

En esta guía aprenderás:
- Por qué Gemini es una gran solución para el scraping web basado en IA
- Cómo usarlo para scrapear un sitio en Python a través de un tutorial guiado
- La mayor limitación de esta forma de raspar la Web y cómo superarla
Sumerjámonos.
¿Por qué utilizar Gemini para el Web Scraping?
Gemini es una familia de modelos de IA multimodal desarrollados por Google que pueden analizar e interpretar texto, imágenes, audio, vídeos y código. El uso de Gemini para el web scraping simplifica la extracción de datos al automatizar la interpretación y estructuración de contenidos no estructurados. Esto elimina la necesidad del esfuerzo manual, especialmente cuando se trata de analizar datos.
En detalle, estos son algunos de los casos de uso más comunes de Gemini en el raspado web:
- Páginas que cambian frecuentemente de estructura: Gemini puede gestionar páginas dinámicas en las que el diseño o los elementos de datos cambian con frecuencia, como en sitios de comercio electrónico como Amazon.
- Páginas con muchos datos no estructurados: Destaca en la extracción de información útil de grandes volúmenes de texto desorganizado.
- Páginas en las que resulta difícil escribir una lógica de análisis sintáctico personalizada: Para páginas con estructuras complejas o impredecibles, Gemini puede automatizar el proceso sin necesidad de intrincadas reglas de análisis sintáctico.
Los escenarios de uso más comunes para Gemini en el raspado web incluyen:
- RAG (Recuperación-Generación mejorada): Combinación de raspado de datos en tiempo real para mejorar los conocimientos de IA. Para ver un ejemplo completo con una tecnología de IA similar, sigue nuestro tutorial sobre cómo crear un chatbot RAG con datos de SERP.
- Raspado de redes sociales: Recopilación de datos estructurados de plataformas con contenido dinámico.
- Agregación de contenidos: Recopilación de noticias, artículos o entradas de blog de múltiples fuentes para crear resúmenes o análisis.
Para obtener más información, consulte nuestra guía sobre el uso de la IA para el web scraping.
Web Scraping con Gemini en Python: Guía paso a paso
Como sitio de destino para esta sección, utilizaremos una página de producto específica del sandbox “Ecommerce Test Site to Learn Web Scraping“:
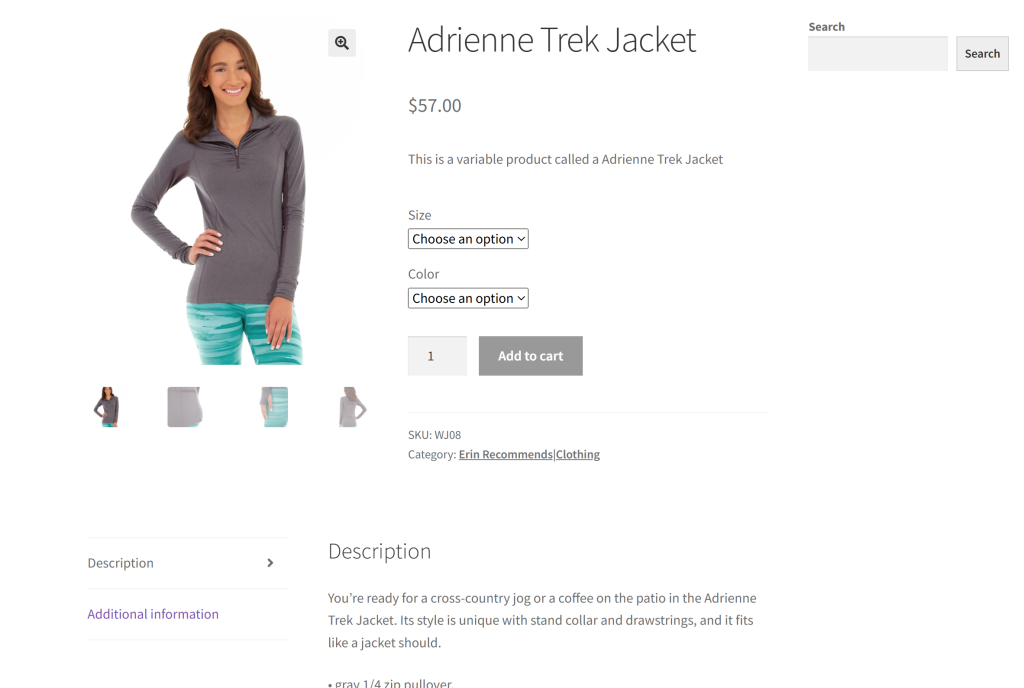
Este es un gran ejemplo porque la mayoría de las páginas de productos de comercio electrónico muestran diferentes tipos de datos o tienen estructuras variadas. Eso es lo que hace que el raspado web de comercio electrónico sea tan difícil, y donde la IA puede ayudar.
El objetivo de nuestro scraper basado en Gemini es aprovechar la IA para extraer los detalles de los productos de la página sin necesidad de escribir una lógica de análisis manual. Los datos del producto recuperados a través de AI incluirán:
- SKU
- Nombre
- Imágenes
- Precio
- Descripción
- Tallas
- Colores
- Categoría
Siga los pasos que se indican a continuación para aprender a realizar raspado web con Gemini.
Paso nº 1: Configuración del proyecto
Antes de empezar, comprueba que tienes Python 3 instalado en tu ordenador. Si no es así, descárgalo y sigue el asistente de instalación.
Ahora, ejecute el siguiente comando para crear una carpeta para su proyecto de scraping:
mkdir gemini-scrapergemini-scraper representa la carpeta del proyecto de su raspador web basado en Python Gemini.
Navega hasta él en el terminal, e inicializa un entorno virtual dentro de él:
cd gemini-scraper
python -m venv venvCarga la carpeta del proyecto en tu IDE de Python favorito. Visual Studio Code con la extensión Python o PyCharm Community Edition son dos grandes opciones.
Crea un archivo scraper.py en la carpeta del proyecto, que ahora debería contener esta estructura de archivos:

Actualmente, scraper.py es un script Python en blanco, pero pronto contendrá la lógica de raspado LLM deseada.
En el terminal del IDE, active el entorno virtual. En Linux o macOS, ejecute este comando:
./venv/bin/activateEquivalentemente, en Windows, ejecute:
venv/Scripts/activate¡Maravilloso! Ahora tienes un entorno Python para web scraping con Gemini.
Paso 2: Configurar Gemini
Gemini proporciona una API a la que puedes llamar utilizando cualquier cliente HTTP, incluidas las solicitudes. Aún así, es mejor conectarse a través del SDK Python oficial de Google AI para la API de Gemini. Para instalarlo, ejecuta el siguiente comando en el entorno virtual activado:
pip install google-generativeaiA continuación, impórtalo en tu archivo scraper.py:
import google.generativeai as genaiPara que el SDK funcione, necesita una clave API Gemini. Si aún no ha obtenido su clave API
sigue la documentación oficial de Google. En concreto, inicia sesión en tu cuenta de Google y únete a Google AI Studio. Navega hasta la página“Obtener clave de API” y verás el siguiente modal:
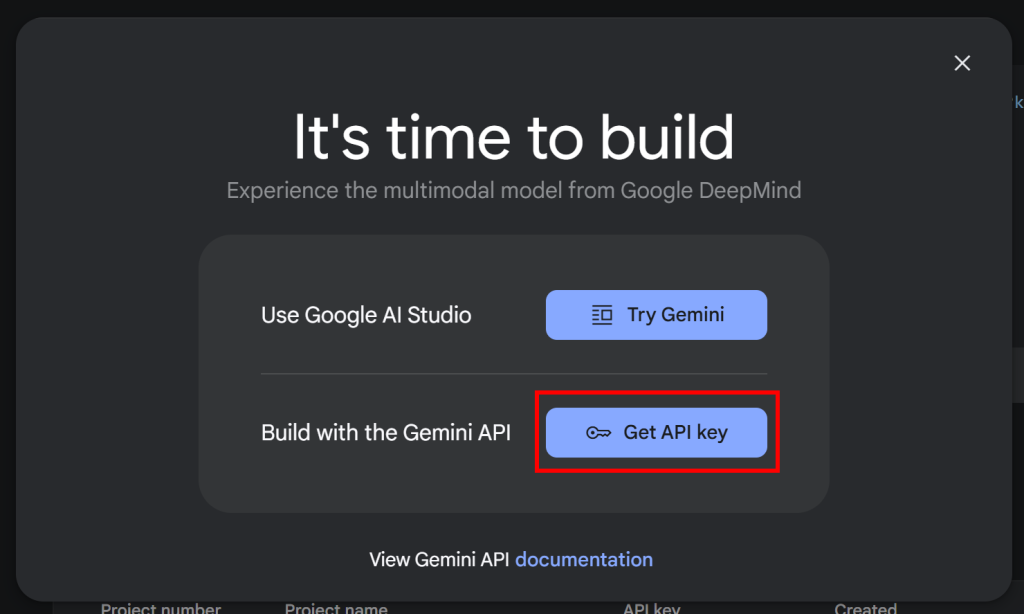
Haga clic en el botón “Obtener clave API” y aparecerá la siguiente sección:
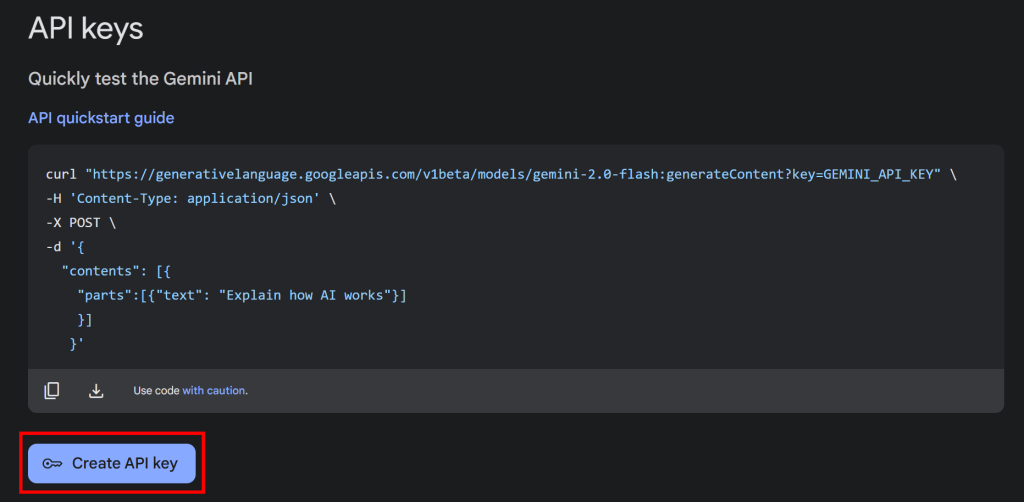
Ahora, pulse “Crear clave API” para generar su clave API Gemini:
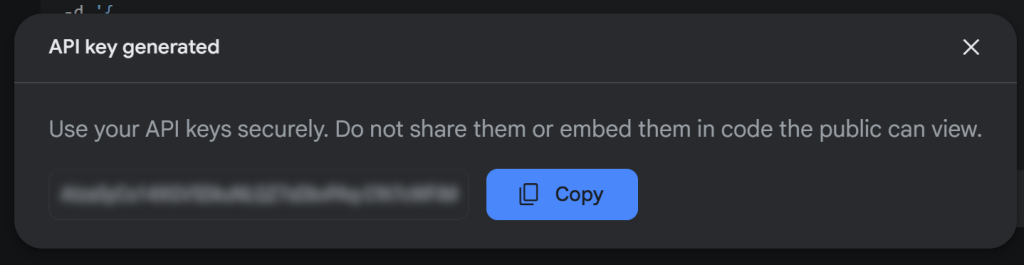
Copie la clave y guárdela en un lugar seguro.
Nota: el nivel gratuito de Gemini es suficiente para este ejemplo. El nivel de pago solo es necesario si necesitas límites de tarifa más altos o si quieres asegurarte de que tus preguntas y respuestas no se utilizan para mejorar los productos de Google. Para obtener más información, consulta la página de facturación de Gemini.
Para utilizar la clave API Gemini en Python, puede establecerla como variable de entorno:
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>O, alternativamente, guárdelo directamente en su script Python como una constante:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Y pasarlo a genai como una configuración, de la siguiente manera:
genai.configure(api_key=GEMINI_API_KEY)En este caso, seguiremos el segundo método. Sin embargo, ten en cuenta que ambos métodos funcionan, ya que google-generativeai intenta leer automáticamente la clave API de GEMINI_API_KEY si no la pasas manualmente.
¡Sorprendente! Ya puedes utilizar el SDK de Gemini para realizar peticiones API al LLM en Python.
Paso 3: Obtener el HTML de la página de destino
Para conectarnos al servidor de destino y recuperar el HTML de sus páginas web, utilizaremos Requests, el cliente HTTP más popular de Python. En un entorno virtual activado, instálalo con:
pip install requestsA continuación, impórtalo en scraper.py:
import requestsUtilícelo para enviar una petición GET a la página de destino y recuperar su documento HTML:
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)response.content contendrá ahora el HTML sin procesar de la página. Es hora de analizarlo y prepararse para extraer datos de él.
Paso 4: Convertir el HTML en Markdown
Si se comparan otras tecnologías de AI scraping como Crawl4AI, se observará que permiten utilizar selectores CSS para seleccionar elementos HTML. A continuación, estas bibliotecas convierten el HTML de los elementos seleccionados en texto Markdown. Por último, procesan ese texto con un LLM.
¿Se ha preguntado alguna vez por qué? Pues por dos razones clave para ese comportamiento:
- Para reducir el número de tokens enviados a la IA, ayudándote a ahorrar dinero (ya que no todos los proveedores de LLM son gratuitos como Gemini).
- Agilizar el procesamiento de la IA, ya que menos datos de entrada suponen menos costes de cálculo y respuestas más rápidas.
Para obtener una guía completa, consulte nuestra guía sobre raspado web con CrawlAI y DeepSeek.
Intentemos replicar esa lógica y ver si realmente tiene sentido. Comience por inspeccionar la página de destino abriéndola en una ventana de incógnito (para abrir una nueva sesión). A continuación, haz clic con el botón derecho del ratón en cualquier parte de la página y selecciona la opción “Inspeccionar”.
Examine la estructura de la página. Verá que todos los datos relevantes están contenidos en el elemento HTML identificado por el selector CSS #main:
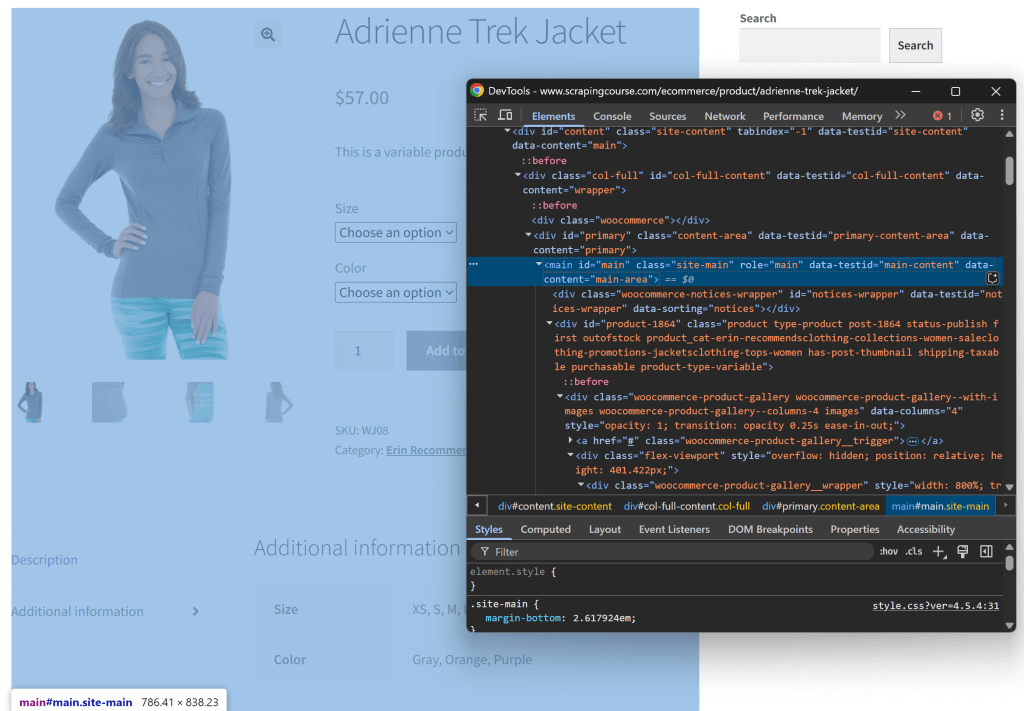
Podrías enviar todo el HTML sin procesar a Gemini, pero eso introduciría mucha información innecesaria (como cabeceras y pies de página). En su lugar, al pasar sólo el contenido #main, se reduce el ruido y se evitan las alucinaciones de la IA.
Para seleccionar sólo #main, necesitas una herramienta de análisis HTML de Python, como Beautiful Soup. Por lo tanto, instalarlo con:
pip install beautifulsoup4Si no está familiarizado con su sintaxis, consulte nuestra guía sobre raspado web Beautiful Soup.
Ahora, impórtalo en scraper.py:
from bs4 import BeautifulSoupUtiliza Beautiful Soup para analizar el HTML sin procesar recuperado a través de Requests, selecciona el elemento #main y extrae su HTML:
# Parse the HTML with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Si imprimes main_html, verás algo como esto:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
</main>Ahora, verifique cuántos tokens generaría este HTML y calcule el coste si estuviera utilizando el nivel de pago de Gemini. Para ello, utiliza una herramienta como Token Calculator:
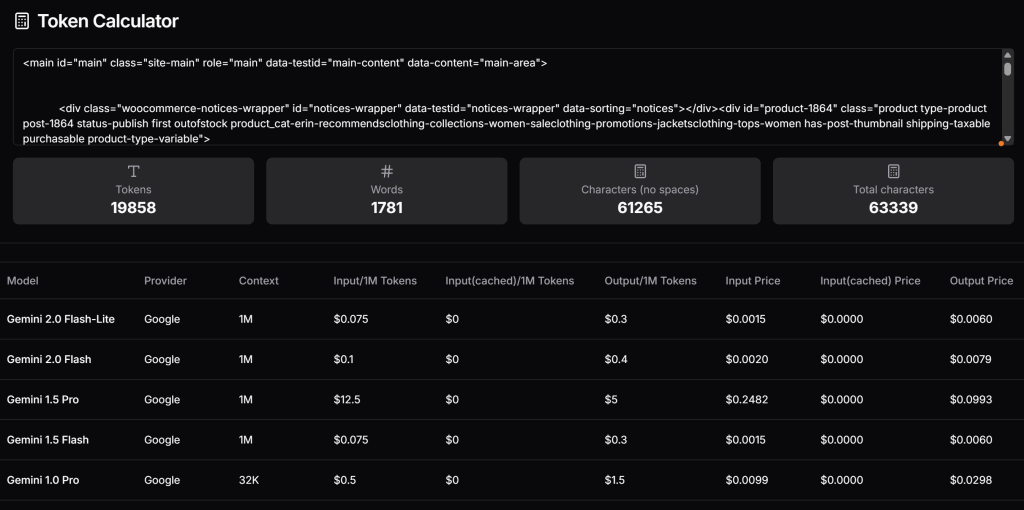
Como puede ver, este enfoque equivale a casi 20.000 tokens, con un coste aproximado de 0,25 dólares por solicitud para Gemini 1.5 Pro. En un proyecto de scraping a gran escala, esto puede convertirse fácilmente en un problema.
Intenta convertir el HTML extraído en Markdown -similar a lo que hace Crawl4AI. Primero, instala una librería HTML-to-Markdown como markdownify:
pip install markdownifyImportar markdownify en scraper.py:
from markdownify import markdownifyA continuación, utilice markdownify para convertir el HTML extraído en Markdown:
main_markdown = markdownify(main_html)La cadena main_markdown resultante contendrá algo como esto:
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back.jpg)
Adrienne Trek Jacket
====================
$57.00
This is a variable product called a Adrienne Trek Jacket
| | |
| --- | --- |
| Size | Choose an optionXSSMLXL |
| Color | Choose an optionGrayOrangePurple[Clear](#) |
Adrienne Trek Jacket quantity
Add to cart
SKU: WJ08
Category: [Erin Recommends|Clothing](https://www.scrapingcourse.com/ecommerce/product-category/clothing/women/tops-women/jacketsclothing-tops-women/promotions-jacketsclothing-tops-women/women-saleclothing-promotions-jacketsclothing-tops-women/collections-women-saleclothing-promotions-jacketsclothing-tops-women/erin-recommendsclothing-collections-women-saleclothing-promotions-jacketsclothing-tops-women/)
* [Description](#tab-description)
* [Additional information](#tab-additional_information)
Description
-----------
You’re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.
* gray 1/4 zip pullover.
* Comfortable, relaxed fit.
* Front zip for venting.
* Spacious, kangaroo pockets.
* 27″ body length.
* 95% Organic Cotton / 5% Spandex.
Additional information
----------------------
| | |
| --- | --- |
| Size | XS, S, M, L, XL |
| Color | Gray, Orange, Purple |Esta versión Markdown de los datos de entrada es mucho más pequeña que el HTML #main original, pero contiene todos los datos clave necesarios para el scraping.
Vuelva a utilizar la Calculadora de fichas para verificar cuántas fichas consumiría la nueva entrada:
Vaya, hemos reducido 19.858 fichas a 765, ¡un 95%!
Paso 5: Utilizar el LLM para extraer datos
Para realizar web scraping con Gemini, siga estos pasos:
- Escriba un prompt bien estructurado para extraer los datos deseados de la entrada Markdown. Asegúrese de definir los atributos que desea que tenga el resultado.
- Envía una petición a un modelo LLM de Gemini utilizando
genai, configurándolo para que la petición devuelva datos con formato JSON. - Analiza el JSON devuelto.
Implementa la lógica anterior con estas líneas de código:
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)La variable prompt indica a Gemini que extraiga datos estructurados del contenido de main_markdown. A continuación, genai.GenerativeModel() establece el modelo "gemini-2.0-flash-lite ” para realizar la solicitud LLM. Por último, la cadena de respuesta sin procesar en formato JSON se convierte en un diccionario Python utilizable con json.loads().
Tenga en cuenta la configuración "application/json ” para indicar a Gemini que devuelva datos JSON.
No olvides importar json de la biblioteca estándar de Python:
import jsonAhora que tiene los datos raspados en un diccionario product_data, puede acceder a sus campos para procesar más datos, como en el ejemplo siguiente:
price = product_data["price"]
price_eur = price * USD_EUR
# ...¡Fantástico! Acaba de utilizar Gemini para el web scraping. Sólo queda exportar los datos raspados.
Paso 6: Exportar los datos obtenidos
Actualmente, tiene los datos raspados almacenados en un diccionario Python. Para exportarlos a un archivo JSON, utilice el siguiente código:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Esto creará un archivo product.json que contiene los datos raspados en formato JSON.
Enhorabuena. El raspador web alimentado por Gemini está completo.
Paso 7: Póngalo todo junto
A continuación se muestra el código completo de su script de raspado Gemini:
import google.generativeai as genai
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
# Your Gemini API key
GEMINI_API_KEY = "<YOUR_GEMINI_API_KEY>"
# Set up the Google Gemini API
genai.configure(api_key=GEMINI_API_KEY)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Inicie el script con:
python scraper.pyUna vez ejecutado, aparecerá un archivo product.json en la carpeta del proyecto. Ábrelo y verás datos estructurados como estos:
{
"sku": "WJ08",
"name": "Adrienne Trek Jacket",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back-416x516.jpg"
],
"price": "$57.00",
"description": "Youu2019re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.nnu2022 gray 1/4 zip pullover. nu2022 Comfortable, relaxed fit. nu2022 Front zip for venting. nu2022 Spacious, kangaroo pockets. nu2022 27u2033 body length. nu2022 95% Organic Cotton / 5% Spandex.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Gray",
"Orange",
"Purple"
],
"category": "Erin Recommends|Clothing"
}¡Et voilà! Partió de datos no estructurados en una página HTML y ahora los tiene en un archivo JSON estructurado, gracias al raspado web con Gemini.
Próximos pasos
Para llevar su rascador Gemini al siguiente nivel, considere estas mejoras:
- Hágalo reutilizable: Modifique el script para que acepte el prompt y la URL de destino como argumentos de la línea de comandos. De este modo, será de uso general y se podrá adaptar a distintos escenarios de uso.
- Implementar el rastreo web: Amplíe el raspador para que pueda gestionar sitios web de varias páginas añadiendo lógica para el rastreo y la paginación.
- Proteja las credenciales de la API: Almacena tu clave API Gemini en un archivo
.envy utilizapython-dotenvpara cargarlo. Esto evita exponer tu clave API en el código.
Superar la principal limitación de este enfoque de raspado web
¿Cuál es la mayor limitación de este enfoque del web scraping? Las peticiones HTTP realizadas por los solicitantes.
Claro, en el ejemplo anterior, funcionó perfectamente, pero eso es porque el sitio de destino es sólo un patio de recreo de raspado web. En realidad, las empresas y los propietarios de sitios web saben lo valiosos que son sus datos, incluso cuando son de acceso público. Para protegerlos, implementan medidas anti-scraping que pueden bloquear fácilmente sus peticiones HTTP automatizadas.
Además, el enfoque anterior no funcionará en sitios dinámicos que dependen de JavaScript para la representación o la obtención de datos de forma asíncrona. Por lo tanto, los sitios ni siquiera necesitan marcos anti-scraping avanzados para detener su scraper. Basta con utilizar la carga de contenidos basada en JavaScript.
¿La solución a todos esos problemas? Una API de desbloqueo web.
Una API de Web Unlocker es un endpoint HTTP al que se puede llamar desde cualquier cliente HTTP. ¿La diferencia clave? Devuelve el HTML completamente desbloqueado de cualquier URL que se le pase, evitando cualquier bloqueo anti-scraping. No importa cuántas protecciones tenga un sitio web, con una simple petición a Web Unlocker obtendrá el HTML de la página.
Para empezar a utilizar esa herramienta y recuperar su clave API, siga la documentación oficial de Web Unlocker. A continuación, sustituye el código de solicitud del “Paso 3” por estas líneas:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)Y así de sencillo: ¡se acabaron los bloqueos y las limitaciones! Ya puedes raspar la Web con Gemini sin preocuparte de que te detengan.
Conclusión
En esta entrada de blog, aprendiste a usar Gemini en combinación con Requests y otras herramientas para construir un scraper potenciado por IA. Uno de los mayores retos del scraping web es el riesgo de ser bloqueado, pero esto se resolvió utilizando la API Web Unlocker de Bright Data.
Como se explica aquí, combinando Gemini y la API Web Unlocker, puede extraer datos de cualquier sitio sin necesidad de una lógica de análisis personalizada. Este es solo uno de los muchos escenarios que soportan los productos y servicios de Bright Data, ayudándole a implementar un raspado web eficaz basado en IA.
Explore nuestras otras herramientas de raspado web:
- Servicios proxy: Cuatro tipos diferentes de proxies para eludir las restricciones de ubicación, incluidas más de 400M+ monthly de IP residenciales.
- API de Web Scraper: Puntos finales dedicados para extraer datos web frescos y estructurados de más de 100 dominios populares.
- API SERP: API para manejar toda la gestión de desbloqueo en curso para SERP y extraer una página.
- Navegador de raspado: Navegador compatible con Puppeteer, Selenium y Playwright con actividades de desbloqueo integradas.
Regístrese ahora en Bright Data y pruebe gratis nuestros servicios proxy y productos de scraping.





