

Todos los datos son valiosos. Los datos agregados son uno de los tipos más buscados en la web. Google Finance contiene toneladas de datos agregados para diferentes mercados financieros. Estos datos son útiles para todo, desde bots de trading hasta informes generales.
¡Empecemos!
Requisitos previos
Si tienes los conocimientos adecuados, puedes extraer datos de Google Finance con relativa facilidad. Necesitarás lo siguiente para extraer datos de Google Finance.
- Python: en realidad, solo necesitas conocimientos básicos de Python. Debes saber cómo manejar variables, funciones y bucles.
- Python Requests: es el cliente HTTP estándar de Python. Se utiliza para realizar solicitudes GET, POST, PUT y DELETE en toda la web.
- BeautifulSoup: BeautifulSoup nos da acceso a un eficiente analizador HTML. Es lo que utilizamos para extraer nuestros datos.
Si aún no los tienes instalados, puedes instalar Requests y BeautifulSoup con los siguientes comandos.
Instalar Requests
pip install requests
Instalar BeautifulSoup
pip install beautifulsoup4
Qué extraer de Google Finance
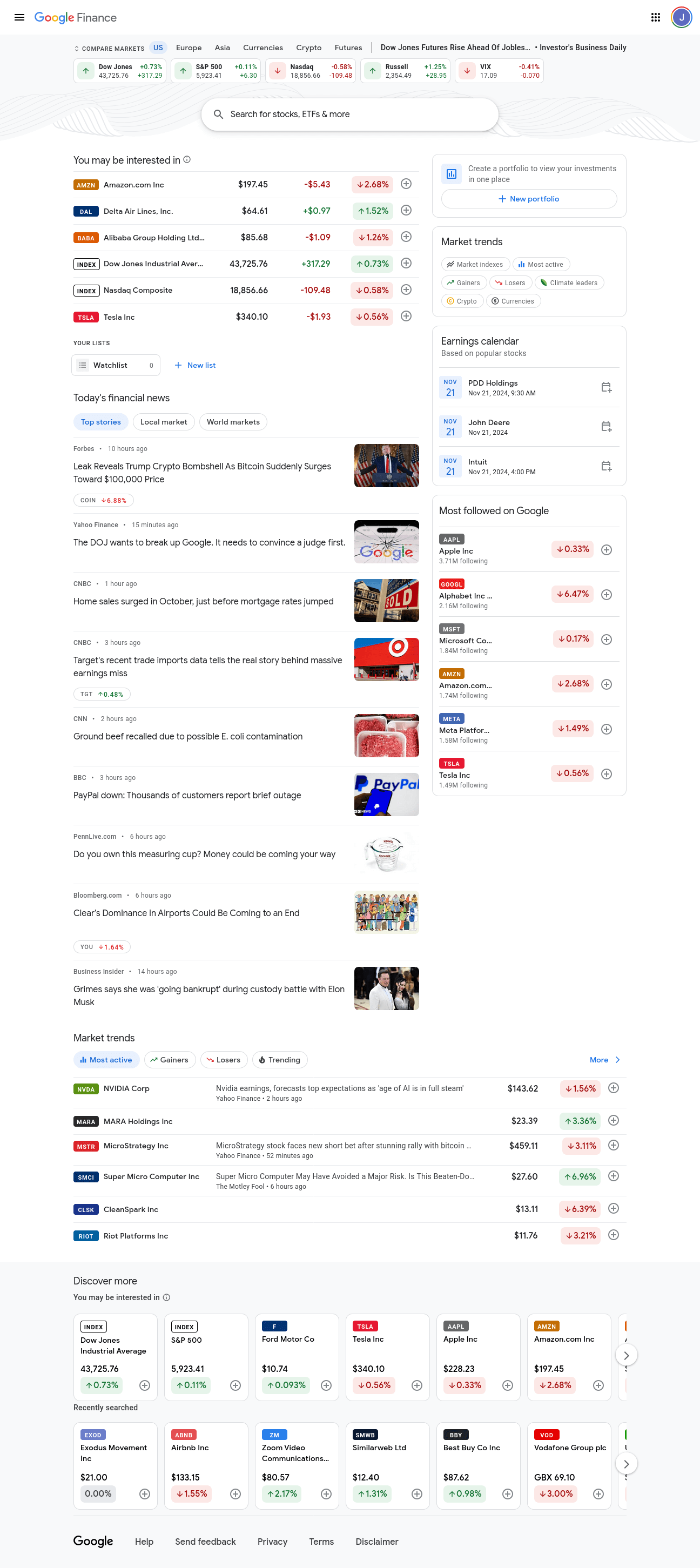
Aquí tienes una captura de la página principal de Google Finance. Contiene pequeños fragmentos de información sobre diferentes mercados. Nosotros queremos información detallada sobre múltiples mercados, no solo pequeños fragmentos.
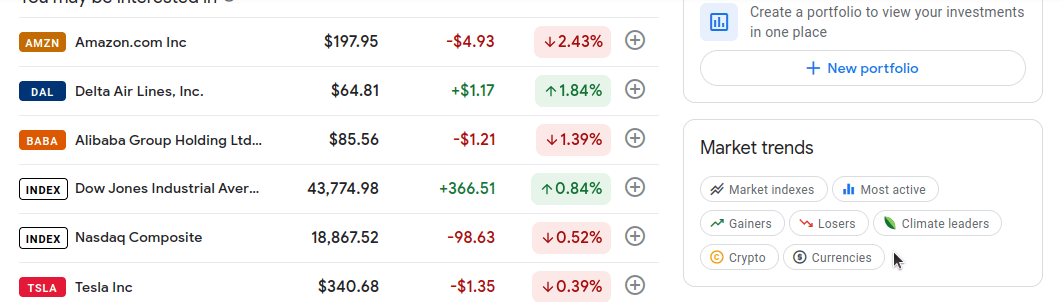
Si te desplazas un poco hacia abajo, verás una sección llamada «Tendencias del mercado» en la parte derecha de la página. Cada burbuja de esta sección enlaza con información detallada sobre un mercado específico. Nos interesan los siguientes mercados: Ganadores, Perdedores, Índices de mercado, Más activos y Criptomonedas.
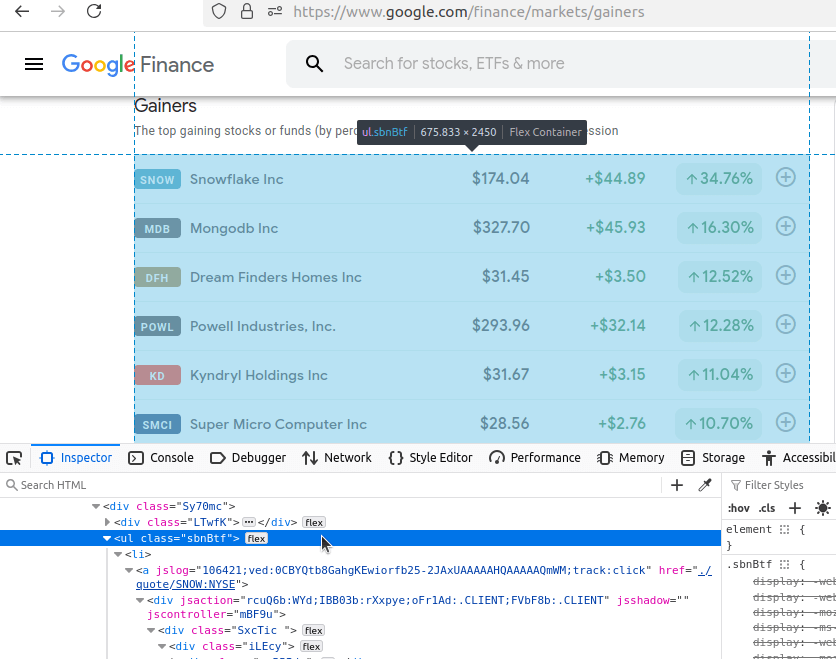
Ahora, haremos clic en cada una de estas páginas y las examinaremos. Comenzaremos con Ganancias. Como puede ver en nuestra barra de direcciones, nuestra URL es: https://www.google.com/finance/markets/gainers. Si observa la consola de desarrollador en la parte inferior, verá que todo el conjunto de datos está incrustado en una lista ul, una lista desorganizada.
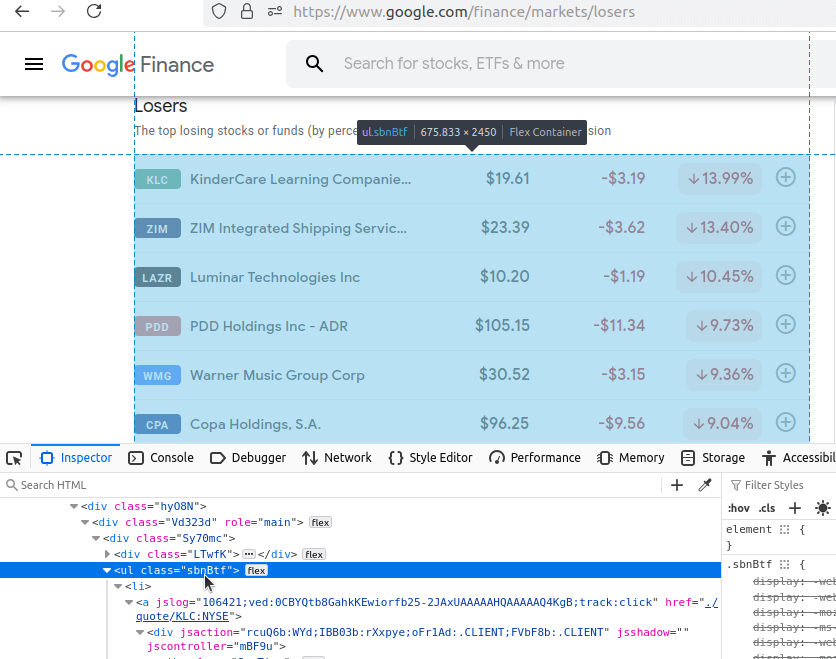
Ahora veremos Perdedores. Nuestra URL es: https://www.google.com/finance/markets/losers. Una vez más, nuestro conjunto de datos viene incrustado en una lista desorganizada.
Aquí tenemos la misma captura de la página de índices de mercado. Esta página es un poco especial. Contiene varios elementos ul, por lo que tendremos que adaptar nuestro código. La URL es: https://www.google.com/finance/markets/indexes. ¿Empieza a notar una tendencia?
A continuación se muestra la página Más activa. Una vez más, todos nuestros datos de destino están incrustados en un ul. Nuestra URL es: https://www.google.com/finance/markets/most-active.
Por último, echemos un vistazo a nuestra página Crypto. Como probablemente ya habrás adivinado, nuestros datos se encuentran dentro de un ul. Nuestra URL es: https://www.google.com/finance/markets/cryptocurrencies.
En cada una de estas páginas, nuestros datos objetivo vienen incrustados en una lista desorganizada. Para extraer nuestros datos, tendremos que encontrar estos elementos ul y extraer los elementos li (elementos de la lista) de cada uno de ellos. Eche un vistazo a nuestra URL base: https://www.google.com/finance/markets. Cada página proviene del punto final de los mercados. El formato de nuestra URL es: https://www.google.com/finance/markets/{NAME_OF_MARKET}. Tenemos 5 Conjuntos de datos y 5 URL, todos estructurados de la misma manera. Esto facilita el rastreo de una gran cantidad de datos utilizando solo unas pocas variables.
Extraer datos de Google Finance manualmente con Python
Si puede evitar que le bloqueen, puede extraer datos de Google Finance con Python Requests y BeautifulSoup. Necesitamos poder extraer nuestros datos. También deberíamos poder almacenarlos. Tenemos varios puntos finales, pero todos provienen de la misma URL base: https://google.com/finance/markets/. Cada vez que recuperamos una página, necesitamos encontrar los elementos ul y extraer todos los elementos li de cada lista.
Repasemos las funciones básicas que utilizaremos en nuestro script. Las llamamos write_to_csv() y scrape_page(). Estos nombres se explican por sí mismos.
Funciones individuales
Echemos un vistazo a write_to_csv().
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Se ha escrito correctamente {filename} en CSV...")
- Nuestra función necesita escribir una lista de objetos
dicten un CSV. Si nuestrosdatosno son unalista, los convertimos condata = [data]. - Cada archivo que generamos proviene de Google Finance, por lo que lo añadimos al crear el archivo
filename = f"google-finance-{filename}.csv". - Nuestro
modopredeterminado es«w»(escribir), pero si el archivo existe, cambiamos nuestromodoa«a»(añadir). csv.DictWriter(file, fieldnames=data[0].keys())inicializa nuestro escritor de archivos.- Si estamos en modo de escritura, el archivo aún no existe, por lo que creamos sus encabezados a partir del primer
diccionariode lalista. - Una vez que hayamos terminado con la configuración, añadimos nuestros datos al archivo con
writer.writerows(data).
Ahora echemos un vistazo a la función de scraping real, scrape_page(). Aquí es donde realmente ocurre la magia. Hacemos nuestra solicitud a nuestra URL formateada. A continuación, utilizamos BeautifulSoup para realizar el parseo del HTML que recibimos. Creamos una lista vacía llamada scraped_data para almacenar nuestros datos extraídos. Encontramos todos los elementos ul de la página. A continuación, extraemos los elementos li de cada ul que encontramos. Sin embargo, hay un problema. El texto de cada elemento de la lista está anidado dentro de varios elementos div. La matriz real que extraemos contiene un montón de repeticiones. Para solucionar esto, extraemos los elementos 3, 6, 8 y 11 y los añadimos (append()) a scraped_data.
Nuestra función scrape_page() se encuentra en el fragmento de código siguiente.
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
- Realizamos nuestra solicitud GET a este punto final:
requests.get(f"https://google.com/finance/markets/{endpoint}"). - Utilizamos el analizador HTML de BeuatifulSoup en nuestra
respuesta:soup = BeautifulSoup(response.text, "html.parser"). - Buscamos todas las tablas de la página:
tables = soup.find_all("ul"). scraped_data = []nos da una matriz para almacenar nuestros resultados.- Iteramos a través de cada una de las tablas que encontramos y hacemos lo siguiente:
- Buscamos todos los elementos de la lista:
table.find_all("li"). - Iteramos por cada uno de los elementos de la lista y encontramos sus elementos
div. Esto devuelve una lista llamadadivs. - Extraemos el texto de los elementos 3, 6, 8 y 11 de
divsy creamos undiccionarioa partir de él. - Añadimos el
diccionarioa nuestroscraped_data. - Las criptomonedas se cotizan por su par comercial, por lo que si estamos en el punto final de las criptomonedas, restablecemos nuestra
monedaan/a.
- Buscamos todos los elementos de la lista:
- Una vez que hayamos terminado el parseo de la página, guardamos nuestros
scrape_dataen un CSV:write_to_csv(scraped_data, endpoint). Pasamos nuestro punto final como nombre de archivo.
Rastrear datos de Google Finance
Podemos poner nuestras funciones de arriba en un script para que todo funcione. Además de esas funciones, añadimos una lista de puntos finales. También añadimos un main para mantener nuestro tiempo de ejecución. ¡No dudes en copiar y pegar el código siguiente y probarlo!
import requests
from bs4 import BeautifulSoup
import csv
from pathlib import Path
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Se ha escrito correctamente {filename} en CSV...")
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
if __name__ == "__main__":
for endpoint in endpoints:
print("---------------------")
scrape_page(endpoint)
Cuando ejecutamos el código anterior, obtenemos el siguiente resultado.
---------------------
Escribiendo en CSV...
Escribiendo datos en el archivo CSV...
Se ha escrito correctamente google-finance-gainers.csv en CSV...
---------------------
Escribiendo en CSV...
Escribiendo datos en el archivo CSV...
Se ha escrito correctamente google-finance-losers.csv en CSV...
---------------------
Escribiendo en CSV...
Escribiendo datos en el archivo CSV...
Se ha escrito correctamente google-finance-indexes.csv en CSV...
---------------------
Escribiendo en CSV...
Escribiendo datos en el archivo CSV...
Se ha escrito correctamente google-finance-most-active.csv en CSV...
---------------------
Escribiendo en CSV...
Escribiendo datos en el archivo CSV...
Se ha escrito correctamente google-finance-cryptocurrencies.csv en CSV...
Si ejecuta el script con VSCode, podrá ver cómo aparecen los archivos CSV a medida que el Scraper completa su trabajo. Están resaltados en la captura de pantalla siguiente.
También mostraremos una captura de pantalla de cómo se ve cada uno en ONLYOFFICE.
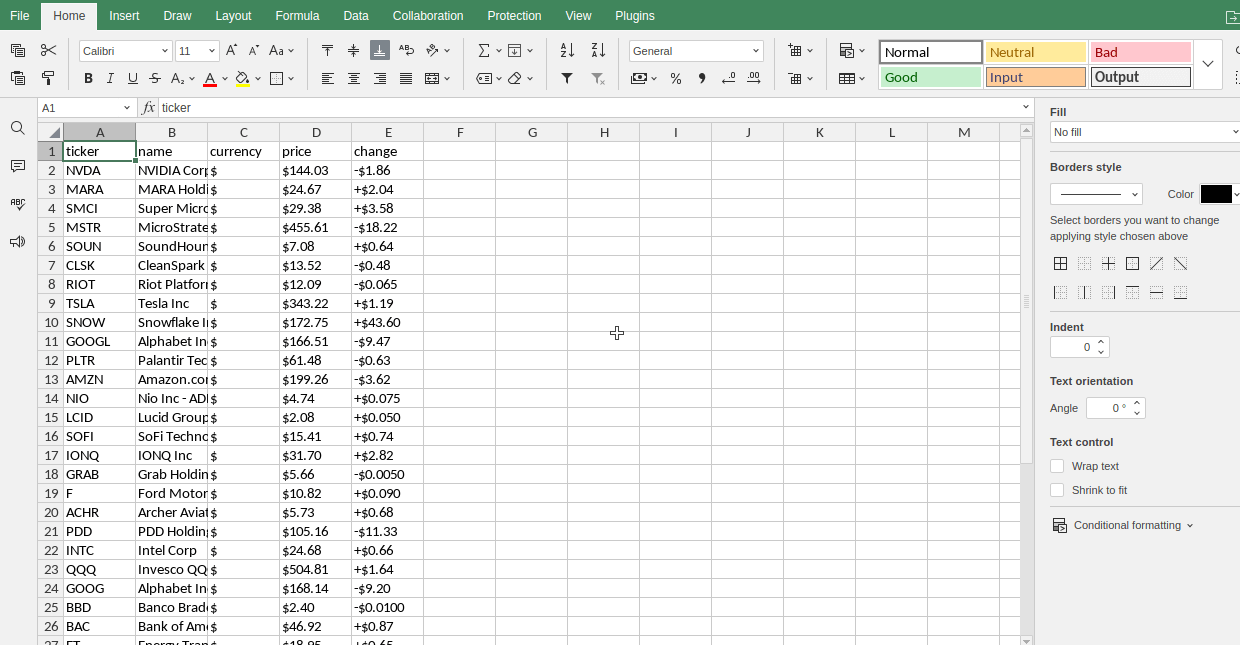
Más activos
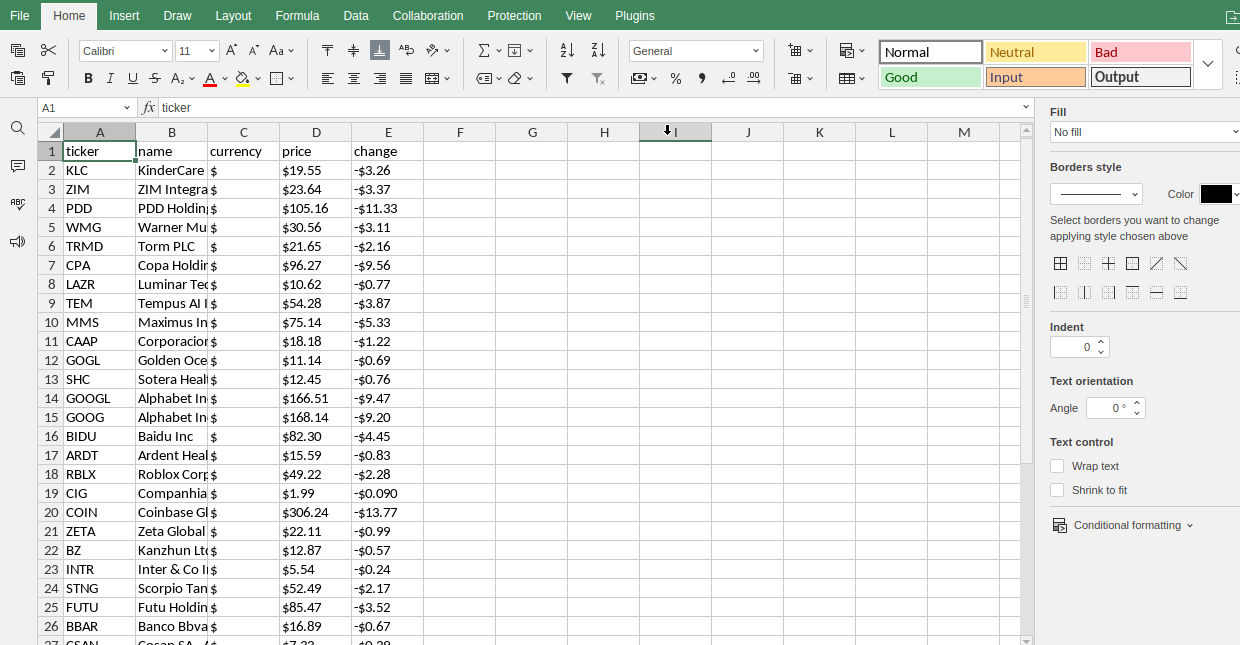
Pérdidas
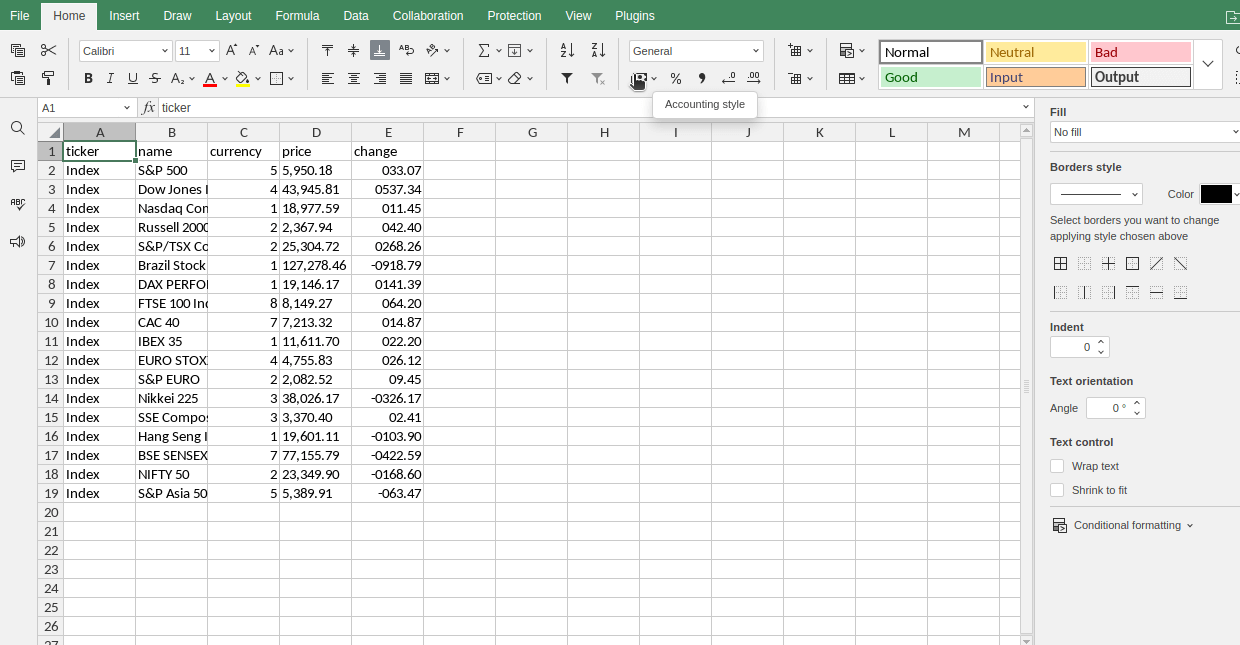
Índices
Ganadores
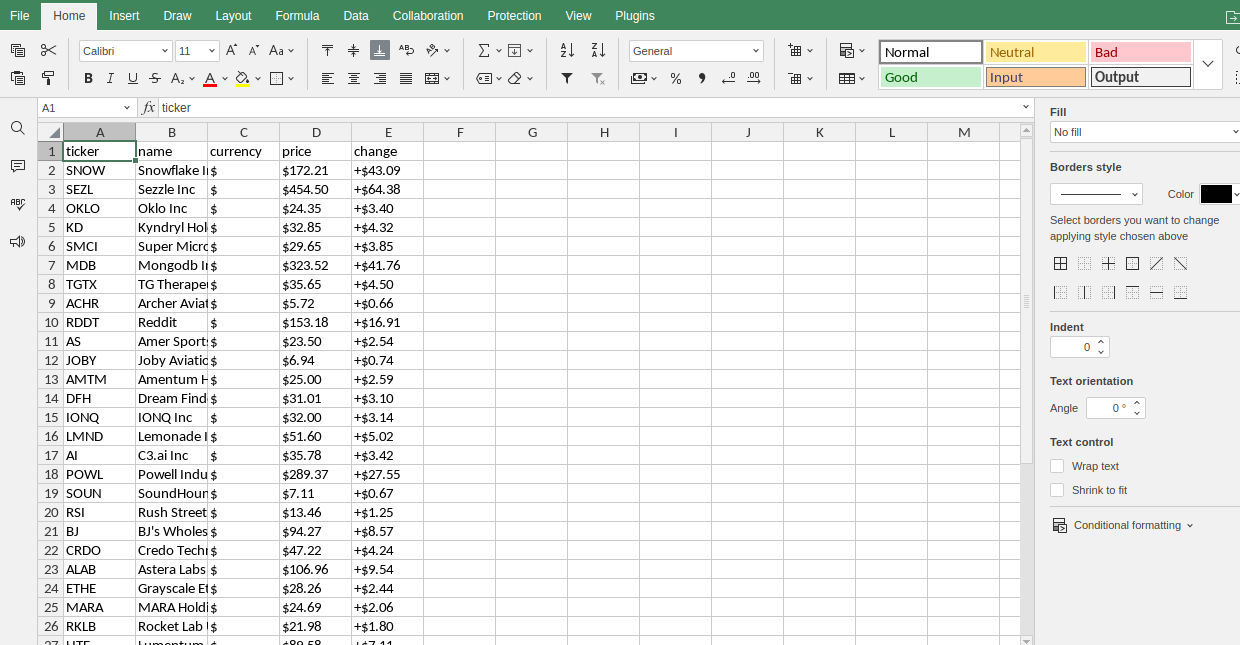
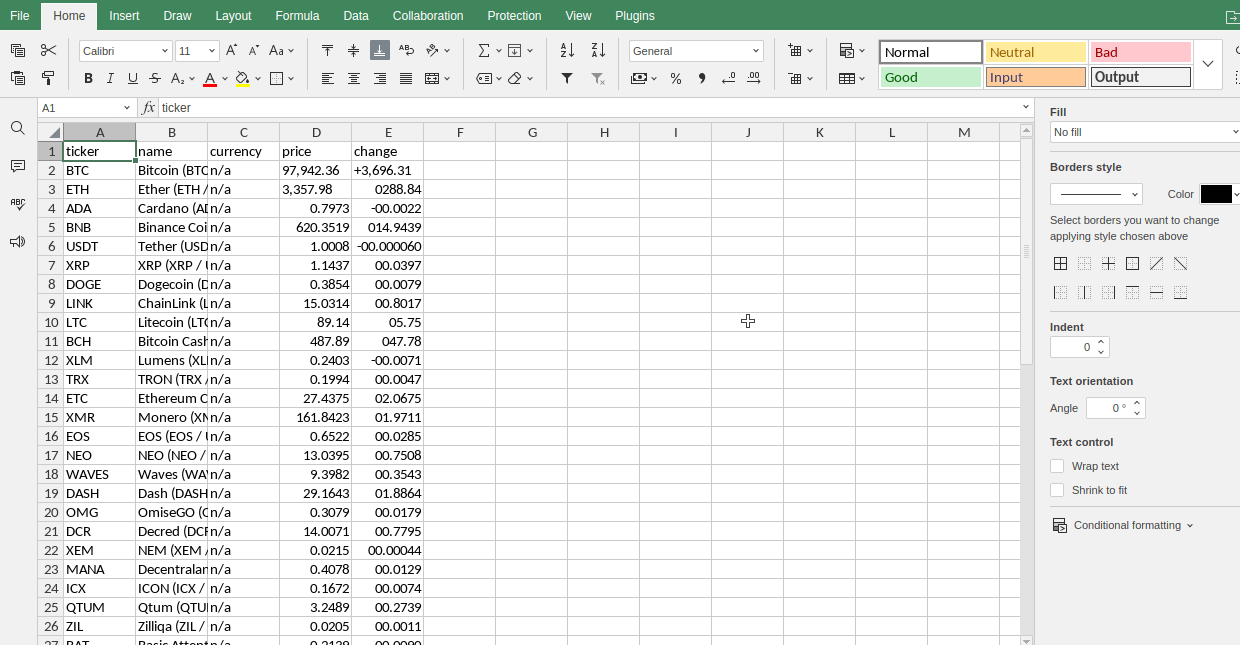
Criptomonedas
Técnicas avanzadas
Manejo de la paginación
Tradicionalmente, la paginación se gestiona utilizando números. En Google Finance, utilizamos nuestra matriz de puntos finales para gestionar la paginación. Cada elemento de nuestra lista de puntos finales representa una página individual que deseamos extraer. Echa un vistazo a esta lista de nuevo. Lee más aquí sobre cómo gestionar la paginación durante el Scraping web.
endpoints = ["ganadores", "perdedores", "índices", "más activos", "criptomonedas"]
Ahora, veamos cómo se utiliza. Con la paginación tradicional, tendrías un punto final o un parámetro de consulta al que pasarías un número. Sin embargo, con este Scraper, pasamos el punto final de cada página a nuestra URL base.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
Mitigar el bloqueo
Durante nuestras pruebas, no encontramos ningún problema de bloqueo. Sin embargo, este mundo no es perfecto y es posible que te encuentres con ellos en el futuro. Hay una variedad de tácticas que puedes utilizar para superar cualquier bloqueo con el que te puedas encontrar.
Agentes de usuario falsos
Cuando se realiza una solicitud a un sitio web (ya sea con un navegador o con Python Requests), el cliente HTTP envía una cadena de agente de usuario al servidor del sitio. Esta se utiliza para identificar la aplicación que realiza la solicitud. Para establecer un agente de usuario falso en Python, creamos una cadena de agente de usuario. A continuación, la añadimos a nuestros encabezados.
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
headers = {
"User-Agent": USER_AGENT
}
response = requests.get(f"https://google.com/finance/markets/{endpoint}", headers=headers)
Solicitudes temporizadas
Sincronizar nuestras solicitudes puede ser muy útil. Si algo solicita 200 páginas por minuto, es probable que no sea humano. Para superar la limitación de velocidad y parecer más humanos, podemos indicarle al Scraper que espere entre solicitudes. De esta forma, nuestra actividad de navegación parecerá mucho más normal. Primero, debes importar sleep desde time.
from time import sleep
A continuación, duerme durante un tiempo arbitrario entre solicitudes. Esto ralentizará tu Scraper y hará que parezca más humano.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
sleep(5)
Considera el uso de Bright Data
El scraping web puede suponer mucho trabajo. Bright Data es uno de los mejores proveedores de conjuntos de datos. Con nuestros conjuntos de datos, el scraping ya está hecho y usted ya tiene los informes. Lo único que tiene que hacer es descargarlos. Entendemos que el scraping web no es para todo el mundo y que algunas personas simplemente quieren obtener sus datos y utilizarlos.
No tenemos un conjunto de datos de Google Finance, pero sí tenemos uno de Yahoo Finance. Yahoo Finance ofrece una gama más amplia de datos financieros y puede satisfacer fácilmente sus necesidades de Google Finance. A continuación le mostramos cómo adquirir este conjunto de datos.
Crear una cuenta
En primer lugar, debe crear una cuenta. Diríjase a nuestra página de registro y cree una cuenta.
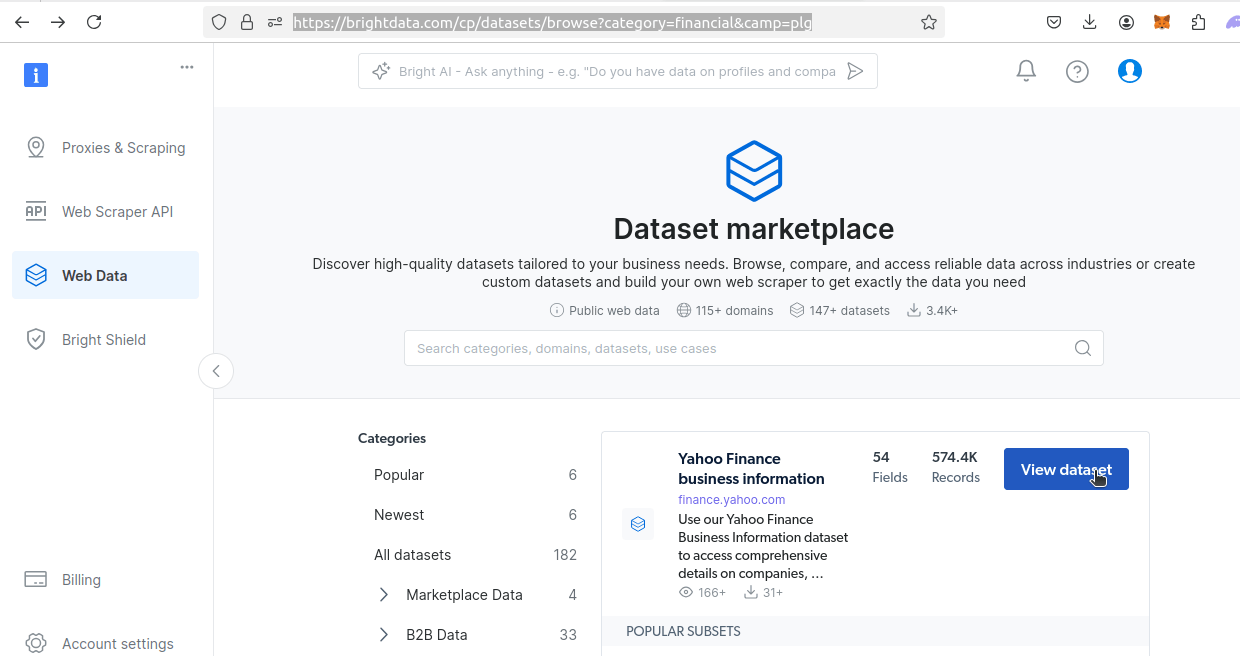
Descargar Conjuntos de datos de Bright Data
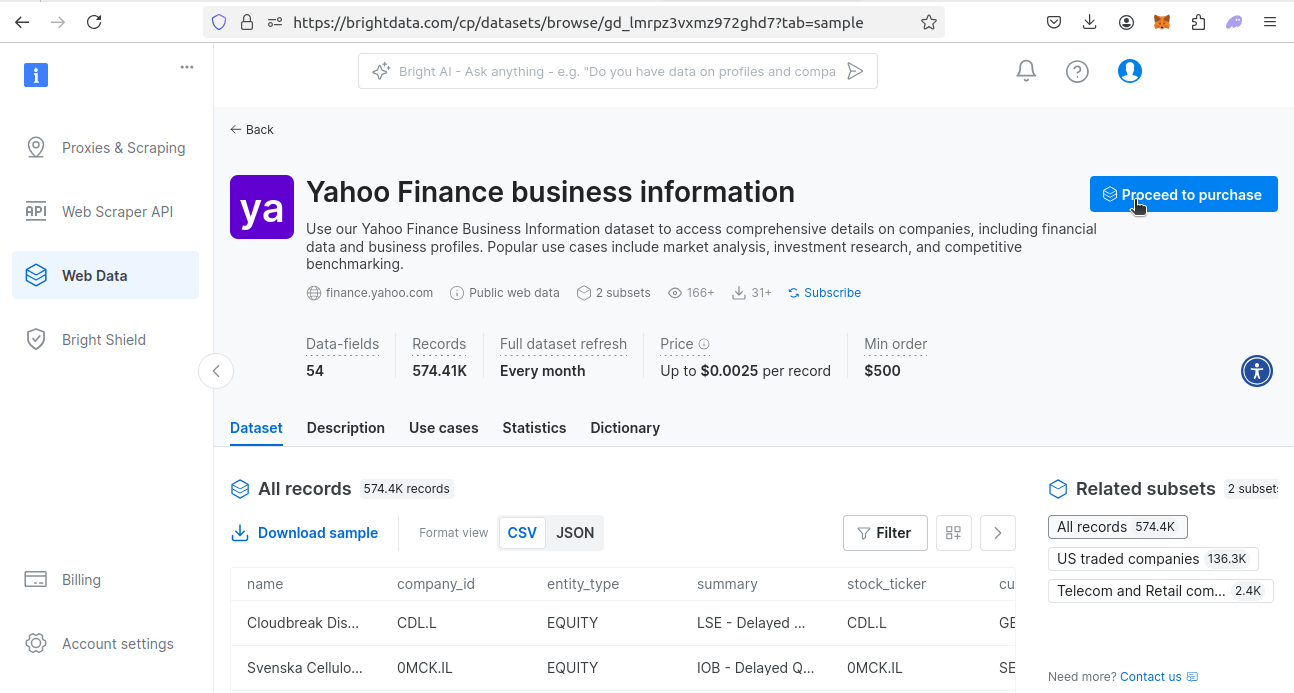
A continuación, vaya a nuestra página de Conjuntos de datos financieros. Busque el conjunto de datos de Yahoo Finance. Haga clic en el botón Ver conjunto de datos.
Una vez que esté viendo el conjunto de datos, tendrá varias opciones. Puede descargar un conjunto de datos de muestra o puede comprar el conjunto de datos. Cuesta 0,0025 $ por registro, con una compra mínima de 500 $. Si desea el conjunto de datos, haga clic en «Continuar con la compra» y siga el proceso de pago.
Con nuestros conjuntos de datos prefabricados, el scraping ya está hecho. ¡Solo tiene que obtener sus datos y seguir con su día!
Conclusión
¡Lo ha conseguido! Los datos agregados son una herramienta muy valiosa para personas de todo el mundo. Ahora ya sabe cómo extraerlos de Google Finance y también sabe cómo obtenerlos de nuestro conjunto de datos de Yahoo Finance. A estas alturas, ya debería saber cómo crear un Scraper básico utilizando Python Requests y BeautifulSoup. Debería saber cómo utilizar el método find_all() al realizar el parseo de objetos de página con BeautifulSoup.
También hemos repasado algunos de los métodos más avanzados, como el manejo de la paginación con puntos finales y las técnicas de mitigación de bloqueos. Aprovecha estos conocimientos y crea un Scraper o ahorra tiempo y trabajo descargando uno de nuestros Conjuntos de datos listos para usar.
Regístrate ahora y comienza hoy mismo tu prueba gratuita, que incluye muestras gratuitas de Conjuntos de datos.






