


Descubra la API (Beta)
Los agentes de IA están evolucionando desde interfaces de chat a sistemas autónomos que ejecutan flujos de trabajo empresariales críticos. Para confiar en ellos, necesitan pruebas verificables más amplias y profundas de la web en vivo, no una lista superficial de enlaces.
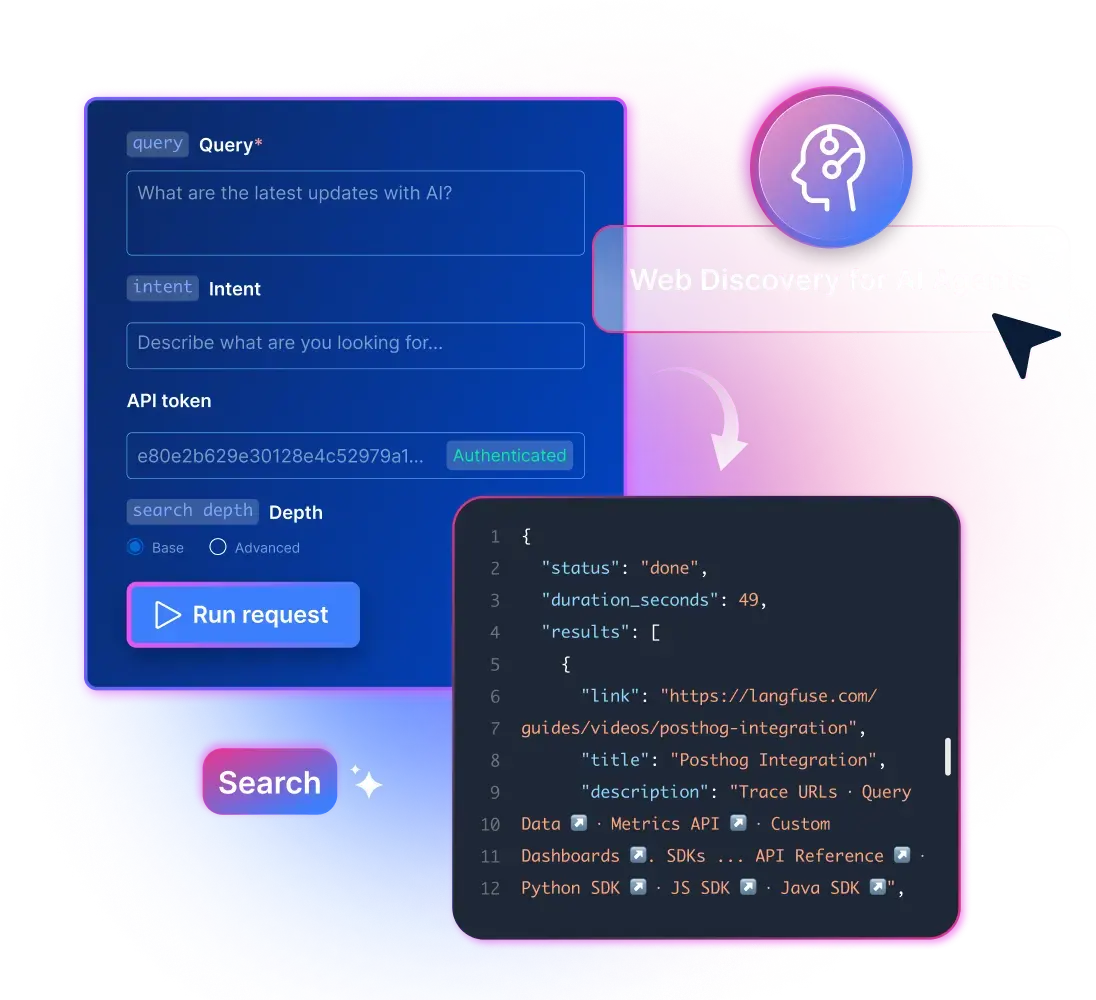
- Recuperación siempre en directo desde
la web. - Hasta 1000 resultados por solicitud
- Clasificado para la intención «
» (aprender a hacer). - Diseñado para cargas de trabajo de traducción paralela (
).
Navega por cualquier sitio web como lo haría un humano.
Priorice las fuentes que se ajusten a la tarea, no las que ganen en SEO.
Recupera hasta 1000 resultados sin lógica de paginación manual.
Reduzca el riesgo de rutas obsoletas almacenadas en caché o indexadas.
Texto fuente Markdown limpio opcional para verificación y RAG.
Diseñado para un alto rendimiento y cargas de trabajo de agentes paralelos.
Por qué los agentes utilizan DiscoverLos motores de búsqueda son para humanos. Las API de búsqueda están optimizadas para la velocidad y los enlaces principales. Discover está diseñado para flujos de trabajo conscientes del mercado que requieren frescura, alta recuperación y contexto verificable.
Priorice las fuentes que se ajusten a la tarea, no las que ganen en SEO.
Recupera hasta 1000 resultados sin lógica de paginación manual.
Reduzca el riesgo de rutas obsoletas almacenadas en caché o indexadas.

Texto fuente Markdown limpio opcional para verificación y RAG.

Diseñado para un alto rendimiento y cargas de trabajo de agentes paralelos.

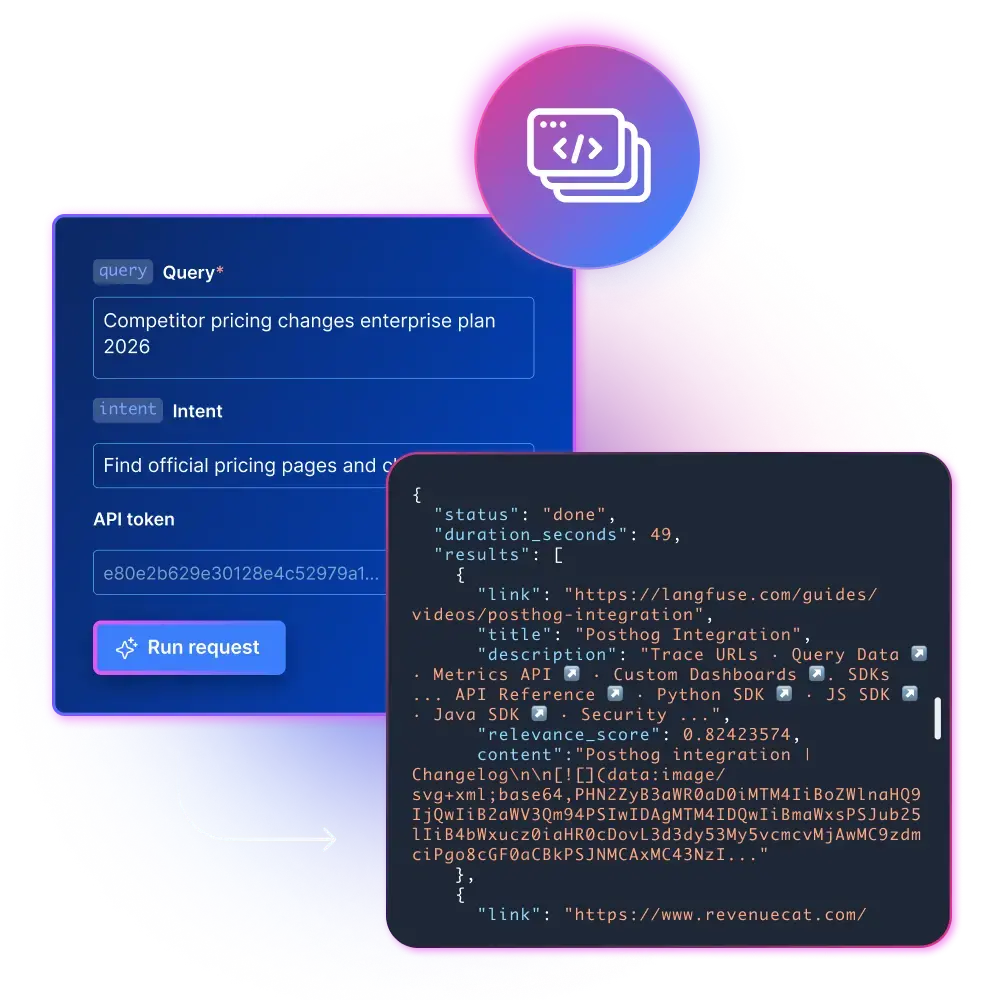
`POST https://api.brightdata.com/discover`
```bash
curl "https://api.brightdata.com/discover"
-H "Authorization: Bearer "
-H "Content-Type: application/json"
-d '{
"query": "competitor pricing changes enterprise plan 2026",
"num_results": 50,
"intent": "find official pricing pages and change notes",
"content": true,
"format": "markdown"
}'
require('request-promise')({
url: 'https://geo.brdtest.com/mygeo.json',
proxy: 'http://brd-customer-[tu ID de cliente]-zona-residential:"[tu contraseña]"@brd.superproxy.io:33335',
})
.then(function(data){ console.log(data); },
function(err){ console.error(err); });
import requests
url = "https://api.brightdata.com/conjuntos-de-datos/snapshots/{id}/download"
headers = {"Authorization": "Bearer "}
response = requests.get(url, headers=headers)
print(response.json())
using System;
using System.Net;
class Example
{
static void Main()
{
// Reemplaza «[tu ID de cliente]» y «[tu contraseña]» con tus credenciales reales
var client = new WebClient();
client.Proxy = new WebProxy("brd.superproxy.io:33335");
client.Proxy.Credentials = new NetworkCredential("brd-customer-[su ID de cliente]-Zona-residencial", "[su contraseña]");
Console.WriteLine(client.DownloadString("https://geo.brdtest.com/mygeo.json"));
}
}
Inicio rápido
Diseñado para la inteligencia de mercado

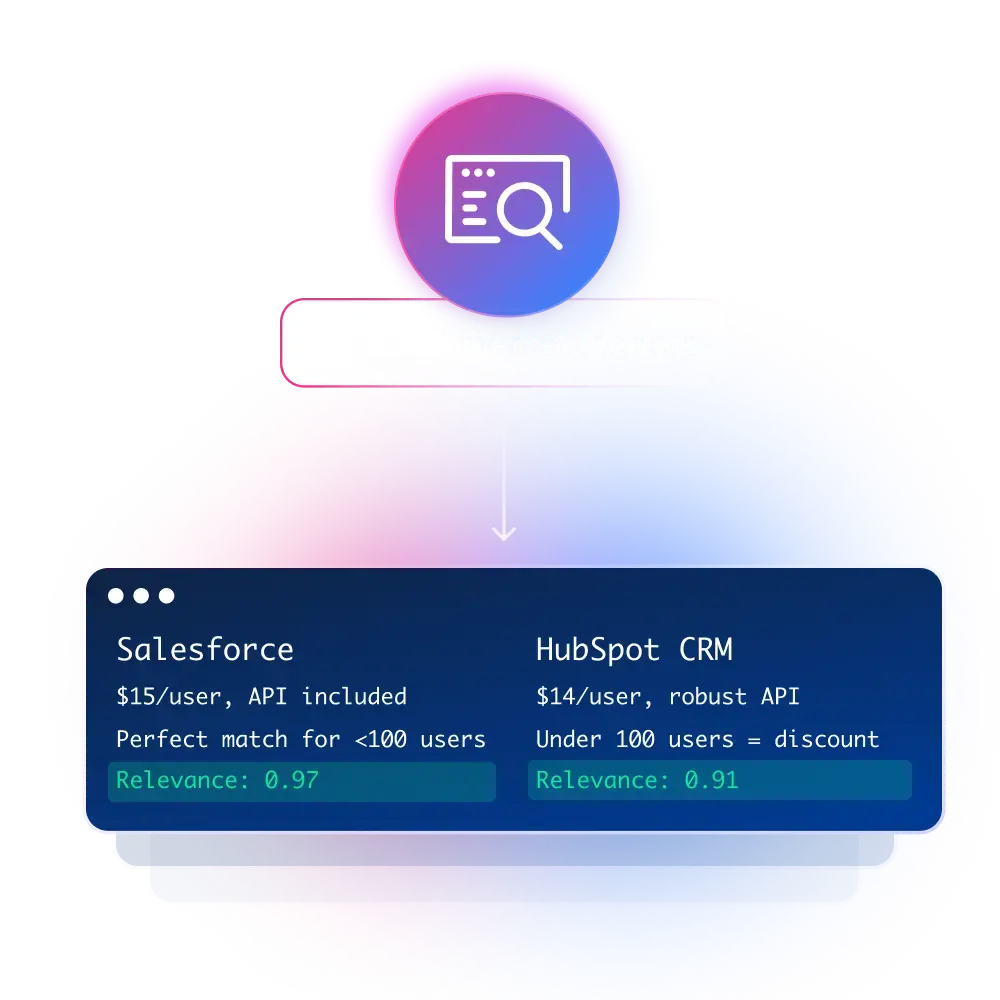
Inteligencia competitiva
Realice un seguimiento de los precios, los lanzamientos y los cambios de posicionamiento.

Supervisión de riesgos
Detecte incidentes, cambios en las políticas y señales.

Diligencia debida
Verifique las afirmaciones en muchas fuentes independientes.

Enriquecimiento
Rellene el CRM con datos web en tiempo real verificados.

Motores de búsqueda verticales
Cree una búsqueda clasificada por intención para un dominio.

Datos alternativos
Captura señales de cola larga en toda la web.
Diseñado para funcionar con los Conjuntos de datos de Bright Data
Utilice Discover para el descubrimiento en tiempo real y la obtención de pruebas recientes. Utilice los Conjuntos de datos de Bright Data para obtener una base de referencia y una recuperación más rápida a gran escala. Para necesidades de datos grandes y repetibles, los Conjuntos de datos son más rentables que redescubrir las mismas entidades una y otra vez, y proporcionan a su agente un punto de partida más sólido antes de realizar el descubrimiento en tiempo real.
Preguntas frecuentes
¿Discover está almacenado en caché o indexado?
Discover está siempre activo. Cada solicitud se ejecuta en el momento de la consulta en la web activa.
¿Qué hace la intención?
La intención indica a Discover lo que el agente está tratando de lograr, de modo que los resultados se clasifican para la tarea.
¿Cuándo debo utilizar include_content?
Utilice include_content=true cuando necesite verificación o fundamentación RAG con el texto de origen.
¿Debo utilizar Discover o Conjuntos de datos?
Utilice Conjuntos de datos para la cobertura básica. Utilice Discover para el descubrimiento en tiempo real y las pruebas recientes. La mayoría de los equipos utilizan ambos.
¿Puedo realizar investigaciones o seguimientos históricos?
Utilice la API de Web Archive para el relleno histórico y la supervisión longitudinal.
¿Qué ocurre si necesito más de 1000 resultados?
Encadenar varias llamadas a Discover o utilizar Conjuntos de datos para la ingesta masiva y, a continuación, utilizar Discover para mantenerlo actualizado.
Empieza gratis
Hable con un experto para analizar las necesidades de su agente.