

En este artículo, aprenderás a recopilar datos financieros manualmente y a usar la API de raspado de datos financieros de Bright Data para automatizar el proceso.
Conoce lo que quieres raspar y cómo está organizado
Los datos financieros abarcan una gama de información amplia y, a menudo, compleja. Antes de empezar a raspar, debes identificar claramente el tipo de datos que necesitas.
Por ejemplo, es posible que quieras analizar los precios de las acciones que muestran el precio más reciente de una acción, así como su precio de apertura y cierre del día, los máximos y mínimos alcanzados durante el día y cualquier cambio de precio que se haya producido a lo largo del tiempo. Los datos financieros, como las cuentas de resultados, los balances (que describen el activo y el pasivo) y los estados de tesorería (que registran las entradas y salidas de dinero), también son necesarios para evaluar el rendimiento de una empresa. Los ratios financieros, las valoraciones de los analistas y los informes pueden orientar las decisiones de compra y venta, mientras que las nuevas actualizaciones y el análisis del sentimiento en las redes sociales ofrecen más información sobre las tendencias del mercado.
Entender cómo están organizados los datos de una página web puede facilitar la búsqueda y el raspado de lo que necesitas.
Analiza los aspectos jurídicos y éticos
Antes de crear un sitio web, asegúrate de consultar las condiciones de servicio de ese sitio. Muchos sitios web prohíben el raspado sin consentimiento o autorización previos.
También debes cumplir las reglas del archivo robots.txt, que muestra a qué partes del sitio puedes acceder. Además, asegúrate de no sobrecargar el servidor con solicitudes e implementar demoras entre las solicitudes. Esto contribuye a proteger los recursos del sitio web y evita cualquier problema.
Usa las herramientas para desarrolladores del navegador
Para ver los elementos HTML de una página web, puedes usar las herramientas para desarrolladores del navegador. Estas herramientas están integradas en la mayoría de los navegadores modernos, incluidos Chrome, Safari y Edge. Para abrir las herramientas para desarrolladores, pulsa Ctrl + Shift + I en Windows o Cmd + Option + I en Mac, o haz clic con el botón derecho en la página y selecciona Inspect (Inspeccionar).
Una vez abierta, puedes inspeccionar la estructura HTML de la página e identificar elementos de datos específicos. La pestaña Elements (Elementos) muestra el árbol del modelo de objetos del documento (DOM), que te permite localizar y resaltar los elementos de la página. La pestaña Network (Red) muestra todas las solicitudes de red, lo que resulta útil para buscar puntos finales de API o datos cargados dinámicamente. La pestaña Console (Consola) permite ejecutar comandos de JavaScript e interactuar con los scripts de la página.
En este tutorial, rasparás las acciones de APPL de Yahoo Finance. Para encontrar las etiquetas HTML correspondientes, dirígete a la página APPL stock (acciones de APPL), haz clic con el botón derecho en el precio que aparece en la página y haz clic en Inspect (Inspeccionar). La pestaña Elements (Elementos) resalta el elemento HTML que contiene el precio:

Anota el nombre de la etiqueta y cualquier atributo único, como class o id para ayudarte a localizar este elemento en tu raspador.
Cómo configurar el entorno y el proyecto
Este tutorial usa [Python]((https://www.python.or) para el raspado web debido a su simplicidad y a las bibliotecas disponibles. Antes de empezar, comprueba que tienes la versión Python 3.10 o superior instalada en tu sistema.
Cuando tengas Python, abre tu terminal o «shell» y ejecuta los siguientes comandos para crear un directorio y un entorno virtual:
mkdir scrape-financial-data
cd scrape-financial-data
python3 -m venv myenv
Una vez creado el entorno virtual, te queda activarlo. Los comandos de activación varían según el sistema operativo.
Si usas Windows, ejecuta el siguiente comando:
.myenvScriptsactivate
Si usas macOS/Linux, ejecuta este comando:
source myenv/bin/activate
Una vez que hayas activado el entorno virtual, instala las bibliotecas necesarias con pip:
pip3 install requests beautifulsoup4 lxml
Este comando instala la biblioteca Requests para gestionar las solicitudes HTTP, Beautiful Soup para analizar los contenidos HTML y lxml para un análisis eficiente de XML y HTML.
Cómo raspar manualmente los datos financieros
Para raspar manualmente los datos financieros, crea un archivo llamado manual_scraping.py y añade el siguiente código para importar las bibliotecas necesarias:
import requests
from bs4 import BeautifulSoup
Establece la URL de los datos financieros que quieres raspar. Como hemos mencionado, este tutorial utiliza la página Yahoo Finance para las acciones de Apple (AAPL):
url = 'https://finance.yahoo.com/quote/AAPL?p=AAPL&.tsrc=fin-srch'
Tras configurar la URL, envía una solicitud GET a la URL:
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
Este código incluye un encabezado User-Agent para imitar una solicitud del navegador, lo que ayuda a evitar que el sitio web objetivo lo bloquee.
Comprueba que la solicitud se ha realizado correctamente:
if response.status_code == 200:
print('Successfully retrieved the webpage')
else:
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
exit()
Luego, analiza los contenidos de la página web con el analizador lxml:
soup = BeautifulSoup(response.content, 'lxml')
Busca los elementos en función de sus atributos únicos, extrae los contenidos del texto e imprime los datos extraídos:
# Extract specific company details
try:
# Extract specific company details
previous_close = soup.find('fin-streamer', {'data-field': 'regularMarketPreviousClose'}).text.strip()
open_price = soup.find('fin-streamer', {'data-field': 'regularMarketOpen'}).text.strip()
day_range = soup.find('fin-streamer', {'data-field': 'regularMarketDayRange'}).text.strip()
week_52_range = soup.find('fin-streamer', {'data-field': 'fiftyTwoWeekRange'}).text.strip()
market_cap = soup.find('fin-streamer', {'data-field': 'marketCap'}).text.strip()
# Extract PE Ratio (TTM)
pe_label = soup.find('span', class_='label', title='PE Ratio (TTM)')
pe_value = pe_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Extract EPS (TTM)
eps_label = soup.find('span', class_='label', title='EPS (TTM)')
eps_value = eps_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Print the scraped details
print("n### Stock Price ###")
print(f"Open Price: {open_price}")
print(f"Previous Close: {previous_close}")
print(f"Day's Range: {day_range}")
print(f"52 Week Range: {week_52_range}")
print("n### Company Details ###")
print(f"Market Cap: {market_cap}")
print(f"PE Ratio (TTM): {pe_value}")
print(f"EPS (TTM): {eps_value}")
except AttributeError as e:
print("Error while scraping data. Some fields may not be found.")
print(e)
Ejecuta y prueba el código
Para probar el código, abre tu terminal o «shell» y ejecuta el siguiente comando:
python3 manual_scraping.py
El resultado debería ser el siguiente:
Successfully retrieved the webpage
### Stock Price ###
Open Price: 225.20
Previous Close: 225.00
Day's Range: 225.18 - 229.74
52 Week Range: 164.08 - 237.49
### Company Details ###
Market Cap: 3.447T
PE Ratio (TTM): 37.50
EPS (TTM): 37.50
Supera los retos con el raspado manual
El raspado manual de datos puede resultar complicado por varias razones, como tener que resolver CAPTCHA o bloqueos de IP, que requieren estrategias para eludirlos. Los datos desestructurados o desordenados pueden causar errores de análisis, mientras que el raspado sin los permisos adecuados puede generar problemas legales. Las actualizaciones frecuentes del sitio web también pueden estropear el raspador, lo que exige un mantenimiento periódico del código para garantizar una funcionalidad continua.
Para crear y automatizar tu raspador, tienes que dedicar mucho tiempo a escribir el código y a arreglarlo en vez de centrarte en analizar los datos. Si se trata de grandes cantidades de datos, puede ser aún más difícil, ya que hay que asegurarse de que los datos estén limpios y organizados. Si gestionas diferentes estructuras de sitios web, también tienes que entender varias tecnologías web.
Es decir, si necesitas raspar datos con frecuencia y rapidez, el raspado web manual no es la mejor opción.
Cómo raspar datos con la API de raspado de datos financieros de Bright Data
Bright Data supera los retos del raspado manual con su API de raspado de datos financieros, que automatiza la extracción de datos. Viene con gestión de proxy integrada con proxies rotativos para evitar bloqueos de IP. La API devuelve datos estructurados en formatos como JSON y CSV. También es muy escalable, lo que facilita el manejo de grandes volúmenes de datos.
Para usar la API de raspado de datos financieros, regístrate para obtener una cuenta gratuita en el sitio web de Bright Data. Verifica tu dirección de correo electrónico y completa los pasos de verificación de identidad necesarios.
Una vez que tu cuenta esté configurada, inicia sesión para acceder al panel y obtener tus claves de API.
Configurar la API de raspado de datos financieros
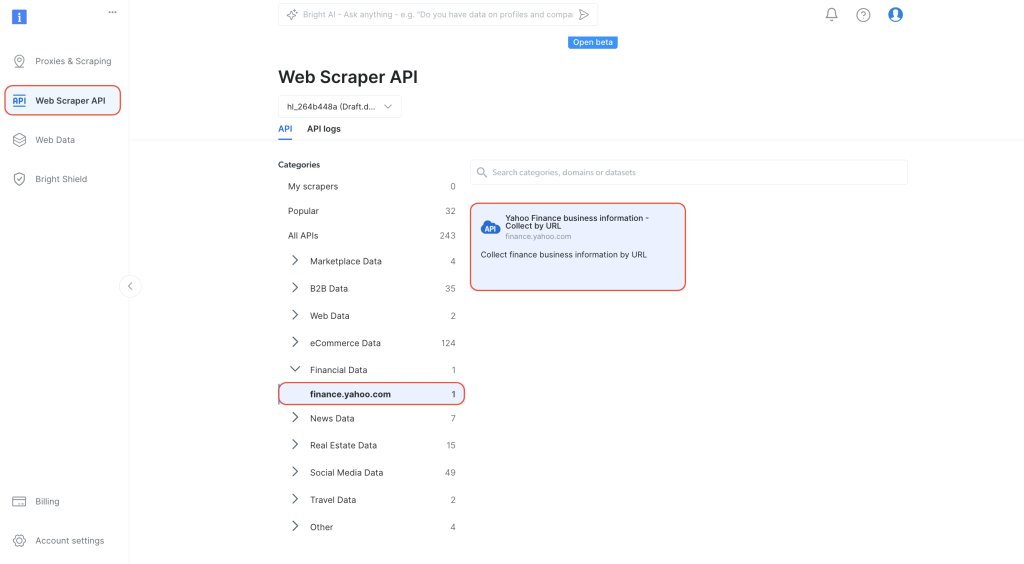
En el panel de control, navega hasta la API de raspado web desde la pestaña de navegación de la izquierda. Selecciona
Financial Data en Categories y, a continuación, haz clic para abrir Yahoo Finance Business Information – Collect by URL (Información empresarial de Yahoo Finance: recopilar por URL):
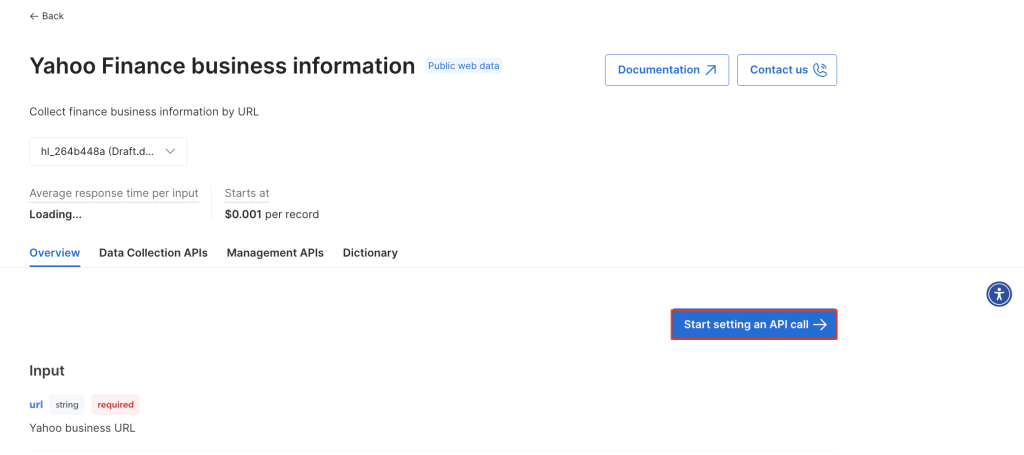
Haz clic en Start setting an API call (Comenzar a configurar una llamada a la API):
Para usar la API, debes crear un token que autentique tus llamadas a la API del raspador de Bright Data. Para crear un token nuevo, haz clic en Create token (Crear token):

Se abrirá un cuadro de diálogo. Establece los permisos en «Admin» y configura la duración como «Unlimited» (ilimitada):

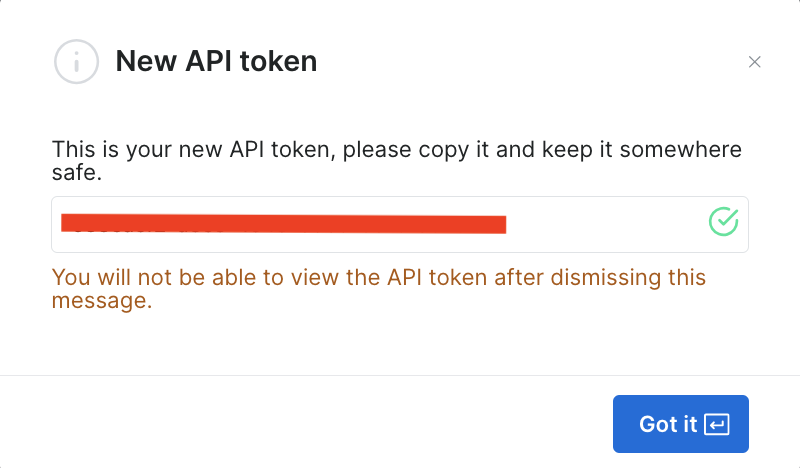
Cuando guardes esta información, se creará el token y se te pedirá que introduzcas el nuevo token. Asegúrate de guardarlo en un lugar seguro, ya que lo volverás a necesitar pronto:
Si ya creaste el token, puedes obtenerlo en la configuración de usuario en API Tokens (Tokens de API). Selecciona la pestaña More (Más) de tu usuario y, a continuación, haz clic en Copy token (Copiar token).
Ejecuta el raspador para recuperar datos financieros
En la página Yahoo Finance Business Information (Información empresarial de Yahoo Finance), añade tu token de API en el campo API token (API de token) y, a continuación, añade la URL estándar del sitio web objetivo, que es https://finance.yahoo.com/quote/AAPL/. Copia la solicitud en la sección AUTHENTICATED REQUEST (SOLICITUD AUTENTICADA) de la derecha:
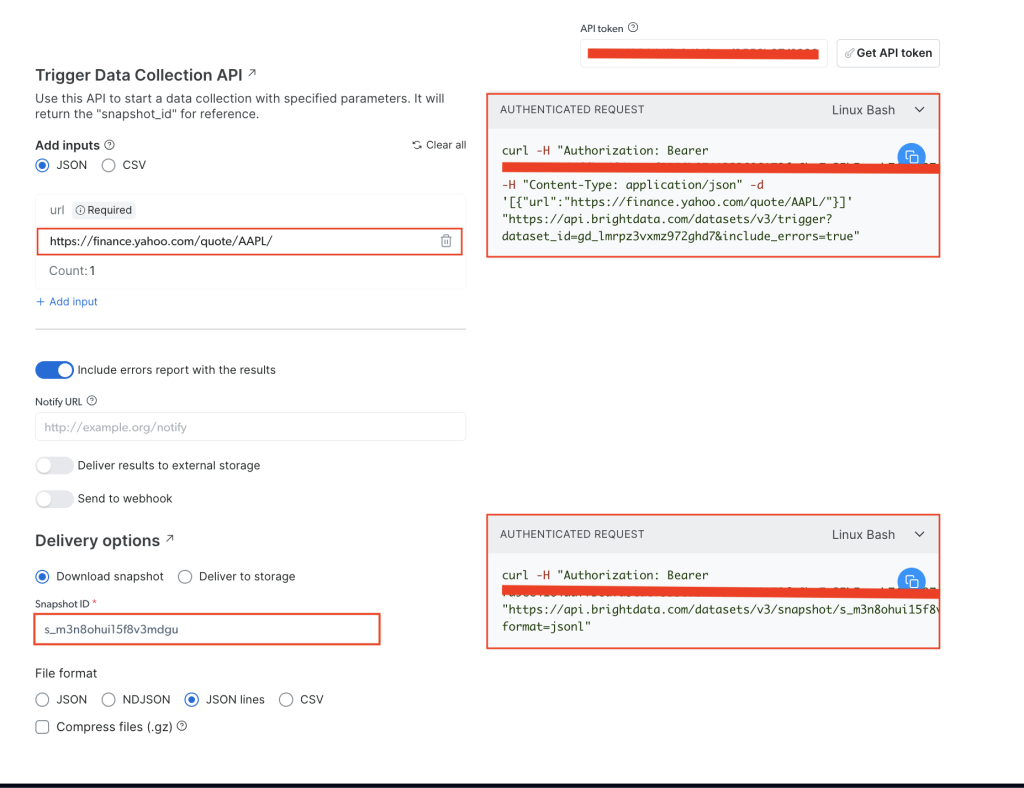
Abre tu terminal o «shell» y ejecuta la llamada a la API con curl. Debería tener este aspecto:
curl -H "Authorization: Bearer YOUR_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://finance.yahoo.com/quote/AAPL/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=YOUR_DATA_SET_ID&include_errors=true"
Tras ejecutar el comando, obtendrás el snapshot_id como respuesta:
{"snapshot_id":"s_m3n8ohui15f8v3mdgu"}
Copia el snapshot_id y ejecuta la siguiente llamada a la API desde tu terminal o «shell»:
curl -H "Authorization: Bearer YOUR_TOKEN" "https://api.brightdata.com/datasets/v3/snapshot/YOUR_SNAP_SHOT_ID?format=jsonl"
Asegúrate de reemplazar
YOUR_TOKENyYOUR_SNAP_SHOT_IDpor tus credenciales.
Tras ejecutar este código, deberías obtener los datos extraídos como salida. Los datos deben parecerse al siguiente archivo JSON.
Si recibes una respuesta indicando que la instantánea no está lista, espere diez segundos e inténtelo de nuevo.
La API de raspado de datos financieros de Bright Data extrajo todos los datos que requerías sin necesidad de analizar la estructura HTML ni localizar etiquetas específicas. Recuperó todos los datos de la página, incluidos campos adicionales como earning_estimate, earnings_historyy growth_estinates.
Todo el código de este tutorial está disponible en este repositorio de GitHub.
Ventajas de usar la API de Bright Data
La API de raspado de datos financieros de Bright Data simplifica el proceso de raspado al eliminar la necesidad de escribir o gestionar código de raspado. La API también ayuda a garantizar el cumplimiento mediante la gestión de la rotación de proxy y la adhesión a las condiciones de servicio de los sitios web, lo que le permite recopilar datos sin temor a sufrir bloqueos o infringir las normas.
La API de raspado de datos financieros de Bright Data ofrece datos estructurados y fiables con muy poca codificación. Se encarga de la navegación por las páginas y del análisis sintáctico de HTML por ti, lo que simplifica el proceso. La escalabilidad de la API te permite recopilar datos sobre numerosas acciones y otras métricas financieras sin realizar grandes cambios en el código. El mantenimiento también es mínimo porque Bright Data actualiza el raspador cuando los sitios web cambian su estructura, por lo que la recopilación de datos continúa sin problemas y sin ningún trabajo adicional.
Conclusión
La recopilación de datos financieros es una tarea fundamental para los desarrolladores y los equipos de datos que participan en el análisis financiero, la negociación algorítmica y la investigación de mercados. En este artículo, has aprendido a raspar datos financieros manualmente con Python y la API de raspdo de datos financieros de Bright Data. Aunque el raspado manual de datos proporciona control, puede resultar complicado gestionar las medidas contra el raspado y los gastos generales de mantenimiento, además de que es difícil de escalar.
La API de raspado de datos financieros de Bright Data agiliza la recopilación de datos mediante la gestión de tareas complejas, como la rotación de proxies y la resolución de CAPTCHA. Además de la API, Bright Data ofrece conjuntos de datos, proxies residencialesy el navegador de raspado para mejorar tus proyectos de raspado web. Regístrate para obtener una prueba gratuita a fin de explorar todo lo que Bright Data ofrece.





