

En este tutorial guiado, descubrirá
- Una visión general de la GAR y sus mecanismos
- Las ventajas de integrar datos SERP en GPT-4o a través de RAG
- Cómo implementar un chatbot RAG en Python utilizando modelos GPT de OpenAI y datos SERP
¡Vamos a sumergirnos!
¿Qué es RAG?
RAG, abreviatura de Retrieval-Augmented Generation, es un enfoque de IA que combina la recuperación de información con la generación de texto. En un flujo de trabajo RAG, la aplicación primero recupera datos relevantes de fuentes externas, como documentos, páginas web o bases de datos. A continuación, pasa los datos a los modelos de IA para que ésta pueda generar respuestas más pertinentes en función del contexto.
RAG mejora los grandes modelos lingüísticos (LLM) como GPT al permitirles acceder y consultar información actualizada más allá de sus datos de entrenamiento originales. Este enfoque es clave en situaciones en las que se necesita información precisa y específica del contexto, ya que mejora tanto la calidad como la precisión de las respuestas generadas por la IA.
Por qué alimentar los modelos de IA con datos SERP
La fecha límite de conocimiento para GPT-4o es octubre de 2023, lo que significa que carece de acceso a eventos o información que hayan salido después de esa fecha. Sin embargo, los modelos de GPT-4o pueden extraer datos de Internet en tiempo real mediante la integración de búsqueda de Bing. Eso les ayuda a ofrecer información más actualizada.
Pero, ¿y si quieres que el modelo de IA emplee fuentes de datos específicas o prefieres motores de búsqueda más fiables? Aquí es donde entra en juego RAG.
En particular, alimentar los datos SERP(Search Engine Results Page) a los modelos de IA a través de RAG es una gran manera de obtener mejores respuestas. Este enfoque es especialmente beneficioso para tareas que requieren información actual o conocimientos especializados.
En resumen, pasar datos de resultados de búsqueda de alto rango a GPT-4o o GPT-4o mini da como resultado respuestas detalladas, precisas y ricas en contexto.
RAG Con Datos SERP Con Modelos GPT Usando Python: Tutorial Paso a Paso
En este tutorial, aprenderás a construir un chatbot RAG usando los modelos GPT de OpenAI. La idea es recopilar texto de las páginas con mejores resultados en Google para una consulta de búsqueda específica y utilizarlo como contexto para una solicitud GPT.
Ahora bien, el mayor reto es obtener los datos de las SERP. La razón es que la mayoría de los motores de búsqueda cuentan con soluciones anti-bot avanzadas para evitar el acceso automatizado a sus páginas. Para obtener información detallada, consulta nuestra guía sobre cómo hacer scraping de Google en Python.
Para simplificar el proceso, utilizaremos la API SERP de Bright Data:
Este raspador SERP premium permite recuperar fácilmente SERPs de Google, DuckDuckGo, Bing, Yandex, Baidu y otros motores de búsqueda mediante simples peticiones HTTP.
A continuación, extraeremos datos de texto de las URL devueltas utilizando un navegador headless. A continuación, utilizaremos esa información como contexto para el modelo GPT en un flujo de trabajo RAG. Si en cambio quieres recuperar datos online directamente usando IA, lee nuestro artículo sobre Scraping web con ChatGPT.
Si tienes ganas de explorar el código o quieres tenerlo a mano mientras sigues los pasos a continuación, clona el repositorio de GitHub que da soporte a este artículo:
git clone https://github.com/Tonel/rag_gpt_serp_scrapingSigue las instrucciones del archivo README.md para instalar las dependencias del proyecto e iniciarlo.
Ten en cuenta que el enfoque presentado en esta entrada de blog puede adaptarse fácilmente a cualquier otro motor de búsqueda o LLM.
Nota: Esta guía se refiere a Unix y macOS. Si eres usuario de Windows, aún puedes seguir el tutorial utilizando el Subsistema de Windows para Linux(WSL).
Paso #1: Inicializar un Proyecto Python
Asegúrate de que tienes Python 3 instalado en tu máquina. Si no, descárgalo e instálalo.
Crea una carpeta para tu proyecto e introdúcela en la terminal:
mkdir rag_gpt_serp_scraping
cd rag_gpt_serp_scrapingLa carpeta rag_gpt_serp_scraping contendrá tu proyecto Python RAG.
A continuación, cargue el directorio del proyecto en su IDE de Python favorito. PyCharm Community Edition o Visual Studio Code con la extensión Python serán suficientes.
Dentro de rag_gpt_serp_scraping, añade un archivo app.py vacío. Este contendrá su lógica de raspado y RAG.
A continuación, inicializa un entorno virtual Python en el directorio del proyecto:
python3 -m venv envActive el entorno virtual con el siguiente comando:
source ./env/bin/activate¡Genial! Ya está todo listo.
Paso #2: Instalar las librerías requeridas
Las dependencias utilizadas por este proyecto Python RAG basado en modelos GPT son:
python-dotenv: Para cargar variables de entorno desde un archivo .env. Se utilizará para gestionar de forma segura las credenciales sensibles, como las credenciales de Bright Data y las claves API de OpenAI.requests: Para realizar solicitudes HTTP a la API SERP de Bright Data. Para obtener más información, consulte nuestra guía sobre cómo utilizar un Proxy con Requests.langchain-community: Forma parte del framework LangChain, un conjunto de herramientas para construir con LLMs encadenando componentes interoperables. Se utilizará para recuperar texto de las páginas SERP de Google y limpiarlo para generar contenido relevante para RAG.openai: La biblioteca cliente oficial de Python para la API OpenAI. Se utilizará para interactuar con los modelos GPT y generar respuestas en lenguaje natural basadas en las entradas dadas y el contexto RAG.streamlit: Un framework para construir aplicaciones web interactivas en Python. Será muy útil para crear una interfaz de usuario en la que los usuarios puedan introducir sus consultas de búsqueda en Google e indicaciones de IA, y ver los resultados de forma dinámica.
En un entorno virtual activado, ejecute el siguiente comando para instalar todas las dependencias:
pip install python-dotenv peticiones langchain-community openai streamlitEn detalle, utilizaremos AsyncChromiumLoader de langchain-community, que requiere las siguientes dependencias:
pip install --upgrade --quiet playwright beautifulsoup4 html2textPara funcionar correctamente, Playwright también requiere instalar los navegadores con:
playwright installInstalar todas estas librerías llevará un rato, así que ten paciencia.
¡Fantástico! Ya está listo para escribir su lógica Python.
Paso #3: Prepara tu proyecto
En app.py, añade los siguientes imports:
from dotenv import carga_dotenv
importar os
importar peticiones
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
import streamlit como stA continuación, cree un archivo .env en la carpeta de su proyecto para almacenar todas sus credenciales. La estructura de su proyecto ahora se verá como a continuación:

Utiliza la siguiente función en app.py para indicar a python-dotenv que cargue las variables de entorno desde .env:
load_dotenv()Ahora puedes importar variables de entorno de .env o del sistema con:
os.environ.get("<ENV_NAME>")Aquí es también por qué importamos la biblioteca estándar de Python os.
Paso #4: Configurar API SERP
Como se mencionó en la introducción, nos basaremos en la API SERP de Bright Data para recuperar contenido de las páginas de resultados de los motores de búsqueda y utilizarlo en nuestro flujo de trabajo RAG de Python. En concreto, extraeremos texto de las URL de las páginas web devueltas por la API SERP.
Para configurar la API SERP, consulta la documentación oficial. También puede seguir las instrucciones que se indican a continuación.
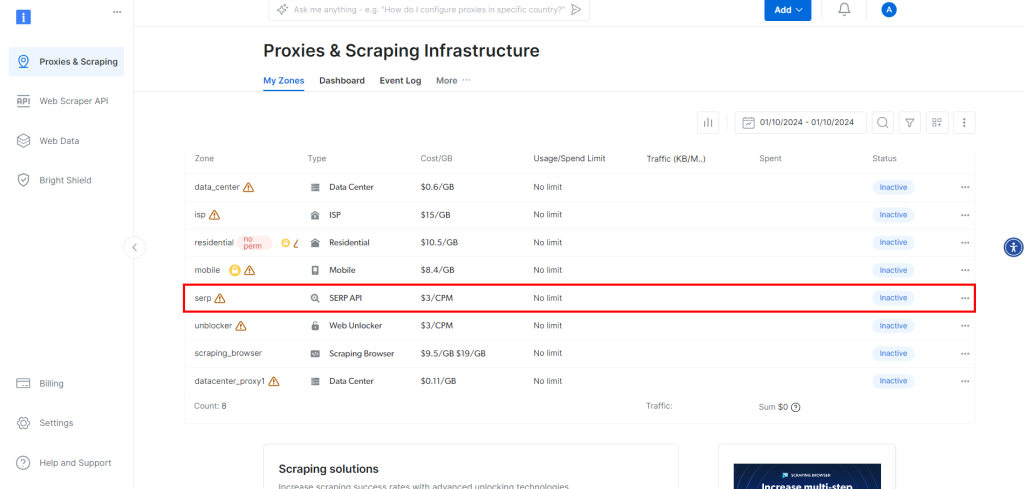
Si aún no ha creado una cuenta, regístrese en Bright Data. Una vez conectado, vaya al panel de control de su cuenta:

Allí, haga clic en el botón “Obtener productos Proxy”.
Esto le llevará a la página siguiente, donde deberá hacer clic en la fila “API SERP”:
En la página del producto API SERP, activa “Activar zona” para habilitar el producto:
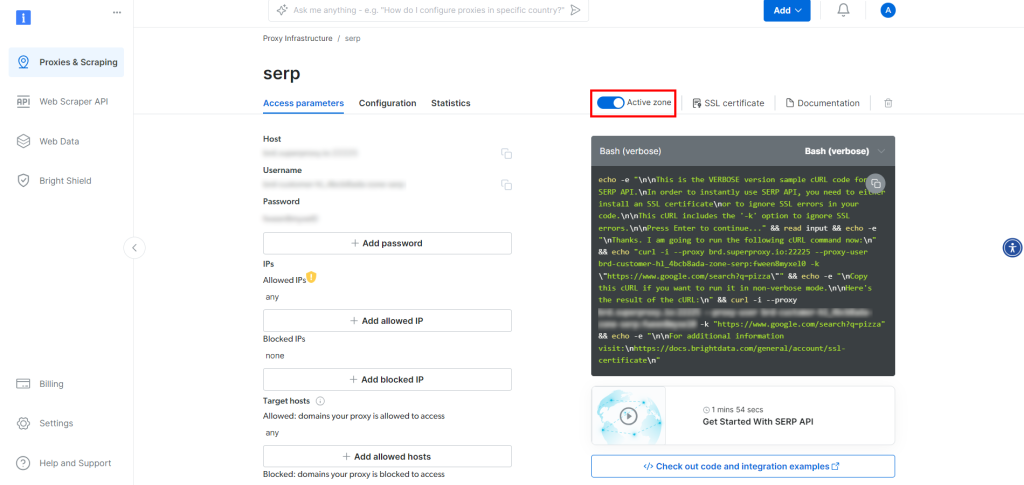
Ahora, copia el host, el puerto, el nombre de usuario y la contraseña de la API SERP en la sección “Parámetros de acceso” y añádelos a tu archivo .env:
BRIGHT_DATA_SERP_API_HOST="<SU_HOST>"
BRIGHT_DATA_SERP_API_PORT=<SU_PUERTO>".
BRIGHT_DATA_SERP_API_USERNAME="<SU_NOMBRE_DE_USUARIO>"
BRIGHT_DATA_SERP_API_PASSWORD="<SU_CONTRASEÑA>"Sustituya los marcadores de posición <YOUR_XXXX> por los valores proporcionados por Bright Data en la página API SERP.
Tenga en cuenta que el host en “Parámetros de acceso” tiene un formato como este
brd.superproxy.io:33335Debe dividirlo como se indica a continuación
BRIGHT_DATA_SERP_API_HOST="brd.superproxy.io"
BRIGHT_DATA_SERP_API_PORT=33335¡Estupendo! Ya puedes utilizar la API SERP en Python.
Paso #5: Implementar la lógica de SERP Scraping
En app.py, añade la siguiente función para recuperar el primer número de URLs de una página SERP de Google:
def get_google_serp_urls(query, number_of_urls=5):
# realiza una petición a la API SERP de Bright Data
# con JSON autoparsing
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
password = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{username}:{password}@{host}:{port}"
Proxies = {"http": proxy_url, "https": proxy_url}
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# recuperar la respuesta JSON analizada
datos_respuesta = respuesta.json()
# extraer un número "number_of_urls" de
# URLs de Google SERP de la respuesta
google_serp_urls = []
if "organic" in datos_respuesta:
for item in datos_respuesta["orgánico"]:
if "link" in item:
google_serp_urls.append(item["link"])
return google_serp_urls[:número_de_urls]Esto realiza una solicitud HTTP GET a la API SERP con la consulta de búsqueda especificada en el argumento query. El parámetro de consulta brd_json=1 garantiza que la API SERP analice los resultados en JSON, en el formato que se indica a continuación:
{
"general": {
"motor_buscador": "google",
"results_cnt": 1980000000,
"tiempo_busqueda": 0.57,
"language": "es",
"móvil": falso,
"basic_view": false,
"search_type": "text",
"page_title": "pizza - Búsqueda Google",
"code_version": "1.90",
"timestamp": "2023-06-30T08:58:41.786Z"
},
"input": {
"original_url": "https://www.google.com/search?q=pizza&brd_json=1",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12) AppleWebKit/608.2.11 (KHTML, como Gecko) Version/13.0.3 Safari/608.2.11",
"request_id": "hl_1a1be908_i00lwqqxt1"
},
"organic": [
{
"enlace": "https://www.pizzahut.com/",
"display_link": "https://www.pizzahut.com",
"title": "Pizza Hut | Delivery & Carryout - ¡Nadie supera a Pizzas The Hut!",
"image": "omitido por brevedad...",
"image_alt": "pizza de www.pizzahut.com",
"image_base64": "omitido por brevedad...",
"rank": 1,
"global_rank": 1
},
{
"link": "https://www.dominos.com/en/",
"display_link": "https://www.dominos.com ' ...",
"title": "Domino's: Pizza Delivery & Carryout, Pasta, Pollo & More",
"description": "Pide pizza, pasta, sándwiches y mucho más online para llevar o entregar a Domino's. Ver menú, encontrar ubicaciones, seguimiento de pedidos. Regístrate para recibir el correo electrónico de Domino's ...",
"imagen": "omitido por brevedad ...",
"image_alt": "pizza de www.dominos.com",
"image_base64": "omitido por brevedad...",
"rank": 2,
"global_rank": 3
},
// omitido por brevedad...
],
// omitido por brevedad...
}Las últimas líneas de la función recuperan cada URL SERP de los datos JSON resultantes, seleccionan sólo el primer número_de_urls URLs, y las devuelven en una lista.
¡Es hora de extraer el texto de estas URLs!
Paso #6: Extraer texto de las URLs SERP
Define una función que extraiga texto de cada una de las URLs SERP:
def extraer_texto_de_urls(urls, numero_de_palabras=600):
# ordena a una instancia headless de Chrome que visite las URLs proporcionadas
# con el user-agent especificado
loader = AsyncChromiumLoader(
urls,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# procesa los documentos HTML extraídos para extraer texto de ellos
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documentos,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# asegúrese de que cada documento de texto HTML contiene sólo un número
# número_de_palabras palabras
lista_texto_extraido = []
for doc_transformado in docs_transformado:
# dividir el texto en palabras y unir el primer número_de_palabras
palabras = doc_transformado.contenido_página.split()[:número_de_palabras]
texto_extraído = " ".join(palabras)
# ignorar documentos de texto vacíos
si len(texto_extraído) != 0:
lista_texto_extraído.append(texto_extraído)
return lista_texto_extraídoEsta función
- Carga páginas web desde las URL pasadas como argumento utilizando una instancia del navegador Chrome sin cabeza.
- Utiliza BeautifulSoupTransformer para procesar el HTML de cada página y extraer texto de etiquetas específicas (como <p>, <h1>, <strong>, etc.), omitiendo etiquetas no deseadas (como <a>) y comentarios.
- Limita el texto extraído para cada página web a un número de palabras especificado por el argumento
número_de_palabras. - Devuelve una lista del texto extraído de cada URL.
Tenga en cuenta que las etiquetas [“p”, “em”, “li”, “strong”, “h1”, “h2”] son suficientes para extraer texto de la mayoría de las páginas web. Sin embargo, en algunos casos concretos, puede que necesites personalizar esta lista de etiquetas HTML. Además, puede que tenga que aumentar o reducir el número de palabras objetivo para cada elemento de texto.
Por ejemplo, considere la siguiente página web:

Aplicando esa función a esa página resultará esta matriz de texto:
["La crítica de Transformers One de Lisa Johnson Mandell revela lo hasta ahora inconcebible: ¡Es una de las mejores películas de animación del año! Nunca pensé que me vería escribiendo esto sobre una película de Transformers, ¡pero Transformers One es realmente una película excepcional! ..."]¡Increíble! Aunque no es perfecto, sigue siendo de gran calidad para los estándares de los modelos de IA.
La lista de elementos de texto devuelta por extract_text_from_urls() representa el contexto RAG para alimentar al modelo OpenAI.
Paso 7: Generar la instrucción RAG
Define una función que transforme la petición de IA y el contexto de texto en la petición RAG final:
def get_openai_prompt(request, text_context=[]):
# prompt por defecto
prompt = solicitud
# añadir el contexto al prompt, si está presente
si len(texto_contexto) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f "Responda a la solicitud utilizando sólo el contexto que se indica a continuación.nnContexto:n{cadena_de_texto}nnSolicitud: {solicitud}"
return mensajeLos mensajes devueltos por la función anterior cuando se especifica un contexto RAG tienen este formato:
Responda a la solicitud utilizando únicamente el siguiente contexto.
Contexto:
Bla bla bla...
--------
Bla bla bla...
--------
Bla bla bla...
Petición: <TU_PEDIDA>Paso #8: Realizar la petición GPT
Primero, inicializa el cliente OpenAI en la parte superior del archivo app.py:
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))Esto depende de la variable de entorno OPENAI_API_KEY, que puedes definir directamente en los entornos de tu sistema o en el archivo .env:
OPENAI_API_KEY="<TU_API_KEY>"
Sustituye <YOUR_API_KEY> por el valor de tu clave de API de OpenAI. Si no sabes cómo conseguir una, sigue la guía oficial.
A continuación, escribe una función que utilice el cliente oficial de OpenAI para realizar una petición al modelo de mini IA GPT-4o:
def interrogar_openai(prompt, max_tokens=800):
# interroga al modelo OpenAI con el prompt dado
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"rol": "user", "content": prompt}],
max_tokens=max_tokens,
)
return response.choices[0].message.contentTenga en cuenta que puede configurar cualquier otro de los modelos GPT admitidos por la API de OpenAI.
Si se llama con un prompt devuelto por get_openai_prompt() que incluya un contexto de texto especificado, interrogate_openai() realizará con éxito la generación aumentada por recuperación según lo previsto.
Paso 9: Crear la interfaz de usuario de la aplicación
Utiliza Streamlit para definir un sencillo formulario UI donde los usuarios puedan especificar:
- La consulta de búsqueda de Google para pasar a la API SERP
- La consulta IA a enviar a GPT-4o mini
Lograr que con estas líneas de código:
con st.form("prompt_form"):
# inicializar los resultados de salida
resultado = ""
final_prompt = ""
# área de texto para que el usuario introduzca su consulta de búsqueda en Google
google_search_query = st.text_area("Búsqueda Google:", None)
# Área de texto para que el usuario introduzca su consulta de IA
request = st.text_area("Petición IA:", None)
# botón para enviar el formulario
submitted = st.form_submit_button("Enviar")
# si se envía el formulario
si enviado:
# recuperar las URL de Google SERP de la consulta de búsqueda dada
google_serp_urls = get_google_serp_urls(google_search_query)
# extraer el texto de las respectivas páginas HTML
lista_texto_extraído = extraer_texto_de_urls(google_serp_urls)
# genera el mensaje de IA utilizando el texto extraído como contexto
mensaje_final = get_openai_prompt(request, extracted_text_list)
# interrogar a un modelo OpenAI con el prompt generado
result = interrogar_openai(mensaje_final)
# desplegable con la consulta generada
final_prompt_expander = st.expander("Pregunta final IA:")
final_prompt_expander.write(aviso_final)
# escribe el resultado del modelo OpenAI
st.write(resultado)Ya está. El script Python RAG está listo.
Paso #10: Ponerlo todo junto
Tu archivo app.py debería contener el siguiente código:
from dotenv import carga_dotenv
importar os
importar peticiones
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
import streamlit como st
# cargar las variables de entorno desde el archivo .env
load_dotenv()
# inicializa el cliente API OpenAI con tu clave API
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def get_google_serp_urls(query, number_of_urls=5):
# realiza una petición a la API SERP de Bright Data
# con JSON autoparsing
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
password = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{username}:{password}@{host}:{port}"
Proxies = {"http": proxy_url, "https": proxy_url}
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# recuperar la respuesta JSON analizada
datos_respuesta = respuesta.json()
# extraer un número "number_of_urls" de
# URLs de Google SERP de la respuesta
google_serp_urls = []
if "organic" in datos_respuesta:
for item in datos_respuesta["orgánico"]:
if "link" in item:
google_serp_urls.append(item["link"])
return google_serp_urls[:número_de_urls]
def extraer_texto_de_urls(urls, número_de_palabras=600):
# ordena a una instancia de Chrome sin cabeza que visite las URL proporcionadas
# con el agente de usuario especificado
loader = AsyncChromiumLoader(
urls,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# procesa los documentos HTML extraídos para extraer texto de ellos
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documentos,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# asegúrese de que cada documento de texto HTML contiene sólo un número
# número_de_palabras palabras
lista_texto_extraido = []
for doc_transformado in docs_transformado:
# dividir el texto en palabras y unir el primer número_de_palabras
palabras = doc_transformado.contenido_página.split()[:número_de_palabras]
texto_extraído = " ".join(palabras)
# ignorar documentos de texto vacíos
si len(texto_extraído) != 0:
lista_texto_extraído.append(texto_extraído)
return lista_texto_extraído
def get_openai_prompt(request, text_context=[]):
# prompt por defecto
prompt = petición
# añadir el contexto al prompt, si está presente
if len(texto_contexto) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f "Responda a la solicitud utilizando sólo el contexto que se indica a continuación.nnContexto:n{cadena_de_texto}nnSolicitud: {solicitud}"
return mensaje
def interrogar_openai(prompt, max_tokens=800):
# interroga al modelo OpenAI con el prompt dado
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"rol": "user", "content": prompt}],
max_tokens=max_tokens,
)
return respuesta.opciones[0].mensaje.contenido
# crear un formulario en la aplicación Streamlit para la entrada del usuario
con st.form("prompt_form"):
# inicializar los resultados de salida
resultado = ""
final_prompt = ""
# área de texto para que el usuario introduzca su consulta de búsqueda en Google
google_search_query = st.text_area("Búsqueda Google:", None)
# Área de texto para que el usuario introduzca su consulta de IA
request = st.text_area("Petición IA:", None)
# botón para enviar el formulario
submitted = st.form_submit_button("Enviar")
# si se envía el formulario
si enviado:
# recuperar las URL de Google SERP de la consulta de búsqueda dada
google_serp_urls = get_google_serp_urls(google_search_query)
# extraer el texto de las respectivas páginas HTML
lista_texto_extraído = extraer_texto_de_urls(google_serp_urls)
# genera el mensaje de IA utilizando el texto extraído como contexto
mensaje_final = get_openai_prompt(request, extracted_text_list)
# interrogar a un modelo OpenAI con el prompt generado
result = interrogar_openai(mensaje_final)
# desplegable con la consulta generada
final_prompt_expander = st.expander("Pregunta final IA")
final_prompt_expander.write(aviso_final)
# escribe el resultado del modelo OpenAI
st.write(resultado)¿Te lo puedes creer? En menos de 150 líneas de código, ¡puedes conseguir RAG usando Python!
Paso #11: Prueba la aplicación
Lance su aplicación RAG en Python con
streamlit run app.pyEn la terminal, deberías ver la siguiente salida:
Ahora puedes ver tu aplicación Streamlit en tu navegador.
URL local: http://localhost:8501
URL de red: http://172.27.134.248:8501Siga las instrucciones y visite http://localhost:8501 en el navegador. A continuación se muestra lo que debería ver:

Como puedes observar, el formulario contiene las entradas de texto “Google Search:” y “IA Prompt:” definidas en el código, así como el botón “Send” y el desplegable “IA Final Prompt”.
Pruebe la aplicación utilizando una consulta de búsqueda en Google como se indica a continuación:
Transformers One reviewY una solicitud de IA como la siguiente:
Escribe una reseña de la película Transformers OneHaz clic en “Enviar” y espera a que la aplicación procese la solicitud. Después de unos segundos, deberías obtener un resultado como este:
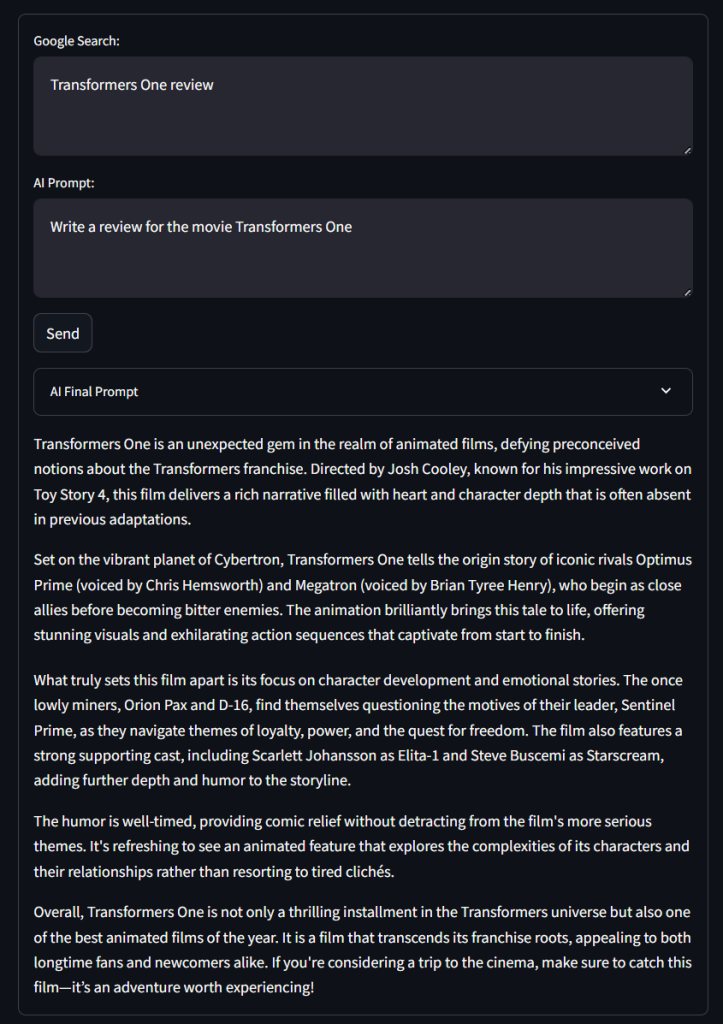
¡Vaya! No está mal la crítica…
Si despliegas el desplegable “Mensaje final de IA”, verás el mensaje completo que utiliza la aplicación para la GAR.
¡Et voilà! Acabas de implementar un chatbot RAG en Python con GPT-4o mini utilizando datos SERP.
Conclusión
En este tutorial, has explorado qué es RAG y cómo se puede lograr alimentando modelos de IA con datos SERP. Específicamente, usted aprendió a construir un chatbot Python RAG que raspa los datos SERP y los utiliza en modelos GPT para mejorar la precisión en los resultados.
El mayor desafío con este enfoque es el raspado de motores de búsqueda como Google, ya que:
- Frecuentemente alteran la estructura de sus páginas SERP.
- Están protegidos por algunas de las medidas anti-bot más sofisticadas que existen.
- La recuperación simultánea de grandes volúmenes de datos SERP es compleja y puede costar mucho dinero.
Como se muestra aquí, la API SERP de Bright Data le ayuda a recuperar datos SERP en tiempo real de los principales motores de búsqueda sin ningún esfuerzo. Es compatible con RAG y muchas otras aplicaciones. Obtenga ahora su prueba gratuita
Regístrese ahora para descubrir cuál de los servicios Proxy o productos de scraping de Bright Data se adapta mejor a sus necesidades. ¡Prueba gratuita!





