

El scraping web es una forma programática de recopilar datos de sitios web, y existen infinitos casos de uso para el scraping web, incluyendo estudios de mercado, Monitoreo de precios, análisis de datos y generación de clientes potenciales.
En este tutorial, verás un caso de uso práctico centrado en una dificultad común de los padres: recopilar y organizar la información que envía la escuela a casa. Aquí te centrarás en las tareas escolares y la información sobre los almuerzos escolares.
A continuación se muestra un diagrama aproximado de la arquitectura del proyecto final:
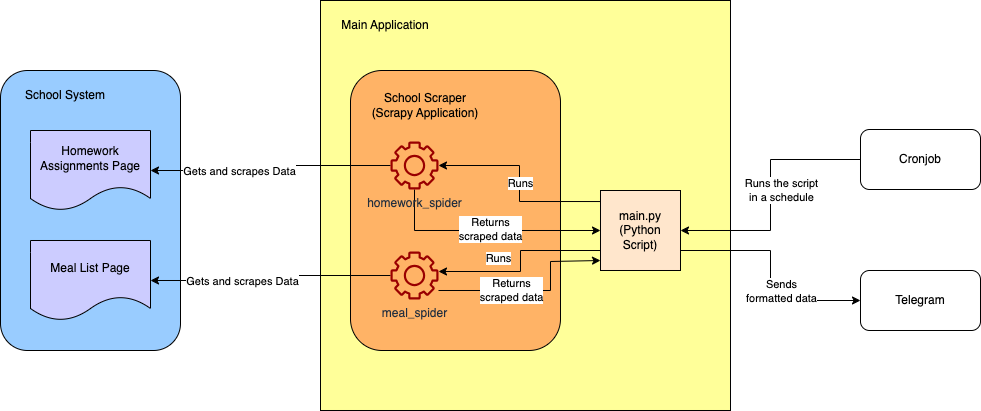
Requisitos previos
Para seguir este tutorial, necesitas lo siguiente:
- Python 3.10+
- entorno virtual que haya sido activado
- Scrapy CLI 2.11.1
- Visual Studio Code
Por motivos de privacidad, utilizarás este sitio web ficticio de un sistema escolar: https://systemcraftsman.github.io/scrapy-demo/website/.
Crear el proyecto
En tu terminal, crea el directorio base del proyecto (puedes colocarlo en cualquier lugar):
mkdir school-scraper
Navega hasta la carpeta recién creada y crea un nuevo proyecto Scrapy ejecutando el siguiente comando:
cd Scraper &
scrapy startproject school_scraper
La estructura del proyecto debería tener este aspecto:
school-scraper
└── school_scraper
├── school_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
El comando anterior crea dos niveles de directorios school_scraper. En el directorio interno hay un conjunto de archivos generados automáticamente: middlewares.py, donde se pueden definir los middlewares de Scrapy; pipelines.py, donde se pueden definir pipelines personalizados para modificar los datos; y settings.py, donde se pueden definir los ajustes generales de la aplicación de scraping.
Lo más importante es que hay una carpeta spiders donde se encuentran las arañas. Las arañas son clases de Python que se pueden utilizar para extraer datos de un sitio concreto de una manera determinada. Se adhieren al principio de separación de preocupaciones dentro del sistema de extracción, lo que permite la creación de una araña dedicada para cada tarea de extracción.
Como aún no tienes una araña generada, esta carpeta está vacía, pero en el siguiente paso generarás tu primera araña.
Crear la araña de tareas
Para extraer datos de tareas de un sistema escolar, debes crear una araña que primero inicie sesión en el sistema y luego navegue hasta la página de tareas para extraer los datos:
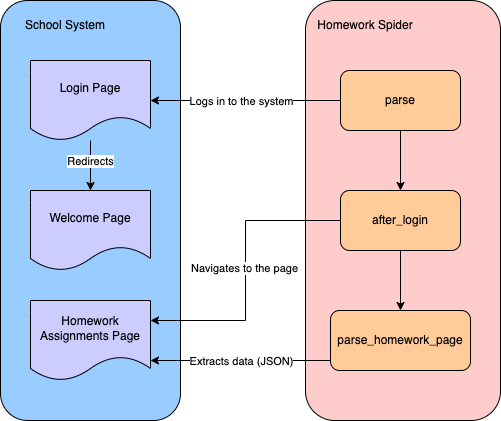
Utilizarás la CLI de Scrapy para crear una araña para el Scraping web. Navega hasta el directorio school-scraper/school_scraper de tu proyecto y ejecuta el siguiente comando para crear una araña llamada HomeworkSpider en la carpeta spiders:
scrapy genspider homework_spider systemcraftsman.github.io/scrapy-demo/website/index.html
NOTA: No olvides ejecutar todos los comandos relacionados con Python o Scrapy en tu entorno virtual activado.
El comando scrapy genspider genera la araña. El siguiente parámetro es el nombre de la araña (es decir, homework_spider) y el último parámetro define la URL de inicio de la araña. De esta manera, systemcraftsman.github.io es reconocido como un dominio permitido por Scrapy.
El resultado debería ser similar a este:
Se ha creado la araña «homework_spider» utilizando la plantilla «basic» en el módulo:
school_scraper.spiders.homework_spider
Se debe crear un archivo llamado homework_spider.py en el directorio school_scraper/spiders y debe tener este aspecto:
class HomeworkSpiderSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
Cambia el nombre de la clase a HomeworkSpider para eliminar el término redundante Spider del nombre de la clase. La función Parseo es la función inicial que inicia el rastreo. En este caso, se trata de iniciar sesión en el sistema.
NOTA: El formulario de inicio de sesión
en https://systemcraftsman.github.io/scrapy-demo/index.htmles un formulario de inicio de sesión ficticio que consta de un par de líneas de JavaScript. Dado que la página es HTML, no acepta ninguna solicitud POST, y en su lugar se utiliza una solicitud HTTP GET para imitar el inicio de sesión.
Actualice la función parse de la siguiente manera:
...código omitido...
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
Aquí, se crea una solicitud de formulario para enviar el formulario de inicio de sesión dentro de la página index.html. El formulario enviado debe redirigir a la welcome_page_url definida y debe tener una función de devolución de llamada para continuar el proceso de scraping. Pronto se añadirá la función de devolución de llamada after_login.
Defina welcome_page_url añadiéndola en la parte superior de la clase donde se definen otras variables:
...código omitido...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
...código omitido...
A continuación, añada la función after_login justo después de la función parse en la clase:
...código omitido...
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
...código omitido...
La función after_login comprueba que el estado de la respuesta sea 200, lo que significa que ha sido satisfactoria. A continuación, navega a la página de tareas y llama a la función de devolución de llamada parse_homework_page, que definirás en el siguiente paso.
Define homework_page_url añadiéndola en la parte superior de la clase, donde se definen las demás variables:
...código omitido...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
...código omitido...
Añade la función parse_homework_page después de la función after_login en la clase:
...código omitido...
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
...código omitido...
La función parse_homework_page comprueba si el estado de la respuesta es 200 (es decir, correcta); a continuación, analiza los datos de los deberes, que se proporcionan en una tabla HTML.
La función comprueba el código HTTP 200 y, a continuación, utiliza XPath para extraer cada fila de datos. Después de extraer cada fila, la función itera sobre los datos y extrae los elementos específicos utilizando la función privada _get_item, que debe añadir a su clase Spider.
La función _get_item debería tener este aspecto:
...código omitido...
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
La función _get_item obtiene el contenido de cada celda utilizando XPath junto con los números de fila y columna. Si una celda tiene más de un párrafo, la función los itera y añade cada párrafo.
La función parse_homework_page también requiere que se defina una date_str, que debe definir como 12.03.2024, ya que es la fecha que tiene en su sitio web estático.
NOTA: En una situación real, debe definir la fecha de forma dinámica, ya que los datos del sitio web serían dinámicos.
Defina date_str añadiéndolo en la parte superior de la clase donde se definen otras variables:
...código omitido...
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
...código omitido...
El archivo final homework_spider.py tiene este aspecto:
import scrapy
from scrapy import FormRequest, Request
class HomeworkSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
En tu directorio school-scraper/school_scraper, ejecuta el siguiente comando para verificar que extrae correctamente los datos de los deberes:
scrapy crawl homework_spider
Deberías ver el resultado extraído entre los demás registros:
...resultado omitido...
2024-03-20 01:36:05 [scrapy.core.scraper] DEBUG: Extraído de <200 https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html>
{'MATHS': "Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.n", 'ENGLISH': 'Lee la historia «Manny and His Monster Manners» en las páginas 100-107 de tu diario de lectura y completa las actividades de las páginas 108 y 109 según la historia.nnReading Log kitabınızın 100-107 sayfalarındaki "Manny and His Monster Manners" nimli hikayeyi okuyunuz ve 108 ve 109'uncu sayfalarındaki aktiviteleri hikayeye göre tamamlayınız.n'}
2024-03-20 01:36:05 [scrapy.core.engine] INFO: Cerrando araña (terminado)
...salida omitida...
¡Enhorabuena! Ha implementado su primera araña. ¡Creemos la siguiente!
Crear la araña de la lista de comidas
Para crear una araña que rastree la página de la lista de comidas, ejecuta el siguiente comando en tu directorio school-scraper/school_scraper:
scrapy genspider meal_spider systemcraftsman.github.io/scrapy-demo/website/index.html
La clase de araña generada debería tener este aspecto:
class MealSpiderSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
El proceso de creación de la araña meal es muy similar al de la araña homework. La única diferencia es la página HTML que se rastrea.
Para ahorrar tiempo, sustituya todo el contenido de meal_spider.py por lo siguiente:
import scrapy
from datetime import datetime
from scrapy import FormRequest, Request
class MealSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
meal_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html"
date_str = "13.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.meal_page_url,
callback=self.parse_meal_page
)
def parse_meal_page(self, response):
if response.status == 200:
data = {"BREAKFAST": "", "LUNCH": "", "SALAD/DESSERT": "", "FRUIT TIME": ""}
week_no = datetime.strptime(self.date_str, '%d.%m.%Y').isoweekday()
rows = response.xpath('//*[@class="table table-condensed table-yemek-listesi"]//tr')
key = ""
try:
for row in rows[1:]:
if self._get_item(row, week_no) in data.keys():
key = self._get_item(row, week_no)
else:
data[key] = self._get_item(row, week_no, "n")
finally:
return data
def _get_item(self, row, col_number, seperator=""):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for i, content in enumerate(contents):
item_str = item_str + content + seperator
return item_str
Observe que las funciones parse y after_login son casi iguales. La única diferencia es el nombre de la función de devolución de llamada parse_meal_page, que analiza el HTML de la página de comidas utilizando una lógica XPath diferente. La función también recibe ayuda de una función privada llamada _get_item, que funciona de manera similar a la creada para los deberes.
La forma en que se utiliza la tabla en las páginas de tareas y de la lista de comidas es diferente, por lo que el parseo y el manejo de los datos también difieren.
Para verificar meal_spider, ejecuta el siguiente comando en tu directorio school-scraper/school_scraper:
scrapy crawl meal_spider
El resultado debería ser similar a este:
...salida omitida...
2024-03-20 02:44:42 [scrapy.core.scraper] DEBUG: Scraped from <200 https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html>
{'BREAKFAST': 'PANCAKE n KREM PEYNİR n SÜZME PEYNİR nnKAKAOLU FINDIK KREMASI n SÜTn', 'LUNCH': 'TARHANA ÇORBAnEKŞİLİ KÖFTEnERİŞTEn', 'SALAD/DESSERT': 'AYRANnKIRMIZILAHANA SALATAnROKALI GÖBEK SALATAn', 'FRUTA': 'FINDIK& KURU ÜZÜMn'}
2024-03-20 02:44:42 [scrapy.core.engine] INFO: Cerrando araña (finalizado)
...salida omitida...
NOTA: Dado que los datos proceden de un sitio web original, no se ha traducido ninguno de ellos para mantener su formato original.
Formatear los datos
Los Scrapers que ha creado para las tareas y la página de listas de comidas están listos para extraer los datos en formato JSON. Sin embargo, es posible que desee dar formato a los datos activando las arañas mediante programación.
En las aplicaciones Python, el archivo main.py suele servir como punto de entrada donde se inicializa la aplicación invocando sus componentes clave. Sin embargo, en este proyecto Scrapy, no se ha creado un punto de entrada porque la CLI de Scrapy proporciona un marco preconstruido para implementar las arañas, y estas se pueden ejecutar a través de la misma CLI.
Para dar formato a los datos en este escenario, creará un programa básico de línea de comandos de Python que toma argumentos y extrae los datos en consecuencia.
Crea un archivo llamado main.py en el directorio raíz de tu proyecto Scraper con el siguiente contenido:
import sys
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from school_scraper.school_scraper.spiders.homework_spider import HomeworkSpider
from school_scraper.school_scraper.spiders.meal_spider import MealSpider
results = []
class ResultsPipeline(object):
def process_item(self, item, spider):
results.append(item)
def _prepare_message(title, data_dict):
if len(data_dict.items()) == 0:
return None
message = f"===={title}====n----------------n"
for key, value in data_dict.items():
message = message + f"==={key}===n{value}n----------------n"
return message
def main(args=None):
if args is None:
args = sys.argv
settings = get_project_settings()
settings.set("ITEM_PIPELINES", {'__main__.ResultsPipeline': 1})
process = CrawlerProcess(settings)
if args[1] == "homework":
process.crawl(HomeworkSpider)
process.start()
print(_prepare_message("HOMEWORK ASSIGNMENTS", results[0]))
elif args[1] == "meal":
process.crawl(MealSpider)
process.start()
print(_prepare_message("LISTA DE COMIDAS", results[0]))
if __name__ == "__main__":
main()
El archivo main.py tiene una función principal y es la función de punto de entrada para su aplicación. Cuando ejecuta main.py, se invoca el método principal. El método principal toma un argumento de matriz llamado args, que puede utilizar para enviar argumentos al programa.
El archivo main.py comienza comprobando el valor de args y configura los ajustes del rastreador Scrapy definiendo una canalización llamada ResultsPipeline. Como puede ver, ResultsPipeline se define en este archivo, pero las canalizaciones se definen en el paquete pipelines.
ResultsPipeline simplemente obtiene los resultados y los añade a una matriz llamada results. Eso significa que la matriz results se puede utilizar como entrada para la función privada _prepare_message, que se utiliza para preparar el mensaje formateado. Esto se hace por araña en la función principal, y la distinción es posible gracias al segundo argumento de la matriz args, que representa el tipo de araña. Si el tipo de araña es homework, el proceso del rastreador llama a HomeworkSpider y lo inicia. Si el tipo de araña es meal, el proceso del rastreador llama a MealSpider y lo inicia.
Cuando se inicia una araña, la ResultsPipeline inyectada añade los datos a la matriz de resultados, y la función principal puede utilizarlos para cada araña llamando a _prepare_message, lo que ayuda a formatear la salida de datos.
En el directorio principal del proyecto, ejecute el archivo main.py recién implementado con el siguiente comando para recuperar las tareas:
python main.py homework
El resultado debería ser similar a este:
...salida omitida...
====TAREAS ASIGNADAS====
----------------
===MATEMÁTICAS===
Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.
----------------
===INGLÉS===
Lee la historia «Manny and His Monster Manners» en las páginas 100-107 de tu diario de lectura y completa las actividades de las páginas 108 y 109 según la historia.
Lea el cuento «Manny and His Monster Manners» en las páginas 100-107 de su libro de lectura y complete las actividades de las páginas 108 y 109 según el cuento.
----------------
...salida omitida...
Para obtener la lista de comidas del día, ejecuta el comando python main.py meal. El resultado será similar a este:
...salida omitida...
====LISTA DE COMIDAS====
----------------
===DESAYUNO===
PANCAKE
KREM PEYNİR
SÜZME PEYNİR
KAKAOLU FINDIK KREMASI
SÜT
----------------
===ALMUERZO===
TARHANA ÇORBA
EKŞİLİ KÖFTE
ERİŞTE
----------------
===ENSALADA/POSTRE===
AYRAN
KIRMIZILAHANA SALATA
ROKALI GÖBEK SALATA
----------------
===FRUTA===
FINDIK& KURU ÜZÜM
----------------
...salida omitida...
Consejos para superar los obstáculos habituales del Scraping web
¡Enhorabuena! Si has llegado hasta aquí, ya has creado oficialmente un Scraper Scrapy.
Aunque crear un Scraper web con Scrapy es fácil, es posible que te encuentres con algunos obstáculos durante la implementación, como CAPTCHAs, bloqueos de IP, gestión de sesiones o cookies y sitios web dinámicos. Veamos algunos consejos para manejar estas diferentes situaciones:
Sitios web dinámicos
Los sitios web dinámicos ofrecen contenidos variables a los visitantes en función de factores como la configuración del sistema, la ubicación, la edad y el sexo. Por ejemplo, dos personas que visitan el mismo sitio web dinámico pueden ver contenidos diferentes adaptados a ellas.
Aunque Scrapy puede extraer contenido web dinámico, no está diseñado para ello. Para extraer contenido dinámico, es necesario programar Scrapy para que se ejecute regularmente, guardando y comparando los resultados para realizar un seguimiento de los cambios en las páginas web a lo largo del tiempo.
En ciertos casos, el contenido dinámico de las páginas web puede tratarse como estático, especialmente cuando esas páginas solo se actualizan ocasionalmente.
CAPTCHAs
Por lo general, los CAPTCHA son imágenes dinámicas que contienen caracteres alfanuméricos. Los visitantes de la página deben introducir los valores correspondientes de la imagen CAPTCHA para superar el proceso de validación.
Los CAPTCHA se utilizan en las páginas web para garantizar que el visitante de la página es humano (en contraposición a una araña o un bot) y, a menudo, para evitar el Scraping web.
El sistema escolar ficticio con el que has trabajado aquí no utiliza un sistema CAPTCHA, pero si te encuentras con uno, puedes crear un middleware Scrapy que descargue el CAPTCHA y lo convierta en texto utilizando una biblioteca OCR.
Manipulación de sesiones y cookies
Cuando abres una página web, entras en una sesión dentro del sistema de esa página. Esta sesión conserva tu información de inicio de sesión y otros datos relevantes para reconocerte en todo el sistema.
Del mismo modo, puedes rastrear la información sobre un visitante de una página web utilizando una cookie. Sin embargo, a diferencia de los datos de sesión, las cookies se almacenan en el ordenador del visitante en lugar de en el servidor del sitio web, y los usuarios pueden eliminarlas si lo desean. Como resultado, no puedes utilizar las cookies para mantener una sesión, pero puedes utilizarlas para diversas tareas de apoyo en las que la pérdida de datos no es crítica.
Pueden surgir situaciones en las que sea necesario manipular la sesión de un usuario o actualizar sus cookies. Scrapy puede manejar ambas situaciones, ya sea a través de sus funciones integradas o mediante bibliotecas de terceros compatibles.
Prohibición de IP
La prohibición de IP, también conocida como bloqueo de direcciones IP, es una técnica de seguridad mediante la cual un sitio web bloquea determinadas direcciones IP entrantes. Esta técnica se utiliza normalmente para impedir que los bots o las arañas accedan a información confidencial, garantizando que solo los usuarios humanos puedan acceder a los datos y procesarlos. Junto con los CAPTCHA, las empresas utilizan la prohibición de IP para disuadir las actividades de Scraping web.
En este caso, el sistema escolar no utiliza un mecanismo de bloqueo de IP. Sin embargo, si lo hubieran implementado, sería necesario adoptar estrategias como el uso de una IP dinámica u ocultar la dirección IP detrás de un Proxy para poder seguir rastreando su sitio web.
Conclusión
En este artículo, ha aprendido a crear arañas para iniciar sesión y realizar el parseo de tablas utilizando XPath en Scrapy. Además, ha aprendido a activar las arañas mediante programación para mejorar el control de los datos.
Puede acceder al código completo de este tutorial en este repositorio de GitHub.
Para aquellos que deseen ampliar las capacidades de Scrapy y superar los obstáculos del scraping, Bright Data ofrece soluciones adaptadas a los datos web públicos. La integración de Bright Data con Scrapy mejora las capacidades de scraping, los servicios de Proxy ayudan a evitar las prohibiciones de IP y Web Unlocker simplifica el manejo de CAPTCHAs y contenido dinámico, lo que hace que la recopilación de datos con Scrapy sea más eficiente.
Regístrese ahora y hable con uno de nuestros expertos en datos sobre nuestras soluciones de scraping.





