Gracias a sus amplias bibliotecas y herramientas, PHP es un excelente lenguaje para crear raspadores web. Diseñado específicamente para el desarrollo web, PHP gestiona tareas de raspado web con facilidad y fiabilidad.
Hay muchas maneras diferentes para raspar sitios web con PHP, y explorarás varios métodos distintos en este artículo. En concreto, aprenderás a raspar sitios web con curl, file_get_contents, Symfony BrowserKit y el componente Panther de Symfony. Además, descubrirás algunos desafíos comunes a los que te puedes enfrentar durante el raspado web y cómo evitarlos.
En este artículo, vamos a analizar estas cuestiones:
En esta sección, descubrirás varios métodos de uso común para raspar sitios web básicos y complejos/dinámicos.
Ten en cuenta: si bien en este tutorial cubrimos varios métodos, esta no es en absoluto una lista exhaustiva.
Requisitos previos
Para seguir este tutorial, necesitas la última versión de PHP y Composer, un administrador de dependencias para PHP. Este artículo se probó con PHP 8.1.18 y Composer 2.5.5.
Una vez configurados PHP y Composer, crea un directorio llamado php-web-scraping y cd en él:
mkdir php-web-scraping
cd $_
Trabajarás en este directorio durante el resto del tutorial.
curl
curl es una biblioteca de bajo nivel casi omnipresente y una herramienta CLI escrita en C. Se puede usar para obtener el contenido de una página web mediante HTTP o HTTPS. En casi todas las plataformas, PHP incluye soporte para curl listo para usar.
En esta sección, extraerás datos de una página web muy básica que enumera los países por población según estimaciones de las Naciones Unidas. Extraerás información de los enlaces del menú junto con los textos de los enlaces.
Para empezar, crea un archivo llamado curl.php y, a continuación, ejecuta curl en ese archivo con la función curl_init :
<?php
$ch = curl_init();
A continuación, define las opciones para acceder a la página web. Esto incluye configurar la URL y el método HTTP (GET, POST, etc.) mediante la función curl_setopt:
En este código, estableces la URL de destino en la página web y el método en GET. El CURLOPT_RETURNTRANSFER le dice a curl que devuelva la respuesta HTML.
Cuando curl esté listo, puedes hacer la solicitud usando curl_exec:
$response = curl_exec($ch);
Obtener los datos HTML es solo el primer paso del raspado web. Para extraer datos de la respuesta HTML, es necesario utilizar varias técnicas. El método más simple es usar expresiones regulares para una extracción de HTML muy básica. Sin embargo, ten en cuenta que no puedes analizar HTML arbitrario con expresiones regulares, pero, para un análisis muy simple, son suficientes.
Por ejemplo, extrae las etiquetas <a> , que tienen los atributos href y title y contienen un <span>:
Después, libera los recursos mediante la función curl_close:
curl_close($ch);
Ejecuta el código con lo siguiente:
php curl.php
Deberías ver que extrae correctamente los enlaces:
curl te da un control de muy bajo nivel sobre cómo se obtiene una página web a través de HTTP/HTTPS. Puedes ajustar las diferentes propiedades de conexión e incluso añadir medidas adicionales, como servidores proxy (más sobre esto después), agentes de usuario y tiempos de espera.
Además, curl se instala de forma predeterminada en la mayoría de los sistemas operativos, lo que lo convierte en una excelente opción para escribir un raspador web multiplataforma.
Sin embargo, como has visto, curl no es suficiente por sí solo y necesitas un analizador HTML para extraer los datos correctamente. curl tampoco puede ejecutar JavaScript en una página web, lo que significa que no puedes raspar páginas web dinámicas y aplicaciones de página única (SPA) con curl.
file_get_contents
La función file_get_contents se usa principalmente para leer el contenido de un archivo. Sin embargo, si pasas una URL HTTP, puedes obtener datos HTML de una página web. Esto significa que file_get_contents puede reemplazar el uso de curl en el código anterior.
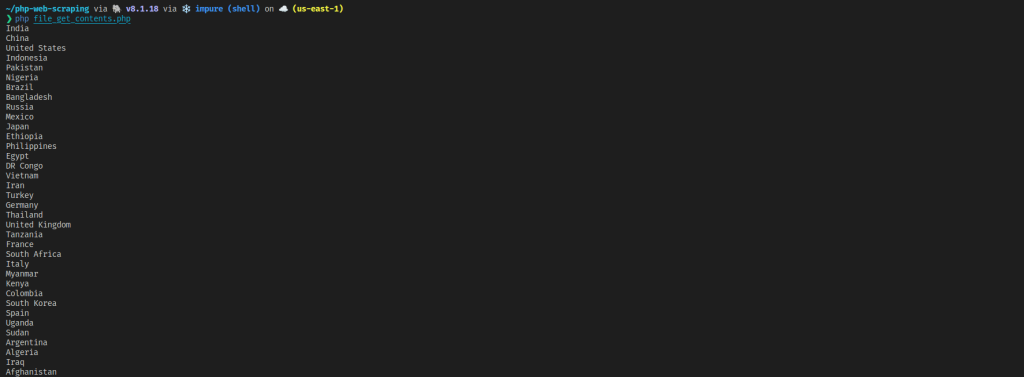
En esta sección, rasparás la página igual que antes, pero, en esta ocasión, el raspador será más avanzado y podrás extraer los nombres de todos los países de la tabla.
Crea un archivo llamado file_get-contents.php y empieza por pasar una URL a file_get_contents:
La variable $html ahora contiene el código HTML de la página web.
Al igual que en el ejemplo anterior, obtener los datos HTML es solo el primer paso. Para animar las cosas, usa libxml para seleccionar elementos mediante los selectores XPath. Para ello, primero tienes que iniciar un DOMDocument y cargar el HTML en él:
$doc = new DOMDocument;
libxml_use_internal_errors(true);
$doc->loadHTML($html);
libxml_clear_errors();
Aquí, selecciona los países en el siguiente orden: el primer elemento tbody, un elemento tr dentro del elemento tbody, el primer td en el elemento tr y un a con un atributo title dentro del elemento td.
El siguiente código inicia una clase DOMXPath y usa evaluate para seleccionar el elemento mediante el selector XPath:
$xpath = new DOMXpath($doc);
$countries = $xpath->evaluate('(//tbody)[1]/tr/td[1]//a[@title=true()]');
Todo lo que queda es conectar los elementos e imprimir el texto:
foreach($countries as $country) {
echo $country->textContent . "n";
}
Ejecuta el código con lo siguiente:
php file_get_contents.php
Como puedes ver, file_get_contents es más fácil de usar que curl y, a menudo, se usa para obtener rápidamente el código HTML de una página web. Sin embargo, tiene los mismos inconvenientes que curl: necesitas un analizador HTML adicional y no puedes raspar páginas web y SPA dinámicas. Además, pierdes los controles ajustados que proporciona curl. Sin embargo, su simplicidad lo convierte en una buena opción para raspar sitios estáticos básicos.
BrowserKit de Symfony
BrowserKit de Symfony es un componente de la plataforma de Symfony que simula el comportamiento de un navegador real. Esto significa que puedes interactuar con la página web como en un navegador real; por ejemplo, haciendo clic en botones/enlaces, enviando formularios y retrocediendo y avanzando en el historial.
En esta sección, visitarás el blog de Bright Data, escribirás PHP en el cuadro de búsqueda y enviarás el formulario de búsqueda. A continuación, rasparás los nombres de los artículos del resultado:
Para usar BrowserKit de Symfony, debes instalar el componente BrowserKit con Composer:
composer require symfony/browser-kit
También necesitas instalar el componente HttpClient para realizar solicitudes HTTP a través de Internet:
composer require symfony/http-client
BrowserKit es compatible con la selección de elementos mediante selectores XPath de forma predeterminada. En este ejemplo, utilizas selectores CSS. Para ello, es necesario instalar también el componente CssSelector:
composer require symfony/css-selector
Crea un archivo llamado symfony-browserkit.php. En este archivo, inicia HttpBrowser:
<?php
require "vendor/autoload.php";
use SymfonyComponentBrowserKitHttpBrowser;
$client = new HttpBrowser();
Usa la función request para hacer una solicitud GET:
Para seleccionar el formulario donde se encuentra el botón de búsqueda, debes seleccionar el propio botón y usar la función form para obtener el formulario adjunto. El botón se puede seleccionar con la función filter pasando su ID. Una vez seleccionado el formulario, puedes enviarlo mediante la función submit de la clase Httpbrowser.
Al pasar un hash de los valores de las entradas, la función submit puede rellenar el formulario antes de enviarlo. En el código siguiente, a la entrada con el nombre q se le asigna el valor PHP, que equivale a escribir PHP en el cuadro de búsqueda:
Si bien BrowserKit de Symfony es una mejora con respecto a los dos métodos anteriores en términos de interacción con las páginas web, sigue teniendo limitaciones porque no puede ejecutar JavaScript. Esto significa que no puedes raspar sitios web y SPA dinámicos con BrowserKit.
Panther de Symfony
Panther de Symfony es otro componente de Symfony que envuelve al componente de BrowserKit. Sin embargo, Panther de Symfony ofrece una gran ventaja: en lugar de simular un navegador, ejecuta el código en un navegador real utilizando el protocolo WebDriver para controlar de forma remota un navegador real. Esto significa que puedes raspar cualquier sitio web, incluidos los sitios web dinámicos y las SPA.
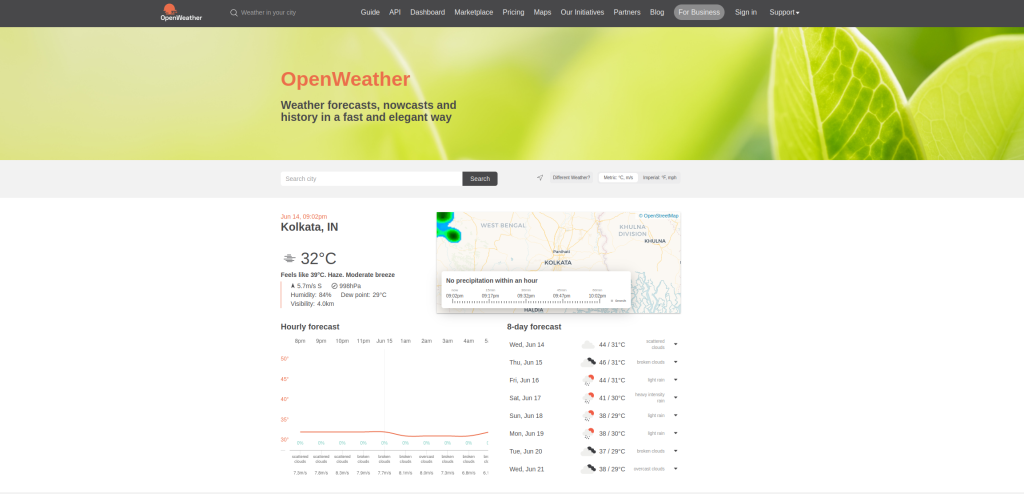
En esta sección, cargarás la página de inicio de OpenWeather, escribirás el nombre de tu ciudad en el cuadro de búsqueda, realizarás la búsqueda y obtendrás el clima actual de tu ciudad:
Para empezar, instala Panther de Symfony con Composer:
composer require symfony/panther
También necesitas instalar dbrekelmans/browser-driver-installer, que puede detectar automáticamente el navegador instalado en tu sistema e instalar el controlador correcto para él. Asegúrate de tener instalado en tu sistema un navegador basado en Firefox o Chromium:
composer require dbrekelmans/bdi
Para instalar el controlador apropiado en el directorio drivers, ejecuta la herramienta bdi:
vendor/bin/bdi detect drivers
Crea un archivo llamado symfony-panther.php y empieza por iniciar un cliente de Panther:
<?php
require 'vendor/autoload.php';
use SymfonyComponentPantherClient;
$client = Client::createFirefoxClient();
Nota: dependiendo de tu navegador, es posible que tengas que usar createChromeClient o createSeleniumClient en lugar de createFirefoxClient.
Como Panther usa BrowserKit de Symfony en segundo plano, los códigos siguientes son muy similares al código de la sección de BrowserKit de Symfony.
Empieza por cargar la página web mediante la función request. Cuando se carga la página, inicialmente está cubierta por un div con la clase owm-loader, que muestra la barra de progreso de la carga. Debes esperar a que este div desaparezca antes de empezar a interactuar con la página. Esto se puede hacer con la función waitForStaleness, que toma un selector CSS y espera a que se elimine del DOM.
Tras eliminar la barra de carga, debes aceptar las cookies para cerrar el cartel de cookies. Para ello, la función selectButton es muy útil, ya que puede buscar un botón por su texto. Una vez que tengas el botón, la función click realiza un clic sobre él:
Nota: dependiendo de la rapidez con la que se cargue la página, la barra de carga puede desaparecer antes de que se ejecute la función waitForStaleness. Esto produce una excepción. Por este motivo, esa línea está envuelta en un bloque try-catch.
Ahora es el momento de escribir Kolkata en la barra de búsqueda. Selecciona la barra de búsqueda con la función filter y utiliza la función sendKeys para proporcionar información a la barra de búsqueda. A continuación, haz clic en el botón Buscar :
Una vez que se selecciona el botón, aparece un buzón de sugerencias de autocompletar. Puedes usar la función waitForVisibility para esperar a que la lista esté visible y, a continuación, hacer clic en el primer elemento con la combinación de filter y click como antes:
Aquí estás esperando que el elemento con el selector .orange-text+h2 contenga Kolkata. Esto indica que se han cargado los resultados.
Ejecuta el código con lo siguiente:
php symfony-panther.php
El resultado es algo así:
Desafíos y posibles soluciones para el raspado web
Aunque PHP facilita la escritura de raspadores web, administrar proyectos de raspado web de la vida real puede resultar complejo. Pueden surgir numerosas situaciones que presenten desafíos que deben abordarse. Estos retos pueden deberse a factores como la estructura de los datos (por ejemplo, paginación) o a las medidas antibot adoptadas por los propietarios del sitio web (por ejemplo, trampas honeypot).
En esta sección, conocerás algunos desafíos comunes y cómo combatirlos.
Navegar por sitios web paginados
Al raspar casi cualquier sitio web real, es probable que te encuentres con una situación en la que no se carguen todos los datos a la vez. O, dicho de otro modo, los datos están paginados. Puede haber dos tipos de paginación:
Todas las páginas se encuentran en URL distintas. El número de página se pasa a través de un parámetro de consulta o un parámetro de ruta. Por ejemplo, example.com?page=3 o example.com/page/3.
Las páginas nuevas se cargan con JavaScript cuando se selecciona el botón Siguiente.
En el primer escenario, puedes cargar las páginas en bucle y convertirlas en páginas web independientes. Por ejemplo, al usar file_get_contents, el siguiente código raspa las diez primeras páginas de un sitio de ejemplo:
for($page = 1; $page <= 10; $page++) {
$html = file_get_contents('https://example.com/page/{$page}');
// DO the scraping
}
En el segundo escenario, necesitas usar una solución que pueda ejecutar JavaScript, como Panther de Symfony. En este ejemplo, debe hacer clic en el botón correspondiente que carga la página siguiente. No olvides esperar un poco a que se cargue la nueva página:
for($page = 1; $page <= 10; $page++>) {
// Do the scraping
// Load the next page
$crawler->selectButton("Next")->click();
$client->waitForElementToContain(".current-page", $page+1)
}
Nota: deberías sustituir la lógica de espera adecuada que tenga sentido para el sitio web concreto que estás raspando.
Proxies rotativos
Un servidor proxy actúa como intermediario entre el equipo y el servidor web de destino. Impide que el servidor web vea tu dirección IP, preservando así tu anonimato.
Sin embargo, no debes confiar en un solo servidor proxy, ya que puede vetarse. En su lugar, debes usar varios servidores proxy y rotar entre ellos. El siguiente código proporciona una solución muy básica en la que se usa una matriz de proxies y uno de ellos se elige al azar:
Muchos sitios web utilizan los CAPTCHA para garantizar que el usuario sea un ser humano y no un bot. Desafortunadamente, esto significa que tu raspador web puede quedar atrapado.
Los CAPTCHA pueden ser muy primitivos, como una simple casilla de verificación que pregunta: «¿Eres humano?» O pueden usar un algoritmo más avanzado, como reCAPTCHA o hCaptcha de Google. Probablemente puedas salirte con la tuya con los CAPTCHA primitivos manipulando páginas web básicas (por ejemplo, marcando una casilla), pero, para combatir los CAPTCHA avanzados, necesitas una herramienta dedicada como 2Captcha. 2Captcha usa personas para resolver los CAPTCHA. Solo tienes que pasar los detalles requeridos a la API de 2Captcha y te devolverá el CAPTCHA resuelto.
Para empezar a usar 2Captcha, tienes que crear una cuenta y obtener una clave de API.
Instala 2Captcha con Composer:
composer require 2captcha/2captcha
En tu código, crea una instancia de TwoCaptcha:
$solver = new TwoCaptchaTwoCaptcha('YOUR_API_KEY');
A continuación, usa 2Captcha para resolver los CAPTCHA:
Las trampas honeypot son una medida antibot que imita un servicio o una red para atraer a los raspadores web y a los rastreadores y desviarlos del objetivo real. Si bien son útiles para prevenir los ataques de bots, pueden resultar problemáticas para el raspado web. No querrás que tu raspador se quede atascado en una de estas trampas.
Hay todo tipo de medidas que puedes tomar para evitar caer en una de ellas. Por ejemplo, los enlaces de las trampas honeypot suelen estar ocultos para que un usuario real no los vea, pero un bot puede recogerlos. Para evitar caer en la trampa, puedes intentar evitar hacer clic en enlaces ocultos (los enlaces con propiedades CSS display: none o visibility: none).
Otra opción es rotar los proxies para que, si una de las direcciones IP del servidor proxy queda atrapada en el honeypot y se veta, puedas seguir conectándote a través de otros proxies.
Conclusión
Gracias a la biblioteca y la plataforma superiores de PHP, crear un raspador web es fácil. En este artículo, aprendiste a hacer lo siguiente:
Raspar un sitio web estático usando curl y expresiones regulares
Raspar un sitio web estático con file_get_contents y libxml
Raspar un sitio estático con BrowserKit de Symfony y enviar formularios
Raspar un sitio dinámico complejo con Panther de Symfony
Desafortunadamente, en el raspado usando estos métodos, aprendiste que el raspado con PHP conlleva complejidades adicionales. Por ejemplo, es posible que tengas que disponer de varios proxies y crear cuidadosamente tu raspador web para evitar las trampas honeypot.
Y aquí es donde Bright Data entra en acción…
Información de los proxies de Bright Data:
Proxies residenciales: con más de 72 millones de IP reales de 195 países, los proxies residenciales de Bright Data te permiten acceder al contenido de cualquier sitio web independientemente de tu ubicación, al tiempo que evitan los vetos de IP y los CAPTCHA.
Proxies de ISP: con más de 700 000 IP de ISP, aprovecha las IP estáticas reales de cualquier ciudad del mundo, asignadas por los ISP y alquiladas a Bright Data para su uso exclusivo, durante el tiempo que necesites.
Proxies de centros de datos: con más de 770 000 IP de centros de datos, la red de proxies de centros de datos de Bright Data está compuesta por varios tipos de IP en todo el mundo, en un grupo de IP compartidas o para la compra individual.
Proxies móviles: con más de 7 millones de IP móviles, la red avanzada de IP móviles de Bright Data ofrece la red de IP 3G/4G/5G de pares reales más rápida y grande del mundo.
Únete a la mayor red de proxies y obtén una prueba gratuita de proxies.