

Entrenar un modelo de IA consiste en enseñarle a reconocer patrones en los datos para tomar decisiones. El ajuste fino es una estrategia que adapta modelos entrenados en grandes conjuntos de datos, como el GPT-4 de OpenAI, a conjuntos de datos más pequeños y específicos de una tarea mediante la continuación del proceso de entrenamiento.
En las siguientes secciones, profundizaremos en el proceso de entrenamiento de un modelo de IA personalizado utilizando el ajuste fino de OpenAI, guiándole a través de cada paso del proceso de ajuste fino.
Comprender la IA y el entrenamiento de modelos
La Inteligencia Artificial (IA) consiste en desarrollar sistemas capaces de realizar tareas que normalmente requieren una inteligencia similar a la humana, como el aprendizaje, la resolución de problemas y la toma de decisiones. Un modelo de IA, en esencia, es un conjunto de algoritmos que hacen predicciones basadas en datos de entrada. El aprendizaje automático, un subconjunto de la IA, permite a las máquinas aprender de los datos y mejorar su rendimiento de forma autónoma.
Los modelos de IA aprenden como un niño que distingue entre perros y gatos, observando características, haciendo conjeturas, corrigiendo errores y volviendo a intentarlo. Este proceso, conocido como entrenamiento del modelo, implica que el modelo procesa los datos de entrada, analiza y procesa los patrones y utiliza este conocimiento para hacer predicciones. El rendimiento del modelo se evalúa comparando sus resultados con los previstos, y se realizan ajustes para mejorar el rendimiento. Con un entrenamiento suficiente, el conjunto de algoritmos del modelo representará un predictor matemático preciso para una situación dada que puede manejar diferentes variaciones de los datos de entrada.
Entrenar un modelo desde cero implica enseñar a un modelo a aprender patrones en los datos sin ningún conocimiento previo. Esto requiere una gran cantidad de datos y recursos informáticos, y el modelo puede no funcionar bien con datos limitados.
El ajuste fino, por su parte, comienza con un modelo preentrenado que ha aprendido patrones generales a partir de un gran conjunto de datos. A continuación, el modelo se entrena en un conjunto de datos más pequeño y específico, lo que le permite aplicar a la nueva tarea los conocimientos adquiridos previamente y, a menudo, mejorar el rendimiento con menos datos y recursos informáticos. El ajuste fino es especialmente útil cuando el conjunto de datos específico de la tarea es relativamente pequeño.
Preparativos para la puesta a punto
Afinar un modelo existente con un entrenamiento adicional en un conjunto de datos curados puede parecer una opción atractiva frente a construir y entrenar un modelo de IA desde cero. Sin embargo, el éxito del proceso de ajuste depende de varios factores clave.
Elegir el modelo adecuado
A la hora de seleccionar un modelo base para la puesta a punto, ten en cuenta lo siguiente:
Alineación de tareas: Es importante definir claramente el alcance de su problema y la funcionalidad esperada del modelo. Elija modelos que destaquen en tareas similares a las suyas, ya que la disimilitud entre las tareas de origen y destino durante el proceso de ajuste puede reducir el rendimiento. Por ejemplo, para tareas de generación de texto, GPT-3 podría ser adecuado, mientras que para tareas de clasificación de texto, BERT o RoBERTa podrían ser mejores.
Tamaño y complejidad del modelo: Equilibra el rendimiento y la eficiencia según sea necesario porque, aunque los modelos más grandes capturan mejor los patrones complejos, requieren más recursos.
Métricas de evaluación: Elija métricas de evaluación que sean relevantes para su tarea. Por ejemplo, la precisión puede ser importante para la clasificación, mientras que BLEU o ROUGE pueden ser beneficiosos para las tareas de generación de lenguaje.
Comunidad y recursos: Elija modelos con una gran comunidad y amplios recursos para la resolución de problemas y la implementación. Dé prioridad a los modelos con directrices claras de ajuste fino para su tarea y busque fuentes acreditadas de puntos de comprobación de modelos preentrenados.
Recogida y preparación de datos
A la hora de afinar, la calidad y la diversidad de los datos pueden influir significativamente en el rendimiento del modelo. He aquí algunas consideraciones clave:
Tipos de datos necesarios: El tipo de datos depende de la tarea específica y de los datos con los que se haya preentrenado el modelo. Para las tareas de PNL, normalmente se necesitan datos de texto de fuentes como libros, artículos, publicaciones en redes sociales o transcripciones de discursos. Utilice métodos como el web scraping, las encuestas o las API de plataformas de redes sociales para recopilar datos. Por ejemplo, el web scraping con IA puede ser especialmente útil cuando se necesita una gran cantidad de datos diversos y actualizados.
Limpieza y anotación de datos: La limpieza de datos consiste en eliminar los datos irrelevantes, tratar los datos que faltan o son incoherentes y normalizarlos. La anotación consiste en etiquetar los datos para que el modelo pueda aprender de ellos. El uso de herramientas automatizadas como Bright Data puede agilizar estos procesos y mejorar la eficiencia.
Incorporación de un conjunto de datos diverso y representativo: Durante el ajuste del modelo, un conjunto de datos diverso y representativo garantiza que el modelo aprenda desde varias perspectivas, lo que conduce a predicciones más generalizadas y fiables. Por ejemplo, si está afinando un modelo de análisis de opiniones para críticas de películas, su conjunto de datos debe incluir críticas de una amplia gama de películas, géneros y opiniones, reflejando la distribución de clases del mundo real.
Creación del entorno de formación
Asegúrese de que dispone del hardware y el software necesarios para el modelo y el marco de IA elegidos. Por ejemplo, los modelos lingüísticos de gran tamaño (LLM) suelen requerir una potencia de cálculo considerable, normalmente proporcionada por GPU.
Frameworks como TensorFlow o PyTorch se utilizan habitualmente para el entrenamiento de modelos de IA. La instalación de las bibliotecas y herramientas pertinentes, junto con cualquier dependencia adicional, es esencial para una integración perfecta en el flujo de trabajo de formación. Por ejemplo, herramientas como la API Open AI pueden ser necesarias para ajustar modelos específicos desarrollados por OpenAI.
El proceso de ajuste
Una vez comprendidos los fundamentos del ajuste fino, veamos una aplicación en el procesamiento del lenguaje natural.
Utilizaré la API de OpenAI para ajustar un modelo preentrenado. El ajuste fino es posible actualmente para modelos como gpt-3.5-turbo-0125 (recomendado), gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, babbage-002, davinci-002 y el experimental gpt-4-0613. El ajuste fino de GPT-4 está en fase experimental y los usuarios que cumplan los requisitos pueden solicitar acceso en la interfaz de usuario de ajuste fino.
1. Preparación del conjunto de datos
Según un estudio, se ha descubierto que GPT-3.5 carece de razonamiento analítico. Así que vamos a intentar afinar el modelo gpt-3.5-turbo para potenciar su razonamiento analítico utilizando un conjunto de datos de preguntas de razonamiento analítico del Examen de Admisión a la Facultad de Derecho (AR-LSAT), publicado en 2022. El conjunto de datos disponible públicamente se puede encontrar aquí.
La calidad de un modelo ajustado depende directamente de los datos utilizados para el ajuste. Cada ejemplo del conjunto de datos debe ser una conversación formateada según la API de finalización de chat de OpenAI, con una lista de mensajes en la que cada mensaje tenga un rol, un contenido y un nombre opcional, y almacenada como un archivo JSONL.
El formato de chat conversacional requerido para la puesta a punto de gpt-3.5-turboises el siguiente:
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": ""}, {"role": "assistant", "content": ""}]}
En este formato, "mensajes" es una lista de mensajes que forman una conversación entre tres "roles": sistema, usuario y asistente. El "contenido" del rol "sistema ” debe especificar el comportamiento del sistema ajustado.
A continuación se muestra un ejemplo formateado tomado del conjunto de datos AR-LSAT que utilizaremos en esta guía:

Estas son las consideraciones clave a la hora de crear el conjunto de datos:
- Página de precios de OpenAI
- cuaderno para contar fichas
- Script en Python
2. Generación de la clave API e instalación de la biblioteca OpenAI
Para poner a punto un modelo de OpenAI, es obligatorio disponer de una cuenta de desarrollador de OpenAI con saldo suficiente.
Para generar la clave API e instalar la biblioteca OpenAI, sigue estos pasos:
1. Regístrate en la web oficial de OpenAI.
2. Para activar el ajuste fino, recargue su saldo desde la pestaña “Facturación” en “Ajustes”.
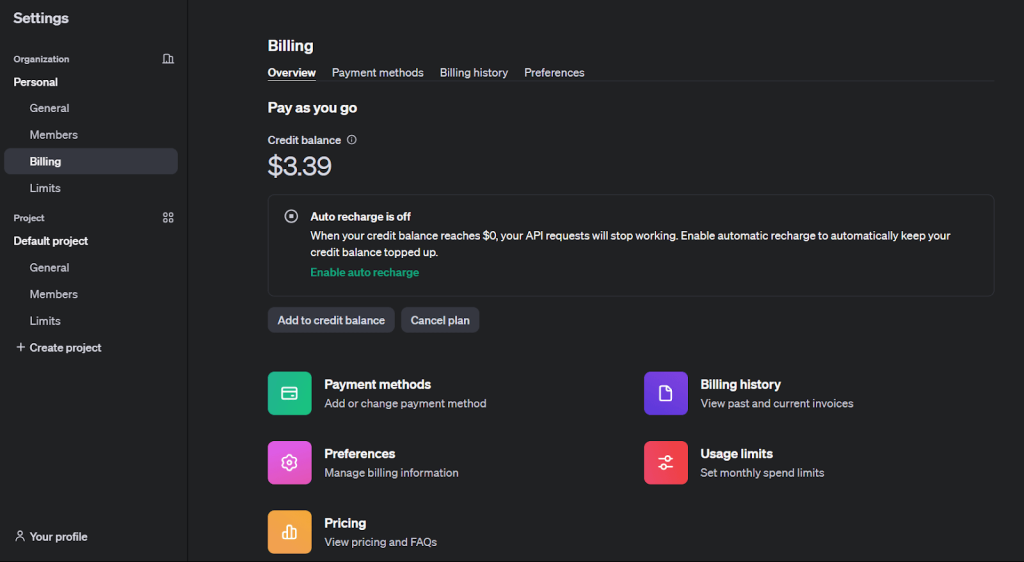
3. Haga clic en el icono de perfil de usuario situado en la esquina superior izquierda y seleccione “Claves API” para acceder a la página de creación de claves.
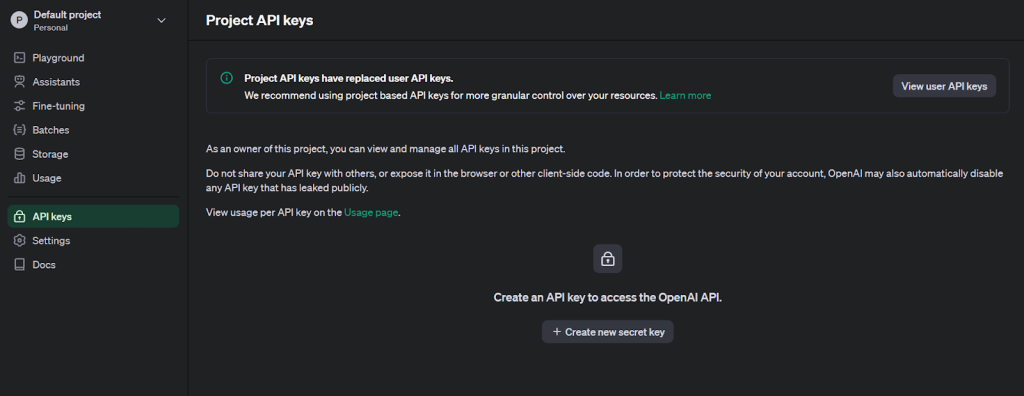
4. Generar una nueva clave secreta proporcionando un nombre.

5. Instale la biblioteca OpenAI de Python para el ajuste fino.
pip install openai
6. Utilice la biblioteca os para establecer el token como variable de entorno y establecer la comunicación API.
import os
from openai import OpenAI
# Set the OPENAI_API_KEY environment variable
os.environ['OPENAI_API_KEY'] = 'The key generated in step 4'
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
3. Carga de los archivos de formación y validación
Después de validar sus datos, cargue los archivos utilizando la API de archivos para trabajos de ajuste.
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune"
)
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")
Los identificadores únicos de los datos de entrenamiento y validación se muestran tras la ejecución correcta.

4. Creación de un trabajo de ajuste
Tras cargar los archivos, cree una tarea de ajuste mediante la interfaz de usuario o mediante programación.
A continuación se explica cómo iniciar un trabajo de ajuste utilizando el SDK de OpenAI:
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs": 10,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
print(f"Training Status: {status}")
model: el nombre del modelo que se va a ajustar(gpt-3.5-turbo,babbage-002,davinci-002, o un modelo ya ajustado).archivo_de_entrenamientoyarchivo_de_validación: los ID de archivo devueltos al cargar los archivos.n_epocs,batch_sizeylearning_rate_multiplier: Hiperparámetros que se pueden personalizar.
Para configurar otros parámetros de ajuste fino, consulte la especificación de la API para el ajuste fino.
El código anterior genera la siguiente información para el jobID (`ftjob-0EVPunnseZ6Xnd0oGcnWBZA7`):

Un trabajo de ajuste puede tardar en completarse. Podría estar en cola detrás de otros trabajos, y la duración del entrenamiento puede variar de minutos a horas en función del modelo y del tamaño del conjunto de datos.
Una vez finalizada la formación, se enviará un correo electrónico de confirmación al usuario que inició el trabajo de ajuste.
Puede supervisar el estado de su trabajo de ajuste fino a través de la interfaz de usuario de ajuste fino:
5. Análisis del modelo ajustado
OpenAI calcula las siguientes métricas durante el entrenamiento:
- Pérdida de formación
- Precisión de las fichas de entrenamiento
- Pérdida por validación
- Precisión de las fichas de validación
La pérdida de validación y la precisión de los tokens de validación se calculan de dos formas: en un pequeño lote de datos en cada paso, y en el conjunto de validación completo al final de cada época. La pérdida de validación completa y la precisión de los tokens de validación completa son las métricas más precisas para realizar un seguimiento del rendimiento del modelo y sirven como comprobación para garantizar un entrenamiento sin problemas (la pérdida debería disminuir y la precisión de los tokens debería aumentar).
Mientras un trabajo de ajuste fino está activo, puede ver estas métricas a través de
1. La IU:

2. La API:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'],)
jobid = ‘jobid you want to monitor’
print(f"Streaming events for the fine-tuning job: {jobid}")
# signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=jobid)
try:
for event in events:
print(
f'{event.data}'
)
except Exception:
print("Stream interrupted (client disconnected).")
El código anterior mostrará los eventos de streaming para el trabajo de ajuste fino, incluyendo el número de pasos, la pérdida de entrenamiento, la pérdida de validación, el total de pasos y la precisión media de los tokens tanto para el entrenamiento como para la validación:
Streaming events for the fine-tuning job: ftjob-0EVPunnseZ6Xnd0oGcnWBZA7
{'step': 67, 'train_loss': 0.30375099182128906, 'valid_loss': 0.49169286092122394, 'total_steps': 67, 'train_mean_token_accuracy': 0.8333333134651184, 'valid_mean_token_accuracy': 0.8888888888888888}
6. Ajustar los parámetros y el conjunto de datos para mejorar el rendimiento
Si los resultados de un trabajo de ajuste no son tan buenos como esperaba, considere las siguientes formas de mejorar el rendimiento:
1. Ajuste el conjunto de datos de entrenamiento:
- Para perfeccionar el conjunto de datos de entrenamiento, considere la posibilidad de añadir ejemplos que aborden los puntos débiles del modelo y asegúrese de que la distribución de las respuestas en sus datos coincide con la distribución esperada.
- También es importante comprobar los datos para detectar problemas que el modelo esté reproduciendo y asegurarse de que los ejemplos contienen toda la información necesaria para la respuesta.
- Mantener la coherencia entre los datos creados por varias personas y estandarizar el formato de todos los ejemplos de formación para que coincidan con lo que se espera en la inferencia.
- En general, los datos de alta calidad son más eficaces que una mayor cantidad de datos de baja calidad.
2. Ajuste de los hiperparámetros:
- OpenAI permite especificar tres hiperparámetros: épocas, multiplicador de la tasa de aprendizaje y tamaño del lote.
- Comience con los valores predeterminados elegidos por las funciones incorporadas en función del tamaño del conjunto de datos y, a continuación, ajústelos si es necesario.
- Si el modelo no sigue los datos de entrenamiento como se esperaba, aumente el número de épocas.
- Si el modelo se diversifica menos de lo esperado, disminuya el número de épocas en 1 ó 2.
- Si el modelo no parece converger, aumente el multiplicador de la tasa de aprendizaje.
7. Utilización de un modelo de control
Actualmente, OpenAI proporciona acceso a los puntos de control de las tres últimas épocas de un trabajo de ajuste. Estos puntos de control son modelos completos que pueden utilizarse para inferir y seguir ajustando.
Para acceder a estos puntos de control, espere a que un trabajo tenga éxito y, a continuación, consulte el punto final de puntos de control con su ID de trabajo de ajuste fino. Cada objeto de punto de control tendrá el campo fine_tuned_model_checkpoint rellenado con el nombre del punto de control del modelo. También puede obtener el nombre del modelo de punto de control a través de la interfaz de usuario de ajuste fino
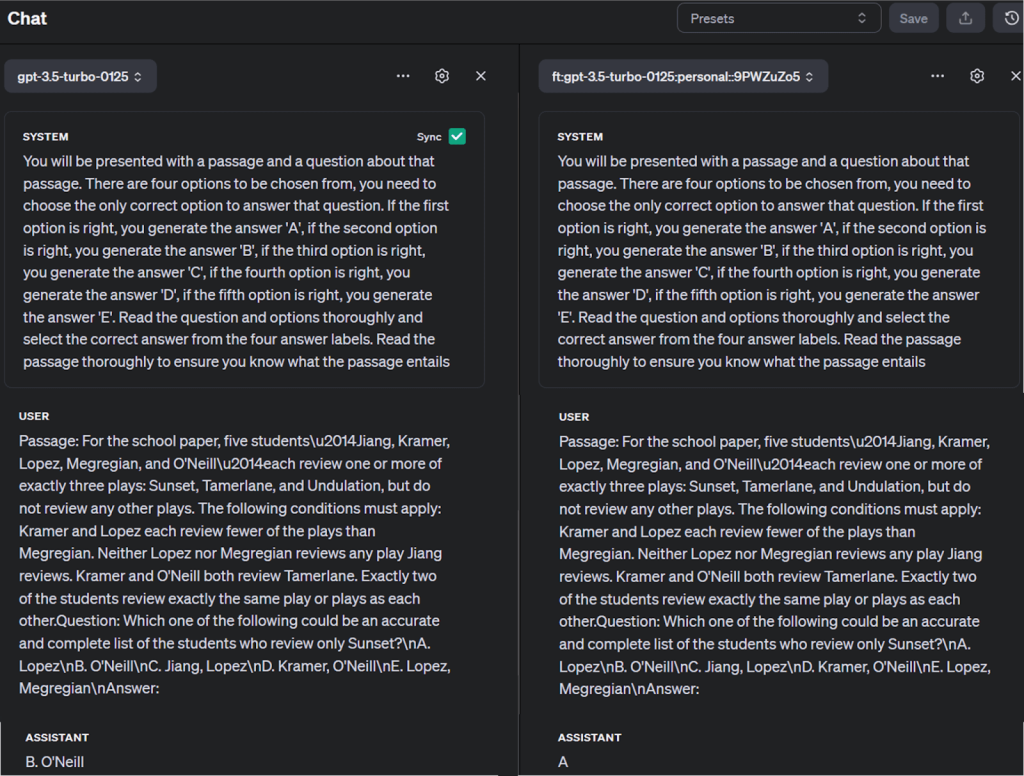
Puede validar los resultados del modelo de punto de control ejecutando consultas con un indicador y el nombre del modelo mediante la función openai.chat.completions.create():
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::9PWZuZo5",
messages=[
{"role": "system", "content": "Instructions: You will be presented with a passage and a question about that passage. There are four options to be chosen from, you need to choose the only correct option to answer that question. If the first option is right, you generate the answer 'A', if the second option is right, you generate the answer 'B', if the third option is right, you generate the answer 'C', if the fourth option is right, you generate the answer 'D', if the fifth option is right, you generate the answer 'E'. Read the question and options thoroughly and select the correct answer from the four answer labels. Read the passage thoroughly to ensure you know what the passage entails"},
{"role": "user", "content": "Passage: For the school paper, five studentsu2014Jiang, Kramer, Lopez, Megregian, and O'Neillu2014each review one or more of exactly three plays: Sunset, Tamerlane, and Undulation, but do not review any other plays. The following conditions must apply: Kramer and Lopez each review fewer of the plays than Megregian. Neither Lopez nor Megregian reviews any play Jiang reviews. Kramer and O'Neill both review Tamerlane. Exactly two of the students review exactly the same play or plays as each other.Question: Which one of the following could be an accurate and complete list of the students who review only Sunset?nA. LopeznB. O'NeillnC. Jiang, LopeznD. Kramer, O'NeillnE. Lopez, MegregiannAnswer:"}
]
)
print(completion.choices[0].message)
El resultado recuperado del diccionario de respuestas es:

También puedes comparar el modelo ajustado con otros modelos del patio de recreo de OpenAI, como se muestra a continuación:
Consejos y buenas prácticas
Para afinar con éxito, tenga en cuenta estos consejos:
Calidad de los datos: Asegúrese de que los datos específicos de la tarea son limpios, diversos y representativos para evitar el sobreajuste, en el que el modelo funciona bien con los datos de entrenamiento pero mal con los datos no vistos.
Selección de hiperparámetros: Elegir los hiperparámetros adecuados para evitar una convergencia lenta o un rendimiento subóptimo. Esto puede ser complejo y llevar mucho tiempo, pero es crucial para un entrenamiento eficaz.
Gestión de recursos: Ten en cuenta que el ajuste fino de grandes modelos requiere tiempo y recursos informáticos considerables.
Evitar escollos
Sobreajuste e infraajuste: Equilibra la complejidad de tu modelo y la cantidad de entrenamiento para evitar el sobreajuste (alta varianza) y el infraajuste (alto sesgo).
Olvido catastrófico: Durante la puesta a punto, el modelo puede olvidar conocimientos generales previamente aprendidos. Para evitarlo, evalúa periódicamente el rendimiento de tu modelo en diversas tareas.
Sensibilidad al cambio de dominio: Si sus datos de ajuste difieren significativamente de los datos de preentrenamiento, puede encontrarse con problemas de cambio de dominio. Utilice técnicas de adaptación de dominios para salvar esta diferencia.
Guardar y reutilizar modelos
Después del entrenamiento, guarda el estado de tu modelo para reutilizarlo más tarde. Esto incluye los parámetros del modelo y cualquier estado del optimizador que se haya utilizado. Esto te permite reanudar el entrenamiento más tarde desde el mismo estado.
Consideraciones éticas
Amplificación de sesgos: Los modelos preentrenados pueden heredar sesgos, que pueden amplificarse durante el ajuste. Intente siempre optar por modelos preentrenados sometidos a pruebas de sesgo y equidad si se requieren predicciones no sesgadas.
Resultados imprevistos: Los modelos perfeccionados pueden generar resultados plausibles pero incorrectos. Implemente mecanismos sólidos de postprocesamiento y validación para hacer frente a esta situación.
Deriva del modelo: El rendimiento de un modelo puede deteriorarse con el tiempo debido a cambios en el entorno o en la distribución de los datos. Supervise regularmente el rendimiento de su modelo y reajústelo si es necesario.
Técnicas avanzadas y perfeccionamiento
Entre las técnicas avanzadas de ajuste fino de los LLM se encuentran la adaptación de bajo rango (Low Ranking Adaptation, LoRA) y la adaptación de bajo rango cuantificada (Quantized LoRA, QLoRA), que reducen los costes computacionales y financieros al tiempo que mantienen el rendimiento. Parameter Efficient Fine Tuning (PEFT) adapta eficazmente los modelos con un mínimo de parámetros entrenables. DeepSpeed y ZeRO optimizan el uso de la memoria para el entrenamiento a gran escala. Estas técnicas abordan retos como el sobreajuste, el olvido catastrófico y la sensibilidad al cambio de dominio, mejorando la eficiencia y la eficacia del ajuste fino LLM.
Además del ajuste fino, existen otras técnicas avanzadas de formación, como el aprendizaje por transferencia y el aprendizaje por refuerzo. El aprendizaje por transferencia consiste en aplicar los conocimientos aprendidos en un problema a otro problema relacionado, mientras que el aprendizaje por refuerzo es un tipo de aprendizaje automático en el que un agente aprende a tomar decisiones realizando acciones en un entorno para maximizar una recompensa.
Para los interesados en profundizar en la formación de modelos de IA, los siguientes recursos pueden resultar útiles:
- Attention is all you need por Ashish Vaswani et al.
- El libro “Deep Learning” de Ian Goodfellow, Yoshua Bengio y Aaron Courville
- El libro “Speech and Language Processing” de Daniel Jurafsky y James H. Martin
- Diferentes formas de formar a los LLM
- Dominar las técnicas LLM: Formación
- Curso de PNL de Hugging Face
Conclusión
Entrenar un modelo de IA es un proceso que requiere una cantidad significativa de datos de alta calidad. Aunque definir el problema, seleccionar un modelo y refinarlo mediante iteraciones es esencial, el verdadero diferenciador es la calidad y el volumen de los datos utilizados. En lugar de construir y mantener raspadores web, puede simplificar la recopilación de datos mediante el uso de conjuntos de datos preconstruidos o personalizados disponibles en la plataforma de Bright Data.
Con el mercado de conjuntos de datos, puede acceder a conjuntos de datos validados y listos para usar de sitios web populares, o puede generar conjuntos de datos personalizados para satisfacer sus necesidades específicas utilizando la plataforma automatizada. De este modo, podrá centrarse en entrenar sus modelos de forma eficiente con datos precisos y conformes, lo que le permitirá obtener resultados más rápidos y fiables en diversos sectores.
Explore las soluciones de conjuntos de datos de Bright Data e intégrelas fácilmente en su flujo de trabajo para recopilar datos sin problemas.
Regístrese ahora y comience su prueba gratuita de la infraestructura de scraping de Bright Data, que incluye muestras gratuitas de conjuntos de datos.






