

En la gestión diaria de datos en línea y en el raspado web, es habitual encontrar mensajes de proxy erróneos. Estos códigos de error son indicadores cruciales de los problemas de entrega de datos con los proxies y desempeñan un papel fundamental en el diagnóstico y la resolución de problemas.
En este artículo se describen los diferentes tipos de códigos de error de proxy HTTP y los distintos tipos, interpretaciones y condiciones en las que suelen aparecer.
Códigos de error de proxy
Los errores de proxy pueden producirse por varios motivos, como el tiempo de inactividad del servidor o una configuración incoherente. Entender estos detalles te ayuda a comprender dónde está el error, lo que facilita su corrección.
En las siguientes secciones, aprenderás acerca de los distintos códigos de proxy y cómo identificar problemas y solucionarlos con eficacia.
Códigos 3xx: redirecciones
Se utiliza un código de estado HTTP 3xx para las redirecciones, lo que indica que el agente de usuario debe tomar medidas adicionales para completar la solicitud. Por lo general, este código implica que eres redireccionado a una nueva URL debido a cambios editoriales o a una reestructuración del sitio web.
En lo que respecta al raspado web, debes gestionar estos redireccionamientos para mantener una recopilación de datos precisa y eficaz.
301: Moved Permanently
Si recibes un error 301, el recurso que estás buscando se ha movido de forma permanente. Esto suele ocurrir cuando un sitio web se está actualizando, por ejemplo, rediseñando o reorganizando su contenido.
Si recibes este error, tu raspador debe transferir sus referencias URL a la nueva ubicación que proviene de los encabezados de respuesta:
response_data = requests.get('http://example.com/old-page')
if response_data.status_code == 301:
new_redirect_url = response_data.headers['Location']
response_data = requests.get(new_redirect_url)
En este código, le indicas a tu raspador que obtenga la ubicación de redireccionamiento que proviene del encabezado. Después, va y accede al contenido en su nueva ubicación:

302: Found (redirección temporal)
El código de estado 302 Found indica que el recurso al que intentas acceder se ha trasladado temporalmente a otra URL. En este caso, el cambio no es permanente y se prevé que la URL original vuelva a ser viable en algún momento. Esto suele ocurrir cuando un sitio web está en mantenimiento.
Al realizar el raspado web, es importante configurar la secuencia de comandos para que gestione los redireccionamientos automáticamente y garantizar que las URL almacenadas no cambien. Si bien muchas bibliotecas HTTP, como las solicitudes de Python, gestionan automáticamente los redireccionamientos 302, es importante comprobar que este comportamiento se ajusta a tus objetivos de raspado, especialmente cuando es necesario conservar el método de solicitud original:

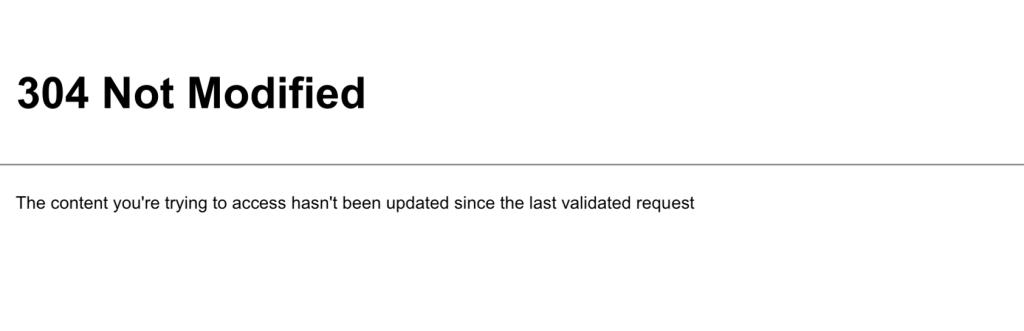
304: Not Modified
Si el contenido al que intentas acceder no se ha actualizado desde la última solicitud validada, recibirás un error 304. Este error ayuda a aumentar la eficacia de las actividades de raspado web y evita la descarga de datos innecesarios.
Si tu raspador accede a una página que ya se ha descargado, los encabezados de la solicitud, como If-Modified-Since o If-None-Match, se pueden usar para verificar que el contenido no esté modificado:
import requests
# Correct header format and Python syntax
headers = {'If-Modified-Since': 'Sat, Oct 29 2024 19:43:31 GMT'}
# Making a GET request to the server with the headers
response = requests.get('http://example.com/page', headers=headers)
# Checking if the status code returned is 304
if response.status_code == 304:
print("Content has not changed.")
En este código, comienzas por probar si el código de respuesta es 304. Si es verdadero, imprime El contenido del mensaje no ha cambiado y no tienes que hacer nada:
307: Temporary Redirect
Una redirección temporal, el código de estado 307, indica que el recurso al que intentas acceder se encuentra temporalmente en otra URL. En este caso, el mismo método HTTP y el mismo cuerpo de la solicitud original se pueden reutilizar con la URL redirigida. Esto difiere del 302, donde la URL redirigida puede usar un método y un cuerpo diferentes:
response = requests.post('http://examples.com/submit-form', data={'key': 'value'} )
if response.status_code == 307:
response = requests.post(response.headers['Location'], data={'key': 'value'})
Debes mantener el orden al redirigir un rastreador web. Esto ayuda a garantizar una recopilación de datos fiable y eficaz, respetando la estructura del sitio web de destino y el sistema de servidores. El siguiente código comprueba si el estado de la respuesta es 307; si es verdadero, reenvía los mismos datos del cuerpo a la nueva Ubicación especificada en el encabezado de la respuesta:

Códigos 4xx: errores del lado del cliente
Los errores del lado del cliente se indican con un rango de códigos de estado HTTP 4xx y, por lo general, se deben a un problema con la solicitud realizada por el cliente. Con frecuencia, estos errores dan como resultado la rectificación de los parámetros de la solicitud o la mejora operativa de los mecanismos de autenticación.
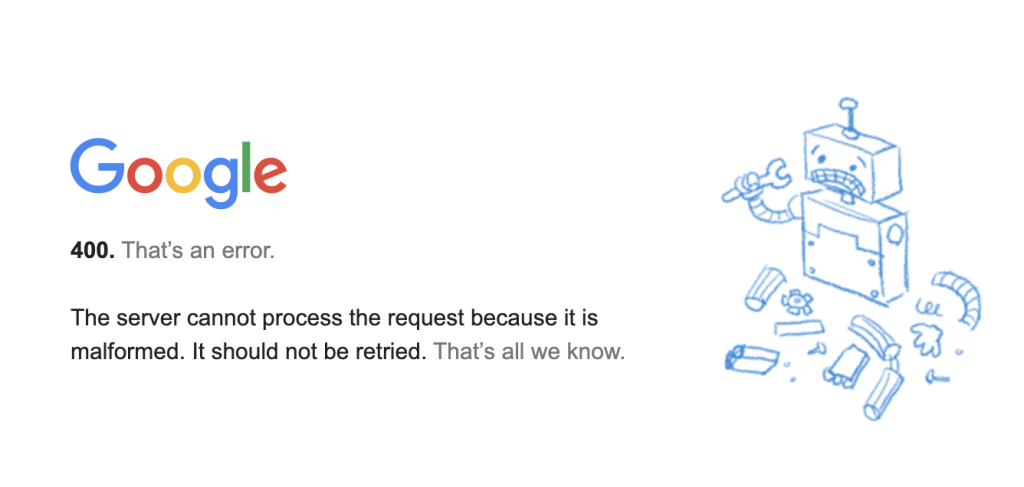
400: Bad Request
El error 400 Bad Request indica que el servidor no ha podido entender la solicitud. En el raspado web, esto suele ocurrir cuando el encabezado de la solicitud no está escrito correctamente o le faltan partes.
Por ejemplo, si envías involuntariamente información en un formato incorrecto (por ejemplo, enviando texto en lugar de JSON), el servidor no puede gestionar la solicitud y se rechaza. Para resolver este problema, debes ejecutar la validación con cuidado y asegurarte de que la sintaxis de la solicitud cumple con las expectativas del servidor.
En el raspado web, hay varios pasos que debes completar para verificar que tus solicitudes cumplen con las expectativas del servidor. Inicialmente, debes asegurarte de comprender la estructura del sitio web objetivo. Puedes utilizar las herramientas de desarrollo del navegador para inspeccionar los elementos y averiguar cómo están formateados los datos. Además, debes implementar las pruebas y la gestión de errores y asegurarte de usar los encabezados adecuados en tus solicitudes:
401: Unauthorized
Un error 401 Unauthorized indica que la autenticación necesaria para acceder a un recurso ha fallado o ha faltado. En el raspado web, esto suele ocurrir cuando se intenta acceder a contenido autenticado. Por ejemplo, el acceso a datos basados en suscripciones con credenciales incorrectas desencadena este error. Para evitarlo, asegúrate de incluir los encabezados de autenticación correctos en tus solicitudes:

403: Forbidden
Un error 403 Forbidden significa que el servidor ha podido entender la solicitud pero se ha negado a permitirte acceder al recurso. Esto es algo común cuando se realiza un raspado de un sitio web que tiene controles de acceso estrictos. Este error aparece con frecuencia al entrar en una parte prohibida de un sitio web. Por ejemplo, si te estás autenticando como usuario e intentas acceder a las publicaciones de otro usuario, no podrás hacerlo porque no tienes permiso:

Si recibes un error 403, verifica la autorización comprobando tus claves o credenciales. Si la autorización no está disponible y no tienes ninguna credencial válida, se recomienda que te abstengas de raspar este contenido para cumplir con la política de acceso del sitio web.
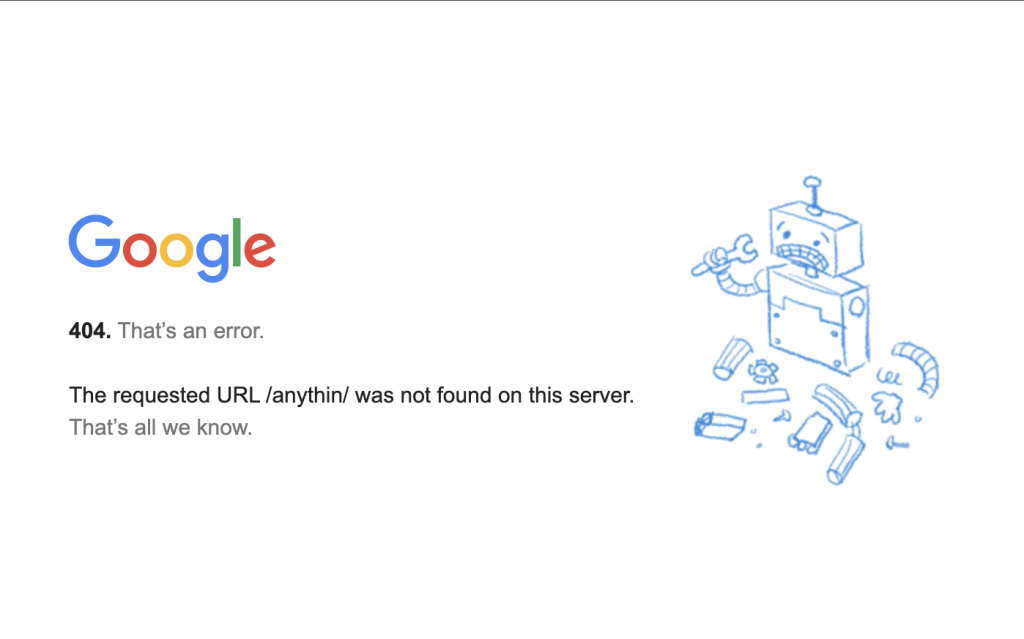
404: Not Found
Cuando el servidor no puede encontrar el recurso solicitado, devuelve el error 404 Not Found.
Esto suele ocurrir cuando las URL utilizadas en el raspado web se modifican o se rompen, por ejemplo, cuando se elimina una página de producto o se modifica su URL sin redirección ni actualizaciones.
Para resolver este problema, verifica las URL de tu secuencia de comandos de raspado y actualízalas según sea necesario para que se ajusten a la estructura actual del sitio web:
Siempre se recomienda encargarse de cualquier error 404 en el código.
Si utilizas Python y el servidor no ha encontrado el recurso, puedes indicar a tu código que pase el siguiente bloque de código para que el código no se detenga cuando se produzca este error:
import requests
# List of URLs to fetch
urls = [
"http://example.com/nonexistentpage.html", # This should result in 404
"http://example.com" # This should succeed
]
for url in urls:
try:
response = requests.get(url)
if response.status_code == 404:
print(f"Error 404: URL not found: {url}")
# Continue to the next URL in the list
continue
print(f"Successfully retrieved data from {url}")
print(response.text[:200]) # Print the first 200 characters of the response content
except requests.exceptions.RequestException as e:
print(f"An error occurred while fetching {url}: {e}")
continue # Continue to the next URL even if a request exception occurs
print("Finished processing all URLs.")
En el siguiente código, repites sobre la matriz de URL y, a continuación, intentas obtener el contenido de la página. Cuando se produce un error 400, el código pasa a la siguiente URL de la matriz.
407: Proxy Authentication Required
El error 407 Proxy Authentication Required se activa cuando el cliente necesita autenticarse en el servidor proxy para poder continuar con la solicitud. Este error suele producirse durante el raspado web, cuando el servidor proxy necesita autenticación. Esto es diferente de un error 401 cuando se requiere autenticación para acceder a los datos relacionados con el sitio web de destino.
Por ejemplo, si recibes este error al usar un proxy privado para acceder a los datos de un sitio web objetivo, no estás autenticado. Para resolver este problema, debes añadir unos detalles de autenticación de proxy válidos en tus solicitudes:

408: Request Timeout
Un código de estado 408 Request Timeout indica que el servidor ha esperado demasiado para recibir la solicitud. Este error puede producirse cuando tu raspador es demasiado lento o si el servidor está sobrecargado, especialmente durante las horas punta.
Cuando se optimiza el tiempo de las solicitudes y se implementan los reintentos con mecanismos de retroceso exponenciales, este problema se puede minimizar ya que el servidor tiene tiempo suficiente para responder:

429: Too Many Requests
El error 429 Too Many Requests se produce cuando un usuario ha enviado muchas solicitudes en poco tiempo. Esto es algo común cuando se superan los límites de tasa de raspado en un sitio web. Por ejemplo, si consultas un sitio web con frecuencia, se activará el límite de velocidad y no podrás raspar datos.
Asegúrate de respetar los límites de velocidad de la API del sitio web objetivo y aplica algunas prácticas recomendadas de raspado, como retrasar las solicitudes, que pueden evitar este problema y mantener el acceso a los recursos necesarios:

Códigos 5xx: problemas del lado del servidor
Los problemas del lado del servidor se indican mediante una serie de códigos de estado HTTP 5xx y se refieren a la incapacidad del servidor para atender las solicitudes debido a problemas internos. Debes comprender estos errores en el raspado web, ya que a menudo exigen un enfoque diferente en comparación con la gestión de los errores del lado del cliente.
500: Internal Server Error
El error 500 Internal Server Error es una respuesta genérica que te informa de que se ha producido una situación anormal en el servidor que no le ha permitido completar la solicitud específica. Este problema no se debe a ningún error cometido por el cliente; más bien, significa que el problema está en el propio servidor.
Por ejemplo, al raspar datos, este error puede producirse al intentar acceder a una página del servidor. Para solucionar el problema, puedes volver a intentarlo más tarde o planificar tus proyectos de raspado web para que se lleven a cabo cuando no sean las horas punta y el servidor no esté cargado:

501: Not Implemented
El error 501 Not Implemented se produce cuando el servidor no reconoce el método de solicitud ni lo completa. Dado que normalmente se prueban los métodos del rastreador de antemano, este error rara vez se produce en el raspado web, pero puede ocurrir si se utilizan métodos HTTP atípicos.
Por ejemplo, si tu raspador está configurado para usar métodos que no son compatibles con el servidor (por ejemplo, PUT o DELETE) y estos métodos son necesarios para tus funciones de raspado web, recibirás un error 501. Para evitarlo, asegúrate de que, si tus secuencias de comandos de raspado utilizan métodos HTTP, estos métodos sean necesarios en todas partes:

502: Bad Gateway
El error 502 Bad Gateway indica que, a pesar de actuar como puerta de enlace o proxy, el servidor recibió una respuesta inapropiada del servidor de destino y se accede a él para cumplir con la solicitud. Esto indica que hubo un problema de comunicación con los servidores intermediarios.
Al realizar un raspado web, puede producirse el error 502 cuando el servidor proxy que estás utilizando no puede obtener una respuesta adecuada del servidor de destino. Para solucionar este problema, comprueba que el estado y la configuración del servidor proxy funcionan y que pueden comunicarse con los servidores de destino. Puedes supervisar el uso de la CPU, la memoria y el ancho de banda de red en tu servidor proxy. También puedes comprobar los registros de errores del servidor proxy, que pueden indicar si hay problemas con la gestión de tus solicitudes:

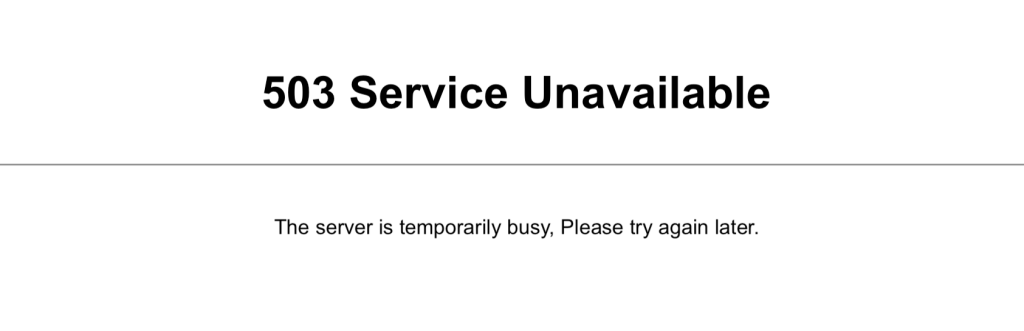
503: Service Unavailable
El error 503 Service Unavailable indica que el servidor está ocupado y no puede atender la solicitud. Esto puede ocurrir debido al mantenimiento o a la sobrecarga del servidor.
Al realizar el raspado web, a menudo te encuentras con este error al intentar acceder a sitios a los que no se puede acceder durante las horas de mantenimiento o de mayor actividad. A diferencia del error 500, que indica un problema con el servidor, el error 503 indica que el servidor está operativo pero no disponible en este momento.
Para evitar este error, debes implementar una estrategia de reintentos que utilice un retroceso exponencial. Los intervalos de retroceso deberían aumentar a medida que se reintenten las solicitudes. Como resultado, las solicitudes no deberían provocar la saturación del servidor durante el tiempo de inactividad:
504: Gateway Timeout
El error 504 Gateway Timeout se produce cuando el servidor que actúa como puerta de enlace o proxy no obtiene una respuesta del servidor ascendente a tiempo. Este error es un problema de tiempo de espera y una variante del error 502.
Cuando se trata del raspado web, este error suele ocurrir cuando la respuesta del servidor de destino a tu proxy es demasiado lenta (es decir, tardó más de 120 segundos). Para solucionar este problema, puedes modificar la configuración del tiempo de espera de tu raspador para cumplir con tiempos de espera más largos o verificar el estado y la capacidad de respuesta de tu servidor proxy:

505: HTTP Version Not Supported
El error 505 HTTP Version Not Supported se produce cuando el servidor no reconoce la versión del protocolo HTTP especificada en la solicitud. Esto es poco frecuente en el raspado web, pero puede ocurrir si el servidor de destino está configurado para admitir solo ciertas versiones del protocolo HTTP. Por ejemplo, si tus solicitudes de raspado llegan con una versión demasiado reciente o demasiado antigua, el servidor no las aceptará.
Para evitar este error, asegúrate de que los encabezados de las solicitudes HTTP indiquen una versión que sea aceptable para el servidor de destino, muy probablemente HTTP/1.1 o HTTP/2, que son las que se admiten con más frecuencia:
Consejos rápidos para evitar errores comunes de proxy
Los errores de proxy pueden resultar frustrantes, pero muchos de ellos se pueden evitar implementando algunas estrategias específicas en tu raspador web.
Reintenta la solicitud
Muchos problemas de proxy se deben a cuestiones a corto plazo, como interrupciones breves de la red o pequeños fallos del servidor. Reintentar la solicitud podría evitar el problema si este se ha resuelto de forma natural.
Así es como puedes implementar los reintentos en tu secuencia de comandos de raspado utilizando la biblioteca requests de Python y la lógica de reintentos urllib3:
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
def requests_retry_session(
retries=3,
backoff_factor=0.3,
status_forcelist=(500, 502, 503, 504),
session=None,
):
session = session or requests.Session()
retry = Retry(
total=retries,
read=retries,
connect=retries,
backoff_factor=backoff_factor,
status_forcelist=status_forcelist,
)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
return session
s = requests_retry_session()
try:
response = s.get('http://example.com', proxies={"http": "http://proxy_address:port"})
print(response.text)
except requests.exceptions.HTTPError as e:
print('HTTPError:', e)
Este código establece un mecanismo de reintento con un factor de retroceso, lo que significa que, si una solicitud falla, puedes reintentar la misma solicitud hasta tres veces y esperar un poco más cada vez antes del siguiente intento.
Verifica la configuración del proxy
Una configuración de proxy incorrecta puede provocar numerosos errores. Por ejemplo, estos errores pueden producirse si introduces un puerto de proxy, una dirección IP o una información de autenticación incorrectos. Asegúrate de verificar que la configuración es correcta de acuerdo con las necesidades de tu red para que las solicitudes puedan llegar a su destino.
Consulta la documentación y el soporte
Si tienes algún problema al utilizar un servicio de proxy o una biblioteca, consulta siempre la documentación oficial como primera línea de defensa. Si no encuentras lo que buscas en la documentación, comprueba si el servicio o la biblioteca tienen un canal de Slack o Discord al que puedas unirte. Por último, siempre puedes abrir un tique en el canal de soporte o enviar un correo electrónico con los detalles y las preguntas que quieres que respondan.
Conclusión
Este artículo te ha enseñado todo sobre los distintos códigos de error de proxy y sus significados, ayudándote a identificar cada error y a solucionar los problemas que surjan durante el raspado web. También has descubierto algunos consejos útiles para evitar que se produzcan errores comunes en primer lugar.
Si tienes problemas con los errores de proxy, considera la posibilidad de utilizar los servicios de proxy de Bright Data. Nuestros proxies pueden ayudar a reducir la aparición de errores y resultar en un proceso de raspado de datos más eficiente. Ya seas un experto o un novato, el conjunto de herramientas de proxy de Bright Data puede ayudarte a mejorar tus habilidades de raspado web.





