

En esta guía, aprenderá:
- Qué es Cloudflare
- Por qué su solución WAF representa un desafío para sus secuencias de comandos de extracción de datos
- Cómo evitar el WAF de Cloudflare utilizando soluciones todo en uno
- Cómo abordar cada una de las principales medidas antibots en las que se basa
¡Vamos a ello!
¿Qué es Cloudflare?
Cloudflare es una empresa de infraestructura y seguridad web que opera una de las redes más grandes de la Web. Ofrece un conjunto completo de servicios diseñados para hacer que los sitios web sean más rápidos y seguros.
En esencia, Cloudflare funciona principalmente como una CDN (red de entrega de contenido), que almacena en caché el contenido del sitio en una red global para mejorar los tiempos de carga y reducir la latencia. Además, ofrece funciones como protección contra ataques DDoS (denegación de servicio distribuida), un WAF (firewall de aplicaciones web), administración de bots, servicios de DNS y más.
Al integrarse con la red de Cloudflare, los sitios pueden obtener rápidamente una mayor seguridad y un rendimiento optimizado. Esto ha convertido a Cloudflare en la solución de referencia para millones de sitios web en todo el mundo.
Cloudflare WAF en pocas palabras
Un WAF, abreviatura de Web Application Firewall, es un sistema de seguridad que filtra y monitorea el tráfico HTTP entre una aplicación web e Internet. Ayuda a proteger los sitios web de ataques como DDoS, secuencias de comandos entre sitios (XSS), inyecciones de SQL y otras actividades maliciosas.
En particular, Cloudflare WAF es una de las soluciones WAF más utilizadas en el mundo. Su popularidad se debe a la adopción generalizada de Cloudflare como CDN. Para los sitios web que ya están en Cloudflare, habilitar el WAF con las configuraciones predeterminadas solo requiere unos pocos clics.
Las principales tecnologías y técnicas antibots implementadas por Cloudflare WAF incluyen:
- Límite de velocidad: limitar la cantidad de solicitudes que puede realizar una sola IP en un período de tiempo determinado para detener los ataques DDoS y evitar los intentos de fuerza bruta.
- Desafíos de JavaScript: Verificar si el visitante puede ejecutar JavaScript, lo cual es un comportamiento típico de los usuarios reales.
- Turnistile CAPTCHA: Presentar pruebas de CAPTCHA a los bots sospechosos.
- Reputación de IP: mantenga una base de datos de reputación para bloquear inmediatamente las direcciones IP sospechosas.
- Análisis del comportamiento: supervisar el comportamiento de los visitantes para detectar patrones automatizados o actividades anormales.
Cuando un sitio está protegido por el WAF de Cloudflare, normalmente emplea una o más soluciones antibots para bloquear las solicitudes automatizadas. La combinación de esas defensas es lo que hace que el rastreo de un sitio protegido por Cloudflare sea particularmente difícil.
Primeras soluciones para evitar los bloqueos de Cloudflare al extraer datos de un sitio
Descubra las mejores soluciones e ideas para una primera aproximación a la extracción de datos web en sitios protegidos por Cloudflare.
Evite Cloudflare por completo
No olvide que Cloudflare actúa como una CDN, lo que significa que almacena en caché y distribuye el contenido del sitio en varios servidores dispersos geográficamente. Por lo tanto, los sitios distribuidos a través de Cloudflare normalmente solo son accesibles a través de servidores de la red CDN.
Ahora, imagine que logra descubrir la dirección IP del servidor del sitio detrás de la CDN. La consecuencia sería que podría interactuar con el sitio sin pasar por completo a Cloudflare. Después de todo, Cloudflare solo puede evaluar las solicitudes que pasan por su red.
Esto es posible consultando herramientas de búsqueda del historial de DNS, como SecurityTrails , para identificar cualquier registro de DNS histórico que revele la dirección IP del servidor original. Una vez que obtenga la IP, puede intentar enviar las solicitudes directamente al servidor, eludiendo Cloudflare.
El problema es que el servidor puede tener configuraciones adicionales para aceptar solicitudes únicamente del rango de IP de Cloudflare. Eso haría casi imposible conectarse directamente al sitio sin estar bloqueado. Además, encontrar correctamente la IP original del servidor es bastante difícil e improbable.
Solucionadores de Cloudflare gratuitos
En Internet, puede encontrar varias bibliotecas gratuitas y de código abierto diseñadas para eludir Cloudflare. Algunas de las más populares son:
- cloudscraper: un módulo de Python que gestiona los desafíos antibots de Cloudflare.
- Cfscrape: un módulo PHP ligero para eludir las páginas antibots de Cloudflare.
- Humanoid: un paquete Node.js para evitar los desafíos de JavaScript antibots de Cloudflare.
Si bien estas soluciones pueden funcionar temporalmente, recuerde que la lucha contra la extracción de datos es un juego del gato y el ratón. Lo que funciona hoy puede no funcionar mañana, ya que Cloudflare actualiza continuamente sus mecanismos de protección.
No es sorprendente que la mayoría de estos proyectos no hayan recibido actualizaciones en años. La razón es que los desarrolladores se dieron por vencidos debido a la continua lucha por mantenerse al día con las actualizaciones de Cloudflare.
Solucionadores premium de Cloudflare
En la mayoría de los casos, la mejor solución para eliminar un sitio protegido por Cloudflare es utilizar un producto premium. El coste garantiza actualizaciones periódicas por parte de expertos en el campo del scraping, lo que mantiene una alta confiabilidad contra las defensas de Cloudflare.
Además de eso, los proveedores de primer nivel, como Bright Data, también ofrecen soporte técnico las 24 horas del día, los 7 días de la semana, para ayudar a resolver cualquier problema. Si está buscando una solución profesional de extracción de datos de Cloudflare, pruebe nuestro navegador de extracción de datos.
Como un navegador con interfaz gráfica de usuario, escalable y basado en la nube, se integra con Playwright, Puppeteer, Selenium y cualquier otra biblioteca de navegador sin interfaz. Para garantizar una alta eficacia contra Cloudflare, incluye funciones como la rotación de IP, la capacidad de resolución de CAPTCHA, la rotación de usuario-agente y más.
Cómo eliminar un sitio protegido contra las erupciones de nube: un enfoque que puede hacer usted mismo para evitar los antibots
Descifrar Cloudflare es difícil, especialmente si no quiere utilizar una solución integral de primera calidad. Si ese es el camino que quiere seguir, debe tener en cuenta todas las defensas de Cloudflare contra los bots y encontrar formas de superarlos.
En esta sección, verá algunas de las técnicas de alto nivel más útiles para eludir Cloudflare y eliminar sitios protegidos por su WAF. Para obtener instrucciones detalladas, consulte nuestra guía sobre cómo evitar Cloudflare.
¡Empecemos!
Renderizado de JavaScript
Una de las técnicas más comunes que usa Cloudflare para detectar bots son los desafíos de JavaScript. Estos son fragmentos de JavaScript integrados en las páginas web que se ejecutan durante el tiempo de renderizado por el navegador Realizan comprobaciones específicas para determinar la probabilidad de que el visitante sea un bot:

Si Cloudflare sospecha que es un bot basándose en el resultado de esos desafíos, le mostrará un CAPTCHA. De lo contrario, podrá acceder al contenido de la página.
Por lo tanto, para segmentar una página protegida por Cloudflare, necesita usar una herramienta de automatización del navegador como Playwright, Selenium o Puppeteer. Estas herramientas le permiten indicar a un navegador que interactúe con las páginas web como los usuarios normales. Obtenga más información en nuestra guía sobre la extracción de datos web de Playwright.
El problema es que los navegadores headless tienen configuraciones predeterminadas que pueden exponerlos a sistemas de detección antibots. Para evitarlo, debería usar bibliotecas como Playwright Stealth o Puppeteer Stealth through Puppeteer Extra, que ayudan a enmascarar la actividad del navegador sin acceso directo.
Resolución de CAPTCHA
Si Cloudflare cree que puede ser un bot, intentará detenerle con un Turnstile CAPTCHA:

Dependiendo de la configuración, el CAPTCHA puede ser una simple prueba basada en clics como la anterior o un rompecabezas más complejo como el siguiente:

Automatizar la resolución de los CAPTCHA es complejo, ya que los CAPTCHA son pruebas diseñadas específicamente para diferenciar entre bots y humanos. Si su navegador virtual se enfrenta a este desafío, puede probar las técnicas descritas en nuestra guía para eludir los CAPTCHAs con Python.
Para una solución más confiable que funcione independientemente de la tecnología que esté utilizando en su secuencia de comandos de extracción de datos, considere el Solucionador de Turnstile de Cloudflare de Bright Data. Esto resuelve rápida y automáticamente los CAPTCHA de Cloudflare Turnstile por usted.
Eliminación de limitaciones de velocidad
Si realiza demasiadas solicitudes desde la misma IP en poco tiempo, es probable que Cloudflare bloquee su IP de forma temporal o incluso permanente. Esto es problemático, ya que detiene la operación de extracción de datos y perjudica la reputación de su IP.
La técnica descrita anteriormente, que se utiliza para detener los ataques DDoS y las solicitudes automatizadas no deseadas, se denomina limitación de velocidad. Como su IP está vinculada a la red a la que está conectado, no puede cambiarla fácilmente. La única forma eficaz de implementar la rotación de IP y evitar las prohibiciones es usar un servicio de proxy.
Con soluciones como los proxies residenciales, puede hacer que las solicitudes de su secuencia de comandos parezcan provenir de dispositivos del mundo real en una ubicación específica. Obtenga más información sobre nuestras ofertas de proxies residenciales..
Falsificación del navegador
Los navegadores, incluso en modo headless, consumen muchos recursos. Por lo tanto, construir una operación de extracción de datos en torno a un sitio web protegido por Cloudflare utilizando una herramienta de automatización de navegadores puede resultar en un proceso que consume muchos recursos. Esto puede requerir varios servidores y una arquitectura compleja.
Para evitar esa molestia, y en los casos en los que el WAF de Cloudflare se haya configurado para que no sea demasiado agresivo, puede probar un enfoque diferente. La idea es realizar solicitudes automatizadas desde clientes HTTP que imiten a los navegadores reales, lo que se conoce como suplantación de navegador.
El objetivo es que tus solicitudes HTTP se parezcan lo más posible a las de un navegador normal. Puede lograr el resultado configurando encabezados HTTP específicos, como User-Agent. Para obtener más información, consulte nuestra guía sobre el mejor User-Agent para la extracción de datos web.
En escenarios más complejos, ese truco por sí solo puede no ser suficiente. Cloudflare aún puede detectar que sus solicitudes provienen de un cliente HTTP y no de un navegador debido a la huella digital TLS:
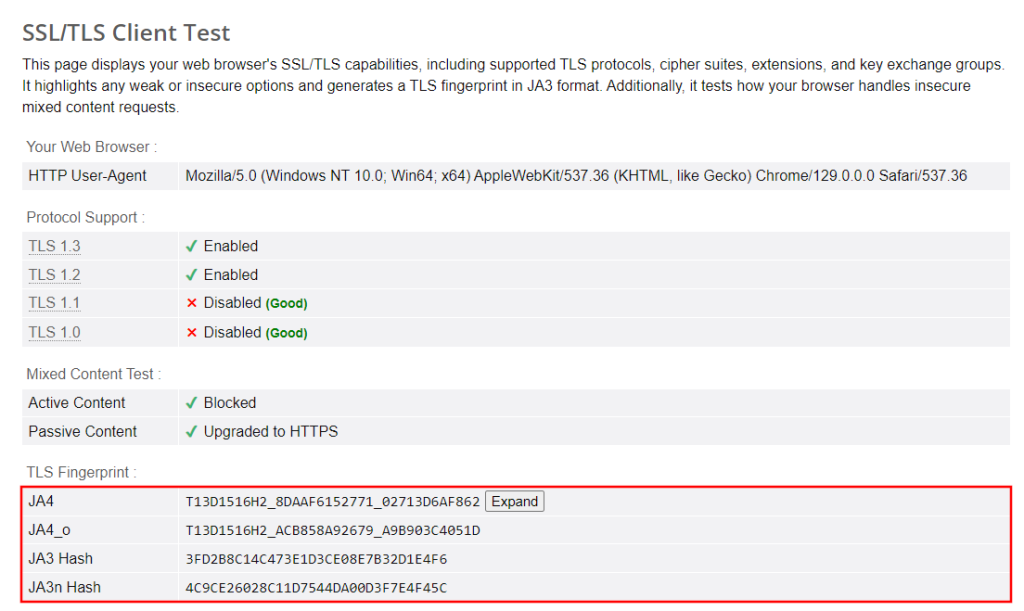
Si no está familiarizado con ese concepto, la toma de huellas digitales TLS implica identificar a un cliente en función de la forma en que establece conexiones seguras a través de TLS. Para replicar la huella digital TLS de un navegador, puede usar un cliente HTTP como curl-impersonate, como se explica en nuestro tutorial dedicado.
Conclusión
En este artículo, ha visto varios consejos y trucos para eliminar sitios protegidos por Cloudflare. Cloudflare es el servicio de CDN más popular del mercado y también ofrece soluciones antibots avanzadas. Como hemos aprendido aquí, eludir las medidas contra la extracción de datos de Cloudflare es un desafío, pero no imposible.
Independientemente del enfoque que elija, recuerde que todo es más fácil con soluciones de extracción de datos profesionales, rápidas y confiables, como:
- Web Unlocker: eluda de forma autónoma la limitación de velocidad, la toma de huellas dactilares y otras restricciones antibots, lo que permite recopilar datos web públicos sin problemas.
- CAPTCHA Solver: resuelve automáticamente varios tipos de CAPTCHA, lo que le permite acceder al contenido de cualquier página web o completar interacciones sin intervención manual.
- Scraping Browser: un navegador completamente hospedado que te permite extraer datos web dinámicos y, al mismo tiempo, automatizar el proceso de desbloqueo de sitios web.
Con el amplio conjunto de herramientas de extracción de datos de Bright Data, ¡extraer datos de sitios protegidos por Cloudflare nunca ha sido tan fácil!
Regístrese ahora para averiguar cuál de las soluciones de Bright Data se adapta mejor a sus necesidades. ¡Empiece ya con una prueba gratuita!





