

En este blog se analizará en detalle la concurrencia y el paralelismo para ayudarle a elegir el mejor concepto para su aplicación.
¿Qué es la concurrencia?
En términos sencillos, la concurrencia es un concepto utilizado en el desarrollo de software para manejar múltiples tareas simultáneamente. Sin embargo, en teoría, no ejecuta todas las tareas al mismo tiempo. En cambio, permite que el sistema o la aplicación gestione múltiples tareas simultáneamente cambiando rápidamente entre ellas, creando una ilusión de procesamiento paralelo. Este proceso también se conoce como intercalación de tareas.
Por ejemplo, considere un servidor web que necesita gestionar múltiples solicitudes de usuarios.
- El usuario 1 envía una solicitud al servidor para recuperar datos.
- El usuario 2 envía una solicitud al servidor para cargar un archivo.
- El usuario 3 envía una solicitud al servidor para recuperar imágenes.
Sin concurrencia, cada usuario debe esperar hasta que se cumpla la solicitud anterior.
- Paso 1: La CPU comienza a procesar la solicitud de recuperación de datos en el subproceso 1.
- Paso 2: Mientras el subproceso 1 espera el resultado, la CPU inicia el proceso de carga del archivo en el subproceso 2.
- Paso 3: Mientras el subproceso 2 espera a que se cargue el archivo, la CPU inicia la recuperación de imágenes en el subproceso 3.
- Paso 4: A continuación, la CPU cambia entre estos tres subprocesos en función de la disponibilidad de recursos para completar las tres tareas simultáneamente.
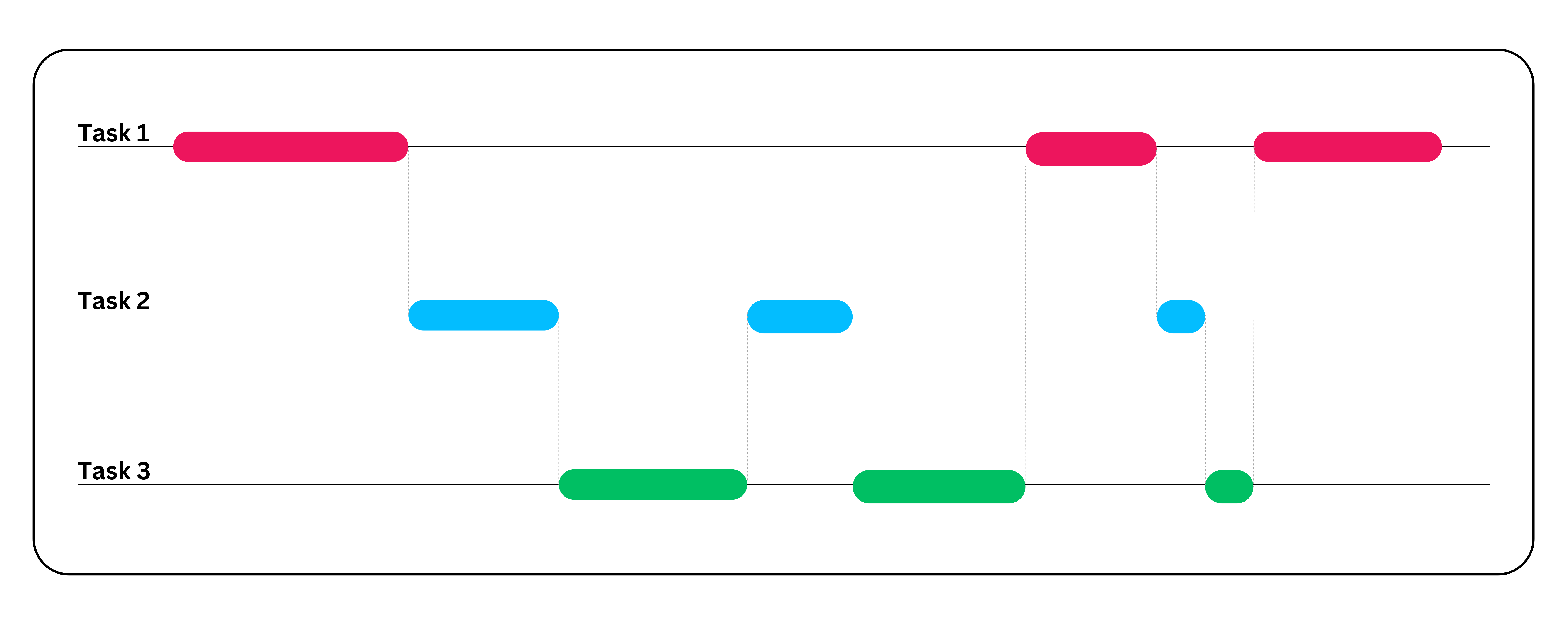
En comparación con el enfoque de ejecución sincrónica, el enfoque de concurrencia es mucho más rápido y extremadamente útil para entornos de un solo núcleo, ya que mejora el tiempo de respuesta general del sistema, la utilización de los recursos y la capacidad de rendimiento del sistema. Sin embargo, la concurrencia no se limita a un solo núcleo, sino que también se puede implementar en entornos multinúcleo.
Casos de uso de la concurrencia
- Interfaces de usuario receptivas.
- Servidores web.
- Sistemas en tiempo real.
- Operaciones de red y E/S.
- Procesamiento en segundo plano.
Diferentes modelos de concurrencia
Con la creciente complejidad y las exigencias de las aplicaciones modernas, los desarrolladores han introducido nuevos modelos de concurrencia para abordar las deficiencias del enfoque tradicional. A continuación se presentan algunos modelos de concurrencia clave y sus usos:
1. Multitarea cooperativa
En este modelo, las tareas ceden voluntariamente el control al programador en los momentos oportunos, lo que le permite procesar otras tareas. Esta cesión suele producirse cuando la tarea está inactiva o esperando operaciones de E/S. Se trata de uno de los modelos más fáciles de implementar, ya que el cambio de contexto se gestiona dentro del código de la aplicación.
Ejemplos:
- Sistemas integrados ligeros
- Versiones antiguas de Microsoft Windows (Windows 3.x)
- Mac OS clásico
Aplicaciones del mundo real:
- Aplicaciones que utilizan corrutinas como Python asyncio y Kotlin coroutines.
2. Multitarea preventiva
El sistema operativo o el programador de tiempo de ejecución obliga a las tareas a detenerse y asigna tiempo de CPU a otras tareas basándose en un algoritmo de programación. Este modelo garantiza que todas las tareas obtengan una parte igual del tiempo de CPU. Sin embargo, requiere un cambio de contexto más complejo.
Ejemplos:
- Hilos Java gestionados por la JVM.
- Módulo de subprocesos de Python.
Aplicaciones en el mundo real:
- Sistemas operativos modernos (Windows, macOS, Linux)
- Servidores web.
3. Concurrencia basada en eventos
En este modelo, las tareas se dividen en pequeñas operaciones sin bloqueo y se ponen en cola. A continuación, se obtienen los trabajos de la cola, se realiza la acción requerida y se pasa al siguiente, manteniendo el sistema interactivo.
Ejemplos:
- Node.js (tiempo de ejecución de JavaScript).
- Patrón async/await de JavaScript.
- Biblioteca asyncio de Python.
Aplicaciones en el mundo real:
- Servidores web como Node.js.
- Aplicaciones de chat en tiempo real.
4. Modelo de actores
Utiliza actores para enviar y recibir mensajes de forma asíncrona. Cada actor procesa un mensaje a la vez, lo que evita el estado compartido y reduce la necesidad de bloqueos.
Ejemplos:
- Marco Akka (Java/Scala).
- Lenguaje de programaciónErlang.
- Microsoft Orleans (aplicaciones .NET distribuidas).
Aplicaciones en el mundo real:
- Sistemas distribuidos.
- Sistemas de telecomunicaciones.
- Sistemas de procesamiento de datos en tiempo real.
5. Programación reactiva
Este modelo permite crear flujos de datos (observables) y definir cómo deben procesarse (operadores) y cómo deben reaccionar (observadores). Se producen cambios en los datos o eventos, que se propagan automáticamente a través de los flujos a todos los observadores suscritos. Este enfoque facilita la gestión de datos y eventos asíncronos, proporcionando una forma limpia y declarativa de manejar flujos de datos complejos.
Ejemplos:
Aplicaciones en el mundo real:
- Canales de procesamiento de datos en tiempo real.
- Interfaces de usuario interactivas.
- Aplicaciones que requieren un manejo de datos dinámico y receptivo.
¿Qué es el paralelismo?
El paralelismo es otro concepto popular utilizado en el desarrollo de software para manejar múltiples tareas simultáneamente. A diferencia de la concurrencia, que crea la ilusión de un procesamiento paralelo al cambiar rápidamente entre tareas, el paralelismo realmente ejecuta múltiples tareas simultáneamente utilizando múltiples núcleos de CPU o procesadores. Implica dividir tareas más grandes en subtareas más pequeñas e independientes que se pueden ejecutar en paralelo. Este proceso se conoce como descomposición de tareas.
Por ejemplo, consideremos una aplicación de procesamiento de datos que genera informes después de realizar análisis y ejecutar simulaciones. Sin paralelismo, esto se ejecutaría como una gran tarea, lo que llevaría mucho tiempo completar. Pero, si se opta por el paralelismo, la tarea se completará mucho más rápido gracias a la descomposición de tareas.
Así es como funciona el paralelismo:
- Paso 1: Divida la tarea principal en subtareas independientes. Estas subtareas deben poder ejecutarse sin esperar las entradas de otras tareas. Sin embargo, si hay alguna dependencia, debe programarlas adecuadamente para garantizar que se ejecuten en el orden correcto. En este ejemplo, supondré que no hay dependencias entre las subtareas.
- Subtarea 1: Realizar el análisis de datos.
- Subtarea 2: Generar informes.
- Subtarea 3: Ejecutar simulaciones.
- Paso 2: Asignar 3 subtareas a 3 núcleos.
- Paso 3: Por último, combinar los resultados de cada subtarea para obtener el resultado final de la tarea original.
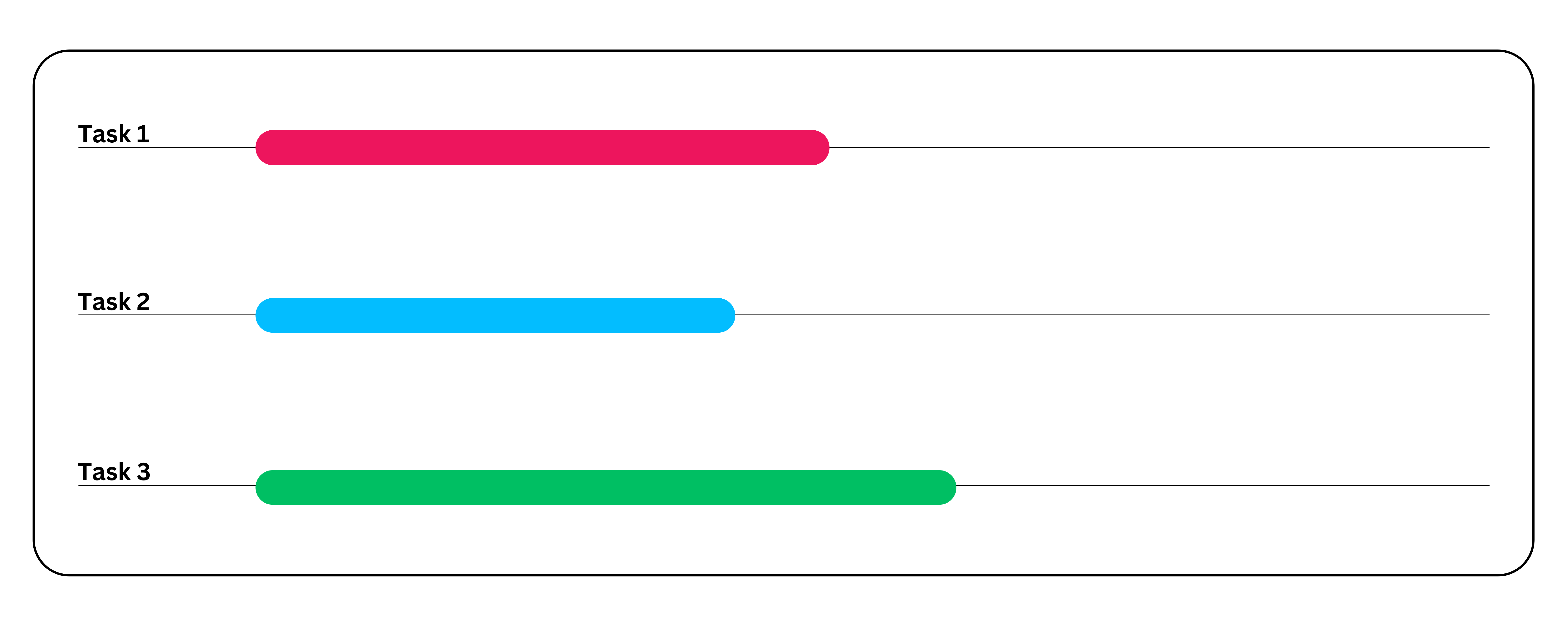
Casos de uso del paralelismo
- Cálculos y simulaciones científicas.
- Procesamiento de datos.
- Procesamiento de imágenes.
- Aprendizaje automático.
- Análisis de riesgos.
Diferentes modelos de paralelismo
Al igual que la concurrencia, el paralelismo también tiene varios modelos diferentes para utilizar de manera eficiente los procesadores multinúcleo y los recursos informáticos distribuidos. A continuación se presentan algunos modelos clave de paralelismo y sus usos:
1. Paralelismo de datos
Este modelo distribuye los datos entre varios procesadores y realiza la misma operación en cada subconjunto de datos simultáneamente. Es especialmente eficaz para tareas que se pueden dividir fácilmente en subtareas independientes.
Ejemplos:
- OperacionesSIMD (instrucción única, datos múltiples).
- Procesamiento paralelo de matrices.
- Marco MapReduce.
Aplicaciones en el mundo real:
- Procesamiento de imágenes y señales
- Análisis de datos a gran escala
- Simulaciones científicas
2. Paralelismo de tareas
El paralelismo de tareas consiste en dividir la tarea global en tareas más pequeñas e independientes que pueden ejecutarse simultáneamente en diferentes procesadores. Cada tarea realiza una operación diferente.
Ejemplos:
- Paralelismo basado en subprocesos en Java.
- Tareas paralelas en .NET.
- Hilos POSIX.
Aplicaciones en el mundo real:
- Servidores web que gestionan múltiples solicitudes de clientes.
- Implementaciones de algoritmos paralelos.
- Sistemas de procesamiento en tiempo real.
3. Paralelismo en pipeline
En el paralelismo en pipeline, las tareas se dividen en etapas y cada etapa se procesa en paralelo. Los datos fluyen a través del pipeline, y cada etapa opera de forma concurrente.
Ejemplos:
- Comandos de canalización de Unix.
- Tuberías de procesamiento de imágenes.
- Tuberías de procesamiento de datos en herramientas ETL (Extraer, Transformar, Cargar).
Aplicaciones en el mundo real:
- Procesamiento de vídeo y audio.
- Aplicaciones de transmisión de datos en tiempo real.
- Automatización de la fabricación y las líneas de montaje.
4. Modelo Fork/Join
Este modelo consiste en dividir una tarea en subtareas más pequeñas (bifurcación), ejecutarlas en paralelo y luego combinar los resultados (unión). Es útil para algoritmos de divide y vencerás.
Ejemplos:
- Marco Fork/Join en Java.
- Algoritmos recursivos paralelos (por ejemplo, mergesort paralelo).
- Intel Threading Building Blocks (TBB).
Aplicaciones en el mundo real:
- Tareas computacionales complejas, como ordenar grandes conjuntos de datos.
- Algoritmos recursivos.
- Cálculos científicos a gran escala.
5. Paralelismo de GPU
El paralelismo de GPU aprovecha las capacidades de procesamiento masivamente paralelo de las unidades de procesamiento gráfico (GPU) para ejecutar miles de subprocesos simultáneamente, lo que lo hace ideal para tareas altamente paralelas.
Ejemplos:
- CUDA (Compute Unified Device Architecture) de NVIDIA.
- OpenCL (lenguaje de computación abierto).
- TensorFlow para aprendizaje profundo.
Aplicaciones en el mundo real:
- Aprendizaje automático y aprendizaje profundo.
- Renderización de gráficos en tiempo real.
- Computación científica de alto rendimiento.
Concurrencia frente a paralelismo
Ahora que ya comprende bien cómo funcionan la concurrencia y el paralelismo, comparémoslos en varios aspectos para ver cómo podemos sacar el máximo partido de ambos.
1. Utilización de recursos
- Concurrencia: ejecuta múltiples tareas dentro de un solo núcleo, compartiendo recursos entre tareas. Por ejemplo, la CPU cambia entre tareas durante los periodos de inactividad o espera.
- Paralelismo: utiliza varios núcleos o procesadores para ejecutar tareas simultáneamente.
2. Enfoque
- Concurrencia: se centra en gestionar varias tareas al mismo tiempo.
- Paralelismo: se centra en ejecutar varias tareas al mismo tiempo.
3. Ejecución de tareas
- Concurrencia: tareas ejecutadas de forma intercalada. El rápido cambio de contexto de la CPU crea una ilusión de ejecución paralela.
- Paralelismo: las tareas se ejecutan de forma verdaderamente paralela en diferentes procesadores o núcleos.
4. Cambio de contexto
- Concurrencia: se producen cambios de contexto frecuentes cuando la CPU cambia entre tareas para dar la apariencia de ejecución simultánea. A veces, esto puede afectar negativamente al rendimiento si las tareas quedan inactivas con frecuencia.
- Paralelismo: el cambio de contexto es mínimo o nulo, ya que las tareas se ejecutan en núcleos o procesadores separados.
5. Casos de uso
- Concurrencia: tareas vinculadas a E/S, como E/S de disco, comunicación de red o entrada del usuario.
- Paralelismo: tareas vinculadas a la CPU que requieren un procesamiento intensivo, como cálculos matemáticos, análisis de datos y procesamiento de imágenes.

¿Podemos utilizar la concurrencia y el paralelismo juntos?
Basándonos en la comparación anterior, podemos observar que la concurrencia y el paralelismo se complementan entre sí en muchas situaciones. Pero antes de entrar en ejemplos del mundo real, veamos cómo funciona esta combinación en un entorno multinúcleo. Para ello, consideremos un servidor web que realiza tareas de lectura, escritura y análisis de datos.
Paso 1: Identificar las tareas
En primer lugar, es necesario identificar las tareas vinculadas a la E/S y las tareas vinculadas a la CPU en la aplicación. En este caso:
- Limitadas por la E/S: lectura y escritura de datos.
- Relacionadas con la CPU: análisis de datos.
Paso 2: Ejecución concurrente
Las tareas de lectura y escritura de datos se pueden ejecutar en subprocesos separados dentro de un único núcleo, ya que son tareas vinculadas a la E/S. El servidor utiliza un bucle de eventos para gestionar estas tareas y cambia rápidamente entre subprocesos, intercalando la ejecución de la tarea. Puede utilizar una biblioteca de programación asíncrona como Python asyncio para implementar este comportamiento concurrente.
Paso 3: Ejecución paralela
Se pueden asignar varios núcleos a tareas limitadas por la CPU para gestionarlas en paralelo. En este caso, el análisis de datos se puede dividir en varias subtareas y cada subtarea se ejecutará en un núcleo independiente. Puede utilizar un marco de ejecución paralela como Python concurrent.futures para implementar este comportamiento.
Paso 4: Sincronización y coordinación
A veces, los subprocesos que se ejecutan en diferentes núcleos pueden depender unos de otros. En tales situaciones, se necesitan mecanismos de sincronización como bloqueos y semáforos para garantizar la integridad de los datos y evitar condiciones de carrera.
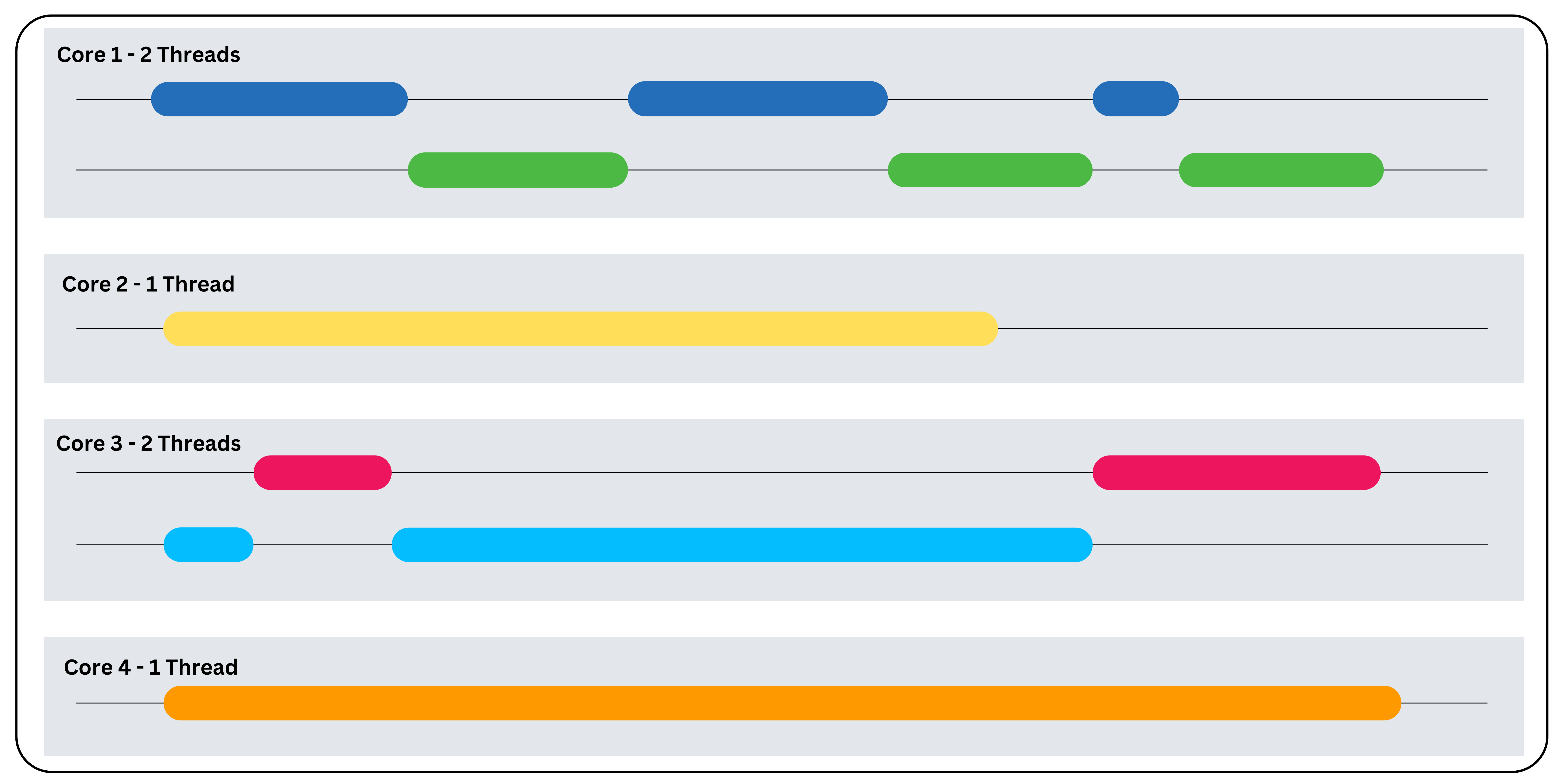
El siguiente fragmento de código muestra cómo utilizar la concurrencia y el paralelismo en la misma aplicación utilizando Python:
import asyncio
from concurrent.futures import ProcessPoolExecutor
import os
# Simular una tarea vinculada a E/S (lectura de datos)
async def read_data():
await asyncio.sleep(1) # Simular retraso de E/S
data = [1, 2, 3, 4, 5] # Datos ficticios
print("Lectura de datos completada")
return data
# Simular tarea vinculada a E/S (escritura de datos)
async def write_data(data):
await asyncio.sleep(1) # Simular retraso de E/S
print(f"Escritura de datos completada: {data}")
# Simular tarea vinculada a la CPU (análisis de datos)
def analyze_data(data):
print(f"Análisis de datos iniciado en la CPU: {os.getpid()}")
result = [x ** 2 for x in data] # Simular cálculo
print(f"Análisis de datos completado en la CPU: {os.getpid()}")
return result
async def handle_request():
# Concurrencia: leer datos de forma asíncrona
data = await read_data()
# Paralelismo: analizar datos en paralelo
loop = asyncio.get_event_loop()
with ProcessPoolExecutor() as executor:
analyzed_data = await loop.run_in_executor(executor, analyze_data, data)
# Concurrencia: escribir datos de forma asíncrona
await write_data(analyzed_data)
async def main():
# Simular el manejo de múltiples solicitudes
await asyncio.gather(handle_request(), handle_request())
# Ejecutar el servidor
asyncio.run(main())
Ejemplos reales de combinación de concurrencia y paralelismo
Ahora, veamos algunos casos de uso comunes en los que podemos combinar la concurrencia y el paralelismo para lograr un rendimiento óptimo.
1. Procesamiento de datos financieros
Las principales tareas de un sistema de procesamiento de datos financieros incluyen la recopilación, el procesamiento y el análisis de datos, al tiempo que se atienden las operaciones diarias.
- La concurrencia se utiliza para obtener datos financieros de diversos recursos, como el mercado de valores, mediante operaciones de E/S asíncronas.
- Análisis de los datos recopilados para generar informes. Se trata de una tarea que requiere un uso intensivo de la CPU, por lo que se utiliza el paralelismo para ejecutarla en paralelo sin afectar a las operaciones diarias.
2. Procesamiento de vídeo
Las principales tareas de un sistema de procesamiento de vídeo incluyen la carga, la codificación/decodificación y el análisis de archivos de vídeo.
- La concurrencia se puede utilizar para gestionar múltiples solicitudes de carga de vídeo mediante operaciones de E/S asíncronas. Esto permite a los usuarios cargar vídeos sin tener que esperar a que se completen otras cargas.
- El paralelismo se utiliza para tareas que requieren un uso intensivo de la CPU, como la codificación, descodificación y análisis de archivos de vídeo.
3. Extracción de datos
Las principales tareas de un servicio de extracción de datos incluyen la obtención de datos de varios sitios web y el parseo de los datos recopilados para obtener información.
- La obtención de datos se puede gestionar mediante la concurrencia. Esto garantiza que la recopilación de datos sea eficiente y no se bloquee mientras se esperan las respuestas.
- El paralelismo se utiliza para procesar los datos recopilados en varios núcleos de CPU. Mejora el proceso de toma de decisiones de la organización al proporcionar informes en tiempo real.
Conclusión
La concurrencia y el paralelismo son dos conceptos clave que se utilizan en el desarrollo de software para mejorar el rendimiento de las aplicaciones. La concurrencia permite que se ejecuten varias tareas simultáneamente, mientras que el paralelismo acelera el procesamiento de datos mediante el uso de varios núcleos de CPU. Aunque tienen funcionalidades distintas, su integración puede mejorar significativamente el rendimiento de las aplicaciones con tareas vinculadas tanto a la E/S como a la CPU.
Las herramientas de Bright Data, como las API de Web Scraper, las funciones de Web Scraper y el Navegador de scraping, están diseñadas para aprovechar al máximo estas técnicas y ayudarle con los retos habituales del Scraping web. Utilizan operaciones asíncronas para recopilar datos de múltiples fuentes simultáneamente y el procesamiento paralelo para analizar y organizar los datos rápidamente. Por lo tanto, elegir un proveedor de datos como Bright Data, que ya ha integrado la concurrencia y el paralelismo en su núcleo, puede ahorrarle tiempo y esfuerzo, ya que no tendrá que implementar estos conceptos desde cero mientras realiza el Scraping web.
¡Comience hoy mismo su prueba gratuita!





