
En esta guía, descubrirá:
- Qué es Langflow y por qué se ha hecho tan popular.
- Las limitaciones de utilizar LLM estándar en aplicaciones Langflow, y cómo superarlas con datos externos.
- Cómo crear una aplicación Langflow AI integrada con Bright Data para el acceso a datos web.
Sumerjámonos.
¿Qué es Langflow?
Langflow es una herramienta de código abierto creada en Python y JavaScript para crear y desplegar agentes y flujos de trabajo basados en IA. Con más de 92.000 estrellas en GitHub, es una de las bibliotecas más populares y adoptadas para desarrollar agentes de IA.
Langflow funciona como una plataforma de desarrollo visual de bajo código. Le permite crear complejas aplicaciones de IA simplemente conectando componentes pre-construidos a través de una interfaz de arrastrar y soltar. Este enfoque elimina la necesidad de una codificación extensa. No obstante, admite la integración de código personalizado para ofrecer la máxima flexibilidad.
Langflow expone una amplia gama de características de IA, incluyendo agentes, LLMs, almacenes de vectores e integración con cualquier API, modelo o base de datos.
Por qué las aplicaciones de IA necesitan acceso a los datos
Comparado con otros frameworks, Langflow brilla como una plataforma visual de bajo código para construir aplicaciones de IA. Pero al igual que cualquier otro sistema impulsado por LLM, las aplicaciones basadas en Langflow son tan inteligentes como los datos a los que tienen acceso.
Los LLM han sido formados con conjuntos de datos estáticos y no conocen los acontecimientos en tiempo real ni los datos privados de las empresas. Esto hace que estén desconectados del mundo actual, a menos que se les conecte con fuentes de datos frescas y relevantes. Y la web es la fuente de información más amplia que existe.
Para superar esas limitaciones de los LLM, Langflow le permite conectarse a canalizaciones de datos web flexibles. Este patrón es fundamental en casos de uso importantes como:
- Flujos de trabajo RAG, en los que los datos recuperados mejoran los resultados del LLM.
- Canalización de datos, donde se extraen y limpian los datos antes del análisis.
- Agentes de IA, que necesitan conocimientos externos para realizar tareas como responder consultas, resumir documentos o ejecutar búsquedas en Internet.
Ahora bien, recuperar datos públicos precisos de la web no es trivial. Se necesita una infraestructura que pueda:
- Conéctese a prácticamente cualquier sitio web (incluso los protegidos por tecnologías anti-scraping).
- Extraiga los datos necesarios de forma fiable.
- Devuélvalo en un formato estructurado y listo para AI.
Esto es exactamente lo que ofrece Bright Data. Al combinar Langflow con las herramientas de Bright Data, su aplicación de IA adquiere potentes capacidades, entre las que se incluyen:
- Rastreo web en tiempo real, eludiendo las defensas anti-bot.
- Extracción de datos estructurados de plataformas de primer nivel como Amazon, LinkedIn, Zillow, etc.
- Acceso a los resultados de los motores de búsqueda para obtener datos SERP en tiempo real basados en consultas.
- Captura visual de datos mediante capturas de pantalla automatizadas a toda página.
Puede conectarse a Bright Data directamente a través de un componente Langflow personalizado. Esto significa que no necesita crear o mantener una lógica de backend compleja. Simplemente conecte el componente a su flujo y ¡listo!
Creación de una aplicación de IA en Langflow con acceso a datos web gracias a Bright Data
En este tutorial paso a paso, utilizarás Langflow para construir un agente de IA capaz de recuperar datos web en vivo integrándolo con Bright Data.
Tenga en cuenta que la configuración del agente de IA presentada aquí es sólo un ejemplo sencillo de lo que puede crear gracias a esta integración. Existen innumerables aplicaciones de IA que puede crear utilizando la integración Bright Data × Langflow. Para inspirarse, explore nuestra lista de posibles casos de uso.
Siga la siguiente guía para crear un agente de IA basado en Bright Data en Langflow.
Requisitos previos
Para seguir este tutorial, asegúrate de que cumples los siguientes requisitos:
- Al menos una CPU de doble núcleo y 2 GB de RAM (Recomendado: CPU multinúcleo y al menos 4 GB de RAM).
- Python versión 3.10 a 3.12 en Windows, o 3.10 a 3.13 en macOS/Linux, instalado localmente.
- paquete
uvinstalado localmente. - Una clave API de Bright Data.
- Una clave API para conectarse a uno de los LLM compatibles (en este caso, utilizaremos Gemini, cuyo uso a través de la API es gratuito).
No se preocupe si no dispone de una clave API de Bright Data, ya que se le guiará a través del proceso de configuración durante el tutorial.
Para instalar uv, ejecute el siguiente comando:
pip install uvSi eres usuario de Windows, también necesitarás Microsoft Visual C++ 14.0 o superior. Descárgalo y sigue la guía de soporte para completar la instalación.
Paso nº 1: Configurar Langflow
En primer lugar, cree una carpeta para su proyecto Langflow y navegue hasta ella:
mkdir langflow-agent
cd langflow-agentLa carpeta langflow-agent servirá como directorio de su proyecto Langflow.
Dentro de la carpeta del proyecto, crea un entorno virtual Python usando uv:
uv venv venvLuego, en macOS/Linux, actívalo con:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venvScriptsactivateCon su entorno virtual activado, instale Langflow en el entorno de su proyecto:
uv pip install langflowEsto tardará un poco, así que ten paciencia.
Una vez finalizada la instalación, compruebe que la configuración funciona ejecutando la aplicación con este comando:
uv run langflow runEspere a que LangFlow inicialice el servidor local. Una vez que esté listo, debería estar disponible en esta página en su navegador:
http://localhost:7860Ábralo, y si todo ha ido como esperaba y es la primera vez que utiliza Langflow, verá esta interfaz:
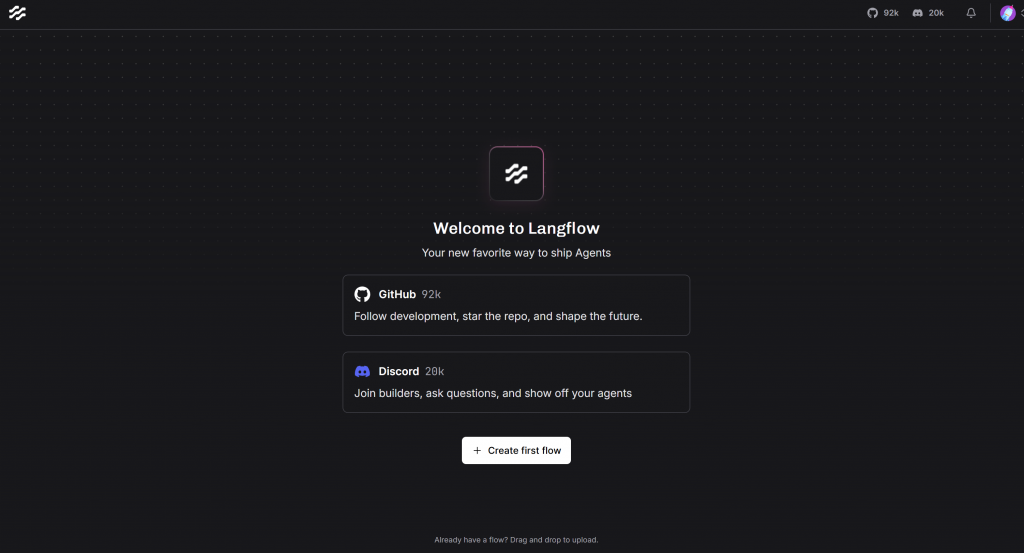
Si encuentra algún error, consulte la guía oficial de instalación.
¡Increíble! Su configuración LangFlow ya está en marcha.
Paso 2: Configurar Bright Data
Para que su aplicación de IA pueda recuperar datos de la web, debe conectarla a la infraestructura de IA de Bright Data.
Bright Data ofrece muchas soluciones de recopilación de datos, pero en este tutorial nos centraremos en:
- Web Unlocker: Una avanzada API de scraping que elude las protecciones contra bots y devuelve cualquier página web en formato HTML o Markdown.
Nota: También es posible la integración con otras herramientas de Bright Data, como las API de Web Scraper, pero esta guía se centra en el Desbloqueador web de uso general.
Para utilizar Web Unlocker en su aplicación Langflow, primero tiene que:
- Configure una zona Web Unlocker en su cuenta de Bright Data.
- Genere su token de API de Bright Data para autenticar las solicitudes.
Siga las instrucciones siguientes para hacer ambas cosas. Como referencia, considere también explorar la documentación oficial.
En primer lugar, si aún no tiene una cuenta de Bright Data, regístrese gratuitamente. Si ya la tiene, inicie sesión y abra su panel de control. Haga clic en el botón “Proxies & Scraping”:
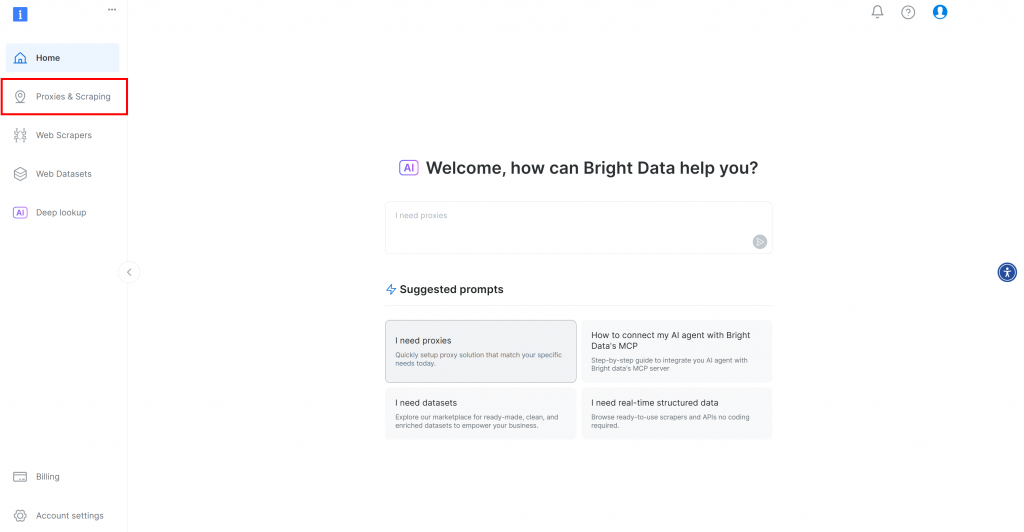
Será redirigido a la página “Proxies & Scraping Infrastructure”:

Si ya tiene una zona Web Unlocker, la verá listada en esta página. En este ejemplo, la zona ya existe y se llama "unblocker" (recuerde este nombre, ya que lo necesitará más adelante).
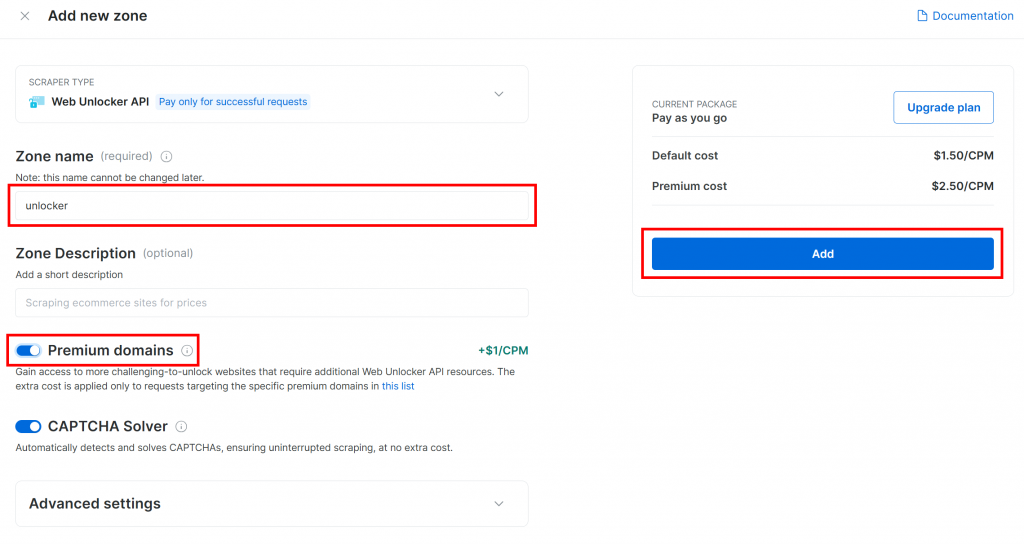
Si aún no dispone de la zona necesaria, desplácese hasta la tarjeta “Web Unlocker API” y haga clic en “Crear zona”:
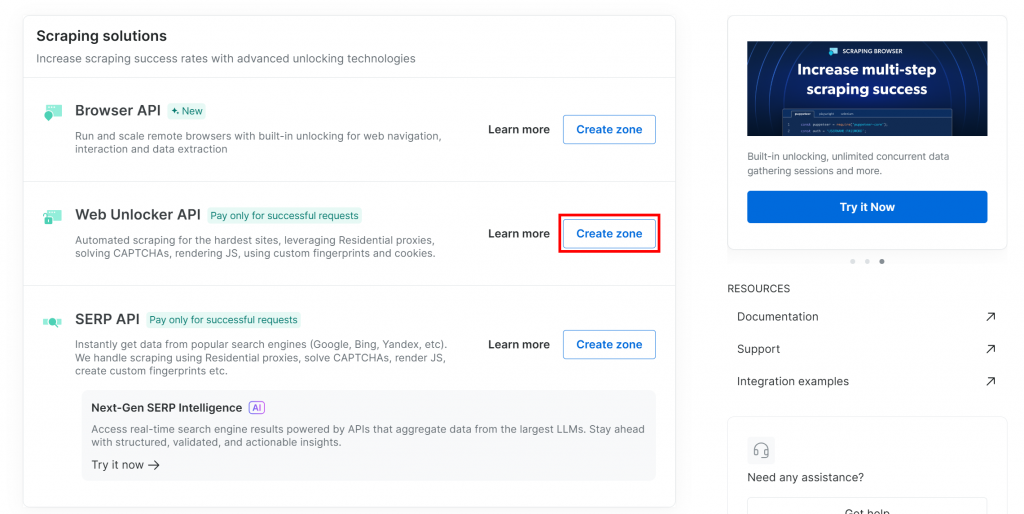
Dale un nombre a tu zona (como “desbloqueador”), activa las funciones avanzadas para un mejor rendimiento y pulsa el botón “Añadir”:
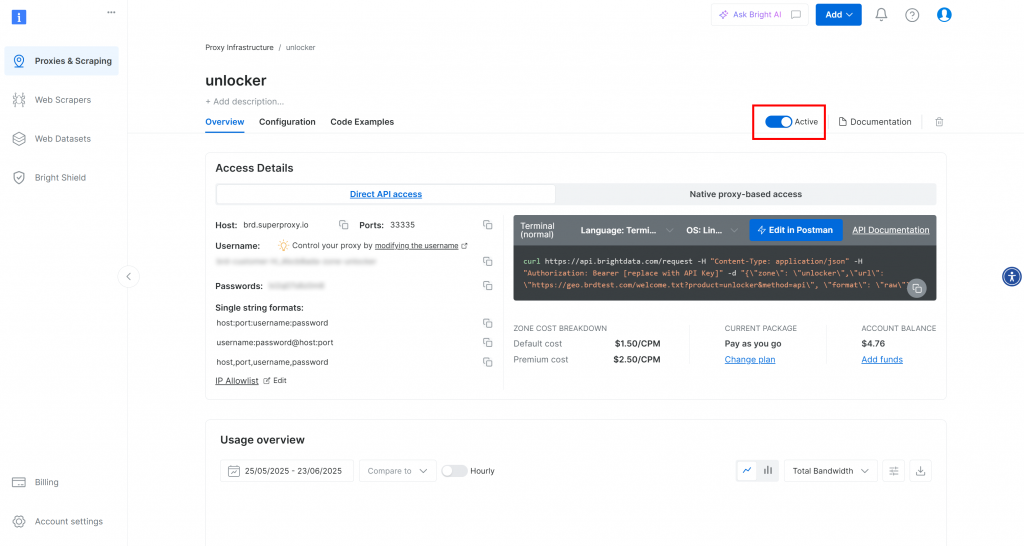
Una vez creado, accederá a la página de detalles de la zona. Asegúrese de que el conmutador está en “Activo”, lo que confirma que el producto está listo para su uso:
Ahora, siga la documentación oficial de Bright Data para generar su clave API. Una vez que la tenga, guárdela en un lugar seguro, ya que la necesitará en breve.
Perfecto. Ya está listo para integrar Bright Data con Langflow mediante un componente personalizado.
Paso nº 3: Inicializar un nuevo flujo en blanco
Antes de continuar, debe crear un nuevo flujo Langflow. Vuelva al servidor local de Langflow y haga clic en el botón “Crear primer flujo”:

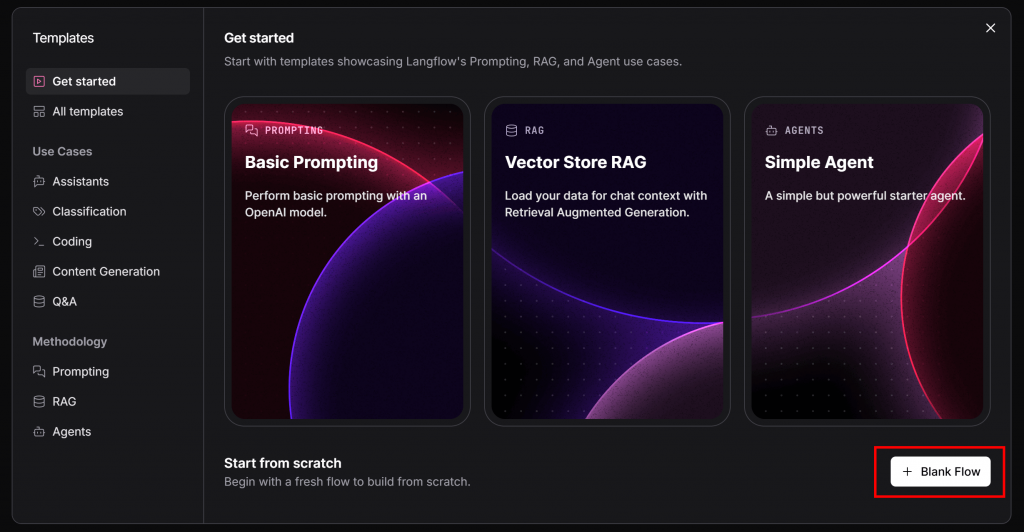
Aparecerá el siguiente modal. Pulse el botón “Flujo en blanco” en la esquina inferior derecha:
Dale a tu flujo un nombre, como “Langflow x Bright Data AI App”. Una vez creado, verá un lienzo en blanco como este:
El lienzo de arriba es donde puedes añadir y conectar componentes para definir tu aplicación de IA. ¡Bien hecho!
Paso 4: Definir un componente de datos de Bright personalizado
La forma más sencilla de integrar Langflow con Bright Data es creando un componente personalizado. Esto permitirá a su agente de IA recopilar datos web utilizando la API Web Unlocker de Bright Data.
En Langflow, los componentes personalizados son clases Python definidas por:
- Entradas: Los datos o parámetros que necesita su componente.
- Salidas: Los datos que tu componente devuelve a los nodos aguas abajo.
- Lógica: El procesamiento interno para convertir las entradas en salidas.
En concreto, su componente personalizado Langflow x Bright Data debería:
- Acepte su clave API de Bright Data y el nombre de zona de Web Unlocker como entradas (para la autenticación).
- Reciba la URL de destino de la página web que desea raspar.
- Realice una solicitud a la API de Web Unlocker, configurada para devolver la página en formato Markdown (que es ideal para el consumo de AI).
- Devuelve el contenido recuperado como salida.
Puedes implementar todo lo anterior con el siguiente componente personalizado de Python:
from langflow.custom import Component
from langflow.io import SecretStrInput, StrInput, Output
from langflow.schema import Data
import httpx
# A Langflow custom component must extend Component
class BrightDataComponent(Component):
# The component name shown in the Langflow UI
display_name = "Bright Data"
# The description in the component details
description = "Retrieve data from the web in Markdown format using Bright Data"
icon = "sparkles" # UI icon identifier
name = "BrightData" # Internal name used by Langflow
# --- INPUTS ---
# Define the inputs required by the component
inputs = [
SecretStrInput(
name="api_key",
display_name="Bright Data API Key",
required=True,
info="Your Bright Data API key from the dashboard"
),
StrInput(
name="zone",
display_name="Web Unlocker Zone Name",
info="The name of the Web Unlocker zone to connect to (e.g., 'web_unlocker')",
required=True
),
StrInput(
name="url",
display_name="Target URL",
info="The URL to transform into Markdown data",
tool_mode=True
),
]
# --- OUTPUT ---
# Define the output returned by the component
outputs = [
Output(
name="web_data",
display_name="Web Data Result",
method="get_web_data" # The name of the method used to generate the output
)
]
# --- LOGIC ---
# This method retrieves web data from Bright Data and returns it
def get_web_data(self) -> Data:
try:
# Bright Data Web Unlocker API endpoint
url = "https://api.brightdata.com/request"
# Request headers including API key for authentication
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Payload specifying the zone, URL, and output format
payload = {
"zone": self.zone,
"url": self.url,
"format": "raw",
"data_format": "markdown"
}
# Send the POST request with a 180-second timeout
with httpx.Client(timeout=180.0) as client:
response = client.post(url, json=payload, headers=headers)
# Raise an error if HTTP status code is not 2xx
response.raise_for_status()
# Extract contains the Markdown-formatted web data
markdown_data = response.text
return Data(data={"data": markdown_data})
# Handle timeout errors
except httpx.TimeoutException:
error_msg = "The Web Unlocker request timed out"
return Data(data={"error": error_msg, "data": None})
# Handle other HTTP errors (e.g., 4xx, 5xx)
except httpx.HTTPStatusError as e:
error_msg = f"Request failed with status {e.response.status_code}: {e.response.text}"
return Data(data={"error": error_msg, "data": None})El BrightDataComponent acepta las siguientes entradas:
- Su clave API de Bright Data.
- El nombre de su zona Web Unlocker.
- La URL de la página que desea raspar.
A continuación, utiliza el cliente HTTPX Python para enviar una solicitud a la API de Web Unlocker, configurada para devolver la respuesta en formato Markdown. La representación Markdown de la página devuelta por la API se convierte en la salida del componente.
Nota: Hemos utilizado HTTPX porque es la biblioteca cliente HTTP por defecto disponible en Langflow. Para obtener más información al respecto, lea nuestra guía sobre cómo utilizar HTTPX para web scraping.
¡Fantástico! Vea cómo añadir este componente a su flujo y dejar que el agente de IA consuma su salida.
Paso nº 5: Añadir el componente de datos personalizados de Bright
Para registrar el componente que ha definido anteriormente, haga clic en el botón “Nuevo componente personalizado” situado en la esquina inferior izquierda. Aparecerá un nuevo componente genérico “Hola, mundo” en el lienzo. Pase el ratón sobre él y haga clic en la sección “Código” para personalizar su lógica:
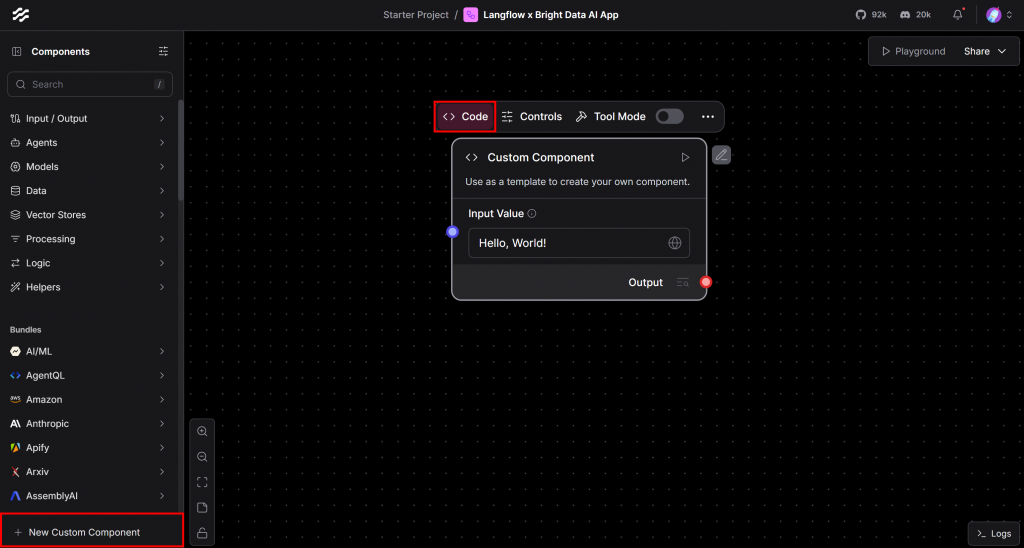
En el editor de código que aparece, pegue el código fuente completo de su clase BrightDataComponent:
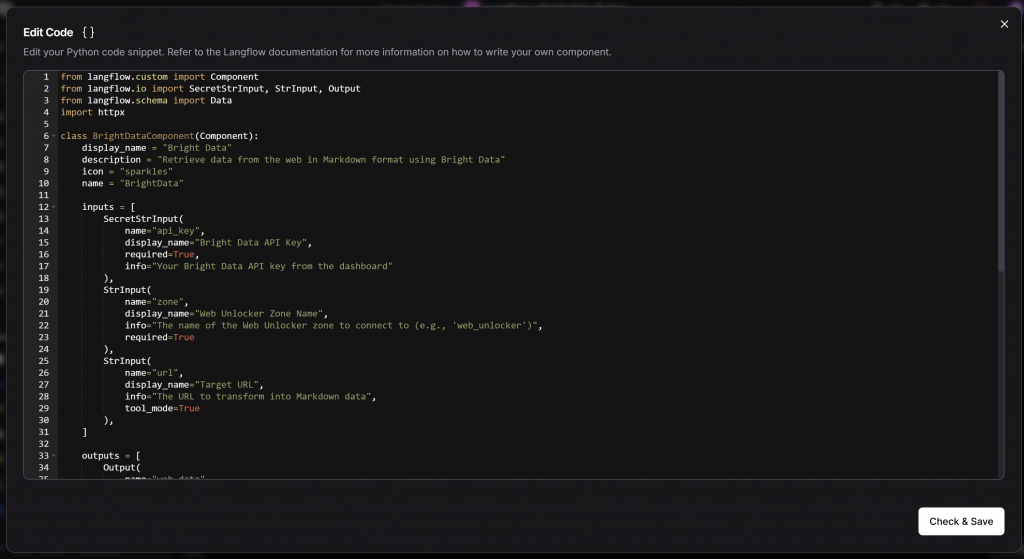
Pulse el botón “Comprobar y guardar”. Ahora debería ver el “Componente personalizado” genérico sustituido por su componente Bright Data:
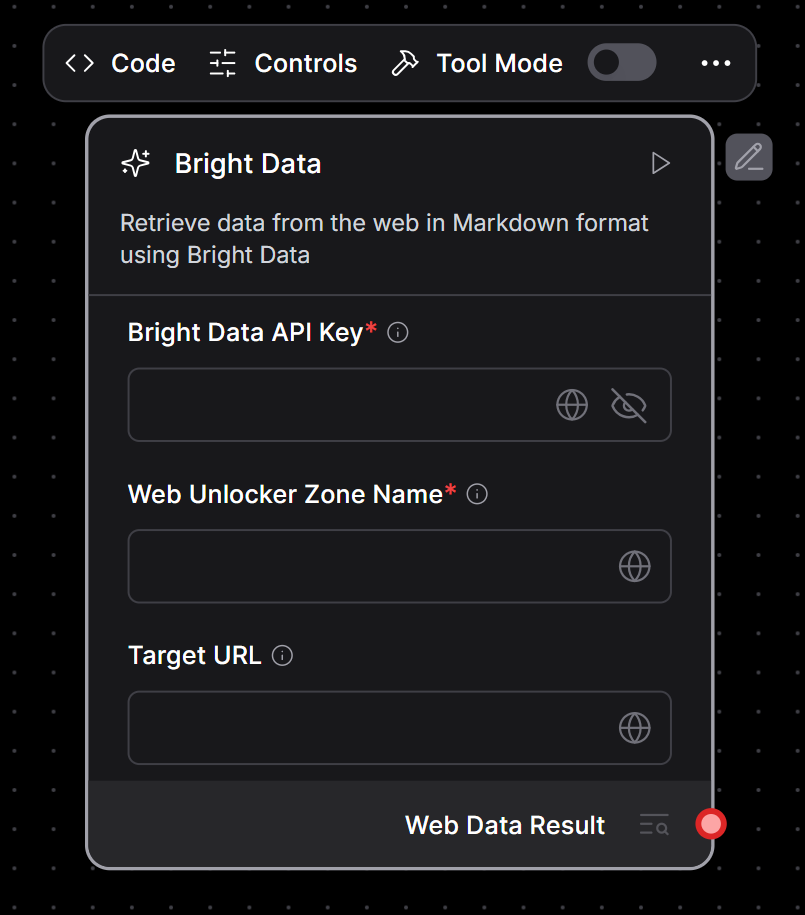
Como puede ver, el componente personalizado de marcador de posición se ha actualizado con su componente personalizado para la integración con Bright Data.
Nota: No es necesario volver a crear manualmente el componente Bright Data en cada flujo.
Simplemente almacene su componente personalizado en un archivo Python y cárguelo automáticamente utilizando el método descrito en la documentación de Langflow.
¡Maravilloso! Ahora su flujo de IA puede integrarse con Bright Data para recuperar datos web.
Paso nº 6: Conectar el agente de IA a Bright Data
Puede utilizar el componente Bright Data directamente dentro de su aplicación Langflow, o convertirlo en una herramienta con la que los agentes de IA puedan interactuar. Al transformarlo en una herramienta, le está dando al agente la capacidad de obtener contenido en vivo de cualquier página web en formato Markdown compatible con IA. En otras palabras, está permitiendo a su IA acceder y recuperar información en tiempo real de cualquier sitio.
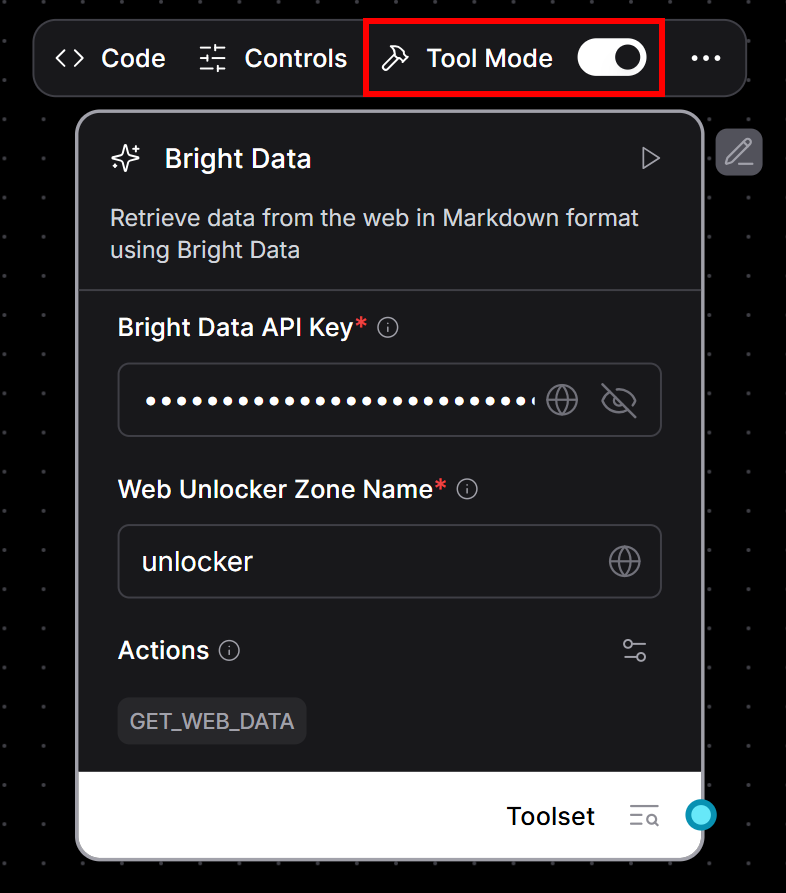
Hacer del componente luminoso una herramienta:
- Pase el ratón por encima de su componente Bright Data.
- Activa el interruptor “Modo Herramienta” para activarlo.
- Rellene los campos obligatorios:
- Su clave API de Bright Data.
- El nombre de su zona Web Unlocker (por ejemplo,
"unlocker").
Esto es lo que debería ver ahora:
Ahora que su componente Bright Data está listo como herramienta, conéctelo a un agente de IA:
- En la barra lateral izquierda, busque el componente “Agentes > Agente”.
- Arrástralo al lienzo.
- Configure el agente para que utilice su LLM preferido (en este ejemplo, utilizaremos Gemini, seleccionando un modelo gratuito como
gemini-2.5-flashy pegando su clave API de Gemini). - Conecte la salida del componente Bright Data “Herramientas” a la entrada del componente Agente:
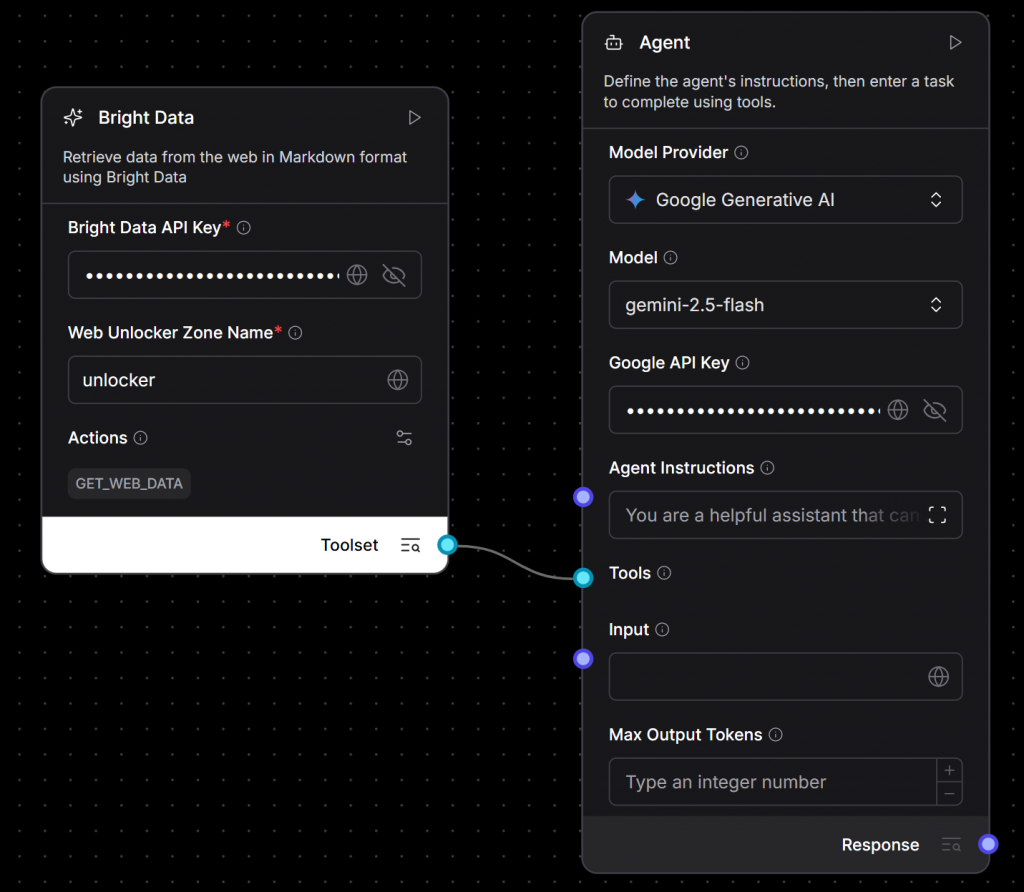
Ya está. El núcleo de su aplicación de IA ya está totalmente conectado. Acaba de crear un agente impulsado por Gemini que puede recuperar dinámicamente contenido web en directo utilizando la infraestructura de raspado de Bright Data.
Paso 7: Completar el flujo
Para que su flujo de IA sea completamente funcional, necesita un componente de entrada y otro de salida. Así que adelante, conecte un componente de chat de entrada a su agente de IA, y un componente de chat de salida para recibir su respuesta.
Después de eso, su flujo debe tener este aspecto:
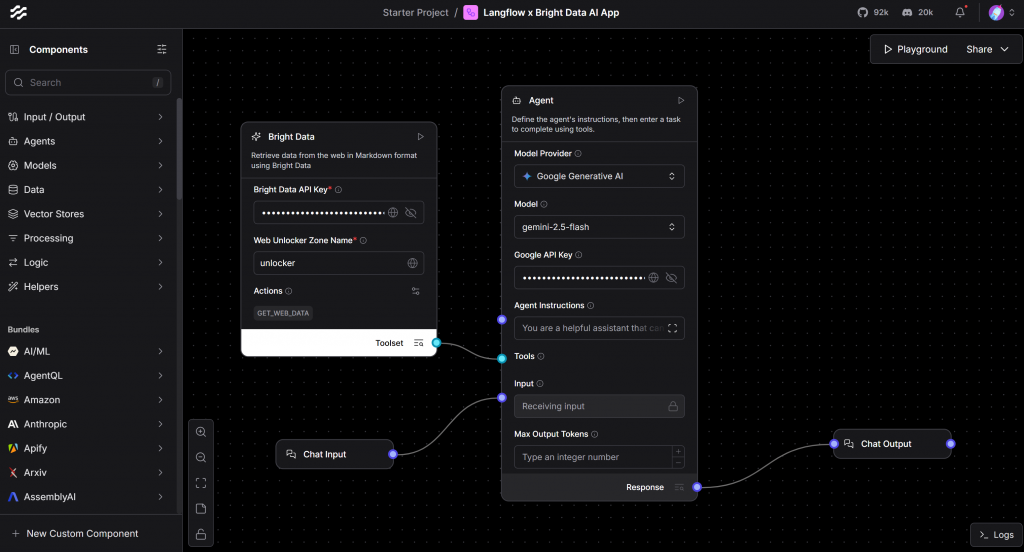
La configuración anterior le proporciona una interfaz similar a la de un chat para interactuar con su agente de IA.
Ya está. Su aplicación Langflow × Bright Data AI ya está completa y lista para usar.
Paso 8: Probar la aplicación de IA
Para lanzar tu aplicación de IA, haz clic en el botón “Playground” en la esquina superior derecha de la interfaz de Langflow:

Esto es lo que deberías ver:
Lo que obtienes es una experiencia al estilo ChatGPT, pero impulsada por tu propio agente de IA. Para comprobar que todo funciona, prueba a escribir algo como:
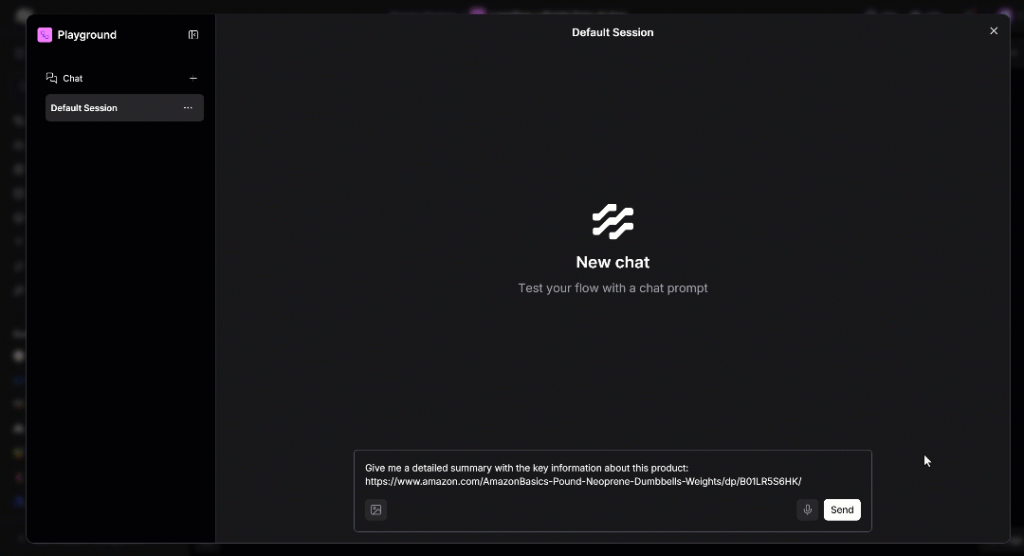
Give me a detailed summary with the key information about this product:
https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/A continuación se expone lo que ocurrirá entre bastidores:
- El mensaje pasa de Chat Input al componente AI Agent.
- El agente utiliza el LLM configurado (Gemini en este caso) y activa la herramienta necesaria procedente del componente Bright Data.
- El agente recibe el contenido web raspado, lo procesa y pasa la respuesta final a Chat Output (que corresponde a la respuesta que verá en el chat).
La pregunta anterior es una gran prueba porque Gemini por sí solo no puede raspar sitios como Amazon debido a sus protecciones anti-bot. Web Unlocker de Bright Data resuelve este problema evitando el CAPTCHA de Amazon, extrayendo datos de la página y proporcionándolos en formato Markdown listo para IA.
Ejecute el prompt y esto es lo que debería ver:
Para confirmar que el agente ha utilizado Bright Data, amplíe el desplegable “Acceder a web_get_data”:
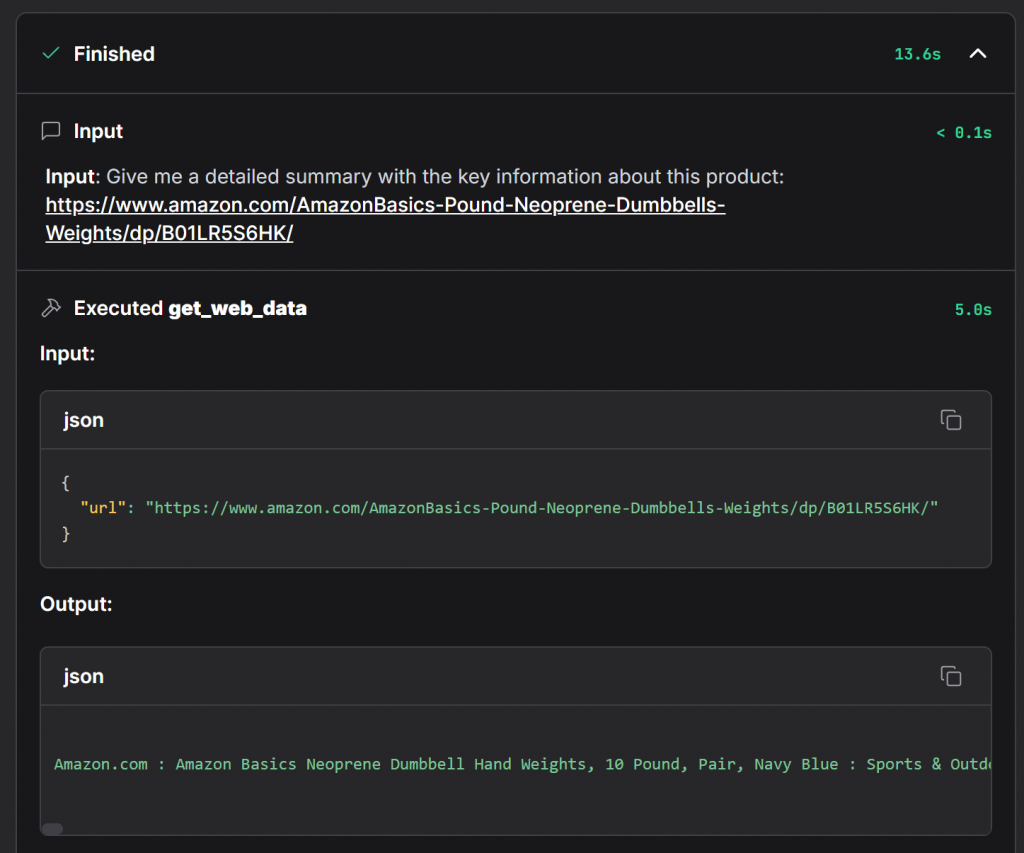
Esto muestra los detalles completos de la llamada a la función get_web_data, que es el método principal de su componente Bright Data. En ella puede comprobar que los datos se han recuperado correctamente de la página de productos de Amazon.
A continuación se muestra una captura de pantalla parcial de la salida real producida por el agente de IA:

Cada dato de este resumen generado por la IA es real y no alucinado, como puedes comprobar visitando la página original de Amazon:
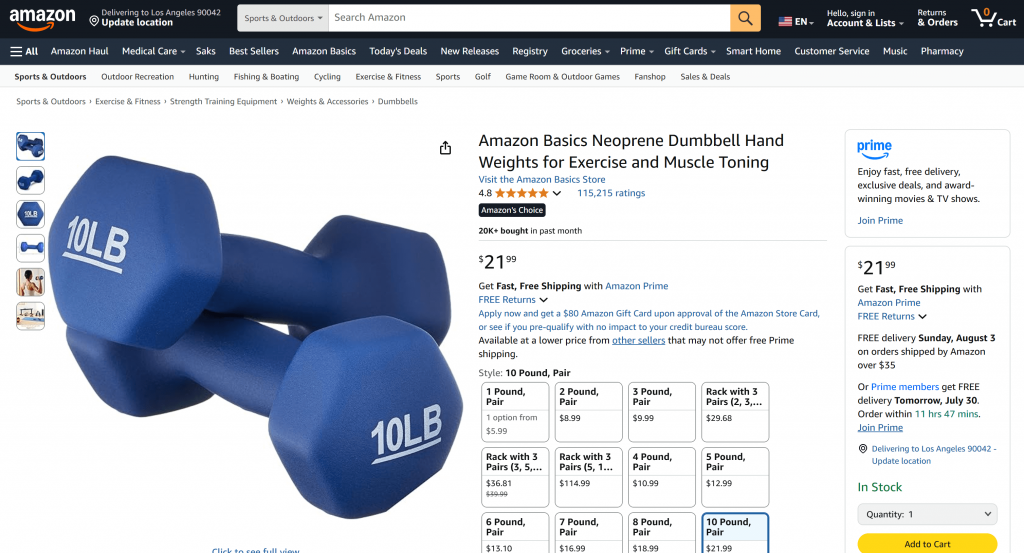
¡Et voilà! Acaba de crear y probar una aplicación de IA con acceso a datos web mediante Langflow y Bright Data.
Próximos pasos
Ahora que la integración está en marcha, estos son los siguientes pasos que puede dar:
- Despliegue su agente utilizando uno de los métodos admitidos oficialmente, ya sea en la nube o en su propio servidor.
- Amplíe la integración conectando otros productos de Bright Data, como las APIs de Web Scraper o las APIs de SERP. Para ello, solo tiene que modificar la lógica de su
BrightDataComponentpara llamar a diferentes API de Bright Data , tal y como se describe en la documentación oficial. - Recombine sus componentes para crear casos de uso más avanzados, como canalizaciones RAG, flujos de trabajo de datos, flujos de automatización de IA y mucho más.
- Conecte su agente de IA al servidor MCP de Bright Data para integrarlo con más de 50 herramientas de forma inmediata.
Conclusión
En este artículo, has aprendido a utilizar Langflow para construir un agente de IA con acceso a datos web. Esto fue posible gracias a una integración personalizada con las herramientas de Bright Data. Esta configuración le da a su LLM la capacidad de recuperar y procesar datos de prácticamente cualquier sitio web en tiempo real.
Ten en cuenta que lo que hemos presentado aquí es sólo un ejemplo básico. Si su objetivo es crear agentes más avanzados, necesitará herramientas para obtener, validar y transformar datos web en tiempo real en información optimizada para el consumo de IA. Eso es específicamente lo que puede encontrar en la infraestructura de IA de Bright Data.
Cree una cuenta gratuita en Bright Data y empiece a experimentar con nuestras herramientas de recuperación de datos preparadas para la IA.




