La búsqueda manual de contenidos en docenas de resultados de búsqueda de Google lleva demasiado tiempo y suele pasar por alto información clave dispersa en múltiples fuentes. El web scraping tradicional proporciona HTML en bruto, pero carece de la inteligencia necesaria para sintetizar la información en narraciones coherentes. Esta guía muestra cómo crear un sistema basado en IA que extraiga automáticamente los resultados de las SERP de Google, analice el contenido mediante incrustaciones y genere artículos o resúmenes completos.
Aprenderás:
- Cómo construir un canal automatizado de investigación a artículo utilizando Bright Data e incrustaciones vectoriales.
- Cómo analizar semánticamente el contenido raspado e identificar temas recurrentes
- Cómo generar esquemas estructurados y artículos completos utilizando LLMs
- Cómo crear una interfaz Streamlit interactiva para la generación de contenidos
¡Empecemos!
Los retos de la investigación para la creación de contenidos
Los creadores de contenidos se enfrentan a importantes obstáculos a la hora de investigar temas para artículos, entradas de blog o materiales de marketing. La investigación manual implica abrir docenas de pestañas del navegador, leer artículos extensos e intentar sintetizar información de fuentes dispares. Este proceso es propenso al error humano, requiere mucho tiempo y es difícil de escalar.
Los métodos tradicionales de raspado web con BeautifulSoup o Scrapy proporcionan texto HTML sin procesar, pero carecen de la inteligencia necesaria para comprender el contexto del contenido, identificar temas clave o sintetizar información de múltiples fuentes. El resultado es una colección de texto no estructurado que requiere un procesamiento manual significativo.
La combinación de las sólidas capacidades de scraping de Bright Data con modernas técnicas de IA, como la incrustación de vectores y los grandes modelos lingüísticos, automatiza todo el proceso de investigación a artículo. Esto transforma horas de trabajo manual en minutos de análisis automatizado.
Qué estamos construyendo: Sistema de investigación de contenidos basado en IA
Creará un sistema inteligente de generación de contenidos que rastrea automáticamente los resultados de búsqueda de Google para cualquier palabra clave. El sistema extrae el contenido completo de las páginas web de destino, analiza la información utilizando incrustaciones vectoriales para identificar temas y puntos de vista, y genera esbozos de artículos estructurados o borradores de artículos completos a través de una interfaz intuitiva Streamlit.
Requisitos previos
Configure su entorno de desarrollo con estos requisitos
- Python 3.9 o superior
- Cuenta de Bright Data: Regístrese y cree un token de API (hay disponibles créditos de prueba gratuitos)
- Clave de API de OpenAI: Cree una clave en su panel de control de OpenAI para incrustaciones y acceso LLM
- Entorno virtual Python: Mantiene las dependencias aisladas
- LangChain + Vector Embeddings (FAISS): Maneja el análisis y almacenamiento de contenidos.
- Streamlit: Proporciona la interfaz de usuario interactiva, permitiendo a los usuarios utilizar la herramienta.
Configuración del entorno
Cree el directorio de su proyecto e instale las dependencias. Empieza por configurar un entorno virtual limpio para evitar conflictos con otros proyectos Python.
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install langchain langchain-community langchain-openai streamlit "crewai-tools[mcp]" crewai mcp python-dotenvCrea un nuevo archivo llamado article_generator.py y añade las siguientes importaciones. Estas librerías se encargan del web scraping, el procesamiento de texto, los embeddings y la interfaz de usuario.
importar streamlit como st
importar os
import json
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from mcp import StdioServerParameters
from crewai_tools import MCPServerAdapter
cargar_dotenv()Configuración de Bright Data
Almacene sus credenciales API de forma segura utilizando variables de entorno. Cree un archivo .env para almacenar sus credenciales, manteniendo la información sensible separada de su código.
BRIGHT_DATA_API_TOKEN="su_bright_data_api_token_aquí"
BRIGHT_DATA_ZONE="tu_nombre_de_zona_serp"
OPENAI_API_KEY="su_openai_api_clave_aquí"Necesita
- Token de API de Bright Data: Generado desde su panel de Bright Data
- Zona de raspado SERP: Crear una nueva zona de raspado web configurada para Google SERP
- Clave API de OpenAI: Para incrustaciones y generación de texto LLM
Configure las conexiones API en article_generator.py. Esta clase gestiona toda la comunicación con la infraestructura de raspado de Bright Data.
clase BrightDataScraper:
def __init__(self):
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"ZONA_DESBLOQUEADOR_WEB": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def scrape_serp(self, keyword, num_results=10):
with MCPServerAdapter(self.server_params) as mcp_tools:
try:
if not mcp_tools:
st.warning("No hay herramientas MCP disponibles")
return {'resultados': []}
para herramienta en mcp_herramientas:
try:
nombre_herramienta = getattr(herramienta, 'nombre', str(herramienta))
si 'motor_busqueda' en nombre_herramienta y 'lote' no en nombre_herramienta:
try:
if hasattr(tool, '_run'):
result = tool._run(query=palabra_clave)
elif hasattr(tool, 'run'):
result = tool.run(query=palabraclave)
elif hasattr(tool, '__call__'):
result = tool(query=palabraclave)
si no
result = tool.search_engine(query=palabra clave)
si resultado:
return self._parse_serp_results(resultado)
except Exception as method_error:
st.warning(f "Método fallido para {nombre_de_la_herramienta}: {str(error_método)}")
continuar
except Excepción como herramienta_error:
st.warning(f "Herramienta {nombre_herramienta} fallida: {str(error_herramienta)}")
continuar
st.warning(f "Ninguna herramienta del motor de búsqueda ha podido procesar: {palabra clave}")
return {'resultados': []}
except Exception as e:
st.error(f "MCP scraping failed: {str(e)}")
return {'resultados': []}
def _parse_serp_results(self, mcp_result):
"""Analiza los resultados de la herramienta MCP en el formato esperado."""
if isinstance(mcp_result, dict) and 'resultados' in mcp_result:
return mcp_result
elif isinstance(mcp_result, list):
return {'resultados': mcp_result}
elif isinstance(mcp_result, str):
return self._parse_html_search_results(mcp_result)
si no
try:
parsed = json.loads(str(mcp_result))
return parsed if isinstance(parsed, dict) else {'resultados': parsed}
excepto:
return {'resultados': []}
def _parse_html_search_results(self, html_content):
"""Parse HTML search results page to extract search results.""""
import re
resultados = []
link_pattern = r'<a[^>]*href="([^"]*)"[^>]*>(.*?)</a>'
title_pattern = r'<h3[^>]*>(.*?)</h3>'
links = re.findall(link_pattern, html_content, re.DOTALL)
para link_url, link_text en links:
if (link_url.startswith('http') and
no any(skip en link_url para skip en [
'google.com', 'cuentas.google', 'soporte.google',
'/búsqueda?', 'javascript:', '#', 'mailto:'
])):
clean_title = re.sub(r'<[^>]+>', '', link_text).strip()
si título_limpio y len(título_limpio) > 10:
results.append({
'url': link_url,
'title': clean_title[:200],
'snippet': '',
'posición': len(resultados) + 1
})
si len(resultados) >= 10
break
if not results:
specific_pattern = r'[(.*?)]((https?://[^)]+))'
coincidencias = re.findall(patrón_especifico, contenido_html)
para título, url en coincidencias:
if not any(skip in url for skip in ['google.com', '/search?']):
results.append({
'url': url,
'title': title.strip(),
'snippet': '',
'posición': len(resultados) + 1
})
si len(resultados) >= 10
break
return {'resultados': resultados}Creación del generador de artículos
Paso 1: Recopilación de SERP y páginas objetivo
La base de nuestro sistema es la recopilación exhaustiva de datos. Es necesario construir un scraper que primero extraiga los resultados de las SERP de Google y luego siga esos enlaces para recopilar el contenido completo de las páginas de las fuentes más relevantes.
clase ContentScraper:
def __init__(self):
self.bright_data = BrightDataScraper()
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"ZONA_DESBLOQUEADOR_WEB": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def extraer_serp_urls(self, palabra_clave, max_resultados=10):
"""Extraer URLs de los resultados SERP de Google."""
serp_data = self.bright_data.scrape_serp(keyword, max_results)
urls = []
results_list = serp_data.get('resultados', [])
para resultado en lista_resultados:
if 'url' in resultado and self.is_valid_url(resultado['url']):
urls.append({
'url': result['url'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
elif 'enlace' in resultado and self.is_valid_url(resultado['enlace']):
urls.append({
'url': result['link'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
devolver urls
def is_valid_url(self, url):
"""Filtra las URLs que no sean de artículos como imágenes, PDFs o redes sociales."""
excluded_domains = ['youtube.com', 'facebook.com', 'twitter.com', 'instagram.com']
excluded_extensions = ['.pdf', '.jpg', '.png', '.gif', '.mp4']
return (not any(domain in url for domain in excluded_domains) and
not any(ext in url.lower() for ext in extensiones_excluidas))
def scrape_page_content(self, url, max_length=10000):
"""Extrae el contenido de texto limpio de una página web utilizando las herramientas MCP de Bright Data."""
try:
with MCPServerAdapter(self.server_params) as mcp_tools:
if not mcp_tools:
st.warning("No MCP tools available for content scraping")
return ""
para tool en mcp_tools:
try:
nombre_herramienta = getattr(herramienta, 'nombre', str(herramienta))
if 'scrape_as_markdown' in nombre_herramienta:
try:
if hasattr(tool, '_run'):
result = tool._run(url=url)
elif hasattr(tool, 'run'):
result = tool.run(url=url)
elif hasattr(tool, '__call__'):
result = tool(url=url)
else:
result = tool.scrape_as_markdown(url=url)
si resultado:
contenido = self._extract_content_from_result(resultado)
si contenido:
return self._clean_content(content, max_length)
except Excepción como error_método:
st.warning(f "Falló el método para {nombre_de_la_herramienta}: {str(error_método)}")
continuar
except Excepción como herramienta_error:
st.warning(f "Herramienta {nombre_herramienta} fallida para {url}: {str(error_herramienta)}")
continuar
st.warning(f "No scrape_as_markdown tool could scrape: {url}")
return ""
except Exception as e:
st.warning(f "Fallo al raspar {url}: {str(e)}")
return ""
def _extract_content_from_result(self, result):
"""Extraer contenido del resultado de la herramienta MCP."""
if isinstance(result, str):
return result
elif isinstance(result, dict):
for key in ['contenido', 'texto', 'cuerpo', 'html']:
if clave en resultado y resultado[clave]:
return resultado[clave]
elif isinstance(result, list) y len(result) > 0
return str(resultado[0])
return str(resultado) if resultado else ""
def _clean_content(self, content, max_length):
"""Limpia y formatea el contenido raspado."""
if isinstance(content, dict):
content = content.get('texto', content.get('contenido', str(contenido)))
si '<' en contenido y '>' en contenido:
import re
content = re.sub(r'<script[^><]*>.*?</script>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<style[^>]*>.*?</style>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<[^>]+>', '', content)
líneas = (line.strip() for line in content.splitlines())
trozos = (frase.strip() para línea en líneas para frase en línea.split(" "))
text = ' '.join(trozo para trozo en trozos si trozo)
return texto[:longitud_máx]Este scraper filtra de forma inteligente las URL para centrarse en el contenido de los artículos y evitar los archivos multimedia y los enlaces a redes sociales que no proporcionarán contenido de texto valioso para el análisis.
Paso 2: Incrustación vectorial y análisis de contenido
Transforme el contenido raspado en incrustaciones vectoriales con capacidad de búsqueda que capturen el significado semántico y permitan un análisis inteligente del contenido. El proceso de incrustación convierte el texto en representaciones numéricas que las máquinas pueden comprender y comparar.
clase ContentAnalyzer:
def __init__(self):
self.embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["nn", "n", ".", "!", "?", ",", " ", ""].
)
def process_content(self, scraped_data):
"""Convierte el contenido raspado en incrustaciones y analiza los temas""".
todos_textos = []
metadatos = []
para item en scraped_data:
if elemento['contenido']:
chunks = self.text_splitter.split_text(item['content'])
para chunk en chunks:
all_texts.append(chunk)
metadata.append({
'url': item['url'],
'title': item['title'],
'position': item['position']
})
if not all_texts:
raise ValueError("No hay contenido disponible para el análisis")
vectorstore = FAISS.from_texts(all_texts, self.embeddings, metadatas=metadata)
return vectorstore, todos_los_textos, metadatos
def identificar_temas(self, vectorstore, términos_consulta, k=5):
"""Utiliza la búsqueda semántica para identificar temas y tópicos clave."""
análisis_temático = {}
para término en términos_consulta:
similar_docs = vectorstore.similarity_search(término, k=k)
análisis_temático[término] = {
'trozos_relevantes': len(documentos_similares),
'pasajes_clave': [doc.contenido_página[:200] + "..." for doc in documentos_similares[:3]],
'sources': list(set([doc.metadata['url'] for doc in similar_docs]))
}
return análisis_temático
def generar_resumen_contenido(self, todos_textos, metadatos):
"""Generar resumen estadístico del contenido scrapeado."""
total_palabras = sum(len(text.split()) for text in all_texts)
total_chunks = len(all_texts)
avg_chunk_length = total_words / total_chunks if total_chunks > 0 else 0
return {
'total_fuentes': len(set(meta['url'] for meta in metadata)),
'total_chunks': total_chunks,
'total_words': total_words,
'avg_chunk_length': round(avg_chunk_length, 1)
}El analizador divide el contenido en trozos semánticos y crea una base de datos vectorial en la que se pueden realizar búsquedas y que permite la identificación inteligente de temas y la síntesis de contenidos.
Paso 3: Generar artículo o esquema con LLM
Transforme el contenido analizado en resultados estructurados mediante instrucciones cuidadosamente elaboradas que aprovechan los conocimientos semánticos de su análisis de incrustación. El LLM toma los datos de su investigación y crea contenidos coherentes y bien estructurados.
clase ArticleGenerator:
def __init__(self):
self.llm = OpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY"),
temperatura=0.7
max_tokens=2000
)
def generate_outline(self, keyword, theme_analysis, content_summary):
"""Generar un esquema estructurado del artículo basado en los datos de la investigación""".
themes_text = self._format_themes_for_prompt(theme_analysis)
esquema_prompt = f""
Basándose en una investigación exhaustiva sobre "{palabra clave}", cree un esquema detallado del artículo.
Resumen de la investigación:
- Analizadas {content_summary['total_sources']} fuentes
- Procesado {content_summary['total_words']} palabras de contenido
- Identificación de temas y perspectivas clave
Temas clave encontrados:
{themes_text}
Crear un esquema estructurado con:
1. Titular convincente
2. 2. Introducción y resumen
3. 4-6 secciones principales con subsecciones
4. Conclusión con puntos clave
5. Llamada a la acción sugerida
Formato markdown con jerarquía clara.
"""
return self.llm(esquema_prompta)
def generate_full_article(self, keyword, theme_analysis, content_summary, target_length=1500):
"""Generar un borrador de artículo completo."""
themes_text = self._format_themes_for_prompt(theme_analysis)
article_prompt = f""
Escribe un artículo completo de {target_length} palabras sobre "{keyword}" basado en una investigación exhaustiva.
Fundación de la investigación:
{temas_texto}
Requisitos de contenido:
- Introducción atractiva que enganche a los lectores
- Cuerpo bien estructurado con secciones claras
- Incluir ideas y datos específicos procedentes de la investigación.
- Tono profesional e informativo
- Conclusión contundente con conclusiones prácticas
- Estructura SEO con subtítulos
Escriba el artículo completo en formato markdown.
"""
return self.llm(anuncio_artículo)
def _format_themes_for_prompt(self, tema_análisis):
""""Formatea el análisis de temas para el consumo de LLM."""
temas_formateados = []
para tema, datos en análisis_temático.elementos():
theme_info = f "**{tema}**: Found in {data['relevant_chunks']} content sectionsn"
theme_info += f "Información clave: {data['key_passages'][0][:150]}...n"
theme_info += f "Fuentes: {len(data['sources'])} unique referencesn"
formatted_themes.append(theme_info)
return "n".join(temas_formateados)El generador crea dos formatos de salida distintos esquemas estructurados para la planificación de contenidos y artículos completos para su publicación inmediata. Ambas salidas se basan en el análisis semántico del contenido raspado.
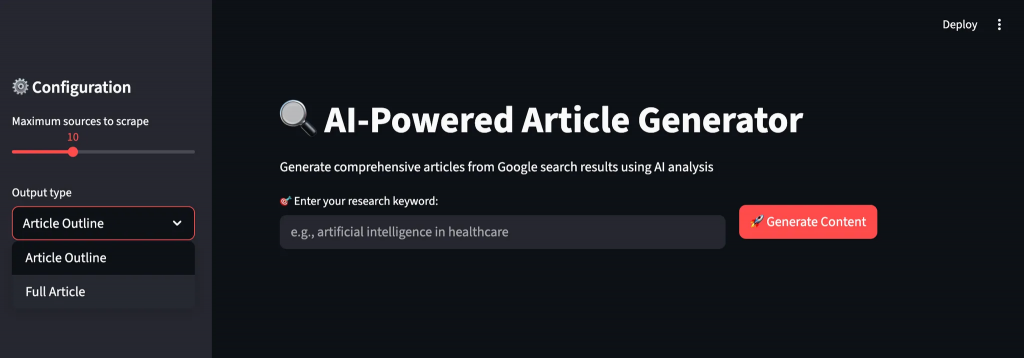
Paso 4: Creación de la interfaz de usuario Streamlit
Cree una interfaz intuitiva que guíe a los usuarios a través del flujo de trabajo de generación de contenidos con información en tiempo real y opciones de personalización. La interfaz hace que las complejas operaciones de IA sean accesibles para usuarios no técnicos.
def main():
st.set_page_config(page_title="AI Article Generator", page_icon="📝", layout="wide")
st.title("🔍 Generador de artículos AI")
st.markdown("Genera artículos completos a partir de los resultados de búsqueda de Google mediante análisis de IA")
raspador = ContentScraper()
analyzer = ContentAnalyzer()
generador = ArticleGenerator()
st.sidebar.header("Configuración de ⚙️")
max_sources = st.sidebar.slider("Máximo de fuentes a raspar", 5, 20, 10)
output_type = st.sidebar.selectbox("Tipo de salida", ["Esquema del artículo", "Artículo completo"])
target_length = st.sidebar.slider("Número de palabras objetivo (artículo completo)", 800, 3000, 1500)
col1, col2 = st.columnas([2, 1])
con col1:
keyword = st.text_input("🎯 Introduzca la palabra clave de su investigación:", placeholder="por ejemplo, inteligencia artificial en sanidad")
con col2:
st.write("")
generate_button = st.button("🚀 Generar contenido", type="primary")
si generar_botón y palabra clave:
try:
progress_bar = st.progress(0)
texto_estado = st.empty()
status_text.text("🔍 Raspando los resultados de búsqueda de Google...")
progress_bar.progress(0.2)
urls = scraper.extract_serp_urls(palabra_clave, max_fuentes)
st.success(f "Encontradas {len(urls)} URLs relevantes")
status_text.text("📄 Extrayendo contenido de páginas web...")
progress_bar.progress(0.4)
datos_raspados = []
for i, url_data in enumerate(urls):
content = scraper.scrape_page_content(url_data['url'])
scraped_data.append({
'url': url_data['url'],
'title': url_data['title'],
'content': contenido,
'position': url_data['position']
})
progress_bar.progress(0.4 + (0.3 * (i + 1) / len(urls)))
status_text.text("🧠 Analizando contenido con AI embeddings...")
progress_bar.progress(0.75)
vectorstore, all_texts, metadata = analyzer.process_content(scraped_data)
términos_consulta = [palabra_clave] + palabra_clave.split()[:3]
theme_analysis = analyzer.identify_themes(vectorstore, query_terms)
resumen_contenido = analizador.generar_resumen_contenido(todos_los_textos, metadatos)
status_text.text("✍️ Generando contenido basado en IA...")
progress_bar.progress(0.9)
si output_type == "Esquema del artículo":
result = generator.generate_outline(keyword, theme_analysis, content_summary)
si no
result = generator.generate_full_article(keyword, theme_analysis, content_summary, target_length)
progress_bar.progress(1.0)
status_text.text("✅ ¡Generación de contenido completada!")
st.markdown("---")
st.subheader(f"📊 Análisis de investigación para '{palabra clave}'")
col1, col2, col3, col4 = st.columnas(4)
con col1:
st.metric("Fuentes analizadas", content_summary['total_fuentes'])
con col2:
st.metric("Trozos de contenido", content_summary['total_trozos'])
con col3:
st.metric("Palabras totales", content_summary['palabras_totales'])
con col4:
st.metric("Tamaño medio de trozos", f"{content_summary['avg_chunk_length']} palabras")
con st.expander("🎯 Temas clave identificados"):
for tema, datos in tema_análisis.elementos():
st.write(f "**{tema}**: {datos['trozos_relevantes']} secciones relevantes encontradas")
st.write(f "Ejemplo de comprensión: {datos['pasajes_clave'][0][:200]}...")
st.write(f "Fuentes: {len(data['sources'])} referencias únicas")
st.write("---")
st.markdown("---")
st.subheader(f"📝 Generado {tipo_salida}")
st.markdown(resultado)
st.botón_descarga(
label="💾 Descargar contenido",
data=resultado,
file_name=f"{palabra_clave.replace(' ', '_')}_{output_type.lower().replace(' ', '_')}.md",
mime="text/markdown"
)
except Exception as e:
st.error(f"❌ Generación fallida: {str(e)}")
st.write("Por favor, compruebe sus credenciales API e inténtelo de nuevo.")
if __name__ == "__main__":
main()La interfaz de Streamlit proporciona un flujo de trabajo intuitivo con seguimiento del progreso en tiempo real, parámetros personalizables y vista previa inmediata tanto del análisis de la investigación como del contenido generado. Los usuarios descargan sus resultados en formato markdown para su posterior edición o publicación.
Ejecutar el generador de artículos
Ejecute la aplicación para empezar a generar contenidos a partir de la investigación web. Abra su terminal y navegue hasta el directorio de su proyecto.
streamlit ejecutar article_generator.pyVerá el flujo de trabajo inteligente del sistema a medida que procesa sus solicitudes:
- Extrae resultados de búsqueda completos de Google SERP con filtrado de relevancia
- Extrae el contenido completo de las páginas web de destino con protección anti-bot
- Procesa el contenido semánticamente utilizando incrustaciones vectoriales e identificación de temas.
- Analiza patrones recurrentes e información clave de múltiples fuentes.
- Genera contenidos estructurados con un flujo adecuado y un formato profesional.
Reflexiones finales
Ahora dispone de un completo sistema de generación de artículos que recopila automáticamente datos de investigación de múltiples fuentes y los transforma en contenidos completos. El sistema realiza un análisis semántico del contenido, identifica temas recurrentes en las fuentes y genera artículos estructurados o esquemas.
Puede adaptar este marco a distintos sectores modificando los objetivos de scraping y los criterios de análisis. El diseño modular le permite añadir nuevas plataformas de contenidos, modelos de incrustación o plantillas de generación a medida que evolucionan sus necesidades.
Para crear flujos de trabajo más avanzados, explore toda la gama de soluciones de la infraestructura Bright Data AI para obtener, validar y transformar datos web en tiempo real.
Cree una cuenta gratuita en Bright Data y empiece a experimentar con nuestras soluciones de datos web preparadas para la IA.