
En este tutorial, aprenderá
- Qué es Kiro y sus capacidades técnicas.
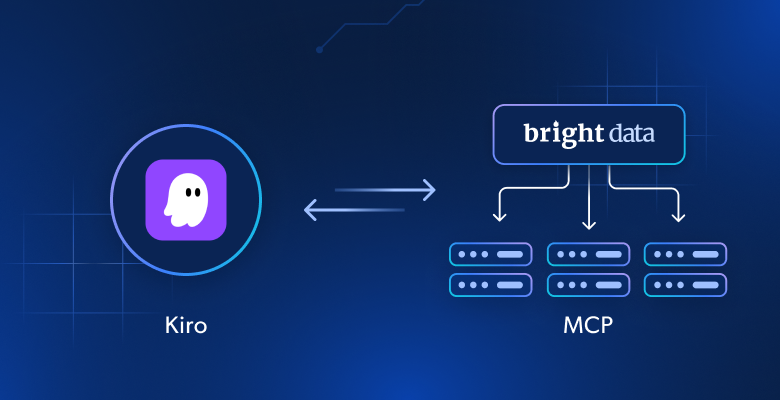
- Cómo la conexión de Kiro con los servidores Web MCP de Bright Data lo transforma de un generador de código estático en un agente dinámico que puede obtener datos en tiempo real, eludir las protecciones anti-bot y generar resultados estructurados.
- Cómo utilizar Kiro para automatizar todo el proceso de obtención de datos del mercado laboral en tiempo real, organizarlos en archivos CSV, generar secuencias de comandos de análisis y elaborar informes detallados.
Visita el proyecto en GitHub.
Y ahora, ¡manos a la obra!
¿Qué es Kiro?
Kiro es un IDE basado en IA que cambia la forma de trabajar de los desarrolladores mediante el uso del desarrollo basado en especificaciones y procesos automatizados. A diferencia de las herramientas de codificación de IA habituales, que se limitan a generar código, Kiro trabaja por su cuenta, comprobando bases de código, modificando varios archivos y creando funciones completas de principio a fin.
Capacidades técnicas clave:
- Flujo de trabajo basado en especificaciones: Kiro convierte las peticiones en requisitos claros, diseños técnicos y tareas, lo que elimina la “codificación vibrante”.
- Ganchos de agente: Tareas automatizadas en segundo plano que gestionan las actualizaciones de documentación, las pruebas y las comprobaciones de calidad del código.
- Integración de MCP: La compatibilidad integrada con el Protocolo de Contexto de Modelos permite establecer vínculos directos con herramientas, bases de datos y API externas.
- Autonomía agéntica: Lleva a cabo tareas de desarrollo de varios pasos utilizando un razonamiento centrado en objetivos.
Construido sobre la base de VS Code con los modelos Claude de Anthropic, Kiro mantiene los flujos de trabajo familiares a la vez que añade una sólida estructura para un desarrollo listo para usar.
¿Por qué ampliar Kiro con servidores MCP de Bright Data?
El razonamiento agéntico de Kiro es sólido, pero sus LLM dependen de datos de entrenamiento antiguos. Al conectar Kiro al servidor Web MCP de Bright Data, estos modelos “congelados” se convierten en agentes de datos en tiempo real. Pueden acceder a contenido web en tiempo real, evitar las defensas anti-bot y proporcionar resultados estructurados directamente en el flujo de trabajo de Kiro.
| Herramienta MCP | Utilice |
|---|---|
motor_de_busqueda |
Recupere resultados SERP recientes de Google/Bing/Yandex para una investigación instantánea de la competencia o las tendencias. |
scrape_as_markdown |
Scrape de una página que devuelve Markdown legible, perfecto para documentos/ejemplos rápidos |
scrape_batch |
Raspado paralelo de varias URL; ideal para el seguimiento de precios o comprobaciones masivas (vuelve a las herramientas de una sola página cuando se agota el tiempo de espera) |
web_data_amazon_product |
JSON limpio con título, precio, valoración e imágenes para cualquier ASIN de Amazon, sin necesidad de analizar HTML |
Cómo ayuda:
- Las entradas en tiempo real (precios, documentos, tendencias sociales) fluyen directamente en el código y las especificaciones generadas por Kiro.
- La gestión automática anti-bot permite a los agentes centrarse en la lógica de desarrollo, no en los dolores de cabeza del scraping.
- Las respuestas JSON estructuradas se introducen directamente en TypeScript/Python sin necesidad de regex.
Con Bright Data MCP conectado, cada solicitud de Kiro puede utilizar “datos en vivo” como una parte clave, cambiando la generación de código estático en una automatización completa y lista para usar.
Cómo conectar Kiro a MCP de Bright Data
En esta sección guiada, aprenderá a instalar y configurar Kiro con el servidor Web MCP de Bright Data. El resultado final será un entorno de desarrollo de IA capaz de acceder y procesar datos web en tiempo real directamente dentro de su flujo de trabajo de codificación.
Específicamente, construirá una configuración mejorada de Kiro con capacidades de datos web y la utilizará para:
- Extraer datos en tiempo real de múltiples sitios
- Generar especificaciones estructuradas basadas en la información actual del mercado
- Procesar y analizar los datos recogidos dentro de su entorno de desarrollo
Siga los siguientes pasos para empezar.
Requisitos previos
Para seguir este tutorial, necesitas
- Node.js 18+ instalado localmente (recomendamos la última versión LTS)
- Acceso a Kiro (requiere inscribirse en la lista de espera y recibir confirmación)
- Una cuenta Bright Data
No se preocupe si todavía no tiene una cuenta Bright Data. Le ayudaremos a configurarla en los siguientes pasos.
Paso 1: Instalar y configurar Kiro
Antes de instalar Kiro, debe inscribirse en la lista de espera en kiro.dev y recibir una confirmación de acceso. Una vez que tengas acceso, sigue la guía oficial de instalación.
En el primer lanzamiento, verás la pantalla de bienvenida. Siga el asistente de instalación para configurar su IDE.
Paso #2: Configure su servidor MCP de Bright Data
Diríjase a Bright Data y cree una cuenta Bright Data o inicie sesión en su cuenta existente.
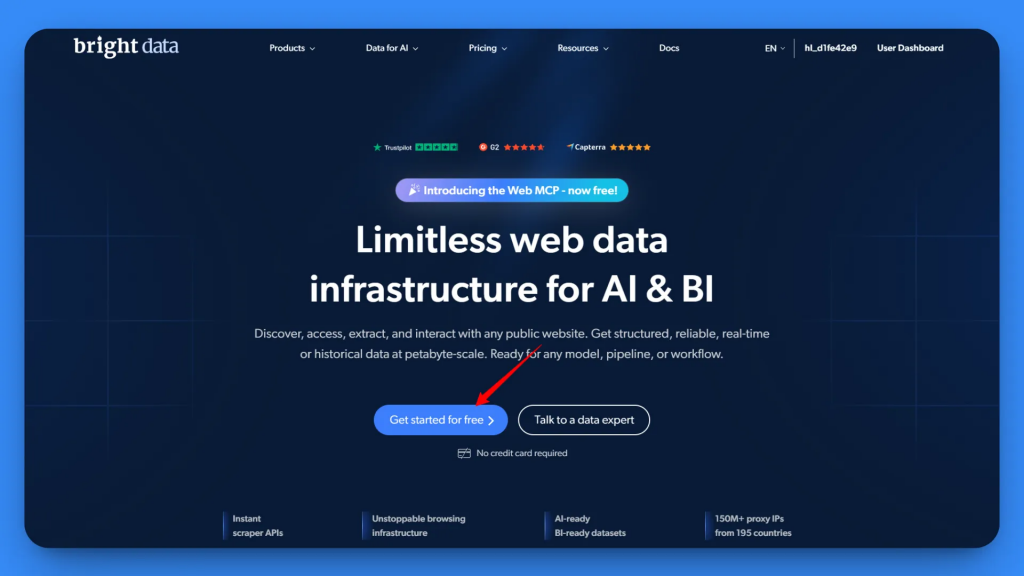
Después de iniciar sesión, llegará a la página de inicio. En la barra lateral izquierda, vaya a la sección MCP.
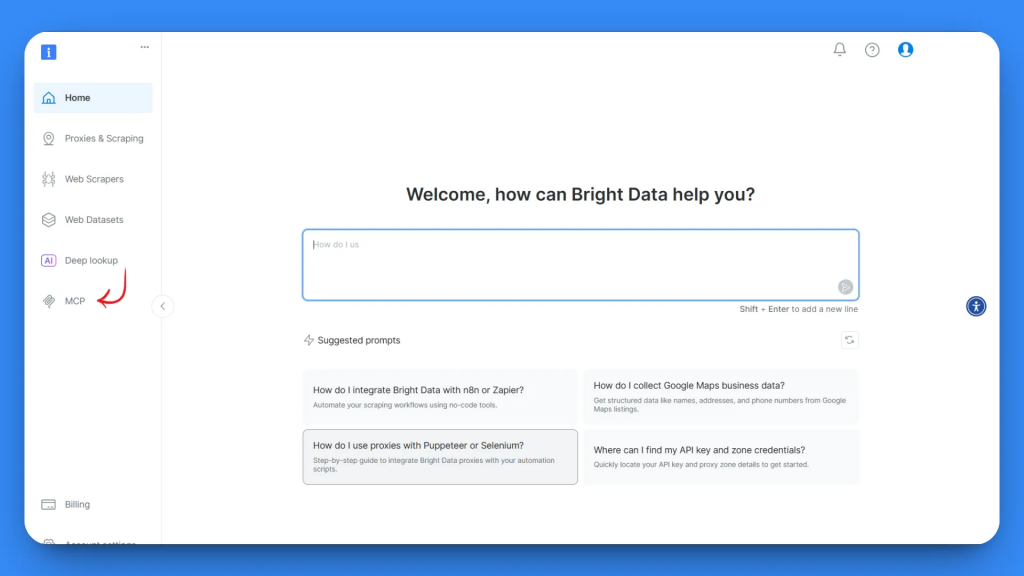
En la página de configuración de MCP, encontrará dos opciones: Autoalojado y Alojado. Para este tutorial, utilizaremos la opción Autoalojado, que proporciona el máximo control.
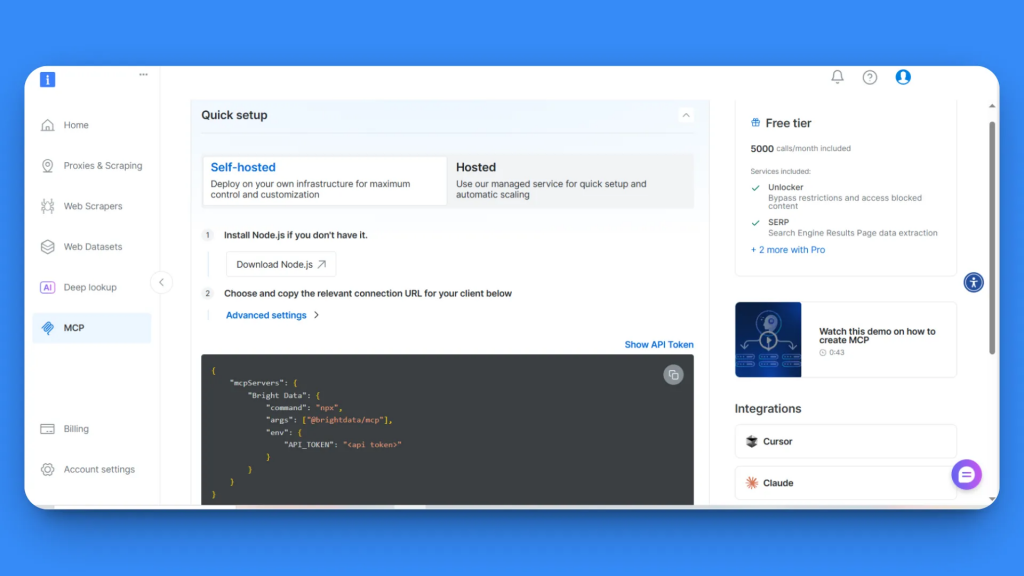
En el paso 2, verás tu clave API y un bloque de código de configuración MCP. Copie todo el código de configuración MCP:
{
"mcpServers": {
"Bright Data": {
"comando": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<api token>"
}
}
}
}Esto contiene todos los detalles de conexión necesarios y su token de API.
Paso #3: Configurar MCP en Kiro
Abra Kiro y cree un nuevo proyecto o abra una carpeta existente.
En la barra lateral izquierda, vaya a la pestaña Kiro. Verá cuatro secciones:
- SPECS
- GANCHOS DE AGENTE
- DIRECCIÓN DE AGENTES
- SERVIDORES MCP
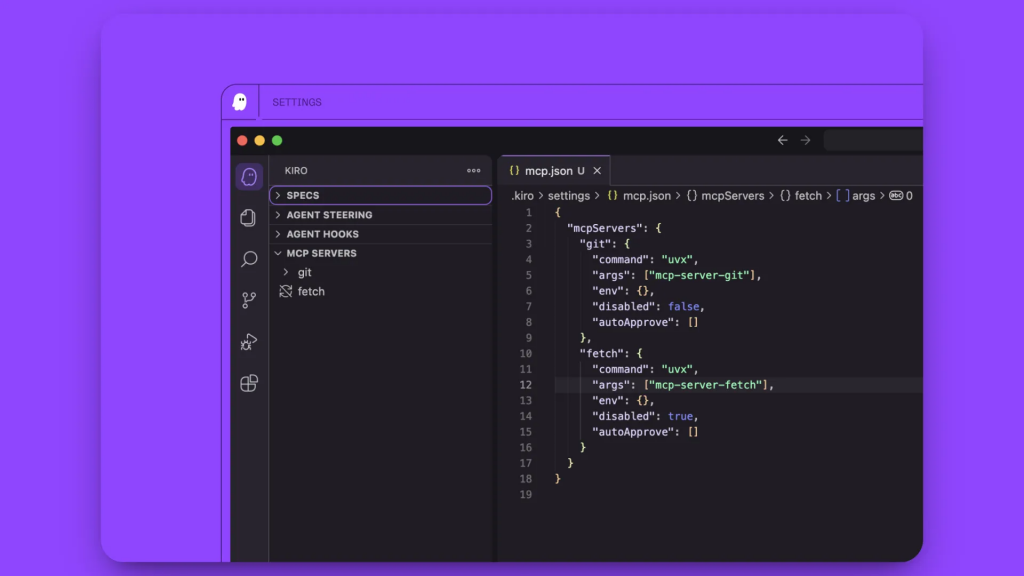
Haga clic en la sección SERVIDORES MCP. Verá un servidor preconfigurado ya presente, elimine esta configuración de servidor por defecto.
Añada el código de configuración MCP que copió de Bright Data pegándolo en el área de configuración.
Kiro comenzará a procesar la configuración. Inicialmente, puede mostrar el estado “Conectando…” o “No conectado” mientras establece la conexión.
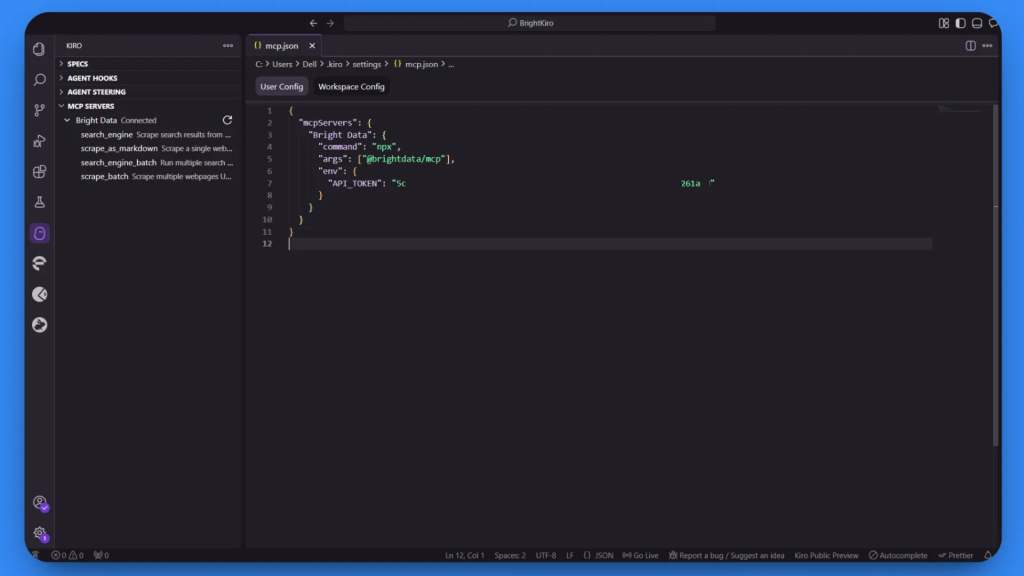
Una vez que el procesamiento se complete con éxito, verá que el estado cambia a “Conectado”, y cuatro herramientas MCP estarán disponibles:
search_enginescrape_as_markdownmotor_busqueda_lotescrape_batch
Paso 4: Verificar la conexión MCP
Para probar la integración, haga clic en cualquiera de las herramientas MCP disponibles en la barra lateral. Esto añadirá automáticamente la herramienta a la interfaz de chat de Kiro.
Pulse Intro para ejecutar la prueba. Kiro procesará la solicitud a través del servidor MCP de Bright Data y devolverá los resultados con el formato adecuado, confirmando que la integración funciona correctamente.
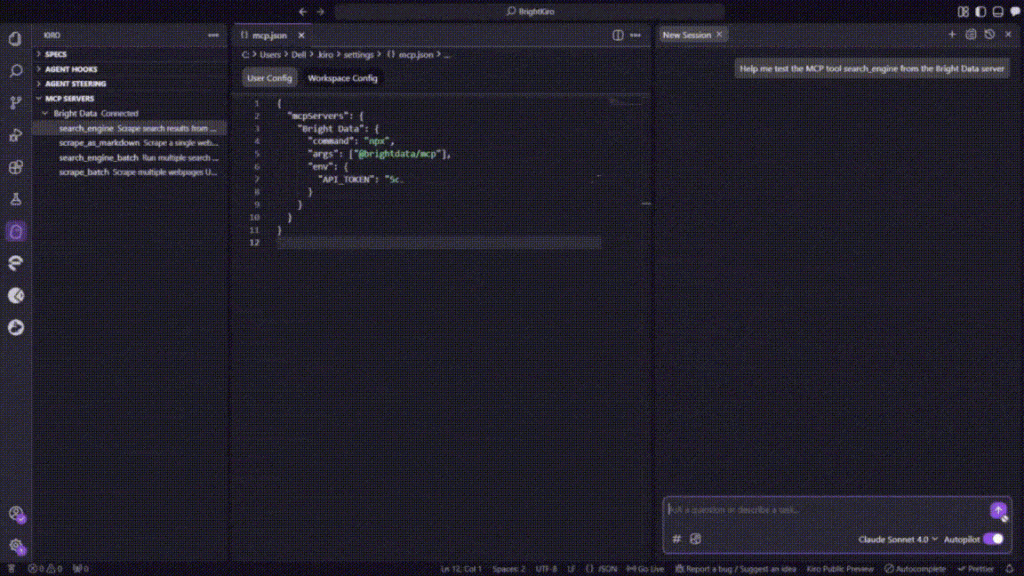
Perfecto. Su instalación de Kiro ahora tiene acceso a las capacidades de raspado web de Bright Data a través de la integración MCP. Ahora puede utilizar preguntas de lenguaje natural para extraer datos de cualquier sitio web público directamente dentro de su desarrollo.
Paso 5: Ejecute su primera tarea MCP en Kiro
Ahora vamos a probar la integración MCP de Kiro + Bright Data con una tarea práctica de recopilación de datos. Este ejemplo muestra cómo recopilar datos actuales del mercado laboral y procesarlos automáticamente.
Pregunta de prueba:
Busque "trabajos remotos de desarrollador de React" en Google, raspe los 5 mejores sitios web de anuncios de trabajo, extraiga títulos de trabajo, empresas, rangos salariales y habilidades requeridas. Crea un archivo CSV con estos datos y genera un script de Python que analice los salarios medios y los requisitos más comunes.Esto simula un caso de uso real para:
- Investigación de mercado y evaluación comparativa de salarios
- Análisis de tendencias de habilidades para la planificación de carreras
- Inteligencia competitiva para equipos de contratación
Pegue este mensaje en la interfaz de chat de Kiro y pulse Intro.
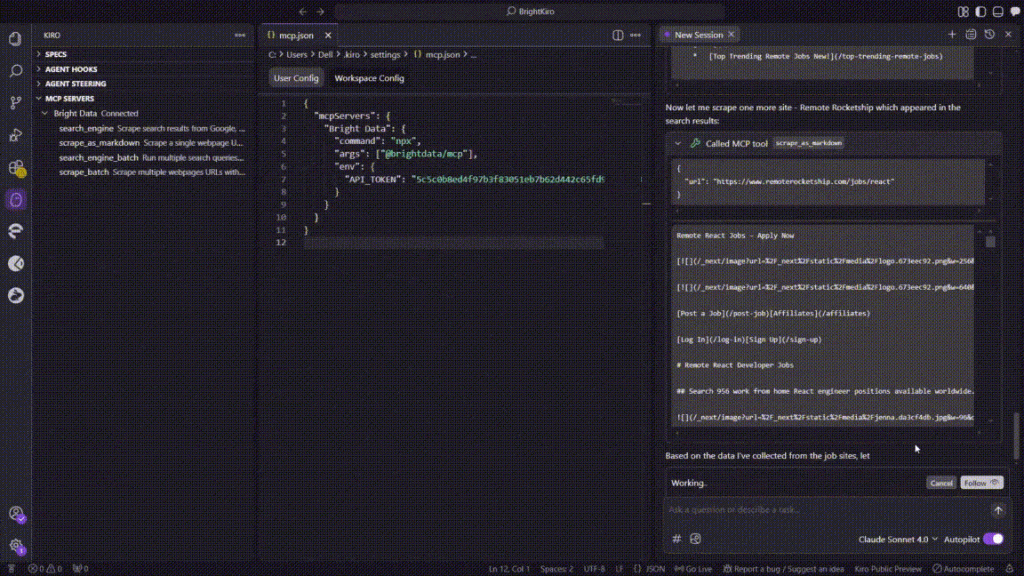
A continuación se muestra la secuencia exacta que siguió Kiro durante la ejecución de esta tarea:
- Fase de búsqueda
- Kiro llamó a la herramienta MCP
search_enginepara consultar “remote React developer jobs” en Google. - La llamada devolvió una lista de las mejores URLs de ofertas de trabajo en ~3s.
- Kiro llamó a la herramienta MCP
- Intento de raspado por lotes
- Kiro invocó
scrape_batchpara obtener las cinco URLs a la vez. - La petición por lotes expiró después de ~60s, por lo que Kiro registró un error MCP
(32001 Request timed out).
- Kiro invocó
- Vuelta al scraping de una sola página
- Kiro cambió a
scrape_as_markdown, raspando cada sitio secuencialmente:
- Indeed
- ZipRecruiter
- Wellfound
- Trabajamos a distancia
- Cada scrape terminaba en 4-10 s y devolvía Markdown legible.
- Kiro cambió a
- Estructuración de datos
- Una rutina de análisis sintáctico extrajo el título del puesto, la empresa, el salario, las habilidades y los campos de origen.
- Kiro agregaba las filas depuradas en una tabla en memoria.
- Creación de archivos CSV
- Kiro guardó la tabla como
remote_react_jobs.csvdentro del espacio de trabajo.
- Kiro guardó la tabla como
- Traspaso de sesión (continuación de contexto)
- El chat original superó la ventana de contexto de Kiro.
- Kiro abrió una nueva sesión de chat, importando automáticamente el contexto anterior para evitar la pérdida de datos.
- Generación de scripts de análisis en Python
- En la nueva sesión, Kiro creó
analyze_react_jobs.py, incluyendo:- Carga y limpieza de CSV
- Lógica de resumen de salarios/habilidades
- Código de gráficos Matplotlib + Seaborn
- El script termina con
print("Análisis completo").
- En la nueva sesión, Kiro creó
Las herramientas MCP de BrightData ayudaron a Kiro a gestionar automáticamente
- Resolución deCAPTCHA y detección de bots en sitios web de empleo
- Extracción de datos de diferentes diseños de sitios web
- Estandarización de formatos salariales y listas de habilidades
- Creación de una estructura CSV adecuada con encabezados
- Estrategia de scraping adaptable cuando las operaciones por lotes se encuentran con tiempos de espera.
Paso 6: Explorar y utilizar los resultados
Después de que Kiro complete la tarea, tendrá dos archivos principales en el directorio de su proyecto:
remote_react_jobs.csv:Contiene datos estructurados del mercado de trabajoanalyze_react_jobs.py: Script de Python para el análisis y la comprensión de los datos
Abra el archivo remote_react_jobs.csv para ver los datos recopilados:
El CSV contiene información real del mercado laboral con columnas como:
- Título del puesto
- Nombre de la empresa
- Rango salarial
- Habilidades requeridas
- Fuente del portal de empleo
Estos datos proceden de ofertas de empleo reales, no de contenido de marcadores de posición. El servidor MCP de Bright Data se encargó de la compleja tarea de extraer información estructurada de múltiples sitios de empleo con diferentes diseños y formatos.
A continuación, examine el script generado analyze_react_jobs.py.
El script incluye funciones para:
- Cargar y limpiar los datos CSV
- Calcular los rangos salariales medios
- Identificar las habilidades requeridas más comunes
- Generar estadísticas resumidas
- Crear visualizaciones e informes detallados
Antes de ejecutar el script de análisis, instale las dependencias necesarias:
pip install -r requirements.txtA continuación, ejecute el script de análisis para obtener información detallada:
python analyze_react_jobs.pyAl ejecutar el script, éste genera automáticamente dos archivos adicionales:
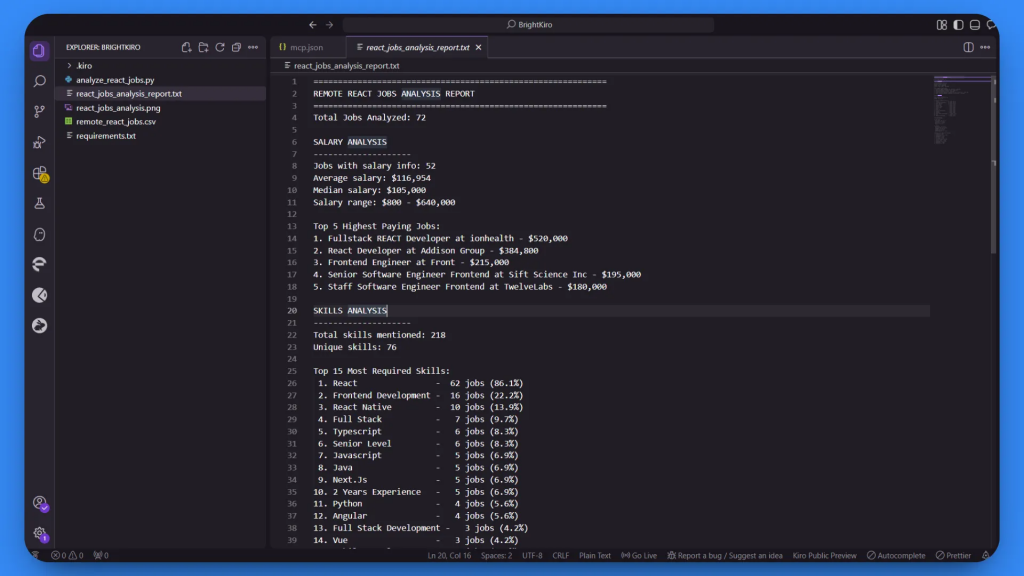
1. Informe de texto detallado (react_jobs_analysis_report.txt):
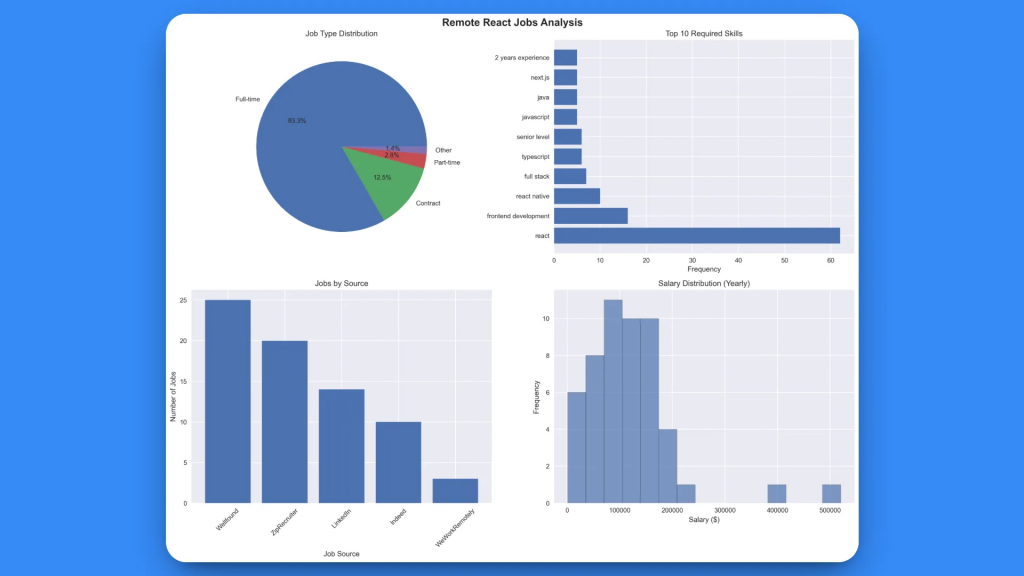
2. Gráfico de análisis visual (react_jobs_analysis.png):
El análisis exhaustivo se basó en 72 trabajos recopilados con éxito.
La visualización generada ofrece cuatro perspectivas clave:
- Distribución por tipo de empleo: Desglose claro de puestos a tiempo completo, por contrato o a tiempo parcial.
- Las 10 habilidades más requeridas: Representación visual de la frecuencia de demanda de competencias
- Empleos por fuente: Volúmenes de publicación de empleos específicos de la plataforma
- Distribución salarial: Histograma que muestra los rangos salariales en todos los puestos
Esto muestra cómo Kiro convierte una simple solicitud en lenguaje natural en un proceso completo de recopilación y análisis de datos. La integración se ocupa automáticamente de los problemas del web scraping, como el ajuste cuando se agotan las operaciones por lotes, a la vez que crea código listo para usar, informes detallados y visuales profesionales para los estudios de mercado en curso.
Conclusión
Eso es todo por este tutorial. En este blog, aprendió cómo mejorar Kiro conectándolo con los servidores Web MCP de Bright Data. Esto le permite raspar datos web en vivo y procesar información en tiempo real directamente en su configuración de desarrollo de IA.
Mostramos esto con un ejemplo práctico de raspado, limpieza, análisis y visualización de trabajos remotos de desarrolladores React de diferentes fuentes. Esta automatización completa demuestra la fuerza de combinar la IA de Kiro con las herramientas de scraping de primera categoría de Bright Data.
Mediante el uso de esta integración, los desarrolladores pueden ir más allá de la generación de código estático a flujos de trabajo totalmente automatizados y basados en datos que aceleran el desarrollo de productos y mejoran la precisión.
Cree su cuenta de Bright Data hoy mismo y empiece a utilizar la inteligencia web en tiempo real para potenciar sus agentes de IA.





