

Si te interesa el raspado web, Crawlee puede ayudarte. Es un motor de raspado rápido e interactivo que utilizan los científicos de datos, desarrolladores e investigadores para recopilar datos web. Crawlee es fácil de configurar y ofrece funciones como la rotación de proxy y la gestión de sesiones. Estas funciones son cruciales para raspar sitios web grandes o dinámicos sin que bloqueen tu dirección IP, lo que garantiza una recopilación de datos fluida e ininterrumpida.
En este tutorial, aprenderás a usar Crawlee para el raspado web. Empezarás con un ejemplo básico de raspado web y pasarás a conceptos más avanzados, como la gestión de sesiones y el raspado de páginas dinámicas.
Cómo hacer raspado web con Crawlee
Antes de comenzar este tutorial, asegúrate de tener instalados los siguientes requisitos previos en tu dispositivo:
- Node.js
- npm: normalmente está incluido con Node.js. Puedes verificar la instalación ejecutando
node -vonpm -ven tu terminal. - Un editor de código de tu elección: este tutorial usa Visual Studio Code.
Raspado web básico con Crawlee
Una vez que tengas todos los requisitos previos, empecemos por raspar el sitio web Books to Scrape, que es perfecto para aprender, ya que proporciona una estructura HTML sencilla.
Abre tu terminal o intérprete de comandos y comienza inicializando un proyecto de Node.js con los siguientes comandos:
mkdir crawlee-tutorial
cd crawlee-tutorial
npm init -y
A continuación, instala la biblioteca de Crawlee con el siguiente comando:
npm install crawlee
Para raspar datos de cualquier sitio web de forma eficaz, debes inspeccionar la página web que deseas raspar para obtener los detalles de las etiquetas HTML del sitio web. Para hacerlo, abre el sitio web en tu navegador y entra en las Herramientas para desarrolladores haciendo clic con el botón derecho en cualquier parte de la página web. A continuación, haz clic en Inspeccionar o Inspeccionar elemento:
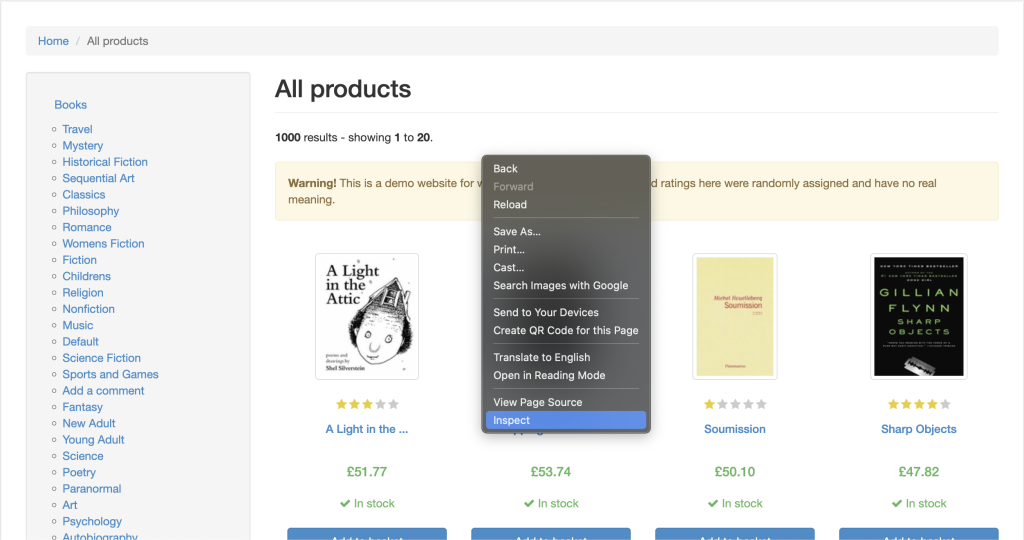
La pestaña Elementos debería estar activa de forma predeterminada y esta pestaña representa el diseño HTML de la página web. En este ejemplo, todos los libros mostrados se colocan en una etiqueta HTML article con la clase product_pod. Dentro de cada artículo, el título del libro aparece en una etiqueta h3. El título real del libro aparece en el atributo title de la etiqueta a ubicada en el elemento h3. El precio del libro aparece dentro de la etiqueta p con la clase price_color:
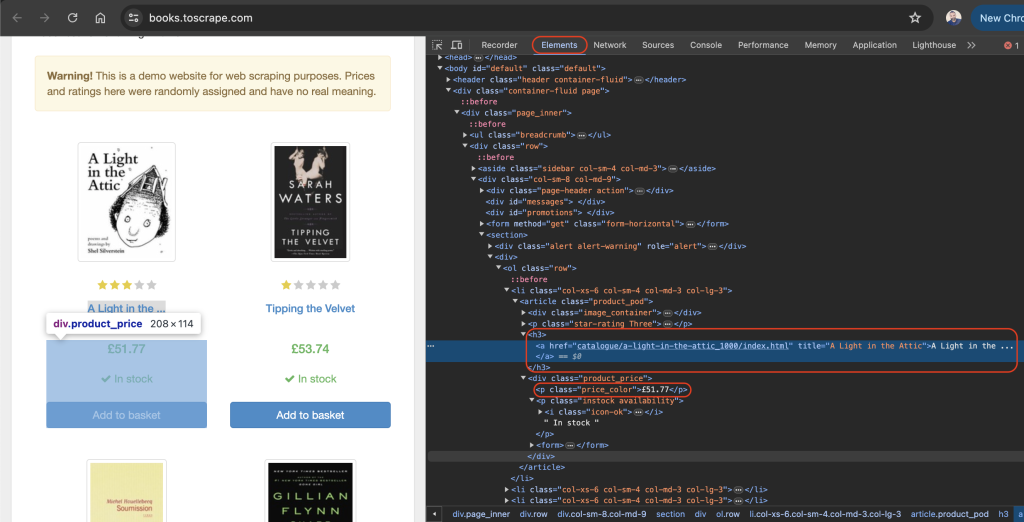
En el directorio raíz de tu proyecto, crea un archivo llamado scrape.js y añade el siguiente código:
const { CheerioCrawler } = require('crawlee');
const crawler = new CheerioCrawler({
async requestHandler({ request, $ }) {
const books = [];
$('article.product_pod').each((index, element) => {
const title = $(element).find('h3 a').attr('title');
const price = $(element).find('.price_color').text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(['https://books.toscrape.com/']);
En este código, utilizas CheerioCrawler de crawlee para raspar títulos y precios de libros de https://books.toscrape.com/. El rastreador obtiene contenido HTML, extrae datos de elementos <article class="product_pod"> con una sintaxis tipo jQuery y registra los resultados en la consola.
Una vez que hayas añadido el código anterior a tu archivo scrape.js, puedes ejecutar el código con el siguiente comando:
node scrape.js
Debería imprimirse una serie de títulos y precios de libros en tu terminal:
…output omitted…
{
title: 'The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics',
price: '£22.60'
},
{ title: 'The Black Maria', price: '£52.15' },
{
title: 'Starving Hearts (Triangular Trade Trilogy, #1)',
price: '£13.99'
},
{ title: "Shakespeare's Sonnets", price: '£20.66' },
{ title: 'Set Me Free', price: '£17.46' },
{
title: "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)",
price: '£52.29'
},
…output omitted…
Rotación de proxy con Crawlee
Un proxy es el intermediario entre tu ordenador e Internet. Cuando usas un proxy, envía tus solicitudes web al servidor proxy, que las reenvía al sitio web de destino. El servidor proxy devuelve la respuesta del sitio web, oculta tu dirección IP e impide que se limite la velocidad o que bloqueen tu IP.
Crawlee facilita la implementación del proxy porque incluye una gestión de proxy integrada, que administra de manera eficiente los reintentos y los errores. Crawlee también admite una variedad de configuraciones de proxy para implementar proxies rotativos.
En la siguiente sección, configurarás un proxy obteniendo primero un proxy válido. A continuación, verificarás que tus solicitudes pasen por los proxies.
Configura un proxy
Por lo general, no se recomiendan los proxies gratuitos porque pueden ser lentos e inseguros, y es posible que no tengan el soporte necesario para tareas web delicadas. En su lugar, considera usar Bright Data, un servicio de proxy seguro, estable y fiable. También ofrece pruebas gratuitas, por lo que puedes probarlo antes de comprometerte.
Para usar Bright Data, haz clic en el botón Iniciar prueba gratuita en su página de inicio y completa la información requerida para crear una cuenta.
Cuando hayas creado tu cuenta, inicia sesión en el panel de control de Bright Data, navega hasta Infraestructura de proxies y raspado y añade un nuevo proxy seleccionando Proxies residenciales:
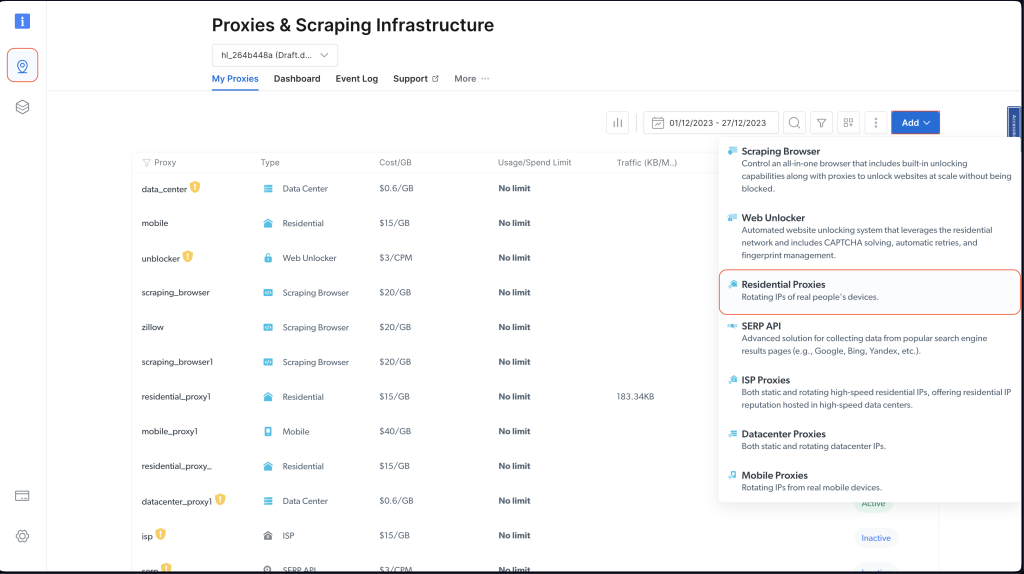
Conserva la configuración predeterminada y finaliza la creación de tu proxy residencial pulsando Añadir.
Si se te pide que instales un certificado, puedes seleccionar Continuar sin certificado. Sin embargo, para los casos prácticos reales y de producción, debes configurar el certificado para evitar el uso indebido si la información de tu proxy queda expuesta en algún momento.
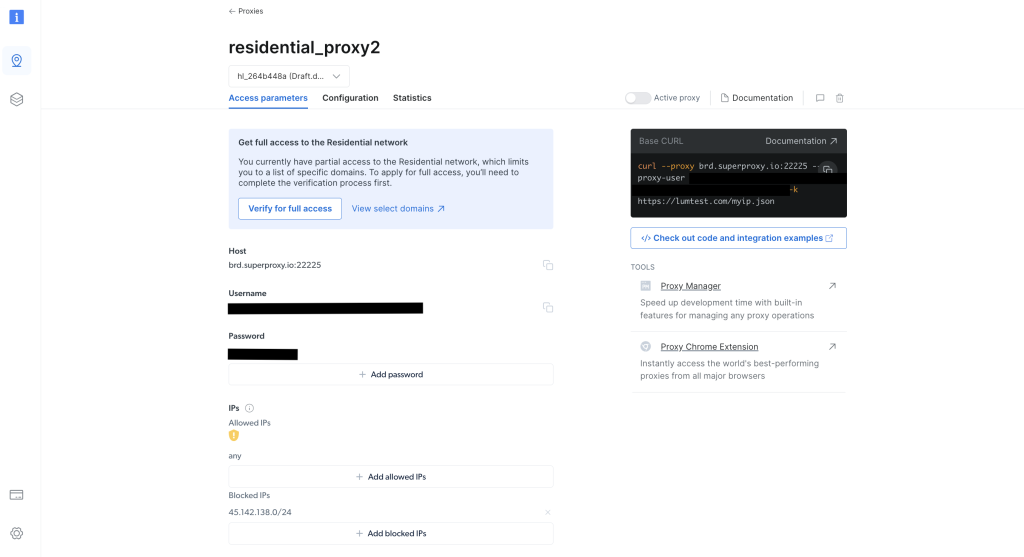
Una vez creado, toma nota de las credenciales del proxy, incluidos el host, el puerto, el nombre de usuario y la contraseña. Las necesitarás en el siguiente paso:
En el directorio raíz de tu proyecto, ejecuta el siguiente comando para instalar la biblioteca axios:
npm install axios
Utiliza la biblioteca axios para realizar una solicitud GET a http://lumtest.com/myip.json, que devuelve los detalles del proxy que utilizas cada vez que ejecutas la secuencia de comandos.
A continuación, en el directorio raíz de tu proyecto, crea un archivo llamado scrapeWithProxy.js y añade el siguiente código:
const { CheerioCrawler } = require("crawlee");
const { ProxyConfiguration } = require("crawlee");
const axios = require("axios");
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ["http://USERNAME:PASSWORD@HOST:PORT"],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
async requestHandler({ request, $, response, proxies }) {
// Make a GET request to the proxy information URL
try {
const proxyInfo = await axios.get("http://lumtest.com/myip.json", {
proxy: {
host: "HOST",
port: PORT,
auth: {
username: "USERNAME",
password: "PASSWORD",
},
},
});
console.log("Proxy Information:", proxyInfo.data);
} catch (error) {
console.error("Error fetching proxy information:", error.message);
}
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(["https://books.toscrape.com/"]);
Nota: asegúrate de reemplazar
HOST,PORT,USERNAMEyPASSWORDpor tus credenciales.
En este código, estás usando CheerioCrawler de crawlee para raspar información de https://books.toscrape.com/ mediante un proxy específico. El proxy se configura con ProxyConfiguration y, a continuación, se obtienen y registran los detalles del proxy mediante una solicitud GET dirigida a http://lumtest.com/myip.json. Por último, extraes los títulos y precios de los libros con una sintaxis tipo jQuery de Cheerio y registras los datos raspados en la consola.
Ahora puedes ejecutar y probar el código para asegurarte de que los proxies funcionan:
node scrapeWithProxy.js
Verás resultados similares a los de antes, pero esta vez tus solicitudes se envían a través de proxies de Bright Data. También deberías ver los detalles del proxy registrado en la consola:
Proxy Information: {
country: 'US',
asn: { asnum: 21928, org_name: 'T-MOBILE-AS21928' },
geo: {
city: 'El Paso',
region: 'TX',
region_name: 'Texas',
postal_code: '79925',
latitude: 31.7899,
longitude: -106.3658,
tz: 'America/Denver',
lum_city: 'elpaso',
lum_region: 'tx'
}
}
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
{ title: 'Soumission', price: '£50.10' },
{ title: 'Sharp Objects', price: '£47.82' },
{ title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },
{ title: 'The Requiem Red', price: '£22.65' },
…output omitted..
Si vuelves a ejecutar la secuencia de comandos con el nodo scrapingWithBrightData.js, observarás que el servidor proxy de Bright Data utiliza una ubicación de dirección IP diferente. Esto valida que Bright Data rota las ubicaciones y las IP cada vez que ejecuta la secuencia de comandos de raspado. Esta rotación es importante para evitar bloqueos o prohibiciones de IP en los sitios web objetivo.
Nota: en
proxyConfiguration, es posible que hayas pasado diferentes IP de proxy, pero como Bright Data lo hace por ti, no necesitas especificar las IP.
Gestión de sesiones con Crawlee
Las sesiones ayudan a mantener el estado de varias solicitudes, lo que resulta útil para los sitios web que utilizan cookies o sesiones de inicio de sesión.
Para gestionar una sesión, crea un archivo llamado scrapeWithSessions.js en el directorio raíz de tu proyecto y añade el siguiente código:
const { CheerioCrawler, SessionPool } = require("crawlee");
(async () => {
// Open a session pool
const sessionPool = await SessionPool.open();
// Ensure there is a session in the pool
let session = await sessionPool.getSession();
if (!session) {
session = await sessionPool.createSession();
}
const crawler = new CheerioCrawler({
useSessionPool: true, // Enable session pool
async requestHandler({ request, $, response, session }) {
// Log the session information
console.log(`Using session: ${session.id}`);
// Extract book data and log it (for demonstration)
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
// First run
await crawler.run(["https://books.toscrape.com/"]);
console.log("First run completed.");
// Second run
await crawler.run(["https://books.toscrape.com/"]);
console.log("Second run completed.");
})();
En este caso, estás usando CheerioCrawler y SessionPool de crawlee para raspar datos de https://books.toscrape.com/. Inicializas un grupo de sesiones y, a continuación, configuras el rastreador para utilizar esta sesión. La función requestHandler registra la información de la sesión y extrae los títulos y precios de los libros utilizando los selectores tipo jQuery de Cheerio. El código realiza dos ejecuciones de raspado consecutivas y registra el identificador de sesión en cada ejecución.
Ejecuta y prueba el código para validar que se estén utilizando diferentes sesiones:
node scrapeWithSessions.js
Deberías ver resultados similares a los de antes, pero esta vez también deberías ver el identificador de sesión de cada ejecución:
Using session: session_GmKuZ2TnVX
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Using session: session_lNRxE89hXu
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Si vuelves a ejecutar el código, verás que se está utilizando un identificador de sesión diferente.
Gestión dinámica de contenido con Crawlee
Si se trata de sitios web dinámicos (es decir, sitios web con contenido rellenado con JavaScript), el raspado web puede resultar extremadamente difícil porque es necesario renderizar JavaScript para acceder a los datos. Para gestionar estas situaciones, Crawlee se integra con Puppeteer, que es un navegador sin interfaz que puede renderizar JavaScript e interactuar con el sitio web objetivo tal como lo haría un humano.
Para demostrar esta funcionalidad, vamos a raspar el contenido de esta página de YouTube. Como siempre, antes de borrar cualquier cosa, asegúrate de revisar las reglas y condiciones de servicio de esa página.
Tras revisar los términos de servicio, crea un archivo llamado scrapeDynamicContent.js en el directorio raíz de tu proyecto y añade el siguiente código:
const { PuppeteerCrawler } = require("crawlee");
async function scrapeYouTube() {
const crawler = new PuppeteerCrawler({
async requestHandler({ page, request, enqueueLinks, log }) {
const { url } = request;
await page.goto(url, { waitUntil: "networkidle2" });
// Scraping first 10 comments
const comments = await page.evaluate(() => {
return Array.from(document.querySelectorAll("#comments #content-text"))
.slice(0, 10)
.map((el) => el.innerText);
});
log.info(`Comments: ${comments.join("n")}`);
},
launchContext: {
launchOptions: {
headless: true,
},
},
});
// Add the URL of the YouTube video you want to scrape
await crawler.run(["https://www.youtube.com/watch?v=wZ6cST5pexo"]);
}
scrapeYouTube();
A continuación, ejecuta el código con el siguiente comando:
node scrapeDynamicContent.js
En este código, utilizas PuppeteerCrawler de la biblioteca de Crawlee para raspar los comentarios de los vídeos de YouTube. Empieza por inicializar un rastreador que navega hasta una URL de vídeo de YouTube específica y espera a que la página se cargue por completo. Una vez cargada la página, el código evalúa el contenido de la página para extraer los diez primeros comentarios seleccionando los elementos con el selector CSS especificado #comments #content -text. A continuación, los comentarios se registran en la consola.
El resultado debería incluir los diez primeros comentarios relacionados con el vídeo seleccionado:
INFO PuppeteerCrawler: Starting the crawler.
INFO PuppeteerCrawler: Comments: Who are you rooting for?? US Marines or Ex Cons
Bro Mateo is a beast, no lifting straps, close stance.
ex convict doing the pushups is a monster.
I love how quick this video was, without nonsense talk and long intros or outros
"They Both have combat experience" is wicked
That military guy doing that deadlift is really no joke.. ...
One lives to fight and the other fights to live.
Finally something that would test the real outcome on which narrative is true on movies
I like the comradery between all of them. Especially on the Bench Press ... Both team members quickly helped out on the spotting to protect from injury. Well done.
I like this style, no youtube funny business. Just straight to the lifts
…output omitted…
Puedes encontrar todo el código usado en este tutorial en GitHub.
Conclusión
En este artículo, has aprendido a usar Crawlee para el raspado web y has observado cómo puede ayudar a mejorar la eficiencia y la fiabilidad de tus proyectos de raspado web.
Recuerda respetar siempre el archivo robots.txt del sitio web objetivo y las condiciones de servicio al raspar datos.
¿Estás preparado para mejorar tus proyectos de raspado web con datos, herramientas y proxies de nivel profesional? Explora la completa plataforma de raspado web de Bright Data, que ofrece conjuntos de datos listos para usar y servicios de proxy avanzados para optimizar tus esfuerzos de recopilación de datos.
¡Regístrate ahora y comienza tu prueba gratuita!





