

Python es uno de los lenguajes más populares cuando se trata de Scraping web. ¿Cuál es la mayor fuente de información en Internet? ¡Google! Por eso es tan popular el Scraping web de Google con Python. La idea es recuperar automáticamente los datos SERP y utilizarlos para marketing, seguimiento de la competencia y mucho más.
Siga este tutorial guiado y aprenda a realizar scraping de Google en Python con Selenium. ¡Empecemos!
¿Qué datos extraer de Google?
Google es una de las mayores fuentes de datos públicos en Internet. Hay mucha información interesante que se puede recuperar de él, desde las reseñas de Google Maps hasta las respuestas de «La gente también pregunta»:
Sin embargo, lo que suele interesar a los usuarios y a las empresas son los datos SERP. SERP, abreviatura de«Search Engine Results Page» (página de resultados del motor de búsqueda), es la página que devuelven los motores de búsqueda como Google en respuesta a la consulta de un usuario. Por lo general, incluye una lista de tarjetas con enlaces y descripciones de texto a páginas web propuestas por el motor de búsqueda.
Así es como se ve una página SERP:
Los datos SERP son cruciales para que las empresas comprendan su visibilidad en línea y estudien la competencia. Proporcionan información sobre las preferencias de los usuarios, el rendimiento de las palabras clave y las estrategias de la competencia. Al analizar los datos SERP, las empresas pueden optimizar su contenido, mejorar el posicionamiento SEO y adaptar las estrategias de marketing para satisfacer mejor las necesidades de los usuarios.
Así que ahora ya sabes que los datos SERP son sin duda muy valiosos. Solo queda averiguar cómo elegir la herramienta adecuada para recuperarlos. Python es uno de los mejores lenguajes de programación para el Scraping web y es perfecto para este fin. Pero antes de lanzarnos al scraping manual, exploremos la mejor y más rápida opción para extraer los resultados de búsqueda de Google: la API SERP de Bright Data.
Presentamos la API SERP de Bright Data
Antes de sumergirte en la guía de scraping manual, considera la posibilidad de aprovechar la API SERP de Bright Data para una recopilación de datos eficiente y sin problemas. La API SERP proporciona acceso en tiempo real a los resultados de los principales motores de búsqueda, incluidos Google, Bing, DuckDuckGo, Yandex, Baidu, Yahoo y Naver. Esta potente herramienta se basa en los servicios de Proxy líderes en el sector y las soluciones avanzadas antibots de Bright Data, lo que garantiza una recuperación de datos fiable y precisa sin los retos habituales asociados al Scraping web.
¿Por qué elegir la API SERP de Bright Data en lugar del scraping manual?
- Resultados en tiempo real y alta precisión: la API SERP ofrece resultados de motores de búsqueda en tiempo real, lo que garantiza que obtenga datos precisos y actualizados. Con una precisión de ubicación hasta el nivel de ciudad, verá exactamente lo que vería un usuario real en cualquier parte del mundo.
- Soluciones avanzadas antibots: olvídese de los bloqueos y los retos CAPTCHA. La API SERP incluye Resolución de CAPTCHA, huellas digitales del navegador y gestión completa de Proxies para garantizar una recopilación de datos fluida e ininterrumpida.
- Personalizable y escalable: la API admite una variedad de parámetros de búsqueda personalizados, lo que le permite personalizar sus consultas para que se adapten a sus necesidades específicas. Está diseñada para grandes volúmenes, por lo que gestiona con facilidad el tráfico creciente y los periodos de máxima actividad.
- Facilidad de uso: con simples llamadas a la API SERP, puede recuperar datos SERP estructurados en formato JSON o HTML, lo que facilita su integración en sus sistemas y flujos de trabajo existentes. El tiempo de respuesta es excepcional, normalmente inferior a 5 segundos.
- Rentable: ahorre en costes operativos utilizando la API SERP. Solo paga por las solicitudes exitosas y no es necesario invertir en el mantenimiento de la Infraestructura de scraping ni ocuparse de los problemas del servidor.
¡Comience hoy mismo su prueba gratuita y experimente la eficiencia y fiabilidad de la API SERP de Bright Data!
Cree un Scraper de SERP de Google en Python
Siga este tutorial paso a paso y vea cómo crear un script de scraping de Google SERP en Python.
Paso 1: Configuración del proyecto
Para seguir esta guía, necesita tener Python 3 instalado en su equipo. Si tiene que instalarlo, descargue el instalador, ejecútelo y siga las instrucciones del asistente.
¡Ahora ya tiene todo lo necesario para rastrear Google en Python!
Utilice los siguientes comandos para crear un proyecto Python con un entorno virtual:
mkdir google-scraper
cd google-scraper
python -m venv envgoogle-Scraper será el directorio raíz de su proyecto.
Cargue la carpeta del proyecto en su IDE de Python favorito. PyCharm Community Edition o Visual Studio Code con la extensión Python son dos excelentes opciones.
En Linux o macOS, activa el entorno virtual con el siguiente comando:
./env/bin/activateEn Windows, ejecuta en su lugar:
env/Scripts/activateTen en cuenta que algunos IDE reconocen el entorno virtual por ti, por lo que no es necesario activarlo manualmente.
Añada un archivo scraper.py en la carpeta de su proyecto e inicialícelo como se indica a continuación:
print("¡Hola, mundo!")Se trata de un script sencillo que imprime el mensaje «¡Hola, mundo!», pero pronto contendrá la lógica de scraping de Google.
Compruebe que su script funciona como desea ejecutándolo mediante el botón de ejecución de su IDE o con este comando:
python Scraper.pyEl script debería imprimir:
¡Hola, mundo!¡Bien hecho! Ahora tienes un entorno Python para el scraping de SERP.
Antes de lanzarte a extraer datos de Google con Python, te recomendamos que eches un vistazo a nuestra guía sobre Scraping web con Python.
Paso 2: Instalar las bibliotecas de scraping
Es hora de instalar la biblioteca de Python adecuada para extraer datos de Google. Hay varias opciones disponibles, y elegir la mejor requiere un análisis del sitio de destino. Al mismo tiempo, estamos hablando de Google, y todos sabemos cómo funciona.
Crear una URL de búsqueda de Google que no llame la atención de sus tecnologías antibots es complejo. Todos sabemos que Google requiere la interacción del usuario. Por eso, la forma más fácil y eficaz de interactuar con el motor de búsqueda es a través de un navegador, simulando lo que haría un usuario real.
En otras palabras, necesitarás una herramienta de navegador sin interfaz gráfica para renderizar páginas web en un navegador controlable. ¡Selenium será perfecto!
En un entorno virtual Python activado, ejecuta el siguiente comando para instalar el paquete selenium:
pip install seleniumEl proceso de configuración puede tardar un poco, así que ten paciencia.
¡Genial! Acabas de añadir selenium a las dependencias de tu proyecto.
Paso 3: Configurar Selenium
Importe Selenium añadiendo las siguientes líneas a scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import OptionsInicialice una instancia de Chrome WebDriver para controlar una ventana de Chrome en modo sin interfaz gráfica, como se muestra a continuación:
# opciones para iniciar Chrome en modo sin interfaz gráfica
options = Options()
options.add_argument('--headless') # coméntalo mientras desarrollas localmente
# inicializa una instancia de controlador web con las
# opciones especificadas
driver = webdriver.Chrome(
service=Service(),
options=options
)Nota: El indicador --headless garantiza que Chrome se iniciará sin GUI. Si desea ver las operaciones realizadas por su script en la página de Google, comente esa opción. En general, desactive el indicador --headless durante el desarrollo local, pero déjelo en producción. Esto se debe a que ejecutar Chrome con la GUI consume muchos recursos.
Como última línea de su script, no olvide cerrar la instancia del controlador web:
driver.quit()Tu archivo scraper.py ahora debería contener:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# opciones para iniciar Chrome en modo sin interfaz gráfica
options = Options()
options.add_argument('--headless') # coméntelo mientras desarrolla localmente
# inicializar una instancia del controlador web con las
# opciones especificadas
driver = webdriver.Chrome(
service=Service(),
options=options)
# lógica de scraping...
# cerrar el navegador y liberar sus recursos
driver.quit()¡Genial! Ya tienes todo lo necesario para extraer datos de sitios web dinámicos.
Paso 4: Visita Google
El primer paso para extraer datos de Google con Python es conectarse al sitio de destino. Utiliza la función get() del objeto controlador para indicar a Chrome que visite la página de inicio de Google:
driver.get("https://google.com/")Así es como debería verse tu script de Python para extraer datos de SERP hasta ahora:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# opciones para iniciar Chrome en modo sin interfaz gráfica
options = Options()
options.add_argument('--headless') # coméntalo mientras desarrollas localmente
# inicializar una instancia de controlador web con las
# opciones especificadas
driver = webdriver.Chrome(
service=Service(),
options=options)
# conectarse al sitio de destino
driver.get("https://google.com/")
# lógica de scraping...
# cerrar el navegador y liberar sus recursos
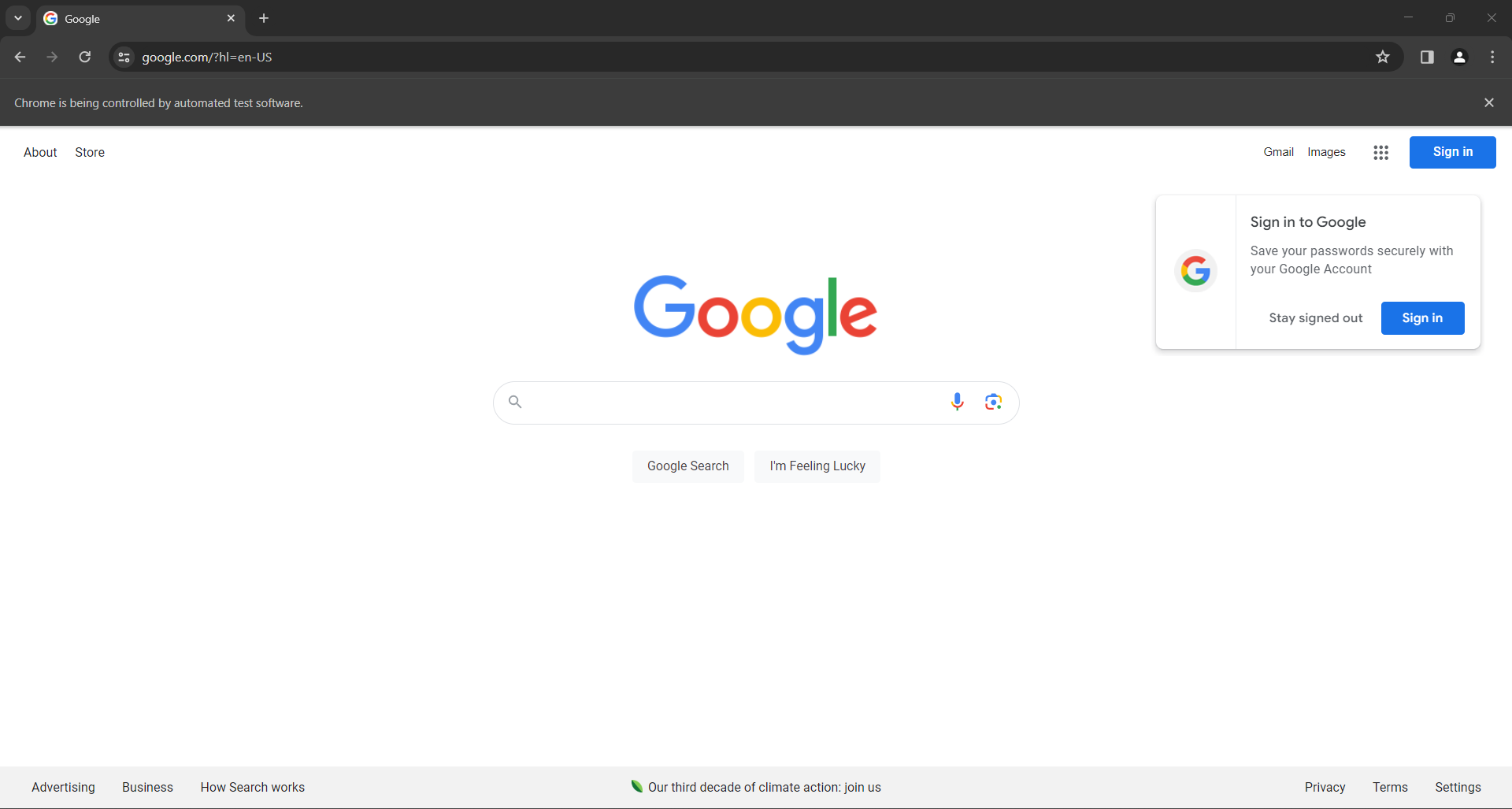
driver.quit()Ejecute el script en modo con interfaz y verá la siguiente ventana del navegador durante una fracción de segundo antes de que la instrucción quit() lo termine:
Si eres un usuario ubicado en la UE (Unión Europea), la página de inicio de Google también contendrá la ventana emergente del RGPD que se muestra a continuación:
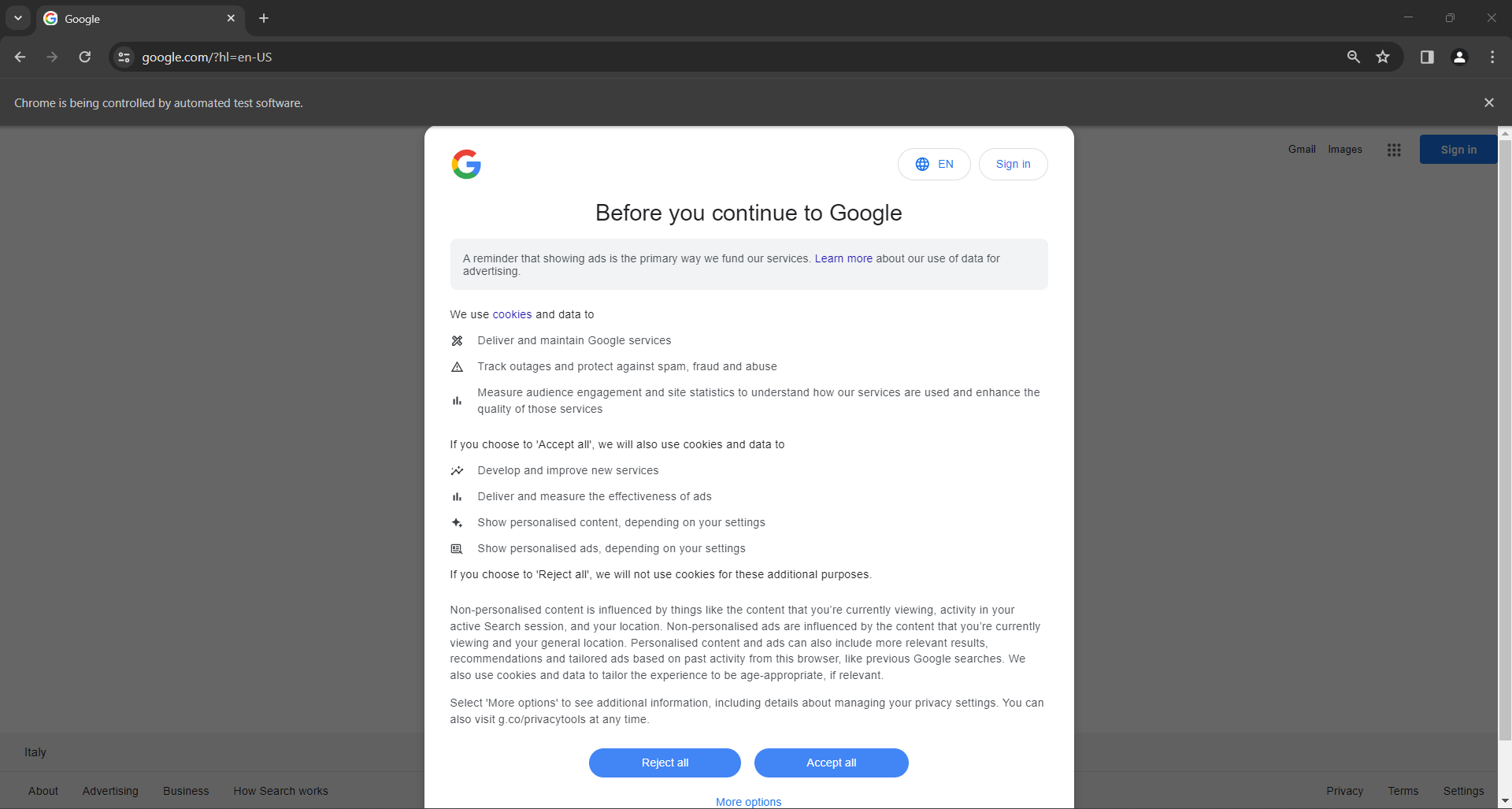
En ambos casos, el mensaje «Chrome está siendo controlado por un software de pruebas automatizado» le informa de que Selenium está controlando Chrome como usted desea.
¡Genial! Selenium abre la página de Google como se desea.
Nota: Si Google muestra el cuadro de diálogo de la política de cookies por motivos relacionados con el RGPD, siga el siguiente paso. De lo contrario, puede pasar al paso 6.
Paso 5: Gestionar el cuadro de diálogo de cookies del RGPD
El siguiente cuadro de diálogo de cookies del RGPD de Google aparecerá o no dependiendo de la ubicación de su IP. Integre un Proxy en Selenium para elegir una IP de salida del país que prefiera y evitar este problema.
Inspeccione el elemento HTML del cuadro de diálogo de cookies con DevTools:
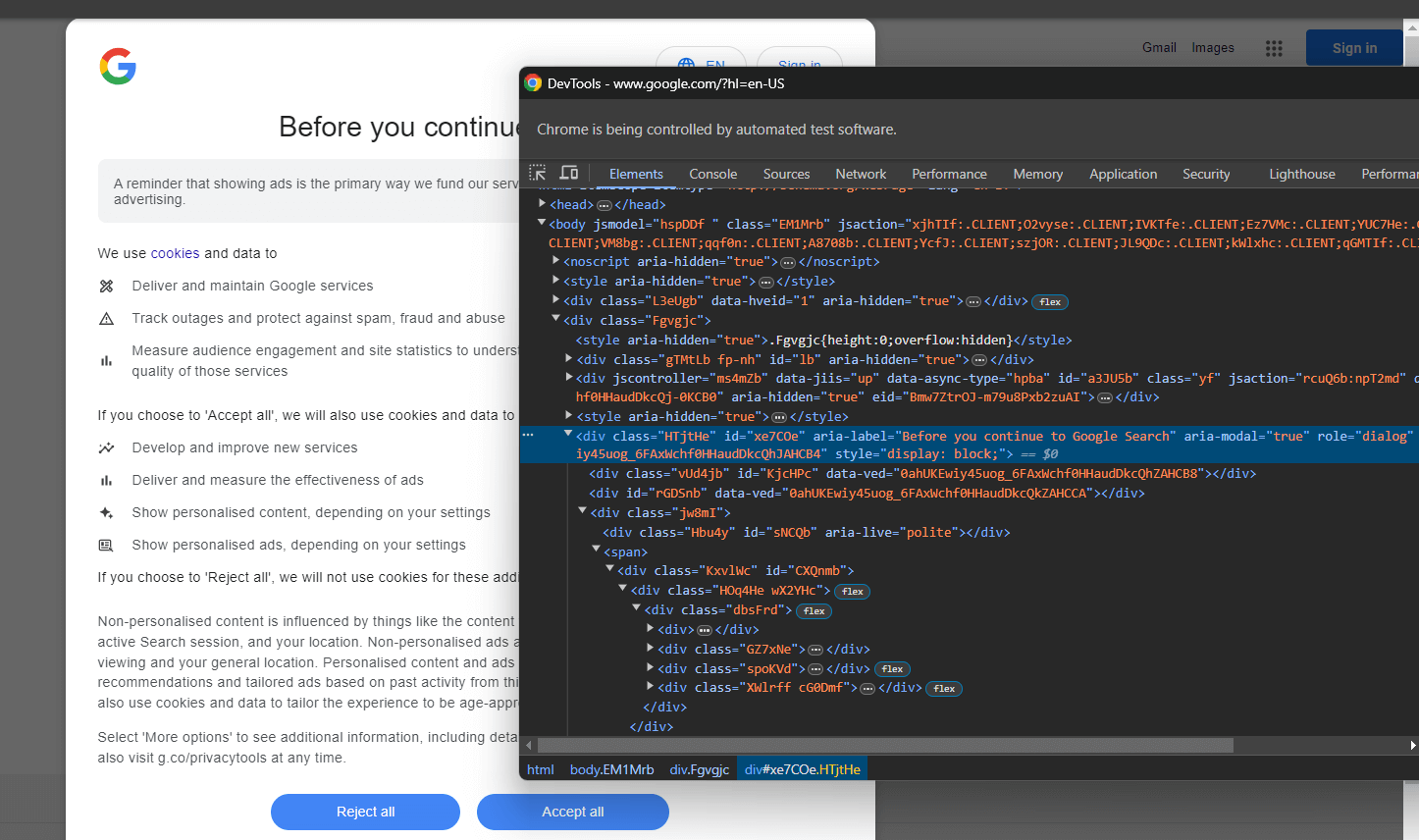
Expanda el código y verá que puede seleccionar este elemento HTML con el selector CSS siguiente:
[role='dialog']Si inspecciona el botón «Aceptar todo», observará que no existe una estrategia de selección CSS sencilla para seleccionarlo:
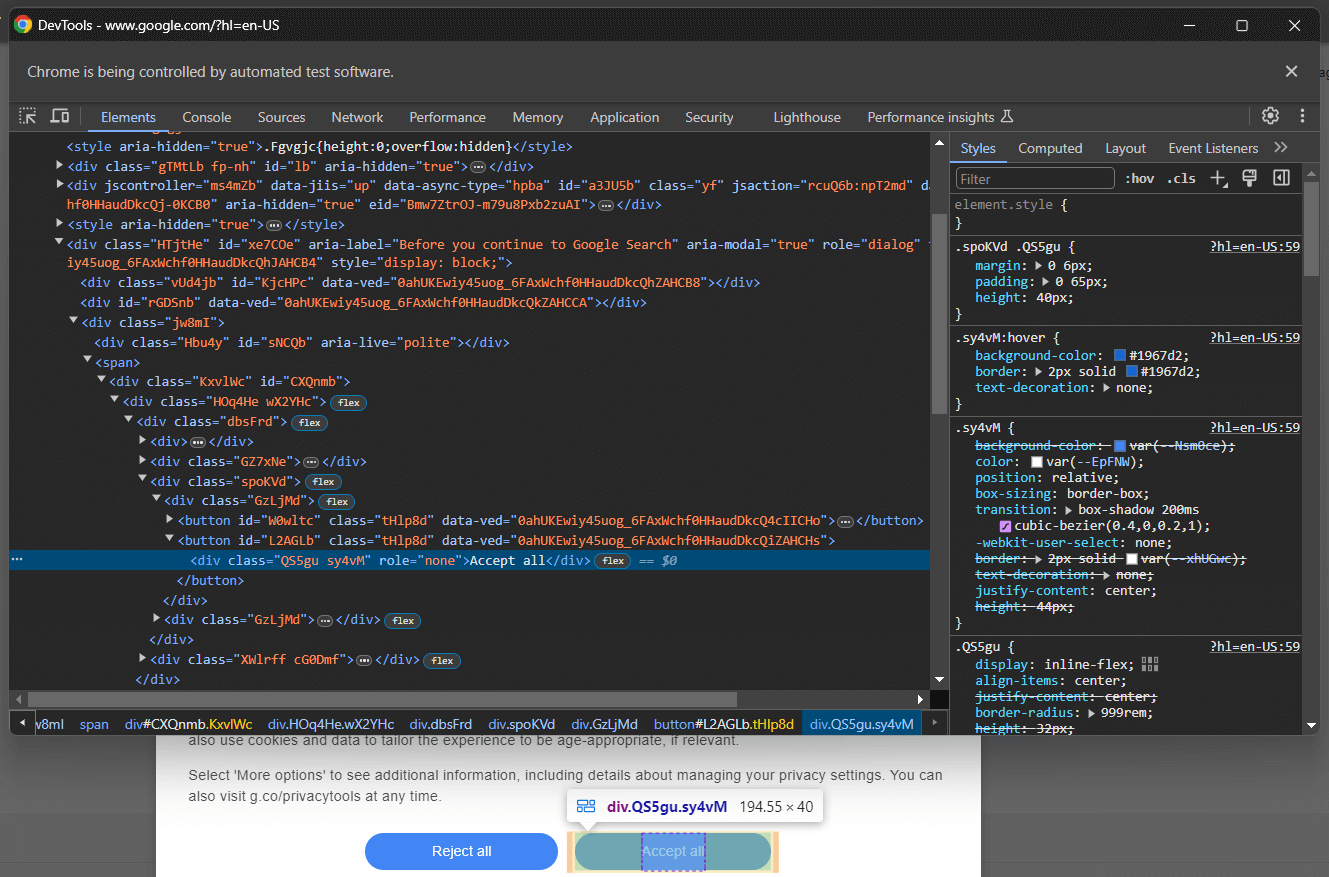
En concreto, las clases CSS del código HTML parecen generarse aleatoriamente. Para seleccionar el botón, obtenga todos los botones del elemento del cuadro de diálogo de cookies y busque el que tenga el texto «Aceptar todo». El selector CSS para obtener todos los botones del cuadro de diálogo de cookies es:
[role='dialog'] buttonAplique un selector CSS en el DOM pasándolo al método find_elements() de Selenium. Esto selecciona los elementos HTML de la página según la estrategia especificada, que en este caso es un selector CSS:
botones = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] botón")Para que funcione correctamente, la línea anterior requiere la siguiente importación:
from selenium.webdriver.common.by import ByUtilice next() para encontrar el botón «Aceptar todo». A continuación, haga clic en él:
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# haga clic en el botón «Aceptar todo», si está presente
if accept_all_button is not None:
accept_all_button.click()Esta instrucción localizará el elemento <button> en el cuadro de diálogo cuyo texto contenga la cadena «Aceptar todo». Si está presente, hará clic en él llamando al método click() de Selenium.
¡Fantástico! Ya estás listo para simular una búsqueda en Google en Python y recopilar algunos datos SERP.
Paso 6: Simular una búsqueda en Google
Abre Google en tu navegador e inspecciona el formulario de búsqueda en DevTools:
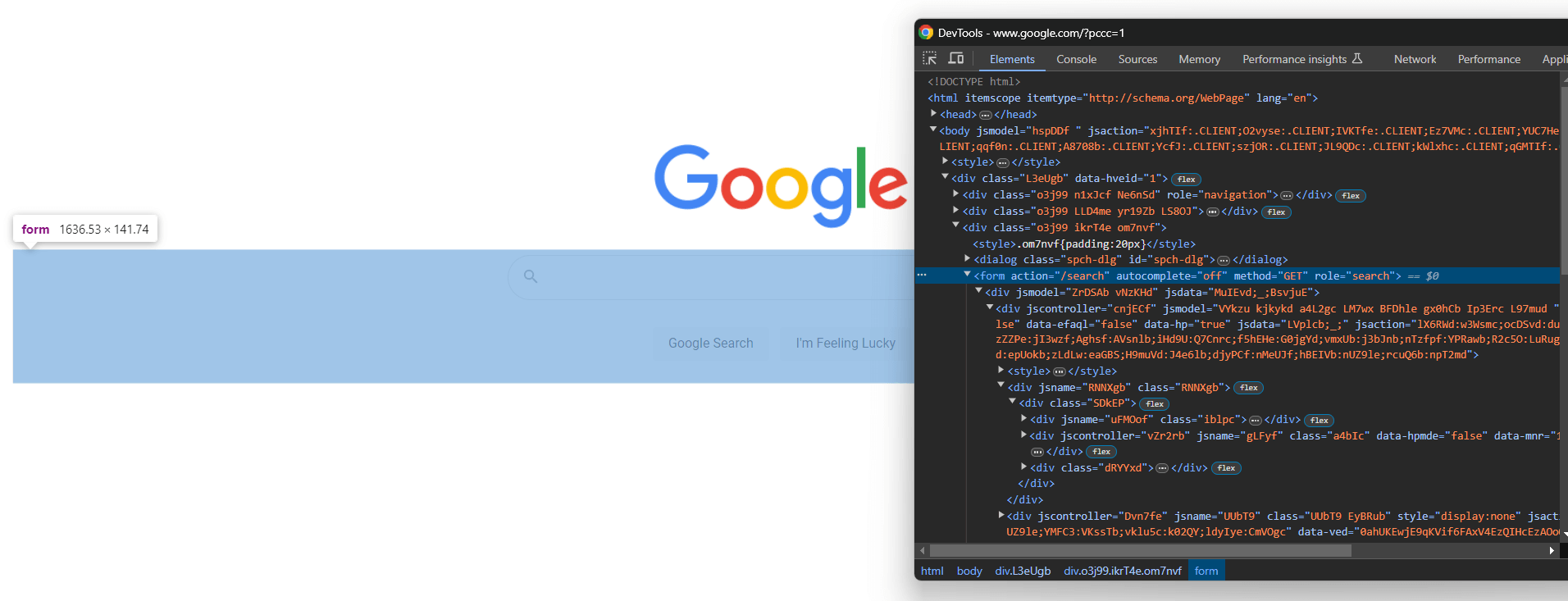
Las clases CSS parecen generarse aleatoriamente, pero puedes seleccionar el formulario apuntando a su atributo de acción con este selector CSS:
form[action='/search']Aplícalo en Selenium para recuperar el elemento del formulario mediante el método find_element():
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")Si ha omitido el paso 5, deberá añadir la siguiente importación:
from selenium.webdriver.common.by import ByExpanda el código HTML del formulario y concéntrese en el área de texto de búsqueda:
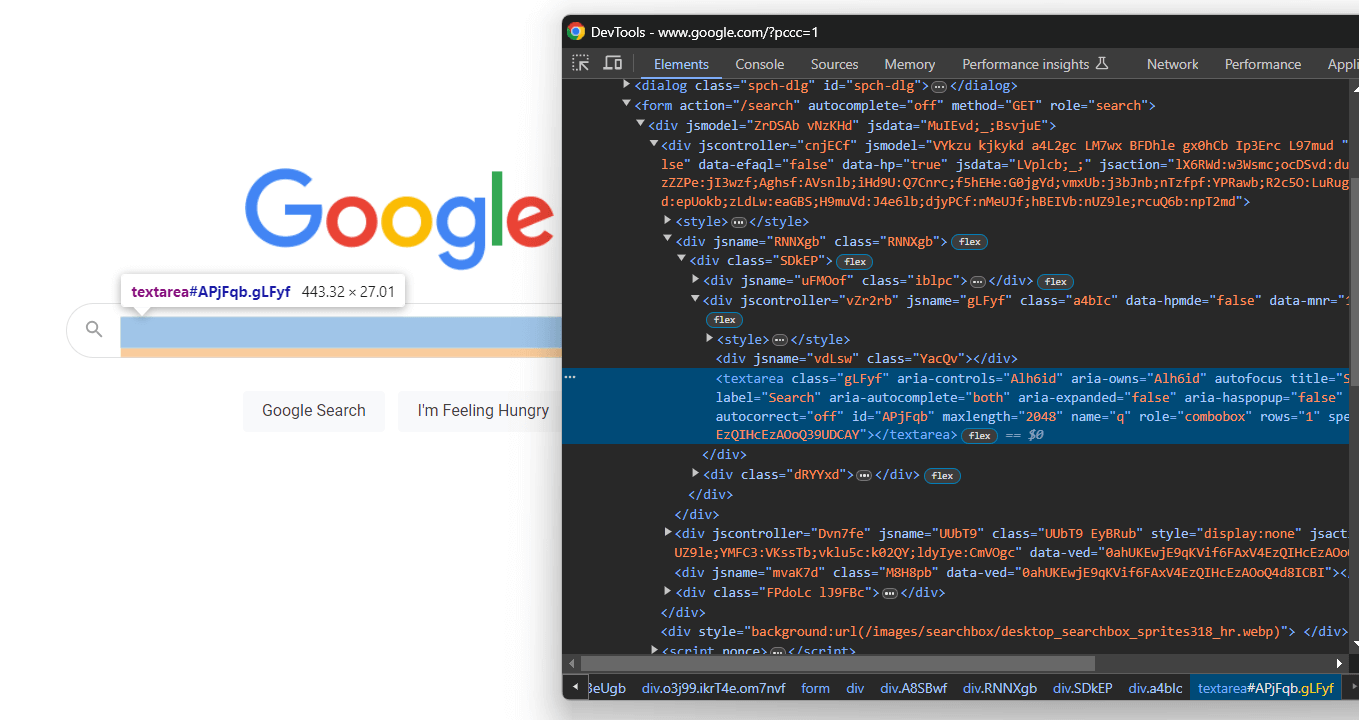
Una vez más, la clase CSS se genera aleatoriamente, pero puede seleccionarla apuntando a su valor aria-label:
textarea[aria-label='Search']Por lo tanto, localice el área de texto dentro del formulario y utilice el botón send_keys() para escribir la consulta de búsqueda de Google:
search_form_textarea= search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)En este caso, la consulta de Google será «datos brillantes». Tenga en cuenta que cualquier otra consulta servirá.
Ahora, llama a submit() en el elemento del formulario para enviarlo y simular una búsqueda en Google:
search_form.submit()Google realizará la búsqueda basándose en la consulta especificada y le redirigirá a la página SERP deseada:
Las líneas para simular una búsqueda en Google en Python con Selenium son:
# selecciona el formulario de búsqueda de Google
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# selecciona el área de texto dentro del formulario
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# rellenar el área de texto con una consulta determinada
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# enviar el formulario y realizar la búsqueda en Google
search_form.submit()¡Ya está! Prepárate para recuperar datos SERP mediante el scraping de Google en Python.
Paso 7: Selecciona los elementos del resultado de la búsqueda
Inspeccione la columna derecha de la sección de resultados:
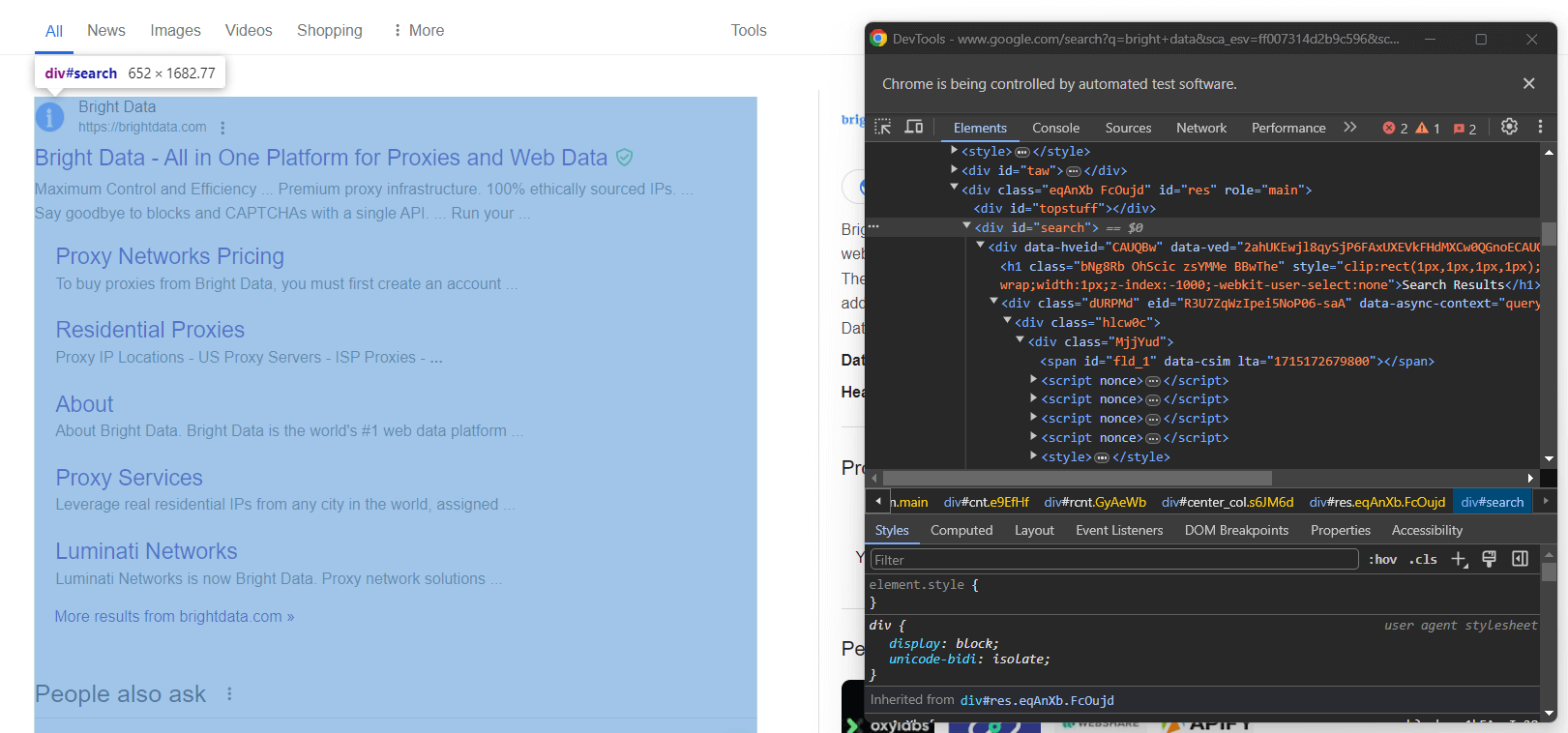
Como puedes ver, se trata de un elemento <div> que puedes seleccionar con el selector CSS siguiente:
#searchNo olvides que las páginas de Google son dinámicas. Por lo tanto, debes esperar a que este elemento esté presente en la página antes de interactuar con él. Para ello, utiliza la siguiente línea:
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))WebDriverWait es una clase especial que ofrece Selenium para implementar esperas explícitas. En concreto, le permite esperar a que se produzca un evento específico en la página.
En este caso, el script esperará hasta 10 segundos a que el nodo HTML #search esté presente en el nodo. De esta manera, puede asegurarse de que la SERP de Google se haya cargado como se desea.
WebDriverWait requiere algunas importaciones adicionales, así que añádelas a scraper.py:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECAhora, inspeccione los elementos de búsqueda de Google:
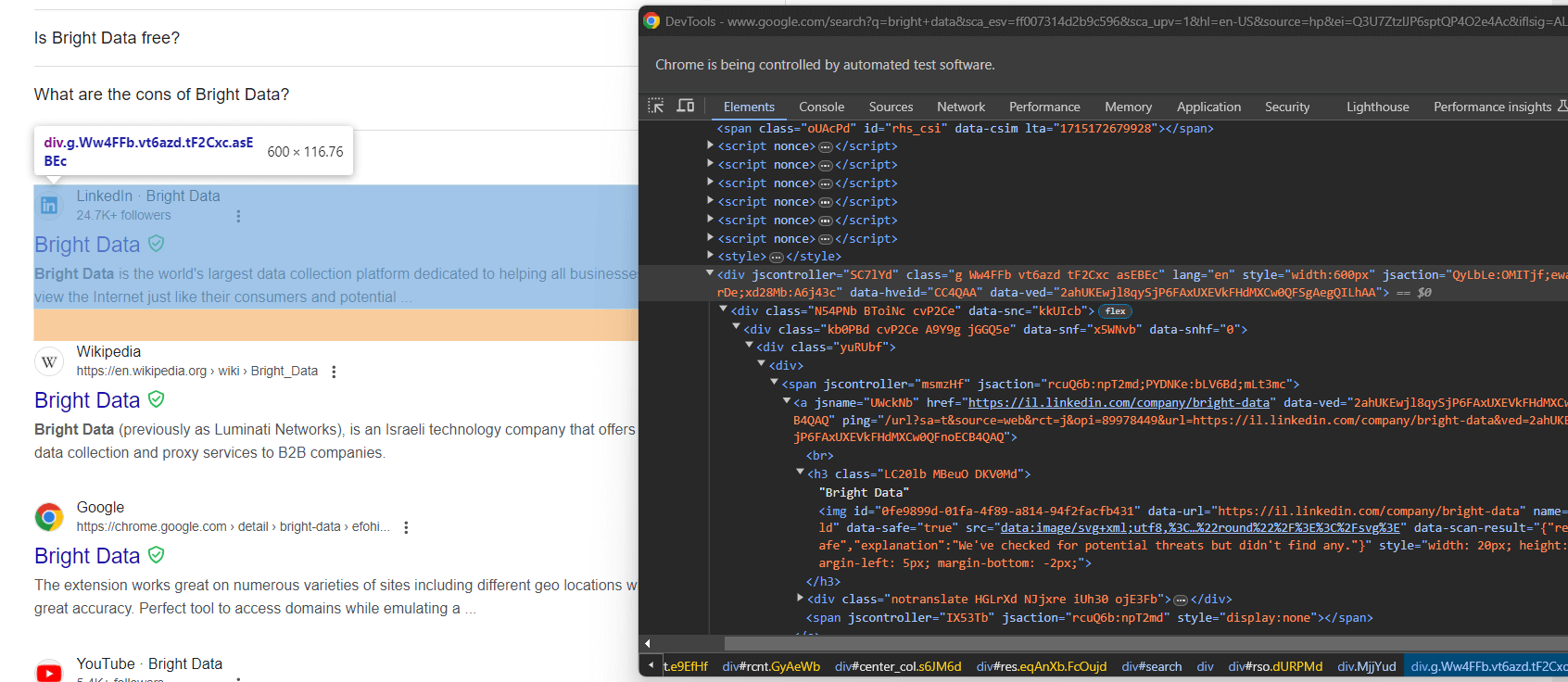
Una vez más, seleccionarlos mediante clases CSS no es un buen enfoque. En su lugar, céntrate en sus atributos HTML inusuales. Un selector CSS adecuado para obtener los elementos de búsqueda de Google es:
div[jscontroller][lang][jsaction][data-hveid][data-ved]Esto identifica todos los <div> que tienen los atributos jscontroller, lang, jsaction, data-hveid y data-ved.
Páselo a find_elements() para seleccionar todos los elementos de búsqueda de Google en Python a través de Selenium:
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")La lógica completa será:
# esperar hasta 10 segundos a que el div de búsqueda aparezca en la página
# y seleccionarlo
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# seleccionar los elementos de búsqueda de Google en la SERP
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")¡Genial! Estás a solo un paso de extraer datos SERP en Python.
Paso 8: Extraer los datos SERP
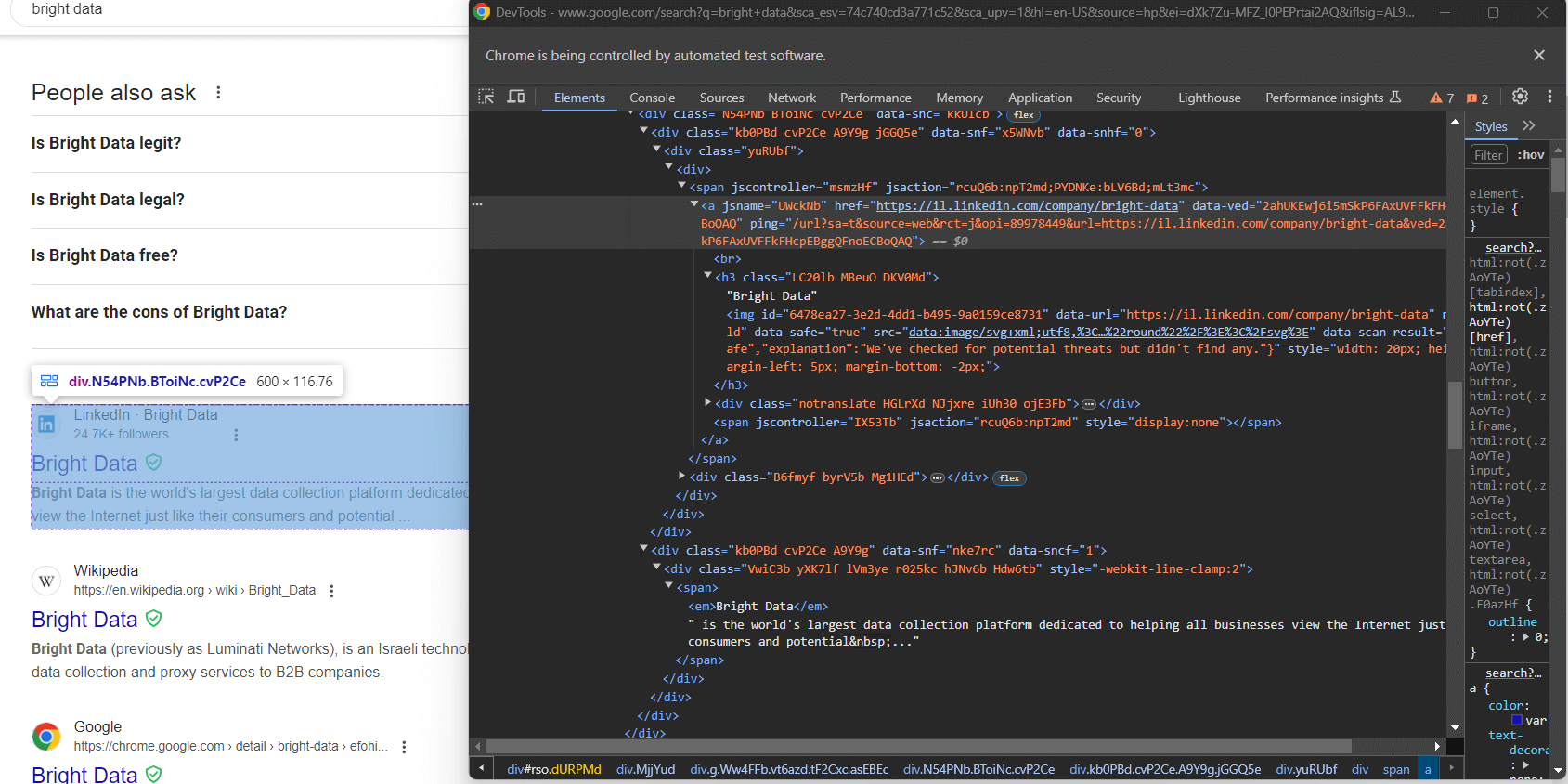
No todas las SERP de Google son iguales. En algunos casos, el primer resultado de búsqueda de la página tiene un código HTML diferente al de los demás elementos de búsqueda:
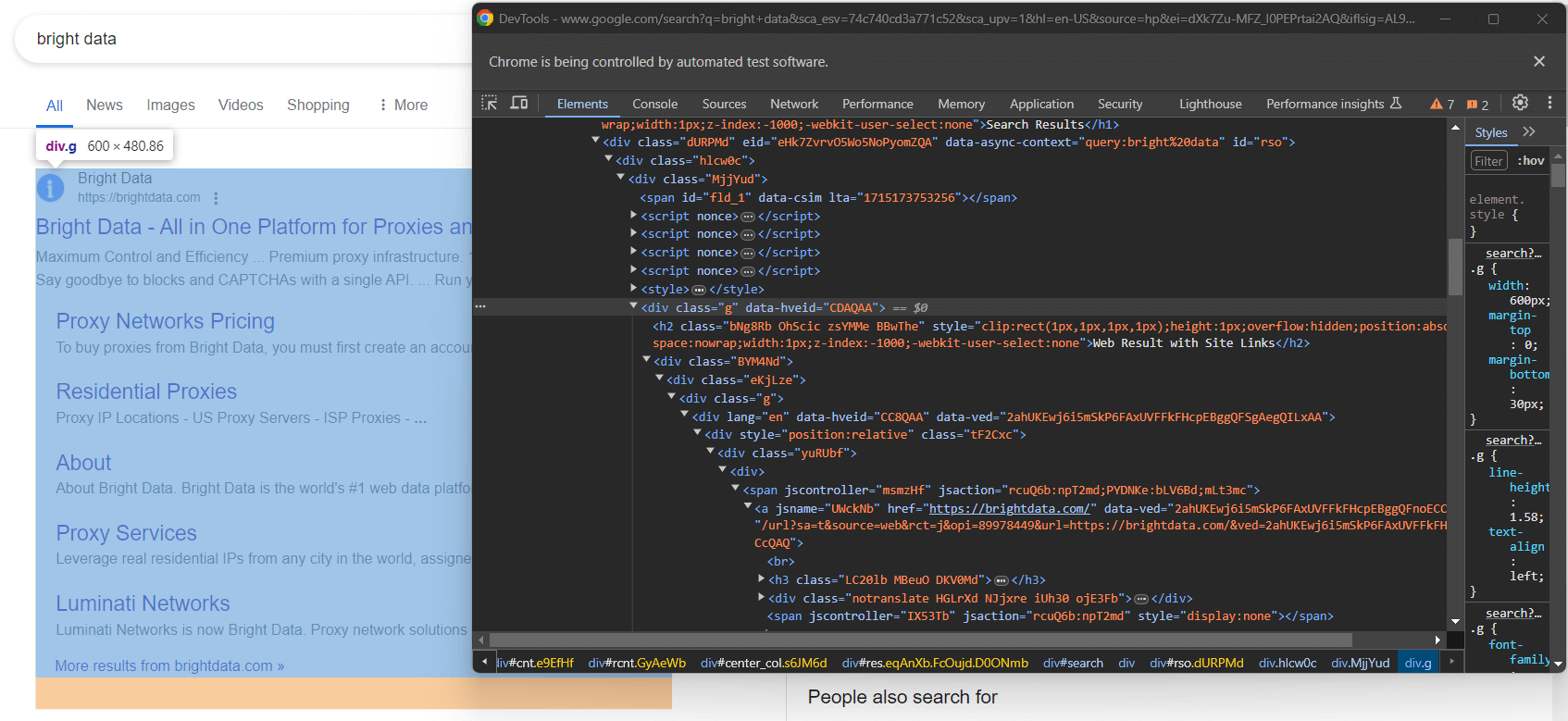
Por ejemplo, en este caso, el primer elemento del resultado de búsqueda se puede recuperar con este selector CSS:
div.g[data-hveid]Aparte de eso, el contenido de los elementos de búsqueda de Google es prácticamente el mismo. Esto incluye:
- El título de la página en un nodo
<h3>. - Una URL a la página específica en un elemento
<a>que es el padre del<h3>anterior. - Una descripción en el
[data-sncf='1'] <div>.
Dado que una sola SERP contiene varios resultados de búsqueda, inicializa una matriz donde almacenar los datos extraídos:
serp_elements = []También necesitará un entero de rango para realizar un seguimiento de su clasificación en la página:
rank = 1Defina una función para extraer elementos de búsqueda de Google en Python de la siguiente manera:
def scrape_search_element(search_element, rank):
# selecciona los elementos de interés dentro del
# elemento de búsqueda, ignorando los que faltan, y aplica
# la lógica de extracción de datos
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
try:
# obtener el elemento «a» que tiene un hijo «h3»
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
except NoSuchElementException:
url = None
try:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
except NoSuchElementException:
description = None
# devuelve un nuevo elemento de datos SERP
return {
'rank': rank,
'url': url,
'title': title,
'description': description
}Google tiende a cambiar mucho sus páginas SERP. Los nodos dentro de los elementos de búsqueda pueden desaparecer, por lo que debes protegerte con sentencias try ... catch. En concreto, cuando un elemento no está en el DOM, find_element() lanza una excepción NoSuchElementException.
Importa la excepción:
from selenium.common import NoSuchElementExceptionTen en cuenta el uso del operador CSS has() para seleccionar un nodo con un hijo específico. Obtén más información al respecto en la documentación oficial.
Ahora, pasa el primer elemento de búsqueda y los restantes a la función scrape_search_element(). A continuación, añade los objetos devueltos a la matriz serp_elements:
# extraer datos del primer elemento de la SERP
# (si está presente)
try:
first_search_element = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(first_search_element, rank))
rank += 1
except NoSuchElementException:
pass
# extraer datos de todos los elementos de búsqueda en la SERP
for google_search_element in google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1Al final de estas instrucciones, serp_elements almacenará todos los datos SERP de interés. Verifícalo imprimiéndolo en la terminal:
print(serp_elements)Esto producirá algo como:
[
{'rank': 1, 'url': 'https://brightdata.com/', 'title': 'Bright Data - All in One Platform for Proxies and Web Data', 'description': None},
{'rank': 2, 'url': 'https://il.linkedin.com/company/bright-data', 'title': 'Bright Data', 'description': "Bright Data es la plataforma de recopilación de datos más grande del mundo dedicada a ayudar a todas las empresas a ver Internet tal y como lo ven sus consumidores y potenciales..."},
# omitido por brevedad...
{'rank': 6, 'url': 'https://aws.amazon.com/marketplace/seller-profile?id=bf9b4324-6ee3-4eb3-9ca4-083e558d04c4', 'title': 'Bright Data - AWS Marketplace', 'description': 'Bright Data es una plataforma líder en recopilación de datos que permite a nuestros clientes recopilar conjuntos de datos estructurados y no estructurados de millones de sitios web...'},
{'rank': 7, 'url': 'https://techcrunch.com/2024/02/26/meta-retira-la-demanda-contra-la-empresa-de-Scraping-web-Bright Data...', 'title': 'Meta retira la demanda contra la empresa de Scraping web Bright Data...', 'description': '26 de febrero de 2024 — Meta ha retirado su demanda contra la empresa israelí de Scraping web Bright Data, tras perder una reclamación clave en su caso hace unas semanas.'}
]¡Increíble! Solo queda exportar los datos extraídos a CSV.
Paso 9: Exportar los datos extraídos a CSV
Ahora que ya sabes cómo extraer datos de Google con Python, veamos cómo exportar los datos recuperados a un archivo CSV.
En primer lugar, importa el paquete csv de la biblioteca estándar de Python:
import csvA continuación, utiliza el paquete csv para rellenar el archivo de salida serp_data.csv con tus datos SERP:
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)¡Et voilà! Tu script de scraping de Google Python está listo.
Paso 10: Ponlo todo junto
Este es el código final de tu script scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import NoSuchElementException
import csv
def scrape_search_element(search_element, rank):
# selecciona los elementos de interés dentro del
# elemento de búsqueda, ignorando los que faltan, y aplica
# la lógica de extracción de datos
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
try:
# obtener el elemento «a» que tiene un hijo «h3»
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
except NoSuchElementException:
url = None
try:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
except NoSuchElementException:
description = None
# devuelve un nuevo elemento de datos SERP
return {
'rank': rank,
'url': url,
'title': title,
'description': description
}
# opciones para iniciar Chrome en modo sin interfaz gráfica
options = Options()
options.add_argument('--headless') # comentarlo durante el desarrollo local
# inicializar una instancia de controlador web con las
# opciones especificadas
driver = webdriver.Chrome(
service=Service(),
options=options)
# conectarse al sitio de destino
driver.get("https://google.com/?hl=en-US")
# seleccionar los botones en el cuadro de diálogo de cookies
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# hacer clic en el botón «Aceptar todo», si está presente
if accept_all_button is not None:
accept_all_button.click()
# seleccionar el formulario de búsqueda de Google
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# selecciona el área de texto dentro del formulario
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# rellena el área de texto con una consulta determinada
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# enviar el formulario y realizar la búsqueda en Google
search_form.submit()
# esperar hasta 10 segundos a que el div de búsqueda aparezca en la página
# y seleccionarlo
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# seleccionar los elementos de búsqueda de Google en la SERP
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")
# dónde almacenar los datos extraídos
serp_elements = []
# para realizar un seguimiento de la clasificación actual
rank = 1
# extraer datos del primer elemento en el SERP
# (si está presente)
try:
first_search_element = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(first_search_element, rank))
rank += 1
except NoSuchElementException:
pass
# extraer datos de todos los elementos de búsqueda en la SERP
for google_search_element in google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1
# exportar los datos extraídos a CSV
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)
# cerrar el navegador y liberar sus recursos
driver.quit()¡Vaya! Con poco más de 100 líneas de código, puedes crear un Scraper de SERP de Google en Python.
Comprueba que produce los resultados esperados ejecutándolo en tu IDE o utilizando este comando:
python Scraper.pyEspera a que finalice la ejecución del Scraper y aparecerá un archivo serp_results.csv en la carpeta raíz del proyecto. Ábrelo y verás:

¡Enhorabuena! Acabas de realizar un rastreo de Google en Python.
Conclusión
En este tutorial, ha visto qué datos se pueden recopilar de Google y por qué los datos SERP son los más interesantes. En concreto, ha aprendido a utilizar la automatización del navegador para crear un Scraper SERP en Python utilizando Selenium.
Esto funciona en ejemplos sencillos, pero hay tres retos principales a la hora de realizar scraping en Google con Python:
- Google cambia constantemente la estructura de las páginas SERP.
- Google cuenta con algunas de las soluciones antibots más avanzadas del mercado.
- Crear un proceso de scraping eficaz que pueda recuperar toneladas de datos SERP en paralelo es complejo y cuesta mucho dinero.
Olvídate de esos retos con la API SERP de Bright Data. Esta API de última generación proporciona un conjunto de puntos finales que exponen datos SERP en tiempo real de todos los principales motores de búsqueda. La API SERP se basa enlos servicios Proxy y las soluciones anti-bot de primera categoría de Bright Data, y se dirige a varios motores de búsqueda sin ningún esfuerzo.
Realice una simple llamada a la API y obtenga sus datos SERP en formato JSON o HTML gracias a la API SERP. ¡Comience hoy mismo su prueba gratuita!





