

En este tutorial, explorará el Scraping web en Laravel y aprenderá:
- Por qué Laravel es una tecnología excelente para el Scraping web
- Cuáles son las mejores bibliotecas de scraping de Laravel
- Cómo crear una API de Scraping web en Laravel desde cero
¡Empecemos!
¿Es posible realizar Scraping web en Laravel?
Resumen: Sí, Laravel es una tecnología viable para el Scraping web.
Laravel es un potente framework PHP conocido por su sintaxis elegante y expresiva. En particular, permite crear API para extraer datos de la web sobre la marcha. Esto es posible gracias al soporte de muchas bibliotecas de scraping, que simplifican el proceso de obtención de datos de las páginas. Para obtener más información, consulte nuestro artículo sobre Scraping web en PHP.
Laravel es una excelente opción para el Scraping web debido a su escalabilidad, su fácil integración con otras herramientas y el amplio soporte de la comunidad. Su sólida arquitectura MVC ayuda a mantener la lógica de scraping bien organizada y fácil de mantener. Esto resulta muy útil a la hora de crear proyectos de Scraping web complejos o a gran escala.
Las mejores bibliotecas de Scraping web de Laravel
Estas son las mejores bibliotecas para realizar Scraping web con Laravel:
- BrowserKit: parte del marco Symfony, simula la API de un navegador web para interactuar con documentos HTML. Se basa en
DomCrawlerpara navegar y extraer documentos HTML. Esta biblioteca es ideal para extraer datos de páginas estáticas en PHP. - HttpClient: un componente de Symfony para enviar solicitudes HTTP. Se integra perfectamente con
BrowserKit. - Guzzle: un cliente HTTP robusto para enviar solicitudes web a servidores y gestionar las respuestas de forma eficiente. Es útil para recuperar los documentos HTML asociados a las páginas web. Aprende a configurar un Proxy en Guzzle.
- Panther: un componente de Symfony que proporciona un navegador sin interfaz gráfica para el Scraping web. Permite interactuar con sitios dinámicos que requieren JavaScript para su renderización o interacción.
Requisitos
Para seguir este tutorial sobre Scraping web en Laravel, debe cumplir los siguientes requisitos previos:
También se recomienda un IDE para programar en PHP. Visual Studio Code con la extensión PHP o WebStorm son dos excelentes soluciones.
Cómo crear una API de Scraping web en Laravel
En esta sección paso a paso, verás cómo crear una API de Scraping web en Laravel. El sitio de destino será el sitio de pruebas de Scraping web Quotes, y el punto final de Scraping web hará lo siguiente:
- Seleccionar los elementos HTML de las citas de la página
- Extraer datos de ellos
- Devolver los datos extraídos en JSON
Así es como se ve el sitio de destino:

Sigue las instrucciones que se indican a continuación y aprende a realizar Scraping web en Laravel.
Paso 1: Configure un proyecto Laravel
Abre el terminal. A continuación, ejecuta el comando Composer create-command que aparece a continuación para inicializar tu aplicación de Scraping web Laravel:
composer create-project laravel/laravel laravel-scraperLa carpeta lavaral-Scraper ahora contendrá un proyecto Laravel en blanco. Cárguelo en su IDE PHP favorito.
Esta es la estructura de archivos de su backend actual:
¡Genial! Ya tiene un proyecto Laravel en marcha.
Paso 2: Inicialice su API de scraping
Ejecuta el comando Artisan siguiente en el directorio del proyecto para añadir un nuevo controlador Laravel:
php artisan make:controller HelloWorldControllerEsto creará el siguiente archivo ScrapingController.php en el directorio /app/Http/Controllers:
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
class ScrapingController extends Controller
{
//
}En el archivo ScrapingController, añada el siguiente método scrapeQuotes():
public function scrapeQuotes(): JsonResponse
{
// lógica de scraping...
return response()->json('Hello, World!');
}Actualmente, el método devuelve un mensaje JSON de marcador de posición «Hello, World!». Pronto, contendrá alguna lógica de scraping en Laravel.
No olvide añadir la siguiente importación:
use IlluminateHttpJsonResponse;Asocia el método scrapeQuotes() a un punto final dedicado añadiendo las siguientes líneas a routes/api.php:
use AppHttpControllersScrapingController;
Route::get('/v1/scraping/scrape-quotes', [ScrapingController::class, 'scrapeQuotes']);¡Genial! Es hora de verificar que la API de scraping de Laravel funciona como se desea. Ten en cuenta que las API de Laravel están disponibles en la ruta /api. Por lo tanto, el punto final completo de la API es /api/v1/scraping/scrape-quotes.
Inicie su aplicación Laravel con el siguiente comando:
php artisan serveTu servidor debería estar ahora escuchando localmente en el puerto 8000.
Utilice cURL para realizar una solicitud GET al punto final /api/v1/scraping/scrape-quotes:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'Nota: En Windows, sustituya curl por curl.exe. Obtenga más información en nuestra guía de cURL para el Scraping web.
Debería obtener la siguiente respuesta:
«¡Hola, mundo!»¡Fantástico! La API de scraping de muestra funciona a la perfección. Es hora de definir alguna lógica de scraping con Laravel.
Paso 3: Instalar las bibliotecas de scraping
Antes de instalar ningún paquete, debe determinar qué bibliotecas de Scraping web de Laravel se adaptan mejor a sus necesidades. Para ello, abra el sitio de destino en su navegador. Haga clic con el botón derecho del ratón en la página y seleccione «Inspeccionar» para abrir las Herramientas de desarrollo. A continuación, vaya a la pestaña «Red», vuelva a cargar la página y acceda a la sección «Fetch/XHR»:
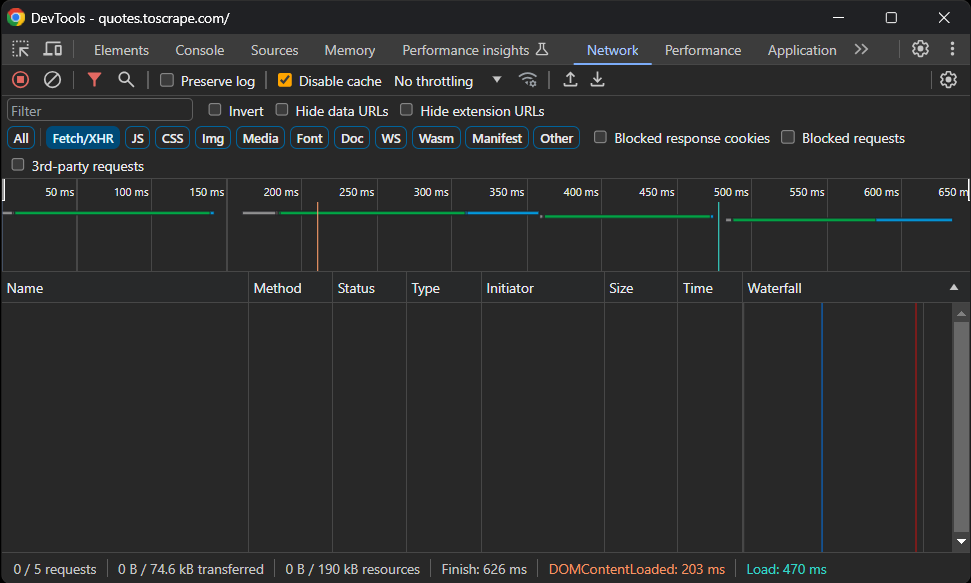
Como puede ver, la página web no realiza ninguna solicitud AJAX. Esto significa que no carga datos de forma dinámica en el lado del cliente. Por lo tanto, es una página estática con todos los datos incrustados en los documentos HTML.
Dado que la página es estática, no necesitas una biblioteca de navegador sin interfaz gráfica para extraerla. Aunque podrías seguir utilizando una herramienta de automatización del navegador, eso solo supondría una sobrecarga innecesaria. El enfoque recomendado es utilizar los componentes BrowserKit y HttpClient de Symfony.
Añada los componentes symfony/browser-kit y symfony/http-client a las dependencias de su proyecto con:
composer require symfony/browser-kit symfony/http-client¡Bien hecho! Ahora tienes todo lo necesario para realizar el rastreo de datos en Laravel.
Paso 4: Descargar la página de destino
Importa BrowserKit y HttpClient en ScrapingController:
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;En scrapeQuotes(), inicializa un nuevo objeto HttpBrowser:
$browser = new HttpBrowser(HttpClient::create());Esto te permite realizar solicitudes HTTP simulando el comportamiento del navegador. Al mismo tiempo, recuerda que no ejecuta solicitudes en un navegador real. HttpBrowser solo proporciona funciones similares a las de un navegador, como el manejo de cookies y sesiones.
Utiliza el método request() para realizar una solicitud HTTP GET a la URL de la página de destino:
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');El resultado será un objeto Crawler, que realiza el parseo automático del documento HTML devuelto por el servidor. Esta clase también proporciona capacidades de selección de nodos y extracción de datos.
Puede verificar que la lógica anterior funciona extrayendo el HTML de la página del rastreador:
$html = $crawler->outerHtml();Para realizar la prueba, haz que tu API devuelva estos datos.
Tu función scrapeQuotes() tendrá ahora el siguiente aspecto:
public function scrapeQuotes(): JsonResponse
{
// inicializar un cliente HTTP similar a un navegador
$browser = new HttpBrowser(HttpClient::create());
// descargar y analizar el HTML de la página de destino
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// obtener el HTML externo de la página y devolverlo
$html = $crawler->outerHtml();
return response()->json($html);
}¡Increíble! Tu API ahora devolverá:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Citas para extraer</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<!-- omitido por brevedad ... -->Paso 5: Inspeccionar el contenido de la página
Para definir la lógica de extracción de datos, es esencial examinar la estructura HTML de la página de destino.
Por lo tanto, abra Citas para extraer en su navegador. A continuación, haga clic con el botón derecho del ratón en un elemento HTML de cita y seleccione la opción «Inspeccionar». En las herramientas de desarrollo de su navegador, expanda el HTML y comience a estudiarlo:
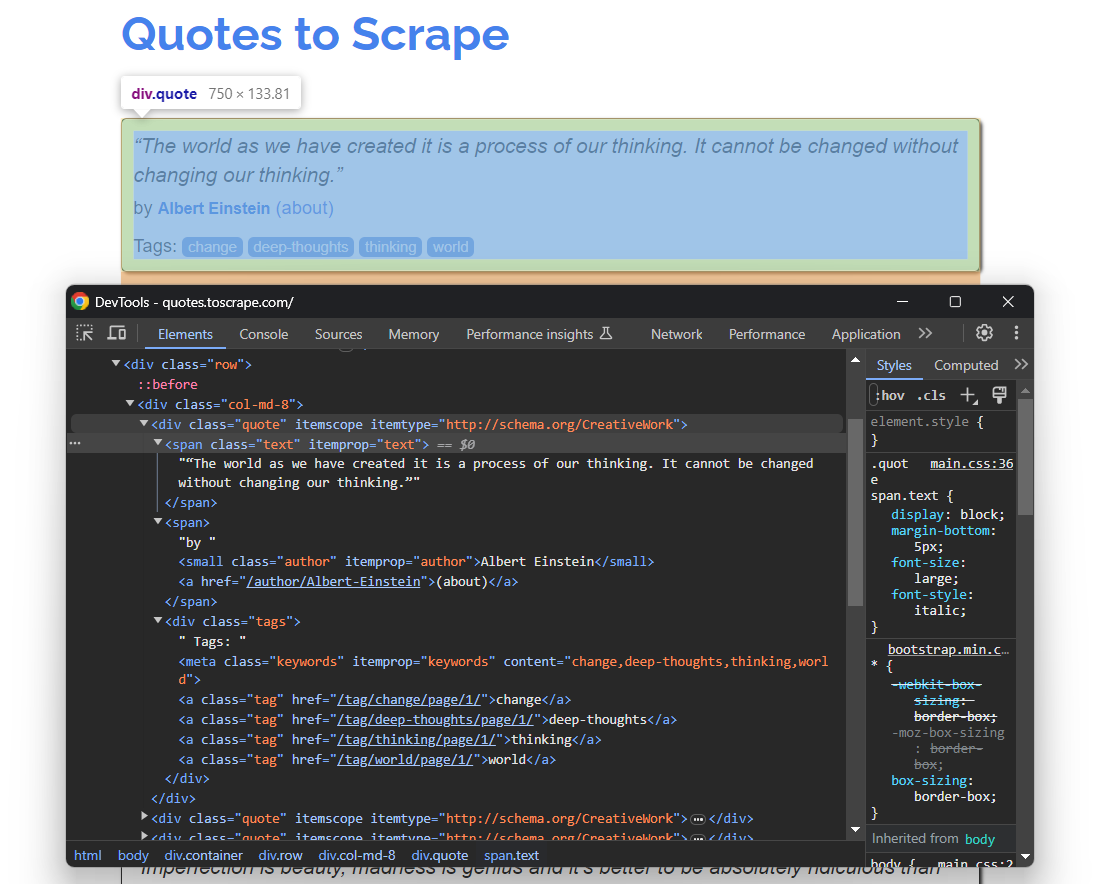
Aquí, observe que cada tarjeta de cita es un nodo HTML .quote que contiene:
- Un elemento
.textcon el texto de la cita - Un nodo
.authorcon el nombre del autor - Muchos elementos
.tag, cada uno de los cuales muestra una sola etiqueta
Con los selectores CSS anteriores, tienes todo lo que necesitas para realizar el Scraping web en Laravel. Utiliza estos selectores para seleccionar los elementos DOM de interés y extraer datos de ellos en los siguientes pasos.
Paso 6: Prepárate para realizar el Scraping web
Dado que la página de destino contiene varias citas, crea una estructura de datos donde almacenar los datos extraídos. Lo ideal sería una matriz:
quotes = []A continuación, utiliza el método filter() de la clase Crawler para seleccionar todos los elementos de cita:
$quote_html_elements = $crawler->filter('.quote');Esto devuelve todos los nodos DOM de la página que coinciden con el selector CSS .quote especificado.
A continuación, itere sobre ellos y prepárese para aplicar la lógica de extracción de datos en cada uno de ellos:
foreach ($quote_html_elements as $quote_html_element) {
// crear un nuevo rastreador de citas
$quote_crawler = new Crawler($quote_html_element);
// lógica de scraping...
}Tenga en cuenta que los objetos DOMNode devueltos por filter() no proporcionan métodos para la selección de nodos. Por lo tanto, debe crear una instancia local de Crawler limitada a su elemento HTML de cita específico.
Para que el código anterior funcione, añada la siguiente importación:
use SymfonyComponentDomCrawlerCrawler;No es necesario instalar manualmente el paquete DomCrawler. Esto se debe a que es una dependencia directa del componente BrowserKit.
¡Genial! Estás un paso más cerca de tu objetivo de Scraping web con Laravel.
Paso 7: Implementar el scraping de datos
Dentro del bucle foreach:
- Extrae los datos de interés de los elementos
.text,.authory.tag - Rellene un nuevo objeto
$quotecon ellos - Añade el nuevo objeto
$quotea$quotes
Primero, seleccione el elemento .text dentro del elemento HTML quote. A continuación, utilice el método text() para extraer el texto interno del mismo:
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();Tenga en cuenta que cada cita está delimitada por los caracteres especiales u201c y u201d. Puede eliminarlos utilizando la función PHP str_replace() de la siguiente manera:
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);Del mismo modo, extraiga la información del autor con:
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();Extraer las etiquetas puede ser un poco más complicado. Dado que una sola cita puede tener varias etiquetas, es necesario definir una matriz y extraer cada etiqueta individualmente:
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}Tenga en cuenta que los elementos DOMNode devueltos por filter() no exponen el método text(). De forma equivalente, proporcionan el atributo textContent.
Así es como se verá toda la lógica de extracción de datos de Laravel:
// crear un nuevo rastreador de citas
$quote_crawler = new Crawler($quote_html_element);
// ejecutar la lógica de extracción de datos
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// eliminar caracteres especiales de la información de texto sin procesar
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}¡Ya está! Estás cerca de la meta final.
Paso 8: Devuelve los datos extraídos
Crea un objeto $quote con los datos recopilados y añádelo a $quotes:
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
$quotes[] = $quote;A continuación, actualiza los datos de respuesta de la API con la lista $quotes:
return response()->json(['quotes' => $quotes]);Al final del bucle de rastreo, $quotes contendrá:
array(10) {
[0]=>
array(3) {
["text"]=>
string(113) "El mundo tal y como lo hemos creado es un proceso de nuestro pensamiento. No puede cambiarse sin cambiar nuestro pensamiento."
["author"]=>
string(15) "Albert Einstein"
["tags"]=>
array(4) {
[0]=>
string(6) "change"
[1]=>
string(13) "deep-thoughts"
[2]=>
string(8) "thinking"
[3]=>
string(5) "world"
}
}
// omitido por brevedad...
[9]=>
array(3) {
["text"]=>
string(48) "Un día sin sol es como, ya sabes, la noche."
["author"]=>
string(12) "Steve Martin"
["tags"]=>
array(3) {
[0]=>
string(5) "humor"
[1]=>
string(7) "obvious"
[2]=>
string(6) "simile"
}
}
}¡Genial! Estos datos se serializarán en JSON y serán devueltos por la API de scraping de Laravel.
Paso 9: Ponlo todo junto
Este es el código final del archivo ScrapingController en Laravel:
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
use IlluminateHttpJsonResponse;
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;
use SymfonyComponentDomCrawlerCrawler;
class ScrapingController extends Controller
{
función pública scrapeQuotes(): JsonResponse
{
// inicializar un cliente HTTP similar a un navegador
$browser = new HttpBrowser(HttpClient::create());
// descargar y analizar el HTML de la página de destino
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// dónde almacenar los datos extraídos
$quotes = [];
// seleccionar todos los elementos HTML de cotización de la página
$quote_html_elements = $crawler->filter('.quote');
// iterar sobre cada elemento HTML de cotización y aplicar
// la lógica de extracción
foreach ($quote_html_elements as $quote_html_element) {
// crear un nuevo rastreador de citas
$quote_crawler = new Crawler($quote_html_element);
// realizar la lógica de extracción de datos
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// eliminar caracteres especiales de la información de texto sin procesar
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}
// crear un nuevo objeto de cita
// con los datos recopilados
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
// añadir el objeto de cita a la matriz de citas
$quotes[] = $quote;
}
var_dump($quotes);
return response()->json(['quotes' => $quotes]);
}
}¡Es hora de probarlo!
Inicia tu servidor Laravel:
php artisan serveA continuación, realiza una solicitud GET al punto final /api/v1/scraping/scrape-quotes:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'Obtendrás el siguiente resultado:
{
"quotes": [
{
"text": "El mundo tal y como lo hemos creado es un proceso de nuestro pensamiento. No se puede cambiar sin cambiar nuestra forma de pensar.",
"author": "Albert Einstein",
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
]
},
// omitido por brevedad...
{
"text": "Un día sin sol es como, ya sabes, la noche.",
"author": "Steve Martin",
"tags": [
"humor",
"obvious",
"simile"
]
}
]
}¡Et voilà! En menos de 100 líneas de código, acabas de realizar Scraping web en Laravel.
Próximos pasos
La API que has creado aquí es solo un ejemplo básico de lo que puedes lograr con Laravel en lo que respecta al Scraping web. Para llevar tu proyecto al siguiente nivel, considera las siguientes mejoras:
- Implementa el rastreo web: el sitio de destino contiene varias citas repartidas en múltiples páginas. Este es un escenario común que requiere el rastreo web para la recuperación completa de datos. Lee nuestro artículo sobre la definición de un rastreador web.
- Programa tu tarea de scraping: añade un programador para llamar a tu API a intervalos regulares, almacena los datos en una base de datos y asegúrate de tener siempre datos actualizados.
- Integra un Proxy: realizar múltiples solicitudes desde la misma IP puede provocar que te bloqueen las medidas antirraspado. Para evitarlo, considera la posibilidad de integrar Proxies residenciales en tu Scraper PHP.
Mantenga su operación de Scraping web con Laravel ética y respetuosa
El scraping web es una forma eficaz de recopilar datos valiosos para diversos fines. Sin embargo, el objetivo es recuperar datos de forma responsable, sin perjudicar al sitio web de destino. Por lo tanto, es importante abordar el scraping con las precauciones adecuadas.
Siga estos consejos para garantizar un Scraping web responsable con Kotlin:
- Compruebe y cumpla con los términos de servicio del sitio: antes de realizar el scraping de un sitio, revise sus términos de servicio. A menudo incluyen información sobre derechos de autor, derechos de propiedad intelectual y directrices para el uso de sus datos.
- Respete el archivo robots.txt: el archivo robots.txt de un sitio web define las reglas sobre cómo los rastreadores automatizados deben acceder a sus páginas. Para mantener prácticas éticas, siga estas directrices. Descubra más en nuestra guía robots.txt para el Scraping web.
- Céntrate solo en la información disponible públicamente: céntrate en los datos que son de acceso público. Evita extraer páginas protegidas por credenciales de inicio de sesión u otras formas de autorización. Centrarse en datos privados o sensibles sin el permiso adecuado no es ético y puede acarrear consecuencias legales.
- Limita la frecuencia de tus solicitudes: realizar demasiadas solicitudes en un breve periodo de tiempo puede sobrecargar el servidor, lo que afectaría al rendimiento del sitio para todos los usuarios. Esto también podría desencadenar medidas de limitación de velocidad y provocar que te bloquearan. Evita saturar el servidor de destino añadiendo retrasos aleatorios entre tus solicitudes.
- Confíe en herramientas de rastreo fiables y actualizadas: prefiera proveedores de buena reputación y opte por herramientas que estén bien mantenidas y se actualicen periódicamente. Esto garantiza que se ajusten a las últimas prácticas éticas de Scraping web de Laravel. Si no está seguro, consulte nuestro artículo sobre cómo elegir el mejor servicio de Scraping web.
Conclusión
En esta guía, ha visto por qué Laravel es un buen marco para crear API de Scraping web. También ha tenido la oportunidad de explorar algunas de sus mejores bibliotecas de Scraping web. A continuación, ha aprendido a crear una API de Scraping web con Laravel que extrae datos de una página de destino sobre la marcha. Como ha visto, el Scraping web con Laravel es sencillo y solo requiere unas pocas líneas de código.
El problema es que la mayoría de los sitios protegen sus datos con soluciones antibots y antirraspado. Estas tecnologías pueden detectar y bloquear tus solicitudes automatizadas. Afortunadamente, Bright Data tiene un conjunto de soluciones para facilitar el rastreo:
- Navegador de scraping: un navegador controlable basado en la nube que ofrece capacidades de renderización de JavaScript y, al mismo tiempo, gestiona CAPTCHAs, huellas digitales del navegador, reintentos automatizados y mucho más por ti. Se integra con las bibliotecas de navegadores de automatización más populares, como Playwright y Puppeteer.
- Web Unlocker: una API de desbloqueo que puede devolver sin problemas el HTML limpio de cualquier página, eludiendo cualquier medida anti-scraping.
- Scraping web: puntosfinales para el acceso programático a datos web estructurados de docenas de dominios populares.
¿No quieres lidiar con el Scraping web, pero sigues interesado en los datos en línea? ¡Explora los Conjuntos de datos listos para usar de Bright Data!
Regístrese ahora y comience su prueba gratuita.





