio Code
Si desea lograr una experiencia similar a Cursor en Visual Studio Code, utilice extensiones como Cline o Roo Code.
En particular, para integrar Web MCP en VS Code, consulte estas guías:
- Añadir Web MCP de Bright Data a Roo Code en Visual Studio Code
- Scraping web en Cline con el servidor MCP de Bright Data
Conclusión
En esta entrada de blog, aprendió cómo aprovechar al máximo la integración de MCP en Cursor. El agente de codificación de IA incorporado en el IDE ya es útil, pero se vuelve mucho más capaz e ingenioso una vez conectado al MCP Web de Bright Data.
Esta integración proporciona a Cursor la capacidad de realizar búsquedas web en vivo, extraer datos estructurados, consumir feeds de datos dinámicos e incluso automatizar las interacciones del navegador. Todo ello, directamente desde su entorno de codificación.
Para crear flujos de trabajo impulsados por IA aún más avanzados, explore el conjunto completo de servicios y soluciones de datos disponibles en el ecosistema de IA de Bright Data.
Cree una cuenta gratuita de Bright Data hoy mismo y empiece a experimentar con nuestras herramientas de datos web preparadas para IA.





