

El rastreo web distribuido es una estrategia para escalar los rastreadores web a través de múltiples máquinas, superando así las limitaciones de los rastreadores de un solo nodo. En este artículo, exploraremos:
- Rastreo web distribuido frente a rastreo web en un único nodo
- La arquitectura central del rastreo web distribuido
- Ejemplos reales de rastreo web distribuido
- Estrategias de aplicación y mejores prácticas
- Errores comunes y cómo solucionarlos
TL;DR: El rastreo web distribuido utiliza un clúster de máquinas para rastrear sitios web en paralelo, lo que resuelve los problemas de escalabilidad y velocidad que los rastreadores de un solo nodo no pueden resolver. Proporciona un mayor rendimiento y fiabilidad (sin un único cuello de botella) a costa de una mayor complejidad arquitectónica y sobrecarga.
Rastreo distribuido frente a nodo único
La mayoría de los proyectos de rastreo no necesitan sistemas distribuidos y, sin embargo, los equipos pierden habitualmente meses construyendo complejas arquitecturas distribuidas cuando bastaría con un único servidor.
En un rastreador de un solo nodo, una máquina se encarga de todas las operaciones de búsqueda, análisis y almacenamiento. Este tipo de sistema es más fácil de desarrollar y mantener, y ahorra dinero. Es ideal para obtener entre 60 y 500 páginas por minuto, pero a medida que aumentan sus necesidades de rastreo, un único nodo se convierte en un cuello de botella, ya que se verá limitado por las restricciones de CPU, memoria y red.
En cambio, los rastreadores distribuidos reparten el trabajo entre varios nodos, lo que permite realizar búsquedas simultáneas a gran escala, a gran velocidad y con mayor tolerancia a fallos. Si un trabajador falla, los demás siguen funcionando, lo que aumenta la fiabilidad. La contrapartida es que los sistemas distribuidos requieren colas de mensajes, sincronización de una frontera URL y un diseño cuidadoso para evitar la duplicación o la saturación de los sitios de destino.
Comparación exhaustiva
| Aspecto | Nodo único | Distribuido |
|---|---|---|
| Rendimiento | 4 segundos/página de media, 60-120 páginas/minuto | 30 veces más rápido, más de 50.000 solicitudes/segundo |
| Escalabilidad | Limitado por los recursos de una sola máquina | Escalado lineal entre nodos |
| Tolerancia a fallos | Punto único de fallo | Conmutación automática por error, autorreparación |
| Distribución geográfica | Ubicación fija | Despliegue multirregional |
| Utilización de los recursos | Sólo escala vertical | Escala horizontal optimizada |
| Complejidad | Configuración sencilla, gastos generales mínimos | Orquestación compleja, mayor coste operativo |
| Coste | Menor inversión inicial | Mayores costes de infraestructura, mejor ROI a escala |
| Mantenimiento | Carga operativa mínima | Requiere experiencia en sistemas distribuidos |
| Tratamiento de datos | Sólo tratamiento local | Procesamiento paralelo entre nodos |
| Antidetección | Rotación IP limitada | Gestión avanzada de proxy, huellas dactilares |
¿Debería optar por la distribución? (Árbol de decisiones)
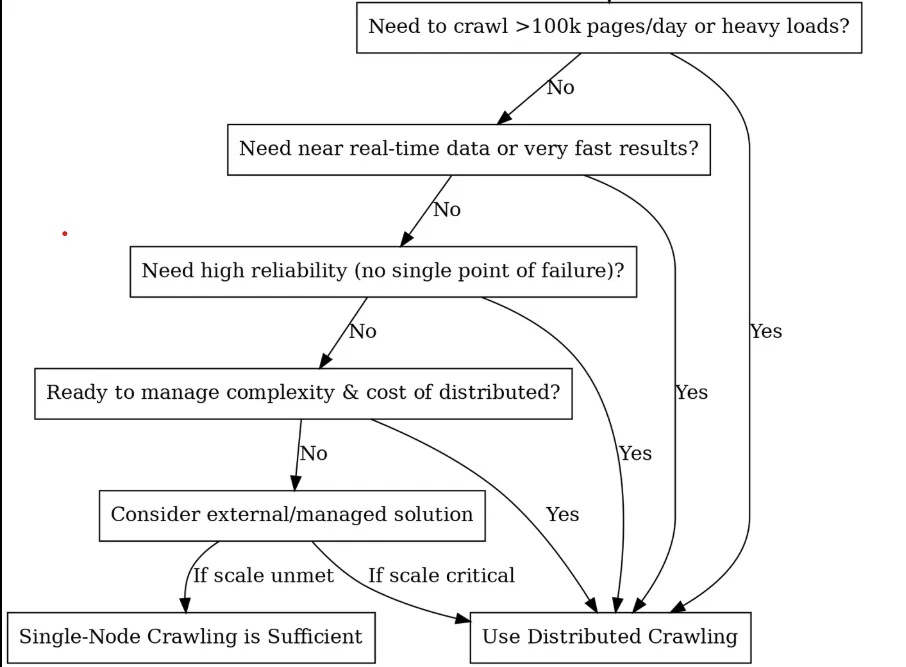
Componentes básicos y arquitectura
Una vez que te hayas decidido por el crawling distribuido, el siguiente paso es desglosar lo que vas a construir. Piense que es como formar un equipo de carreras de alto rendimiento en el que cada componente tiene una función específica y todos deben trabajar juntos a la perfección. Estos son los componentes clave necesarios para construir un sistema de rastreo distribuido:
Programador / Cola (El cerebro)
En el corazón de un rastreador distribuido hay un planificador o cola de tareas que coordina el trabajo entre los nodos, y es donde sus URLs viven antes de ser rastreadas. Un componente planificador también puede gestionar la cortesía (tiempo) y los reintentos. Por ejemplo, puede implementar colas específicas de dominio para asegurarse de que un sitio no es alcanzado por todos los trabajadores a la vez.
Con los programadores, tienes tres opciones principales, cada una con su propia personalidad:
- Kafka: Es como el campeón de los pesos pesados. Está diseñado para un rendimiento masivo y no le cuesta nada gestionar millones de mensajes por segundo. La belleza reside en su diseño basado en registros, que es perfecto para gestionar la frontera de URL. Puedes hacer particiones por dominio para mantener tu rastreo educado.
- RabbitMQ: Es como una navaja suiza. Enrutamiento más flexible que Kafka, con características como colas prioritarias. RabbitMQ tiene almacenamiento en memoria, por lo que es más rápido para cargas de trabajo pequeñas. Es ideal cuando se necesitan diferentes estrategias de rastreo para distintos tipos de contenido.
- Celery: El mejor amigo del desarrollador de Python. Esta opción no es tan eficiente como las otras, pero es fácil de usar. Celery es perfecto para crear prototipos o rastrear a mediana escala cuando necesitas que algo funcione rápidamente.
Frontera URL y deduplicación: La memoria del rastreador
¿Alguna vez ha rastreado accidentalmente la misma página 1.000 veces? Ahí es donde la deduplicación te salva. Necesitas rastrear lo que has visto respetando la cortesía del servidor, para no machacar repetidamente el mismo dominio.
Los conjuntos Redis pueden ofrecerte una precisión perfecta, pero consumen mucha memoria. Los Filtros Bloom utilizan un 90% menos de memoria (1.2GB vs 12GB+ para un billón de URLs) pero ocasionalmente tienen falsos positivos (pueden decir que no has visto una URL cuando sí lo has hecho), así que puede que quieras ir con esta implementación de Redis:
class DistributedURLFrontier:
def __init__(self, redis_client):
self.redis = redis_client
def add_url(self, url, priority=0):
domain = urlparse(url).netloc
# Skip if already seen
if self.redis.sismember("seen_urls", url):
return
# Mark as seen and queue by domain
self.redis.sadd("seen_urls", url)
self.redis.lpush(f"queue:{domain}", url)
self.redis.zadd("priority_queue", {url: priority})
def get_next_url(self):
# Get highest priority URL
result = self.redis.zrevrange("priority_queue", 0, 0)
if not result:
return None
url = result[0]
domain = urlparse(url).netloc
# Respect crawl delay (1 second between requests per domain)
last_crawl = self.redis.get(f"last_crawl:{domain}")
if last_crawl and time.time() - float(last_crawl) < 1.0:
return None
# Remove from queues and update last crawl time
self.redis.zrem("priority_queue", url)
self.redis.rpop(f"queue:{domain}")
self.redis.set(f"last_crawl:{domain}", time.time())
return url
Nodos trabajadores (el músculo)
Los nodos de trabajo son los caballos de batalla del rastreo. Son los procesos o máquinas que realmente realizan el trabajo de rastreo, como la obtención de URL y el procesamiento del contenido. Cada trabajador ejecuta la misma lógica de rastreo (por ejemplo, el mismo script Python o aplicación), pero operan en paralelo en diferentes URLs de la cola.
Para sacar el máximo partido a tus trabajadores, debes mantenerlos sin estado, de modo que cualquier estado (URLs visitadas, resultados, etc.) se almacene en un espacio compartido o se transmita a través de mensajes. De este modo, cualquier trabajador puede realizar cualquier tarea y, cuando uno muere, los demás se hacen cargo al instante sin perder el ritmo.
class DistributedWorker:
def __init__(self, worker_id, max_concurrent=50):
self.worker_id = worker_id
self.semaphore = asyncio.Semaphore(max_concurrent)
self.session = aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=30),
connector=aiohttp.TCPConnector(limit=100)
)
async def crawl_batch(self, urls):
tasks = [self.crawl_url(url) for url in urls]
return await asyncio.gather(*tasks, return_exceptions=True)
async def crawl_url(self, url):
async with self.semaphore:
try:
async with self.session.get(url) as response:
content = await response.text()
return {'url': url, 'content': content, 'status': response.status}
except Exception as e:
return {'url': url, 'error': str(e)}
Pro tip: Con los workers, es importante no usar un mazo para todo. Deberías usar trabajadores HTTP ligeros para HTML estático y trabajadores Puppeteer pesados para páginas renderizadas en JavaScript. Diferentes herramientas, diferentes grupos de trabajadores. Puede elegir fácilmente los tipos de proxy adecuados para su flota de trabajadores con nuestra completa guía de selección de proxy.
Capa de almacenamiento (el almacén)
La capa de almacenamiento es donde se guardan los datos y metadatos rastreados, y suele constar de dos partes:
- El almacenamiento de contenidos gestiona la mayor parte de HTML sin procesar, respuestas JSON, imágenes y PDF. Piense en ello como su almacén digital. Los almacenes de objetos como S3, Google Cloud Storage o HDFS sobresalen aquí porque escalan infinitamente y manejan escrituras concurrentes de múltiples trabajadores sin sudar.
- El almacenamiento de metadatos contiene el oro estructurado que ha extraído: campos analizados, relaciones entre entidades, marcas de tiempo de rastreo y estado de éxito/fracaso. Estos datos se almacenan en bases de datos optimizadas para consultas y actualizaciones, no solo para el volumen de almacenamiento.
Los rastreadores distribuidos necesitan un almacenamiento que gestione escrituras concurrentes masivas sin ahogarse. Los almacenes de objetos como S3 o Google Cloud Storage son excelentes para el contenido en bruto porque escalan infinitamente, mientras que las bases de datos NoSQL (MongoDB, Cassandra) o SQL gestionan metadatos estructurados con eficacia.
Supervisión y alerta
El funcionamiento de un rastreador distribuido requiere visibilidad del rendimiento del sistema. Puede utilizar Prometheus y Grafana para crear paneles de control exhaustivos que controlen las tasas de rastreo, las tasas de éxito, los tiempos de respuesta y la profundidad de las colas. Entre las métricas clave se incluyen las solicitudes por segundo por dominio, los tiempos de respuesta del percentil 95 y las tendencias del tamaño de las colas.
Capa antibot y de evasión
El rastreo web a gran escala implica jugar constantemente al gato y al ratón con los sistemas anti-bot. Se necesitan tres capas de defensa: rotación de IP entre miles de proxies residenciales y de centros de datos, aleatorización de huellas dactilares de agentes de usuario y firmas de navegadores, e imitación de comportamientos para evitar patrones de detección.
Bright Data Web Unlocker ofrece funciones antidetección de nivel empresarial con una tasa de éxito superior al 99%, gracias a la resolución automática de CAPTCHA, la rotación de IP y la toma de huellas dactilares del navegador. Su enfoque basado en API simplifica la integración a la vez que gestiona complejos retos anti-bot.
class BrightDataWebUnlocker:
def crawl_url(self, url: str, options: Dict = None) -> Dict:
payload = {
"url": url,
"zone": self.zone,
"format": "raw",
"country": "US",
"render_js": True,
"wait_for_selector": ".content"
}
response = requests.post(
self.base_url,
headers={"Authorization": f"Bearer {self.api_key}"},
json=payload,
timeout=60
)
La rotación avanzada de proxy implementa la comprobación del estado, la optimización geográfica y la recuperación de fallos en grupos de proxy residenciales, de centros de datos y móviles. Una gestión de proxy satisfactoria requiere más de 1000 IP con algoritmos de rotación inteligentes.
La evasión de huellas dactilares aleatoriza los agentes de usuario, las huellas dactilares del navegador y las características de la red para evitar su detección por parte de sofisticados sistemas anti-bot. Esto incluye la rotación de huellas TLS, la suplantación de huellas canvas y la simulación de patrones de comportamiento.
Casos prácticos reales con ejemplos de código
Vamos a explorar dos casos de uso común para rastreadores distribuidos, y esbozar cómo uno podría implementarlos con fragmentos de código. Utilizaremos Python y Celery en los ejemplos para simplificar, pero los principios se aplican en general.
Caso práctico 1: Control de precios en el comercio electrónico
Imagina que estás rastreando los precios de la competencia en 50.000 páginas de productos cada día. Si intenta utilizar una sola máquina para acceder a todas esas URL, tendrá que rastrearlas durante más de 12 horas, suponiendo que nada se rompa. Además, la mayoría de los sitios de comercio electrónico empezarán a bloquearte después de unos cuantos miles de peticiones rápidas desde la misma IP.
Aquí es donde ayuda el rastreo distribuido. En lugar de una máquina abrumada, distribuyes esas 50.000 URL entre docenas de trabajadores, cada uno de ellos con direcciones IP diferentes. Lo que antes tardaba medio día, ahora termina en 2-3 horas, y pasas desapercibido para los sistemas anti-bot.
La configuración es sencilla. Es necesario mantener las listas de URL de los competidores (a partir de sitemaps o rastreos de descubrimiento) y utilizar algo como Celery con Redis para distribuir el trabajo. Cada mañana, se ponen en cola las 50.000 URL y el ejército de trabajadores se pone manos a la obra. El trabajador 1 se encarga de las zapatillas Nike, el trabajador 2 de las zapatillas Adidas y el trabajador 3 de los precios de Puma. Todo simultáneamente, todo desde diferentes IP.
from celery import Celery
import requests
from bs4 import BeautifulSoup
import random
import time
import re
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# Initialize Celery app with Redis as broker
app = Celery('price_monitor', broker='redis://localhost:6379/0')
# Realistic user agents for rotation
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"
]
# Proxy pool (replace with your actual proxy service)
PROXY_POOL = [
"<http://proxy1:8080>",
"<http://proxy2:8080>",
"<http://proxy3:8080>",
# Add your proxy endpoints here
]
def get_session_with_retries():
"""Create a session with retry strategy and random proxy."""
session = requests.Session()
# Retry strategy for resilience
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
# Random proxy rotation
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
@app.task(bind=True, max_retries=3)
def fetch_product_price(self, url, site_config=None):
"""Fetches product price with full anti-detection measures."""
# Human-like delay before starting
time.sleep(random.uniform(2, 8))
# Randomized headers to avoid fingerprinting
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Cache-Control": "max-age=0"
}
try:
session = get_session_with_retries()
resp = session.get(url, headers=headers, timeout=30)
resp.raise_for_status()
# Parse the page for price
soup = BeautifulSoup(resp.text, 'html.parser')
price_value = extract_price(soup, url, site_config)
if price_value:
# Store in database (implement your storage logic here)
store_price_data(url, price_value, resp.status_code)
return {"url": url, "price": price_value, "status": "success"}
else:
return {"url": url, "error": "Price not found", "status": "failed"}
except requests.exceptions.RequestException as e:
print(f"Request failed for {url}: {e}")
# Retry with exponential backoff
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"url": url, "error": str(e), "status": "failed"}
def extract_price(soup, url, site_config=None):
"""Extract price using multiple strategies."""
# Site-specific selectors (customize for each competitor)
price_selectors = [
".price", ".product-price", ".current-price", ".sale-price",
"[data-price]", ".price-current", ".price-now", ".offer-price"
]
# Try configured selectors first
if site_config and site_config.get('price_selector'):
price_selectors.insert(0, site_config['price_selector'])
price_text = None
for selector in price_selectors:
price_elem = soup.select_one(selector)
if price_elem:
price_text = price_elem.get_text(strip=True)
break
# Try data attributes as fallback
if not price_text:
price_elem = soup.find(attrs={"data-price": True})
if price_elem:
price_text = price_elem.get("data-price")
if not price_text:
return None
# Clean and parse price
return parse_price(price_text)
def parse_price(price_text):
"""Parse price from various formats."""
# Remove common currency symbols and whitespace
cleaned = re.sub(r'[^\d.,]', '', price_text)
# Handle formats like "1,299.99" or "1299.99"
try:
# Remove commas and convert to float
if ',' in cleaned and '.' in cleaned:
# Format: 1,299.99
price_value = float(cleaned.replace(',', ''))
elif ',' in cleaned:
# Could be European format: 1299,99
if cleaned.count(',') == 1 and len(cleaned.split(',')[1]) == 2:
price_value = float(cleaned.replace(',', '.'))
else:
# Format: 1,299 (no cents)
price_value = float(cleaned.replace(',', ''))
else:
price_value = float(cleaned)
return price_value
except ValueError:
print(f"Could not parse price from: {price_text}")
return None
def store_price_data(url, price, status_code):
"""Store price data in your database."""
# Implement your storage logic here
# Could be PostgreSQL, MongoDB, or any other database
print(f"Storing: {url} -> ${price} (Status: {status_code})")
# Site-specific configurations for better accuracy
SITE_CONFIGS = {
"competitor1.com": {"price_selector": ".price-box .price"},
"competitor2.com": {"price_selector": "[data-testid='price']"},
"competitor3.com": {"price_selector": ".product-price-value"},
}
def get_site_config(url):
"""Get site-specific configuration."""
for domain, config in SITE_CONFIGS.items():
if domain in url:
return config
return None
# Load your 50k product URLs (from database, file, or API)
def load_product_urls():
"""Load URLs from your data source."""
# Replace with your actual data loading logic
urls = [
"<https://competitor1.com/product/123>",
"<https://competitor2.com/product/456>",
# ... 49,998 more URLs
]
return urls
# Main execution: dispatch all crawling tasks
def start_daily_price_monitoring():
"""Start the daily price monitoring job."""
product_urls = load_product_urls()
print(f"Starting crawl for {len(product_urls)} URLs...")
for url in product_urls:
site_config = get_site_config(url)
fetch_product_price.delay(url, site_config)
print("All tasks queued successfully!")
# Run with: python -m celery worker -A price_monitor --loglevel=info
# Start monitoring with: start_daily_price_monitoring()
En el código mejorado anterior, fetch_product_price es una tarea Celery robusta diseñada para la supervisión de precios a escala empresarial. Al llamar a delay(url, site_config) para cada URL, ponemos las tareas en cola en Redis, donde más de 100 trabajadores pueden tomarlas al instante. El enfoque distribuido transforma un rastreo de 12 horas de una sola máquina en una operación de 2-3 horas a través de su flota de trabajadores.
Consideraciones clave sobre la producción:
- La gestión del proxy es crítica: Este ejemplo incluye un PROXY_POOL que rota las IPs por petición, esencial cuando se accede a 50.000 URLs. Sin esto, estás esencialmente haciendo DoS a sitios objetivo desde una IP, garantizando bloqueos.
- Limitación de la tasa por dominio: Incluso con distribución, 50.000 URL de un sitio competidor dispararán las alarmas si todas llegan en cuestión de minutos. Incluimos retrasos similares a los humanos
(time.sleep(random.uniform(2, 8)), pero tenemos en cuenta la limitación por dominio. - Programación y control. Utilice Celery Beat para la programación diaria o intégrelo con Airflow para flujos de trabajo complejos. La función
start_daily_price_monitoring()puede activarse mediante cron o su plataforma de orquestación. - Integración de la canalización de datos. Después de cada rastreo, la función
store_price_data()guarda los resultados en la base de datos. - Resistencia a los fallos. El código incluye lógica de reintento con retroceso exponencial, pero prevea fallos parciales. Si el 5% de las URL fallan sistemáticamente, investigue si esos productos se han dejado de fabricar, se han trasladado o si esos sitios específicos tienen medidas anti-bot más estrictas que requieren enfoques diferentes.
Caso práctico 2: SEO e investigación de mercado
La SEO y los estudios de mercado requieren rastrear millones de páginas en dos flujos críticos: el análisis de contenidos y la supervisión de los motores de búsqueda. No se trata solo de rastrear, sino de crear inteligencia competitiva que exige velocidad, sigilo y precisión.
Si desea realizar un seguimiento de las menciones de palabras clave en un millón de páginas de competidores y, al mismo tiempo, supervisar las clasificaciones en las SERP de cientos de palabras clave a diario, una sola máquina tardaría semanas y se bloquearía en cuestión de horas. Esto exige a gritos una arquitectura distribuida.
El enfoque de rastreo web distribuido para ello puede dividirse en dos corrientes:
- Inteligencia de contenidos: Rastree los sitios de la competencia, los medios de comunicación y los blogs del sector para realizar un seguimiento de la densidad de palabras clave, las lagunas de contenido y las tendencias del mercado.
- Vigilancia SERP: Supervisa las clasificaciones de Google/Bing para tus palabras clave objetivo, rastrea las posiciones de la competencia y los cambios en las características de las SERP.
from celery import Celery
import requests
from bs4 import BeautifulSoup
import redis
import hashlib
import json
import time
import random
import re
from urllib.parse import urljoin, urlparse
from dataclasses import dataclass
from typing import List, Dict, Optional
import logging
# Initialize Celery and Redis
app = Celery('seo_intelligence', broker='redis://localhost:6379/0')
redis_client = redis.Redis(host='localhost', port=6379, db=1)
# Anti-detection configurations
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Safari/605.1.15"
]
PROXY_POOL = [
"<http://user:[email protected]:8080>",
"<http://user:[email protected]:8080>",
# Add your proxy endpoints
]
@dataclass
class KeywordData:
keyword: str
frequency: int
context: List[str] # Surrounding text snippets
url: str
domain: str
@dataclass
class SERPResult:
keyword: str
position: int
title: str
url: str
snippet: str
domain: str
class SEOCrawler:
def __init__(self):
self.session = self._create_session()
def _create_session(self):
session = requests.Session()
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
def _get_headers(self):
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Cache-Control": "max-age=0"
}
# Deduplication utilities
def get_url_hash(url: str) -> str:
"""Generate consistent hash for URL deduplication."""
return hashlib.md5(url.encode()).hexdigest()
def is_url_processed(url: str) -> bool:
"""Check if URL was already processed today."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
return redis_client.exists(f"processed:{today}:{url_hash}")
def mark_url_processed(url: str):
"""Mark URL as processed with 24h expiry."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
redis_client.setex(f"processed:{today}:{url_hash}", 86400, 1)
# Stream 1: Content Intelligence Crawling
@app.task(bind=True, max_retries=3)
def crawl_content_for_keywords(self, url: str, target_keywords: List[str]):
"""Crawl a page and extract keyword intelligence."""
# Skip if already processed today
if is_url_processed(url):
return {"status": "skipped", "reason": "already_processed", "url": url}
# Human-like delay
time.sleep(random.uniform(3, 7))
try:
crawler = SEOCrawler()
response = crawler.session.get(
url,
headers=crawler._get_headers(),
timeout=30
)
response.raise_for_status()
# Extract content and analyze keywords
soup = BeautifulSoup(response.text, 'html.parser')
content_data = extract_keyword_intelligence(soup, url, target_keywords)
# Store results
store_keyword_data(content_data)
mark_url_processed(url)
return {
"status": "success",
"url": url,
"keywords_found": len(content_data),
"total_mentions": sum(kd.frequency for kd in content_data)
}
except Exception as e:
logging.error(f"Content crawl failed for {url}: {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"status": "failed", "url": url, "error": str(e)}
def extract_keyword_intelligence(soup: BeautifulSoup, url: str, keywords: List[str]) -> List[KeywordData]:
"""Extract keyword data from page content."""
# Remove script and style elements
for script in soup(["script", "style", "nav", "footer", "header"]):
script.decompose()
# Get clean text content
text = soup.get_text()
text = re.sub(r'\s+', ' ', text).strip().lower()
domain = urlparse(url).netloc
keyword_data = []
for keyword in keywords:
keyword_lower = keyword.lower()
# Find all occurrences
pattern = r'\b' + re.escape(keyword_lower) + r'\b'
matches = list(re.finditer(pattern, text))
if matches:
# Extract context around each match
contexts = []
for match in matches[:5]: # Limit to first 5 for performance
start = max(0, match.start() - 100)
end = min(len(text), match.end() + 100)
context = text[start:end].strip()
contexts.append(context)
keyword_data.append(KeywordData(
keyword=keyword,
frequency=len(matches),
context=contexts,
url=url,
domain=domain
))
return keyword_data
# Stream 2: SERP Tracking
@app.task(bind=True, max_retries=3)
def track_serp_rankings(self, keyword: str, search_engine: str = "google"):
"""Track SERP positions for a keyword."""
time.sleep(random.uniform(5, 10)) # Longer delay for search engines
try:
crawler = SEOCrawler()
if search_engine == "google":
search_url = f"<https://www.google.com/search?q={keyword}&num=20>"
else: # Bing
search_url = f"<https://www.bing.com/search?q={keyword}&count=20>"
# Special headers for search engines
headers = crawler._get_headers()
headers.update({
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Referer": "<https://www.google.com/>" if search_engine == "google" else "<https://www.bing.com/>"
})
response = crawler.session.get(search_url, headers=headers, timeout=30)
response.raise_for_status()
# Parse SERP results
soup = BeautifulSoup(response.text, 'html.parser')
serp_data = parse_serp_results(soup, keyword, search_engine)
# Store SERP data
store_serp_data(serp_data)
return {
"status": "success",
"keyword": keyword,
"results_found": len(serp_data),
"search_engine": search_engine
}
except Exception as e:
logging.error(f"SERP tracking failed for '{keyword}': {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=120 * (2 ** self.request.retries))
return {"status": "failed", "keyword": keyword, "error": str(e)}
def parse_serp_results(soup: BeautifulSoup, keyword: str, search_engine: str) -> List[SERPResult]:
"""Parse search engine results page."""
results = []
position = 1
if search_engine == "google":
# Google result selectors
result_elements = soup.select('div.g')
for element in result_elements:
title_elem = element.select_one('h3')
link_elem = element.select_one('a[href]')
snippet_elem = element.select_one('.VwiC3b, .s3v9rd')
if title_elem and link_elem:
url = link_elem.get('href', '')
if url.startswith('/url?q='):
url = url.split('/url?q=')[1].split('&')[0]
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20: # Limit to top 20
break
else: # Bing
result_elements = soup.select('.b_algo')
for element in result_elements:
title_elem = element.select_one('h2 a')
snippet_elem = element.select_one('.b_caption p')
if title_elem:
url = title_elem.get('href', '')
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20:
break
return results
# Data storage functions
def store_keyword_data(keyword_data: List[KeywordData]):
"""Store keyword intelligence in database."""
for kd in keyword_data:
data = {
"keyword": kd.keyword,
"frequency": kd.frequency,
"context": kd.context,
"url": kd.url,
"domain": kd.domain,
"crawled_at": time.time()
}
# Store in your preferred database (PostgreSQL, MongoDB, etc.)
redis_client.lpush(f"keyword_data:{kd.keyword}", json.dumps(data))
print(f"Stored: {kd.keyword} found {kd.frequency} times on {kd.domain}")
def store_serp_data(serp_data: List[SERPResult]):
"""Store SERP tracking data."""
for result in serp_data:
data = {
"keyword": result.keyword,
"position": result.position,
"title": result.title,
"url": result.url,
"snippet": result.snippet,
"domain": result.domain,
"tracked_at": time.time()
}
redis_client.lpush(f"serp_data:{result.keyword}", json.dumps(data))
print(f"SERP: '{result.keyword}' -> #{result.position} {result.domain}")
# Orchestration functions
def start_content_intelligence_crawl(urls: List[str], keywords: List[str]):
"""Launch content crawling across 1M+ URLs."""
print(f"Starting content intelligence crawl for {len(urls)} URLs...")
for url in urls:
crawl_content_for_keywords.delay(url, keywords)
print(f"Queued {len(urls)} content crawling tasks")
def start_serp_tracking(keywords: List[str], search_engines: List[str] = ["google", "bing"]):
"""Launch SERP tracking for target keywords."""
print(f"Starting SERP tracking for {len(keywords)} keywords...")
for keyword in keywords:
for engine in search_engines:
track_serp_rankings.delay(keyword, engine)
print(f"Queued {len(keywords) * len(search_engines)} SERP tracking tasks")
# Example usage
if __name__ == "__main__":
# Target keywords for analysis
target_keywords = [
"artificial intelligence", "machine learning", "data science",
"cloud computing", "cybersecurity", "digital transformation"
]
# URLs to crawl for content intelligence (load from your database)
content_urls = [
"<https://techcrunch.com/ai>",
"<https://venturebeat.com/ai>",
"<https://competitor-blog.com/insights>",
# ... 999,997 more URLs
]
# Keywords to track in SERPs
serp_keywords = [
"best AI tools 2026", "enterprise machine learning",
"data analytics platform", "cloud security solutions"
]
# Launch both crawling streams
start_content_intelligence_crawl(content_urls, target_keywords)
start_serp_tracking(serp_keywords)
Consideraciones clave sobre la producción:
- Deduplicación inteligente: El sistema utiliza Redis con caducidad de 24 horas para evitar volver a rastrear el mismo contenido a diario. Para una deduplicación más profunda, considera el hashing de contenido para detectar páginas que cambiaron de URL pero mantuvieron el mismo contenido.
- Limitación de la tasa en función del dominio: El rastreo de las SERP requiere especial precaución, ya que los motores de búsqueda son más agresivos a la hora de bloquear. Nuestro ejemplo incluye retrasos más largos (5-10 segundos) para las consultas de búsqueda frente al rastreo de contenidos (3-7 segundos).
- Seguimiento de características SERP: El analizador gestiona los resultados de Google y Bing, pero puedes ampliarlo para realizar un seguimiento de los fragmentos destacados, los paquetes locales y otras características de las SERP que afectan a tu estrategia de visibilidad.
- Integración de canalización de datos: Almacene los resultados en la base de datos que prefiera (PostgreSQL para análisis relacionales, MongoDB para esquemas flexibles).
Buenas prácticas
Respete robots.txt o aténgase a las consecuencias
Analice el archivo robots.txt antes de poner en cola las URL y respete religiosamente las directivas de retardo de rastreo. Si las ignora, todo su rango de IP aparecerá en la lista negra más rápido de lo que tarda en decir “rastreador distribuido”. Incorpore la comprobación de robots.txt directamente en la frontera de URL y no la convierta en responsabilidad del nodo trabajador.
Más allá del cumplimiento de robots.txt, también debe implementar estrategias integrales para evitar la detección en toda su flota distribuida.
Registrar siempre para depuración 3 AM
Cuando tu rastreo muere a medianoche, necesitas metadatos: URL, estado HTTP, latencia, ID del proxy, ID del trabajador y fecha y hora de cada solicitud. Los registros estructurados en JSON salvan la cordura. La cuestión no es si necesitará depurar un fallo de producción, sino cuándo.
Valídelo todo, no se fíe de nada
La validación de esquemas en los datos extraídos es necesaria para la supervivencia de sus rastreadores web distribuidos, ya que una sola respuesta malformada puede envenenar todo su conjunto de datos. Compruebe los tipos de campo, los campos obligatorios y la frescura de los datos en el momento de la ingesta. Detecte la basura a tiempo o verá cómo corrompe sus análisis meses después.
Lucha sin cuartel contra la deuda
Los sistemas distribuidos se pudren rápidamente. Es necesario programar una limpieza mensual de claves Redis obsoletas, colas de tareas fallidas y procesos de trabajadores huérfanos. Las URL muertas se acumulan, los grupos de proxy se contaminan con IP bloqueadas y las fugas de memoria de los trabajadores se agravan con el tiempo. El mantenimiento no es glamuroso, pero mantiene su rastreador en buen estado. La deuda técnica de los rastreadores aumenta exponencialmente, por lo que debe abordarse antes de que rompa el sistema.
Errores comunes del rastreo distribuido y cómo evitarlos
Existen numerosos escollos comunes a los que la gente se enfrenta cuando utiliza el rastreo web distribuido, razón por la cual la mayoría de los ingenieros buscan alternativas, como los conjuntos de datos de Bright Data. Algunas de estas dificultades son:
La trampa del “punto único de fallo
Construir todo alrededor de una instancia de Redis o coordinador maestro es una mala idea. Cuando muere, todo el rastreo se detiene.
Corrección: Utiliza Redis Cluster o múltiples instancias de broker. Diseñe para que el coordinador desaparezca, por lo que los trabajadores deben manejar con gracia las interrupciones del corredor y reconectarse automáticamente.
La espiral mortal del reintento
Cuando las URLs fallidas vuelven inmediatamente a la cola principal, se crea un bucle infinito que machaca los endpoints rotos y atasca su pipeline.
Corrección: Colas de reintentos separadas con backoff exponencial. Primer reintento después de 1 minuto, luego 5, luego 30. Después de 3 fallos, enviar a una cola de letra muerta para revisión manual.
La falacia de que todos los trabajadores son iguales
La distribución de tareas round-robin asume que cada trabajador tiene la misma velocidad de red, calidad de proxy y potencia de procesamiento. La realidad suele ser más confusa.
Solución: aplique una puntuación de los trabajadores basada en la tasa de éxito, la latencia y el rendimiento. Asigne las tareas más difíciles a los trabajadores con mejor rendimiento.
La bomba de relojería de las fugas de memoria
Los workers que nunca se reinician acumulan fugas de memoria, especialmente cuando analizan HTML malformado o manejan respuestas de gran tamaño. Si se dejan solos, su rendimiento de rastreo web distribuido se degrada hasta que los trabajadores se bloquean.
Corregir: Reiniciar los trabajadores después de procesar 1000 tareas o cada 4 horas. Supervisar el uso de memoria e implementar disyuntores.
Conclusión
Ya dispone de los planos necesarios para realizar un rastreo distribuido de millones de páginas. Para profundizar en los fundamentos del rastreo web en los que se basan los sistemas distribuidos, lee nuestro completo resumen sobre rastreadores web.
La arquitectura es sencilla, pero la cruda realidad es que el 90% de los equipos siguen fracasando porque subestiman la complejidad antidetección de un sistema de rastreo web distribuido. Gestionar miles de proxies, rotar huellas dactilares y manejar CAPTCHAs se convierte en una pesadilla de ingeniería a tiempo completo que distrae de la extracción de datos valiosos.
Esta es exactamente la razón por la que existe la API Web Unlocker de Bright Data. En lugar de dedicar meses a crear una infraestructura de proxy que se rompe cada semana, sus trabajadores distribuidos solo tienen que dirigir las solicitudes a través de la API de Web Unlocker, con una tasa de éxito superior al 99 %.
Sin gestión de proxy, sin rotación de huellas dactilares, sin resolución de CAPTCHA: sólo extracción de datos fiable a escala. Su equipo de ingenieros se centra en crear la lógica empresarial mientras Bright Data se encarga de los juegos del gato y el ratón con los sistemas anti-bot.
Los cálculos son sencillos: la antidetección casera cuesta meses de tiempo de ingeniería, además de continuos quebraderos de cabeza de mantenimiento, mientras que Web Unlocker cuesta una fracción de eso y ofrece fiabilidad de nivel empresarial. Así que deje de reinventar la rueda y empiece a extraer información. Obtenga su cuenta gratuita de Bright Data hoy mismo y convierta su rastreador distribuido de una carga de mantenimiento en una ventaja competitiva.





