

El scraping web a menudo requiere sortear mecanismos anti-bot, cargar contenidos dinámicos mediante herramientas de automatización del navegador como Puppeteer, utilizar rotación de proxy para evitar bloqueos de IP y resolver CAPTCHAs. Incluso con estas estrategias, escalar y mantener sesiones estables sigue siendo un reto.
Este artículo le enseña cómo pasar del scraping tradicional basado en proxy al Bright Data Scraping Browser. Aprenda a automatizar la gestión y el escalado de proxy para reducir los costes de desarrollo y mantenimiento. Se compararán ambos métodos, cubriendo la configuración, el rendimiento, la escalabilidad y la complejidad.
Nota: Los ejemplos de este artículo tienen fines educativos. Consulta siempre las condiciones de servicio del sitio web de destino y cumple las leyes y normativas pertinentes antes de realizar el scraping de datos.
Requisitos previos
Antes de empezar el tutorial, asegúrese de que dispone de los siguientes requisitos previos:
- Node.js
- Código de Visual Studio
- Una cuenta gratuita de Bright Data para poder utilizar su Scraping Browser
Comienza creando una nueva carpeta de proyecto Node.js donde puedas almacenar tu código.
A continuación, abre tu terminal o shell y crea un nuevo directorio utilizando los siguientes comandos:
mkdir scraping-tutorialrncd scraping-tutorial
Inicializa un nuevo proyecto Node.js:
npm init -y
La bandera -y responde automáticamente sí a todas las preguntas, creando un archivo package.json con la configuración por defecto.
Web Scraping basado en proxy
En un enfoque típico basado en proxy, se utiliza una herramienta de automatización del navegador como Puppeteer para interactuar con el dominio de destino, cargar contenido dinámico y extraer datos. Mientras lo hace, integra proxies para evitar las prohibiciones de IP y mantener el anonimato.
Vamos a crear rápidamente un script de web scraping usando Puppeteer que scrapea datos de un sitio web de comercio electrónico usando proxies.
Crear un script de Web Scraping usando Puppeteer
Comience instalando Puppeteer:
npm install puppeteer
A continuación, crea un archivo llamado proxy-scraper.js (puedes ponerle el nombre que quieras) en la carpeta scraping-tutorial y añade el siguiente código:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Launch a headless browserrn const browser = await puppeteer.launch({rn headless: true,rn });rn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
Este script utiliza Puppeteer para extraer los títulos y precios de los libros de las cinco primeras páginas del sitio web Books to Scrape. Inicia un navegador sin cabeza, abre una nueva página y navega por cada página del catálogo.
Para cada página, el script utiliza selectores DOM dentro de page.evaluate() para extraer los títulos y precios de los libros, almacenando los datos en un array. Una vez procesadas todas las páginas, los datos se imprimen en la consola y se cierra el navegador. Este método extrae eficazmente los datos de un sitio web paginado.
Pruebe y ejecute el código utilizando el siguiente comando:
node proxy-scraper.jsEl resultado debería ser el siguiente:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrn[rn { title: 'A Light in the Attic', price: '£51.77' },rn { title: 'Tipping the Velvet', price: '£53.74' },rn { title: 'Soumission', price: '£50.10' },rn { title: 'Sharp Objects', price: '£47.82' },rn { title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },rn { title: 'The Requiem Red', price: '£22.65' },rn…output omitted…rn {rn title: 'In the Country We Love: My Family Divided',rn price: '£22.00'rn }rn]
Configurar proxies
Los proxies se emplean habitualmente en las configuraciones de scraping para dividir las peticiones y hacerlas imposibles de rastrear. Un enfoque común es mantener un grupo de proxies y rotarlos dinámicamente.
Coloque sus proxies en una matriz o almacénelos en un archivo separado si lo desea:
const proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];
Utilizar la lógica de rotación de proxy
Vamos a mejorar el código con la lógica que gira a través de la matriz de proxy cada vez que se inicia el navegador. Actualiza proxy-scraper.js para incluir el siguiente código:
const puppeteer = require(u0022puppeteeru0022);rnrnconst proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];rnrn(async () =u0026gt; {rn // Choose a random proxyrn const randomProxy =rn proxies[Math.floor(Math.random() * proxies.length)];rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.launch({rn headless: true,rn args: [rn `u002du002dproxy-server=http=${randomProxy}`,rn u0022u002du002dno-sandboxu0022,rn u0022u002du002ddisable-setuid-sandboxu0022,rn u0022u002du002dignore-certificate-errorsu0022,rn ],rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(`Using proxy: ${randomProxy}`);rn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
Nota : En lugar de hacer la rotación de los proxies manualmente, puedes utilizar una librería como luminati-proxy para automatizar el proceso.
En este codigo, un proxy aleatorio es seleccionado de la lista de proxies y aplicado a Puppeteer usando la opcion --proxy-server=${randomProxy}. Para evitar la deteccion, tambien se asigna una cadena de agente de usuario aleatoria. La logica de scraping es repetida, y el proxy usado para scrapear los datos del producto es registrado.
Cuando ejecutes el código de nuevo, deberías ver una salida como antes pero con un añadido al proxy que se utilizó:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrnUsing proxy: 115.147.63.59:8081rn…output omitted…
Desafíos del scraping basado en proxy
Aunque un enfoque basado en proxy puede funcionar para muchos casos de uso, puede enfrentarse a algunos de los siguientes retos:
- Bloqueos frecuentes: los proxies pueden bloquearse si el sitio tiene una detección anti-bot estricta.
- Sobrecarga de rendimiento: la rotación de proxies y el reintento de solicitudes ralentizan el proceso de recopilación de datos.
- Escalabilidad compleja: gestionar y rotar un gran grupo de proxies para obtener un rendimiento y una disponibilidad óptimos es complejo. Requiere equilibrar la carga, evitar el uso excesivo de proxies, periodos de enfriamiento y gestionar los fallos en tiempo real. El reto aumenta con las solicitudes simultáneas, ya que el sistema debe eludir la detección mientras supervisa y sustituye continuamente las IP incluidas en listas negras o de bajo rendimiento.
- Mantenimiento del navegador: El mantenimiento del navegador puede ser un reto técnico y consumir muchos recursos. Es necesario actualizar y manipular continuamente la huella digital del navegador (cookies, cabeceras y otros atributos identificativos) para imitar el comportamiento real del usuario y eludir los controles anti-bot avanzados.
- Sobrecarga del navegador en la nube: Los navegadores basados en la nube generan una sobrecarga operativa adicional a través de mayores requisitos de recursos y un complejo control de la infraestructura, lo que se traduce en elevados gastos operativos. El escalado de las instancias del navegador para obtener un rendimiento constante complica aún más el proceso.
DynamicScraping con Bright Data Scraping Browser
Para superar estos retos, puede utilizar una solución de API única como Bright Data Scraping Browser. Simplifica las operaciones, elimina la necesidad de rotar manualmente el proxy y las complejas configuraciones del navegador y, a menudo, aumenta la tasa de éxito en la recuperación de datos.
Configure su cuenta de Bright Data
Para empezar, inicie sesión en su cuenta de Bright Data y vaya a Proxies & Scraping, desplácese hasta Scraping Browser y haga clic en Empezar:
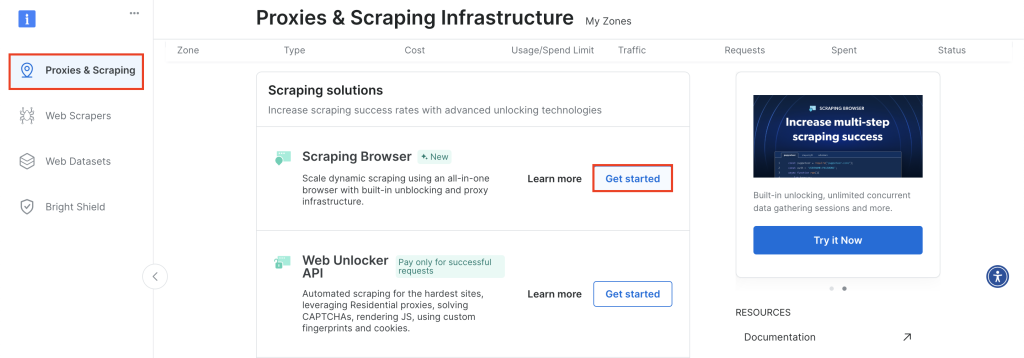
Mantenga la configuración predeterminada y haga clic en Añadir para crear una nueva instancia de Scraping Browser:
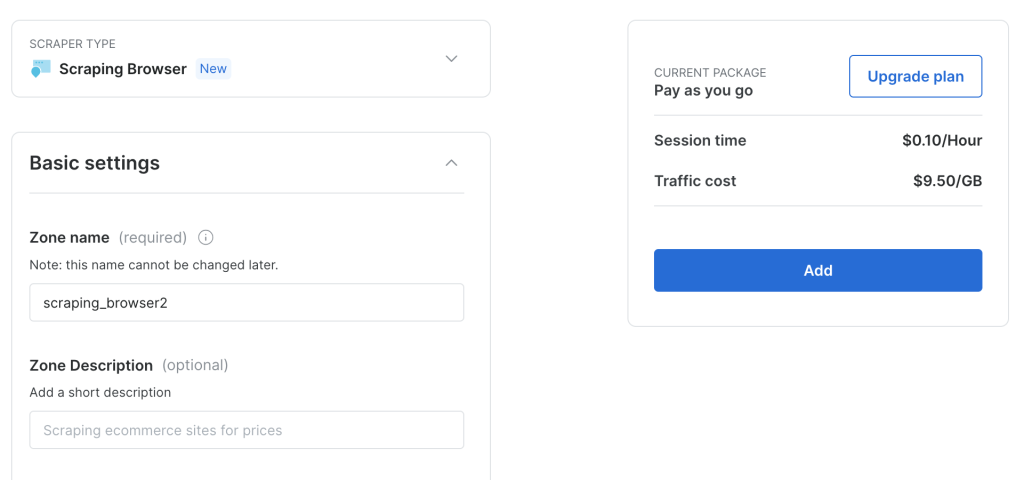
Después de haber creado una instancia de Scraping Browser, toma nota de la URL de Puppeteer ya que la necesitarás pronto:
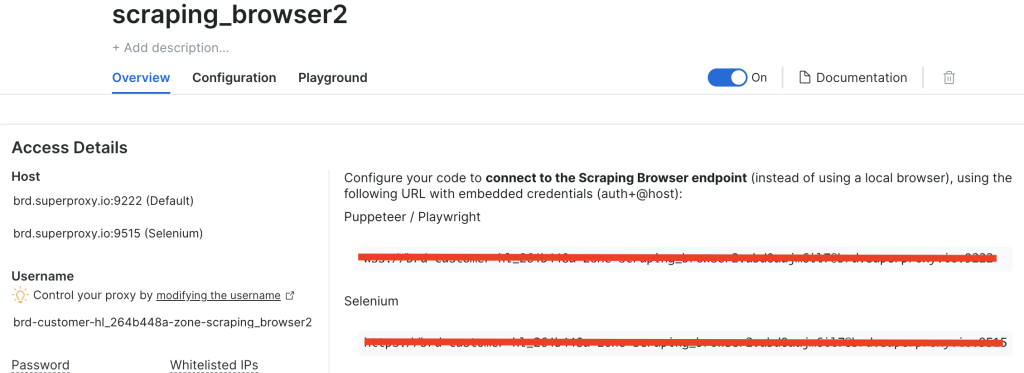
Ajuste el código para utilizar el navegador de raspado de datos Bright
Ahora, vamos a ajustar el código para que en lugar de utilizar proxies rotatorios, se conecte directamente al endpoint de Bright Data Scraping Browser.
Crea un nuevo archivo llamado brightdata-scraper.js y añade el siguiente código:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Choose a random proxyrn const SBR_WS_ENDPOINT = u0022YOUR_BRIGHT_DATA_WS_ENDPOINTu0022rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();
Asegúrese de sustituir YOUR_BRIGHT_DATA_WS_ENDPOINT por la URL que recuperó en el paso anterior.
Este código es similar al anterior, pero en lugar de tener una lista de proxies y hacer malabarismos entre los diferentes proxies, se conecta directamente al endpoint de Bright Data.
Ejecute el siguiente código:
node brightdata-scraper.js
El resultado debería ser el mismo que antes, pero ahora no tendrá que rotar proxies manualmente ni configurar agentes de usuario. Bright Data Scraping Browser se encarga de todo, desde la rotación de proxies hasta la omisión de CAPTCHA, lo que garantiza un raspado de datos ininterrumpido.
Convierta el código en un punto final Express
Si desea integrar Bright Data Scraping Browser en una aplicación más amplia, considere la posibilidad de exponerlo como un punto final Express.
Empieza por instalar Express:
npm install express
Crea un archivo llamado server.js y añade el siguiente código:
const express = require(u0022expressu0022);rnconst puppeteer = require(u0022puppeteeru0022);rnrnconst app = express();rnconst PORT = 3000;rnrn// Needed to parse JSON bodies:rnapp.use(express.json());rnrn// Your Bright Data Scraping Browser WebSocket endpointrnconst SBR_WS_ENDPOINT =rn u0022wss://brd-customer-hl_264b448a-zone-scraping_browser2:[email protected]:9222u0022;rnrn/**rn POST /scraperrn Body example:rn {rn u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022rn }rn*/rnapp.post(u0022/scrapeu0022, async (req, res) =u0026gt; {rn const { baseUrl } = req.body;rnrn if (!baseUrl) {rn return res.status(400).json({rn success: false,rn error: 'Missing u0022baseUrlu0022 in request body.',rn });rn }rnrn try {rn // Connect to the existing Bright Data (Luminati) Scraping Browserrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rn const books = [];rnrn // Example scraping 5 pages of the base URLrn for (let i = 1; i {rn const data = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn const title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn const price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn data.push({ title, price });rn });rn return data;rn });rnrn books.push(...pageBooks);rn }rnrn // Close the browser connectionrn await browser.close();rnrn // Return JSON with the scraped datarn return res.json({rn success: true,rn books,rn });rn } catch (error) {rn console.error(u0022Scraping error:u0022, error);rn return res.status(500).json({rn success: false,rn error: error.message,rn });rn }rn});rnrn// Start the Express serverrnapp.listen(PORT, () =u0026gt; {rn console.log(`Server is listening on http://localhost:${PORT}`);rn});
En este código, se inicializa una aplicación Express, se aceptan cargas JSON y se define una ruta POST /scrape. Los clientes envían un cuerpo JSON que contiene la baseUrl, que se reenvía al endpoint Bright Data Scraping Browser con la URL objetivo.
Ejecute su nuevo servidor Express:
node server.js
Para probar el punto final, puede utilizar una herramienta como Postman (o cualquier otro cliente REST de su elección), o puede utilizar curl desde su terminal o shell de esta manera:
curl -X POST http://localhost/scrape rn-H 'Content-Type: application/json' rn-d '{u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022}'rn
El resultado debería ser el siguiente:
{rn u0022successu0022: true,rn u0022booksu0022: [rn {rn u0022titleu0022: u0022A Light in the Atticu0022,rn u0022priceu0022: u0022£51.77u0022rn },rn {rn u0022titleu0022: u0022Tipping the Velvetu0022,rn u0022priceu0022: u0022£53.74u0022rn },rn {rn u0022titleu0022: u0022Soumissionu0022,rn u0022priceu0022: u0022£50.10u0022rn },rn {rn u0022titleu0022: u0022Sharp Objectsu0022,rn u0022priceu0022: u0022£47.82u0022rn },rn {rn u0022titleu0022: u0022Sapiens: A Brief History of Humankindu0022,rn u0022priceu0022: u0022£54.23u0022rn },rn {rn u0022titleu0022: u0022The Requiem Redu0022,rn u0022priceu0022: u0022£22.65u0022rn },rn {rn u0022titleu0022: u0022The Dirty Little Secrets of Getting Your Dream Jobu0022,rn u0022priceu0022: u0022£33.34u0022rn },rn {rn u0022titleu0022: u0022The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhullu0022,rn u0022priceu0022: u0022£17.93u0022rn },rn rn ... output omitted...rn rn {rn u0022titleu0022: u0022Judo: Seven Steps to Black Belt (an Introductory Guide for Beginners)u0022,rn u0022priceu0022: u0022£53.90u0022rn },rn {rn u0022titleu0022: u0022Joinu0022,rn u0022priceu0022: u0022£35.67u0022rn },rn {rn u0022titleu0022: u0022In the Country We Love: My Family Dividedu0022,rn u0022priceu0022: u0022£22.00u0022rn }rn ]rn}
A continuación se muestra un diagrama que muestra el contraste entre la configuración manual (proxy giratorio) y el enfoque del Navegador de Bright Data Scraping:
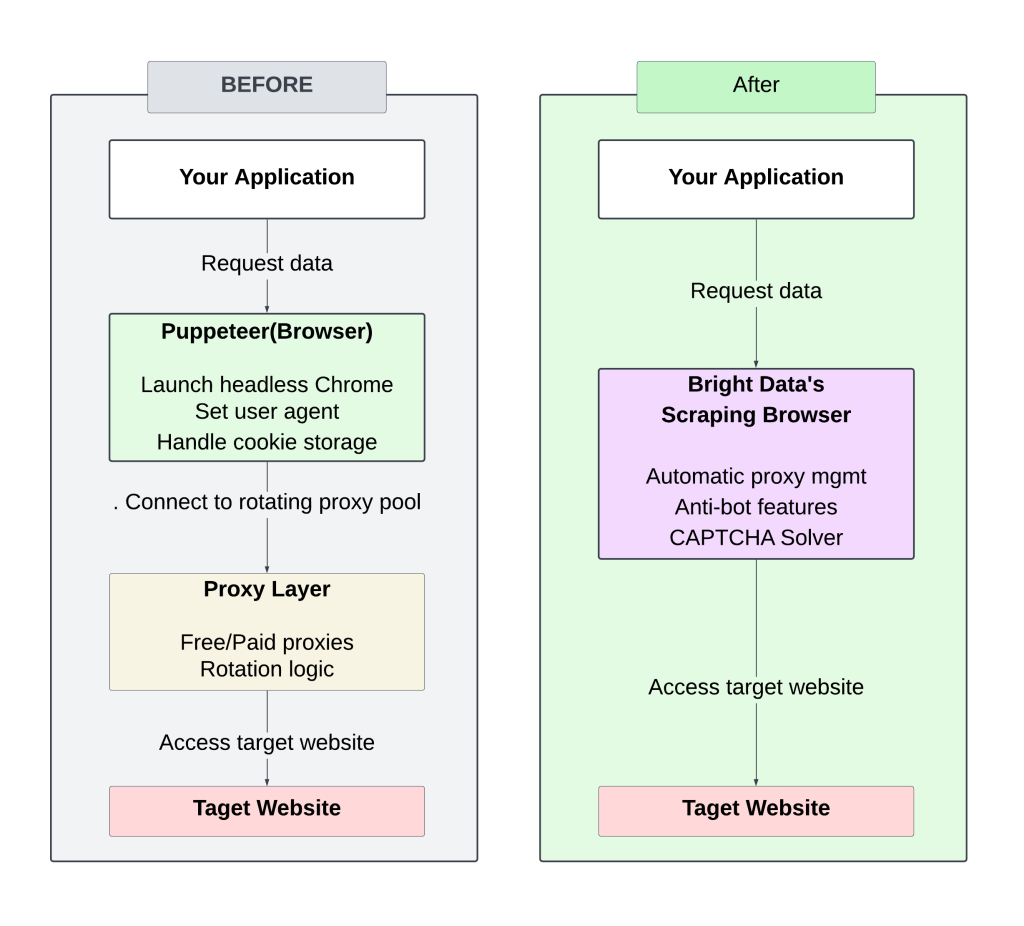
Gestionar proxies que rotan manualmente requiere una atención y un ajuste constantes, lo que provoca bloqueos frecuentes y una escalabilidad limitada.
El uso de Bright Data Scraping Browser agiliza el proceso al eliminar la necesidad de gestionar proxies o cabeceras, al tiempo que ofrece tiempos de respuesta más rápidos gracias a una infraestructura optimizada. Sus estrategias anti-bot integradas aumentan las tasas de éxito, por lo que es menos probable que seas bloqueado o marcado.
Todo el código de este tutorial está disponible en este repositorio de GitHub.
Calcular el ROI
Pasar de una configuración de raspado manual basada en proxy al Navegador de raspado de datos de Bright puede reducir significativamente el tiempo y los costes de desarrollo.
Configuración tradicional
El raspado diario de sitios web de noticias requiere lo siguiente:
- Desarrollo inicial: ~50 horas (5.000 USD a 100 USD/hora)
- Mantenimiento continuo: ~10 horas/mes (1.000 USD) para actualizaciones de código, infraestructura, escalado y gestión de proxy.
- Costes de proxy/IP: ~250 USD/mes (varía en función de las necesidades de IP)
Coste mensual total estimado: ~1.250 USD
Configuración del navegador de Bright Data Scraping
- Tiempo de desarrollo: 5-10 horas (1.000 USD)
- Mantenimiento: ~2-4 horas/mes (200 USD)
- No se necesitaproxy ni gestión de infraestructuras
- Costes del servicio Bright Data:
- Uso del tráfico: 8,40 USD/GB(por ejemplo, 30GB/mes = 252 USD)
Coste mensual total estimado: ~450 USD
La automatización de la gestión de proxies y el escalado de Bright Data Scraping Browser reducen tanto los costes iniciales de desarrollo como el mantenimiento continuo, lo que hace que el scraping de datos a gran escala sea más eficiente y rentable.
Conclusión
La transición de una configuración de raspado web tradicional basada en proxy a Bright Data Scraping Browser elimina la molestia de la rotación de proxy y la gestión manual anti-bot.
Además de la obtención de HTML, Bright Data también ofrece herramientas adicionales para agilizar la extracción de datos:
- Web Scrapers para facilitar la extracción de datos
- API de Web Unlocker para raspar sitios más difíciles
- Conjuntos de datos para que pueda acceder a datos estructurados recopilados previamente
Estas soluciones pueden simplificar el proceso de scraping, reducir la carga de trabajo y mejorar la escalabilidad.





