

El raspado web es el proceso de recopilación automática de datos de sitios web con fines tales como analizar datos o ajustar modelos de IA.
Python es una opción popular para el raspado web debido a su amplia gama de bibliotecas de raspado, como lxml, que se utiliza para analizar documentos XML y HTML. lxml amplía las capacidades de Python con una API de Python para las bibliotecas C rápidas libxml2 y libxslt. También se integra con ElementTree, la estructura jerárquica de datos de Python para árboles XML/HTML, lo que convierte a lxml en la herramienta preferida para un raspado web eficiente y confiable.
En este artículo, aprenderás a utilizar lxml para raspado web.
Bright Data Solutions como la alternativa perfecta
En lo que respecta al raspado web, usar lxml con Python es un enfoque poderoso, pero puede llevar mucho tiempo y ser costoso, especialmente cuando se trata de sitios web complejos o grandes volúmenes de datos. Bright Data ofrece una alternativa eficiente con sus conjuntos de datos listos para usar y API Web Scraper. Estas soluciones reducen significativamente el tiempo y el coste que implica la recopilación de datos al proporcionar datos prerecopilados de más de 100 dominios y API de raspado fáciles de integrar.
Con Bright Data, puedes evitar los retos técnicos del raspado manual, lo que te permite centrarte en analizar los datos en lugar de recuperarlos. Tanto si necesitas conjuntos de datos adaptados a tus requisitos específicos como API que gestionen proxies y resuelvan CAPTCHA, las herramientas de Bright Data ofrecen una solución ágil y rentable para todas tus necesidades de raspado web.
Uso de lxml para el raspado web en Python
En la web, los datos estructurados y jerárquicos se pueden representar en dos formatos: HTML y XML:
- XML es una estructura básica que no incluye etiquetas ni estilos prediseñados. El codificador crea la estructura definiendo sus propias etiquetas. El objetivo principal de la etiqueta es crear una estructura de datos estándar que pueda entenderse entre diferentes sistemas.
- HTML es un lenguaje de marcado web con etiquetas predefinidas. Estas etiquetas vienen con algunas propiedades de estilo, como
font-sizeen etiquetas<h1>odisplaypara etiquetas<img />. La función principal del HTML es estructurar las páginas web de forma eficaz.
lxml funciona con documentos HTML y XML.
Requisitos previos
Antes de empezar a hacer raspado web con lxml, tienes que instalar unas cuantas bibliotecas en tu máquina:
pip install lxml requests cssselect
Este comando instala lo siguiente:
- lxml para analizar XML y HTML
- requests para buscar páginas web
- cssselect, que usa selectores CSS para extraer elementos HTML
Análisis de contenido HTML estático
Se pueden extraer dos tipos principales de contenido web: estático y dinámico. El contenido estático se integra en el documento HTML cuando la página web se carga inicialmente, lo que facilita el raspado. Por el contrario, el contenido dinámico se carga de forma continua o se activa mediante JavaScript después de la carga inicial de la página. El raspado de contenido dinámico requiere programar la función de raspado para que se ejecute solo después de que el contenido esté disponible en el navegador.
En este artículo, empezarás por raspar el sitio web Books to Scrape, que tiene contenido HTML estático diseñado con fines de prueba. Extraes los títulos y precios de los libros y guardas esa información como un archivo JSON.
Para empezar, usa las Dev Tools de tu navegador para identificar los elementos HTML relevantes. Abre Dev Tools haciendo clic con el botón derecho en la página web y seleccionando la opción Inspeccionar . Si estás en Chrome, puedes pulsar F12 para acceder a este menú:
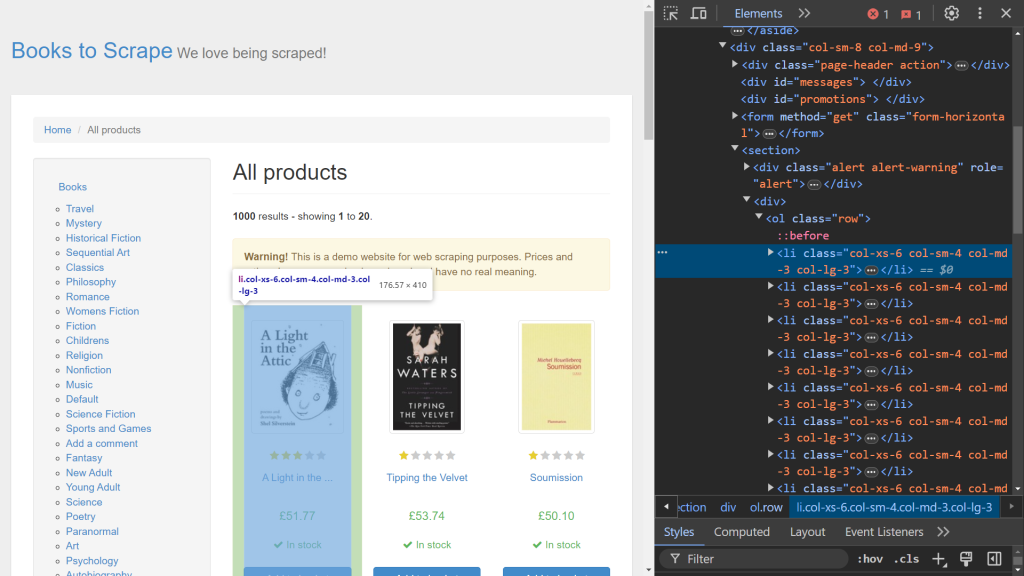
El lado derecho de la pantalla muestra el código responsable de renderizar la página. Para localizar el elemento HTML específico que gestiona los datos de cada libro, busca en el código con la opción de pasar el ratón para seleccionar (la flecha situada en la esquina superior izquierda de la pantalla):
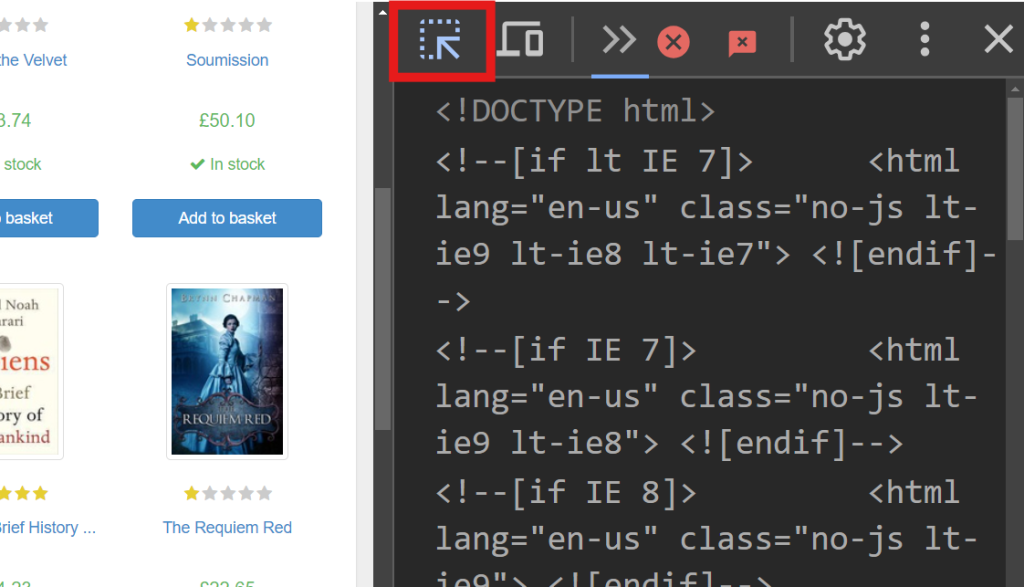
En Dev Tools, deberías ver el siguiente fragmento de código:
<article class="product_pod">
<!-- code omitted -->
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<!-- code omitted -->
</div>
</article>
En este fragmento, cada libro está contenido en una etiqueta <article> marcada con la clase product_pod. Este elemento se orienta para extraer los datos. Crea un nuevo archivo llamado static_scrape.py e introduce el siguiente código:
import requests
from lxml import html
import json
URL = "https://books.toscrape.com/"
content = requests.get(URL).text
Este código importa las bibliotecas necesarias y define una variable URL . Utiliza requests.get () para obtener el contenido HTML estático de la página web enviando una solicitud GET a la URL especificada. A continuación, el código HTML se recupera mediante el atributo text de la respuesta.
Una vez obtenido el contenido HTML, el siguiente paso es analizarlo con lxml y extraer los datos necesarios. lxml ofrece dos métodos de extracción: selectores de XPath y CSS. En este ejemplo, utiliza XPath para recuperar el título del libro y los selectores CSS para obtener el precio del libro.
Añade el siguiente código a tu script:
parsed = html.fromstring(content)
all_books = parsed.xpath('//article[@class="product_pod"]')
books = []
Este código inicializa la variable parsed usando html.fromstring (content), que analiza el contenido HTML en una estructura de árbol jerárquico. La variable all_books usa un selector de XPath para recuperar todas las etiquetas
de la clase product_pod de la página web. Esta sintaxis es válida específicamente para las expresiones XPath.
A continuación, añade lo siguiente a tu script para recorrer en iteración cada libro de all_books y extraer datos de ellos:
for book in all_books:
book_title = book.xpath('.//h3/a/@title')
price = book.cssselect("p.price_color")[0].text_content()
books.append({"title": book_title, "price": price})
La variable book_title se define mediante un selector de XPath que recupera el atributo title de una etiqueta dentro de una etiqueta
. El punto (.) al principio de la expresión XPath especifica que se debe iniciar la búsqueda desde la etiqueta <article> en lugar del punto de inicio predeterminado. La siguiente línea usa el método cssselect para extraer el precio de una
etiqueta con la clase price_color. Como cssselect devuelve una lista, indexing ([0]) accede al primer elemento y text_content () recupera el texto del elemento. A continuación, cada par de títulos y precios extraídos se añade a la lista books en forma de diccionario, que se puede almacenar fácilmente en un archivo JSON.
Ahora que has completado el proceso de raspado web, es el momento de guardar estos datos localmente. Abre el archivo de script e introduce el siguiente código:
with open("books.json", "w", encoding="utf-8") as file:
json.dump(books ,file)
En este código, se crea un nuevo archivo llamado books.json . Este archivo se rellena con el método json.dump , que toma la lista books como fuente y un objeto file como destino.
Puedes probar este script abriendo la terminal y ejecutando el siguiente comando:
python static_scrape.py
Este comando genera un nuevo archivo en tu directorio con el siguiente resultado:
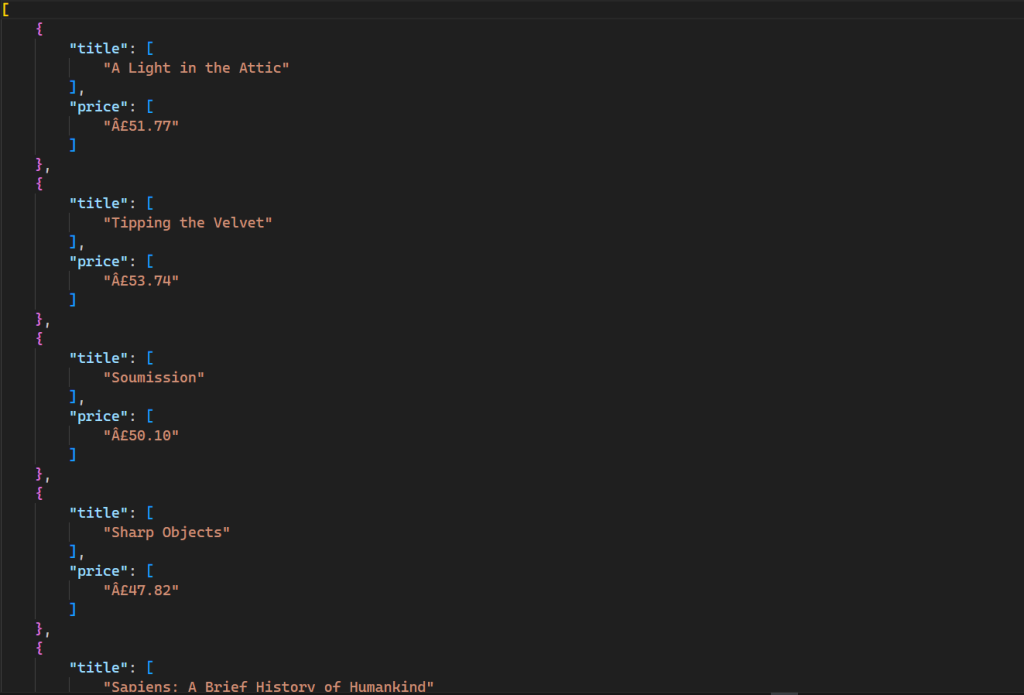
Todo el código de este script está disponible en GitHub.
Análisis de contenido HTML dinámico
El raspado del contenido web dinámico es más complicado que el raspado del contenido estático, ya que JavaScript procesa los datos de forma continua en lugar de procesar todos a la vez. Para ayudar a extraer contenido dinámico, utilizas una herramienta de automatización del navegador llamada Selenium, que te permite crear y ejecutar una instancia de navegador y controlarla mediante programación.
Para instalar Selenium, abre la terminal y ejecuta el siguiente comando:
pip install selenium
YouTube es un excelente ejemplo de contenido renderizado con JavaScript. Cuando visitas cualquier canal, al principio solo se carga un número limitado de vídeos y aparecen más vídeos a medida que te desplazas hacia abajo. Aquí, raspas los datos de los cien vídeos más vistos del canal de YouTube freeCodeCamp.org emulando las pulsaciones del teclado para desplazar la página.
Para empezar, inspecciona el código HTML de la página web. Cuando abras Dev Tools, verás lo siguiente:
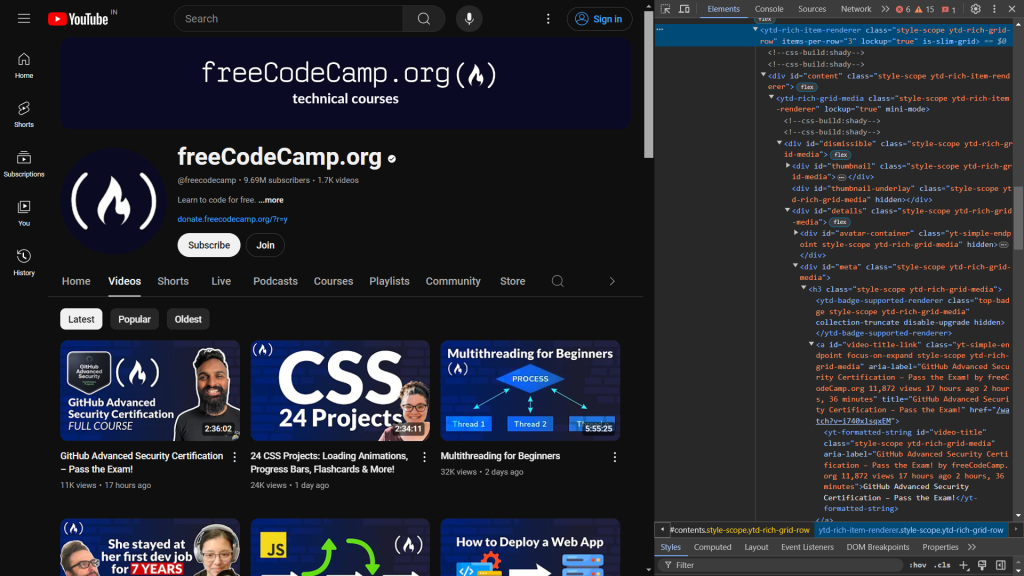
El siguiente código identifica los elementos responsables de mostrar el título y el enlace del vídeo:
<a id="video-title-link" class="yt-simple-endpoint focus-on-expand style-scope ytd-rich-grid-media" href="/watch?v=i740xlsqxEM">
<yt-formatted-string id="video-title" class="style-scope ytd-rich-grid-media">GitHub Advanced Security Certification – Pass the Exam!
</yt-formatted-string></a>
El título del vídeo está dentro de la etiqueta yt-formatted-string con el ID video-title, y el enlace del vídeo se encuentra en el atributo href de la etiqueta a con el ID video-title-link.
Una vez que hayas identificado lo que quieres borrar, crea un nuevo archivo llamado dynamic_scrape.py y agrega el siguiente código, que importa todos los módulos necesarios para el script:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from lxml import html
from time import sleep
import json
En este caso, empieza importando webdriver desde selenium, lo que crea una instancia de navegador que puedes controlar mediante programación. Las siguientes líneas importan By y Keys, que seleccionan un elemento de la web y realizan algunas pulsaciones sobre él. La función sleep se importa para pausar la ejecución del programa y esperar a que JavaScript muestre el contenido de la página.
Con todas las importaciones ordenadas, puedes definir la instancia del controlador para el navegador que elijas. Este tutorial usa Chrome, pero Selenium también es compatible con Edge, Firefoxy Safari.
Para definir la instancia del controlador para el navegador, añade el script con el siguiente código:
URL = "https://www.youtube.com/@freecodecamp/videos"
videos = []
driver = webdriver.Chrome()
driver.get(URL)
sleep(3)
Al igual que en el script anterior, declaras una variable URL que contiene la URL web que quieres extraer y una variable videos que almacena todos los datos en forma de lista. A continuación, se declara una variable driver (es decir, una instancia de Chrome ) que usas cuando interactúas con el navegador. La función get () abre la instancia del navegador y envía una solicitud a la URL especificada. Después de eso, llamarás a la función sleep para esperar tres segundos antes de acceder a cualquier elemento de la página web y asegurarte de que todo el código HTML se carga en el navegador.
Como se mencionó anteriormente, YouTube usa JavaScript para cargar más vídeos a medida que te desplazas hasta el final de la página. Para raspar datos de un centenar de vídeos, debes desplazarte programáticamente hasta la parte inferior de la página después de abrir el navegador. Para ello, añade el siguiente código a tu script:
parent = driver.find_element(By.TAG_NAME, 'html')
for i in range(4):
parent.send_keys(Keys.END)
sleep(3)
En este código, la etiqueta <html> se selecciona con la función find_element . Devuelve el primer elemento que coincide con los criterios dados, que en este caso es la etiqueta html . El método send_keys simula la pulsación de la tecla END para desplazarse hasta el final de la página, lo que hace que se carguen más vídeos. Esta acción se repite cuatro veces dentro de un bucle for para garantizar que se carguen suficientes vídeos. La función sleep se detiene durante tres segundos después de cada desplazamiento para permitir que los vídeos se carguen antes de volver a desplazarse.
Ahora que tienes todos los datos necesarios para comenzar el proceso de raspado, es hora de usar lxml con cssselect para seleccionar los elementos que desees extraer:
html_data = html.fromstring(driver.page_source)
videos_html = html_data.cssselect("a#video-title-link")
for video in videos_html:
title = video.text_content()
link = "https://www.youtube.com" + video.get("href")
videos.append( {"title": title, "link": link} )
En este código, se pasa el contenido HTML del atributo page_source del controlador al método fromstring , que crea un árbol jerárquico del HTML. A continuación, selecciona todas las etiquetas <a> con el ID video-title-link usando selectores CSS, donde el signo # indica la selección mediante el ID de la etiqueta. Esta selección devuelve una lista de elementos que cumplen los criterios dados. Luego, el código itera sobre cada elemento para extraer el título y el enlace. El método text_content recupera el texto interno (el título del vídeo), mientras que el método get obtiene el valor del atributo href (el enlace del vídeo). Por último, los datos se almacenan en una lista llamada videos.
En este punto, has terminado con el proceso de raspado. El siguiente paso consiste en almacenar estos datos raspados localmente en tu sistema. Para almacenar los datos, añade el siguiente código al script:
with open('videos.json', 'w') as file:
json.dump(videos, file)
driver.close()
Aquí, crea un archivo videos.json y usa el método json.dump para serializar la lista de vídeos en formato JSON y escribirla en el objeto de archivo. Por último, se llama al método close en el objeto del controlador para cerrar y destruir de forma segura la instancia del navegador.
Ahora puedes probar tu script abriendo la terminal y ejecutando el siguiente comando:
python dynamic_scrape.py
Tras ejecutar el script, se crea un nuevo archivo llamado videos.json en tu directorio:
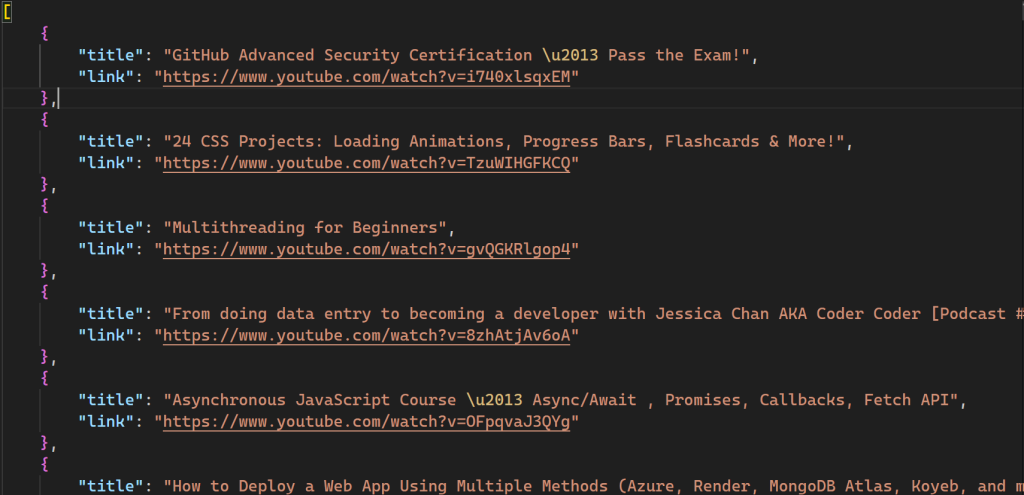
Todo el código de este script también está disponible en GitHub.
Uso de lxml con Bright Data Proxy
Si bien el raspado web es una excelente técnica para automatizar la recopilación de datos de diversas fuentes, el proceso no está exento de desafíos. Tienes que lidiar con las herramientas antiraspado implementadas por los sitios web, la limitación de velocidad, el geobloqueo y la falta de anonimato. Los servidores proxy pueden ayudar con estos problemas actuando como intermediarios que enmascaran la dirección IP del usuario, lo que permite a los rastreadores eludir las restricciones y acceder a los datos específicos sin ser detectados. Bright Data es la mejor opción para servicios de proxy fiables.
El siguiente ejemplo destaca lo fácil que es trabajar con los proxies de Bright Data. Implica realizar algunos cambios en el archivo script_scrape.py para eliminar el sitio web Books to Scrape.
Para empezar, necesitas obtener proxies de Bright Data suscribiéndote a una prueba gratuita que proporciona 5 USD en recursos de proxy. Tras crear una cuenta de Bright Data, verás el siguiente panel:
Navega hasta la opción Mis zonas y crea una nueva zona de proxy residencial . Al crear una nueva zona, se muestran el nombre de usuario, la contraseña y el host del proxy, que necesitarás en el siguiente paso.
Abre el archivo static_scrape.py y añade el siguiente código debajo de la variable URL:
URL = "https://books.toscrape.com/"
# new
username = ""
password = ""
hostname = ""
proxies = {
"http": f"https://{username}:{password}@{hostname}",
"https": f"https://{username}:{password}@{hostname}",
}
content = requests.get(URL, proxies=proxies).text
Sustituye los marcadores de posición username, passwordy hostname por tus credenciales de proxy. Este código indica a la biblioteca requests que utilice el proxy especificado. El resto del script permanece sin cambios.
Prueba el script ejecutando el siguiente comando:
python static_scrape.py
Tras ejecutar este script, verás un resultado similar al que recibiste en el ejemplo anterior.
Puedes ver este script completo en GitHub.
Conclusión
lxml es una herramienta sólida y fácil de usar para extraer datos de documentos HTML. lxml está optimizado para ser rápido y es compatible con los selectores XPath y CSS, lo que permite analizar de manera eficiente documentos XML y HTML de gran tamaño.
En este tutorial, has aprendido todo sobre el raspado web con lxml y sobre el raspado de contenido dinámico y estático. También has aprendido que el hecho de usar servidores proxy de Bright Data puede ayudarte a eludir las restricciones que los sitios web imponen a los raspadores.
Bright Data es una solución integral para todos tus proyectos de raspado web. Ofrece funciones como proxies, navegadores de raspado y reCAPTCHA que permiten a los usuarios resolver eficazmente los desafíos de raspado web. Bright Data también ofrece un blog detallado con tutoriales y mejores prácticas relacionadas con el raspado web.
¿Estás interesado en empezar? ¡Regístrate ahora y prueba nuestros productos gratis!






