En este tutorial, aprenderás a crear un script de Python para raspar la sección «La gente también pregunta» de Google. Incluye las preguntas más frecuentes relacionadas con tu consulta de búsqueda y contiene información valiosa.
¡Vamos allá!
Entender la función «La gente también pregunta» de Google
«La gente también pregunta» (PAA) es una sección de las SERP (páginas de resultados de motores de búsqueda) de Google que incluye una lista dinámica de preguntas relacionadas con la consulta de búsqueda:

Esta sección te ayuda a explorar más a fondo los temas relacionados con tu consulta de búsqueda. Lanzada por primera vez alrededor de 2015, la sección de PAA aparece en los resultados de búsqueda como una serie de preguntas ampliables. Cuando se hace clic en una pregunta, se amplía para mostrar una respuesta breve que proviene de una página web relevante, junto con un enlace a la fuente:
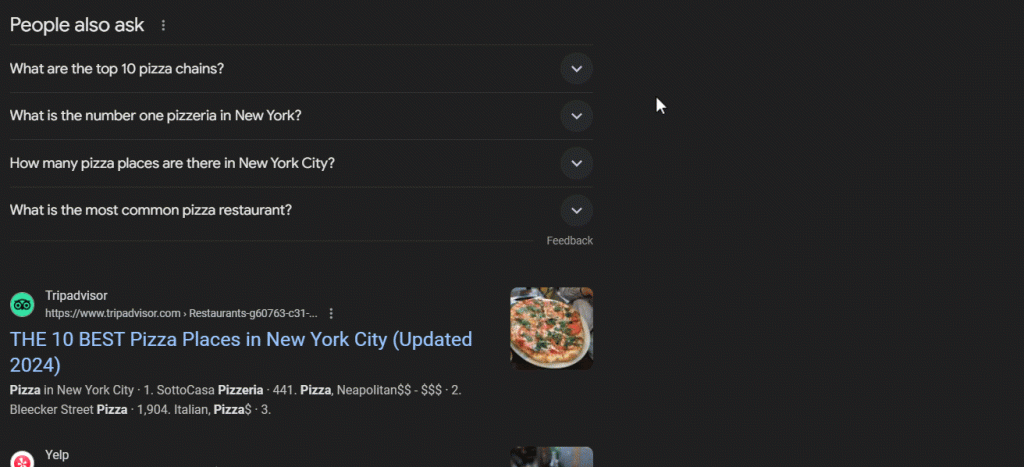
La sección «La gente también pregunta» se actualiza con frecuencia y se adapta en función de las búsquedas de los usuarios, ofreciendo información nueva y relevante. Las preguntas nuevas se cargan de forma dinámica a medida que se abren los menús desplegables.
Cómo raspar «La gente también pregunta» de Google: guía paso a paso
Sigue esta sección guiada para aprender a crear un script de Python para raspar la sección «La gente también pregunta» de una SERP de Google.
El objetivo final es recuperar los datos contenidos en cada pregunta de la sección «La gente también pregunta» de la página. Si, por el contrario, te interesa el raspado de datos de Google, sigue nuestro tutorial sobre el raspado de datos de las SERP.
Paso 1: configuración del proyecto
Antes de empezar, comprueba que tienes Python 3 instalado en tu ordenador. Si no lo tienes, descárgalo, inicia el ejecutable y sigue las instrucciones del asistente de instalación.
A continuación, inicia un proyecto de Python con un entorno virtual usando los siguientes comandos:
mkdir people-also-ask-scraper
cd people-also-ask-scraper
python -m venv env
El directorio people-also-ask-scraper representa la carpeta del proyecto de tu raspador de PAA de Python.
Carga la carpeta del proyecto en tu IDE de Python favorito. PyCharm Community Edition o Visual Studio Code con la extensión de Python son dos grandes opciones.
En la carpeta del proyecto, crea un archivo scraper.py. Ahora es un script en blanco, pero pronto contendrá la lógica del raspado:

En la terminal del IDE, activa el entorno virtual. En Linux o macOS, ejecuta este comando:
./env/bin/activate
Como alternativa, en Windows, ejecuta:
env/Scripts/activate
Genial, ¡ahora tienes un entorno Python para tu raspador!
Paso 2: instala Selenium
Google es una plataforma que requiere la interacción del usuario. Además, falsificar una URL de búsqueda de Google válida puede resultar difícil. Por tanto, la mejor manera de trabajar con el motor de búsqueda es desde un navegador.
Es decir, para raspar la sección «La gente también pregunta», necesitas una herramienta de automatización del navegador. Si no conoces este concepto, las herramientas de automatización de navegadores te permiten renderizar e interactuar con páginas web dentro de un navegador controlable. ¡Una de las mejores opciones en Python es Selenium!
Instala Selenium ejecutando el siguiente comando en un entorno virtual de Python activado:
pip install selenium
El paquete pip selenium se añadirá a las dependencias de tu proyecto. Puede llevar un tiempo, así que ten paciencia.
Para obtener más información sobre cómo usar esta herramienta, lee nuestra guía sobre el raspado web con Selenium.
Genial, ¡ya tienes todo lo que necesitas para empezar a raspar páginas de Google!
Paso 3: navega a la página de inicio de Google
Importa Selenium en scraper.py e inicializa un objeto WebDriver para controlar una instancia de Chrome en modo «headless»:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
El fragmento anterior crea una instancia de Chrome WebDriver, el objeto para controlar programáticamente una ventana de Chrome. La opción --«headless» configura Chrome para que se ejecute en modo «headless». Para fines de depuración, comenta esa línea para que puedas observar las acciones del script automatizado en tiempo real.
Luego, usa el método get() para conectarte a la página de inicio de Google:
driver.get("https://google.com/")
No olvides liberar los recursos del controlador al final del script:
driver.quit()
Ponlo todo junto y obtendrás:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# scraping logic...
# close the browser and free up the resources
driver.quit()
Fantástico, ¡ya puedes crear sitios web dinámicos!
Paso 4: gestiona el cuadro de diálogo sobre cookies del RGPD
Nota: si no te encuentras en la UE (Unión Europea), puedes omitir este paso.
Ejecuta el script scraper.py en modo «headed». Se abrirá brevemente una ventana del navegador Chrome en la que se mostrará una página de Google antes de que el comando quit() la cierre. Si te encuentras en la UE, esto es lo que verás:
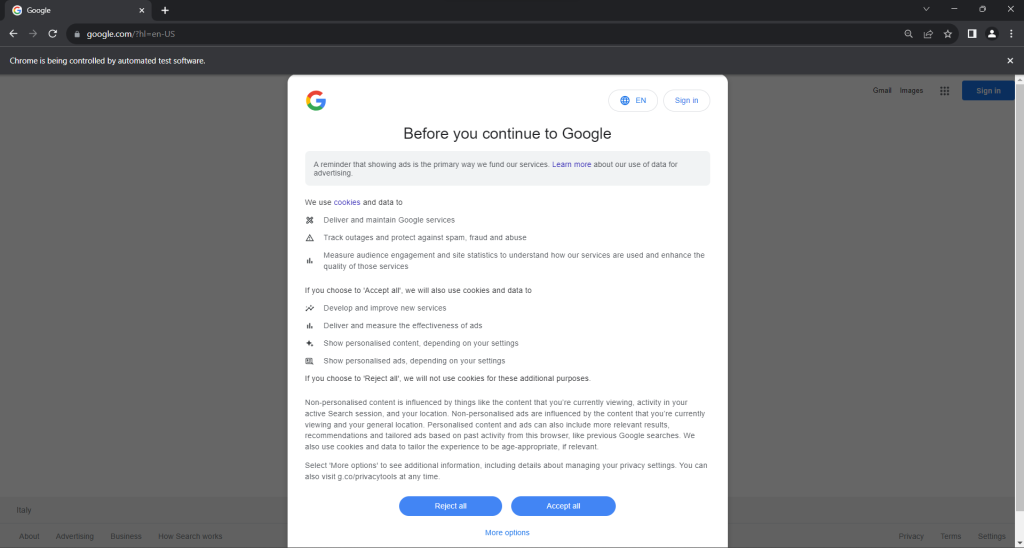
El mensaje «Chrome is being controlled by automated test software» («Chrome está siendo controlado por un software de pruebas automatizado») asegura que Selenium está controlando Chrome como se desea.
A los usuarios de la UE se les muestra un cuadro de diálogo de política de cookies a efectos del RGPD. Si es tu caso, debes solucionarlo si quieres interactuar con la página subyacente. De lo contrario, puedes pasar al paso 5.
Abre una página de Google en modo incógnito e inspecciona el cuadro de diálogo de cookies del RGPD. Haz clic con el botón derecho sobre él y elige la opción «Inspeccionar»:
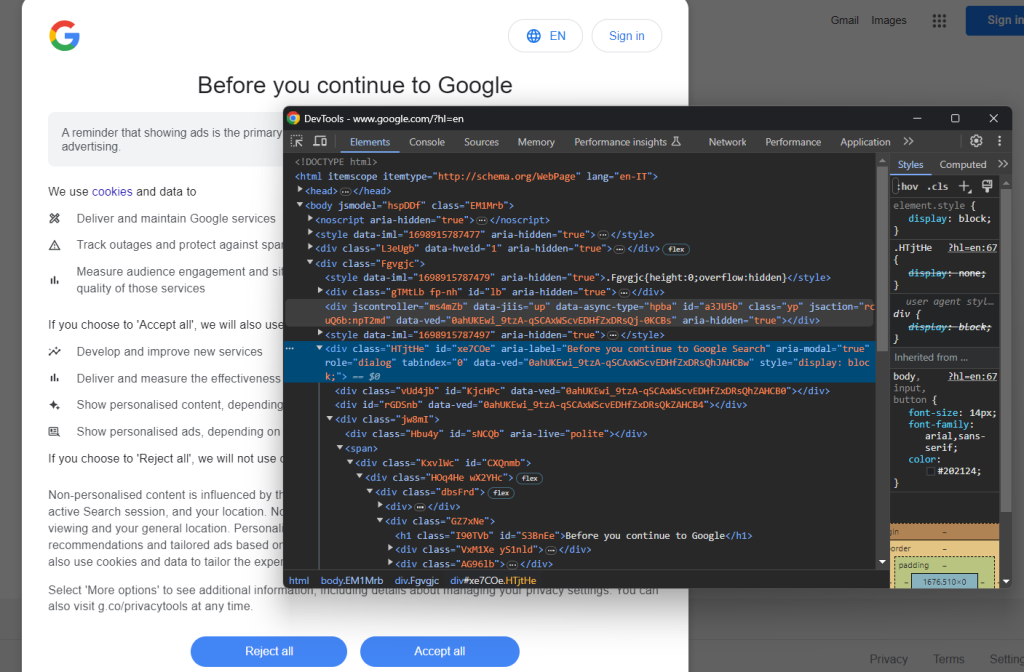
Puedes localizar el elemento HTML del cuadro de diálogo con:
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
find_element() es un método proporcionado por Selenium para localizar elementos HTML en la página mediante diferentes estrategias. En este caso, utilizamos un selector CSS.
No olvides importar By de la siguiente manera:
from selenium.webdriver.common.by import By
Ahora, concéntrate en el botón «Aceptar todo»:
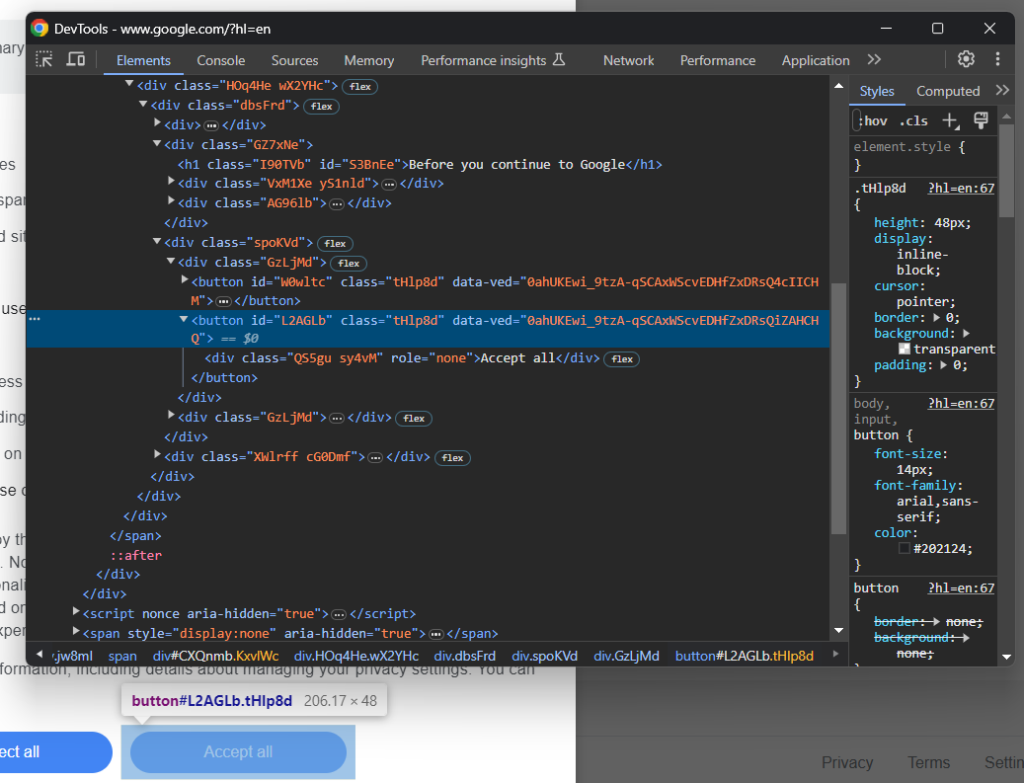
Como verás, no hay una manera fácil de seleccionarlo, ya que su clase CSS parece generarse aleatoriamente. Por tanto, puedes recuperarlo mediante una expresión XPath que apunte a su contenido:
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
Esta instrucción localizará el primer botón del cuadro de diálogo cuyo texto contenga la cadena «Aceptar». Para obtener más información, lee nuestra guía sobre selector de XPath frente a CSS.
A continuación se muestra cómo encaja todo para gestionar el diálogo opcional de cookies de Google:
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
La instrucción click() hace clic en el botón «Aceptar todo» para cerrar el cuadro de diálogo y permitir la interacción del usuario. Si el cuadro de diálogo de la política de cookies no está presente, se lanzará en su lugar una NoSuchElementException. El script lo capturará y continuará.
Recuerda importar la NoSuchElementException:
from selenium.common import NoSuchElementException
¡Excelente! Ya puedes acceder a la página con la sección «La gente también pregunta».
Paso 5: envía el formulario de búsqueda
Ve a la página de inicio de Google de tu navegador e inspecciona el formulario de búsqueda. Haz clic con el botón derecho sobre él y selecciona la opción «Inspeccionar»:
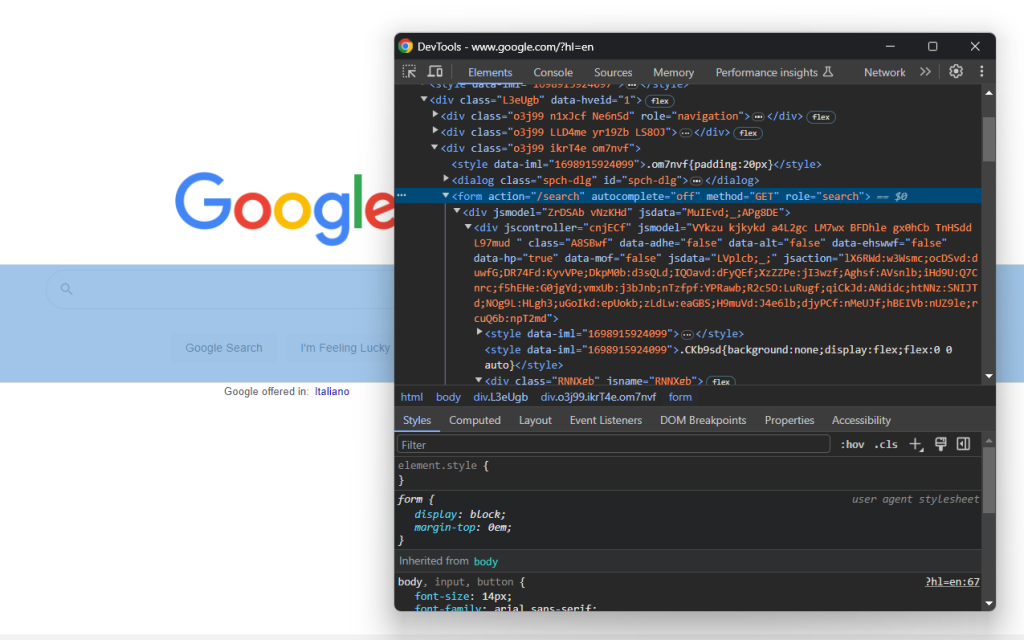
Este elemento no tiene clase CSS, pero puedes seleccionarlo mediante su atributo action:
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
Si has omitido el paso 4, importa By con:
from selenium.webdriver.common.by import By
Amplía el código HTML del formulario y echa un vistazo al área de texto de búsqueda:
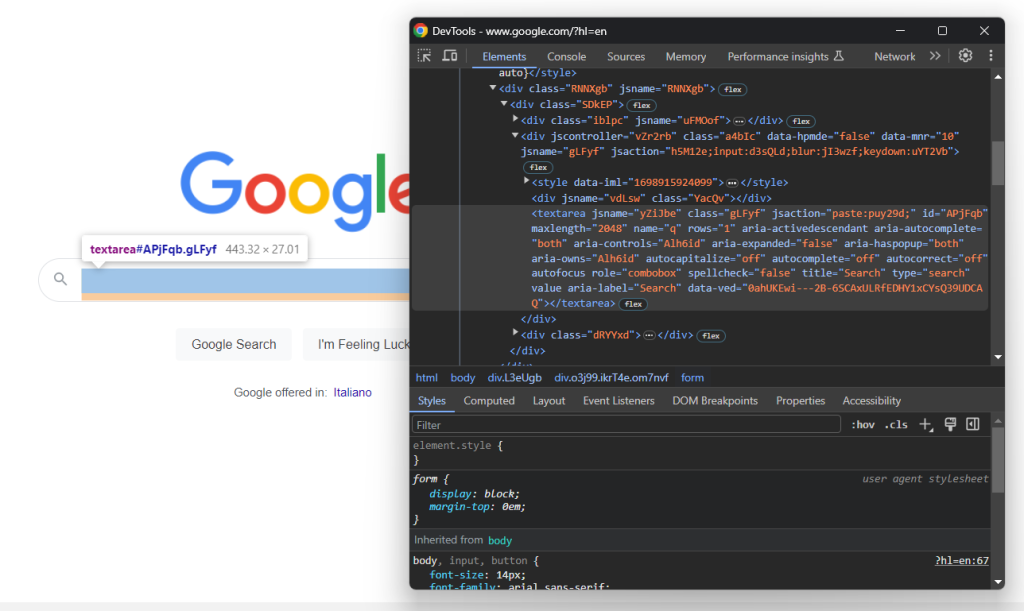
La clase CSS de este nodo parece generarse aleatoriamente. Por tanto, selecciónalo a través de su atributo aria-label. Luego, usa el método send_keys() para escribir la consulta de búsqueda de destino:
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
En este ejemplo, la consulta de búsqueda es «Bright Data», pero cualquier otra búsqueda es correcta.
Envía el formulario para activar un cambio de página:
search_form.submit()
¡Fantástico! El navegador controlado ahora se redirigirá a la página de Google que contiene la sección «La gente también pregunta».
Si ejecutas el script en modo «headed», se mostrará esto antes de que se cierre el navegador:
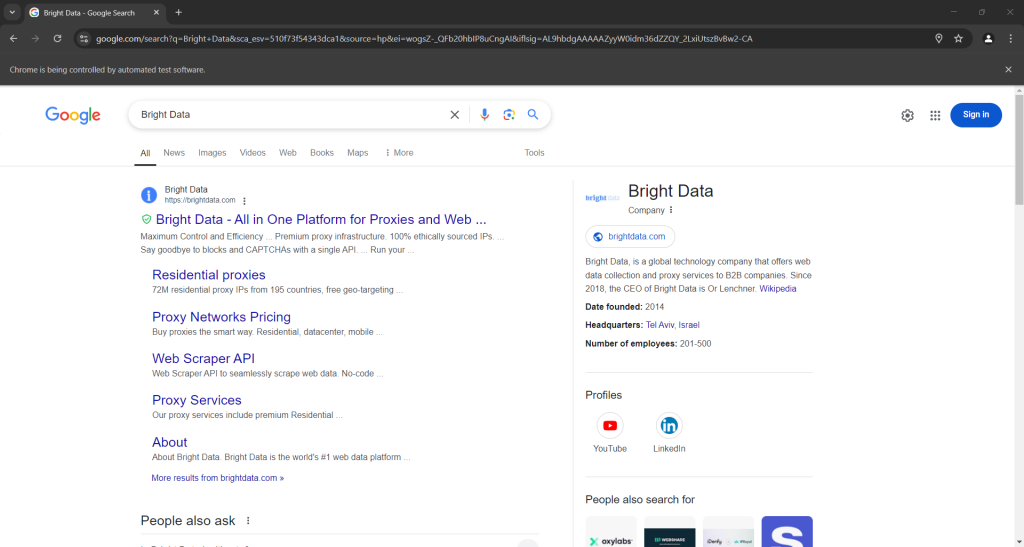
Observa la sección «La gente también pregunta» en la parte inferior de la captura de pantalla anterior.
Paso 6: selecciona el nodo «La gente también pregunta»
Inspecciona el elemento HTML «La gente también pregunta»:
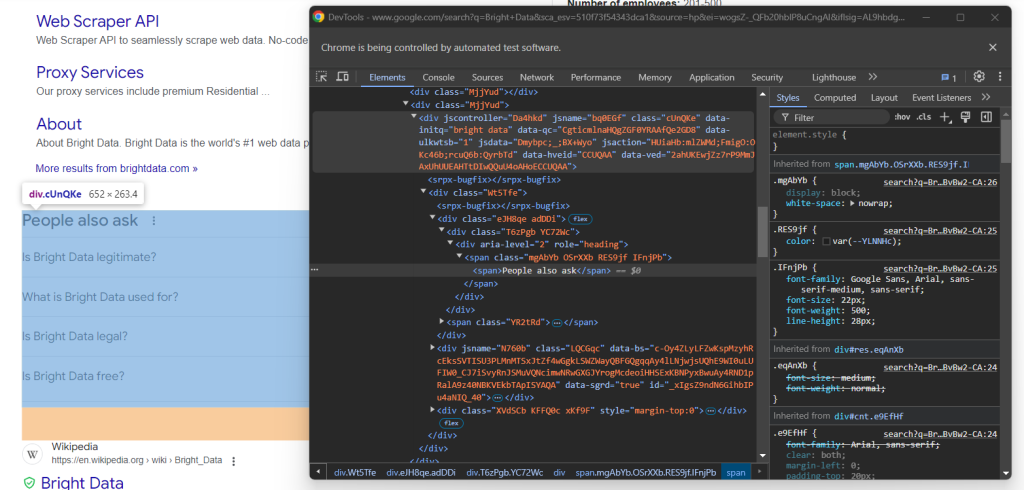
De nuevo, no hay una manera fácil de seleccionarlo. Esta vez, lo que puedes hacer es recuperar el <div>elemento con los atributos jscontroller, jsnamey jsaction que contiene un div con role=heading con el texto «La gente también pregunta»:
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
WebDriverWait es una clase especial de Selenium que detiene el script hasta que se cumpla una condición específica en la página. Arriba, espera hasta 5 segundos para que aparezca el elemento HTML deseado. Esta acción es necesaria para que la página se cargue por completo después de enviar el formulario.
La expresión XPath utilizada en presence_of_element_located() es compleja, pero describe con precisión los criterios necesarios para seleccionar el elemento «La gente también pregunta».
No olvides añadir las importaciones necesarias:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
¡Es hora de raspar los datos de la sección «La gente también pregunta» de Google!
Paso 7: raspa la sección «La gente también pregunta»
En primer lugar, inicializa una estructura de datos donde almacenar los datos raspados:
people_also_ask_questions = []
Debe ser una matriz, ya que la sección «La gente también pregunta» contiene varias preguntas.
Ahora, inspecciona el menú desplegable de la primera pregunta del nodo «La gente también pregunta»:
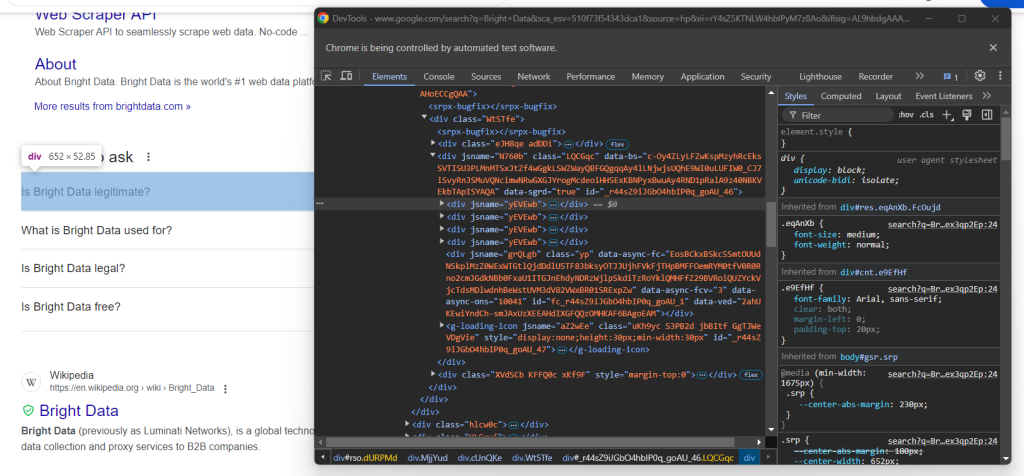
Aquí puedes ver que los elementos de interés son los elementos secundarios del data-sgrd="true"
jsname. Google usa los dos últimos elementos hijos como marcadores de posición y los rellena dinámicamente al abrir los desplegables.Selecciona los menús desplegables de preguntas con la siguiente lógica:
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# scraping logic...
Haz clic en el elemento para expandirlo:
child.click()
Luego, concéntrate en el contenido de los elementos de la pregunta:
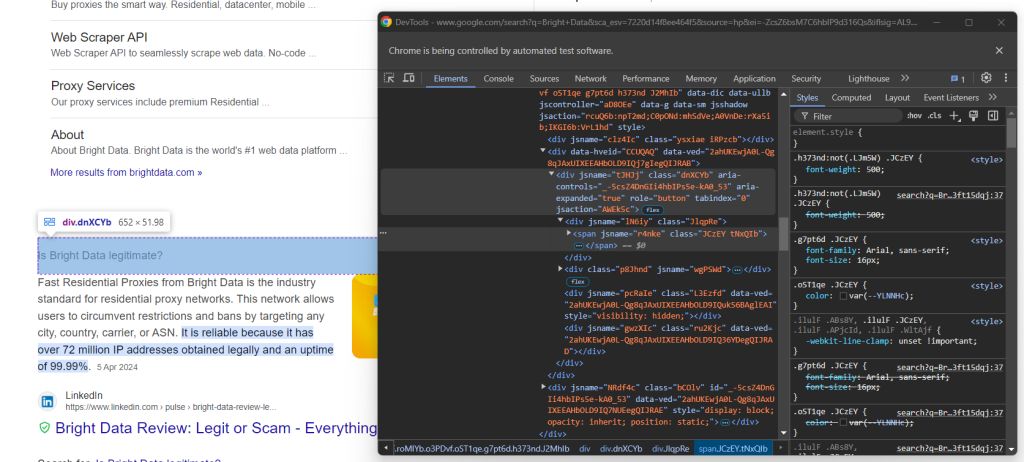
Ten en cuenta que la pregunta está contenida en el <span> dentro del nodo aria-expanded="true". Ráspalo así:
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
Luego, inspecciona el elemento de respuesta:
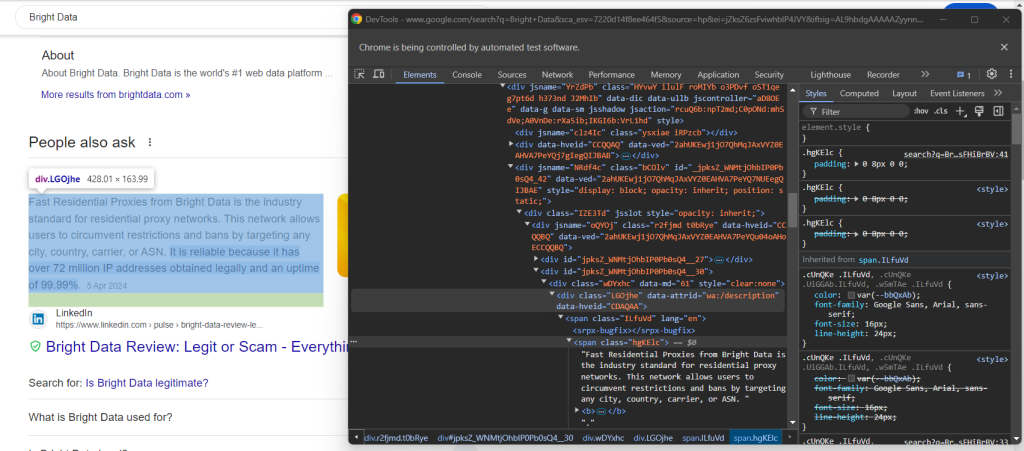
Observa cómo puedes recuperarlo recopilando el texto del nodo <span> con el atributo lang dentro del elemento data-attrid="wa:/description":
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
A continuación, inspecciona la imagen opcional del cuadro de respuesta:
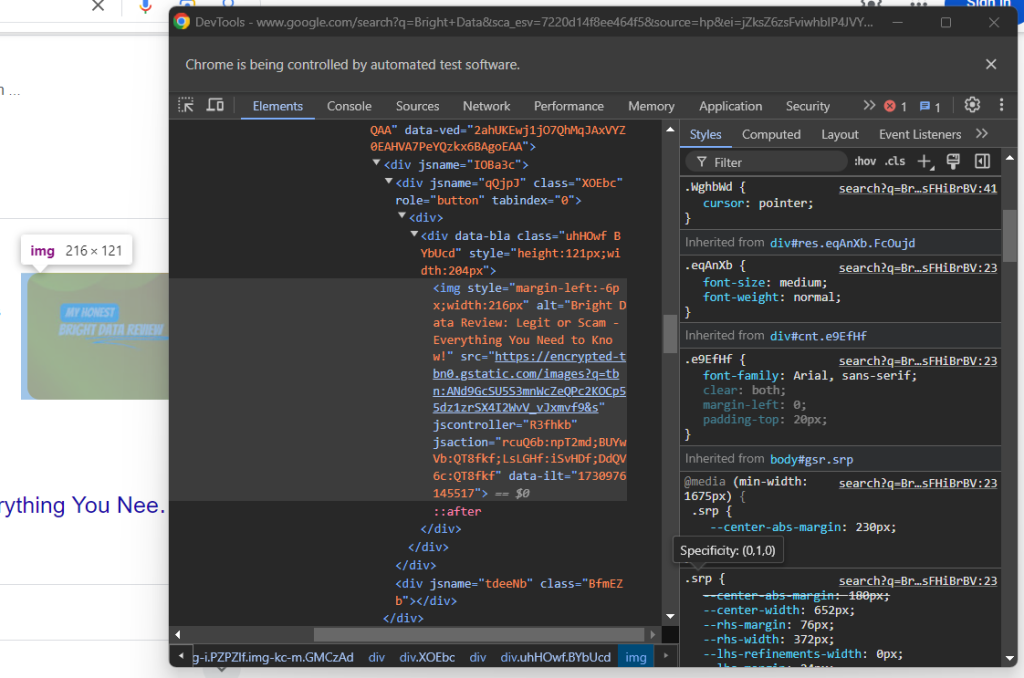
Puedes obtener su URL accediendo al atributo src del elemento <img> con el atributo data-ilt:
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
Como el elemento image es opcional, debes envolver el código anterior con un bloque try... except. Si el nodo no está presente en la pregunta actual, find_element() generará una NoSuchElementException. En ese caso, el código lo interceptará y seguirá adelante.
Si has omitido el paso 4, importa la excepción:
from selenium.common import NoSuchElementException
Por último, inspecciona la sección de origen:
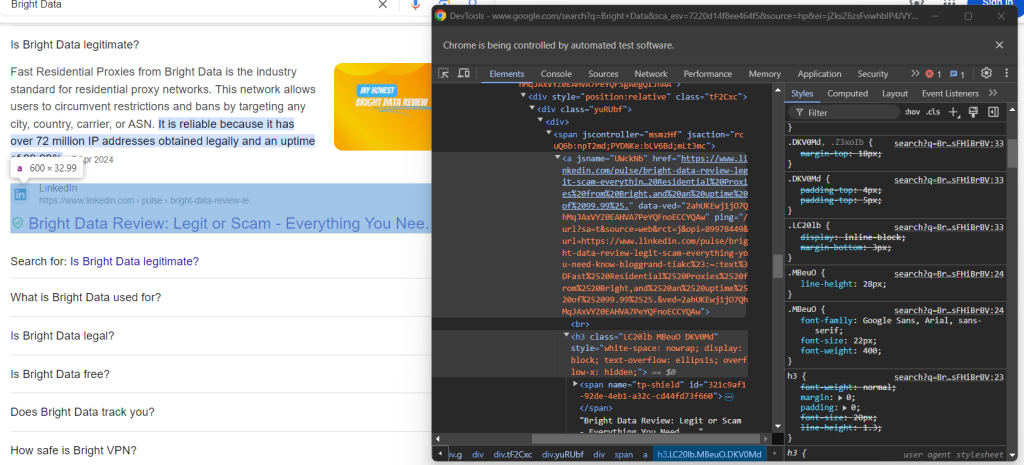
Puede obtener la URL de la fuente seleccionando el elemento padre <a> del elemento <h3>:
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
Utiliza los datos raspados para rellenar un nuevo objeto y añadirlo a la matriz people_also_ask_questions:
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
¡Así se hace! Acabas de raspar la sección «La gente también pregunta» de una página de Google.
Paso 8: exporta los datos raspados a CSV
Si imprimes people_also_ask_questions, verás el siguiente resultado:
[{'title': 'Is Bright Data legitimate?', 'description': 'Fast Residential Proxies from Bright Data is the industry standard for residential proxy networks. This network allows users to circumvent restrictions and bans by targeting any city, country, carrier, or ASN. It is reliable because it has 400M+ monthly IP addresses obtained legally and an uptime of 99.99%.', 'image': 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSU5S3mnWcZeQPc2KOCp55dz1zrSX4I2WvV_vJxmvf9&s', 'source': 'https://www.linkedin.com/pulse/bright-data-review-legit-scam-everything-you-need-know-bloggrand-tiakc#:~:text=Fast%20Residential%20Proxies%20from%20Bright,and%20an%20uptime%20of%2099.99%25.'}, {'title': 'What is Bright Data used for?', 'description': "Bright Data is the world's #1 web data platform, supporting the public data needs of over 22,000 organizations in nearly every industry. Using our solutions, organizations research, monitor, and analyze web data to make better decisions.", 'image': None, 'source': "https://brightdata.com/about#:~:text=Bright%20Data%20is%20the%20world's,data%20to%20make%20better%20decisions."}, {'title': 'Is Bright Data legal?', 'description': "Bright Data's platform, technology, and network (collectively, “Services”) are meant for legitimate and legal purposes only and are subject to the Bright Data Master Service Agreement.", 'image': None, 'source': "https://brightdata.com/acceptable-use-policy#:~:text=Bright%20Data's%20platform%2C%20technology%2C%20and,Bright%20Data%20Master%20Service%20Agreement."}, {'title': 'Is Bright Data free?', 'description': 'Bright Data offers four free proxy solutions to meet various needs: Anonymous Proxies: These top-performing anonymous proxies let you access websites anonymously, routing traffic through a vast Residential IP Network of 400M+ monthly IPs, concealing your true location.', 'image': None, 'source': 'https://brightdata.com/solutions/free-proxies#:~:text=Bright%20Data%20offers%20four%20free,IPs%2C%20concealing%20your%20true%20location.'}]
Claro, es genial, pero sería mucho mejor si estuviera en un formato que puedas compartir fácilmente con otros miembros del equipo. Por tanto, ¡exporta people_also_ask_questions a un archivo CSV!
Importa el paquete csv de la biblioteca estándar de Python:
import csv
A continuación, úsalo para rellenar un archivo CSV de salida con tus datos de SERP:
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
¡Por fin! Tu script de raspado «La gente también pregunta» está completo.
Paso 9: júntalo todo
Tu script final de scraper.py debe contener el siguiente código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# deal with the optional Google cookie GDPR dialog
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
# select the search form
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# select the textarea and fill it out
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
# submit the form to perform a Google search
search_form.submit()
# wait up to 5 seconds for the "People also ask" section
# to be on the page after page change
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
# where to store the scraped data
people_also_ask_questions = []
# select the question dropdowns and iterate over them
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# expand the element
child.click()
# scraping logic
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
# populate the array with the scraped data
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
# export the scraped data to a CSV file
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
# close the browser and free up the resources
driver.quit()
En 100 líneas de código, ¡acabas de crear un raspador para PAA!
Ejecútalo para comprobar que funciona. En Windows, inicia el raspador con:
python scraper.py
Como alternativa, en Linux o macOS, ejecuta:
python3 scraper.py
Espera a que finalice la ejecución del raspador y aparecerá un archivo people_also_ask.csv en el directorio raíz de tu proyecto. Ábrelo y verás:
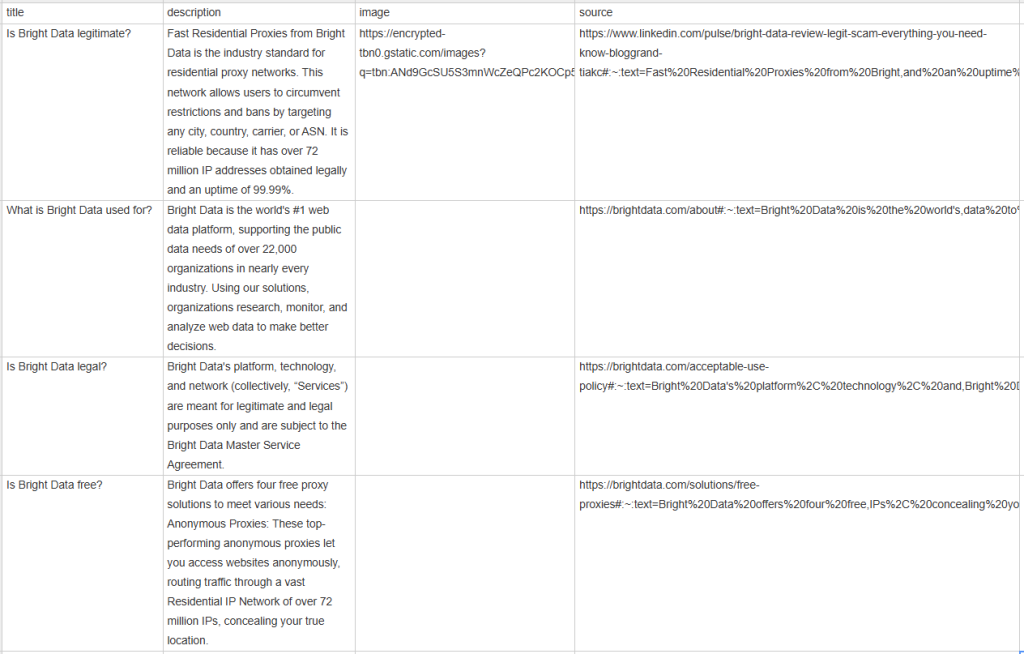
Enhorabuena: ¡misión cumplida!
Conclusión
En este tutorial, has aprendido qué es la sección «La gente también pregunta» en las páginas de Google, los datos que contiene y cómo rasparlos con Python. Como has aprendido aquí, crear un script sencillo para recuperar datos automáticamente solo requiere unas pocas líneas de código Python.
Si bien la solución presentada funciona bien para proyectos pequeños, no es práctica para el raspado a gran escala. El problema es que Google cuenta con una de las tecnologías antibots más avanzadas de la industria. Por tanto, podría bloquearte con CAPTCHA o prohibiciones de IP. Además, escalar este proceso en varias páginas aumentaría los costes de infraestructura.
¿Significa eso que es imposible raspar Google de manera eficiente y fiable? ¡En absoluto! Lo único que necesitas es una solución avanzada que aborde estos retos, como la API de Búsqueda en Google de Bright Data.
La API de Búsqueda de Google proporciona un punto final para recuperar datos de las páginas SERP de Google, incluida la sección «La gente también pregunta». Con una simple llamada a la API, puedes obtener los datos que quieras en formato JSON o HTML. Consulta cómo empezar a usarla en la documentación oficial.
¡Regístrate ahora y comienza tu prueba gratuita!