

En esta extensa guía, hablaremos de:
- Las mejores bibliotecas de raspado web en C#
- Requisitos previos
- Raspado de sitios web de contenido estático en C#
- Raspado de sitios web de contenido dinámico en C#
- Qué Hacer con los Datos Extraídos
- Privacidad de Datos con Proxies
- Conclusión
Principales bibliotecas de raspado web en C#
El raspado web resulta más sencillo cuando se adoptan las herramientas adecuadas. Echemos un vistazo a las mejores bibliotecas NuGet de raspado web para C#:
HtmlAgilityPack: la biblioteca de raspado C# más popular.HtmlAgilityPackpermite descargar páginas web, analizar su contenido HTML, seleccionar elementos HTML y extraer datos de ellas.HttpClient: el cliente HTTP más popular de C#.HttpClientes particularmente útil cuando se trata de rastreo web (crawling), ya que permite realizar peticiones HTTP fácilmente y de forma asíncrona.Selenium WebDriveres una biblioteca compatible con varios lenguajes de programación que permite escribir pruebas automatizadas para aplicaciones web. También se puede utilizar para fines de raspado web.Puppeteer Sharpes el puerto C# de Puppeteer. Puppeteer Sharp proporciona capacidades de navegador headless (sin interfaz gráfica) y permite el raspado web de páginas con contenido dinámico.
En este tutorial, presentaremos la manera de raspar datos web usando C# con HtmlAgilityPack y Selenium.
Prerrequisitos para Raspado web con C#
Antes de escribir la primera línea de código del raspador web en C#, es necesario cumplir algunos requisitos previos:
- Visual Studio: la edición gratuita Community de Visual Studio 2022 será suficiente.
- .NET 6+: cualquier versión LTS superior o igual a 6 servirá.
Si no se cumple alguno de estos requisitos, hacer clic en el enlace anterior para descargar las herramientas y seguir el asistente de instalación para configurarlas.
Ya puede crear un proyecto de raspado web en C# en Visual Studio.
Configuración de un proyecto en Visual Studio
Abrir Visual Studio y hacer clic en la opción “Crear un nuevo proyecto”.
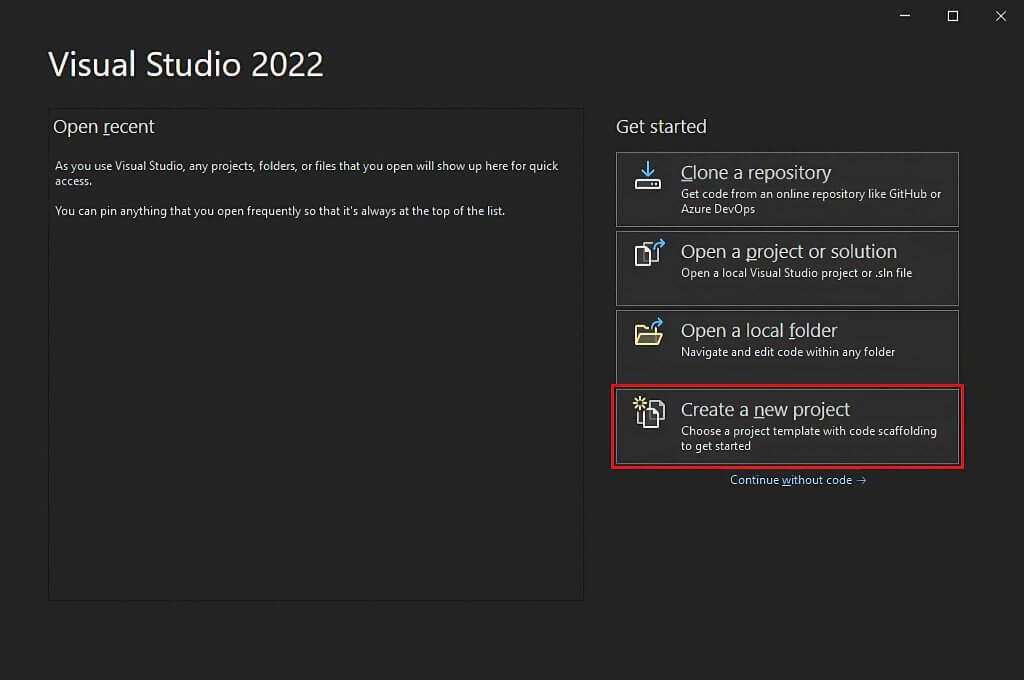
En la ventana “Crear un nuevo proyecto”, seleccionar la opción “C#” de la lista desplegable. Tras especificar el lenguaje de programación, seleccionar la plantilla “Console App” y hacer clic en “Siguiente”.
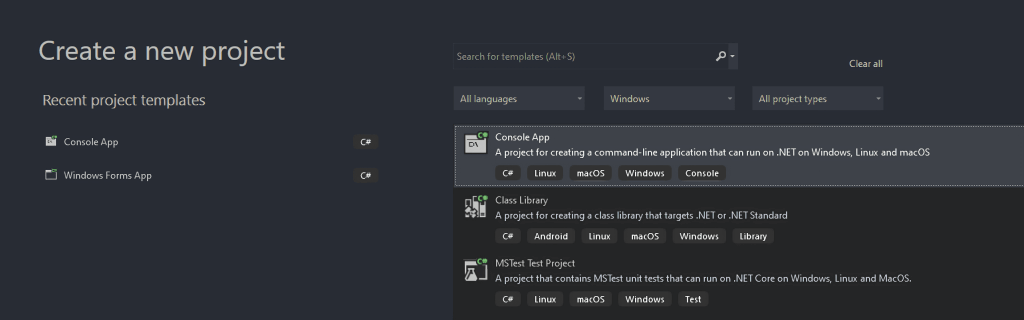
A continuación, llamar al proyecto StaticWebScraping, hacer clic en “Seleccionar” y elegir la versión .NET. Si ha instalado .NET 6.0, Visual Studio debería seleccionarla.
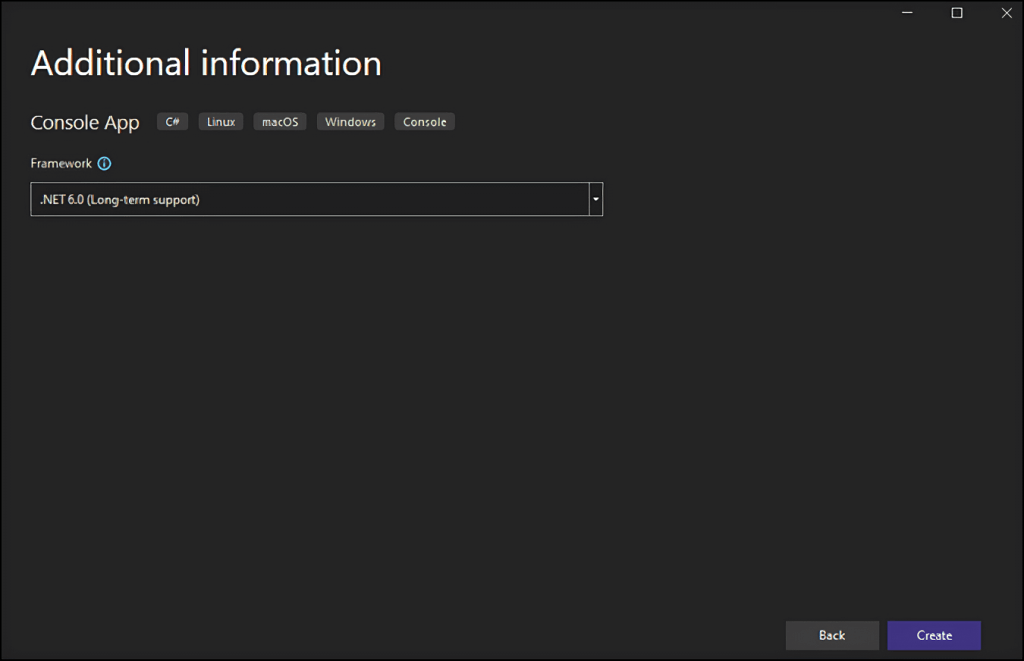
Hacer clic en el botón “Crear” para inicializar su proyecto de raspado web en C#. Visual Studio inicializará una carpeta StaticWebScraping que contendrá un archivo App.cs. Este archivo almacenará su lógica de raspado web en C#:
namespace WebScraping {
public class Program {
public static void Main() {
// scraping logic...
}
}
}
Es hora de aprender cómo crear un raspador web en C#.
Raspado de sitios web con contenido estático en C#
En los sitios web de contenido estático, el contenido de las páginas web ya está almacenado en los documentos HTML devueltos por el servidor. Esto significa que una página web de contenido estático no realiza peticiones XHR para recuperar datos ni requiere que se ejecute JavaScript.
El raspado de páginas web estáticas es bastante sencillo. Todo lo que se tiene que hacer es:
- Instalar una librería C# de raspado web
- Descargar la página web de destino y analizar su documento HTML
- Utilizar una biblioteca de raspado web para seleccionar los elementos HTML de interés.
- Extraer datos de ellos
Apliquemos todos estos pasos a la página de Wikipedia “Lista de episodios de Bob Esponja SquarePants“:

El objetivo del raspador web en C# que está a punto de construir es recuperar automáticamente todos los datos de los episodios de esa página de Wikipedia de contenido estático.
Comecemos.
Paso 1: Instalar HtmlAgilityPack
HtmlAgilityPack es una librería C# de código abierto que permite analizar documentos HTML, seleccionar elementos del DOM y extraer datos de ellos. Básicamente, HtmlAgilityPack ofrece todo lo necesario para raspar un sitio web de contenido estático.
Para instalarlo, hacer clic con el botón derecho del ratón en la opción “Dependencias” situada bajo el nombre del proyecto en el “Explorador de soluciones”. A continuación, seleccionar “Administrar paquetes NuGet”. En la ventana del gestor de paquetes NuGet, busque “HtmlAgilityPack”, y hacer clic en el botón “Instalar” en la sección derecha de la pantalla.
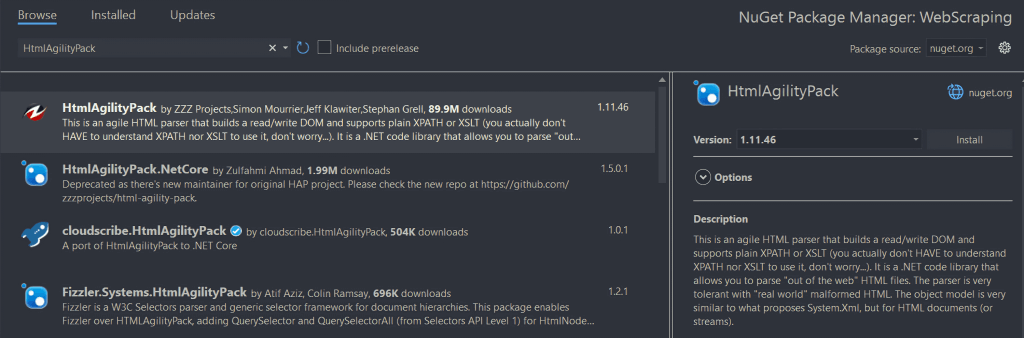
Una ventana emergente preguntará si está de acuerdo en realizar cambios en su proyecto. Hacer clic en “Aceptar” para instalar HtmlAgilityPack. Ahora es posible utilizarlo para realizar raspado web en C# en un sitio web estático.
Ahora, agregue la siguiente línea en la parte superior de su archivo App.cs para importar HtmlAgilityPack:
using HtmlAgilityPack;Paso 2: Cargar una Página Web HTML
Puede conectarse a la página web de destino con HtmlAgilityPack de la siguiente manera:
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
La instancia de la clase HtmlWeb le permite cargar una página web gracias a su método Load(). Entre bastidores, este método realiza una petición HTTP GET para recuperar el documento HTML asociado a la URL pasada como parámetro. Load() devuelve una instancia de HtmlAgilityPack HtmlDocument que usted puede utilizar para seleccionar elementos HTML de la página.
Paso 3: Seleccionar elementos HTML
Puede seleccionar elementos HTML de una página web con selectores XPath. En detalle, XPath le permite seleccionar uno o más elementos DOM específicos. Para obtener el selector XPath relacionado con un elemento HTML, haga clic con el botón derecho sobre él, abra las herramientas de inspección en su navegador, asegúrese de que está seleccionando el elemento DOM de interés, haga clic con el botón derecho sobre el elemento DOM y seleccione “Copiar XPath”.
El objetivo del raspador web C# es extraer los datos asociados a cada episodio. Por tanto, extraiga el selector XPath aplicando el procedimiento descrito anteriormente a un elemento episodio<tr>.
Esto devolverá:
//*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]
Tenga en cuenta que se desea seleccionar todos los elementos <tr>. Por lo tanto, es necesario cambiar el índice asociado con el elemento select row. No deseamos raspar la primera fila de la tabla, ya que sólo contiene los navegadores sin interfaz gráfica de la tabla. En XPath, los índices comienzan a partir de 1, por lo que se puede seleccionar todos los elementos <tr> de la primera tabla de episodios de la página añadiendo la sintaxis position()>1 XPath.
Además, se desea raspar los datos de todas las tablas de temporada. En la página de Wikipedia, las tablas que contienen datos sobre los episodios van de la segunda a la decimoquinta tabla HTML contenidas en el documento HTML. Así es como quedará la cadena XPath final:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Ahora se puede utilizar la función SelectNodes() ofrecida por HtmlAgilityPack para seleccionar los elementos HTML de interés como sigue:
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");Note que sólo puede llamar al método SelectNodes() en una instancia HtmlNode. Por lo tanto, necesita obtener el nodo HTML raíz del documento HTML con la propiedad DocumentNode.
Además, no olvide que los selectores XPath son sólo uno de los muchos métodos que tiene para seleccionar elementos HTML de una página web. Los selectores CSS son otra opción popular.
Paso 4: Extraer Datos de Elementos HTML
Primero, se requiere una clase personalizada donde almacenar los datos raspados. Cree un archivo Episode.cs en la carpeta WebScraping e inicialícelo como se indica a continuación:
namespace StaticWebScraping {
public class Episode {
public string OverallNumber { get; set; }
public string Title { get; set; }
public string Directors { get; set; }
public string WrittenBy { get; set; }
public string Released { get; set; }
}
}
Como puede ver, esta clase tiene cuatro atributos para almacenar toda la información más importante a raspar sobre un episodio. Observe que OverallNumber es una cadena porque el número de episodio en Bob Esponja siempre contiene un carácter.
Ahora, puede implementar la lógica de raspado web en C# en su archivo App.cs como se muestra a continuación:
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
namespace StaticWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
// selecting the HTML nodes of interest
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new List<Episode>();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = HtmlEntity.DeEntitize(node.SelectSingleNode("th[1]").InnerText),
Title = HtmlEntity.DeEntitize(node.SelectSingleNode("td[2]").InnerText),
Directors = HtmlEntity.DeEntitize(node.SelectSingleNode("td[3]").InnerText),
WrittenBy = HtmlEntity.DeEntitize(node.SelectSingleNode("td[4]").InnerText),
Released = HtmlEntity.DeEntitize(node.SelectSingleNode("td[5]").InnerText)
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
Este raspador web de C# recorre los nodos HTML seleccionados, crea una instancia de la clase Episode para cada uno de ellos y la almacena en la lista de episodios. Tenga en cuenta que los nodos HTML de interés son filas de una tabla. Por lo tanto, necesita seleccionar algunos elementos con el método SelectSingleNode(). A continuación, utilice el atributo InnerText para extraer de ellos los datos que desee raspar. Observe el uso de la función estática HtmlEntity.DeEntitize() para reemplazar los caracteres HTML especiales por sus representaciones naturales.
Paso 5: Exportar los datos raspados a CSV
Ahora que ha aprendido cómo hacer raspado web en C#, puede hacer lo que quiera con los datos raspados. Uno de los escenarios más comunes es convertir los datos raspados a un formato legible por humanos, como CSV. De este modo, cualquier miembro de su equipo podrá explorar los datos obtenidos directamente en Excel.
Veamos ahora cómo exportar datos del raspado a CSV con C#.
Para facilitar las cosas, vamos a utilizar una biblioteca. CSVHelper es una biblioteca .NET rápida, fácil de usar y potente para leer y escribir archivos CSV. Para añadir la dependencia de CSVHelper, abra la sección “Manage NuGet Packages” en Visual Studio, busque “CSVHelper” e instálelo.
Puede utilizar CSVHelper para convertir nuestros datos raspados en CSV como se indica a continuación:
using CsvHelper;
using System.IO;
using System.Text;
using System.Globalization;
// scraping logic…
// initializing the CSV file
using (var writer = new StreamWriter("output.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(episodes);
}
Si no se ha familiarizado con la palabra clave using, ésta define un ámbito al final del cual se eliminarán los objetos que contiene. En otros términos, using es ideal para tratar con recursos de archivo. A continuación, la función WriteRecords() CSVHelper se encarga de convertir automáticamente los datos raspados en CSV y escribirlos en el archivo output.csv.
Tan pronto como su raspador web en C# termine de ejecutarse, verá aparecer un archivo output.csv en la carpeta raíz del proyecto. Ábralo en Excel y verá los siguientes datos:
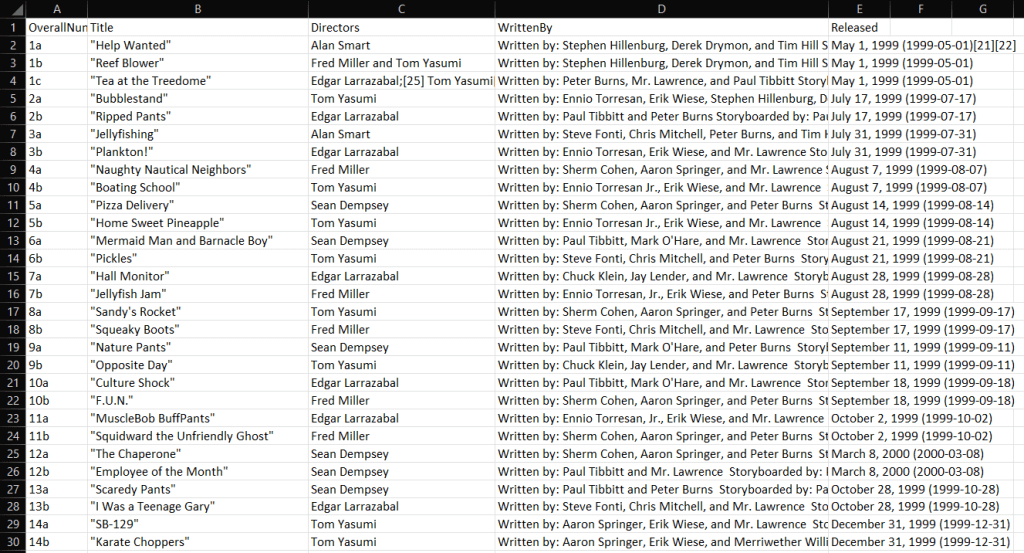
¡Et voilà! Ahora sabe cómo realizar raspado web con C# en sitios web de contenido estático.
Raspado de sitios web de contenido dinámico en C#
Los sitios web de contenido dinámico utilizan JavaScript para recuperar datos de forma dinámica a través de la tecnología AJAX. Los documentos HTML asociados a las páginas de contenido dinámico pueden estar básicamente vacíos. Al mismo tiempo, contienen scripts JavaScript que se encargan de recuperar y renderizar datos dinámicamente, en tiempo de renderizado. Esto significa que, para extraer datos de ellos, se necesita un navegador que renderice sus páginas. La razón es que sólo un navegador puede ejecutar JavaScript.
El raspado de sitios web dinámicos puede ser complicado y es definitivamente más difícil que el de los estáticos. En concreto, se necesita un navegador sin interfaz gráfica (headless) para raspar este tipo de sitios web. Si no se conoce esta tecnología, un navegador headless es un navegador sin interfaz gráfica de usuario. En otros términos, si requiere raspar sitios web de contenido dinámico en C#, necesita una librería que proporcione capacidades de navegador headless, como Selenium.
Siga el párrafo presentado al principio del artículo para configurar un nuevo proyecto en C#. Esta vez, llámelo DynamicWebScraping.
Paso 1: Instalar Selenium
Selenium es un framework de código abierto para pruebas automatizadas que soporta varios lenguajes de programación. Selenium proporciona capacidades de navegador sin interfaz gráfica y permite instruir a un navegador web para realizar acciones específicas.
Para añadir Selenium a las dependencias de un proyecto, consultar de nuevo la sección “Manage NuGet Packages”, buscar “Selenium.WebDriver” e instalar.
Importe Selenium añadiendo estas dos líneas en la parte superior de su archivo App.cs:
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
Paso 2: Conéctese al sitio web de destino
Dado que Selenium abre el sitio web de destino en un navegador, no es necesario realizar manualmente una solicitud HTTP GET. Todo lo que es necesario hacer es utilizar el controlador web de Selenium como se indica a continuación:
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
Aquí se ha creado una instancia del controlador web de Chrome. Si utiliza otro navegador, adapte el código en consecuencia utilizando el controlador de navegador adecuado. A continuación, gracias al método Navigate() de la variable del controlador, puede llamar al método GoToUrl() para conectarse a la página web de destino. En detalle, esta función acepta un parámetro URL y lo utiliza para visitar la página web asociada a la URL en el navegador headless.
Paso 3: Extraer datos de elementos HTML
Tal como se vio anteriormente, puede utilizar el siguiente selector XPath para seleccionar los elementos HTML de interés:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Utilizar un selector XPath en Selenium con:
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
En concreto, el método Selenium By.XPath() permite aplicar una cadena XPath para seleccionar elementos HTML del DOM de la página.
Ahora, supongamos que ya se ha definido una clase Episode.cs como antes bajo el espacio de nombres DynamicWebScraping. Ahora se puede construir un raspador web en C# con Selenium como se muestra a continuación:
using System;
using System.Collections.Generic;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace DynamicWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
// selecting the HTML nodes of interest
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = node.FindElement(By.XPath("th[1]")).Text,
Title = node.FindElement(By.XPath("td[2]")).Text,
Directors = node.FindElement(By.XPath("td[3]")).Text,
WrittenBy = node.FindElement(By.XPath("td[4]")).Text,
Released = node.FindElement(By.XPath("td[5]")).Text
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
Como se puede ver, la lógica de raspado web no cambia mucho en comparación con lo que se hace con HtmlAgilityPack. En detalle, gracias a los métodos FindElements() y FindElement() de Selenium, se puede lograr el mismo objetivo de raspado web que antes. Lo que realmente cambia es que Selenium realiza todas estas operaciones en un navegador.
Tenga en cuenta que en los sitios web de contenido dinámico, es posible que tenga que esperar a que los datos se recuperen y rendericen. Puede conseguirlo con WebDriverWait.
¡Felicitaciones! Ha aprendido a realizar raspado web con C# en sitios web de contenido dinámico. Sólo queda aprender qué hacer con los datos raspados.
Qué hacer con los datos raspados
- Almacenarlos en una base de datos para consultarlos cuando lo necesite.
- Convertirlos en JSON y usarlos para llamar algunas APIs.
- Transformarlos en formatos legibles por humanos, como CSV, para abrirlos con Excel.
Estos son sólo algunos ejemplos. Lo que realmente importa es que una vez que tiene los datos raspados en el código, puede utilizarlos como desee. Normalmente, los datos raspados se convierten en un formato más útil para su equipo de marketing, análisis de datos o ventas.
Pero tenga en cuenta que el raspado web conlleva varios retos.
Privacidad de los datos con proxies
Si quiere evitar exponer su IP, ser bloqueado y proteger su identidad, considere la posibilidad de adoptar proxies para el raspado web. Un servidor proxy actúa como una pasarela entre su aplicación y el servidor del sitio web de destino, ocultando así su IP.
Como resultado, un servicio proxy le permite superar los bloqueos de IP, recopilar datos de forma anónima y desbloquear contenidos en todos los países. Hay diferentes tipos de proxy, y todos tienen diferentes casos de uso y propósitos. Asegúrese de elegir el proveedor de proxy adecuado.
Analicemos ahora las ventajas que los proxies web pueden aportar a su proceso de raspado web.
Evite la prohibición de IP
Cuando su aplicación de raspado web intenta acceder a un sitio web en Internet, la dirección IP de la que procede la solicitud es pública. Esto significa que los sitios web pueden hacer un seguimiento y bloquear a los usuarios que realicen demasiadas solicitudes. De esto trata la detección de bots. Si utiliza un proxy web, el servidor de destino verá la IP del proxy rotatorio, no la suya. Por lo tanto, con los proxies, podemos eludir fácilmente las prohibiciones de IP.
Direcciones IP rotativas
Los proxies Premium generalmente ofrecen funciones de rotación de IP. Esto significa que cada vez que se contacta con el servidor proxy, se brinda una nueva dirección IP de un gran grupo de IPs. Esto es genial para evitar que los sistemas antiraspado le rastreen.
Raspado web regional
Muchos sitios web cambian su información en función de la procedencia de la solicitud. Además, algunos de ellos sólo están disponibles en determinadas regiones. El raspado de estos sitios web para realizar estudios de mercado en todo el mundo puede ser un problema. Por suerte, puede utilizar proxies anónimos para seleccionar la ubicación de la dirección IP de salida. Esta es una gran manera de recopilar información valiosa sobre productos de sitios web internacionalizados.
Conclusión
Ha aprendido cómo construir un raspador web usando C#. Como ha notado, esto no requiere demasiadas líneas de código. Por otra parte, cuando sus páginas web de destino cambien, tendrá que actualizar el raspador en consecuencia. Algunos sitios web realizan cambios en su estructura a diario. Por este motivo, convendría probar un IDE de raspador web avanzado. Los raspadores de Bright Data siempre están actualizados, por lo que puede concentrarse en los datos en lugar de configurar su raspador una y otra vez.




