

En esta guía aprenderás:
- Qué es Pydoll y qué funciones ofrece
- Cómo usarlo para raspar sitios web con JavaScript
- Cómo eludir la protección de Cloudflare
- Sus mayores limitaciones
- Cómo superar esas limitaciones mediante la integración del proxy rotatorio
- Las mejores alternativas a Pydoll basadas en Python
Sumerjámonos.
Introducción a Pydoll
Descubra qué es Pydoll, cómo funciona y qué ofrece como biblioteca de raspado web en Python.
Qué es
Pydoll es una biblioteca de automatización del navegador Python construida para el web scraping, pruebas y automatización de tareas repetitivas. Lo que la distingue es que elimina la necesidad de controladores web tradicionales. En concreto, se conecta directamente a los navegadores a través del protocolo DevTools, sin necesidad de dependencias externas.
La primera versión estable de Pydoll, la 1.0, se lanzó en febrero de 2026. Esto la convierte en una empresa relativamente nueva en el sector del web scraping. A pesar de ello, ya ha ganado un fuerte impulso, ganando más de 3.000 estrellas en GitHub:
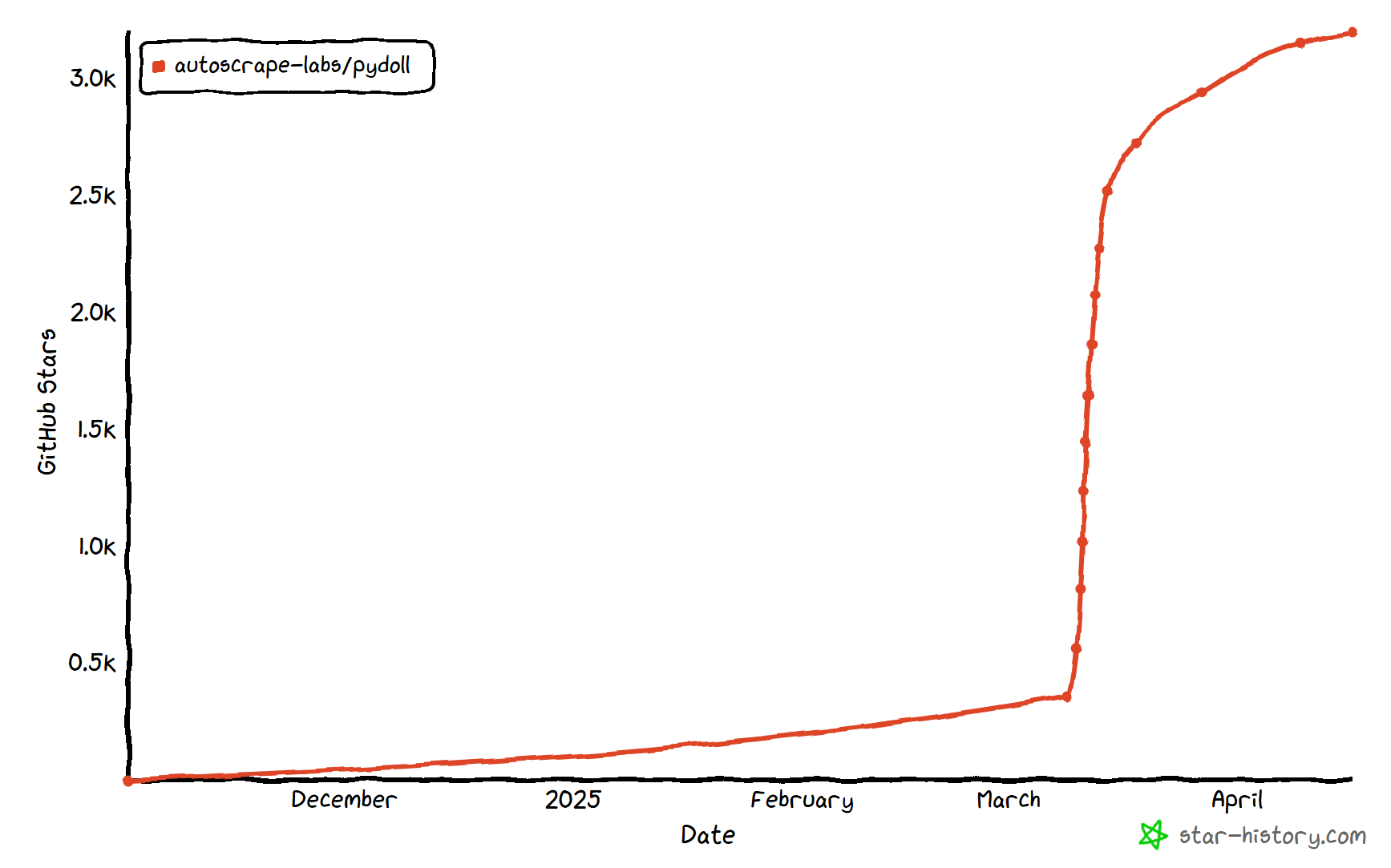
Como se puede ver, la biblioteca está ganando mucha popularidad en la comunidad de Python web scraping.
Características
He aquí un resumen de las principales características que ofrece Pydoll:
- Cero controladores web: Elimina la dependencia del controlador del navegador, lo que reduce los problemas de desajuste de versiones y simplifica la configuración para la automatización basada en Chromium.
- Arquitectura asíncrona: Construido enteramente sobre asyncio para alta concurrencia, uso eficiente de memoria y patrones de desarrollo Python modernos.
- Interacciones similares a las humanas: Imita de forma realista la escritura, los movimientos del ratón y los clics para reducir la detección de bots durante la automatización.
- Funciones basadas en eventos: Permite reaccionar en tiempo real a los eventos del navegador, DOM, red y ciclo de vida para una automatización con capacidad de respuesta.
- Compatible con varios navegadores: Compatible con Chrome, Edge y otros navegadores Chromium utilizando la misma interfaz unificada.
- Captura de pantalla y exportación a PDF: Capture páginas completas, elementos específicos o genere PDF de alta calidad a partir de cualquier página web cargada.
- Bypass nativo de Cloudflare: Elude automáticamente el anti-bot de Cloudflare sin servicios de terceros, imitando sesiones de navegador de confianza cuando la reputación IP es alta.
- Raspado concurrente: Raspa varias páginas o sitios web en paralelo, lo que reduce drásticamente el tiempo total de ejecución.
- Control avanzado del teclado: Simula la escritura real del usuario con un control preciso de la temporización, los modificadores y el manejo de teclas especiales.
- Potente sistema de eventos: Proporciona supervisión y gestión en tiempo real de solicitudes de red, cargas de páginas y eventos personalizados del navegador.
- Carga de archivos: Automatiza la carga de archivos utilizando tanto la entrada directa como los diálogos interactivos del selector de archivos.
- Integración de proxy: Soporta el uso de proxy para rotación de IP, geo-targeting o evitar límites de tasa durante el scraping.
- Interceptación desolicitudes: Intercepte, modifique o bloquee solicitudes y respuestas HTTP para una automatización avanzada y un control del scraping.
Más información en la documentación oficial.
Uso de Pydoll para Web Scraping: Tutorial completo
En esta sección del tutorial, aprenderá a utilizar Pydoll para raspar datos de la versión asíncrona y con JavaScript de “Quotes to Scrape“:

Esta página presenta dinámicamente los elementos de la cita utilizando JavaScript tras un breve retardo. Por lo tanto, las herramientas tradicionales de scraping no funcionarán. Para extraer el contenido de esa página, necesitas una herramienta de automatización del navegador como Pydoll.
Siga los pasos que se indican a continuación para crear un raspador web Pydoll que extraiga dinámicamente datos de cotizaciones de “Quotes to Scrape”.
Paso nº 1: Configuración del proyecto
Antes de empezar, asegúrate de que tienes Python 3+ instalado en tu máquina. En caso contrario, descárgalo y sigue las instrucciones de instalación.
A continuación, ejecute el siguiente comando para crear una carpeta para su proyecto de scraping:
mkdir pydoll-scraperEl directorio pydoll-scraper servirá como carpeta del proyecto.
Navega a la carpeta en tu terminal e inicializa un entorno virtual Python dentro de ella:
cd pydoll-scraper
python -m venv venvCarga la carpeta del proyecto en tu IDE de Python favorito. Visual Studio Code con la extensión Python o PyCharm Community Edition serán suficientes.
Crear un archivo scraper.py en la carpeta del proyecto, que ahora debe contener:

En este momento, scraper.py es sólo un script Python vacío. Sin embargo, pronto contendrá la lógica de análisis de datos.
A continuación, active el entorno virtual en el terminal de su IDE. En Linux o macOS, ejecute:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venv/Scripts/activate¡Maravilloso! Su entorno Python está ahora preparado para el web scraping con Pydoll.
Paso 2: Configurar Pydoll
En un entorno virtual activado, instale Pydoll mediante el paquete pydoll-python:
pip install pydoll-pythonAhora, añade la lógica de abajo al archivo scraper.py para empezar con Pydoll:
import asyncio
from pydoll.browser.chrome import Chrome
async def main():
async with Chrome() as browser:
# Launch the Chrome browser and open a new page
await browser.start()
page = await browser.get_page()
# scraping logic...
# Execute the async scraping function
asyncio.run(main())Tenga en cuenta que Pydoll proporciona una API asíncrona para el web scraping y requiere el uso de la biblioteca estándar asyncio de Python.
Muy bien. Ya tienes un script Pydoll básico.
Paso nº 3: Conectarse al sitio de destino
Llama al método go_to() proporcionado por el objeto page para navegar al sitio de destino:
await page.go_to("https://quotes.toscrape.com/js-delayed/?delay=2000")El parámetro de consulta ?delay=2000 indica a la página que cargue los datos deseados dinámicamente tras un retraso de 2 segundos. Se trata de una función del sitio sandbox de destino, diseñada para ayudar a probar el comportamiento dinámico del scraping.
Ahora, intenta ejecutar el script anterior. Si todo funciona correctamente, Pydoll lo hará:
- Iniciar una instancia de Chrome
- Navegue hasta el sitio de destino
- Cerrar la ventana del navegador inmediatamente, ya que aún no hay lógica adicional en el script.
Concretamente, esto es lo que debería poder ver antes de que se cierre:

Perfecto. Ya está listo para añadir la lógica de espera.
Paso 4: Esperar a que aparezcan los elementos HTML
Eche un vistazo a la última imagen del paso anterior. Representa el contenido de la página controlada por Pydoll en la instancia de Chrome. Observará que está completamente en blanco: no se ha cargado ningún dato.
La razón es que el sitio de destino presenta dinámicamente los datos después de un retraso de 2 segundos. Ahora bien, ese retraso es específico del sitio de ejemplo. Aún así, tener que esperar a que la página se renderice es un escenario común cuando se raspan SPAs (aplicaciones de una sola página) y otros sitios web dinámicos que dependen de AJAX.
Obtenga más información en nuestro artículo sobre el scraping de sitios web dinámicos con Python.
Para hacer frente a ese escenario común, Pydoll proporciona mecanismos de espera incorporados a través de este método:
wait_element(): Espera a que aparezca un único elemento (con soporte de tiempo de espera).
El método anterior soporta selectores CSS, expresiones XPath, y más-similar a cómo funciona el objeto By de Selenium.
Ha llegado el momento de familiarizarse con el HTML de la página de destino. Para ello, ábrala en su navegador, espere a que se carguen las comillas, haga clic con el botón derecho en una de ellas y seleccione la opción “Inspeccionar”:

En el panel DevTools, verá que cada cita está envuelta en una etiqueta
quote. Eso significa que puede orientarlas utilizando el selector CSS:
.quoteAhora, utiliza Pydoll para esperar a que aparezcan estos elementos antes de continuar:
await page.wait_element(By.CSS_SELECTOR, ".quote", timeout=3)No olvides importar By:
from pydoll.constants import ByEjecute de nuevo el script, y esta vez verá que Pydoll espera a que se carguen los elementos de la cita antes de cerrar el navegador. ¡Buen trabajo!
Paso 5: Prepararse para el Web Scraping
Recuerde que la página de destino contiene más de una cita. Puesto que quieres rasparlas todas, necesitas una estructura de datos que contenga esos datos. Un simple array funciona perfectamente, así que inicializa uno:
quotes = []Para encontrar elementos de la página, Pydoll proporciona dos prácticos métodos:
encontrar_elemento(): Encuentra el primer elemento coincidenteencontrar_elementos(): Encuentra todos los elementos coincidentes
Al igual que con wait_element(), estos métodos aceptan un selector utilizando el objeto By.
Por lo tanto, seleccione todos los elementos de la cita en la página con:
quote_elements = await page.find_elements(By.CSS_SELECTOR, ".quote")A continuación, realice un bucle a través de los elementos y prepárese para aplicar su lógica de raspado:
for quote_element in quote_elements:
# Scraping logic...¡Fantástico! Hora de la lógica de extracción de datos.
Paso 6: Implementar la lógica de análisis de datos
Comience por inspeccionar un único elemento de la cita:

Como puede deducirse del HTML anterior, un elemento de cita simple contiene:
- La cita textual en un nodo
.text - El autor en el elemento
.author - Una lista de etiquetas en los elementos
.tag
Implementar la lógica de scraping para seleccionar esos elementos y extraer los datos de interés de con:
# Extract the quote text (and remove curly quotes)
text_element = await quote_element.find_element(By.CSS_SELECTOR, ".text")
text = (await text_element.get_element_text()).replace("“", "").replace("”", "")
# Extract the author name
author_element = await quote_element.find_element(By.CSS_SELECTOR, ".author")
author = await author_element.get_element_text()
# Extract all associated tags
tag_elements = await quote_element.find_elements(By.CSS_SELECTOR, ".tag")
tags = [await tag_element.get_element_text() for tag_element in tag_elements]Nota: El método replace( ) elimina las comillas dobles rizadas innecesarias del texto entrecomillado extraído.
Ahora, utiliza los datos obtenidos para rellenar un nuevo objeto diccionario y añádelo a la matriz de citas:
# Populate a new quote with the scraped data
quote = {
"text": text,
"author": author,
"tags": tags
}
# Append the extracted quote to the list
quotes.append(quote)Bien hecho. Sólo queda exportar los datos raspados a CSV.
Paso 7: Exportar a CSV
Actualmente, los datos raspados se almacenan en una lista de Python. Haz que sea más fácil compartirlos y explorarlos con otros exportándolos a un formato legible por humanos como CSV.
Utilice Python para crear un nuevo archivo llamado quotes.csv y rellénelo con los datos obtenidos:
with open("quotes.csv", "w", newline="", encoding="utf-8") as csvfile:
# Add the header
fieldnames = ["text", "author", "tags"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Populate the output file with the scraped data
writer.writeheader()
for quote in quotes:
writer.writerow(quote)Recuerda importar csv de la biblioteca estándar de Python:
import csv¡Misión completada! Su Pydoll raspador está listo para su ejecución.
Paso 8: Póngalo todo junto
El archivo scraper. py debería contener ahora:
import asyncio
from pydoll.browser.chrome import Chrome
from pydoll.constants import By
import csv
async def main():
async with Chrome() as browser:
# Launch the Chrome browser and open a new page
await browser.start()
page = await browser.get_page()
# Navigate to the target page
await page.go_to("https://quotes.toscrape.com/js-delayed/?delay=2000")
# Wait up to 3 seconds for the quote elements to appear
await page.wait_element(By.CSS_SELECTOR, ".quote", timeout=3)
# Where to store the scraped data
quotes = []
# Select all quote elements
quote_elements = await page.find_elements(By.CSS_SELECTOR, ".quote")
# Iterate over them and scrape data from them
for quote_element in quote_elements:
# Extract the quote text (and remove curly quotes)
text_element = await quote_element.find_element(By.CSS_SELECTOR, ".text")
text = (await text_element.get_element_text()).replace("“", "").replace("”", "")
# Extract the author
author_element = await quote_element.find_element(By.CSS_SELECTOR, ".author")
author = await author_element.get_element_text()
# Extract all tags
tag_elements = await quote_element.find_elements(By.CSS_SELECTOR, ".tag")
tags = [await tag_element.get_element_text() for tag_element in tag_elements]
# Populate a new quote with the scraped data
quote = {
"text": text,
"author": author,
"tags": tags
}
# Append the extracted quote to the list
quotes.append(quote)
# Export the scraped data to CSV
with open("quotes.csv", "w", newline="", encoding="utf-8") as csvfile:
# Add the header
fieldnames = ["text", "author", "tags"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Populate the output file with the scraped data
writer.writeheader()
for quote in quotes:
writer.writerow(quote)
# Execute the async scraping function
asyncio.run(main())¡Wow! En menos de 60 líneas de código, puedes construir un bot de web scraping con Pydoll.
Prueba el script anterior ejecutándolo:
python scraper.pyCuando termine de ejecutarse, aparecerá un archivo quotes.csv en la carpeta del proyecto. Ábrelo y verás los datos raspados perfectamente organizados:

¡Et voilà! Su script de raspado web Pydoll funciona como se esperaba.
Evitar Cloudflare con Pydoll
Al interactuar con un sitio en una herramienta de automatización del navegador, uno de los mayores retos a los que se enfrentará son los cortafuegos de aplicaciones web (WAF). Piensa en soluciones como Cloudflare, que suelen venir con protecciones anti-bot avanzadas.
Cuando se sospecha que sus solicitudes proceden de un navegador automatizado, estos sistemas suelen mostrar un CAPTCHA. En algunos casos, lo presentan a todos los usuarios durante la primera visita al sitio.
Evitar CAPTCHAs en Python no es pan comido. Sin embargo, hay maneras de engañar a Cloudflare para que piense que eres un usuario real, de modo que no muestre un CAPTCHA en primer lugar. Aquí es donde Pydoll entra en juego, proporcionando una API dedicada para ese propósito.
Para demostrar cómo funciona, utilizaremos la página de prueba “Antibot Challenge” del sitio ScrapingCourse:

Como puede ver, la página siempre realiza el Desafío JavaScript de Cloudflare. Una vez superado, muestra algún contenido de muestra para confirmar que la protección anti-bot ha sido derrotada.
Pydoll expone dos enfoques para manejar Cloudflare:
- Enfoque de gestor de contexto: Maneja el desafío anti-bot de forma sincrónica, pausando la ejecución del script hasta que se resuelve el desafío.
- Enfoque de procesamiento en segundo plano: Trata con el anti-bot de forma asíncrona en segundo plano.
Cubriremos ambos métodos. Sin embargo, como se menciona en la documentación oficial, tenga en cuenta que la derivación de Cloudflare no siempre funciona. Esto se debe a problemas como la reputación IP o el historial de navegación.
Para técnicas más avanzadas, lea nuestro tutorial completo sobre el scraping de sitios protegidos por Cloudflare.
Enfoque del gestor de contexto
Para que Pydoll gestione automáticamente el desafío anti-bot de Cloudflare por ti, utiliza el método expect_and_bypass_cloudflare_captcha() de la siguiente manera:
import asyncio
from pydoll.browser.chrome import Chrome
from pydoll.constants import By
async def main():
async with Chrome() as browser:
# Launch the Chrome browser and open a new page
await browser.start()
page = await browser.get_page()
# Wait for the Cloudflare challenge to be executed
async with page.expect_and_bypass_cloudflare_captcha():
# Connect to the Cloudflare-protected page:
await page.go_to("https://www.scrapingcourse.com/antibot-challenge")
print("Waiting for Cloudflare anti-bot to be handled...")
# This code runs only after the anti-bot is successfully bypassed
print("Cloudflare anti-bot bypassed! Continuing with automation...")
# Print the text message on the success page
await page.wait_element(By.CSS_SELECTOR, "#challenge-title", timeout=3)
success_element = await page.find_element(By.CSS_SELECTOR, "#challenge-title")
success_text = await success_element.get_element_text()
print(success_text)
asyncio.run(main())Al ejecutar este script, la ventana de Chrome omitirá automáticamente el desafío y cargará la página de destino.
La salida será:
Waiting for Cloudflare anti-bot to be handled...
Cloudflare anti-bot bypassed! Continuing with automation...
You bypassed the Antibot challenge! 😀Enfoque del tratamiento de fondo
Si prefieres no bloquear la ejecución del script mientras Pydoll gestiona el desafío de Cloudflare, puedes utilizar los métodos enable_auto_solve_cloudflare_captcha() y disable_auto_solve_cloudflare_captcha() de esta forma:
import asyncio
from pydoll.browser import Chrome
from pydoll.constants import By
async def main():
async with Chrome() as browser:
# Launch the Chrome browser and open a new page
await browser.start()
page = await browser.get_page()
# Enable automatic captcha solving before navigating
await page.enable_auto_solve_cloudflare_captcha()
# Connect to the Cloudflare-protected page:
await page.go_to("https://www.scrapingcourse.com/antibot-challenge")
print("Page loaded, Cloudflare anti-bot will be handled in the background...")
# Disable anti-bot auto-solving when no longer needed
await page.disable_auto_solve_cloudflare_captcha()
# Print the text message on the success page
await page.wait_element(By.CSS_SELECTOR, "#challenge-title", timeout=3)
success_element = await page.find_element(By.CSS_SELECTOR, "#challenge-title")
success_text = await success_element.get_element_text()
print(success_text)
asyncio.run(main())Este enfoque permite a su scraper realizar otras operaciones mientras Pydoll resuelve el desafío anti-bot de Cloudflare en segundo plano.
Esta vez, la salida será:
Page loaded, Cloudflare anti-bot will be handled in the background...
You bypassed the Antibot challenge! 😀Limitaciones de este enfoque del Web Scraping
Con Pydoll -o cualquier herramienta de scraping- sienvías demasiadas peticiones, es muy probable que el servidor de destino te bloquee. Esto ocurre porque la mayoría de los sitios web limitan la tasa de peticiones para evitar que los bots (como tu script de scraping) saturen sus servidores con peticiones.
Se trata de una técnica anti-scraping y anti-DDoS habitual. Al fin y al cabo, nadie quiere que su sitio se vea inundado de tráfico automatizado.
Incluso si sigue las mejores prácticas, como respetar robots.txt, realizar muchas peticiones desde la misma dirección IP puede levantar sospechas. Como resultado, es posible que te encuentres con errores 403 Forbidden o 429 Too Many Requests.
La mejor forma de evitarlo es rotar su dirección IP utilizando un proxy web.
Si no estás familiarizado con ello, un proxy web actúa como intermediario entre tu scraper y el sitio web de destino. Reenvía tus peticiones y devuelve las respuestas, haciendo que el sitio de destino parezca que el tráfico proviene del proxy y no de tu máquina real.
Esta técnica no sólo ayuda a ocultar tu IP real, sino que también es útil para eludir las restricciones geográficas y muchos otros casos de uso.
Existen varios tipos de proxies. Para evitar que te bloqueen, necesitas un proveedor de alta calidad que ofrezca proxies rotativos auténticos como Bright Data.
En la siguiente sección, verá cómo integrar los proxies rotativos de Bright Data con Pydoll para raspar páginas web de forma más eficaz, especialmente a escala.
Integración de Pydoll con los proxies rotativos de Bright Data
Bright Data controla una de las mayores redes proxy del mundo, en la que confían empresas de la lista Fortune 500 y más de 20.000 clientes. Su red de proxy incluye:
- Proxies de centros de datos – Más de 770.000 IP de centros de datos.
- Proxies residenciales – Más de 150.000.000 de IP residenciales en más de 195 países.
- Proxies de I SP – Más de 700.000 IP de ISP.
Siga los pasos que se indican a continuación y aprenda a utilizar los proxies residenciales de Bright Data con Pydoll.
Si aún no tiene una cuenta, regístrese en Bright Data. De lo contrario, inicie sesión para acceder a su panel de control:

En el panel de control, haga clic en el botón “Obtener productos proxy”:

Será redirigido a la página “Proxies & Scraping Infrastructure”:

En la tabla, busque la fila “Residencial” y haga clic en ella:

Llegará a la página de configuración del proxy residencial:

Si es la primera vez, sigue el asistente de instalación para configurar el proxy según tus necesidades. Si necesitas ayuda, ponte en contacto con el servicio de asistencia 24/7.
Ve a la pestaña “Visión general” y localiza el host, el puerto, el nombre de usuario y la contraseña de tu proxy:

Utilice esos datos para construir su URL proxy:
proxy_url = "<brightdata_proxy_username>:<brightdata_proxy_password>@<brightdata_proxy_host>:<brightdata_proxy_port>";Sustituya los marcadores de posición (, , , ) con las credenciales reales del proxy.
Asegúrese de activar el producto proxy cambiando el interruptor de “Off” a “On”:
Ahora que ya tienes tu proxy listo, así es cómo integrarlo en Pydoll utilizando sus capacidades de configuración de proxy incorporadas:
import asyncio
from pydoll.browser.chrome import Chrome
from pydoll.browser.options import Options
from pydoll.constants import By
import traceback
async def main():
# Create browser options
options = Options()
# The URL of your Bright Data proxy
proxy_url = "<brightdata_proxy_username>:<brightdata_proxy_password>@<brightdata_proxy_host>:<brightdata_proxy_port>" # Replace it with your proxy URL
# Configure the proxy integration option
options.add_argument(f"--proxy-server={proxy_url}")
# To avoid potential SSL errors
options.add_argument("--ignore-certificate-errors")
# Start browser with proxy configuration
async with Chrome(options=options) as browser:
await browser.start()
page = await browser.get_page()
# Visit a special page that returns the IP of the caller
await page.go_to("https://httpbin.io/ip")
# Extract the page content containing only the IP of the incoming
# request and print it
body_element = await page.find_element(By.CSS_SELECTOR, "body")
body_text = await body_element.get_element_text()
print(f"Current IP address: {body_text}")
# Execute the async scraping function
asyncio.run(main())Cada vez que ejecute este script, verá una dirección IP de salida diferente, gracias a la rotación de proxy de Bright Data.
Nota: Normalmente, la opción --proxy-server de Chrome no admite proxies autenticados. Sin embargo, el gestor de proxy avanzado de Pydoll anula esta limitación y permite utilizar servidores proxy protegidos por contraseña.
Con los proxies rotativos de Bright Data, la rotación de proxies de Pydoll es sencilla, fiable y escalable.
Alternativas a Pydoll para Web Scraping
Pydoll es sin duda una potente librería de web scraping, especialmente para automatizar navegadores con funciones anti-bot bypass incorporadas. Sin embargo, no es la única herramienta en el juego.
A continuación se presentan algunas alternativas sólidas de Pydoll que vale la pena considerar:
- SeleniumBase: Un marco de Python construido sobre las API de Selenium/WebDriver, que ofrece un conjunto de herramientas de nivel profesional para la automatización web. Admite desde pruebas integrales hasta flujos de trabajo de scraping avanzados.
- ChromeDriver no detectado: Una versión parcheada de ChromeDriver diseñada para evadir la detección de servicios anti-bot populares como Imperva, DataDome y Distil Networks. Ideal para el scraping sigiloso cuando se utiliza Selenium.
Si busca una solución de raspado web más general que funcione en cualquier sitio web y admita varios lenguajes de programación, consulte nuestros servicios de raspado:
- Navegador de raspado: Un navegador compatible con Selenium-, Playwright-, Puppeteer con capacidades de desbloqueo integradas.
- APIs de Web Scraper: API preconfiguradas para extraer datos estructurados de más de 100 dominios importantes.
- Desbloqueador Web: Una API todo en uno que maneja el desbloqueo de sitios en sitios con protecciones anti-bot.
- API SERP: Una API especializada que desbloquea los resultados de los motores de búsqueda y extrae datos completos de las SERP.
Conclusión
En este tutorial de integración de proxy, has aprendido qué es Pydoll y cómo funciona. Exploramos cómo usarlo para el web scraping en un sitio web con JavaScript y vimos cómo hacer frente a su principal
limitación a través de la integración de proxy.
También ha comprendido por qué utilizar Pydoll sin un mecanismo de rotación de IP puede dar lugar a resultados poco fiables. Para obtener un rendimiento estable, mayor seguridad y escalabilidad, debe elegir un proveedor de proxy de confianza. Ahorre tiempo y esfuerzo yendo directamente al mejor proveedor de proxy del mercado, Bright Data.
Cree una cuenta y empiece a probar nuestros proxies gratis hoy mismo.





