

En esta guía aprenderás
- Todo lo que necesita saber para empezar con el Scraping web de Baidu.
- Los métodos más populares y eficaces para el scraping de Baidu.
- Cómo construir un Raspador Baidu personalizado desde cero en Python.
- Cómo recuperar resultados de motores de búsqueda utilizando la API SERP de Bright Data.
- Cómo dar a sus agentes de IA acceso a los datos de búsqueda de Baidu a través del Web MCP.
¡Vamos a sumergirnos!
Familiarizarse con la SERP de Baidu
Antes de emprender cualquier acción, dedique algún tiempo a comprender cómo está estructurada la SERP (página de resultados del motor de búsqueda) de Baidu, qué datos contiene, cómo acceder a ellos, etc.
URL de la SERP de Baidu y sistema de detección de bots
Abre Baidu en tu navegador y comienza a realizar algunas búsquedas. Por ejemplo, busque “bright data”. Deberías obtener una URL como esta
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=bright%20data&fenlei=256&oq=ai%2520model&rsv_pq=970a74b9001542b3&rsv_t=7f84gPOmZQIjrqRcld6qZUI%2FiqXxDExphd0Tz5ialqM87sc5Falk%2B%2F3hxDs&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=12&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&inputT=1359&rsv_sug4=1358Entre todos estos parámetros de consulta, los importantes son:
- URL base:
https://www.baidu.com/s. - Parámetro de consulta de búsqueda:
wd.
En otras palabras, puede obtener los mismos resultados con una URL más corta:
https://www.baidu.com/s?wd=bright%20dataAdemás, Baidu estructura sus URL para la paginación mediante el parámetro de consulta pn. En concreto, la segunda página añade &pn=10, y luego cada página siguiente incrementa ese valor en 10. Por ejemplo, si desea raspar 3 páginas con la palabra clave “datos brillantes”, sus URL de SERP serían:
https://www.baidu.com/s?wd=bright%20data -> página 1
https://www.baidu.com/s?wd=bright%20data&pn=10 -> página 2
https://www.baidu.com/s?wd=bright%20data&pn=20 -> página 3Ahora bien, si intentas acceder directamente a esa URL mediante una simple petición GET HTTP en un cliente HTTP como Postman, probablemente verás algo como esto:
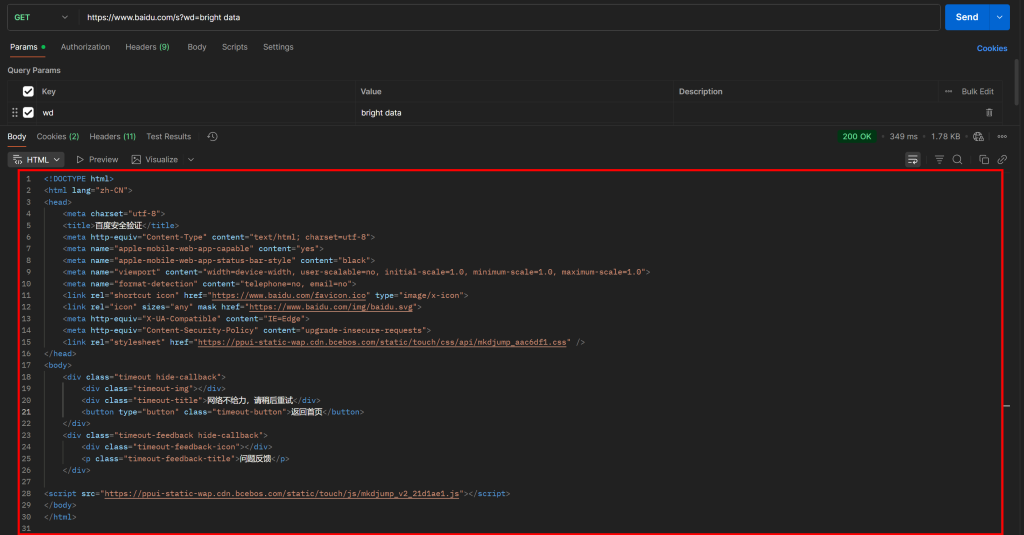
Como puede ver, Baidu devuelve una página con el mensaje “网络不给力,请稍后重试” (que se traduce como “La red no funciona bien, por favor inténtelo de nuevo más tarde”, pero en realidad es una página anti-bot).
Esto ocurre incluso si se incluye una cabecera User-Agent, que normalmente es esencial para las tareas de Scraping web. En otras palabras, Baidu detecta que tu solicitud es automatizada y la bloquea, requiriendo una verificación humana adicional.
Esto demuestra claramente que para hacer scraping en Baidu se necesita una herramienta de automatización del navegador (como Playwright o Puppeteer). Una simple combinación de un cliente HTTP y un analizador HTML no será suficiente, ya que provocará sistemáticamente bloqueos anti-bot.
Datos disponibles en una SERP de Baidu
Ahora, concéntrate en la SERP de Baidu para “datos brillantes” mostrada en tu navegador. Deberías ver algo como esto:
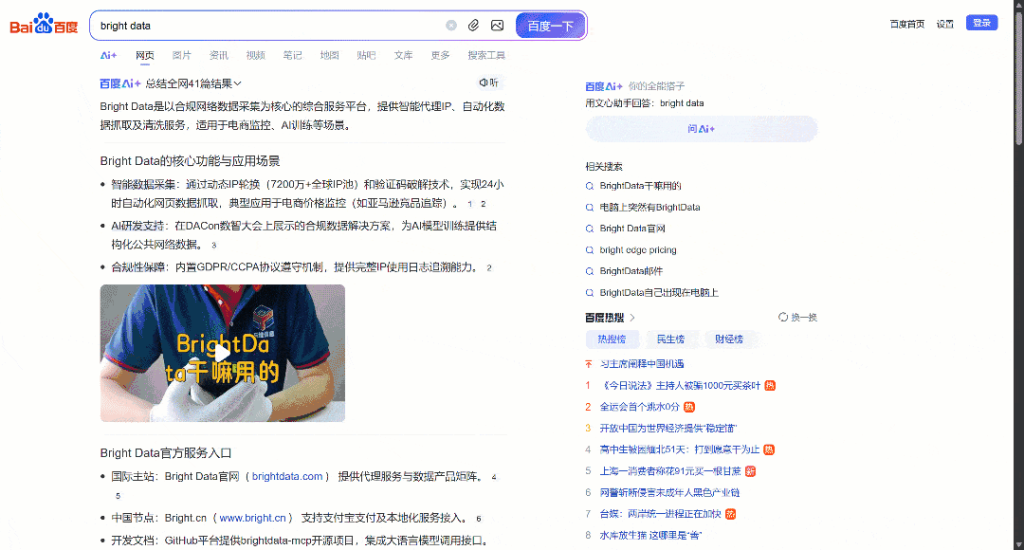
Cada página SERP de Baidu está dividida en dos columnas. La columna de la izquierda contiene una descripción general de la IA (véase cómo extraer descripciones generales de la IA), seguida de los resultados de la búsqueda. En la parte inferior de esta columna, está la sección “相关搜索” (“Búsquedas relacionadas”), y debajo, los elementos de navegación de paginación.
La columna de la derecha contiene “百度热搜” (“Baidu Hot Searches”), que muestra los temas de tendencia o más populares en Baidu.(Nota: estos resultados de trending no están necesariamente relacionados con tus términos de búsqueda).
Estos son todos los datos principales que puedes extraer de una SERP de Baidu. En este tutorial, nos centraremos únicamente en los resultados de búsqueda, que suelen ser la información más importante.
Principales métodos para obtener datos de Baidu
Hay varias formas de obtener datos de los resultados de búsqueda de Baidu. Compara las principales en la tabla resumen de abajo:
| Método | Integración Complejidad | Requisitos | Precio | Riesgo de bloques | Escalabilidad |
|---|---|---|---|---|---|
| Construir un Raspador a medida | Medio/Alto | Conocimientos de programación Python + conocimientos de automatización de navegadores | Gratuito (puede requerir navegadores anti-bot para evitar bloqueos) | Posible | Limitado |
| Utilizar la API SERP de Bright Data | Bajo | Cualquier cliente HTTP | De pago | Ninguno | Ilimitado |
| Integrar el servidor Web MCP | Bajo | Marco o plataforma de agente de IA compatible con MCP | Nivel gratuito disponible, luego de pago | Ninguno | Ilimitado |
A lo largo del tutorial aprenderá a aplicar cada uno de estos métodos.
Nota 1: Independientemente del método que elijas, la consulta de búsqueda objetivo utilizada a lo largo de esta guía será “datos brillantes”. Esto significa que verás cómo recuperar los resultados de búsqueda de Baidu específicamente para esa consulta.
Nota 2: Supondremos que ya tiene Python instalado localmente y que está familiarizado con las secuencias de comandos web de Python.
Método nº 1: Crear un Raspador Personalizado
Utilice un marco de automatización del navegador o un cliente HTTP combinado con un analizador HTML para construir un raspador de Baidu desde cero.
Ventajas:
- Control total sobre la lógica de análisis de datos, con la posibilidad de extraer exactamente lo que necesitas.
- Flexible y personalizable a tus necesidades.
👎 Contras:
- Requiere esfuerzo de configuración, codificación y mantenimiento.
- Puede enfrentarse a bloqueos de IP, CAPTCHAs, límites de velocidad y otros retos de Scraping web cuando se ejecuta a escala.
Método 2: Utilizar la API SERP de Bright Data
Aproveche la API SERP de Bright Data, una solución de primera calidad que le permite consultar Baidu (y otros motores de búsqueda) a través de un punto final HTTP fácil de llamar. Gestiona todas las medidas anti-bot y el escalado por usted. Estas y muchas otras características la convierten en una de las mejores API SERP y de búsqueda del mercado.
Ventajas:
- Altamente escalable y fiable, respaldada por una red Proxy de más de 150M de IPs.
- Sin prohibiciones de IP ni problemas de CAPTCHA.
- Funciona con cualquier cliente HTTP (incluyendo herramientas visuales como Postman o Insomnia).
Contras:
- Servicio de pago.
Enfoque #3: Integrar el Servidor Web MCP
Permita que su agente de IA acceda a los resultados de búsqueda de Baidu de forma gratuita a través de Web MCP de Bright Data, que se conecta a la API SERP y a Web Unlocker de Bright Data bajo el capó.
Ventajas:
- Integración en flujos de trabajo y agentes de IA.
- Nivel gratuito disponible.
- No requiere lógica de parseo de datos (la IA se encarga de ello).
Contras:
- Control limitado sobre el comportamiento de los LLM.
Método #1: Construir un Raspador Baidu Personalizado en Python Usando Playwright
Siga los siguientes pasos para construir un script personalizado de Scraping web de Baidu en Python.
Como se mencionó anteriormente, el scraping de Baidu requiere la automatización del navegador porque las solicitudes HTTP simples se bloquearán. En esta sección del tutorial, utilizaremos Playwright, una de las mejores librerías para la automatización del navegador en Python.
Paso #1: Configurar tu proyecto de scraping
Comienza abriendo tu terminal y creando una nueva carpeta para tu proyecto Raspador de Baidu:
mkdir baidu-scraperLa carpeta baidu-scraper/ contendrá todos los archivos para su proyecto de raspado.
A continuación, navega al directorio del proyecto y crea un entorno virtual Python dentro de él:
cd baidu-scraper
python -m venv .venvAhora, abre la carpeta del proyecto en tu IDE de Python preferido. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Añade un nuevo archivo llamado raspador.py a la raíz del directorio de tu proyecto. La estructura de tu proyecto debería ser la siguiente
baidu-scraper/
├── .venv/
└── raspador.pyA continuación, activa el entorno virtual en el terminal. En Linux o macOS, ejecute:
source .venv/bin/activateDe forma equivalente, en Windows, ejecuta:
.venv/Scripts/activateCon el entorno virtual activado, instale Playwright mediante pip a través del paquete playwright:
pip install playwrightA continuación, instale las dependencias necesarias de Playwright (por ejemplo, los binarios del navegador):
python -m playwright installListo. Su entorno Python está ahora listo para empezar a construir su Raspador web Baidu.
Paso 2: Inicializar el script Playwright
En scraper.py, importa Playwright y utiliza su API síncrona para iniciar una instancia controlada del navegador Chromium:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Inicializar una instancia de Chromium en modo headless
browser = p.chromium.launch(headless=True) # set headless=False to see the browser for debugging
page = browser.new_page()
# Lógica de depuración...
# Cerrar el navegador y liberar sus recursos
browser.close()El fragmento anterior constituye la base de su Raspador Baidu.
El parámetro headless=True indica a Playwright que inicie Chromium sin una GUI visible. Según las pruebas realizadas, esta configuración no activa la detección de bots de Baidu. Por lo tanto, funciona bien para el scraping. Sin embargo, mientras desarrollas o depuras tu código, puede que prefieras establecer headless=False para poder ver lo que ocurre en el navegador en tiempo real.
Perfecto. Ahora, conéctese al SERP de Baidu y comience a recuperar los resultados de búsqueda.
Paso #3: Visita la SERP objetivo
Como se ha analizado anteriormente, crear una URL SERP de Baidu es sencillo. En lugar de indicar a Playwright que simule las interacciones del usuario (como escribir en el cuadro de búsqueda y enviarlo), es mucho más fácil crear la URL de la SERP mediante programación e indicar a Playwright que navegue directamente hasta ella.
Esta es la lógica para crear una URL SERP de Baidu para el término de búsqueda “bright data”:
# La URL base de la página de búsqueda de Baidu
base_url = "https://www.baidu.com/s"
# La palabra clave/frase clave de búsqueda
search_query = "datos_brillantes"
params = {"wd": search_query}
# Construir la URL de la SERP Baidu
url = f"{base_url}?{urlencode(params)}"No olvides importar la función urlencode() de la Python Standard Library:
from urllib.parse import urlencodeAhora, indique al navegador controlado por Playwright que visite la URL generada mediante goto():
page.goto(url)Si ejecutas el script en modo headful (con headless=False) en el depurador, verás que una ventana de Chromium carga la página SERP de Baidu:
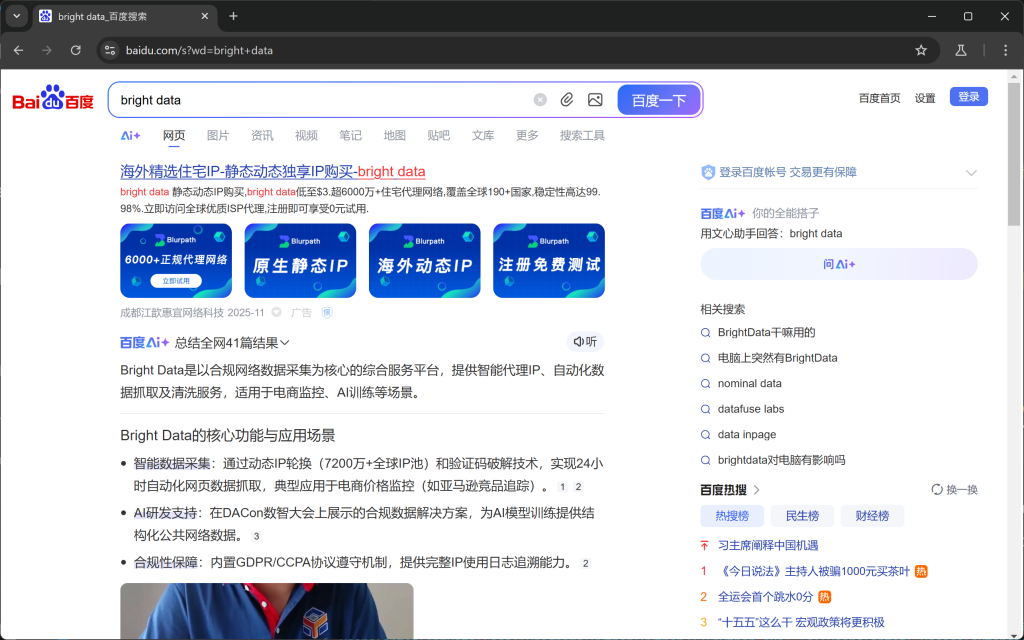
¡Impresionante! Esa es exactamente la SERP que vas a raspar a continuación.
Paso 4: Prepararse para extraer todos los resultados de las SERP
Antes de sumergirte en la lógica del scraping, debes estudiar la estructura de las SERPs de Baidu. En primer lugar, como la página contiene múltiples elementos de resultados de búsqueda, necesitará una lista para almacenar los datos extraídos. Por lo tanto, comience por inicializar una lista vacía:
serp_results = []A continuación, abra la SERP de Baidu de destino en una ventana de incógnito (para garantizar una sesión limpia) en su navegador:
https://www.baidu.com/s?wd=bright%20dataHaz clic con el botón derecho en uno de los elementos de los resultados de búsqueda y selecciona “Inspeccionar” para abrir las DevTools del navegador:
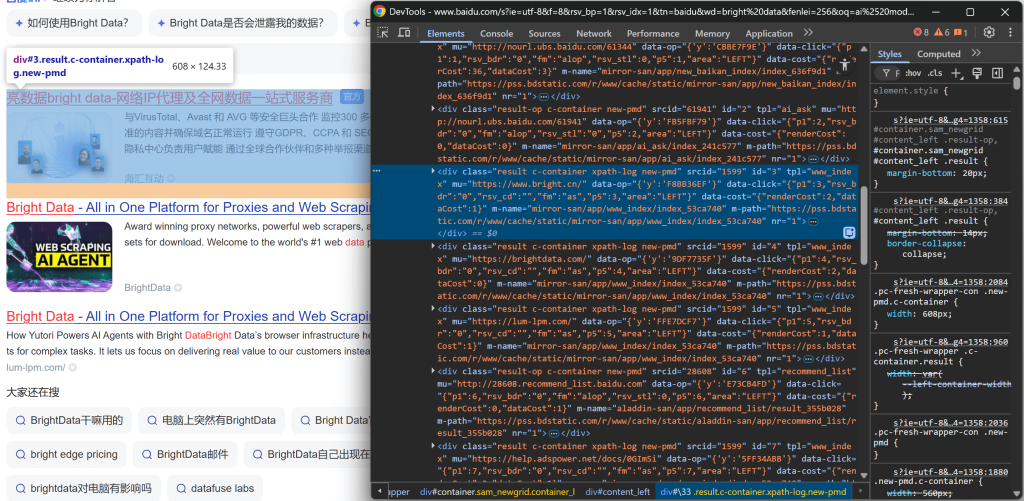
Observando la estructura DOM, te darás cuenta de que cada elemento de resultado de búsqueda tiene la clase result. Esto significa que puedes seleccionar todos los resultados de búsqueda de la página utilizando el selector CSS .result.
Aplique ese selector en su script Playwright:
search_result_elements = page.locator(".result")Nota: Si no está familiarizado con esta sintaxis, lea nuestra guía sobre Scraping web de Playwright.
Por último, itere sobre cada elemento seleccionado:
for search_result_element in search_result_elements.all():
# Lógica de parseo de datos...Prepárate para aplicar la lógica de análisis de datos para extraer los resultados de búsqueda de Baidu y rellenar la lista serp_results:
¡Perfecto! Ahora está a punto de finalizar su flujo de trabajo de extracción de Baidu.
Paso 5: Extraer los datos de los resultados de búsqueda
Inspeccione la estructura HTML de un elemento SERP en la página de resultados de Baidu. Esta vez, céntrate en sus elementos anidados para identificar los datos que quieres extraer.
Empieza explorando la sección del título:
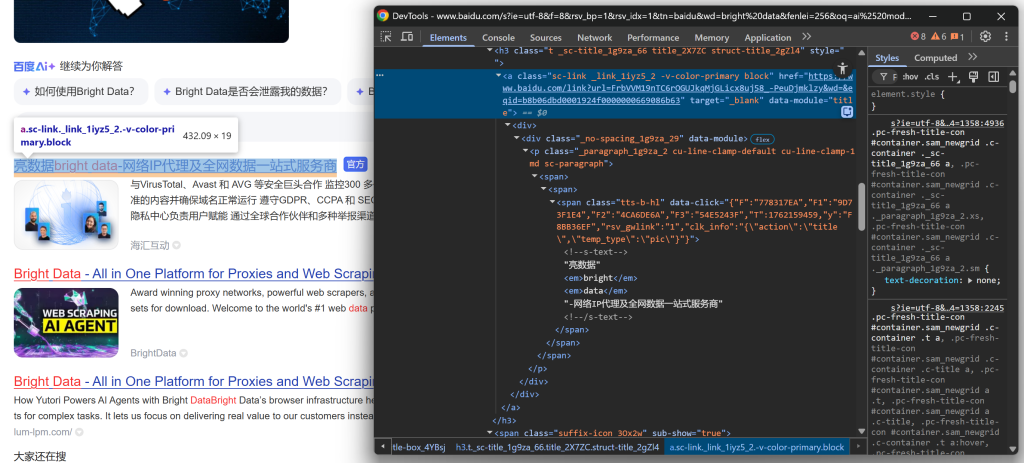
Continúa observando que algunos resultados muestran una etiqueta “官方” (“Oficial”):
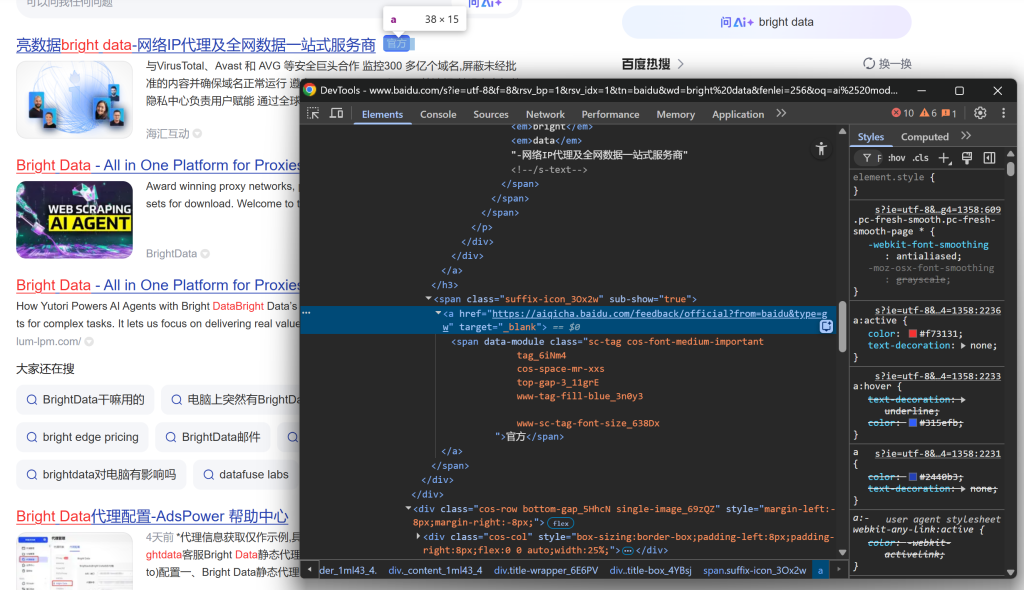
Y, a continuación, céntrate en la imagen del resultado de la SERP:
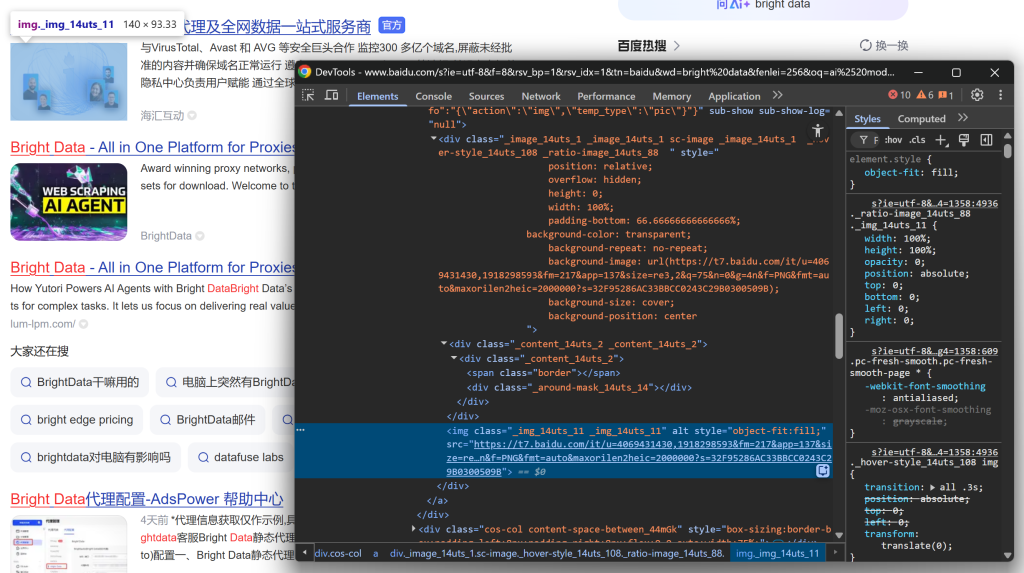
Y concluir mirando la descripción/abstracto:
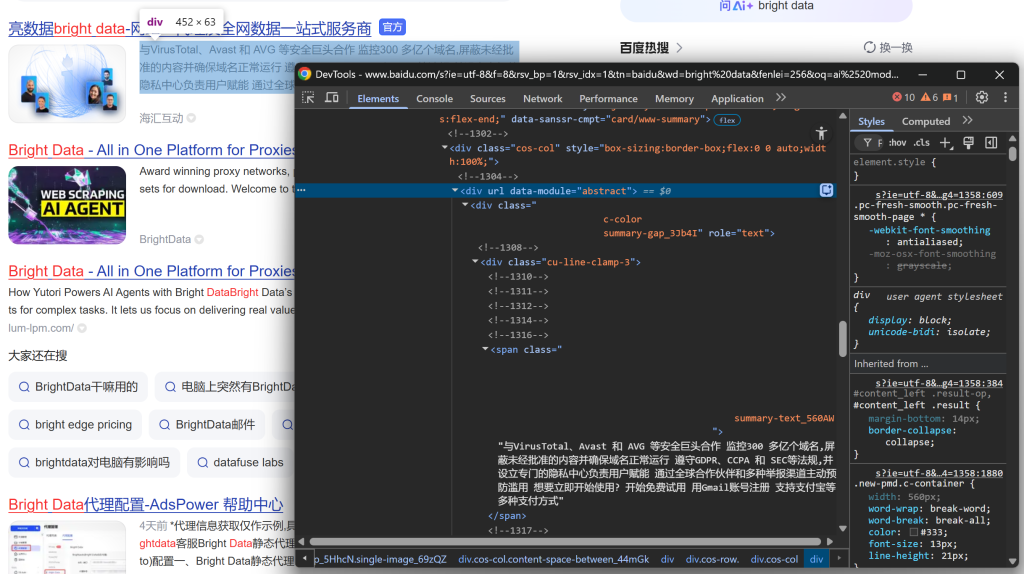
De estos elementos anidados, puede extraer los siguientes datos:
- URL del resultado a partir del atributo
hrefdel elemento.sc-link. - Título del resultado a partir del texto del elemento
.sc-link. - Descripción/resumen delresultado a partir del texto
[data-module='abstract']. - Imagen resultante a partir del atributo
srcdel elementoimgdentro de.sc-image. - Fragmento delresultado a partir del texto
.result__snippet. - Etiqueta oficial, en un elemento
<a>cuyohrefcomience porhttps://aiqicha.baidu.com/feedback/official(si está presente).
Utilice la API de localización de Playwright para seleccionar elementos y extraer los datos deseados:
link_element = search_result_element.locator(".sc-link")
link = elemento_enlace.get_attribute("href")
title = elemento_enlace.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0Tenga en cuenta que no todos los elementos SERP son iguales. Para evitar errores, comprueba siempre que el elemento existe (.count() > 0) antes de acceder a sus atributos o texto.
¡Estupendo! Acaba de definir la lógica de análisis de datos SERP de Baidu.
Paso 6: Recopilar los datos de los resultados de búsqueda obtenidos
Concluye el bucle for creando un diccionario para cada resultado de búsqueda y añadiéndolo a la lista serp_results:
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"imagen": imagen.strip() if imagen else "",
"oficial": oficial
}
serp_results.append(serp_result)¡Maravilloso! La lógica de Scraping web de Baidu ya está completa. El paso final es exportar los datos obtenidos para su uso posterior.
Paso 7: Exportar los resultados de búsqueda a CSV
En esta etapa, los resultados de la búsqueda en Baidu se almacenan en una lista de Python. Para que otros equipos o herramientas puedan utilizar los datos, expórtalos a un archivo CSV utilizando la biblioteca csv integrada de Python:
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Lee dinámicamente los nombres de campo del primer elemento
fieldnames = list(serp_results[0].keys())
# Inicializar el escritor CSV
writer = csv.DictWriter(csvfile, fieldnames=nombresdecampo)
# Escribir la cabecera y rellenar el archivo CSV de salida
writer.writeheader()
writer.writerows(serp_results)No olvides importar csv:
import csvDe esta forma, tu Raspador Baidu generará un archivo de salida llamado baidu_serp_results.csv, que contendrá todos los resultados raspados en formato CSV. Misión cumplida
Paso 8: Ponerlo todo junto
El código final contenido en scraper.py es:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
import csv
# Dónde almacenar los datos raspados
serp_results = []
with sync_playwright() as p:
# Inicializar una instancia de Chromium en modo headless
browser = p.chromium.launch(headless=True) # set headless=False to see the browser for debugging
page = browser.new_page()
# La URL base de la página de búsqueda de Baidu
base_url = "https://www.baidu.com/s"
# La palabra clave/frase clave de búsqueda
search_query = "datos_brillantes"
params = {"wd": search_query}
# Construir la URL de la SERP Baidu
url = f"{base_url}?{urlencode(params)}"
# Visita la página de destino en el navegador
page.goto(url)
# Seleccionar todos los elementos del resultado de la búsqueda
search_result_elements = page.locator(".result")
for elemento_resultado_buscado in elementos_resultado_buscado.all():
# Lógica de parseo de datos
elemento_enlace = elemento_de_búsqueda.locator(".sc-enlace")
link = elemento_enlace.get_attribute("href")
title = elemento_enlace.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0
# Rellenar un nuevo objeto de resultado de búsqueda con los datos raspados
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"imagen": imagen.strip() if imagen else "",
"oficial": oficial
}
# Añade el resultado de la SERP de Baidu a la lista
serp_results.append(serp_result)
# Cerrar el navegador y liberar sus recursos
browser.close()
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Lee dinámicamente los nombres de campo del primer elemento
fieldnames = list(serp_results[0].keys())
# Inicializar el escritor CSV
writer = csv.DictWriter(csvfile, fieldnames=nombresdecampo)
# Escribir la cabecera y rellenar el archivo CSV de salida
writer.writeheader()
writer.writerows(serp_results)¡Vaya! En tan sólo 70 líneas de código, has creado un script de extracción de datos de Baidu.
Prueba el script con:
python raspador.pyEl resultado será un archivo baidu_serp_results.csv en la carpeta del proyecto. Ábrelo para ver los datos estructurados extraídos de los resultados de búsqueda de Baidu:

Nota: Para obtener más resultados, repite el proceso utilizando el parámetro de consulta pn para gestionar la paginación.
¡Et voilà! Has transformado con éxito los resultados de búsqueda no estructurados de Baidu en un archivo CSV estructurado.
[Extra] Utilice un servicio de navegador remoto para evitar bloqueos
El Raspador mostrado arriba funciona bien para pequeñas ejecuciones, pero no escalará bien. Baidu empezará a bloquear peticiones cuando vea demasiado Tráfico desde la misma IP, devolviendo páginas de error o desafíos. Ejecutar muchas instancias locales de Chromium también consume muchos recursos (mucha RAM) y es difícil de coordinar.
Una solución más escalable y fácil de gestionar es conectar su instancia de Playwright a una solución remota de scraping browser-as-a-service como Bright Data’s Browser API. Esto proporciona rotación automática del Proxy, gestión de CAPTCHA y derivación anti-bot, instancias de navegador reales para evitar problemas de fingerprinting y escalado ilimitado.
Siga la guía de configuración de la API de navegador de Bright Data y obtendrá una cadena de conexión WSS similar a la siguiente
wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222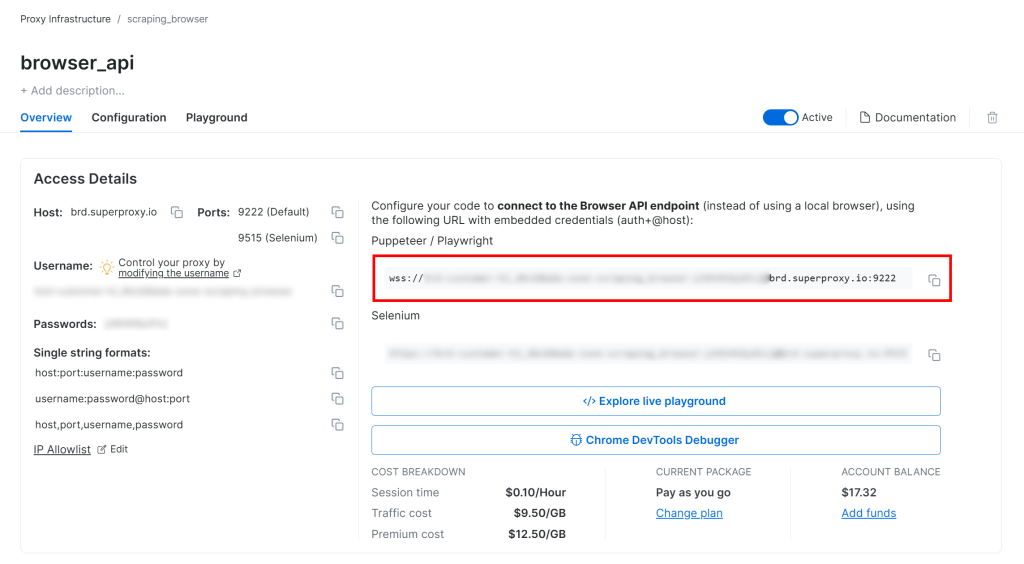
Utilice esa URL WSS para conectar Playwright a las instancias remotas del navegador a través del CDP(Chrome DevTools Protocol):
wss_url = "wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222"
browser = playwright.chromium.connect_over_cdp(wss_url)
page = browser.new_page()
# ...Ahora sus solicitudes de Playwright a Baidu se enrutarán a través de la infraestructura remota de la API de navegador de Bright Data, que está respaldada por una red proxy residencial de 150 millones de IP e instancias de navegador reales. Esto garantiza una IP nueva para cada sesión y una huella digital del navegador realista.
Método nº 2: Utilizar la API SERP de Bright Data
En este capítulo, verá cómo utilizar la API SERP todo en uno de Baidu de Bright Data para recuperar resultados de búsqueda mediante programación.
Nota: Para simplificar, asumimos que ya tiene un proyecto Python con la bibliotecarequests instalada.
Paso 1: Configure una Zona API SERP en su cuenta de Bright Data
Comience configurando el producto API SERP en Bright Data para obtener los resultados de búsqueda de Baidu. En primer lugar, cree una cuenta de Bright Data o inicie sesión si ya tiene una.
Para una configuración más rápida, puede consultar la guía oficial de “Inicio rápido” de la API SERP de Bright Data. De lo contrario, continúe con los pasos siguientes.
Una vez iniciada la sesión, vaya a “Proxies & Scraping” en su cuenta de Bright Data para acceder a la página de productos:
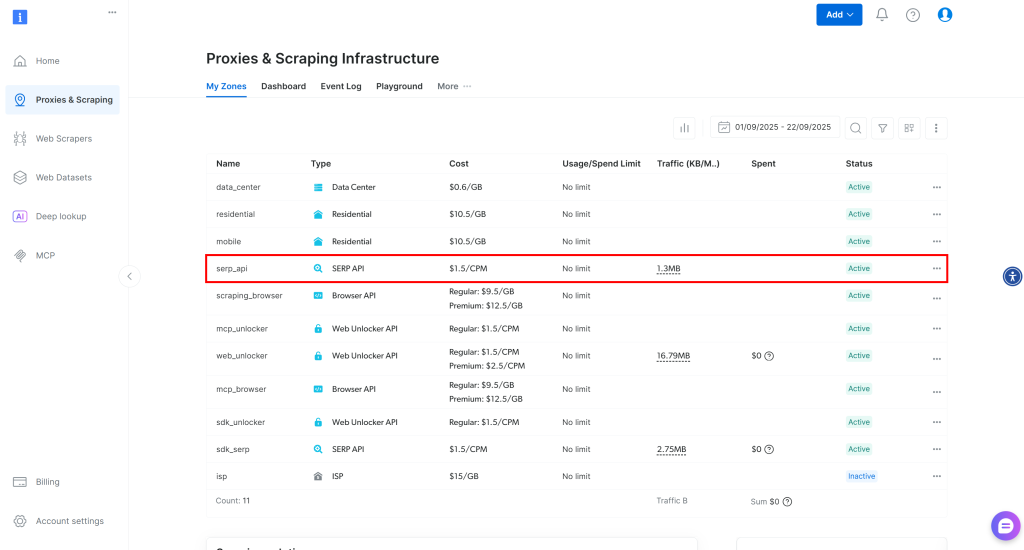
Eche un vistazo a la tabla “Mis zonas”, que enumera sus productos de Bright Data configurados. Si ya existe una zona API SERP activa, está listo para empezar. Simplemente copie el nombre de la zona (por ejemplo, serp_api), ya que lo necesitará más adelante.
Si no existe ninguna zona API SERP, desplácese hasta la sección “Soluciones de raspado” y haga clic en “Crear zona” en la tarjeta “API SERP”:
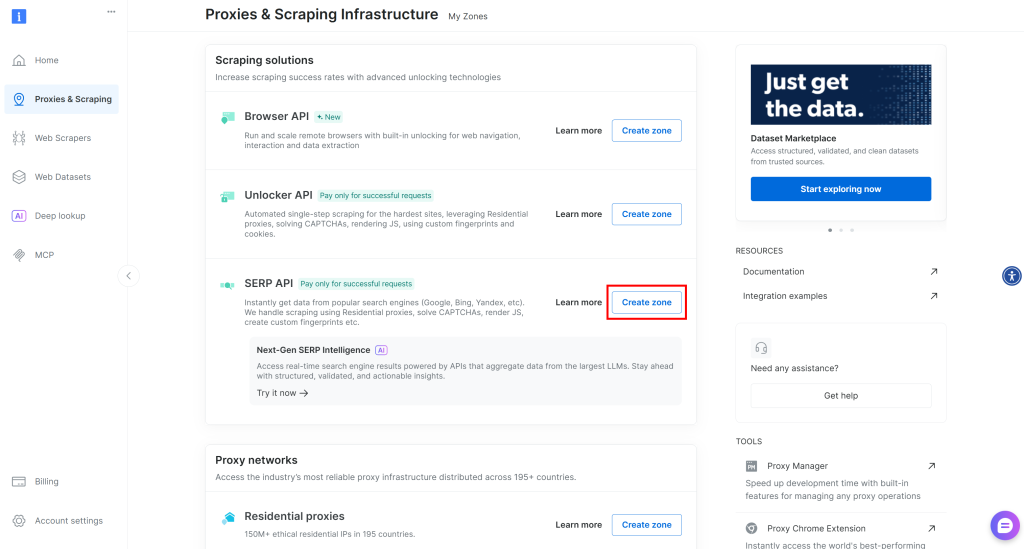
Dale un nombre a tu zona (por ejemplo, serp-api) y haz clic en el botón “Añadir”:
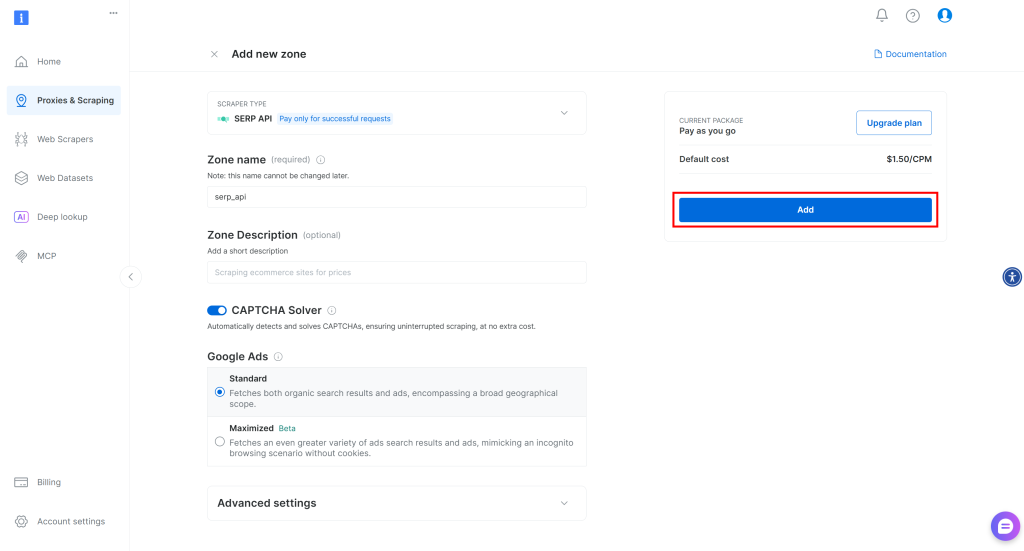
A continuación, vaya a la página de producto de la Zona y asegúrese de que está activada cambiando el interruptor a “Activo”:
¡Genial! Su zona API SERP de Bright Data ya está configurada y lista para usar.
Paso 2: Obtenga su clave API de Bright Data
La forma recomendada de autenticar las solicitudes a la API SERP es utilizar su clave de API de Bright Data. Si aún no ha generado una, siga la guía oficial de Bright Data para crear su clave de API.
Cuando realice una solicitud POST a la API SERP, incluya su clave de API en el encabezado Autorización de la siguiente manera:
"Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>"¡Sorprendente! Ya tiene todo lo que necesita para llamar a la API SERP de Bright Data desde un script Python con peticiones, o desdecualquier otro cliente HTTP Python.
Ahora, ¡pongamos todo junto!
Paso 3: Llamar a la API SERP
Utilice la API SERP de Bright Data en Python para recuperar los resultados de búsqueda de Baidu para la palabra clave “bright data”:
# pip install peticiones
importar requests
from urllib.parse import urlencode
# credenciales de Bright Data (TODO: sustitúyalas por sus valores)
bright_data_api_key = "<TU_CLAVE_API_BRIGHT_DATA_API>"
bright_data_serp_api_zone_name = "<SU_SERP_API_ZONE_NAME>" # (por ejemplo, "serp_api")
# URL base de la página de búsqueda de Baidu
base_url = "https://www.baidu.com/s"
# Palabra clave/frase clave de búsqueda
search_query = "datos brillantes"
params = {"wd": search_query}
# Construir la URL SERP de Baidu
url = f"{base_url}?{urlencode(params)}"
# Enviar una solicitud POST a la API SERP de Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f "Portador {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"zone": bright_data_serp_api_zone_name,
"url": url
"format": "raw"
}
)
# Recuperar el HTML completamente renderizado
html = respuesta.texto
# La lógica de Parseo va aquí...Para ver otro ejemplo, eche un vistazo al “Bright Data API SERP Python Project” en GitHub.
La API SERP de Bright Data gestiona la renderización de JavaScript, se integra con una red proxy para la rotación automática de IP y gestiona medidas anti-scraping como la huella digital del navegador, CAPTCHAs y otras. Esto significa que no se encontrará con la página de error “网络不给力,请稍后重试” (“La red no funciona bien, inténtelo de nuevo más tarde.” ) que obtendría normalmente al raspar Baidu con un cliente HTTP básico como las solicitudes.
En términos más sencillos, la variable html contiene la página de resultados de búsqueda de Baidu completamente renderizada. Compruébelo imprimiendo el HTML con
print(html)Obtendrás una salida como la siguiente:
A partir de aquí, puede analizar el HTML como se muestra en el primer enfoque para extraer los datos de búsqueda de Baidu que necesita. Como prometimos, la API SERP de Bright Data evita los bloqueos y le permite alcanzar una escalabilidad ilimitada.
Enfoque #3: Integrar el Servidor Web MCP
Recuerde que la API SERP (y muchos otros productos de Bright Data) también es accesible a través de la herramienta search_engine en el MCP Web de Bright Data.
Este servidor Web MCP de código abierto proporciona un acceso fácil para la IA a las soluciones de recuperación de datos web de Bright Data, incluido el scraping de Baidu. En concreto, las herramientas search_engine y scrape_as_markdown están disponibles en el nivel gratuito de Web MCP, lo que le ofrece la oportunidad de utilizarlas en agentes o flujos de trabajo de IA sin coste alguno.
Para integrar el Web MCP en su solución de IA, sólo necesita Node.js instalado localmente y un archivo de configuración como éste:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<SU_CLAVE_API_BRIGHT_DATA>"
}
}
}
}Por ejemplo, esta configuración funciona con Claude Desktop y Code (y muchas otras bibliotecas y soluciones de IA). Descubra otras integraciones en la documentación.
Alternativamente, puede conectarse a través del servidor remoto de Bright Data sin ningún requisito previo local.
Con esta integración, sus flujos de trabajo o agentes basados en IA podrán obtener de forma autónoma datos SERP de Baidu (u otros motores de búsqueda compatibles) y procesarlos sobre la marcha.
Conclusión
En este tutorial, ha explorado tres métodos recomendados para el scraping de Baidu:
- Uso de un Raspador personalizado.
- Aprovechando la API SERP de Baidu.
- A través del MCP de Bright Data Web.
Como se ha demostrado, la forma más fiable de scrapear Baidu a escala evitando bloqueos es utilizando una solución de scraping estructurada. Ésta debe estar respaldada por una tecnología avanzada anti-bot bypass y una red Proxy robusta, como los productos de Bright Data.
Cree una cuenta gratuita de Bright Data y empiece a explorar nuestras soluciones de scraping hoy mismo.




