

Walmart es la empresa más grande del mundo tanto en ingresos como en número de empleados. A diferencia de la opinión popular, Walmart es mucho más que una corporación minorista. De hecho, es uno de los mayores sitios web de comercio electrónico del mundo, lo que lo convierte en una gran fuente de información sobre productos. Sin embargo, debido a la vasta cartera de productos, es imposible para cualquier persona recopilar estos datos manualmente, por lo que es el caso de uso ideal para el raspado web.
Con el raspado web, puede recuperar rápidamente datos sobre miles de productos Walmart (como el nombre del producto, el precio, la descripción, las imágenes y las valoraciones) y almacenarlos en cualquier formato que le resulte útil. El raspado de datos de Walmart le permitirá controlar los precios de los diferentes productos y su nivel de existencias, analizar los movimientos del mercado y el comportamiento de los clientes, y crear diferentes aplicaciones.
En este artículo, conocerá dos métodos completamente diferentes para hacer raspado web de Walmart.com. En primer lugar, seguirá las instrucciones paso a paso para aprender a raspar datos web de Walmart utilizando Python y Selenium, una herramienta utilizada principalmente para automatizar aplicaciones web. En segundo lugar, aprenderá cómo puede utilizar más fácilmente Walmart Scraper de Bright Data para hacer lo mismo.
Raspado de Walmart
Como usted sabe, hay muchas maneras diferentes de raspar sitios web, incluyendo Walmart. Uno de estos métodos implica la utilización de Python y Selenium.
Instrucciones para raspar datos en Walmart con Python y Selenium
Python es uno de los lenguajes de programación más populares cuando se trata de raspado web. Mientras tanto, Selenium se utiliza principalmente para automatizar las pruebas. Sin embargo, también se puede utilizar para el raspado web debido a su capacidad para automatizar los navegadores web.
En esencia, Selenium simula acciones manuales en un navegador web. Con Python y Selenium, puede simular la apertura de un navegador web y cualquier página web y luego raspar información de esa página en particular. Esto lo hace con un WebDriver, que se utiliza para controlar los navegadores web.
Si aún no tiene Selenium instalado, es necesario instalar tanto la biblioteca Selenium como un controlador de navegador. Las instrucciones para hacerlo están disponibles en la documentación de Selenium.
Debido a su popularidad, el ChromeDriver también se utilizará en este artículo, pero los pasos son los mismos independientemente del controlador.
Ahora echa un vistazo a cómo puede utilizar Python y Selenium para realizar algunas tareas comunes de raspado web:
Buscar productos
Para empezar a utilizar Selenium para simular la búsqueda de productos de Walmart, es necesario importarlo. Puede hacerlo con el siguiente fragmento de código:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import ServiceDespués de importar Selenium, el siguiente paso es utilizarlo para abrir un navegador web, en este caso, Chrome. No obstante, puedes elegir el navegador que prefieras. Una vez abierto el navegador, los pasos a seguir son los mismos. Abrir un navegador es muy sencillo, y puede hacerlo ejecutando el siguiente segmento de código como un script de Python o desde un Jupyter Notebook:
s=Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=s)Este simple segmento de código no hará nada más que abrir Chrome. Este es el resultado:
Ahora que ha abierto Chrome, es necesario ir a la página de inicio de Walmart, lo que puede hacer con el siguiente código:
driver.get("https://www.walmart.com")
Como se puede ver en la captura de pantalla, esto simplemente abrirá Walmart.com.
El siguiente paso es mirar manualmente el código fuente de la página con la herramienta Inspect (Inspeccionar). Esta herramienta le permite inspeccionar cualquier elemento específico de una página web. Con ella, se puede ver (e incluso editar) el HTML y CSS de cualquier página web.
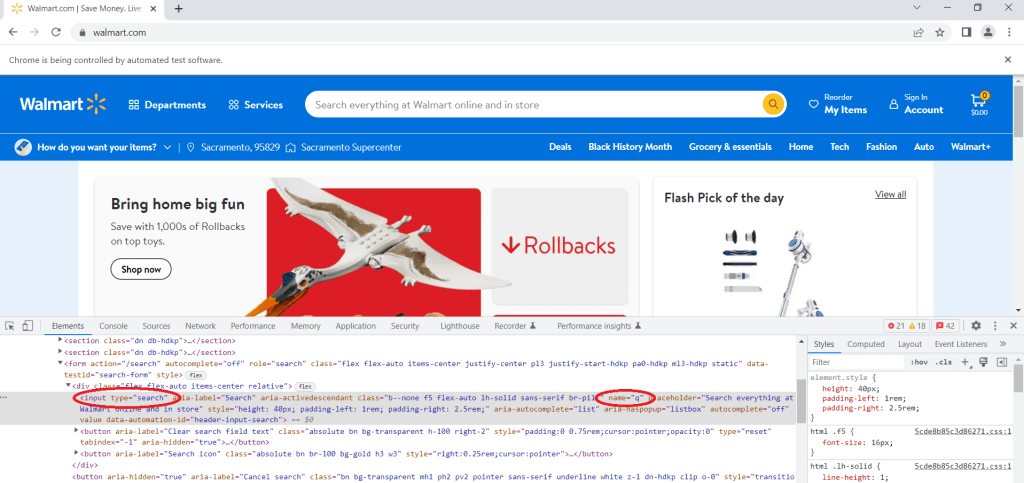
Como queremos buscar un producto, es necesario navegar hasta la barra de búsqueda, hacer clic con el botón derecho del ratón y hacer clic en Inspect. Localice la etiqueta input con el atributo type igual a search. Esta es la barra de búsqueda donde es necesario introducir el término de búsqueda. A continuación, es necesario encontrar el atributo name y ver su valor. En este caso, se puede ver que el atributo name tiene el valor q:
Para introducir una consulta en la barra de búsqueda, puede utilizar el siguiente fragmento de código:
search = driver.find_element("name", "q")
search.send_keys("Gaming Laptops")Este código introducirá la consulta Gaming Laptops, pero puede introducir cualquier frase que desee sustituyendo el término “Gaming Laptops” por cualquier otro término:
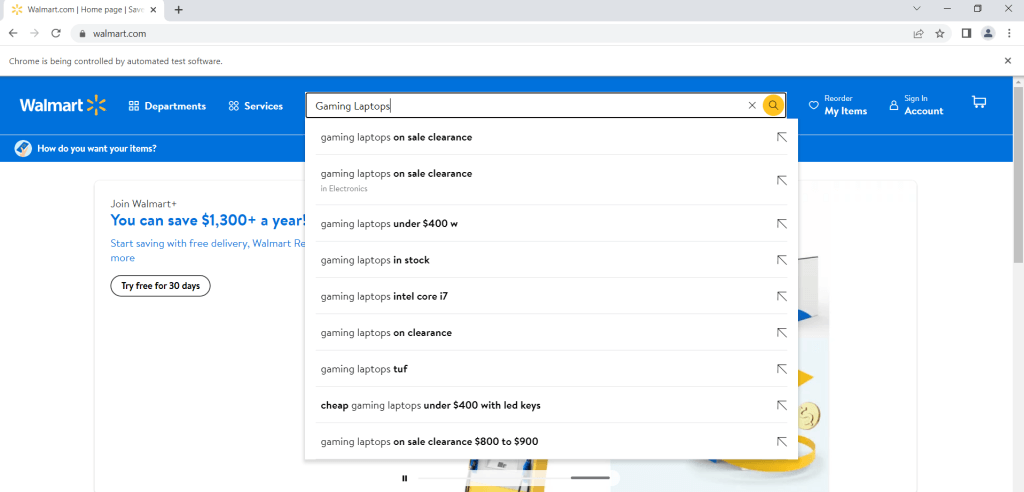
Tenga en cuenta que el código anterior sólo introducía el término de búsqueda en la barra de búsqueda, pero no lo buscaba verdaderamente. Para buscar realmente el término, es necesario usar la siguiente línea de código:
search.send_keys(Keys.ENTER)Este es el aspecto que tendrá la salida:
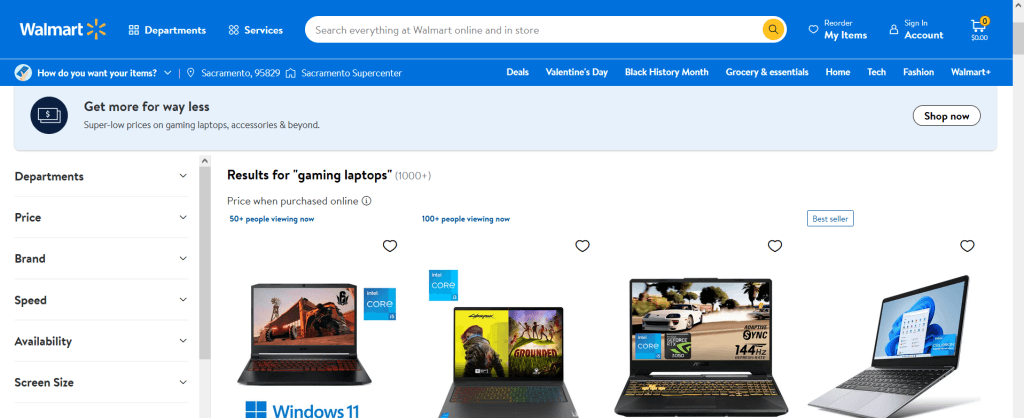
Ahora debería obtener todos los resultados para el término de búsqueda que introdujo. Y si desea buscar un término diferente, sólo es necesario ejecutar las dos últimas líneas de código con el nuevo término de búsqueda que desee.
Navegar a la página de un producto y raspar la información del producto
Otra tarea común que puede realizar con Selenium es abrir la página de un producto específico y obtener información sobre él. Por ejemplo, puede obtener el nombre, la descripción, el precio, la valoración o las reseñas del producto.
Supongamos que ha elegido un producto cuya información desea obtener. Comience por abrir la página del producto, lo que puede hacer con el siguiente código (suponiendo que ya ha instalado e importado Selenium en el primer ejemplo):
url = "https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101"
driver.get(url)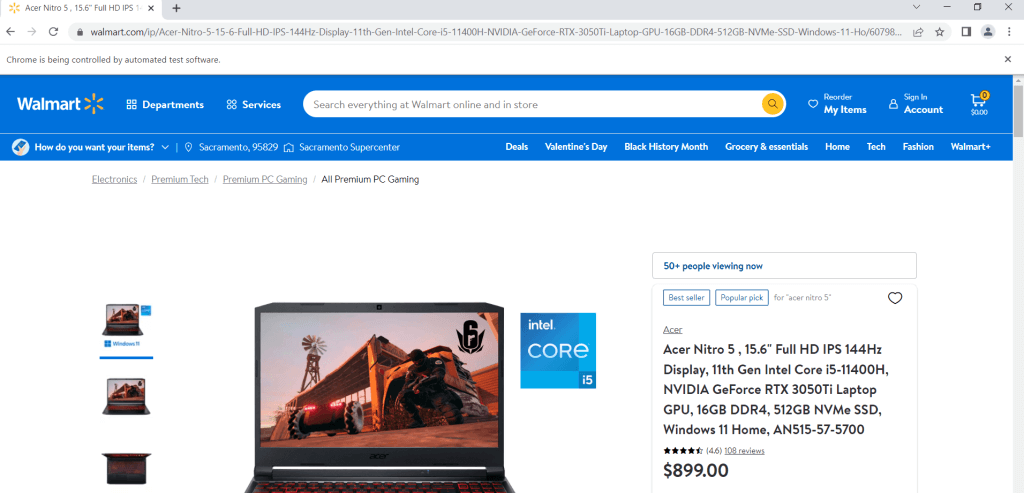
Una vez abierta la página, es necesario utilizar la herramienta Inspect. En esencia, es necesario navegar hasta cualquier elemento cuya información se desee obtener, hacer clic con el botón derecho del ratón y hacer clic en Inspect. Por ejemplo, una vez que inspeccione el título del producto, se dará cuenta de que el título está en una etiqueta H1. Como es la única etiqueta H1 de la página, puede obtenerla con el siguiente fragmento de código:
title = driver.find_element(By.TAG_NAME, "h1")
print(title.text)
>>>'Acer Nitro 5 , 15.6" Full HD IPS 144Hz Display, 11th Gen Intel Core i5-11400H, NVIDIA GeForce RTX 3050Ti Laptop GPU, 16GB DDR4, 512GB NVMe SSD, Windows 11 Home, AN515-57-5700'De forma similar, puede localizar y extraer el precio, la valoración y el número de opiniones del producto:
price = driver.find_element(By.CSS_SELECTOR, '[itemprop="price"]')
print(price.text)
>>> '$899.00'
rating = driver.find_element(By.CLASS_NAME,"rating-number")
print(rating.text)
>>> '(4.6)'
number_of_reviews = driver.find_element(By.CSS_SELECTOR, '[itemprop="ratingCount"]')
print(number_of_reviews.text)
>>> '108 reviews'Una cosa importante a tener en cuenta es que Walmart hace que sea extremadamente difícil raspar datos de la manera que se muestra aquí. Esto se debe a que Walmart cuenta con sistemas antispam que intentan bloquear activamente a los raspadores web. Así que si usted encuentra que sus esfuerzos de raspado web son constantemente bloqueados, sepa que probablemente no es su culpa, y no hay mucho que pueda hacer al respecto. Sin embargo, utilizar la solución que se muestra en la siguiente sección debería resultar mucho más eficaz.
Instrucciones paso a paso para raspar Walmart con Bright Data
Como puede ver, raspar Walmart con Python y Selenium no es realmente sencillo. Hay una manera mucho más fácil de raspar el sitio web de Walmart, que implica el uso del IDE Web Scraper de Bright Data. Con esta herramienta, puede realizar más fácil y eficientemente las mismas tareas mostradas anteriormente. Otra ventaja de utilizar el IDE Web Scraper es que Walmart no podrá bloquear instantáneamente sus esfuerzos.
Para utilizar IDE Web Scraper, primero es necesario registrarse para obtener una cuenta de Bright Data. Una vez registrado y conectado, verá la siguiente pantalla. Haga clic en el botón Conjuntos de Datos e IDE Web Scraper (Datasets & Web Scraper IDE) de la izquierda:
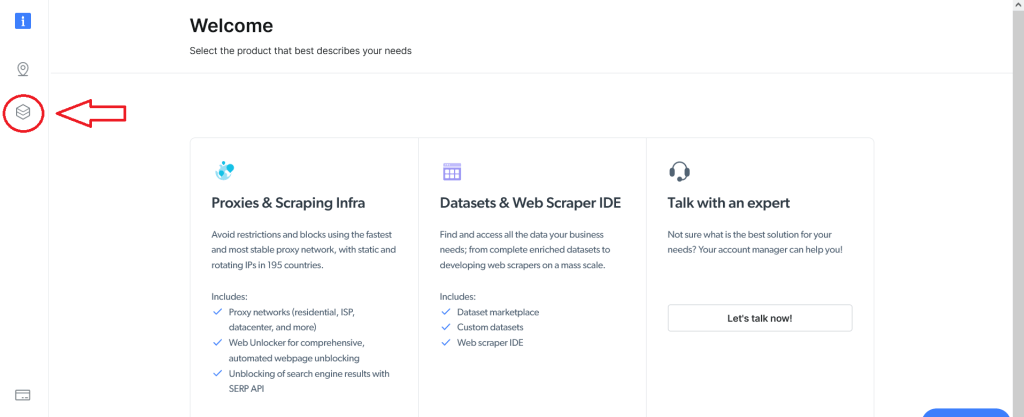
Esto le llevará a la siguiente pantalla. Desde allí, vaya al campo Mis raspadores (My scrapers):
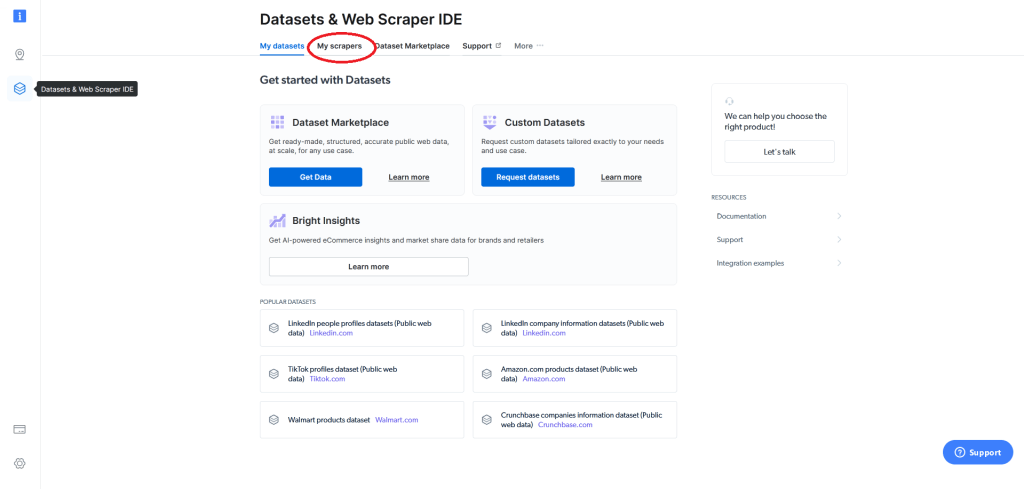
Esto mostrará sus raspadores web existentes (si tiene alguno) y le dará la opción de desarrollar un raspador web (IDE). Suponiendo que es la primera vez que utiliza Bright Data, no tendrá ningún raspador web, por lo que deberá hacer clic en Desarrollar un raspador web (IDE):
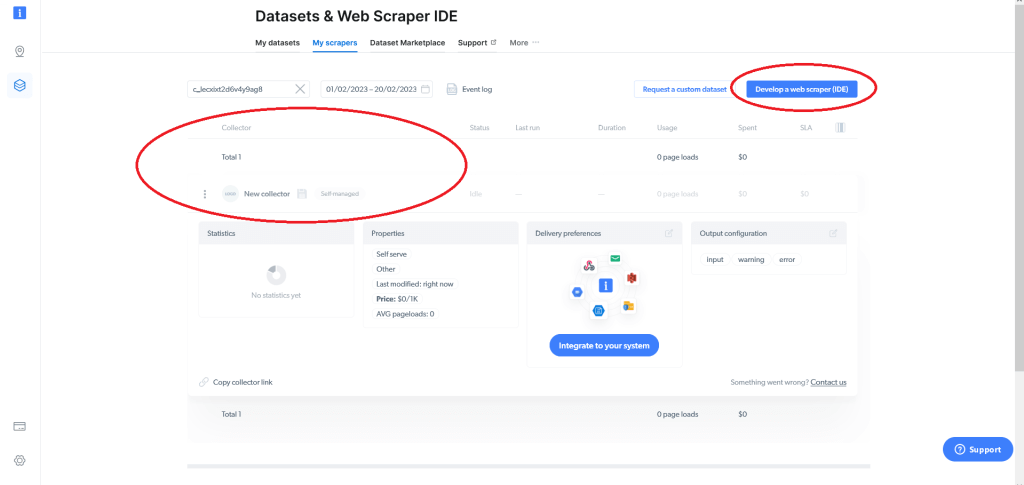
Se le dará la opción de utilizar una de las plantillas existentes o de iniciar el código desde cero. Para raspar datos de Walmart.com específicamente, haga clic en Comenzar desde cero (Start from scratch). Se abrirá el IDE Web Scraper de Bright Data:
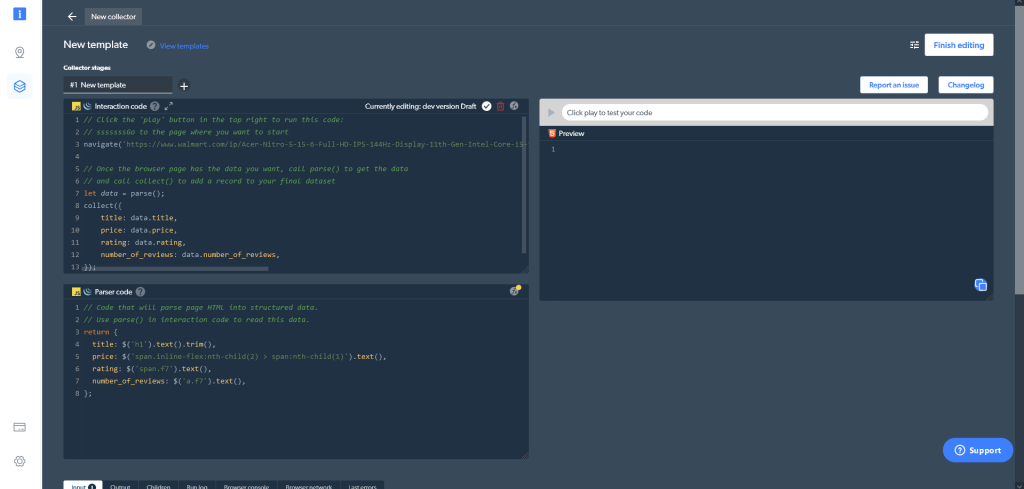
El IDE Web Scraper consta de varias ventanas diferentes. En la parte superior izquierda, encontrará la ventana Código de interacción (Interaction code). Como su nombre indica, utilizará esta ventana para interactuar con un sitio web, incluyendo navegar y desplazarse por el sitio web, hacer clic en los botones, así como realizar otras acciones. Debajo está la ventana de Código del analizador (Parser code), que le permitirá analizar los resultados HTML de la interacción con el sitio web. En la parte derecha, puede previsualizar y probar su código.
Además, en la configuración del código, en la esquina superior derecha, puede elegir entre diferentes tipos de trabajadores. Se puede alternar entre un código (la opción por defecto) y un browser worker para navegar y rastrear los datos:
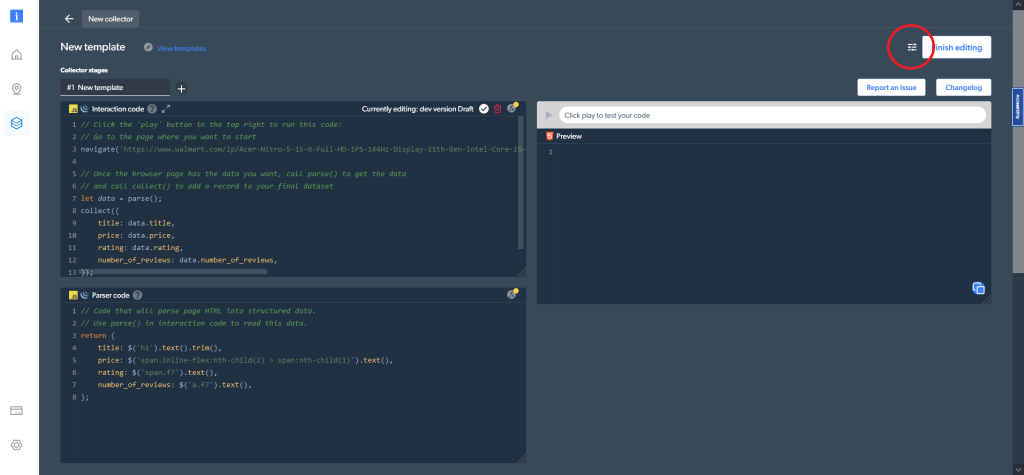
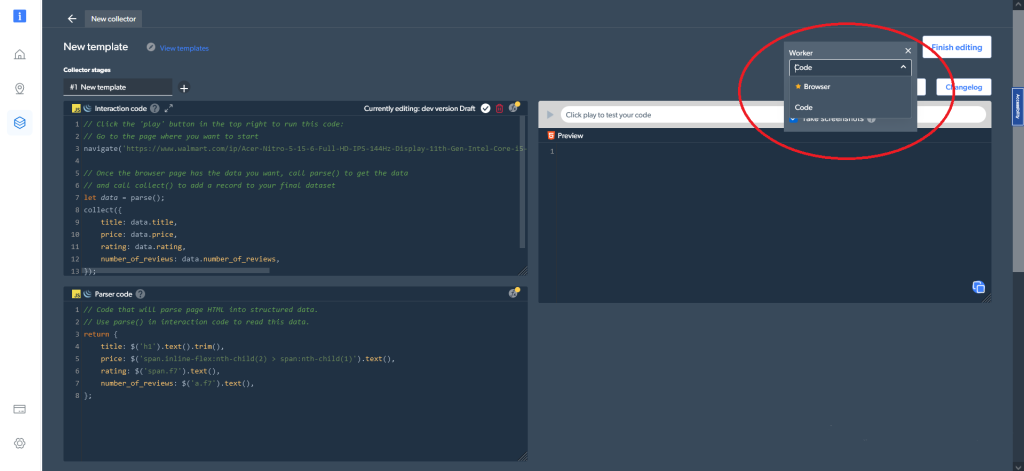
Ahora veamos cómo se pueden rastrear los mismos datos para el mismo producto como se hizo con Python y Selenium. Para empezar, navegue a la página del producto, lo que puede hacer con la siguiente línea de código en la ventana de Código de Interaccion:
navigate('https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101');Alternativamente, puede utilizar un parámetro de entrada modificable con navigate(input.url). En ese caso, añada las URLs que desea raspar como una entrada, como se muestra aquí:
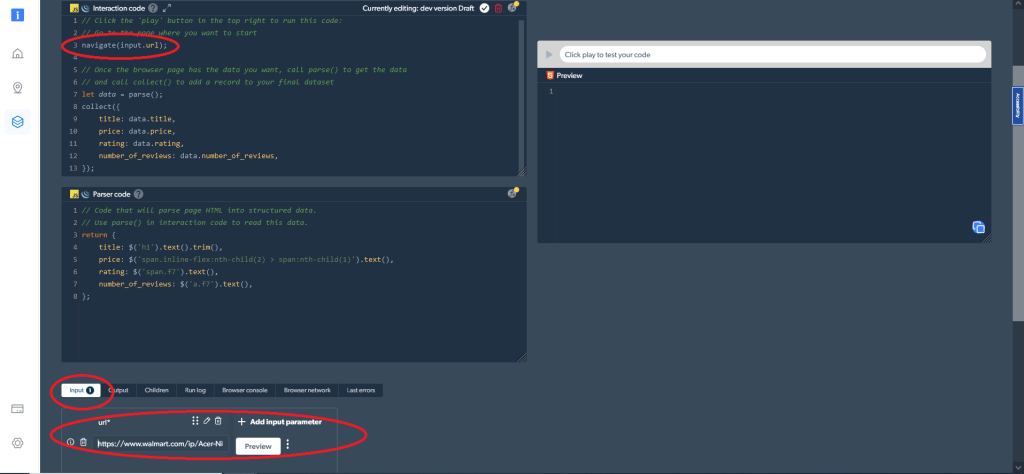
Después de esto, es necesario recoger los datos que desea, que se puede hacer con este código:
let data = parse();
collect({
title: data.title,
price: data.price,
rating: data.rating,
number_of_reviews: data.number_of_reviews,
});Lo último que es necesario hacer es convertir el HTML en datos estructurados. Puede hacerlo con la ayuda del siguiente fragmento de código en la ventana Parser code:
return {
title: $('h1').text().trim(),
price: $('span.inline-flex:nth-child(2) > span:nth-child(1)').text(),
rating: $('span.f7').text(),
number_of_reviews: $('a.f7').text(),
};A continuación, puede obtener los datos que desee directamente en el IDE Web Scraper. Simplemente haga clic en el botón de reproducción en el lado derecho (o pulse Ctrl + Enter), y los resultados que es necesario se dará salida. También puede descargar los datos directamente desde Web Scraper IDE:
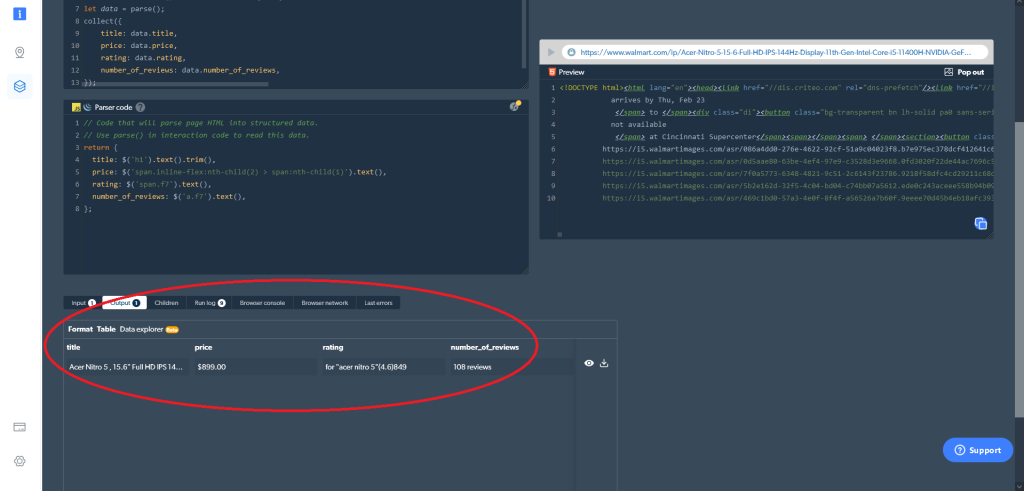
En caso de que haya elegido navegador en lugar de código como tipo de trabajador, este es el aspecto que tendría la salida:
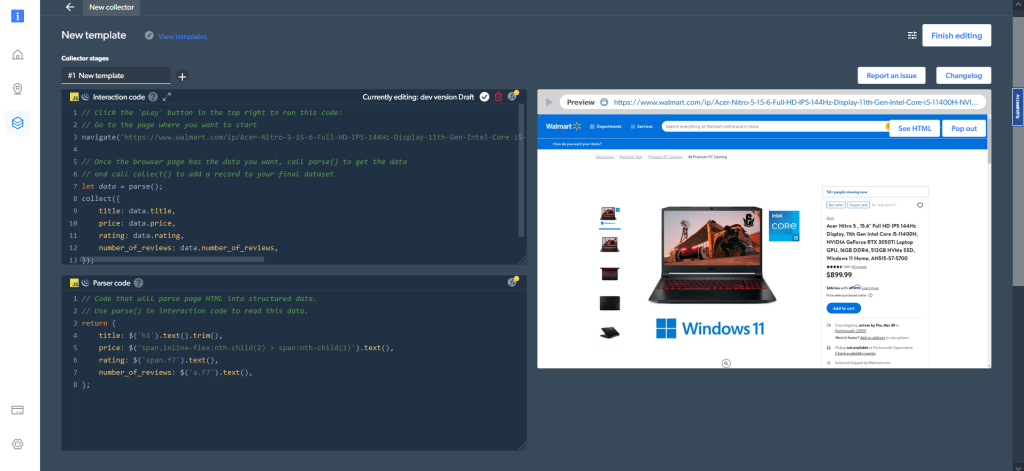
Obtener resultados directamente desde el IDE Web Scraper es sólo una de las opciones que tiene para obtener los datos. También puede establecer sus preferencias de entrega en el panel Mis raspadores (My scrapers).
Por último, si el raspado web le resulta demasiado difícil incluso con el IDE de Web Scraper, Bright Data pone a su disposición un conjunto de datos de productos Walmart en el Mercado de conjuntos de datos, donde hay numerosos conjuntos de datos disponibles con sólo pulsar un botón:
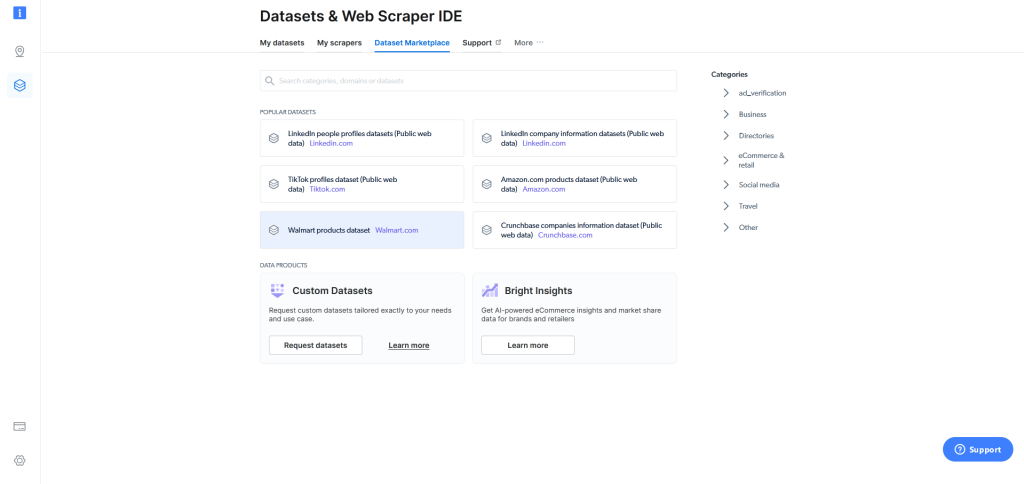
Como se muestra aquí, utilizar el IDE Web Scraper de Bright Data es más fácil y más amigable que construir su propio raspador web con Python y Selenium. Aún mejor, el IDE Web Scraper de Bright Data hace posible que los principiantes empiecen a recopilar datos de Walmart. Por el contrario, es necesario tener conocimientos sólidos de programación para raspar Walmart.com con Python y Selenium.
Aparte de la facilidad de uso, otra cosa impresionante sobre Walmart Scraper de Bright Data es su escalabilidad. Se pueden raspar datos sobre tantos productos como sea necesario sin ningún problema.
Una cosa clave a resaltar cuando se trata de raspado web son las leyes de privacidad. Muchas empresas prohíben o restringen la información que se puede extraer de su sitio web. Así que si usted está construyendo su propio raspador web con Python y Selenium, es necesario asegurarse de que no está rompiendo ninguna regla. Sin embargo, cuando utiliza el IDE Web Scraper de Bright Data, Bright Data asume esta responsabilidad y se asegurará de que se sigan las mejores prácticas de la industria y todas las regulaciones de privacidad.
Conclusión
En este artículo se discutió por qué raspar los datos de Walmart, pero lo más importante, en realidad aprendió a raspar los precios de Walmart, nombres, número de comentarios, y las calificaciones de miles de productos de Walmart.
Como se demostró, puede raspar estos datos usando Python y Selenium; sin embargo, este método puede ser difícil e implica desafíos que pueden intimidar a los principiantes. Existen soluciones que facilitan enormemente la extracción de datos de Walmart, como el IDE Web Scraper. Proporciona funciones y plantillas de código para raspar muchos sitios web populares, le permite evitar CAPTCHAs, y cumple con las leyes de protección de datos.






