

En este tutorial, aprenderemos a extraer datos de Amazon utilizando Bright Data y un proyecto de extracción listo para su producción.
Trataremos los siguientes temas:
- Cómo utilizar la API Amazon Scraper
- Cómo configurar un proyecto y configurar los objetivos de rastreo de Amazon
- Obtención y renderización de páginas de Amazon
- Cómo extraer datos de productos de las páginas de búsqueda y de productos
- Rastrear Amazon utilizando Web MCP de Bright Data con Claude Desktop
¿Por qué extraer datos de Amazon?
Amazon es el mercado de productos más grande del mundo y una de las fuentes más ricas de datos comerciales en tiempo real en Internet. Desde las tendencias de precios hasta la opinión de los clientes, la plataforma refleja el comportamiento del mercado a una escala que pocos otros sitios web pueden igualar.
El scraping de Amazon permite a los equipos ir más allá de la investigación manual y de los Conjuntos de datos estáticos, lo que permite una toma de decisiones automatizada y basada en datos a gran escala.
Casos de uso comunes del scraping de Amazon
Algunas de las razones más comunes por las que las empresas y los desarrolladores extraen datos de Amazon son:
- Monitoreo de precios e inteligencia competitiva: realice un seguimiento de los precios de los productos, los descuentos y la disponibilidad de existencias en todas las categorías y vendedores casi en tiempo real.
- Investigación de mercados y productos: analizar listados de productos, categorías y clasificaciones de los más vendidos para identificar tendencias de demanda y nuevas oportunidades.
- Análisis de opiniones y sentimientos: recopilar opiniones y valoraciones de los clientes para comprender los sentimientos de los compradores, el rendimiento de los productos y las carencias en las características.
- Aplicaciones basadas en IA: introducir datos de Amazon en tiempo real en LLM y agentes de IA para tareas como asistentes de compras, modelos de precios dinámicos y análisis de mercado automatizados.
Ahora que los casos de uso están claros, podemos pasar a la práctica y ver cómo se puede extraer información de Amazon con Bright Data.
Rastrear Amazon con la API Amazon Scraper de Bright Data
Además de crear scrapers personalizados o utilizar MCP con Claude, Bright Data también ofrece una API de Amazon Scraper gestionada. Necesitará su clave API para la autenticación.
Elegir un scraper de Amazon
Comience abriendo la biblioteca de scrapers de Bright Data.
De la lista de scrapers disponibles, seleccione el scraper de Amazon que se ajuste a su caso de uso, como por ejemplo:
- Detalles del producto por ASIN
- Resultados de búsqueda
- Reseñas
Cada scraper está diseñado para un tipo específico de datos de Amazon.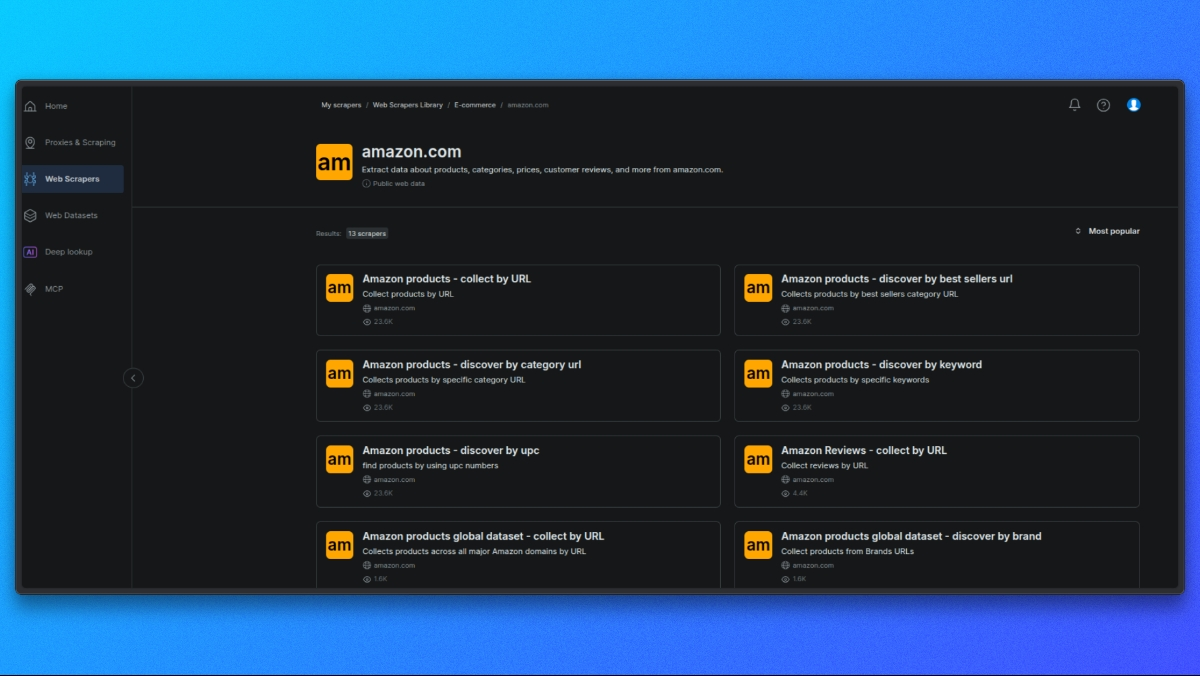
Seleccione el punto final del Scraper
Cada rascador ofrece diferentes puntos finales en función de los datos que desee (por ejemplo, detalles del producto, resultados de búsqueda, reseñas).
Haga clic en el punto final que se ajuste a su caso de uso.
Cree su solicitud
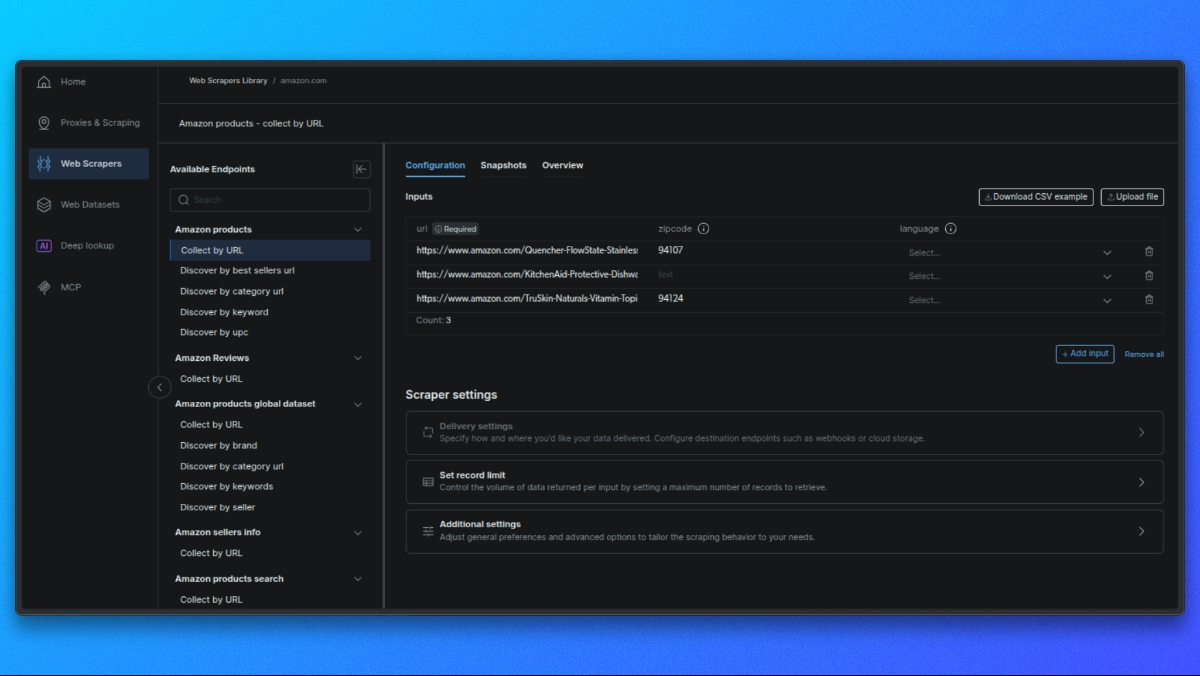
En el panel central, verá un formulario para configurar su solicitud:
- Entrada única: pegue la URL del producto, el ASIN o la palabra clave.
- CSV masivo: suba un archivo CSV con varias entradas para el procesamiento por lotes.
Configuración opcional: - Esquema de salida: seleccione solo los campos que necesite.
- Almacenamiento externo: configura S3, GCS o Azure para la entrega directa.
- URL de webhook: configure un webhook para recibir los resultados automáticamente.
Realizar la solicitud API
A continuación se muestra un ejemplo básico que utiliza curl para una página de producto:
curl -i --silent --compressed "https://api.brightdata.com/dca/trigger?customer=hl_ee3f47e5&zone=YOUR_ZONE_NAME"
-H "Content-Type: application/json"
-H "Authorization: Bearer YOUR_API_KEY"
-d '{
"input": {
"url": "https://www.amazon.com/dp/B08L5TNJHG"
}
}'Reemplaza YOUR_ZONE_NAME y YOUR_API_KEY con tu zona y clave API reales.
### Recupera tus resultados
- Para trabajos en tiempo real (hasta 20 URL), obtendrá los resultados directamente.
- Para trabajos por lotes, recibirá un ID de trabajo para consultar los resultados u obtenerlos a través de webhook/almacenamiento externo.
Ahora, veamos cómo crear un rastreador personalizado con los proxies residenciales de Bright Data.
Configuración del proyecto
Puede seguir este tutorial utilizando el código del proyecto disponible en el repositorio.
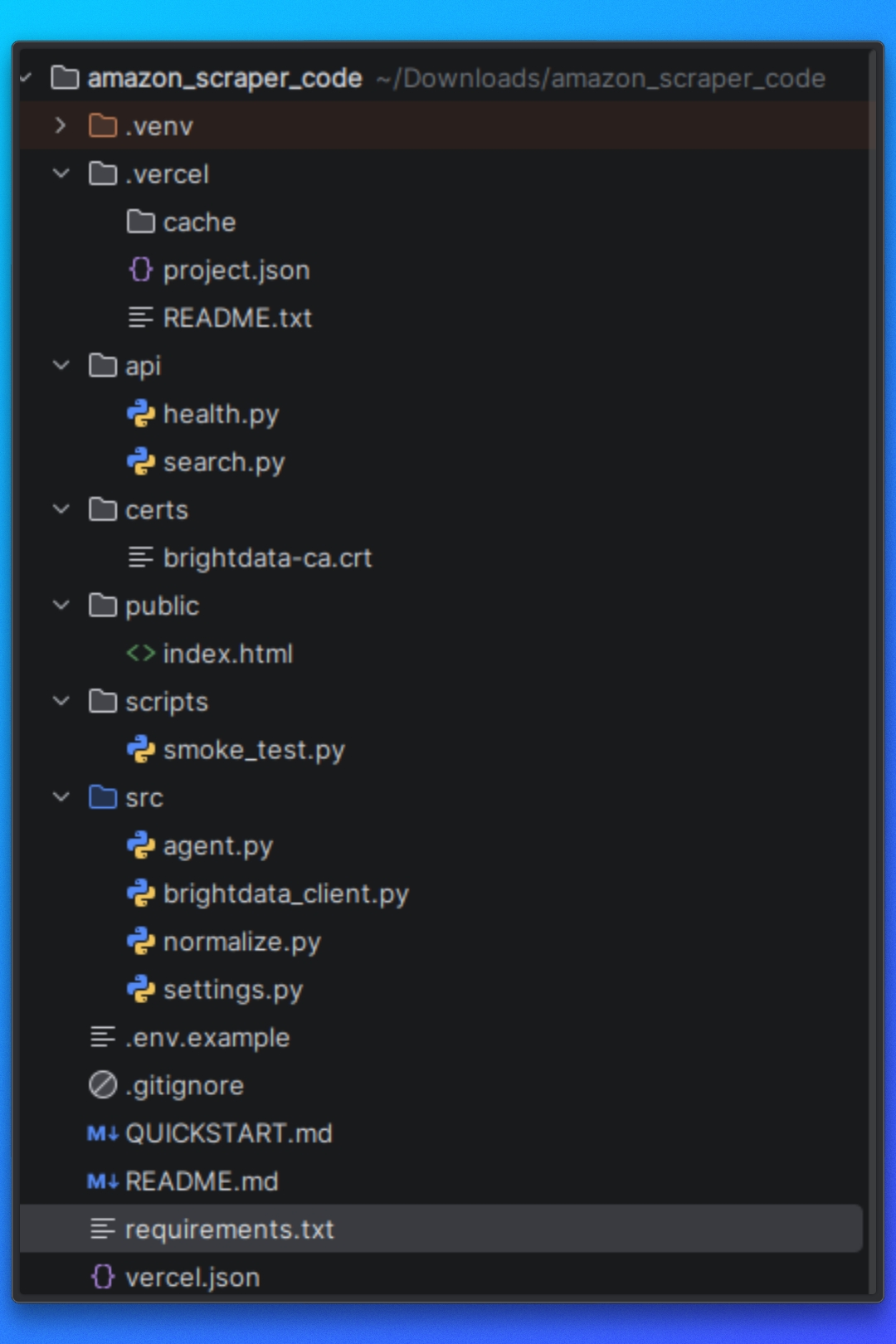
Antes de empezar, asegúrate de que tienes los siguientes requisitos previos instalados en tu sistema.
Requisitos
Este proyecto requiere:
- Python 3.10+
- pip para la gestión de dependencias
- Node.js 18+ (requerido por Vercel)
- Vercel CLI
Además, necesitarás:
- Una cuenta de Bright Data
- Acceso al MCP web de Bright Data
- Claude Desktop
Instalación de dependencias
Instala las dependencias de Python necesarias utilizando el archivo requirements.txt proporcionado:
pip install -r requirements.txtEsto instala todas las bibliotecas utilizadas para la obtención de páginas, la automatización del navegador, el Parseo de HTML y la extracción de datos.
Certificado CA de Bright Data
Este proyecto utiliza un certificado CA de Bright Data para la verificación TLS al enrutar solicitudes a través del Proxy.
Asegúrese de que el archivo de certificado se encuentra en la siguiente ruta:
certs/brightdata-ca.crtEste archivo se pasa al cliente HTTP durante las solicitudes. Si falta o se referencia incorrectamente, las solicitudes de Amazon fallarán debido a errores de verificación TLS.
Configuración de Vercel
Este proyecto está diseñado para ejecutarse como una función sin servidor de Vercel.
El archivo api/search.py sirve como punto de entrada de la API y es ejecutado por Vercel en respuesta a las solicitudes HTTP entrantes.
Asegúrese de que la CLI de Vercel está instalada y autenticada:
vercel login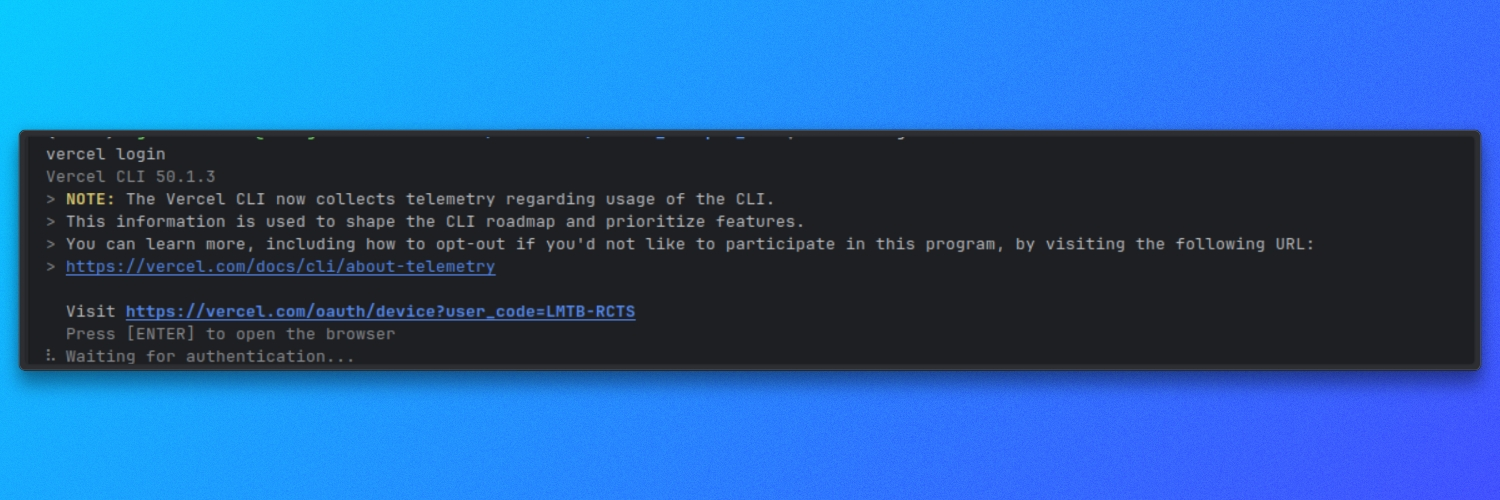
Variables de entorno
El proyecto utiliza una configuración basada en el entorno para los ajustes de tiempo de ejecución.
Cree un archivo .env en la raíz del proyecto y defina las variables necesarias tal y como se especifica en el repositorio. Estos valores controlan cómo el Scraper obtiene, renderiza y procesa las páginas de Amazon.
Una vez instaladas las dependencias y configuradas las variables de entorno, el proyecto está listo para su uso.
Comprensión de la estructura del proyecto
Antes de ejecutar el Scraper, debemos comprender cómo está organizado el proyecto y cómo fluye el proceso de rastreo de principio a fin.
El proyecto está estructurado en torno a una clara separación de responsabilidades.
Configuración
Esta parte del proyecto define los objetivos de Amazon, las opciones de tiempo de ejecución y el comportamiento del scraper. Estos ajustes controlan lo que se extrae y cómo funciona el scraper.
Obtención y renderización de páginas
Esta parte del proyecto se encarga de cargar las páginas de Amazon y devolver HTML utilizable. Se ocupa de la navegación, la carga de páginas y la ejecución de JavaScript para que la lógica posterior funcione con contenido totalmente renderizado.
Lógica de extracción
Una vez que el HTML está disponible, la capa de extracción analiza la página y extrae los datos estructurados. Esto incluye la lógica tanto para las páginas de resultados de búsqueda de Amazon como para las páginas de productos individuales.
Flujo de ejecución
El flujo de ejecución coordina la obtención, la representación, la extracción y la salida. Garantiza que cada paso se ejecute en el orden correcto.
Gestión de la salida
Los datos extraídos se escriben en el disco en un formato estructurado, lo que facilita su inspección o consumo en otros flujos de trabajo.
Esta estructura mantiene el rascador modular y facilita la reutilización de componentes individuales, especialmente cuando se integran métodos de obtención externos como Web MCP de Bright Data más adelante en el tutorial.
Con esta descripción general, podemos pasar a configurar los objetivos de Amazon y definir qué datos debe recopilar el rascador.
Configuración de los objetivos de Amazon
En esta sección, configuraremos dos cosas:
- La palabra clave de búsqueda de Amazon que queremos extraer
- Las credenciales de Bright Data que necesitamos para recuperar correctamente las páginas de Amazon
1. Pasar la palabra clave de búsqueda de Amazon
Enviamos nuestra palabra clave de Amazon utilizando un parámetro de consulta llamado q.
Esto se gestiona en api/search.py. La API lee q de la URL de la solicitud y se detiene inmediatamente si falta:
# api/search.py
query = query_params.get("q", [None])[0]
if not query:
self._send_json_response(400, {"error": "Missing required parameter: q"})
returnQué significa esto:
Debemos llamar al punto final con ?q=...
Si olvidamos q, obtenemos una respuesta 400 y el scraper no se ejecuta
Establecer cuántos productos queremos
También podemos controlar cuántos productos devolvemos utilizando el parámetro opcional limit.
Todavía en api/search.py, analizamos limit, lo convertimos en un entero y lo limitamos a un rango seguro:
# api/search.py
limit_str = query_params.get("limit", [None])[0]
limit = DEFAULT_SEARCH_LIMIT
if limit_str:
try:
limit = int(limit_str)
limit = min(limit, MAX_SEARCH_LIMIT)
limit = max(1, limit)
except ValueError:
limit = DEFAULT_SEARCH_LIMITPor lo tanto:
Si no pasamos el límite, utilizamos el valor predeterminado.
Si pasamos algo no válido, recurrimos al valor predeterminado.
Si pasamos un valor superior al permitido, se limita.
Los valores predeterminados y máximos se definen en src/settings.py:
# src/settings.py
DEFAULT_SEARCH_LIMIT = 10
MAX_SEARCH_LIMIT = 50Si alguna vez queremos cambiar el comportamiento predeterminado, aquí es donde lo hacemos.
2. Asignación de nuestra consulta al punto final de búsqueda de Amazon
Una vez que tenemos q, obtenemos los resultados de búsqueda de Amazon a través de Bright Data utilizando fetch_products(query, limit):
# api/search.py
raw_response = fetch_products(query, limit)El punto final de Amazon que se está rastreando se define en src/brightdata_client.py:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"Y cuando obtenemos los resultados, pasamos nuestra palabra clave a Amazon utilizando el parámetro k:
# src/brightdata_client.py
r = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,
)Esto significa que:
- Nuestro parámetro API es
q - El parámetro de búsqueda de Amazon es
k - Si proporcionamos q=auriculares inalámbricos, la solicitud se envía a Amazon como
https://www.amazon.com/s?k=wireless+auriculares
3. Configuración de las credenciales de Bright Data
Para enviar solicitudes a través de Bright Data, necesitamos credenciales de Proxy disponibles como variables de entorno.
En src/settings.py, cargamos la configuración de Bright Data de la siguiente manera:
# src/settings.py
BRIGHTDATA_USERNAME = os.getenv('BRIGHTDATA_USERNAME', '')
BRIGHTDATA_PASSWORD = os.getenv('BRIGHTDATA_PASSWORD', '')
BRIGHTDATA_PROXY_HOST = os.getenv('BRIGHTDATA_PROXY_HOST', 'brd.superproxy.io')
BRIGHTDATA_PROXY_PORT = os.getenv('BRIGHTDATA_PROXY_PORT', 'your_port)En tu archivo .env, añade las siguientes credenciales:
BRIGHTDATA_USERNAME=tu_nombre_de_usuario_brightdata
BRIGHTDATA_PASSWORD=tu_contraseña_brightdata
BRIGHTDATA_PROXY_HOST=brd.superproxy.io
BRIGHTDATA_PROXY_PORT=tu_puertoCuando ejecutamos el scraper, estos valores se utilizan para crear la URL del Proxy de Bright Data dentro de src/brightdata_client.py:
# src/brightdata_client.py
proxy_url = (
f"http://{BRIGHTDATA_USERNAME}:{BRIGHTDATA_PASSWORD}"
f"@{BRIGHTDATA_PROXY_HOST}:{BRIGHTDATA_PROXY_PORT}")
proxies = {"http": proxy_url, "https": proxy_url}Si no configuramos BRIGHTDATA_USERNAME o BRIGHTDATA_PASSWORD, el rastreador falla rápidamente con un error claro:
# src/brightdata_client.py
if not BRIGHTDATA_USERNAME or not BRIGHTDATA_PASSWORD:
raise ValueError(
"Bright Data Proxy credentials not configured. "
"Set BRIGHTDATA_USERNAME and BRIGHTDATA_PASSWORD."
)Con nuestra palabra clave y las credenciales de Bright Data configuradas, estamos listos para recuperar las páginas de Amazon.
Recuperación de páginas de Amazon
En esta etapa, ya hemos validado la entrada y configurado Bright Data. Ahora nos centramos en dónde se ejecuta la solicitud de Amazon y qué supuestos mínimos hace.
Todas las solicitudes de Amazon se envían desde src/brightdata_client.py.
Punto final de búsqueda de Amazon
Definimos el punto final de búsqueda de Amazon una vez y lo reutilizamos para todas las solicitudes de búsqueda:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"Encabezados de solicitud
Enviamos encabezados genéricos, similares a los de un navegador, para garantizar que Amazon devuelva el diseño HTML estándar para ordenadores de sobremesa. Estos encabezados no están vinculados al sistema operativo del usuario.
# src/brightdata_client.py
headers = {
"User-Agent": (
"Mozilla/5.0 "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
}Envío de la solicitud
Con el punto final, los encabezados y la configuración del Proxy ya establecidos, ejecutamos la solicitud de Amazon:
# src/brightdata_client.py
response = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,)
response.raise_for_status()
html = response.text or ""Al final de esta llamada, html contiene el contenido sin procesar de la página de búsqueda de Amazon.
Una vez completada la fase de obtención, podemos pasar al parseo del HTML y extraer los enlaces de los productos y los metadatos de la página de resultados de búsqueda de Amazon.
Extracción de resultados de búsqueda
Una vez recuperada la página de búsqueda de Amazon, el siguiente paso es extraer los listados de productos del HTML devuelto. Todo este paso se realiza dentro de src/brightdata_client.py.
Una vez completada la solicitud, pasamos el HTML sin procesar al analizador interno:
products = _parse_amazon_search_html(html, limit=limit)
return {"products": products}Toda la lógica de extracción de resultados de búsqueda se encuentra dentro de _parse_amazon_search_html.
Parseo el HTML
Comenzamos mediante el parseo del HTML sin procesar en un árbol DOM utilizando BeautifulSoup. Esto nos permite consultar la estructura de la página de forma fiable.
soup = BeautifulSoup(html, "lxml")También normalizamos el límite solicitado para garantizar que siempre extraemos al menos un elemento:
max_items = max(1, int(limit)) if isinstance(limit, int) else 10Localización de contenedores de resultados de búsqueda
Las páginas de búsqueda de Amazon incluyen muchos elementos que no son listados de productos. Para aislar los resultados reales, primero nos centramos en el contenedor de resultados de búsqueda principal de Amazon:
containers = soup.select('div[data-component-type="s-search-result"]')Como alternativa, también buscamos elementos que contengan un atributo data-asin válido:
fallback = soup.select('div[data-asin]:not([data-asin=""])')Si el selector principal no devuelve ningún resultado, pero el alternativo sí, cambiamos al alternativo:
if not containers and fallback:
containers = fallbackEsto nos proporciona resistencia frente a variaciones menores en el diseño, al tiempo que mantenemos la extracción limitada a las entradas de productos reales.
Iteración a través de los resultados
Iteramos a través de los contenedores seleccionados y nos detenemos una vez que alcanzamos el límite solicitado:
productos = []
para c en contenedores:
si len(productos) >= max_items:
breakPara cada contenedor, extraemos los campos principales. Si una ficha de producto no contiene tanto un título como una URL, la omitimos.
title = _extract_title(c)
url = _extract_url(c)
if not title or not url:
continueExtracción de campos de productos
Cada ficha de producto se analiza utilizando pequeñas funciones auxiliares, todas ellas definidas en el mismo archivo.
imagen = _extract_image(c)
calificación = _extract_rating(c)
reseñas = _extract_reviews_count(c)
precio = _extract_price(c)A continuación, ensamblamos un objeto de producto estructurado:
products.append(
{
"title": title,
"price": price,
"rating": rating,
"reviews": reviews,
"url": url,
"image": image,
}
)Ayudantes para la extracción de campos
Cada asistente se centra en un campo y gestiona de forma segura las marcas que faltan o son parciales.
Extracción del título
def _extract_title(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
if a:
t = a.get_text(" ", strip=True)
if t:
return t
img = container.select_one("img.s-image")
alt = img.get("alt") if img else ""
return alt.strip() if isinstance(alt, str) else ""URL del producto
def _extract_url(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
href = a.get("href") if a else ""
if isinstance(href, str) and href:
return "https://www.amazon.com" + href if href.startswith("/") else href
return ""Imagen
def _extract_image(container) -> Optional[str]:
img = container.select_one("img.s-image")
src = img.get("src") if img else None
return src if isinstance(src, str) and src else NoneCalificación
def _extract_rating(container) -> Optional[float]:
el = container.select_one("span.a-icon-alt")
text = el.get_text(" ", strip=True) if el else ""
if not text:
el = container.select_one('span:contains("out of 5 stars")')
text = el.get_text(" ", strip=True) if el else ""
if not text:
return None
m = re.search(r"(d+(?:.d+)?)", text)
return float(m.group(1)) if m else NoneRecuento de reseñas
def _extract_reviews_count(container) -> Optional[int]:
el = container.select_one("span.s-underline-text")
text = el.get_text(" ", strip=True) if el else ""
m = re.search(r"(d[d,]*)", text)
return int(m.group(1).replace(",", "")) if m else NonePrecio
def _extract_price(container) -> str:
whole = container.select_one("span.a-price-whole")
frac = container.select_one("span.a-price-fraction")
whole_text = whole.get_text(strip=True).replace(",", "") if whole else ""
frac_text = frac.get_text(strip=True) if frac else ""
if not whole_text:
return ""
return f"${whole_text}.{frac_text}" if frac_text else f"${whole_text}"Al final de este paso, tenemos una lista de entradas de productos estructuradas extraídas directamente de los resultados de búsqueda de Amazon.
Cada elemento incluye:
- título
- precio
- calificación
- reseñas
- URL del producto
- URL de la imagen
Una vez completada la extracción de los resultados de búsqueda, pasamos a normalizar y devolver la respuesta, lo cual se gestiona en src/normalize.py.
Normalización de la respuesta
En este punto, nuestra extracción de búsqueda devuelve objetos de producto, pero los campos aún no están estandarizados. Por ejemplo, el precio sigue siendo una cadena (como «129,99 $»), el recuento de reseñas puede incluir comas y algunos campos pueden faltar dependiendo de la tarjeta.
Para que la respuesta de la API sea coherente, normalizamos todo dentro de src/normalize.py.
En api/search.py, la normalización se produce justo después de obtener los resultados sin procesar:
# api/search.py
normalized = normalize_response(raw_response, query)Esa única llamada convierte la salida sin procesar de Bright Data en una respuesta limpia que siempre tiene el siguiente aspecto:
items: una lista de objetos de productos normalizadoscount: cuántos elementos hemos devuelto
Normalización de una respuesta dict
normalize_response admite múltiples tipos de entrada. En nuestro flujo de API, pasamos un dict como {"products": [...]} desde fetch_products(...).
Aquí está la rama dict:
# src/normalize.py
if isinstance(raw_response, dict):
products = raw_response.get("products", []) or raw_response.get("items", [])
normalized_items = [normalize_product(p) for p in products if isinstance(p, dict)]
return {"items": normalized_items[:limit], "count": len(normalized_items[:limit])}Qué hace:
- Lee los productos de products (o items, si están presentes).
- Normaliza cada producto utilizando normalizar_producto
- Devuelve una carga útil consistente
{"items": [...], "count": N}
Normalización de un solo producto
Cada producto se normaliza mediante normalize_product(...).
El precio se analiza en un valor numérico y un código de moneda utilizando parse_price(...):
# src/normalize.py
price_str = raw_product.get("price", "")
price, currency = parse_price(price_str)La valoración se convierte en un valor flotante si es posible:
# src/normalize.py
rating = raw_product.get("rating")
if rating is not None:
try:
rating = float(rating)
except (ValueError, TypeError):
rating = None
else:
rating = NoneEl recuento de reseñas se normaliza en un entero, admitiendo tanto las claves reviews como reviews_count:
# src/normalize.py
reviews_count = raw_product.get("reviews") or raw_product.get("reviews_count")
if reviews_count is not None:
try:
reviews_count = int(str(reviews_count).replace(",", ""))
except (ValueError, TypeError):
reviews_count = None
else:
reviews_count = NonePor último, devolvemos un objeto de producto estandarizado:
# src/normalize.py
return {
"title": raw_product.get("title", ""),
"price": price,
"currency": currency,
"rating": rating,
"reviews_count": reviews_count,
"url": raw_product.get("url", ""),
"image": raw_product.get("image"),
"source": "brightdata",
}Una vez completada la normalización, ahora tenemos una lista de artículos coherente que se puede devolver de forma segura desde la API y que es fácil de consumir para los clientes.
Ejecución del Scraper en Vercel
Este scraper se ejecuta como una función sin servidor de Vercel. Localmente, lo ejecutamos utilizando el servidor de desarrollo de Vercel para que las rutas api/ se comporten de la misma manera que lo harían en producción.
Ejecutar localmente con Vercel
Desde la raíz del repositorio, inicia el servidor de desarrollo:
vercel dev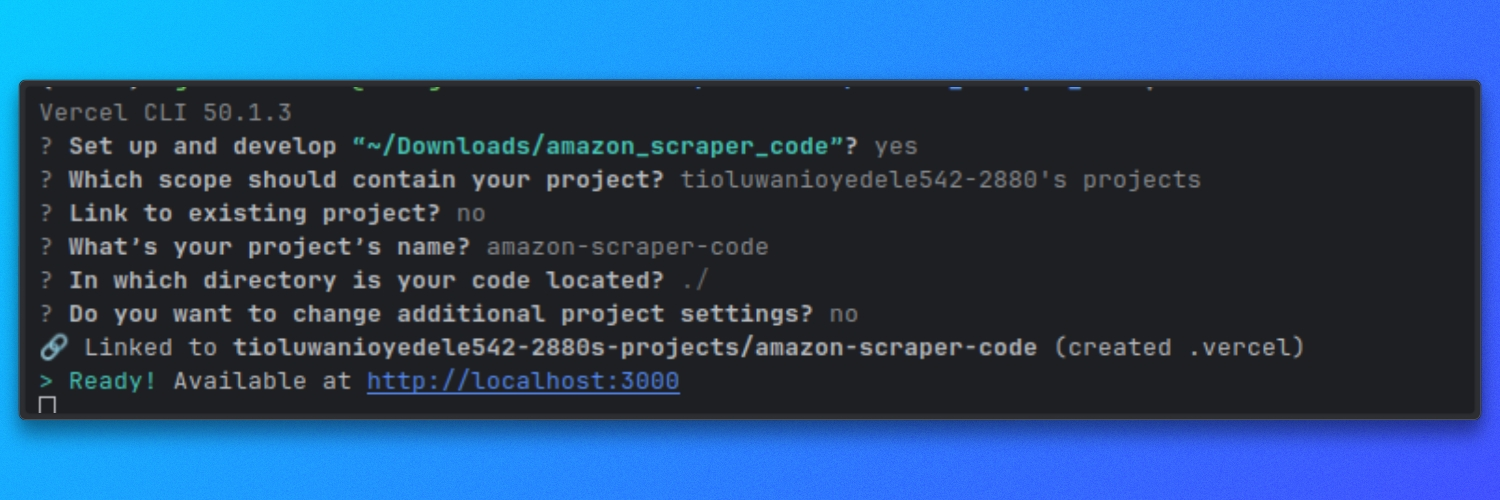
De forma predeterminada, esto inicia el servidor en:
http://localhost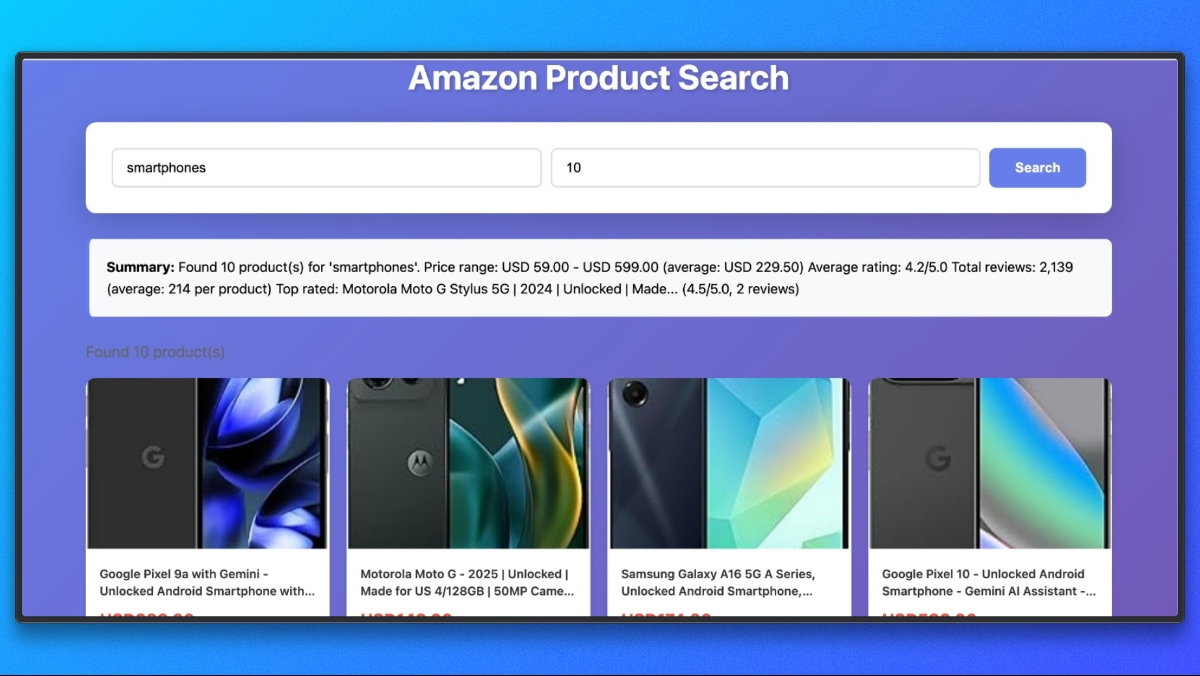
Ahora ya tenemos nuestro proyecto de scraping completo. Puede ejecutarlo y probar a extraer datos de diferentes productos de Amazon.
Además, también puede extraer datos utilizando Bright `Data MCP con un agente de IA. Veamos brevemente cómo se hace.
Conectar Claude Desktop al Web MCP de Bright Data
Claude Desktop debe configurarse para iniciar el servidor Web MCP de Bright Data.
Abre el archivo de configuración de Claude Desktop.
Puede navegar a Configuración, hacer clic en el icono Desarrollador y seleccionar Editar configuración. Esto abre el archivo de configuración utilizado por Claude Desktop.

Añada la siguiente configuración y sustituya YOUR_TOKEN_HERE por su token API de Bright Data:
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_TOKEN_HERE"
}
}
}
}Guarde el archivo y reinicie Claude Desktop.
Una vez que Claude se reinicie, el Web MCP de Bright Data estará disponible como herramienta.
Extracción de listados de productos de Amazon con Claude
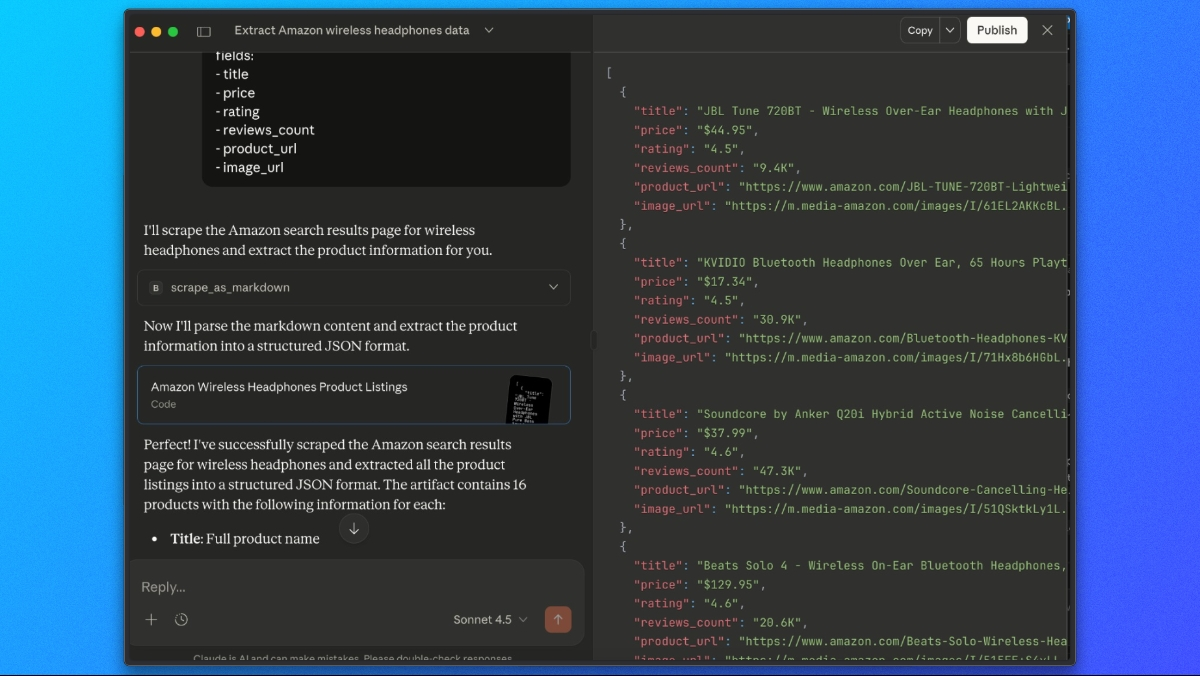
Con el Web MCP de Bright Data conectado, podemos pedirle a Claude que recopile y extraiga los resultados de búsqueda de Amazon en un solo paso.
Utilice un comando como este:
Utiliza la herramienta scrape_as_markdown para ir a:
https://www.amazon.com/s?k=wireless+headphones
A continuación, mira el resultado de markdown y extrae todos los listados de productos en una lista JSON con los siguientes campos:
- título
- precio
- valoración
- número de reseñas
- URL del producto
- URL de la imagenClaude recuperará la página a través del Web MCP de Bright Data, analizará el contenido renderizado y devolverá una respuesta JSON estructurada que contiene los datos extraídos de los productos de Amazon.
Reflexiones finales
En este tutorial, hemos explorado tres formas de extraer datos de Amazon utilizando Bright Data:
- API Amazon Scraper: la forma más rápida de empezar. Utiliza puntos finales predefinidos para obtener detalles de productos, resultados de búsqueda y reseñas sin necesidad de escribir ningún código de scraping.
- Scraper personalizado con proxies de Bright Data: crea un rascador listo para la producción como una función sin servidor de Vercel con control total sobre la obtención, extracción y normalización.
- Claude Desktop con Web MCP: extraiga datos de Amazon de forma interactiva utilizando la extracción basada en IA sin escribir código.
Omita por completo el rastreo
Si necesita datos de Amazon a gran escala y listos para la producción sin tener que crear una infraestructura, considere los Conjuntos de datos de Amazon de Bright Data. Obtenga acceso a:
- Listados de productos, precios y reseñas recopilados previamente
- Datos históricos para el análisis de tendencias
- Conjuntos de datos listos para usar y actualizados periódicamente
- Cobertura en múltiples mercados de Amazon
Tanto si necesita scraping en tiempo real como conjuntos de datos ya preparados, Bright Data le proporciona la infraestructura necesaria para acceder a los datos de Amazon de forma fiable y a gran escala.




