

En este artículo trataremos:
- Desmitificando PhantomJS
- Las ventajas y desventajas de utilizar PhantomJS para la recopilación de datos
- Guía paso a paso para la recopilación de datos con PhantomJS
- Automatización de datos: alternativas más sencillas al rastreo manual
Desmitificando PhantomJS
PhantomJS es un «navegador web sin interfaz». Esto significa que no tiene interfaz gráfica de usuario (GUI), sino que solo se ejecuta mediante scripts (lo que lo hace más ligero, rápido y, por lo tanto, más eficiente). Se puede utilizar para automatizar diferentes tareas mediante JavaScript (JS), como probar código o recopilar datos.
Para los principiantes, recomendaría instalar primero PhantomJS en el ordenador utilizando «npm» en la CLI. Para ello, ejecute el siguiente comando:
npm install phantomjs -g
Ahora el comando «phantomjs» estará disponible para su uso.
Ventajas e inconvenientes de utilizar PhantomJS para el rastreo de datos
PhantomJS tiene muchas ventajas, entre ellas el hecho de ser «sin interfaz gráfica», lo que, como he explicado anteriormente, lo hace más rápido, ya que no es necesario cargar gráficos para probar o recuperar información.
PhantomJS se puede utilizar de manera eficiente para lograr lo siguiente:
Captura de pantalla
PhantomJS puede ayudar a automatizar el proceso de capturar y guardar archivos PNG, JPEG e incluso GIF. Esta función facilita mucho la garantía de la interfaz de usuario y la experiencia de usuario front-end. Por ejemplo, puede ejecutar la línea de comando: Phantomjs amazon.js, para recopilar imágenes de los listados de productos de la competencia o para asegurarse de que los listados de productos de su empresa se muestran correctamente.
Automatización de páginas
Esta es una de las principales ventajas de PhantomJS, ya que ayuda a los desarrolladores a ahorrar mucho tiempo. Al ejecutar líneas de comando como Phantomjs userAgent.js, los desarrolladores pueden escribir y comprobar el código JS en relación con una página web específica. La principal ventaja en cuanto al ahorro de tiempo es que este proceso se puede automatizar y realizar sin tener que abrir un navegador.
Pruebas
PhantomJS es ventajoso a la hora de probar sitios web, ya que agiliza el proceso, al igual que otras herramientas populares de Scraping web, como Selenium. La navegación sin interfaz gráfica de usuario (GUI) permite detectar problemas más rápidamente, ya que los códigos de error se descubren y se envían a nivel de línea de comandos.
Los desarrolladores también integran PhantomJS con diferentes tipos de sistemas de integración continua (CI) para probar el código antes de su puesta en marcha. Esto ayuda a los desarrolladores a corregir el código defectuoso en tiempo real, lo que garantiza proyectos en vivo más fluidos.
Supervisión de redes/Recopilación de datos
PhantomJS también se puede utilizar para supervisar el tráfico y la actividad de la red. Muchos desarrolladores lo programan de manera que ayude a recopilar datos específicos, como por ejemplo:
- El rendimiento de una página web específica
- Cuándo se añaden o eliminan líneas de código
- Datos sobre la fluctuación del precio de las acciones
- Datos sobre influencers/interacción al rastrear sitios como Instagram
Algunas desventajas del uso de PhantomJS son:
- Puede ser utilizado por personas malintencionadas para llevar a cabo ataques automatizados (principalmente «gracias» al hecho de que no utiliza una interfaz de usuario).
- A veces puede resultar complicado cuando se trata de pruebas de ciclo completo/de extremo a extremo y pruebas funcionales.
Guía paso a paso para la recopilación de datos con PhantomJS
PhantomJS es muy popular entre los desarrolladores de NodeJS, por lo que ofrecemos un ejemplo de cómo utilizarlo en el entorno NodeJS. El ejemplo muestra cómo obtener el contenido HTML de la URL.
Paso uno: configurar package.json e instalar paquetes npm
Cree una carpeta de proyecto y un archivo «package.json» en ella.
{
"name": "phantomjs-example",
"version": "1.0.0",
"title": "PhantomJS Example",
"description": "PhantomJS Example",
"keywords": [
"phantom example"
],
"main": "./index.js",
"scripts": {
"inst": "rm -rf node_modules && rm package-lock.json && npm install",
"dev": "nodemon index.js"
},
"dependencies": {
"phantom": "^6.3.0"
}
}
A continuación, ejecute este comando en su terminal: $ npm install. Se instalará Phantom en la carpeta local de su proyecto «node_modules».
Paso dos: crear un script JS Phantom
Crea un script JS y asígnale el nombre «index.js»
const phantom = require('phantom');
const main = async () => {
const instance = await phantom.create();
const page = await instance.createPage();
await page.on('onResourceRequested', function(requestData) {
console.info('Requesting', requestData.url);
});
const url = 'https://example.com/';
console.log('URL::', url);
const status = await page.open(url);
console.log('STATUS::', status);
const content = await page.property('content');
console.log('CONTENT::', content);
await instance.exit();
};
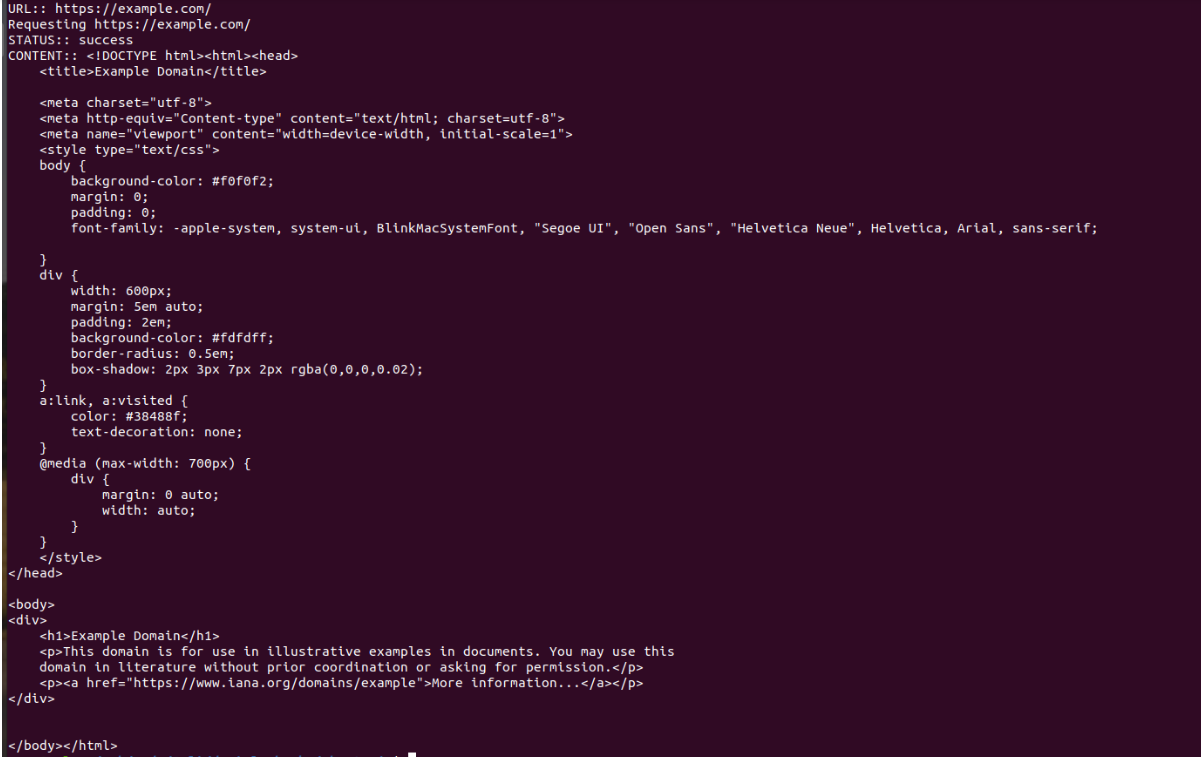
main().catch(console.log);Paso tres: ejecutar el script JS
Para iniciar el script, ejecute en su terminal: $ node index.js. El resultado será contenido HTML.
Automatización de datos: alternativas más sencillas al scraping manual
Cuando se trata de extraer datos a gran escala, algunas empresas pueden preferir utilizar alternativas a PhantomJS.
Entre ellas se incluyen:
- Proxies: el Scrapingweb con proxies puede ser beneficioso, ya que permite a los usuarios recopilar datos a gran escala, enviando un número infinito de solicitudes simultáneas. Los proxies también pueden ayudar a sortear los bloqueos de los sitios web de destino, como las limitaciones de velocidad o los bloqueos basados en la geolocalización. En este caso, las empresas pueden aprovechar los dispositivos y las IPs móviles y residenciales específicos de cada país o ciudad para enrutar las solicitudes de datos, lo que les permite recuperar datos más precisos sobre los usuarios (por ejemplo, precios de la competencia, campañas publicitarias y resultados de búsqueda de Google).
- Conjuntos de datos listos para usar: los conjuntos de datos son esencialmente «paquetes de información» que ya se han recopilado y están listos para ser entregados a algoritmos o equipos para su uso inmediato. Por lo general, incluyen información de un sitio de destino y se enriquecen con información de sitios relevantes de toda la web (por ejemplo, información sobre productos de una categoría relevante entre múltiples proveedores y una variedad de mercados de comercio electrónico). Los conjuntos de datos también se pueden actualizar periódicamente para garantizar que todos los puntos de datos estén actualizados. La principal ventaja aquí es que no se invierte tiempo ni recursos en la recopilación de datos, lo que significa que se puede dedicar más tiempo al análisis de datos y a la creación de valor para los clientes.
- API de Web Scraper totalmente automatizadas: La API de Web Scraper es una solución de recopilación de datos fácil de usar, sin código, sin infraestructura y personalizable. Permite a las empresas recopilar datos web estructurados sin esfuerzo y sin las molestias del desarrollo y mantenimiento de software o hardware.
Hable con uno de los expertos en datos de Bright Data para ver qué productos se adaptan mejor a sus necesidades de Scraping web.






