

En este tutorial aprenderás:
- Qué es Crawl4AI y qué ofrece para el web scraping
- Los escenarios ideales para utilizar Crawl4AI con un LLM como DeepSeek
- Cómo construir un rascador Crawl4AI alimentado por DeepSeek en una sección guiada.
Sumerjámonos.
¿Qué es Craw4AI?
Crawl4AI es un rastreador y raspador web de código abierto preparado para la IA y diseñado para una integración perfecta con grandes modelos lingüísticos (LLM), agentes de IA y canalizaciones de datos. Ofrece una extracción de datos de alta velocidad y en tiempo real, a la vez que es flexible y fácil de implementar.
Las características que ofrece para AI web scraping son:
- Construido para LLMs: Genera Markdown estructurado optimizado para la generación aumentada por recuperación (RAG) y el ajuste fino.
- Control flexible del navegador: Admite gestión de sesiones, proxies y ganchos personalizados.
- Inteligencia heurística: Utiliza algoritmos inteligentes para optimizar el análisis sintáctico de los datos.
- Totalmente de código abierto: Sin necesidad de claves API; desplegable a través de Docker y plataformas en la nube.
Más información en la documentación oficial.
Cuándo utilizar Crawl4AI y DeepSeek para el Web Scraping
DeepSeek ofrece potentes modelos LLM gratuitos y de código abierto que han causado sensación en la comunidad de IA por su eficiencia y eficacia. Además, estos modelos se integran sin problemas con Crawl4AI.
Aprovechando DeepSeek en Crawl4AI, puede extraer datos estructurados incluso de las páginas web más complejas e incoherentes. Todo ello sin necesidad de una lógica de análisis predefinida.
A continuación se presentan escenarios clave en los que la combinación DeepSeek + Crawl4AI resulta especialmente útil:
- Cambios frecuentes en la estructura del sitio: Los raspadores tradicionales se estropean cuando los sitios web actualizan su estructura HTML, pero AI se adapta dinámicamente.
- Diseños de página incoherentes: Plataformas como Amazon tienen diferentes diseños de páginas de productos. Un LLM puede extraer datos de forma inteligente independientemente de las diferencias de diseño.
- Análisis de contenidos no estructurados: Extraer información de reseñas de texto libre, entradas de blog o discusiones en foros resulta sencillo con el procesamiento basado en LLM.
Web Scraping Con Craw4AI y DeepSeek: Guía paso a paso
En este tutorial guiado, aprenderás a construir un raspador web potenciado por IA usando Crawl4AI. Como motor LLM, utilizaremos DeepSeek.
En concreto, verá cómo crear un AI scraper para extraer datos de la página G2 para Bright Data:
Siga los pasos que se indican a continuación y aprenda a realizar web scraping con Crawl4AI y DeepSeek.
Requisitos previos
Para seguir este tutorial, asegúrese de que cumple los siguientes requisitos previos:
- Python 3+ instalado en su máquina
- Una cuenta GroqCloud
- Una cuenta de Bright Data
No se preocupe si todavía no tiene una cuenta GroqCloud o Bright Data. Se le guiará a través de su configuración durante los siguientes pasos.
Paso nº 1: Configuración del proyecto
Ejecute el siguiente comando para crear una carpeta para su proyecto de raspado Crawl4AI DeepSeek:
mkdir crawl4ai-deepseek-scraperNavega hasta la carpeta del proyecto y crea un entorno virtual:
cd crawl4ai-deepseek-scraper
python -m venv venvAhora, carga la carpeta crawl4ai-deepseek-scraper en tu IDE de Python favorito. Visual Studio Code con la extensión Python o PyCharm Community Edition son dos grandes opciones.
Dentro de la carpeta del proyecto, crear:
scraper.py: El archivo que contendrá la lógica de raspado impulsada por IA.models/: Un directorio para almacenar modelos de datos LLM Crawl4AI basados en Pydantic..env: Un archivo para almacenar variables de entorno de forma segura.
Después de crear estos archivos y carpetas, la estructura de tu proyecto debería tener este aspecto:

A continuación, active el entorno virtual en el terminal de su IDE.
En Linux o macOS, ejecute este comando:
./env/bin/activateDe forma equivalente, en Windows, ejecute:
env/Scripts/activateMuy bien. Ahora tiene un entorno Python para Crawl4AI web scraping con DeepSeek.
Paso #2: Instalar Craw4AI
Con su entorno virtual activado, instale Crawl4AI a través del paquete pip crawl4ai:
pip install crawl4aiTenga en cuenta que la biblioteca tiene varias dependencias, por lo que la instalación puede tardar un poco.
Una vez instalado, ejecute el siguiente comando en su terminal:
crawl4ai-setupEl proceso:
- Instala o actualiza los navegadores Playwright necesarios (Chromium, Firefox, etc.).
- Realiza comprobaciones a nivel de sistema operativo (por ejemplo, se asegura de que las bibliotecas del sistema necesarias están instaladas en Linux).
- Confirma que su entorno está correctamente configurado para el rastreo web.
Después de ejecutar el comando, debería ver una salida similar a esta:
[INIT].... → Running post-installation setup...
[INIT].... → Installing Playwright browsers...
[COMPLETE] ● Playwright installation completed successfully.
[INIT].... → Starting database initialization...
[COMPLETE] ● Database backup created at: C:Usersantoz.crawl4aicrawl4ai.db.backup_20260219_092341
[INIT].... → Starting database migration...
[COMPLETE] ● Migration completed. 0 records processed.
[COMPLETE] ● Database initialization completed successfully.
[COMPLETE] ● Post-installation setup completed!¡Increíble! Crawl4AI ya está instalado y listo para usar.
Paso #4: Inicializar scraper.py
Dado que Crawl4AI requiere código asíncrono, empieza por crear un script asíncrono básico:
import asyncio
async def main():
# Scraping logic...
if __name__ == "__main__":
asyncio.run(main())Ahora, recuerda que el proyecto implica integraciones con servicios de terceros como DeepSeek. Para implementarlo, necesitarás contar con claves API y otros secretos. Los almacenaremos en un archivo .env.
Instale python-dotenv para cargar variables de entorno:
pip install python-dotenvAntes de definir main(), cargue las variables de entorno desde el archivo .env con load_dotenv():
load_dotenv()Importar load_dotenv de la biblioteca python-dotenv:
from dotenv import load_dotenvPerfecto! scraper.py está listo para alojar alguna lógica de raspado potenciada por IA.
Paso 5: Cree su primer AI Scraper
Dentro de la función main() en scraper.py, añade la siguiente lógica usando un crawler Crawl4AI básico:
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")En el fragmento anterior, los puntos clave son:
BrowserConfig: Controla cómo se lanza y se comporta el navegador, incluyendo ajustes como el modo headless y agentes de usuario personalizados para web scraping.CrawlerRunConfig: Define el comportamiento de rastreo, como la estrategia de almacenamiento en caché, las reglas de selección de datos, los tiempos de espera, etc.headless=True: Configura el navegador para que se ejecute en modo headless -sinla GUI- para ahorrar recursos.CacheMode.BYPASS: Esta configuración garantiza que el rastreador obtiene el contenido fresco directamente del sitio web en lugar de basarse en los datos almacenados en caché.crawler.arun(): Este método lanza el crawler asíncrono para extraer datos de la URL especificada.resultado.markdown: El contenido extraído se convierte a formato Markdown, lo que facilita su análisis.
No olvides añadir las siguientes importaciones:
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheModeEn este momento, scraper.py debe contener:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
# Load secrets from .env file
load_dotenv()
async def main():
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")
if __name__ == "__main__":
asyncio.run(main())Si ejecuta el script, debería ver una salida como la siguiente:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 0.83s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 1ms
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 0.83s
Parsed Markdown data:Esto es sospechoso, ya que el contenido Markdown analizado está vacío. Para investigar más a fondo, imprime el estado de la respuesta:
print(f"Response status code: {result.status_code}")Esta vez, la salida incluirá:
Response status code: 403El resultado analizado en Markdown está vacío porque la solicitud de Crawl4AI fue bloqueada por los sistemas de detección de bots de G2. Esto queda claro por el código de estado 403 Forbidden devuelto por el servidor.
No es de extrañar, ya que G2 cuenta con estrictas medidas anti-bot. En particular, a menudo muestra CAPTCHAs, incluso cuando se accede a través de un navegador normal:

En este caso, como no se recibió ningún contenido válido, Crawl4AI no pudo convertirlo a Markdown. En el siguiente paso, exploraremos cómo evitar esta restricción. Para más información, echa un vistazo a nuestra guía sobre cómo evitar CAPTCHAs en Python.
Paso 6: Configurar Web Unlocker API
Crawl4AI es una potente herramienta con mecanismos integrados para evitar bots. Sin embargo, no puede eludir sitios web altamente protegidos como G2, que emplean estrictas medidas anti-bot y anti-scraping.
Contra este tipo de sitios, la mejor solución es utilizar una herramienta dedicada diseñada para desbloquear cualquier página web, independientemente de su nivel de protección. El producto de raspado ideal para esta tarea es Web Unlocker de Bright Data, una API de raspado que:
- Simula el comportamiento real de los usuarios para eludir la detección de robots.
- Gestión de proxy y resolución automática de CAPTCHA
- Escala sin problemas sin necesidad de gestionar la infraestructura
Siga las siguientes instrucciones para integrar Web Unlocker API en su raspador Crawl4AI DeepSeek.
Alternativamente, eche un vistazo a la documentación oficial.
En primer lugar, acceda a su cuenta de Bright Data o cree una si aún no lo ha hecho. Financie su cuenta o aproveche la prueba gratuita disponible para todos los productos.
A continuación, vaya a “Proxies & Scraping” en el panel de control y seleccione la opción “unblocker” en la tabla:
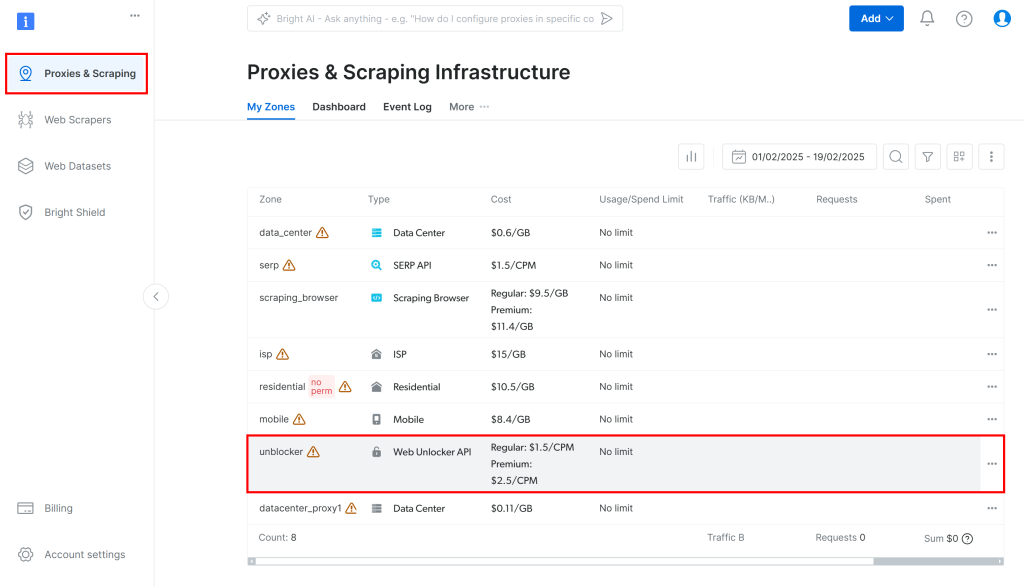
Esto le llevará a la página de configuración de Web Unlocker API que se muestra a continuación:
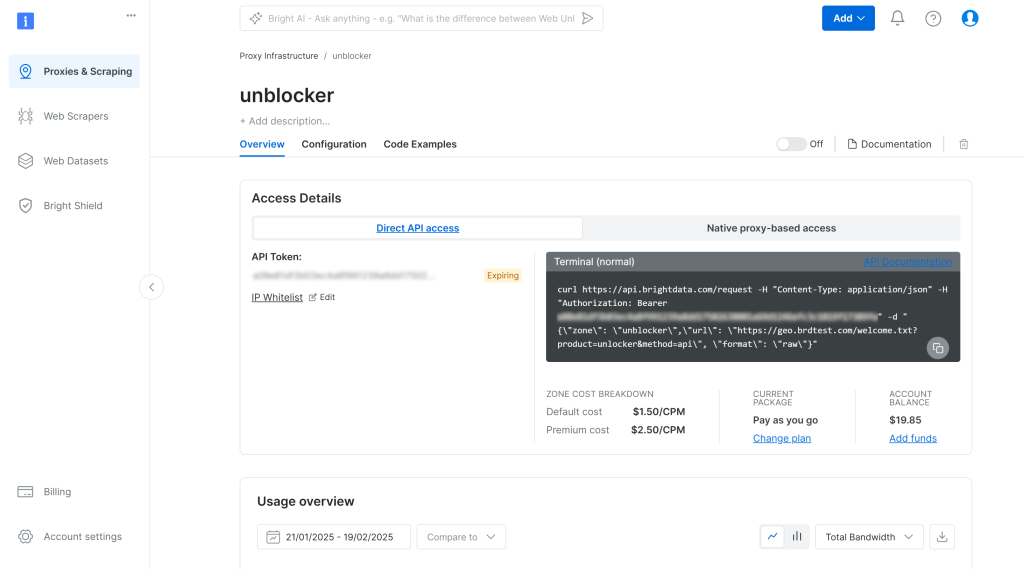
Aquí, habilite Web Unlocker API haciendo clic en el conmutador:

G2 está protegido por defensas anti-bot avanzadas, incluyendo CAPTCHAs. Por lo tanto, compruebe que los dos interruptores siguientes están activados en la página “Configuración”:
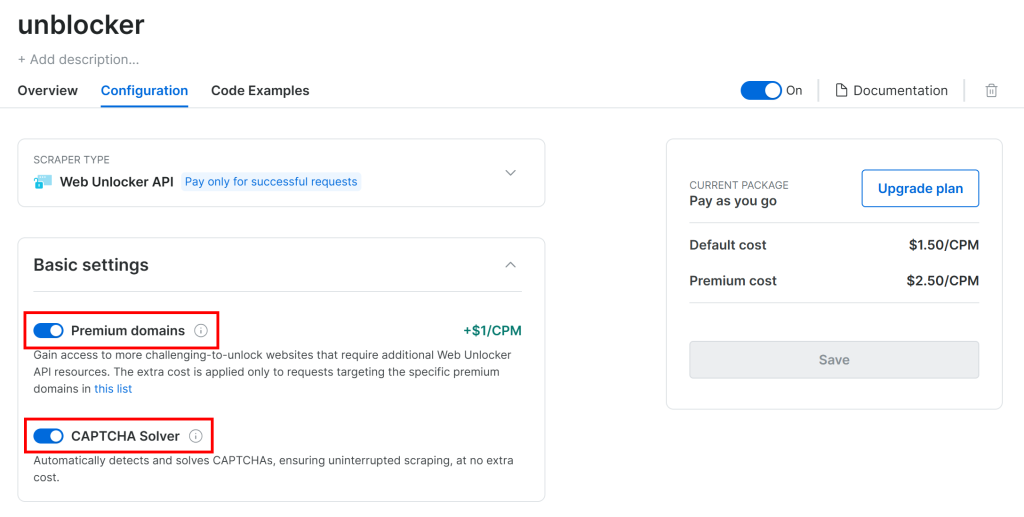
Crawl4AI funciona navegando por páginas en un navegador controlado. Bajo el capó, se basa en la función goto() de Playwright, que envía una solicitud HTTP GET a la página web de destino. En cambio, Web Unlocker API funciona mediante peticiones POST.
Eso no es un problema, ya que puede seguir utilizando Web Unlocker API con Crawl4AI configurándolo como proxy. Esto permite al navegador de Crawl4AI enviar peticiones a través del producto de Bright Data, recibiendo de vuelta páginas HTML desbloqueadas.
Para acceder a sus credenciales de proxy de la API de Web Unlocker, vaya a la pestaña “Acceso nativo basado en proxy” de la página “Visión general”:
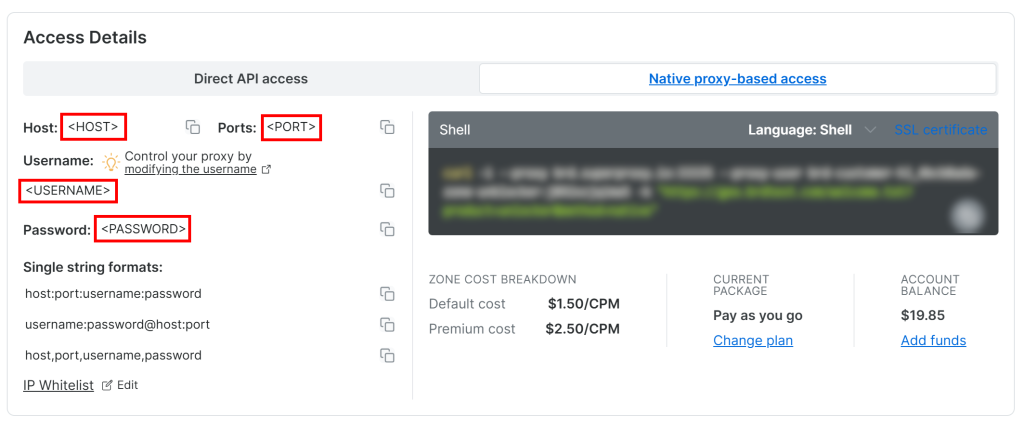
Copie las siguientes credenciales de la página:
<HOST><PUERTO><NOMBRE DE USUARIO><CONTRASEÑA>
A continuación, utilícelas para rellenar su archivo .env con estas variables de entorno:
PROXY_SERVER=https://<HOST>:<PORT>
PROXY_USERNAME=<USERNAME>
PROXY_PASSWORD=<PASSWORD>¡Fantástico! Web Unlocker ya está listo para integrarse con Crawl4AI.
Paso #7: Integrar Web Unlocker API
BrowserConfig soporta integración proxy a través del objeto proxy_config. Para integrar Web Unlocker API con Crawl4AI, rellene ese objeto con las variables de entorno de su archivo .env y páselo al constructor de BrowserConfig:
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)Recuerda importar os de la biblioteca estándar de Python:
import osTenga en cuenta que Web Unlocker API introduce cierta sobrecarga de tiempo debido a la rotación de IP a través del proxy y la eventual resolución de CAPTCHA. Para tenerlo en cuenta, deberías:
- Aumentar el tiempo de espera de carga de la página a 3 minutos
- Indica al rastreador que espere a que el DOM esté completamente cargado antes de analizarlo.
Consígalo con la siguiente configuración de CrawlerRunConfig:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded", # wait until the DOM of the page has been loaded
page_timeout=180000, # wait up to 3 mins for page load
)Tenga en cuenta que incluso Web Unlocker API no es impecable cuando se trata de sitios complejos como G2. En raras ocasiones, la API de raspado puede fallar a la hora de recuperar la página desbloqueada, provocando que el script termine con el siguiente error:
Error: Failed on navigating ACS-GOTO:
Page.goto: net::ERR_HTTP_RESPONSE_CODE_FAILURE at https://www.g2.com/products/bright-data/reviewsTenga la seguridad de que sólo se le cobrará por las solicitudes realizadas con éxito. Por lo tanto, no hay necesidad de preocuparse por relanzar el script hasta que funcione. En un script de producción, considere implementar una lógica de reintento automático.
Cuando la solicitud tenga éxito, recibirá una salida como ésta:
Response status code: 200
Parsed Markdown data:
* [Home](https://www.g2.com/products/bright-data/</>)
* [Write a Review](https://www.g2.com/products/bright-data/</wizard/new-review>)
* Browse
* [Top Categories](https://www.g2.com/products/bright-data/<#>)
Top Categories
* [AI Chatbots Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/ai-chatbots>)
* [CRM Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/crm>)
* [Project Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/project-management>)
* [Expense Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/expense-management>)
* [Video Conferencing Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/video-conferencing>)
* [Online Backup Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/online-backup>)
* [E-Commerce Platforms](https://www.g2.com/products/brig¡Estupendo! Esta vez, G2 respondió con un código de estado 200 OK. Esto significa que la solicitud no se ha bloqueado y que Crawl4AI ha podido convertir el HTML en Markdown tal y como estaba previsto.
Paso 8: Configuración de Groq
GroqCloud es uno de los pocos proveedores que admite modelos de IA DeepSeek a través de API compatibles con OpenAI, incluso en un plan gratuito. Por lo tanto, será la plataforma utilizada para la integración de LLM en Crawl4AI.
Si aún no tiene una cuenta Groq, cree una. De lo contrario, sólo tiene que iniciar sesión. En su panel de usuario, vaya a “Claves API” en el menú de la izquierda y haga clic en el botón “Crear clave API”:
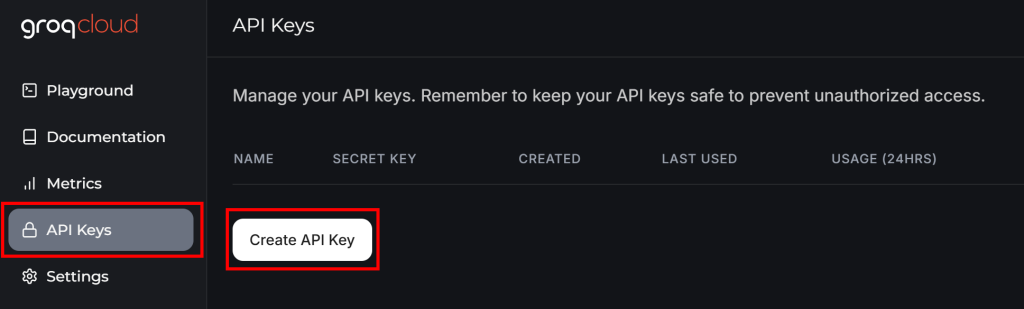
Aparecerá una ventana emergente:
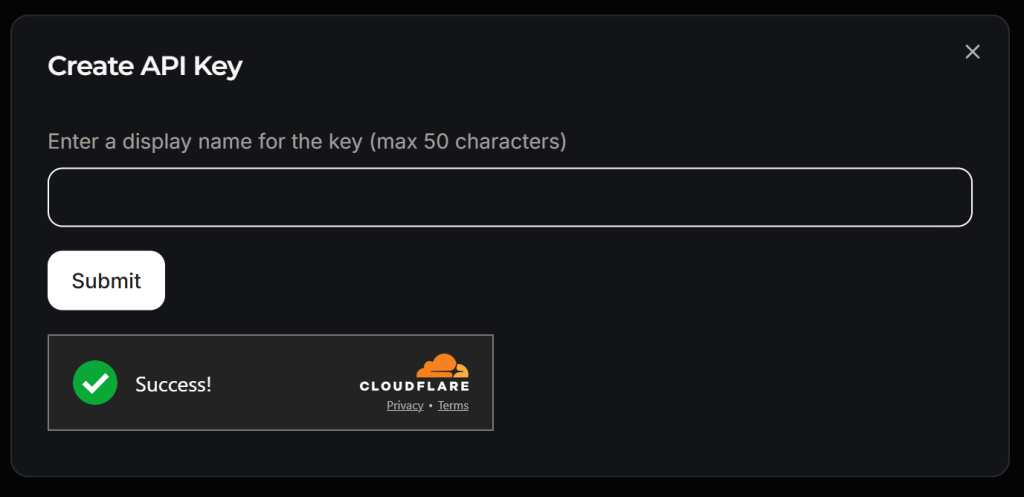
Dale un nombre a tu clave API (por ejemplo, “Crawl4AI Scraping”) y espera a la verificación anti-bot por parte de Cloudflare. A continuación, haz clic en “Enviar” para generar tu clave API:
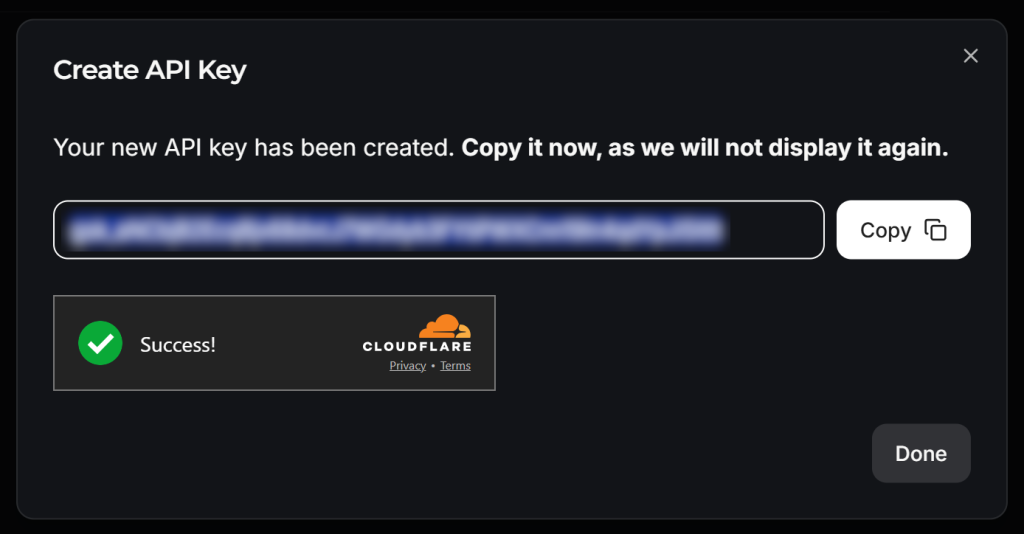
Copie la clave API y añádala a su archivo .env como se indica a continuación:
LLM_API_TOKEN=<YOUR_GROK_API_KEY>Sustituya por la clave API real proporcionada por Groq.
¡Precioso! Usted está listo para usar DeepSeek para LLM raspado con Crawl4AI.
Paso 9: Defina un esquema para sus datos raspados
Crawl4AI realiza el raspado LLM siguiendo un enfoque basado en esquemas. En este contexto, un esquema es una estructura de datos JSON que define:
- Un selector base que identifica el elemento “contenedor” de la página (por ejemplo, una fila de productos, una tarjeta de entrada de blog).
- Campos que especifican los selectores CSS/XPath para capturar cada dato (por ejemplo, texto, atributo, bloque HTML).
- Tipos anidados o de lista para estructuras repetidas o jerárquicas.
Para definir el esquema, primero debe identificar los datos que desea extraer de la página de destino. Para ello, abre la página de destino en modo incógnito en tu navegador:
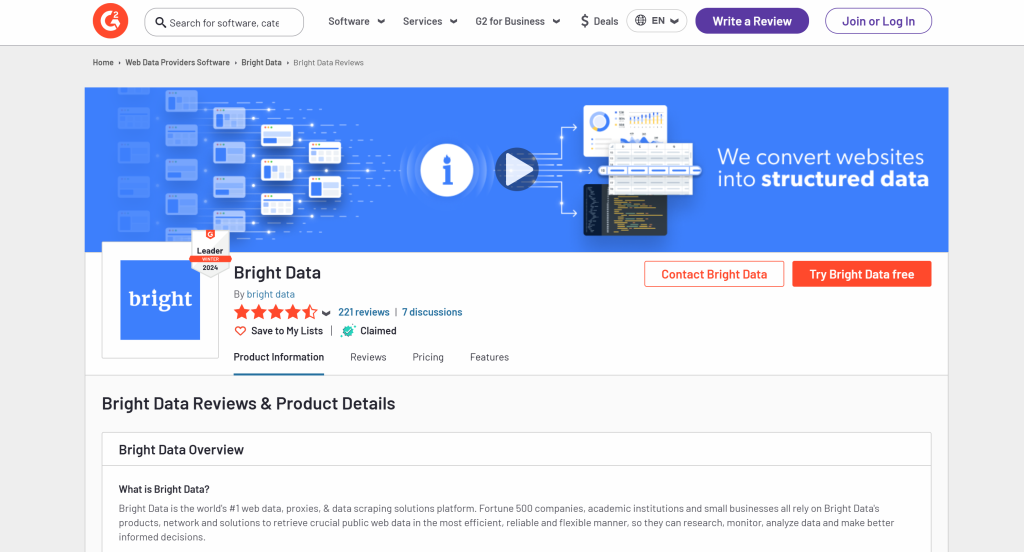
En este caso, supongamos que le interesan los siguientes campos:
nombre: El nombre del producto/empresa.URL_imagen: La URL de la imagen del producto/empresa.Descripción: Una breve descripción del producto/empresa.puntuación_opinión: La puntuación media de las reseñas del producto/empresa.número_de_reseñas: El número total de reseñas.reclamado: Un booleano que indica si el perfil de la empresa está reclamado por el propietario.
Ahora, en la carpeta models, crea un archivo g2_product.py y rellénalo con una clase de esquema basada en Pydantic llamada G2Product de la siguiente manera:
# ./models/g2_product.py
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolSí. El proceso de raspado LLM realizado por DeepSeek devolverá objetos que siguen el esquema anterior.
Paso nº 10: Prepararse para integrar DeepSeek
Antes de completar la integración de DeepSeek con Crawl4AI, revise la página “Configuración > Límites” en su cuenta GroqCloud:
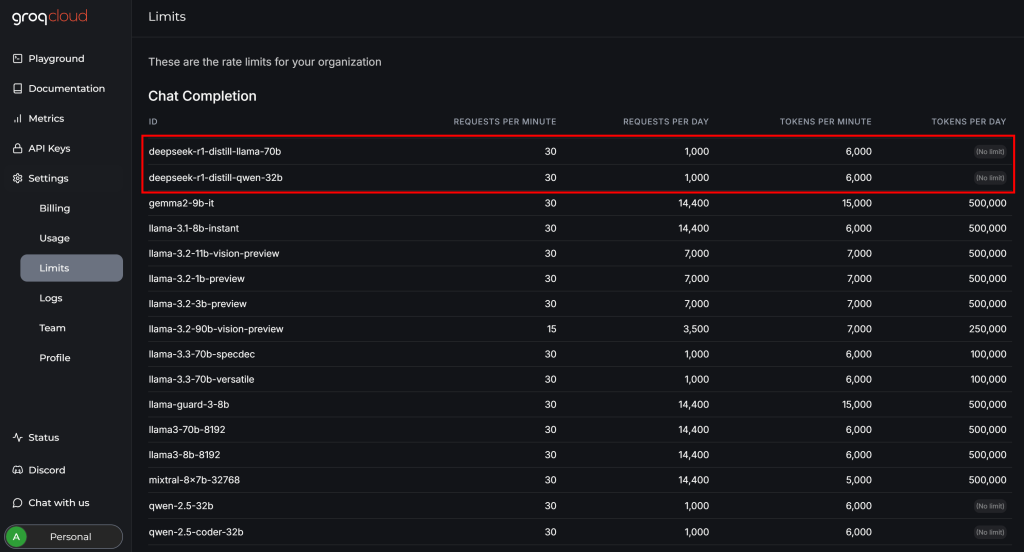
Allí podrá ver que los dos modelos de DeepSeek disponibles tienen las siguientes limitaciones en el plan gratuito:
- Hasta 30 solicitudes por minuto
- Hasta 1.000 solicitudes al día
- No más de 6.000 fichas por minuto
Mientras que las dos primeras restricciones no suponen un problema para este ejemplo, la última presenta un desafío. Una página web típica puede contener millones de caracteres, lo que se traduce en cientos de miles de tokens.
En otras palabras, no se puede introducir toda la página G2 directamente en los modelos DeepSeek a través de Groq debido a los límites de tokens. Para solucionar este problema, Crawl4AI le permite seleccionar sólo secciones específicas de la página. Esas secciones -y no toda la página- se convertirán a Markdown y se pasarán al LLM. El proceso de selección de secciones se basa en selectores CSS.
Para determinar las secciones que debe seleccionar, abra la página de destino en su navegador. Haga clic con el botón derecho del ratón en los elementos que contienen los datos de interés y seleccione la opción “Inspeccionar”:
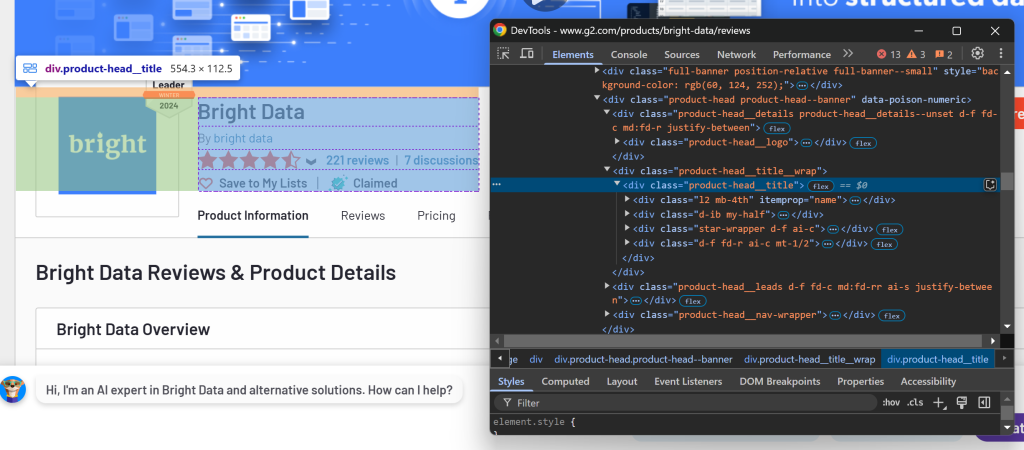
Aquí puede observar que el elemento .product-head__title contiene el nombre del producto/empresa, la puntuación de la reseña, el número de reseñas y el estado reclamado.
Ahora, inspeccione la sección del logotipo:
Puede recuperar esa información utilizando el selector CSS .product-head__logo.
Por último, inspeccione la sección de descripción:
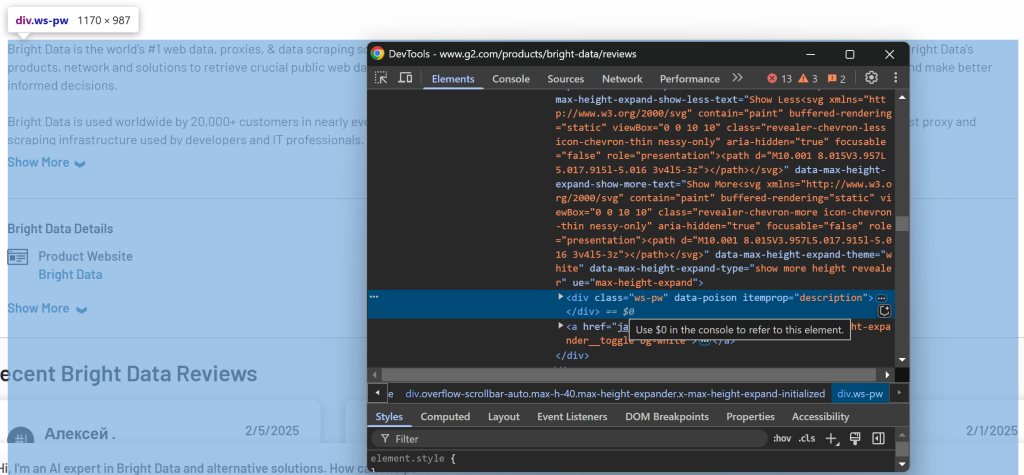
La descripción está disponible mediante el selector [itemprop="description"].
Configure estos selectores CSS en CrawlerRunConfig como sigue:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000,
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]", # the CSS selectors of the elements to extract data from
)Si ejecutas scraper.py de nuevo, ahora obtendrás algo como:
Response status code: 200
Parsed Markdown data:
[](https:/www.g2.com/products/bright-data/reviews)
[Editedit](https:/my.g2.com/bright-data/product_information)
[Bright Data](https:/www.g2.com/products/bright-data/reviews)
By [bright data](https:/www.g2.com/sellers/bright-data)
Show rating breakdown
4.7 out of 5 stars
[5 star78%](https:/www.g2.com/products/bright-data/reviews?filters%5Bnps_score%5D%5B%5D=5#reviews)
[4 star19%](https:/www.g2.cLa salida sólo incluye las secciones relevantes en lugar de toda la página HTML. Este enfoque reduce significativamente el uso de tokens, lo que le permite mantenerse dentro de los límites de Groq y extraer eficazmente los datos de interés.
Paso nº 11: Definir la estrategia de extracción LLM basada en DeepSeek
Craw4AI soporta la extracción de datos basada en LLM a través del objeto LLMExtractionStrategy. Puede definir una para la integración con DeepSeek como se indica a continuación:
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)Para especificar el modelo LLM, añada la siguiente variable de entorno a .env:
LLM_MODEL=groq/deepseek-r1-distill-llama-70bEsto indica a Craw4AI que utilice el modelo deepseek-r1-distill-llama-70b de GroqCloud para la extracción de datos basada en LLM.
En scraper.py, importa LLMExtractionStrategy y G2Product:
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2ProductA continuación, pase el objeto extraction_strategy a crawler_config:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)Cuando ejecutes el script, Craw4AI lo hará:
- Conéctese a la página web de destino a través del proxy API de Web Unlocker.
- Recupera el contenido HTML de la página y filtra los elementos utilizando los selectores CSS especificados.
- Convierte los elementos HTML seleccionados a formato Markdown.
- Envíe el Markdown formateado a DeepSeek para la extracción de datos.
- Indique a DeepSeek que procese la entrada de acuerdo con la
instrucciónproporcionada y devuelva los datos extraídos.
Después de ejecutar crawler.arun(), puedes comprobar el uso de tokens con:
print(extraction_strategy.show_usage())A continuación, puede acceder a los datos extraídos e imprimirlos con:
result_raw_data = result.extracted_content
print(result_raw_data)Si ejecutas el script e imprimes los resultados, deberías ver una salida como esta:
=== Token Usage Summary ===
Type Count
------------------------------
Completion 525
Prompt 2,002
Total 2,527
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 525 2,002 2,527
None
[
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c07c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}
]La primera parte de la salida (uso de tokens) proviene de show_usage(), confirmando que estamos muy por debajo del límite de 6.000 tokens. Los siguientes datos resultantes son una cadena JSON que coincide con el esquema G2Product.
¡Simplemente increíble!
Paso nº 12: Manejar los datos de los resultados
Como se puede ver en la salida del paso anterior, DeepSeek devuelve normalmente una matriz en lugar de un único objeto. Para ello, analice los datos devueltos como JSON y extraiga el primer elemento de la matriz:
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]Recuerda importar json de la biblioteca estándar de Python:
import jsonEn este punto, result_data debería ser una instancia de G2Product. El último paso es exportar estos datos a un archivo JSON.
Paso #13: Exportar los datos raspados a JSON
Utilice json para exportar result_data a un archivo g2.json:
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)Misión cumplida.
Paso nº 14: Ponerlo todo junto
Su archivo scraper.py final debe contener:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
import os
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2Product
import json
# Load secrets from .env file
load_dotenv()
async def main():
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)
# LLM extraction strategy for data extraction using DeepSeek
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# Log the AI model usage info
print(extraction_strategy.show_usage())
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]
# Export the scraped data to JSON
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)
if __name__ == "__main__":
asyncio.run(main())Entonces, models/g2_product.py almacenará:
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolY .env tendrá:
PROXY_SERVER=https://<WEB_UNLOCKER_API_HOST>:<WEB_UNLOCKER_API_PORT>
PROXY_USERNAME=<WEB_UNLOCKER_API_USERNAME>
PROXY_PASSWORD=<WEB_UNLOCKER_API_PASSWORD>
LLM_API_TOKEN=<GROQ_API_KEY>
LLM_MODEL=groq/deepseek-r1-distill-llama-70bInicie su raspador DeepSeek Crawl4AI con:
python scraper.pyLa salida en el terminal será algo como esto:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 56.13s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 397ms
[LOG] Call LLM for https://www.g2.com/products/bright-data/reviews - block index: 0
[LOG] Extracted 1 blocks from URL: https://www.g2.com/products/bright-data/reviews block index: 0
[EXTRACT]. ■ Completed for https://www.g2.com/products/bright-data/reviews... | Time: 12.273853100006818s
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 68.81s
=== Token Usage Summary ===
Type Count
------------------------------
Completion 524
Prompt 2,002
Total 2,526
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 524 2,002 2,526
NoneAdemás, aparecerá un archivo g2.json en la carpeta de tu proyecto. Ábrelo y verás:
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c7c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}Enhorabuena. Empezaste con una página G2 protegida por bots y utilizaste Crawl4AI, DeepSeek y Web Unlocker API para extraer datos estructurados de ella, sin escribir una sola línea de lógica de análisis.
Conclusión
En este tutorial, usted exploró qué es Crawl4AI y cómo usarlo en combinación con DeepSeek para construir un scraper potenciado por IA. Uno de los mayores retos a la hora de hacer scraping es el riesgo de ser bloqueado, pero esto se superó con la API Web Unlocker de Bright Data.
Como se demuestra en este tutorial, con la combinación de Crawl4AI, DeepSeek y la API Web Unlocker, puede extraer datos de cualquier sitio -incluso de los más protegidos, como G2- sin necesidad de una lógica de análisis específica. Este es sólo uno de los muchos escenarios soportados por los productos y servicios de Bright Data, que le ayudan a implementar un raspado web eficaz basado en IA.
Explore nuestras otras herramientas de raspado web que se integran con Crawl4AI:
- Servicios de proxy: 4 tipos diferentes de proxies para eludir las restricciones de ubicación, incluidos más de 400M+ monthly de IP residenciales.
- API de Web Scraper: Puntos finales dedicados para extraer datos web frescos y estructurados de más de 100 dominios populares.
- API SERP: API para manejar toda la gestión de desbloqueo en curso para SERP y extraer una página.
- Navegador de raspado: Navegador compatible con Puppeteer, Selenium y Playwright con actividades de desbloqueo integradas.
Regístrese ahora en Bright Data y pruebe gratis nuestros servicios proxy y productos de scraping.





