

- Scraper basado en API
Utilice nuestra interfaz para crear su solicitud de API - Automatización a escala
Cree su propio programador para controlar la frecuencia - Entrega
Entregue los datos a su almacenamiento preferido o descárguelos



API de Web Scraper
La API de scraping web más fiable. Extraiga datos de cualquier sitio web con rotación automática de proxies, bypass anti-bot y renderización de JavaScript. Empiece con más de 120 scrapers listos para usar para las plataformas más populares.
No se requiere tarjeta de crédito

1238 scrapers
- Recopile datos en tiempo real a través de API.
- Pague solo por los resultados entregados con éxito.
- Gestión de solicitudes masivas, hasta 5000 URL.
- Recupera los resultados en múltiples formatos
Confiado por 20,000+ clientes
Scrape web data effortlessly

API de rastreadores web
Biblioteca API de Web Scraper
Elimine la necesidad de desarrollar y mantener la infraestructura. Simplemente extraiga grandes volúmenes de datos web y garantice la escalabilidad y la fiabilidad utilizando nuestra API Web Scraper.
LinkedIn people profiles
ID, Name, City, Country code, Position, About, Posts, Current company, and more.
 117.4K+
117.4K+ 11K+
11K+Amazon products
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by best sellers category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific keywords
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - find products by using upc numbers
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
LinkedIn company information
ID, Name, Country code, Locations, Followers, Employees in linkedin, About, Specialties, and more.
Instagram - Profiles
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Instagram - Profiles - Collect profile information by user name
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Crunchbase companies information
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Crunchbase companies information - Searching data by keyword
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Linkedin job listings information
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover new jobs by keyword
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover jobs by company URL
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Instagram - Posts
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Instagram - Posts - Collects posts from a specific URLs by using profile URL
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Google Maps full information
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - discover records by location search
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Collect Google Maps Businesses data by place id
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Discover new records by Customer ID
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Zillow properties listing information
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Discover by custom filters - location, home type and status
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Search by parameters on zillow and use the direct link as input
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
LinkedIn posts
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover user's articles by URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover posts by Profile URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover new posts company URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
X (formerly Twitter) - Posts
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Collecting Twitter posts URLs
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Getting x posts by array of profiles
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
TikTok - Profiles
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
TikTok - Profiles - Discover by search URL and country
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
Youtube - Videos posts
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search new youtube videos by keyword
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discover videos by channel URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search videos by keyword and then apply relevant video filters
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Collect YouTube posts by hashtags
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery records by Explore page URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery videos by podcast url
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Amazon Reviews
URL, Product name, Product rating, Product rating object, Product rating max, Rating, Author name, Asin, and more.
TikTok - Posts
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Input specific profile URL to get posts published by it
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Search posts by specific keyword or hashtag
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - discover new records by TikTok discover URL
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Facebook - Pages Posts by Profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Indeed job listings information
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Collect new jobs by keyword search in specific location
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Discover jobs by company URL
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Walmart - products
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Find new products by using specific category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Collects products by specific keywords
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Discover products by using sku numbers
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
TikTok Shop
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - category
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - Collect TikTok shop products by keywords search
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - discover records by shop url
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
YouTube - Channels
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
YouTube - Channels - Collects channel by keyword related to the channel or video's of the channel
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
Reddit- Posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover Reddit posts by Subreddit URL
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discovery by keyword of Reddit posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover posts by author
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Glassdoor companies overview information
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - Search for companies by keyword
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover new companies by input filters
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover by search url
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Google maps reviews
URL, Place id, Place name, Country, Address, Review id, Reviewer name, Reviews by reviewer, and more.
Instagram - Reels
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Discover reels video from Instagram profile or direct search url
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Collect all Reels from Instagram profiles (without the post timestamp)
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Airbnb Properties Information
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Search Airbnb by location
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Discover by search url
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
X (formerly Twitter) - Profiles
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
X (formerly Twitter) - Profiles - Collect profile information by user name
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Glassdoor companies reviews
Overview id, Review id, Review url, Rating date, Count helpful, Count unhelpful, Employee job end year, Employee length, and more.
Booking Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings -
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Yahoo Finance business information
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Yahoo Finance business information - Discover records by keyword
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Instagram - Comments
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
Precios de la API de raspado de Las de Web
Solo paga por lo que se entrega con éxito. Sin tarifas ocultas, sin cargos por entregas fallidas.
Obtén un 25% de descuento en Scraper API durante 3 meses. Usa el código APIS25 al pagar.
Aceitamos esses métodos de pagamento:
Cada plan te da acceso completo - paga menos por registro a medida que escalas
Recolección de Datos
- Gestión automatizada de proxies
- Renderizado completo del navegador
- Resolución CAPTCHA
Rendimiento a escala
- Concurrencia ilimitada
- Recolección por lotes y programada
- APIs de gestión de trabajos
Entrega de datos
- Validación y descubrimiento de datos
- Análisis de datos (JSON o CSV)
- Entrega por webhook o API
Demo de la API del raspador web
Proxy-Based Scraper vs. Web Scraper API
 Monitoreo y mantenimiento
Monitoreo y mantenimiento Infraestructura de raspador
Infraestructura de raspador Análisis
Análisis Tiempo de comercialización
Tiempo de comercialización Eficiencia de costos
Eficiencia de costosCODE EXAMPLES
Puntos finales dedicados para más de 100 dominios.
Entrada
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.linkedin.com/in/elad-moshe-05a90413/"},{"url":"https://www.linkedin.com/in/jonathan-myrvik-3baa01109"},{"url":"https://www.linkedin.com/in/aviv-tal-75b81/"},{"url":"https://www.linkedin.com/in/bulentakar/"},{"url":"https://www.linkedin.com/in/nnikolaev/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l1viktl72bvl7bjuj0&format=json&uncompressed_webhook=true"
Salida
JSON
[
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "ane***-ka***m-8*********",
"name": "aneesa k****m",
"city": "South Africa",
"country_code": "ZA",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "lil***ia-***b0a******",
"name": "Lili ***",
"city": "Algeria",
"country_code": "DZ",
"position": "Aide chez Citi",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "ber***is-***y-8*********",
"name": "berkhais m**y",
"city": "Nabeul, Tunisia",
"country_code": "TN",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "san***p-k***r-y*********eep******************",
"name": "sandeep k***r y***v s*****p k***r",
"city": "Kakori, Uttar Pradesh, India",
"country_code": "IN",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "mar***n-s***iag*********69",
"name": "Maryann S******o",
"city": "Philippines",
"country_code": "PH",
"position": "Supervisor Assistant at SMK Electronics",
"about": null
}
]
Entrada
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","asin":"B0CRMZHDG8","origin_url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","zipcode":"94107","language":""},{"url":"https://www.amazon.com/KitchenAid-Protective-Dishwasher-Stainless-8-72-Inch/dp/B07PZF3QS3","asin":"B07PZF3QS3","zipcode":"","language":""},{"url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","asin":"","origin_url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","zipcode":"94124","language":""}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l7q7dkf244hwjntr0&format=json&uncompressed_webhook=true"
Salida
JSON
[
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Retro Wildwood New Jersey Waves Sun Ocean Beach NJ Vacation T-Shirt",
"seller_name": "Ama***.co***",
"brand": "Wildwood NJ Design Co",
"description": "Retro Wildwood New Jersey Waves Sun Ocean Beach NJ Vacation Design. Buy This For Yourself Or Someone Who Loves To Vacati...",
"initial_price": 19.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "SP Hydrate Shampoo 500ml",
"seller_name": "Glo***Hai***",
"brand": "Wella Professionals",
"description": "Produktbeschreibung SP Hydrate Shampoo 500ml Gebrauchsanweisung Das Shampoo auf nasses Haar auftragen, sanft einmassiere...",
"initial_price": 14.88,
"currency": "EUR"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Jewelry Making for Beginners: A Step-by-Step Guide to Wirework, Stone Setting, Chainmaille, Clasps, Mixed Media, Finishi...",
"seller_name": null,
"brand": "Annika Blake",
"description": "Jewelry Making for BeginnersTurn simple materials into beautiful, wearable creations with confidence.Jewelry Making for ...",
"initial_price": 4.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Sound Dampening Foam Panels, 6 Pack 48\u0022 x 24\u0022 x 2\u0022 High Density Egg Crate Foam, Acoustic Sound Proofing Wall Panels for ...",
"seller_name": "Xinyang J****i T*****g C**, L**.",
"brand": "Evovoce",
"description": "About this item Noise Reduction Panels:Evovoce egg crate foam panels help reduce echo, reverberation, and reflected soun...",
"initial_price": 79.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "51mm Coffee Distributor, Tamper Leveler Espresso Tamper,Coffee Distribution Tool Adjustable Height,Espresso Accessories ...",
"seller_name": "FAN***SI",
"brand": "Fixiooz",
"description": "51mm Coffee Distributor",
"initial_price": 16.99,
"currency": "USD"
}
]
Entrada
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.zillow.com/homedetails/2506-Gordon-Cir-South-Bend-IN-46635/77050198_zpid/?t=for_sale"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lfqkr8wm13ixtbd8f5&format=json&uncompressed_webhook=true"
Salida
JSON
[
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 120742808,
"city": "Charleston",
"state": "SC",
"homeStatus": "RECENTLY_SOLD",
"address:city": "Charleston",
"address:streetAddress": "1119 Oak Overhang St"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 447697956,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "4091 Briars Creek Ln"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 10861113,
"city": "Johns Island",
"state": "SC",
"homeStatus": "OTHER",
"address:city": "Johns Island",
"address:streetAddress": "4966 Green Dolphin Way"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 110231160,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "55 Cotton Hall"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 10857946,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "1374 Dunlin Ct"
}
]
Entrada
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.instagram.com/p/Cuf4s0MNqNr"},{"url":"https://www.instagram.com/p/DP861NijuwE"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lk5ns7kz21pck8jpis&format=json&uncompressed_webhook=true"
Salida
JSON
[
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DREdllLDePe",
"user_posted": "paulziemiak",
"description": "Viva Polonia an Rhein und Ruhr! \n 🇩🇪 🇵🇱 \n\nWusstet ihr, dass Millionen Menschen in Nordrhein-Westfalen polnische Vorf...",
"hashtags": [
"#NRW."
],
"num_comments": 11,
"date_posted": "2025-11-15T08:03:54.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DJeauFvT6GZ",
"user_posted": "theindianidiot",
"description": "🙏🏾",
"hashtags": null,
"num_comments": 350,
"date_posted": "2025-05-10T13:47:56.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/reel\/DQwBJGXCEbg",
"user_posted": "gretchenrole",
"description": "+32 🎂 \n#harrypotter #harrypottercake",
"hashtags": [
"#harrypotter",
"#harrypottercake"
],
"num_comments": 123,
"date_posted": "2025-11-07T08:49:40.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/reel\/DQpbapXjtak",
"user_posted": "bb.realestates",
"description": "Wie läuft die Vermarktung in Zusammenarbeit mit Berenfänger \u0026 Bechtold ab?👨🏻💻\n\n#bbrealestate #berenfaengerbechtold #...",
"hashtags": [
"#bbrealestate",
"#berenfaengerbechtold",
"#immobilien",
"#architecture",
"#realestate",
"#luxuryhomes",
"#interior",
"#immobilienmakler"
],
"num_comments": 0,
"date_posted": "2025-11-04T20:06:25.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DQN2K_UgRU0",
"user_posted": "eluniversalmx",
"description": "Con una sonrisa en el rostro y saludando al público, Pato entró con un saco de color negro con distintos diseños que rea...",
"hashtags": null,
"num_comments": 0,
"date_posted": "2025-10-25T03:00:30.000Z"
}
]
LA MEJOR EXPERIENCIA DIGITAL
Fácil de empezar. Más fácil aún de ajustar.
Estabilidad inigualable
Asegúrate de que el rendimiento sea uniforme y de que se minimicen los fallos al confiar en la infraestructura de proxy que es líder mundial.
Extracción web simplificada
Pon tu herramienta de raspado web en automático gracias a API que están listas para funcionar, de manera que ahorras recursos y reduces el mantenimiento.
Capacidad ilimitada para ajustar la escala
Ajusta la escala de tus proyectos de raspado sin ningún problema para poder satisfacer las demandas de datos y para mantener un rendimiento óptimo.
USO MÁS RÁPIDO
Un toque de la API. Toneladas de datos.
Descubrimiento de datos
Detectar estructuras y patrones de datos para garantizar una extracción de datos eficiente y concreta.
Gestión de solicitudes masivas
Reducir la carga del servidor y optimizar la recopilación de datos para las tareas de raspado de gran volumen.
Análisis de datos
Convertir de forma eficiente el HTML sin procesar en datos estructurados, lo que facilita la integración y el análisis de los datos.
Validación de datos
Garantizar la fiabilidad de los datos y ahorrar tiempo en las comprobaciones manuales y en el procesamiento previo.
BAJO EL CAPÓ
Nunca más te preocupes por los proxies y los CAPTCHAs
- Rotación automática de IP
- Resolución de CAPTCHA
- Rotación de agente de usuario
- Encabezados personalizados
- Renderizado de JavaScript
- Proxies residenciales
Cada 15 minutos, nuestros clientes recopilan datos suficientespara entrenar ChatGPT desde cero.
API para acceso fluido a datos de Las de Web
Extracción de datos web integral, escalable y compatible
API para acceso fluido a datos de Las de Web
Extracción de datos web integral, escalable y compatible
Adaptado a tu flujo de trabajo
Obtén datos estructurados en archivos JSON, NDJSON o CSV mediante entrega por Webhook o API.
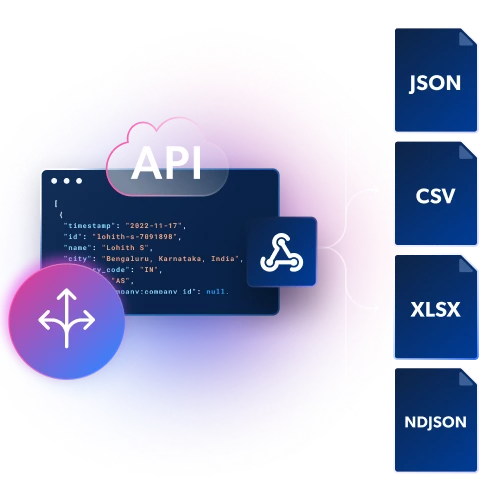
Infraestructura y desbloqueo integrados
Obtén el máximo control y flexibilidad sin mantener infraestructura de Proxy y desbloqueo. Extrae datos fácilmente desde cualquier ubicación geográfica evitando CAPTCHAs y bloqueos.

Infraestructura probada en batalla
La plataforma de Bright Data impulsa a más de 20.000 empresas en todo el mundo, ofreciendo tranquilidad con un tiempo de actividad del 99,99% y acceso a más de 150 millones de IPs reales de usuarios en 195 países.

Cumplimiento líder en la industria
Nuestras prácticas de privacidad cumplen con las leyes de protección de datos, incluido el marco regulatorio de protección de datos de la UE, el GDPR y la CCPA.

API para acceso fluido a datos de Las de Web
Extracción de datos web integral, escalable y compatible
FLEXIBLE
Adaptado a tu flujo de trabajo
Obtén datos estructurados en archivos JSON, NDJSON o CSV mediante entrega por Webhook o API.ESCALABLE
Infraestructura y desbloqueo integrados
Obtén el máximo control y flexibilidad sin mantener infraestructura de Proxy y desbloqueo. Extrae datos fácilmente desde cualquier ubicación geográfica evitando CAPTCHAs y bloqueos.ESTABLE
Infraestructura probada en batalla
La plataforma de Bright Data impulsa a más de 20.000 empresas en todo el mundo, ofreciendo tranquilidad con un tiempo de actividad del 99,99% y acceso a más de 150 millones de IPs reales de usuarios en 195 países.COMPATIBLE
Cumplimiento líder en la industria
Nuestras prácticas de privacidad cumplen con las leyes de protección de datos, incluido el marco regulatorio de protección de datos de la UE, el GDPR y la CCPA.CASOS DE USO
API de scraper para cada caso de uso





Preguntas frecuentes sobre la API de Web Scraper
¿Qué son las API de Web Scraper?
Web Scraper APIs es un servicio basado en la nube que simplifica la extracción de datos web, ofreciendo un manejo automatizado de la rotación de IP, la Resolución de CAPTCHA y el Parseo de datos en formatos estructurados. Permite una recopilación de datos eficiente y escalable, adaptada a las empresas que necesitan acceder a datos web valiosos de forma fluida.
¿Quién puede beneficiarse del uso de las API de Web Scraper?
Los analistas de datos, científicos, ingenieros y desarrolladores que buscan métodos eficientes para recopilar y analizar datos web para Datos para IA, ML, big data y más encontrarán las API de Web Scraper especialmente beneficiosas.
¿Por qué elegir las API de Web Scraper en lugar de los métodos de scraping manuales?
Las API de Web Scraper superan las limitaciones del Scraping web manual, como lidiar con los cambios en la estructura de los sitios web, encontrar bloqueos y captchas, y los altos costes asociados al mantenimiento de la infraestructura. Ofrecen una solución automatizada, escalable y fiable para la extracción de datos, lo que reduce significativamente los costes operativos y el tiempo.
¿Qué hace que las API de Web Scraper de Bright Data sean únicas en el mercado?
La singularidad de las API de Web Scraper reside en sus características especializadas, como el manejo de solicitudes masivas, el descubrimiento de datos y la validación automatizada, respaldadas por tecnologías avanzadas que incluyen proxies residenciales y renderización JavaScript. Estas capacidades garantizan un amplio acceso, mantienen una alta integridad de los datos y mejoran la eficiencia general, lo que distingue a las API de Scraper en el panorama competitivo.
¿Cómo puedo empezar a utilizar las API de Web Scraper?
Comenzar a utilizar las API de Web Scraper es muy sencillo a través del panel de control de Bright Data, que proporciona documentación completa y un panel de control fácil de usar para la gestión y configuración de claves API. Este enfoque minimiza los requisitos de configuración, lo que permite el acceso inmediato a una plataforma altamente escalable y fiable para las necesidades de extracción de datos web.
¿Para qué casos de uso específicos están optimizadas las API de Web Scraper?
Las API de Web Scraper admiten una amplia gama de necesidades de desarrollo, incluyendo comparativas competitivas, análisis de tendencias de mercado, algoritmos de precios dinámicos, extracción de opiniones y alimentación de datos en procesos de aprendizaje automático. Esenciales para el comercio electrónico, la tecnología financiera y el análisis de redes sociales, estas API permiten a los desarrolladores implementar estrategias basadas en datos de forma eficaz.
¿Cómo gestionan las API de Web Scraper las tareas de extracción de datos a gran escala?
Con capacidades para una alta concurrencia y procesamiento por lotes, las API de Scraping web destacan en escenarios de extracción de datos a gran escala. Esto garantiza que los desarrolladores puedan escalar sus operaciones de scraping de manera eficiente, acomodando grandes volúmenes de solicitudes con un alto rendimiento.
¿En qué formatos de datos pueden proporcionar la información extraída las API de Web Scraper?
Las API de Web Scraper proporcionan datos extraídos en formatos versátiles, como NDJSON y CSV, lo que garantiza una integración perfecta con una amplia gama de herramientas de análisis y flujos de trabajo de procesamiento de datos, facilitando así su adopción en entornos de desarrollo.