
En este artículo, aprenderás:
- Qué es Alteryx One y las funcionalidades que ofrece.
- Por qué conectarlo a datos web de Bright Data hace que los flujos de trabajo sean más reveladores.
- Cómo definir un flujo de trabajo automatizado en Alteryx One utilizando datos web estructurados y actualizados obtenidos mediante web scraping de Bright Data.
¡Comencemos!
¿Qué es Alteryx One?
Alteryx One es una plataforma de análisis unificada e impulsada por IA. Reúne preparación de datos, análisis, automatización e IA en un único entorno. En detalle, ayuda a las organizaciones a conectarse a múltiples fuentes de datos, crear flujos de trabajo reutilizables y operacionalizar insights a escala.
Las principales funcionalidades que ofrece Alteryx One son:
- Análisis nativo con IA: Integra IA en los flujos de trabajo analíticos para detectar patrones, generar insights y apoyar el modelado predictivo sin herramientas adicionales.
- Preparación de datos lista para IA: Conecta, limpia y transforma datos de múltiples fuentes en conjuntos de datos confiables y listos para el análisis, con gobernanza integrada.
- Automatización de flujos de trabajo: Automatiza tareas analíticas repetitivas y procesos de extremo a extremo, reduciendo el esfuerzo manual y mejorando la consistencia.
- Espacio de trabajo analítico unificado: Proporciona un entorno único donde los equipos pueden crear, ejecutar y gestionar flujos de trabajo analíticos de forma colaborativa.
- Gobernanza y seguridad empresarial: Garantiza el cumplimiento normativo, el seguimiento del linaje de datos y el acceso controlado para que el análisis pueda escalar de forma segura en grandes organizaciones.
- Integraciones extensibles: Se conecta con sistemas empresariales y LLMs para integrar el análisis directamente en los ecosistemas de datos existentes.
Cómo Bright Data apoya a Alteryx One
Los flujos de trabajo de Alteryx One son tan potentes como los datos que consumen. Sin duda, la plataforma ofrece capacidades sólidas para la preparación de datos, el análisis y la automatización. Sin embargo, la calidad, actualidad y fiabilidad de los datos de entrada determinan en última instancia la precisión de los resultados. Aquí es donde Bright Data desempeña un papel fundamental como proveedor de datos web de nivel empresarial.
Bright Data entrega datos web estructurados a gran escala a través de una infraestructura de proxies global con más de 400 millones de IPs en 195 países. Con un tiempo de actividad del 99,99% y una tasa de éxito del 99,95%, proporciona la fiabilidad necesaria para pipelines de análisis de nivel productivo.
Para una integración directa con Alteryx One, puedes comenzar recuperando datos web actualizados mediante las Web Scraping APIs de Bright Data o accediendo a datos web estáticos a través de los datasets de Bright Data. Estos datos pueden entregarse automáticamente a Amazon S3 (o cualquier otro destino de entrega habitual) en un formato estructurado.
Alteryx One puede entonces importar ese dataset directamente desde S3, donde se procesa mediante un flujo de trabajo sin código. Finalmente, los resultados procesados se escriben de vuelta en S3 (o cualquier destino preferido) para su uso posterior.
El resultado es un pipeline de análisis automatizado de extremo a extremo. Aquí, Bright Data garantiza una ingesta de datos fiable y de nivel empresarial, mientras que Alteryx One transforma esos datos en insights accionables.
Crea un flujo de trabajo automatizado de análisis de datos en Alteryx One con datos web de Bright Data
En este capítulo paso a paso, se te guiará a través de la configuración de un flujo de trabajo automatizado en Alteryx One.
Para demostrar este tipo de flujo de trabajo de automatización web, utilizarás los siguientes componentes:
- El Yahoo Finance Scraper de Bright Data para recopilar datos bursátiles actualizados, configurándolo para la entrega en Amazon S3.
- Un flujo de trabajo de Alteryx One que importa los datos, los ordena por volumen y los divide en dos datasets: uno para acciones positivas y otro para acciones negativas. Luego, escribe los resultados procesados de vuelta en Amazon S3.
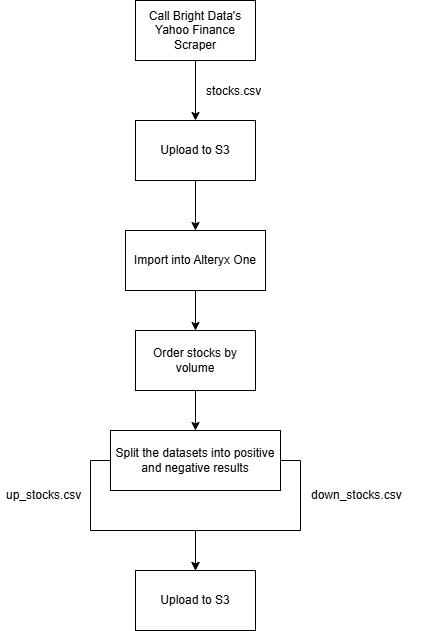
¡Sigue las instrucciones a continuación para construir este flujo de trabajo!
Requisitos previos
Para seguir esta sección, asegúrate de tener:
- Una cuenta de Alteryx One (incluso una en prueba gratuita es válida).
- Un bucket de S3 definido en tu cuenta de AWS.
- Una cuenta de Bright Data con una clave API configurada. Sigue las instrucciones oficiales para generar tu clave API.
En este tutorial, asumiremos que tu bucket de S3 se llama bright-data-datasets. Sin embargo, cualquier otro nombre de bucket también funcionará.
Paso #1: Configura la API de Scraping de Bright Data
El primer paso en tu pipeline de automatización de datos web es recuperar los datos de origen desde la web. Para ello, utilizarás el Yahoo Finance Scraper de Bright Data para recopilar datos financieros en tiempo real. ¡Comencemos!
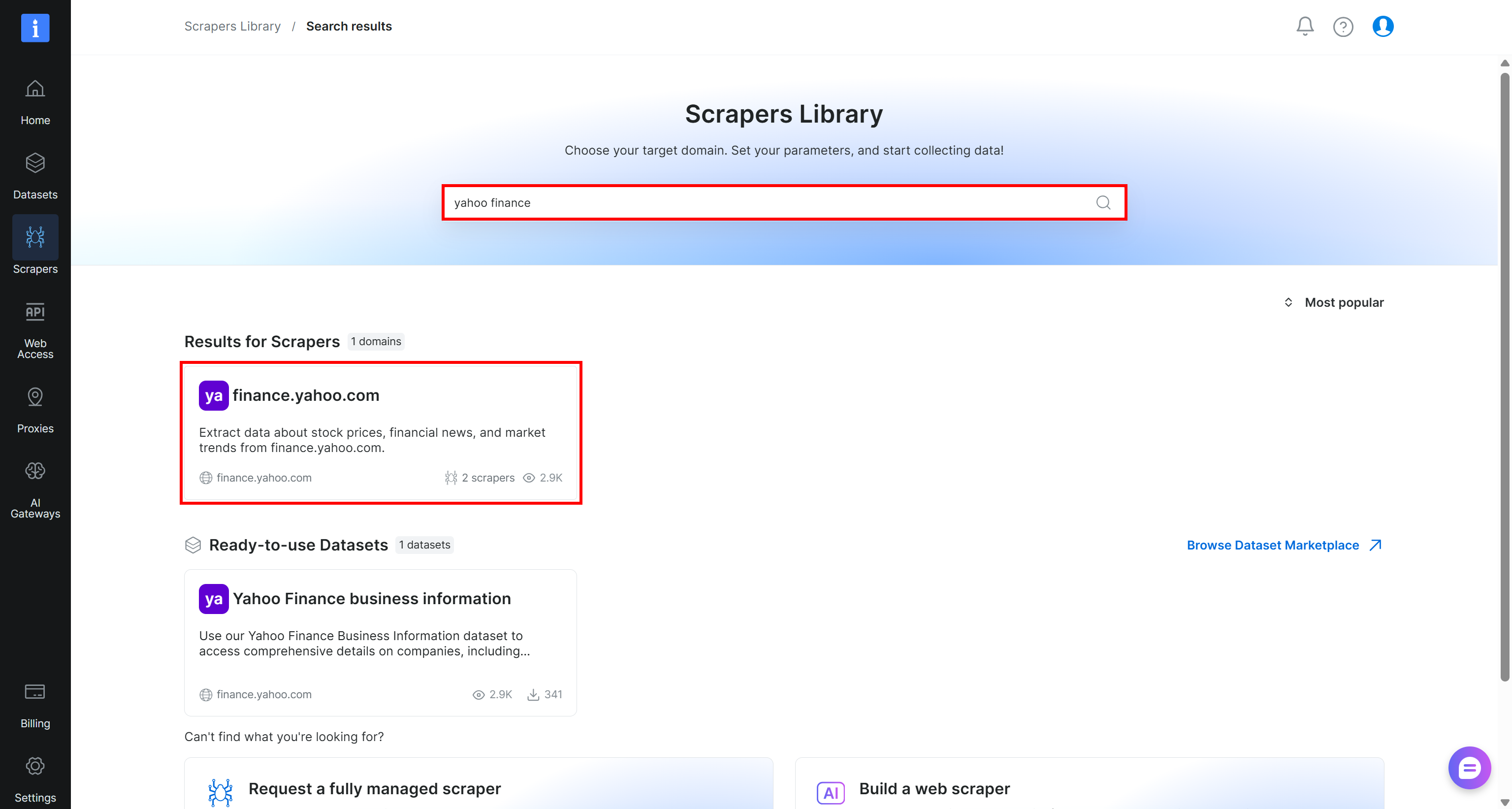
Empieza creando una cuenta de Bright Data, si aún no tienes una. De lo contrario, inicia sesión en tu cuenta existente. En el panel de control, navega a la página “Scrapers > Scrapers Library”:
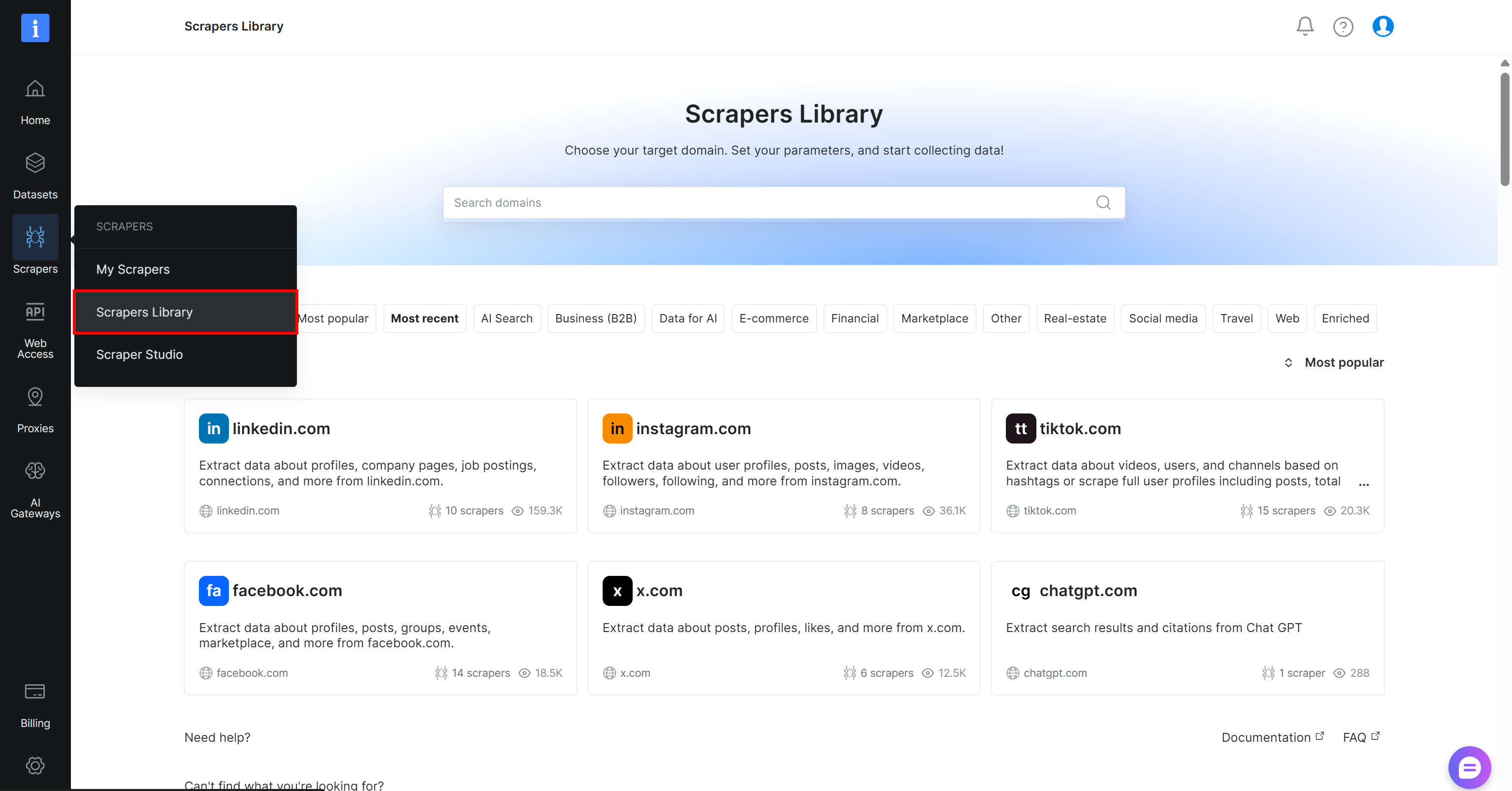
Busca “yahoo finance” y selecciona el scraper “finance.yahoo.com”:
En la página del Yahoo Finance Scraper, revisa los requisitos de entrada del scraper y el esquema de salida:
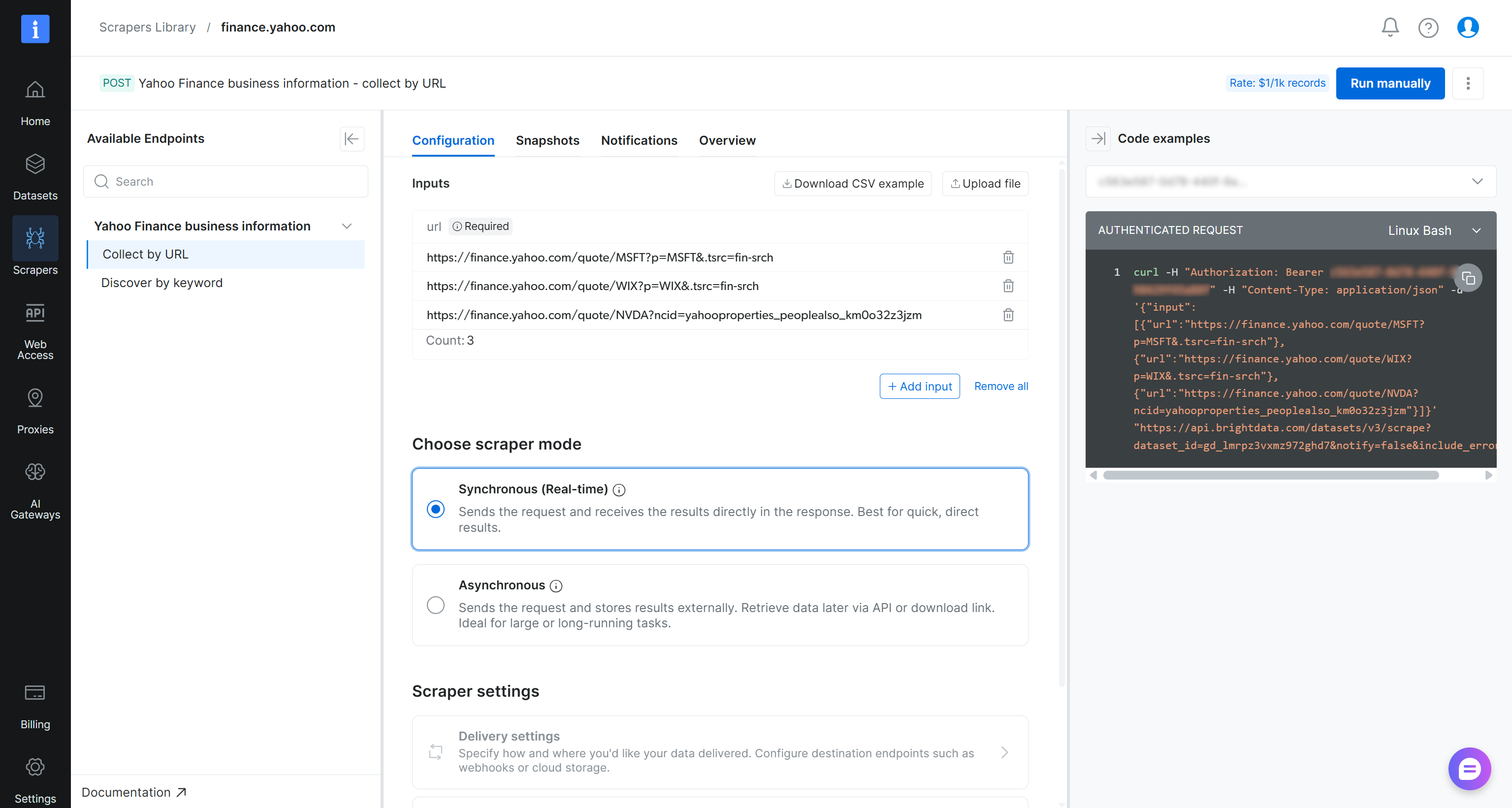
En términos generales, el scraper acepta una o más URLs de páginas de acciones de Yahoo Finance como entrada y devuelve datos financieros estructurados en tiempo real. ¡Exactamente lo que necesitamos!
Paso #2: Configura la entrega a S3
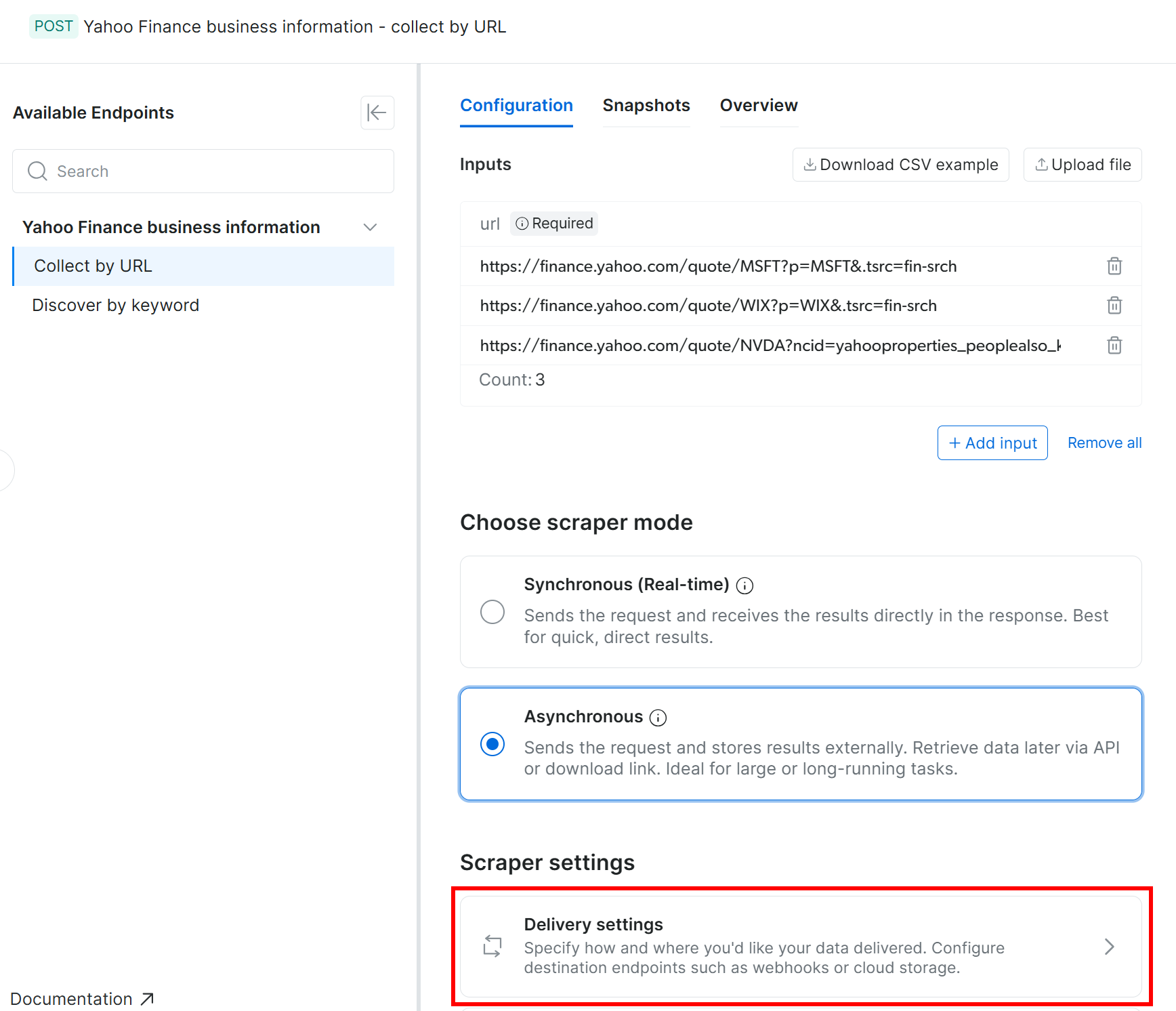
Las Web Scraping APIs de Bright Data admiten la entrega automática de datos extraídos a Amazon S3 (junto con varios otros proveedores de almacenamiento en la nube y métodos de entrega). Para habilitar la entrega a Amazon S3, primero debes cambiar el scraper al modo asíncrono.
En la pestaña “Configuration”, selecciona la opción “Asynchronous”. Luego, presiona “Delivery settings”:
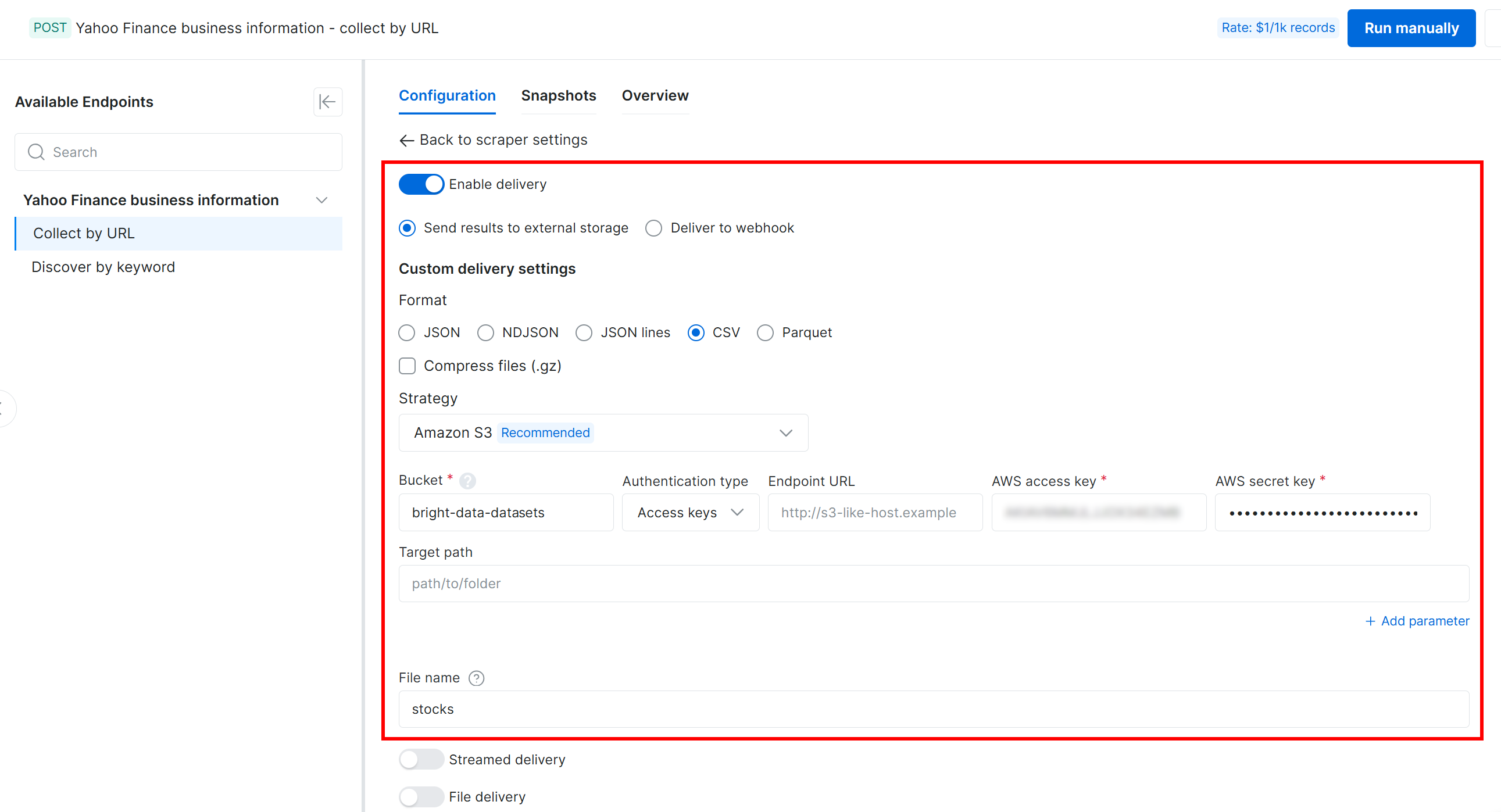
A continuación, configura la entrega a tu bucket de Amazon S3 con los siguientes ajustes:
- Activa el interruptor “Enable delivery”.
- Establece el formato de datos de salida en CSV.
- Selecciona “Amazon S3” como destino de almacenamiento.
- Introduce el nombre de tu bucket de S3 (en este ejemplo,
bright-data-datasets). (Puedes dejar el campo “Endpoint URL” vacío.) - Deja el campo “Target path” vacío para subir el archivo a la carpeta raíz del bucket.
- Establece la opción “Authentication type” en “Access keys”.
- Pega tu AWS Access Key ID y AWS Secret Access Key.
- Establece el nombre del archivo como
stocks.
Con esta configuración, la Web Scraping API se ejecuta en modo asíncrono. En lugar de devolver los datos de inmediato, Bright Data crea un trabajo de scraping que se ejecuta en su infraestructura. Una vez completado el trabajo, los datos extraídos se suben automáticamente a tu bucket de Amazon S3. ¡Cómodo y sin intervención manual!
Paso #3: Ejecuta la tarea de recuperación de datos web
Para verificar que el flujo de trabajo de extracción de datos web funciona correctamente, añade algunas URLs de acciones de Yahoo Finance como entrada. En este ejemplo, asumiremos que deseas rastrear las 10 principales acciones del Nasdaq (es decir, NVDA, AAPL, GOOGL, MSFT, AMZN, TSLA, META, AVGO, WMT y AMD).
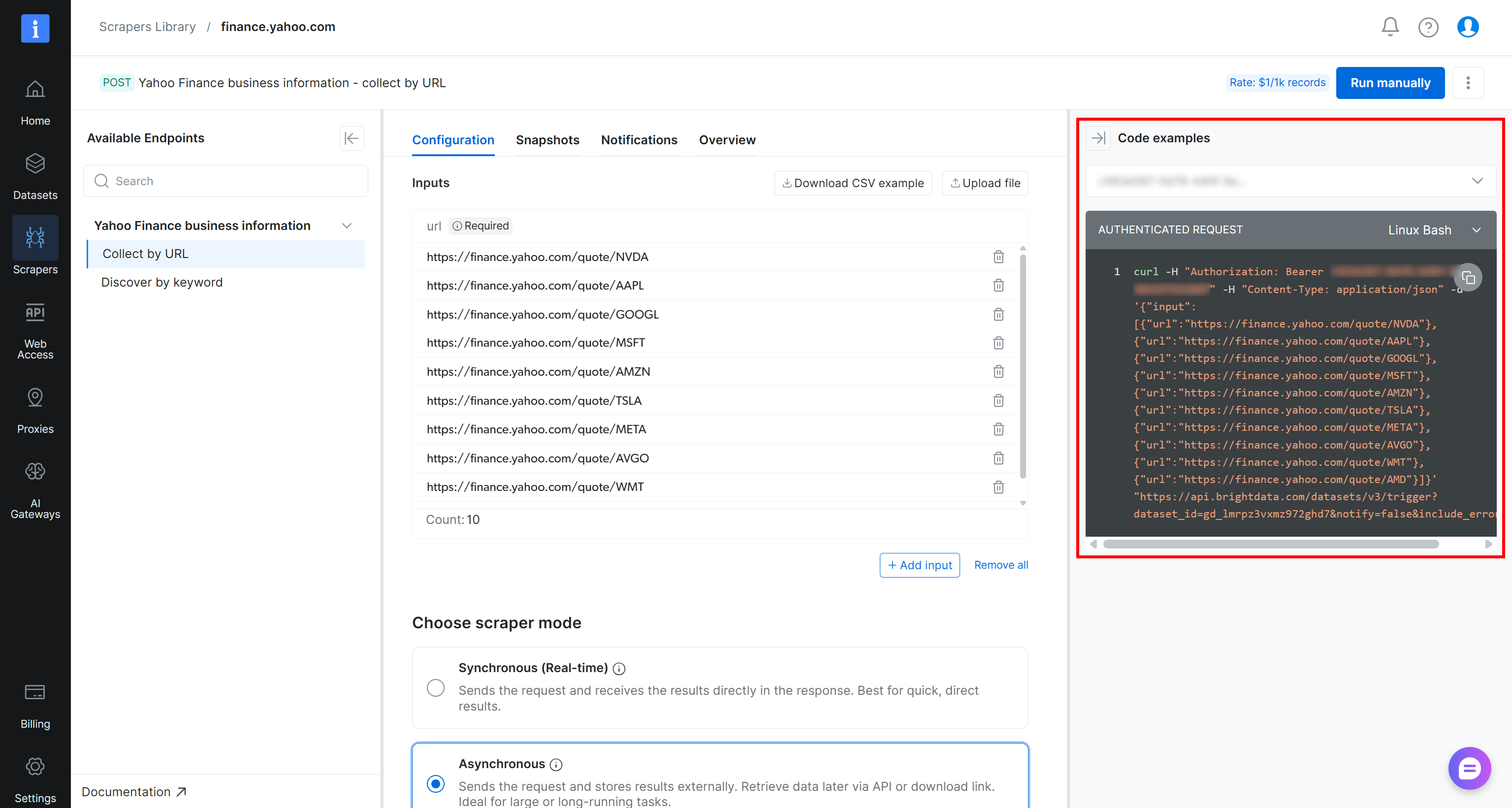
Para activar la tarea de scraping de forma programática, puedes usar el fragmento cURL proporcionado en la página del scraper:
curl -H "Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>" -H "Content-Type: application/json" -d '{"input":[{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}]}' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true"Alternativamente, puedes ejecutar el siguiente script de Python:
# pip install requests
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())En ambos casos, asegúrate de reemplazar <YOUR_BRIGHT_DATA_API_KEY> con tu clave API de Bright Data.
Nota: Para un enfoque aún más sencillo, ejecuta la tarea haciendo clic en el botón “Run manually” directamente desde el panel de control.
Una vez activada, la solicitud de scraping se enviará a la infraestructura en la nube de Bright Data, donde comenzará la tarea de extracción. Puedes monitorear su estado en tiempo real desde el panel de control de Bright Data:
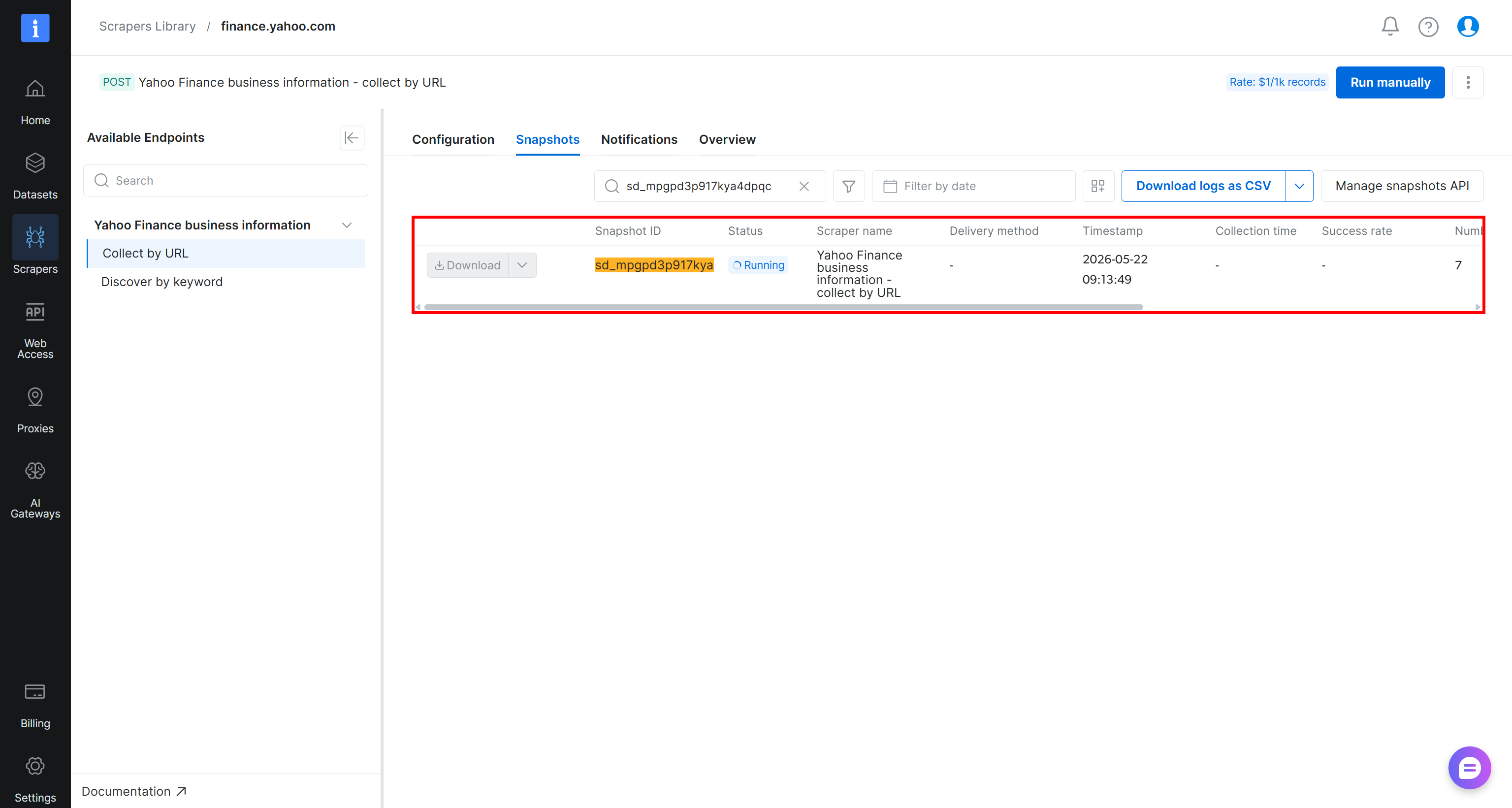
Cuando el estado de la tarea cambie a “Ready”, abre tu bucket de Amazon S3. Deberías ver un nuevo archivo llamado stocks.csv:

Descarga el archivo stocks.csv y ábrelo. Verás algo como esto:
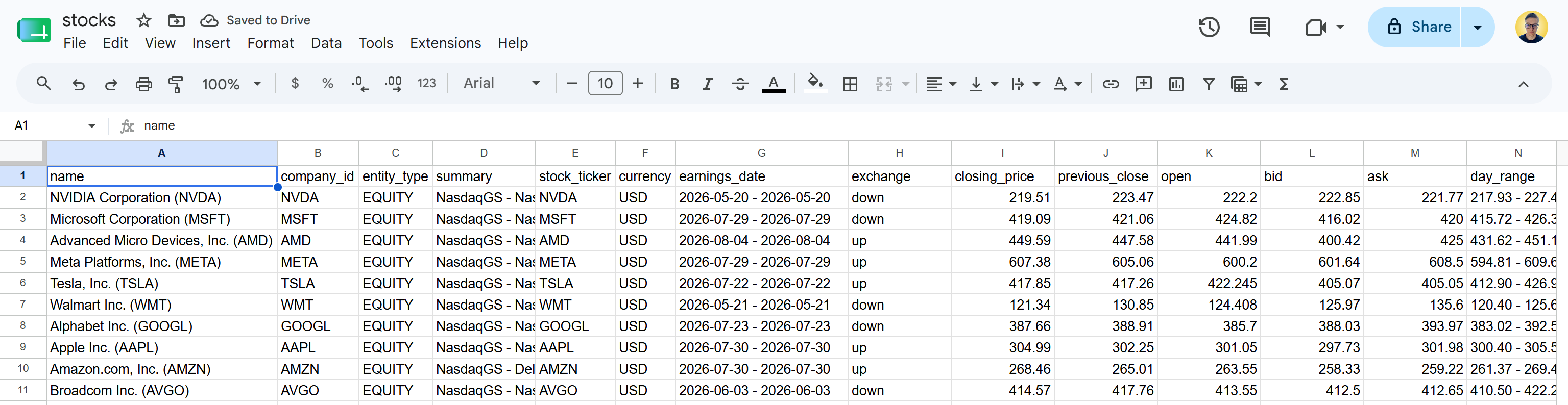
Estos son los mismos datos bursátiles disponibles en las páginas de Yahoo Finance especificadas. La API del Yahoo Finance Scraper de Bright Data recuperó los datos bursátiles y los transformó en un formato CSV estructurado.
Para comprender mejor cómo están estructurados los datos extraídos y qué columnas están disponibles, consulta la sección “Dictionary” en la pestaña “Overview” de la página del scraper de Yahoo Finance:
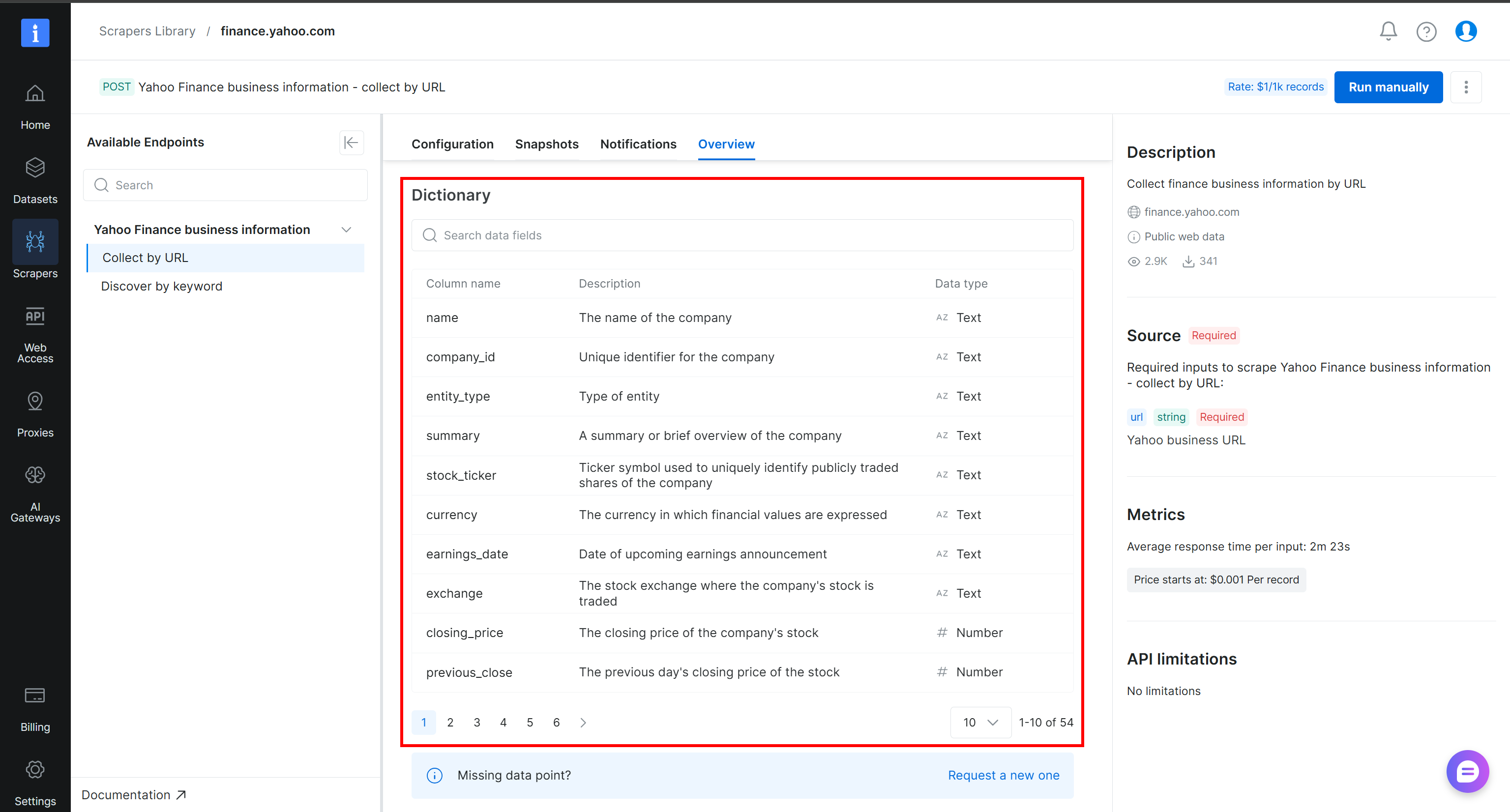
¡Genial! Ahora tienes los datos necesarios para construir tu pipeline de datos web en Alteryx One.
Paso #4: Conecta Alteryx One a la fuente de datos de S3
Actualmente, los datos de origen extraídos se entregan a Amazon S3. El siguiente paso es conectar tu cuenta de Alteryx One a ese bucket de S3 para que los flujos de trabajo puedan acceder y analizar los datos según sea necesario.
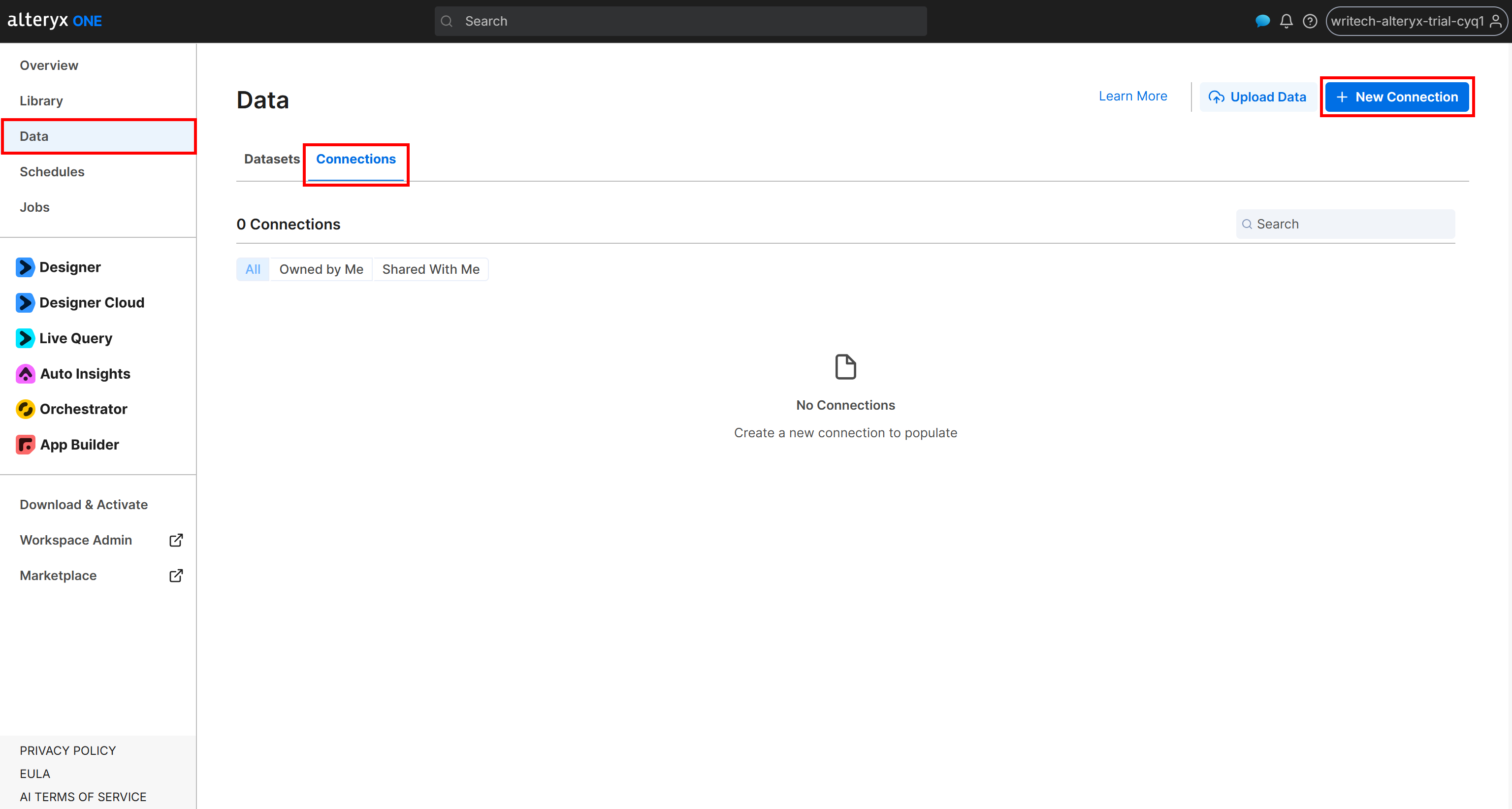
Para crear una conexión a tu bucket de Amazon S3, inicia sesión en Alteryx One. Navega a la página “Data” y abre la pestaña “Connections”. Luego haz clic en “New Connection”:
A continuación, completa el formulario de conexión “External Amazon S3” de la siguiente manera:
- Connection Name: Bright Data S3 (o cualquier nombre que prefieras).
- Default Bucket:
bright-data-datasets(o el nombre real de tu bucket). - Access Key ID y Secret Access Key: Tu AWS Access Key ID y AWS Secret Access Key.
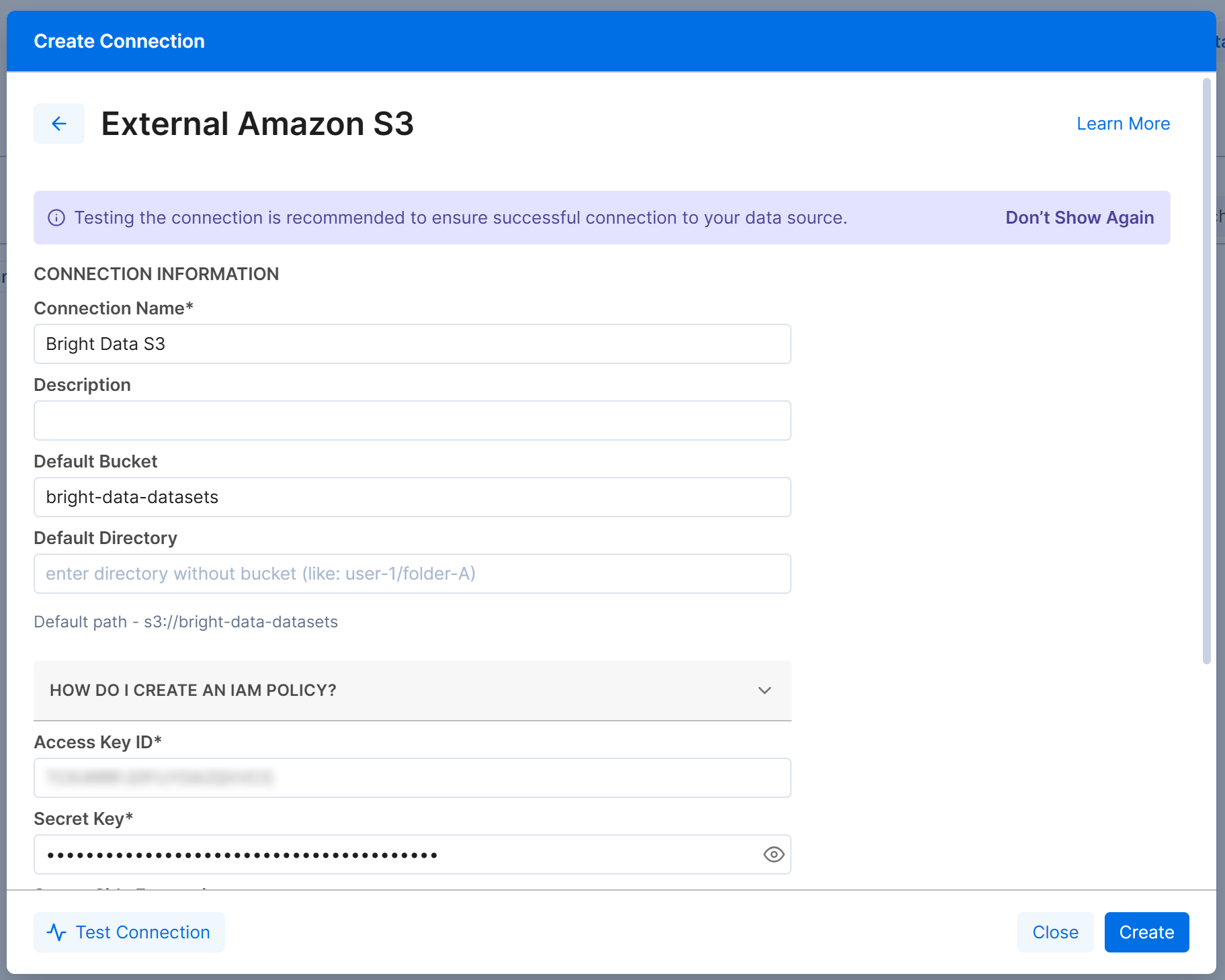
Haz clic en “Create” y la conexión de Amazon S3 aparecerá en la pestaña “Connections”:
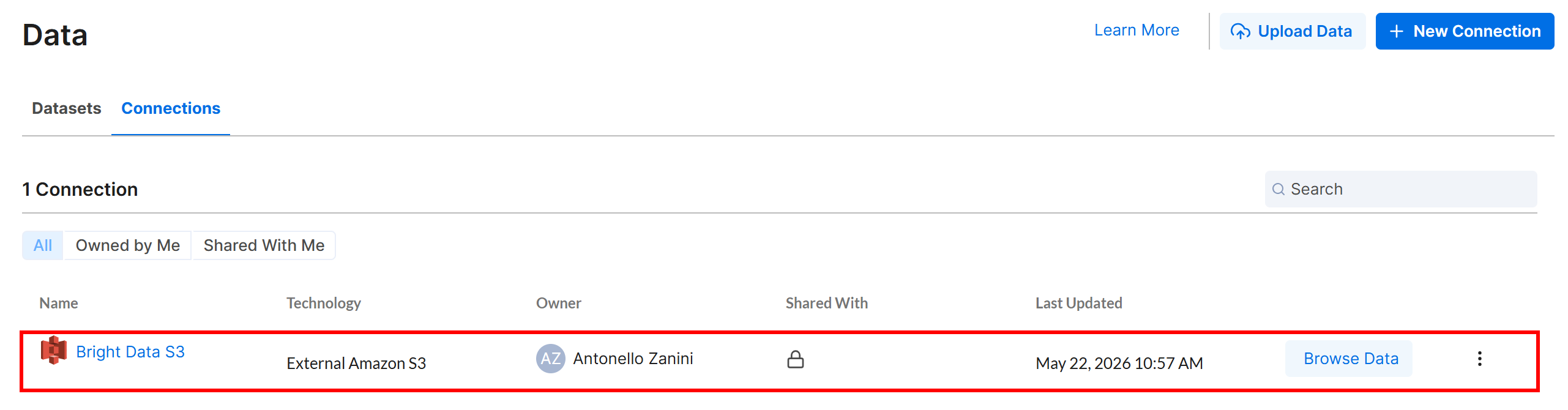
¡Excelente! Es hora de definir un flujo de trabajo en Alteryx One que lea los datos de entrada desde tu bucket de Amazon S3, donde la API del Yahoo Finance Scraper almacena su salida.
Paso #5: Inicializa el flujo de trabajo de Alteryx One
Ve a la página “Overview” y haz clic en el botón “New Workflow with Designer Cloud”:
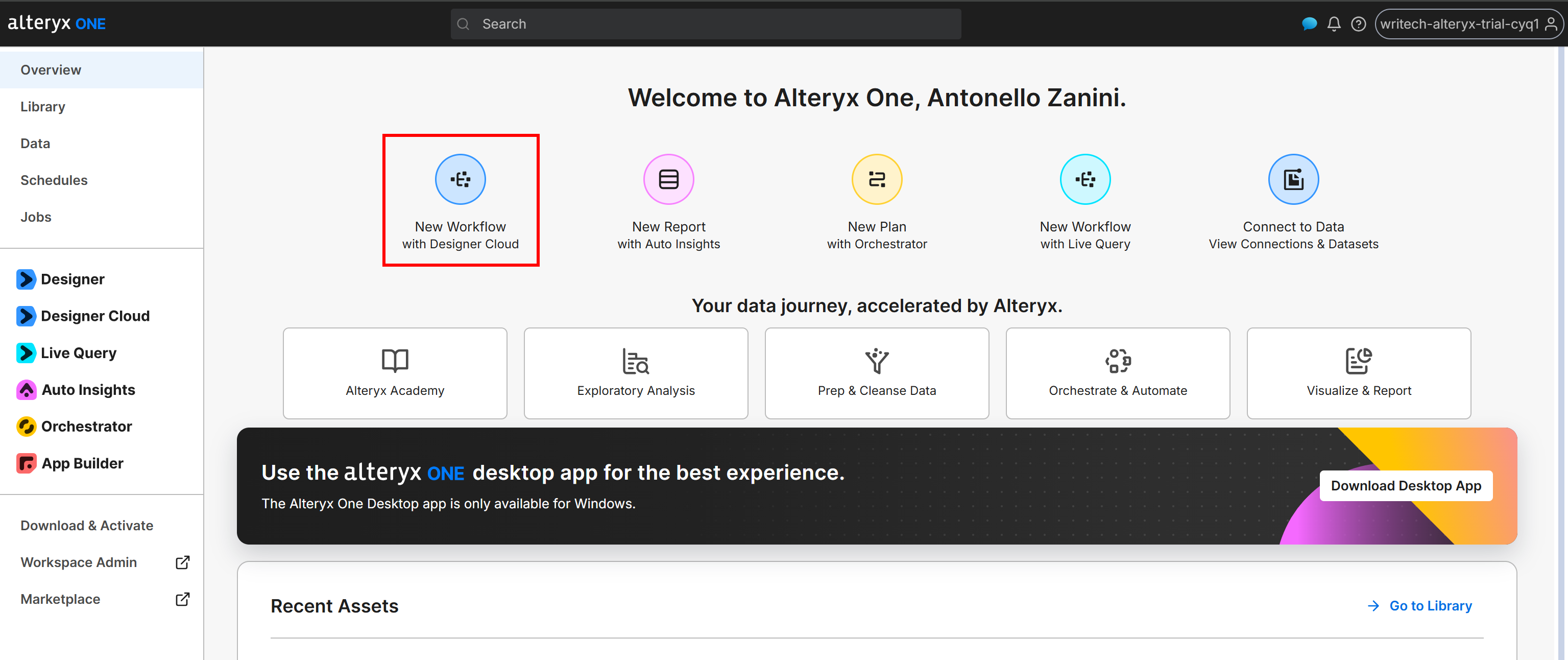
Alternativamente, puedes crear el flujo de trabajo desde la aplicación de escritorio de Alteryx One.
Dale un nombre a tu flujo de trabajo, como “Automated Stock Analyzer”:
El primer paso para construir el flujo de trabajo es cargar los datos de origen. Para ello, arrastra el nodo “Input Data” al lienzo del flujo de trabajo:

Luego haz doble clic en el nodo para configurarlo y conectarlo a tu bucket de Amazon S3, seleccionando el archivo stocks.csv. Sigue el asistente de configuración para importar el dataset. Una vez completado, deberías ver los datos cargados correctamente:
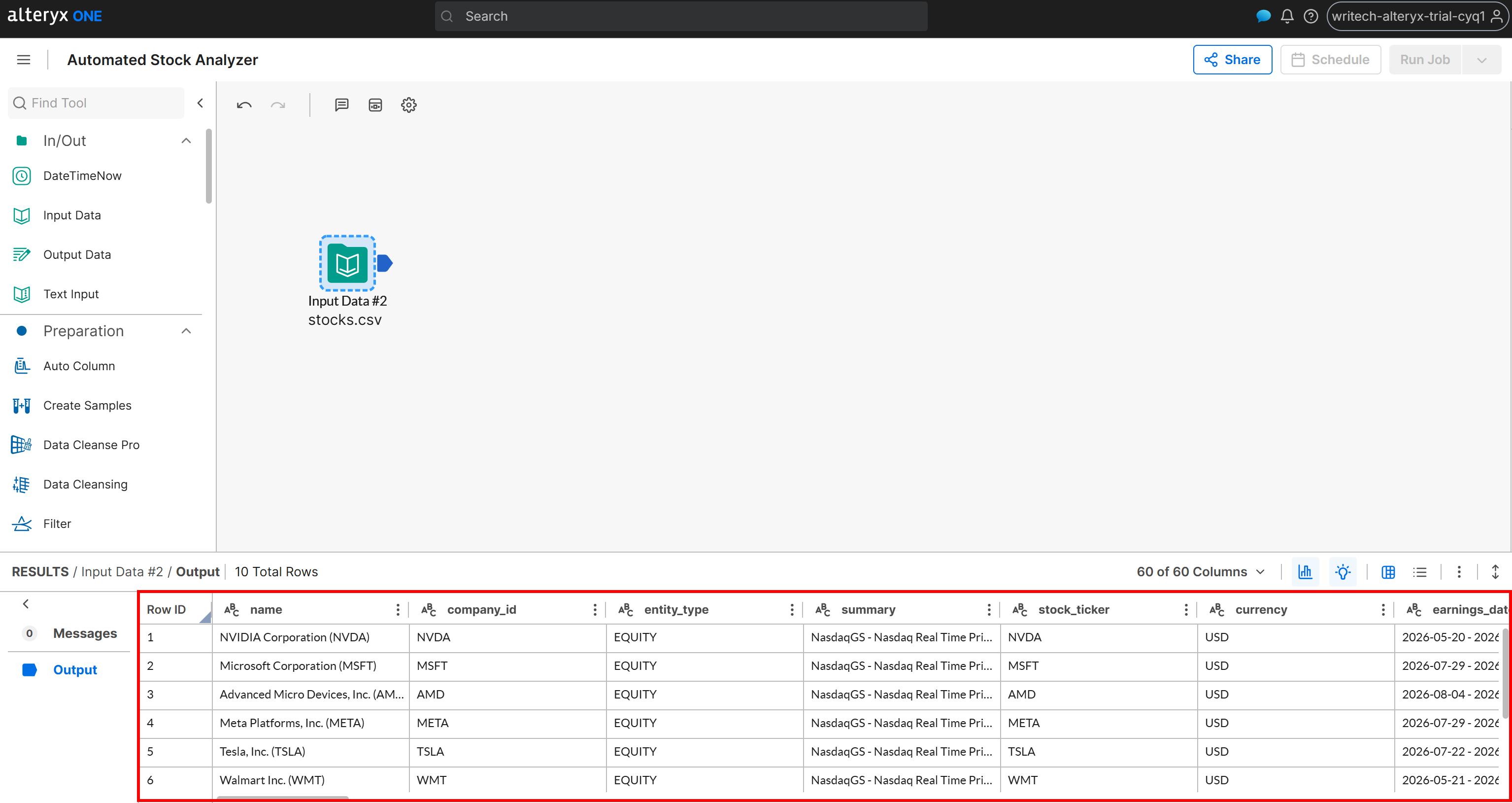
En este punto, el flujo de trabajo tiene acceso a los datos web extraídos. ¡Genial! Ahora puedes comenzar a añadir la lógica de análisis de datos.
Paso #6: Define la lógica de análisis de datos
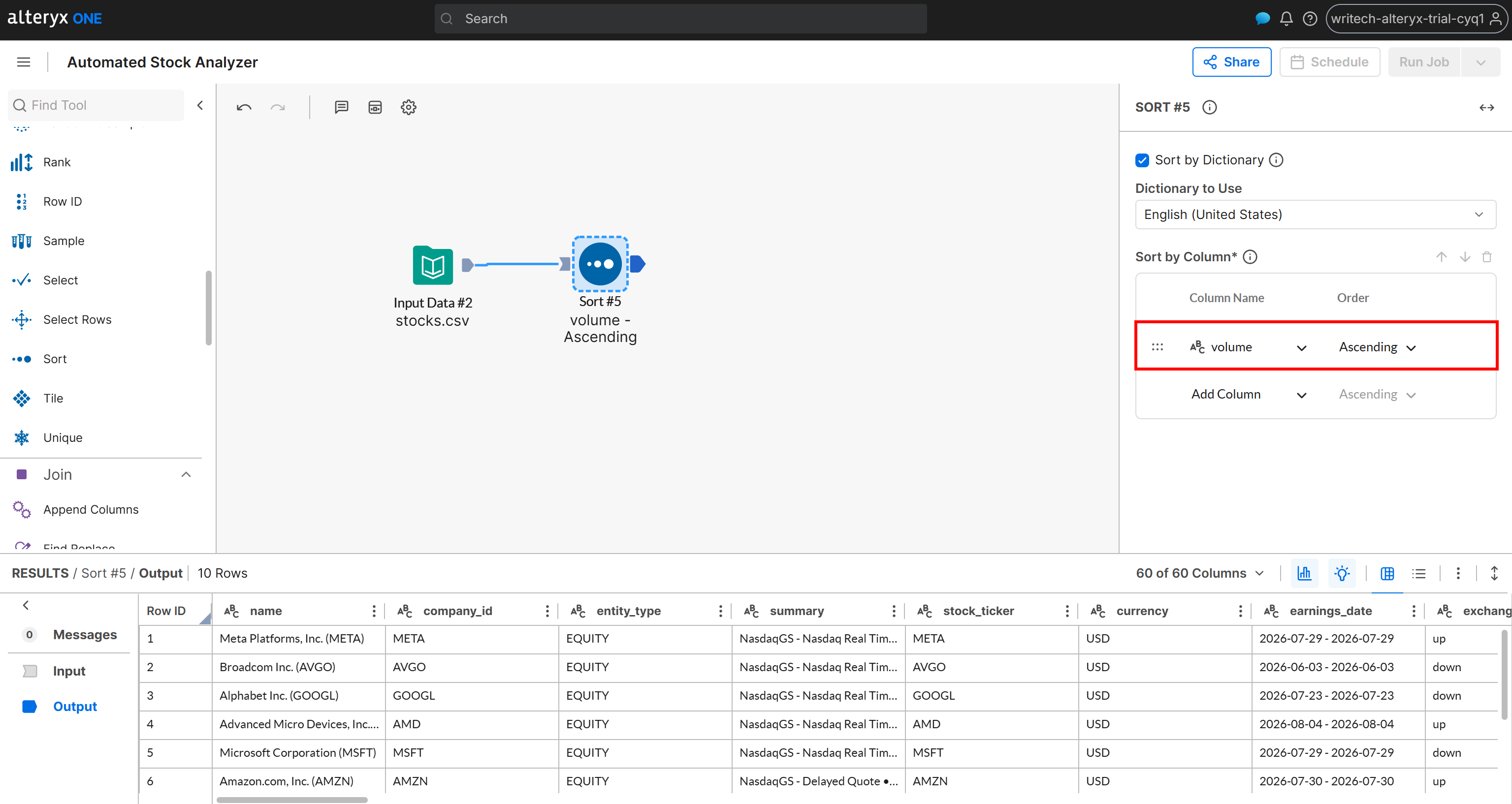
Supón que deseas que los resultados estén ordenados por un criterio específico, como el volumen de negociación diario. Añade un nodo “Sort” y, en la configuración de ordenación, selecciona la columna volume y establece el orden en Ascending:
Ahora, supón que deseas dividir el dataset en dos grupos:
- Acciones que cerraron el día en territorio positivo.
- Acciones que cerraron el día en territorio negativo.
Para ello, clasifica las acciones según si su campo exchange contiene “up” o “down”. Añade un nodo “Filter” y conéctalo a la salida del nodo “Sort”. Luego define una condición de filtro como:
- Column Name:
exchange - Operator: Equals
- Value:
up
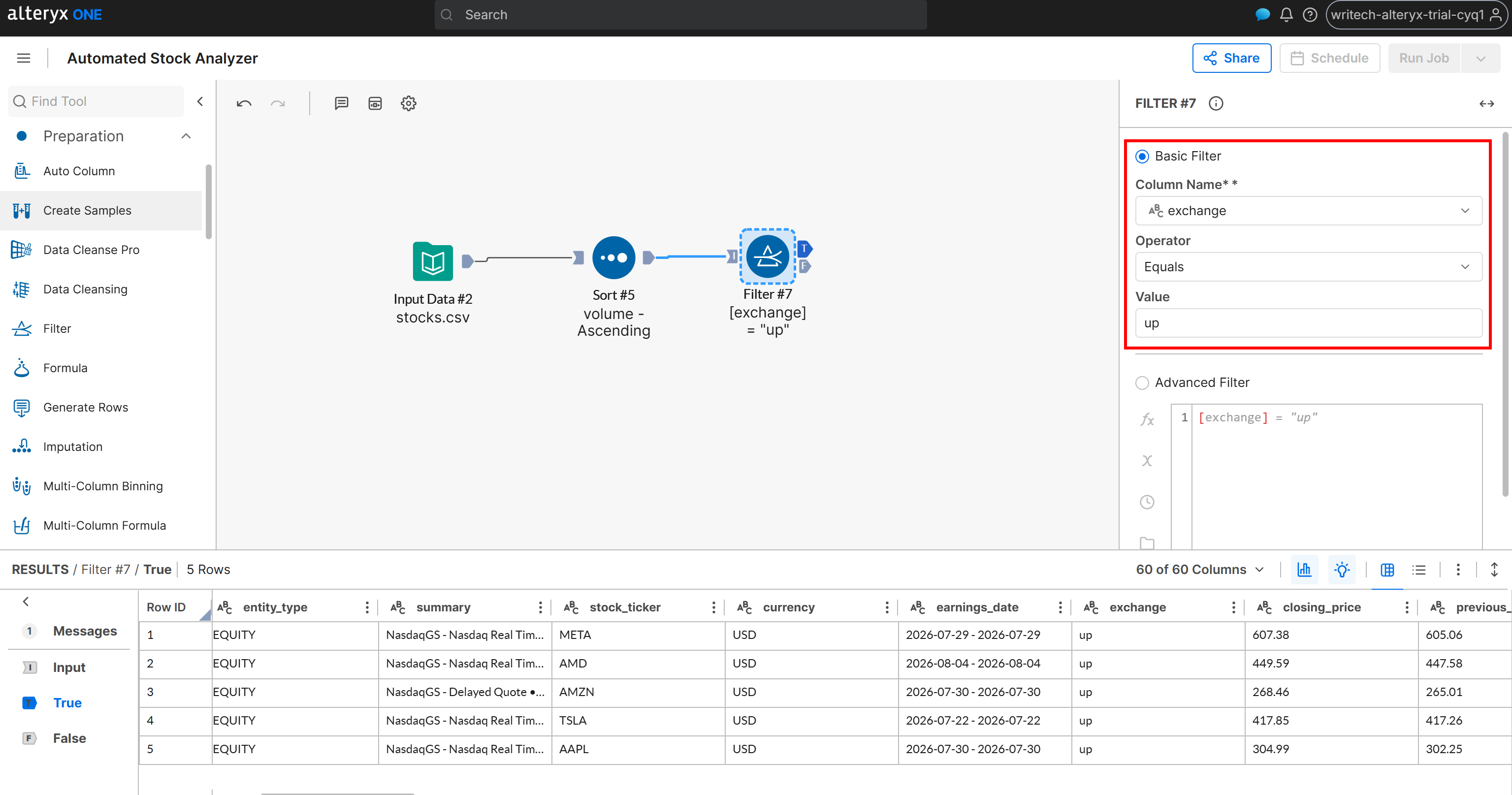
El nodo Filter produce dos salidas:
T(True): Contiene las acciones donde el campoexchangees “up”.F(False): Contiene las acciones donde el campoexchangeno es “up” (es decir, es “down”).
El paso final en este sencillo flujo de trabajo de automatización web es definir los destinos de salida. ¡Ocúpate de ello!
Paso #7: Especifica los archivos de salida
Añade un nodo “Output Data” al lienzo y conéctalo a la salida T del nodo “Filter”. Configura el nodo “Output Data” para escribir los datos en tu bucket de Amazon S3 (o cualquier otra fuente de datos conectada). Por ejemplo, crea un archivo llamado up_stocks.csv:
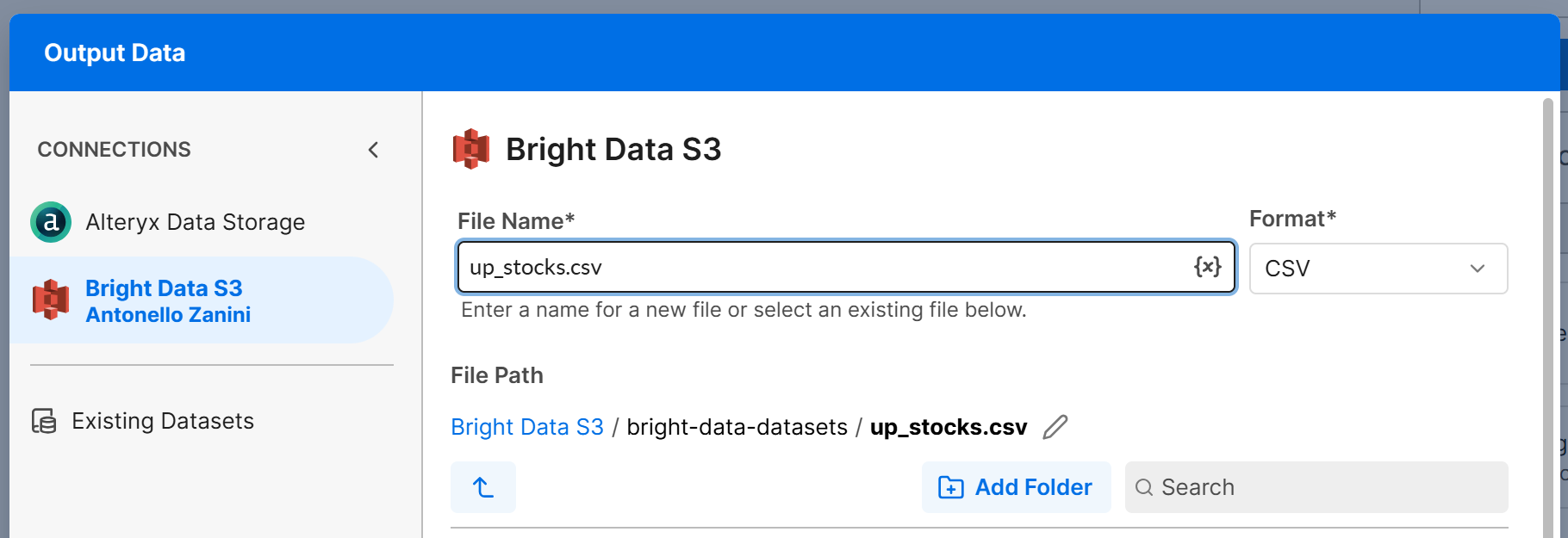
Haz clic en “Next” y luego en “Confirm” para guardar la configuración de salida para la rama T. Repite el mismo proceso para la rama F y configúrala para escribir en un archivo down_stocks.csv.
Así es como se verá el flujo de trabajo final:
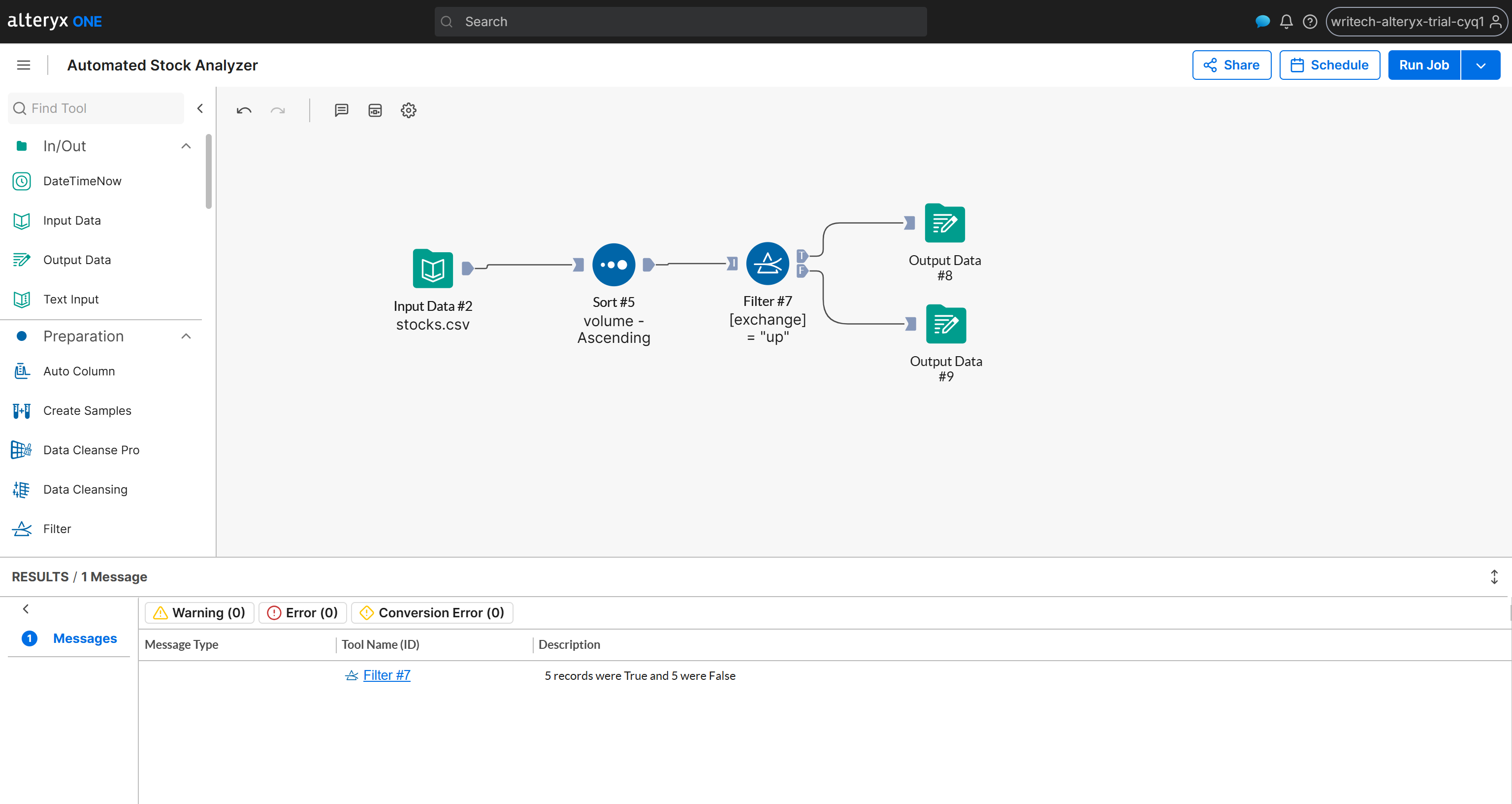
¡Misión cumplida! Ahora solo necesitas ejecutar el flujo de trabajo para verificar que todo funciona como se espera.
Paso #8: Lanza el flujo de trabajo
Haz clic en el botón “Run Job” y espera a que se complete el flujo de trabajo automatizado de análisis de datos web impulsado por Bright Data:

Una vez completada la ejecución, recibirás una notificación de éxito en Alteryx One, junto con un correo electrónico de confirmación.
Ahora, inspecciona la salida generada para el escenario T:
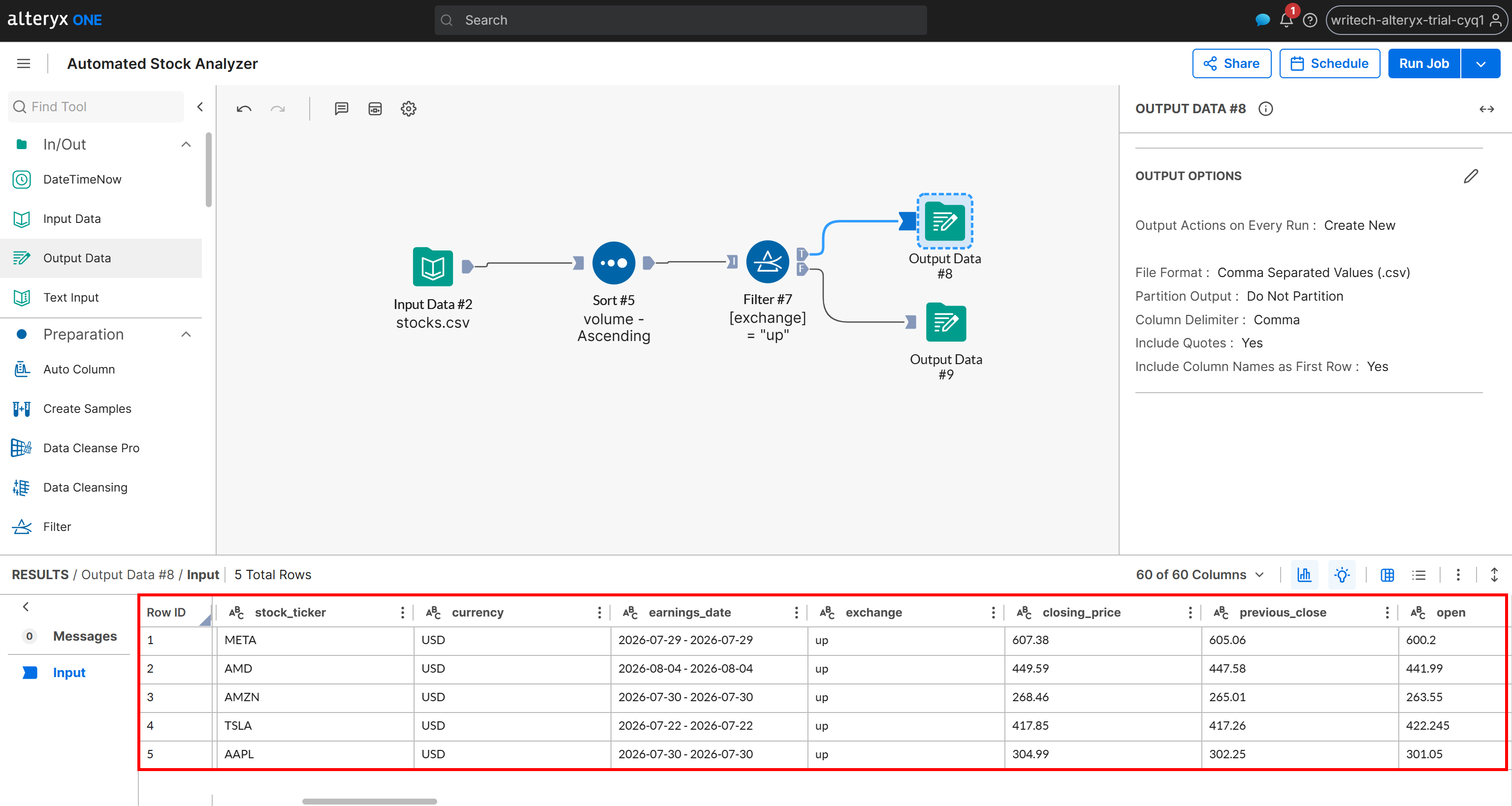
Observa que esta salida contiene únicamente las acciones cuyo estado de cambio es “up”, ordenadas por volumen en orden ascendente. Los mismos datos también están disponibles en el archivo up_stocks.csv generado por el pipeline y almacenado en tu bucket de Amazon S3.
A continuación, inspecciona la salida generada para el escenario F:
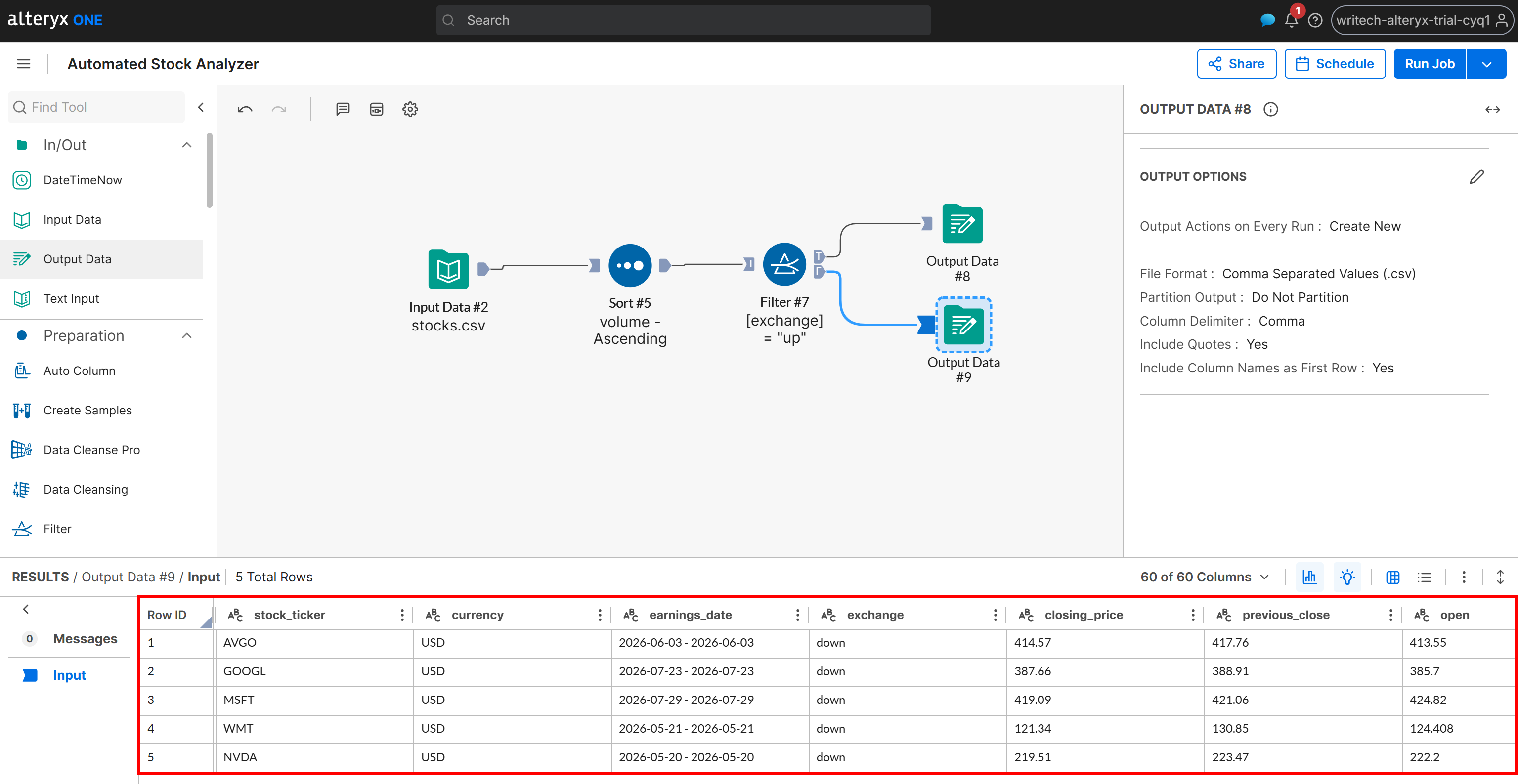
Esta salida contiene únicamente las acciones cuyo estado de cambio es “down”, también ordenadas por volumen en orden ascendente. Los mismos resultados se escriben en el archivo down_stocks.csv en tu bucket de Amazon S3.
¡Et voilà! Acabas de construir un pipeline de análisis de datos web en Alteryx One impulsado por Bright Data. Ten en cuenta que esto fue solo un ejemplo, y son posibles muchos otros escenarios de automatización de datos web.
Próximos pasos
Ten en cuenta que este fue solo un pipeline de análisis de datos sencillo con algunos pasos de ejemplo. En la práctica, puedes hacerlo mucho más complejo añadiendo nodos de procesamiento adicionales (incluidos nodos de IA) e incluso incorporando múltiples fuentes de datos.
Por ejemplo, puedes configurar otras Web Scraping APIs de Bright Data para que escriban en el mismo bucket de Amazon S3. Los datasets resultantes pueden combinarse para enriquecimiento y análisis más avanzados mediante operaciones de join.
Además, para construir un pipeline de datos completamente automatizado y siempre actualizado:
- Activa las Web Scraping APIs de Bright Data para actualizar los datos de origen en Amazon S3.
- En Bright Data, configura un webhook que llame a la API de ejecución de flujos de trabajo de Alteryx One.
Conclusión
En este tutorial, aprendiste qué aporta Alteryx One al análisis de datos automatizado. En concreto, viste cómo los datos recuperados a través de las Web Scraping APIs de Bright Data pueden integrarse en Alteryx One a través de Amazon S3. Los datos web de alta calidad mejoran considerablemente la precisión y el valor de los insights, lo que conduce a mejores resultados de análisis.
¡Crea hoy una cuenta gratuita de Bright Data y comienza a explorar nuestras soluciones de datos web listas para empresas!





