

La creación de una solución fiable de extracción de datos web comienza con la infraestructura adecuada. En esta guía, creará una aplicación de una sola página que acepta cualquier URL de página web pública y una pregunta en lenguaje natural. A continuación, raspa, analiza y devuelve JSON limpio y estructurado, automatizando por completo el proceso de extracción.
La pila combina la infraestructura anti-bot scraping de Bright Data, el backend seguro de Supabase y las herramientas de desarrollo rápido de Lovable en un flujo de trabajo sin fisuras.
Qué construirás
Este es el canal de datos completo que construirás, desde la entrada del usuario hasta la salida JSON estructurada y el almacenamiento:
User Input
↓
Authentication
↓
Database Logging
↓
Edge Function
↓
Bright Data Web Unlocker (Bypasses anti-bot protection)
↓
Raw HTML
↓
Turndown (HTML → Markdown)
↓
Clean structured text
↓
Google Gemini AI (Natural language processing)
↓
Structured JSON
↓
Database Storage
↓
Frontend Display
↓
User ExportHe aquí un rápido vistazo al aspecto de la aplicación terminada:
Autenticación de usuarios: Los usuarios pueden registrarse o iniciar sesión de forma segura mediante la pantalla de autenticación de Supabase.

Interfaz de extracción de datos: Tras iniciar sesión, los usuarios pueden introducir la URL de una página web y una pregunta en lenguaje natural para recuperar datos estructurados.
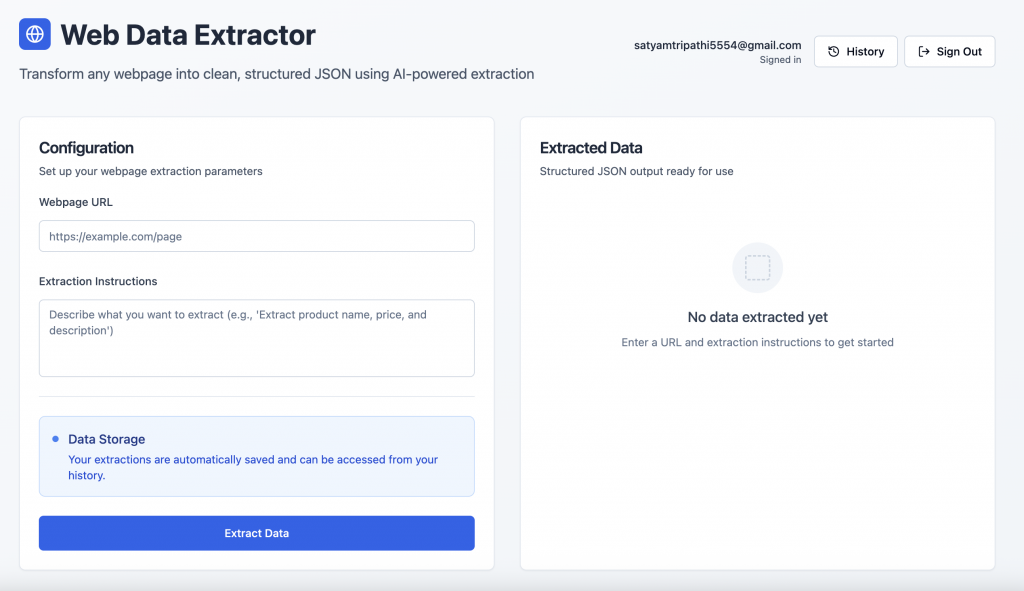
Resumen de la pila tecnológica
He aquí un desglose de nuestra pila y la ventaja estratégica que aporta cada componente.
- Bright Data: El scraping web a menudo se topa con bloqueos, CAPTCHAs y detección avanzada de bots. Bright Data se ha diseñado específicamente para afrontar estos retos. Ofrece:
- Rotación automática de proxy
- Resolución de CAPTCHA y protección contra bots
- Infraestructura global para un acceso coherente
- Procesamiento de JavaScript para contenidos dinámicos
- Gestión automatizada de límites de velocidad
Para esta guía, utilizaremos Web Unlocker de Bright Data, una herramienta diseñada específicamente para obtener de forma fiable el HTML completo incluso de las páginas más protegidas.
- Supabase:Supabase proporciona una base de backend segura para aplicaciones modernas:
- Autenticación y gestión de sesiones integradas
- Una base de datos PostgreSQL con soporte en tiempo real
- Edge Functions para lógica sin servidor
- Almacenamiento seguro de claves y control de acceso
- Lovable: Lovable agiliza el desarrollo con herramientas basadas en IA e integración nativa con Supabase. Ofrece:
- Generación de código basada en IA
- Andamiaje front-end/backend sin fisuras
- React + Tailwind UI fuera de la caja
- Creación rápida de prototipos para aplicaciones listas para producción
- Google Gemini AI:Gemini convierte HTML sin formato en JSON estructurado mediante instrucciones en lenguaje natural. Es compatible con:
- Comprensión y análisis precisos de los contenidos
- Soporte de entrada de gran tamaño para el contexto de página completa
- Extracción de datos escalable y rentable
Requisitos previos y configuración
Antes de empezar el desarrollo, asegúrate de que tienes acceso a lo siguiente:
- Cuenta de Bright Data
- Regístrese en brightdata.com
- Crear una zona Web Unlocker
- Obtenga su clave API en la configuración de la cuenta
- Cuenta de Google AI Studio
- Visita Google AI Studio
- Crear una nueva clave API
- Proyecto Supabase
- Inscríbete en supabase.com
- Crear una nuevaorganización y, a continuación, un nuevo proyecto
- En el panel de control del proyecto, vaya a Funciones Edge → Secretos → Añadir nuevo secreto. Añada secretos como
BRIGHT_DATA_API_KEYyGEMINI_API_KEYcon sus respectivos valores.
- Cuenta adorable
- Registrarse en lovable.dev
- Ve a tu perfil → Configuración → Integraciones.
- En Supabase, haga clic en Conectar Supabase
- Autorice el acceso a la API y vincúlelo a la organización Supabase que acaba de crear
Construir la aplicación paso a paso con Lovable prompts
A continuación se muestra un flujo estructurado y basado en instrucciones para desarrollar su aplicación de extracción de datos web, desde el frontend hasta el backend, la base de datos y el análisis sintáctico inteligente.
Paso nº 1: configuración del frontend
Empiece por diseñar una interfaz de usuario limpia e intuitiva.
Build a modern web data extraction app using React and Tailwind CSS. The UI should include:
- A gradient background with card-style layout
- An input field for the webpage URL
- A textarea for the extraction prompt (e.g., "Extract product title, price, and ratings")
- A display area to render structured JSON output
- Responsive styling with hover effects and proper spacingPaso 2: conectar Supabase y añadir autenticación
Para vincular su proyecto Supabase:
- Haz clic en el icono Supabase de la esquina superior derecha de Lovable
- Seleccione Conectar Supabase
- Elija la organización y el proyecto que creó anteriormente
Lovable integrará su proyecto Supabase automáticamente. Una vez vinculado, utilice el siguiente mensaje para habilitar la autenticación:
Set up complete Supabase authentication:
- Sign up and login forms using email/password
- Session management and auto-persistence
- Route protection for unauthenticated users
- Sign out functionality
- Create user profile on signup
- Handle all auth-related errorsLovable generará el esquema SQL y los desencadenadores necesarios: revíselos y apruébelos para finalizar su flujo de autenticación.
Paso nº 3: definir el esquema de la base de datos Supabase
Configure las tablas necesarias para registrar y almacenar la actividad de extracción:
Create Supabase tables for storing extractions and results:
- extractions: stores URL, prompt, user_id, status, processing_time, error_message
- extraction_results: stores parsed JSON output
Apply RLS policies to ensure each user can only access their own dataPaso nº 4 – crear la función Supabase Edge
Esta función se encarga de la lógica central de raspado, conversión y extracción:
Create an Edge Function called 'extract-web-data' that:
- Fetches the target page using Bright Data's Web Unlocker
- Converts raw HTML to Markdown using Turndown
- Sends the Markdown and prompt to Google Gemini AI (gemini-2.0-flash-001)
- Returns clean structured JSON
- Handles CORS, errors, and response formatting
- Requires GEMINI_API_KEY and BRIGHT_DATA_API_KEY as Edge Function secrets
Below is a reference implementation that handles HTML fetching using Bright Data, markdown conversion with Turndown, and AI-driven extraction with Gemini:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// Constants
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('Failed to initialize WebContentExtractor:', error);
throw error;
}
}
/**
* Fetches webpage content using Bright Data Web Unlocker service
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// Append Web Unlocker parameters to the target URL
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`Web Unlocker request failed with status: ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('Failed to fetch webpage content:', error);
return null;
}
}
/**
* Converts HTML to clean Markdown format for better AI processing
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('Failed to convert HTML to Markdown:', error);
return null;
}
}
/**
* Uses Gemini AI to extract specific information from markdown content
* Uses low temperature for more consistent, factual responses
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('Failed to extract information with AI:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `You are a data extraction assistant. Below is some content in markdown format extracted from a webpage.
Please analyze this content and extract the information requested by the user.
USER REQUEST: ${userQuery}
MARKDOWN CONTENT:
${markdownContent}
Please provide a clear, structured response based on the user's request. If the requested information is not available in the content, please indicate that clearly.`;
}
/**
* Main extraction workflow: fetches webpage → converts to markdown → extracts with AI
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('Could not retrieve HTML content from URL');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('Could not convert HTML to Markdown');
return null;
}
const extractedInformation: string | null = await this.extractInformationWithAI(markdownContent, extractionQuery);
return extractedInformation;
} catch (error) {
console.error('Error in extractDataFromUrl:', error);
return null;
}
}
}
/**
* Example usage of the WebContentExtractor
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('Failed to extract data from the specified URL');
}
} catch (error) {
console.error(`Application error: ${error}`);
}
}
// Execute the application
runExtraction().catch(console.error);Convertir HTML en bruto a Markdown antes de enviarlo a Gemini AI tiene varias ventajas clave. Elimina el ruido HTML innecesario, mejora el rendimiento de la IA al proporcionar una entrada más limpia y estructurada, y reduce el uso de tokens, lo que permite un procesamiento más rápido y rentable.
Consideración importante: Lovable es genial para construir apps a partir de lenguaje natural, pero puede que no siempre sepa cómo integrar correctamente herramientas externas como Bright Data o Gemini. Para garantizar una implementación precisa, incluya un ejemplo de código de trabajo en sus instrucciones. Por ejemplo, el método fetchContentViaBrightData The del aviso anterior demuestra un caso de uso sencillo para Web Unlocker de Bright Data.
Bright Data ofrece varias API, como Web Unlocker, SERP API y Scraper API, cada una con su punto final, método de autenticación y parámetros. Al configurar un producto o una zona en el panel de Bright Data, la pestaña Descripción general proporciona fragmentos de código específicos del lenguaje (Node.js, Python, cURL) adaptados a su configuración. Utilice estos fragmentos tal cual o adáptelos para que se ajusten a la lógica de su función Edge.
Paso nº 5 – conectar el frontend a Edge Function
Una vez que su función Edge esté lista, intégrela en su aplicación React:
Connect the frontend to the Edge Function:
- On form submission, call the Edge Function
- Log the request in the database
- Update status (processing/completed/failed) after the response
- Show processing time, status icons, and toast notifications
- Display the extracted JSON with loading statesPaso nº 6: añadir historial de extracción
Proporcionar a los usuarios una forma de revisar las solicitudes anteriores:
Create a history view that:
- Lists all extractions for the logged-in user
- Displays URL, prompt, status, duration, and date
- Includes View and Delete options
- Expands rows to show extracted results
- Uses icons for statuses (completed,failed,processing)
- Handles long text/URLs gracefully with a responsive layoutPaso 7 – Pulido de la interfaz de usuario y mejoras finales
Perfeccione la experiencia con útiles toques de interfaz de usuario:
Polish the interface:
- Add toggle between "New Extraction" and "History"
- Create a JsonDisplay component with syntax highlighting and copy button
- Fix responsiveness issues for long prompts and URLs
- Add loading spinners, empty states, and fallback messages
- Include feature cards or tips at the bottom of the pageConclusión
Esta integración reúne lo mejor de la automatización web moderna: flujos de usuario seguros con Supabase, scraping fiable a través de Bright Data y análisis sintáctico flexible y potenciado por IA con Gemini, todo ello mediante el constructor intuitivo basado en chat de Lovable para un flujo de trabajo sin código y de alta productividad.
¿Preparado para crear el suyo propio? Empiece en brightdata.com y explore las soluciones de recopilación de datos de Bright Data para un acceso escalable a cualquier sitio, sin quebraderos de cabeza de infraestructura.





