

Este tutorial cubrirá:
- ¿Por qué raspar Yelp?
- Bibliotecas y herramientas de raspado de Yelp
- Raspado de datos de negocios de Yelp con Beautiful Soup
¿Por qué raspar Yelp?
Hay varias razones para raspar Yelp. Entre ellas
- Obtener acceso a datos empresariales completos: proporciona una gran cantidad de información sobre las empresas locales, incluyendo comentarios, calificaciones, información de contacto, y mucho más.
- Obtener información sobre las opiniones de los clientes: es conocida por las reseñas de sus usuarios, que proporcionan un tesoro de información sobre las opiniones y experiencias de los clientes.
- Realizar análisis de la competencia y evaluaciones comparativas: ofrece información valiosa sobre el rendimiento de sus competidores, sus puntos fuertes y débiles y el sentimiento de los clientes.
Existen plataformas similares, pero Yelp es la preferida para el raspado de datos por su:
- Amplia base de usuarios
- Diversas categorías de negocios
- Reputación consolidada
Los datos extraídos de Yelp pueden ser valiosos para la investigación de mercado, el análisis de la competencia, el análisis de opiniones y la toma de decisiones. Esta información también ayuda a identificar áreas de mejora, ajustar ofertas y mantenerse por delante de la competencia.
Bibliotecas y herramientas de raspado de Yelp
Python está ampliamente considerado como un lenguaje excelente para el raspado web debido a su facilidad de uso, su sintaxis sencilla y su amplia gama de bibliotecas. Por eso es el lenguaje de programación recomendado para el raspado de Yelp. Para obtener más información, consulte nuestra guía detallada sobre cómo hacer raspado web con Python.
El siguiente paso consiste en seleccionar las bibliotecas de raspado adecuadas entre la amplia gama de opciones disponibles. Para tomar una decisión informada, primero debe explorar la plataforma en un navegador web. Al inspeccionar las llamadas AJAX realizadas por las páginas web, descubrirá que la mayoría de los datos están incrustados dentro de los documentos HTML recuperados del servidor.
Esto implica que un simple cliente HTTP para hacer peticiones al servidor combinado con un analizador HTML, será suficiente para la tarea. Por esta razón debe optar por:
- Requests: la librería cliente HTTP más popular para Python. Agiliza el proceso de envío de peticiones HTTP y la gestión de sus correspondientes respuestas.
- Beautiful Soup: una completa biblioteca de análisis de HTML y XML muy utilizada para el raspado web. Proporciona métodos robustos para navegar y extraer datos del DOM.
Gracias a Requests y Beautiful Soup, es posible raspar Yelp con Python. Veamos en detalle cómo llevar a cabo esta tarea.
Raspado de datos de negocios de Yelp con Beautiful Soup
Siga este tutorial paso a paso y aprenda a crear un raspador de Yelp.
Paso 1: Configuración del proyecto Python
Antes de empezar, es necesario asegurarse de que tiene:
- Python 3+ instalado en su ordenador:
Descargue el instalador, ejecútelo y siga las instrucciones. - Un IDE de Python de su elección: Visual Studio Code con la extensión Python o PyCharm Community Edition.
Primero, cree una carpeta yelp-scraper e inicialícelo como un proyecto Python con un entorno virtual con:
mkdir yelp-scrapernncd yelp-scrapernnpython -m venv env
En Windows, ejecute el siguiente comando para activar el entorno:
Your Code Here...
A continuación, añada un archivo scraper.py que contenga la siguiente línea en la carpeta del proyecto:
print('Hello, World!')
Este es el script Python más sencillo. Por ahora, sólo imprime “¡Hola, mundo!” pero pronto contendrá la lógica para raspar Yelp.
Se puede ejecutar el raspador con:
python scraper.py
Debería imprimir en la terminal:
Hello, World!
Exactamente lo que se esperaba. Ahora que sabemos que todo funciona, abra la carpeta del proyecto en su IDE de Python.
¡Genial, prepárese para escribir algo de código Python!
Paso 2: Instalar las librerías de raspado
Ahora es necesario añadir las librerías necesarias para realizar el raspado web a las dependencias del proyecto. En el entorno virtual activado, ejecute el siguiente comando para instalar Beautiful Soup y Requests:
pip install beautifulsoup4 requests
Elimine el archivo scraper.py y luego añada estas líneas para importar los paquetes:
import requestsnnfrom bs4 import BeautifulSoupnn# scraping logic...
Asegúrese de que su IDE de Python no informa de ningún error. Es posible que reciba algunas advertencias debido a importaciones no utilizadas, pero puede ignorarlas. Está a punto de utilizar estas bibliotecas de raspado para extraer datos de Yelp.
Paso 3: Identificar y descargar la página de destino
Navegue por Yelp e identifique la página que desea raspar. En esta guía, verá cómo recuperar datos de la lista de los restaurantes italianos mejor valorados de Nueva York:
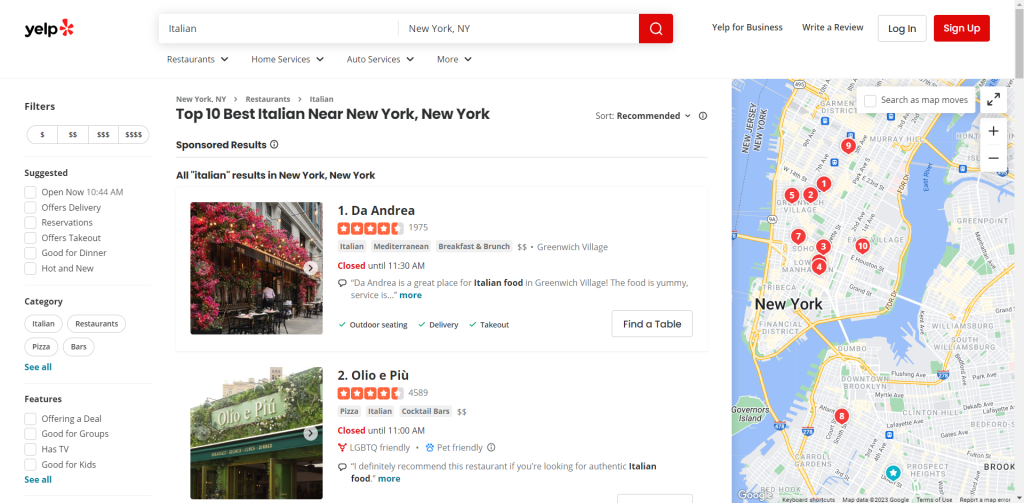
Asigne la URL de la página de destino a una variable:
url = 'https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY'nnNext, use requests.get() to make an HTTP GET request to that URL:nnpage = requests.get(url)
La página variable contendrá ahora la respuesta producida por el servidor.
En concreto, page.text almacena el documento HTML asociado a la página web de destino. Puede comprobarlo registrándolo:
print(page.text)
Esto debería imprimirse:
u003c!DOCTYPE htmlu003eu003chtml lang=u0022en-USu0022 prefix=u0022og: http://ogp.me/ns#u0022 style=u0022margin: 0;padding: 0; border: 0; font-size: 100%; font: inherit; vertical-align: baseline;u0022u003eu003cheadu003eu003cscriptu003edocument.documentElement.className=document.documentElement.className.replace(no-j/,u0022jsu0022);u003c/scriptu003eu003cmeta http-equiv=u0022Content-Typeu0022 content=u0022text/html; charset=UTF-8u0022 /u003eu003cmeta http-equiv=u0022Content-Languageu0022 content=u0022en-USu0022 /u003eu003cmeta name=u0022viewportu0022 content=u0022width=device-width, initial-scale=1, shrink-to-fit=nou0022u003eu003clink rel=u0022mask-iconu0022 sizes=u0022anyu0022 href=u0022https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/b2bb2fb0ec9c/assets/img/logos/yelp_burst.svgu0022 content=u0022#FF1A1Au0022u003eu003clink rel=u0022shortcut iconu0022 href=u0022https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/dcfe403147fc/assets/img/logos/favicon.icou0022u003eu003cscriptu003e window.ga=window.ga||function(){(ga.q=ga.q||[]).push(arguments)};ga.l=+new Date;window.ygaPageStartTime=new Date().getTime();u003c/scriptu003eu003cscriptu003ennu003c!u002du002d Omitted for brevity... u002du002du003e
Perfecto. Aprendamos a analizarlo para recuperar datos de él.
Paso 4: Analizar el contenido HTML
Introduzca el contenido HTML recuperado por el servidor en el constructor BeautifulSoup() para analizarlo:
soup = BeautifulSoup(page.text, 'html.parser')
La función toma dos argumentos:
- La cadena que contiene el HTML.
- El analizador que Beautiful Soup utilizará para analizar el contenido.
“html.parser” es el nombre del analizador HTML incorporado en Python.
BeautifulSoup() devolverá el contenido analizado como una estructura de árbol explorable. En particular, la variable soup expone métodos útiles para seleccionar elementos del árbol DOM. Los más populares son:
- find(): devuelve el primer elemento HTML que coincida con la estrategia de selección pasada como parámetro.
- find_all(): devuelve la lista de elementos HTML que coinciden con la estrategia de selector introducida.
- select_one(): devuelve el primer elemento HTML que coincida con el selector CSS pasado como parámetro.
- select(): devuelve la lista de elementos HTML que coinciden con el selector CSS introducido.
¡Fantástico! Pronto los utilizará para extraer los datos deseados de Yelp.
Paso 5: Familiarización con la página
Para idear una estrategia de selección eficaz, primero es necesario familiarizarse con la estructura de la página web de destino. Abra la página en su navegador y comience a explorarla.
Haga clic con el botón derecho del ratón en un elemento HTML de la página y seleccione “Inspeccionar” para abrir las DevTools:
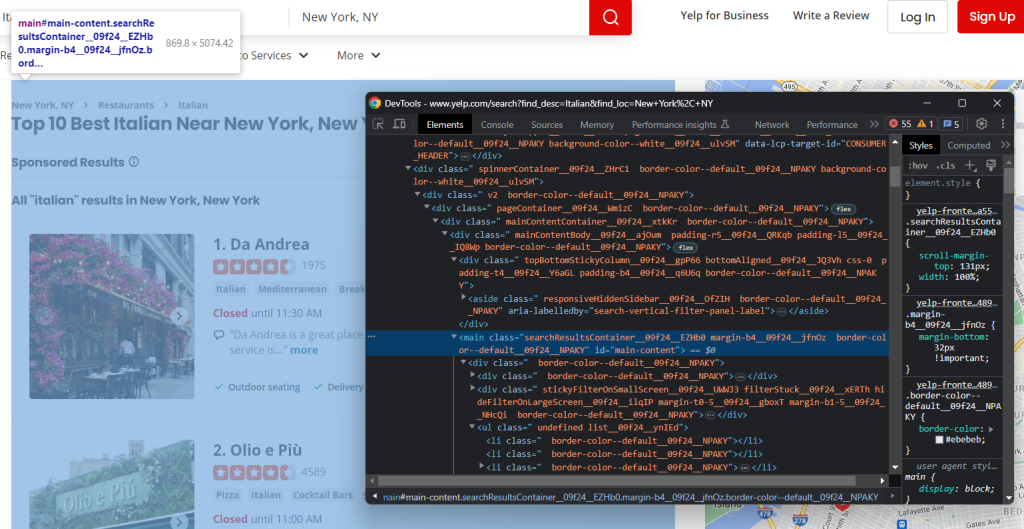
Inmediatamente observará que el sitio se basa en clases CSS que parecen generarse aleatoriamente en el momento de la compilación. Como pueden cambiar en cada despliegue, no debe basar sus selectores CSS en ellos. Esta información es esencial para construir un raspador eficaz.
Si profundiza en el DOM, también verá que los elementos más importantes tienen atributos HTML distintivos. Por lo tanto, su estrategia de selección debe basarse en ellos.
Siga inspeccionando la página en DevTools hasta que se sienta preparado para rasparla con Python.
Paso 6: Extracción de los datos de negocio
El objetivo aquí es extraer la información de negocio de cada tarjeta de la página. Para seguir la pista de estos datos, es necesario una estructura de datos donde almacenarlos:
items = []
Primero, inspeccione un elemento HTML de la tarjeta:
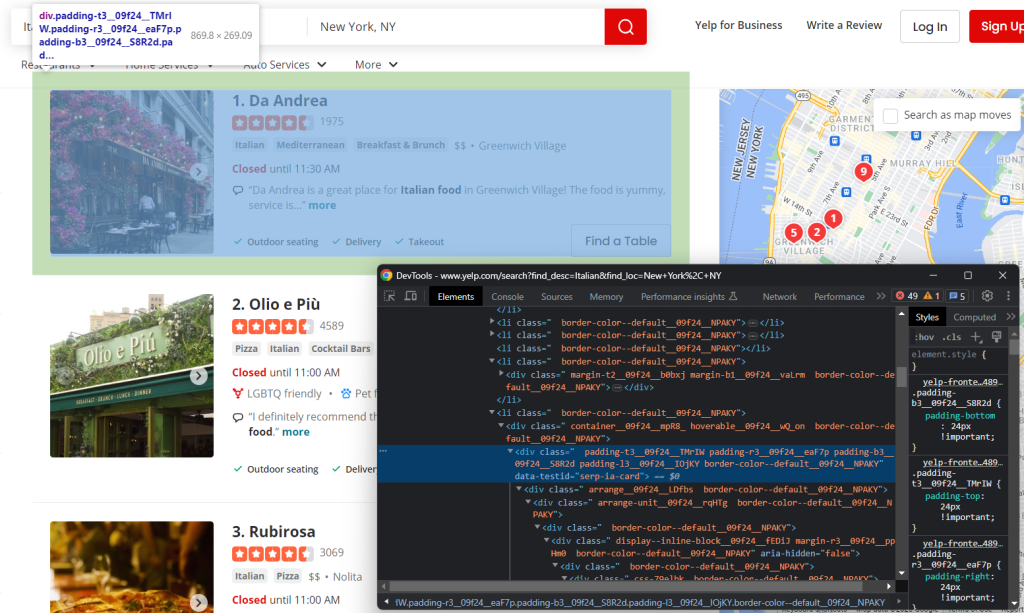
Tenga en cuenta que puede seleccionarlos todos con:
html_item_cards = soup.select('[data-testid=u0022serp-ia-cardu0022]')
Itere sobre ellas y prepare su script para:
- Extraer datos de cada uno de ellos.
- Guardarlo en un elemento del diccionario Python.
- Añadirlos a los elementos.
for html_item_card in html_item_cards:nn item = {}nn # scraping logic...nn items.append(item)
¡Es hora de implementar la lógica de raspado!
Inspeccionar el elemento imagen:
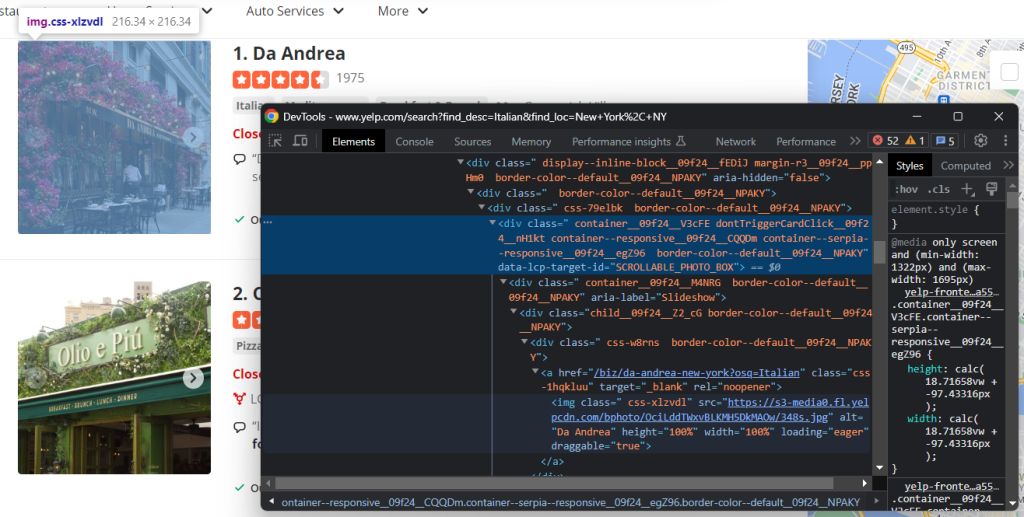
Recuperar la URL de la imagen del negocio con:
image = html_item_card.select_one('[data-lcp-target-id=u0022SCROLLABLE_PHOTO_BOXu0022] img').attrs['src']
Después de recuperar un elemento con select_one(), se puede acceder a su atributo HTML a través del miembro attrs.
Otra información útil a recuperar es el título y la URL de la página de detalles del negocio:
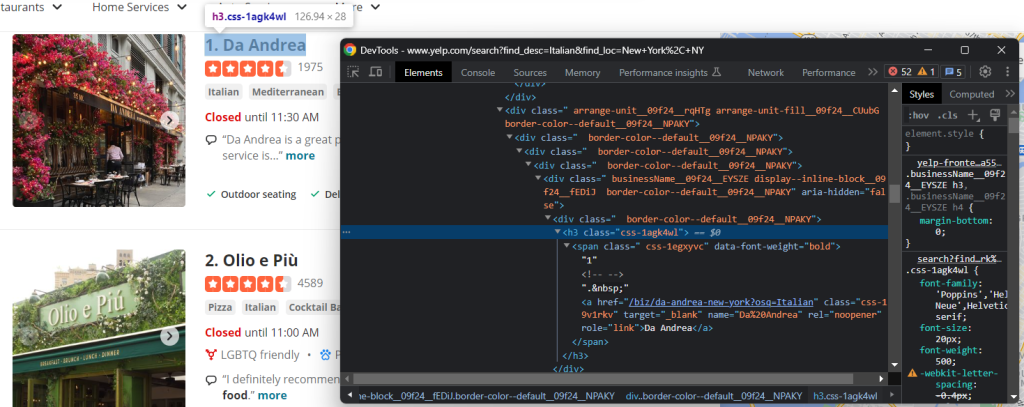
Como puede ver, puede obtener ambos campos de datos del nodo h3 a:
name = html_item_card.select_one('h3 a').textnnurl = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']
El atributo text devuelve el contenido de texto dentro del elemento actual y todos sus hijos. Como algunos enlaces son relativos, puede que sea necesario añadir la URL base para completarlos.
Uno de los datos más importantes en Yelp es la tasa de reseñas de los usuarios:
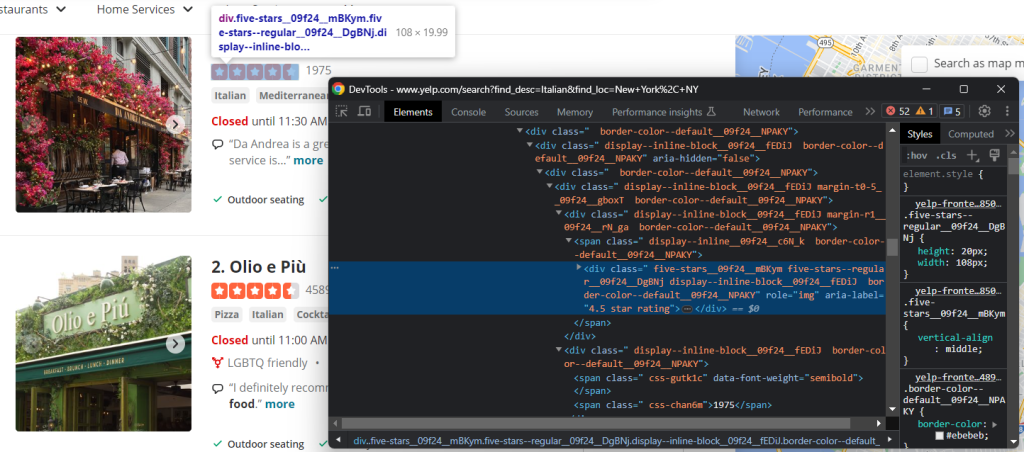
En este caso, no hay una forma fácil de obtenerlo, pero aun así se puede lograr el objetivo con:
html_stars_element = html_item_card.select_one('[class^=u0022five-starsu0022]')nnstars = html_stars_element.attrs['aria-label'].replace(' star rating', '')nnreviews = html_stars_element.parent.parent.next_sibling.text
Observe el uso de la función replace() de Python para limpiar la cadena y obtener sólo los datos relevantes.
Inspeccione también las etiquetas y los elementos del rango de precios:
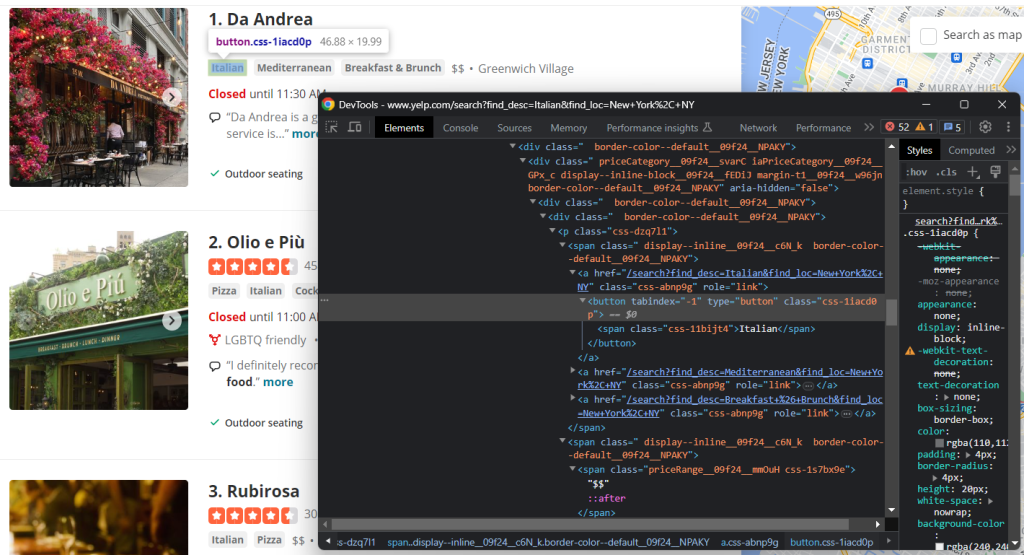
Para recoger todas las cadenas de etiquetas, es necesario seleccionarlas todas e iterar sobre ellas:
tags = []nnhtml_tag_elements = html_item_card.select('[class^=u0022priceCategoryu0022] button')nnfor html_tag_element in html_tag_elements:nn tag = html_tag_element.textnn tags.append(tag)
En cambio, recuperar la indicación opcional de rango de precios es mucho más sencillo:
price_range_html = html_item_card.select_one('[class^=u0022priceRangeu0022]')nn# since the price range info is optionalnnif price_range_html is not None:nn price_range = price_range_html.text
Por último, también hay que raspar los servicios ofrecidos por el restaurante:
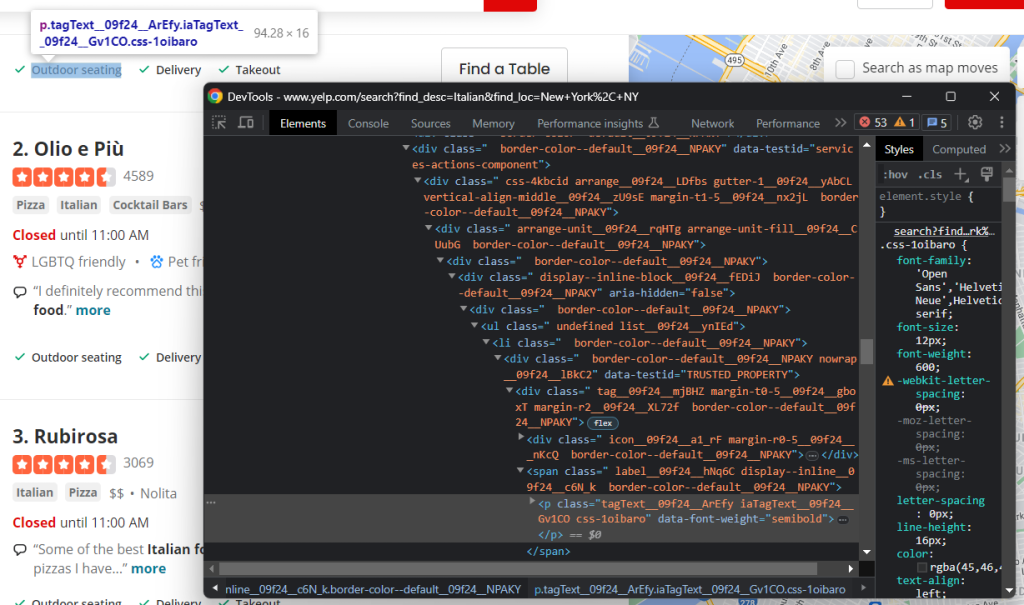
De nuevo, es necesario iterar sobre cada nodo:
services = []nnhtml_service_elements = html_item_card.select('[data-testid=u0022services-actions-componentu0022] p[class^=u0022tagTextu0022]')nnfor html_service_element in html_service_elements:nn service = html_service_element.textnn services.append(service)
¡Bien hecho! Ha implementado la lógica de raspado.
Añada las variables de los datos raspados al diccionario:
item['name'] = namennitem['image'] = imagennitem['url'] = urlnnitem['stars'] = starsnnitem['reviews'] = reviewsnnitem['tags'] = tagsnnitem['price_range'] = price_rangennitem['services'] = services
Con print(item) compruebe que el proceso de extracción de datos funciona como desea. En la primera tarjeta, obtendrá:
{'name': 'Olio e Più', 'image': 'https://s3-media0.fl.yelpcdn.com/bphoto/CUpPgz_Q4QBHxxxxDJJTTA/348s.jpg', 'url': 'https://www.yelp.com/biz/olio-e-pi%C3%B9-new-york-7?osq=Italian', 'stars': '4.5', 'reviews': '4588', 'tags': ['Pizza', 'Italian', 'Cocktail Bars'], 'price_range': '$$', 'services': ['Outdoor seating', 'Delivery', 'Takeout']}
¡Genial! ¡Se acerca más a su objetivo!
Paso 7: Implementar la lógica de recopilación
No olvide que las empresas se presentan a los usuarios en una lista paginada. Acabamos de ver cómo raspar una sola página, pero ¿y si quisiéramos obtener todos los datos? Para ello, hay que integrar la recopilación web en el raspador de datos de Yelp.
En primer lugar, hay que definir algunas estructuras de datos de apoyo en la parte superior del script:
visited_pages = []nnpages_to_scrape = ['https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY']n
visited_pages will contain the URLs of the pages scraped, while pages_to_scrape the next ones to visit.nnCreate a while loop that terminates when there are no longer pages to scrape or after a specific number of iterations:nnnlimit = 5 # in production, you can remove itnni = 0nnwhile len(pages_to_scrape) != 0 and i u003c limit:nn # extract the first page from the arraynn url = pages_to_scrape.pop(0)nn # mark it as u0022visitedu0022nn visited_pages.append(url)nn # download and parse the pagenn page = requests.get(url)nn soup = BeautifulSoup(page.text, 'html.parser')nn # scraping logic...nn # crawling logic...nn # increment the page counternn i += 1
Cada iteración se encargará de eliminar una página de la lista, rasparla, descubrir nuevas páginas y añadirlas a queue. limit simplemente evita que el raspador se ejecute eternamente.
Sólo queda implementar la lógica de recopilación. Inspeccione el elemento HTML de paginación:

Consta de varios enlaces. Recopílelos todos y añada los recién descubiertos a pages_to_visit con:
pagination_link_elements = soup.select('[class^=u0022pagination-linksu0022] a')nnfor pagination_link_element in pagination_link_elements:nn pagination_url = pagination_link_element.attrs['href']nn # if the discovered URL is newnn if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:nn pages_to_scrape.append(pagination_url)
¡Maravilloso! Ahora su raspador recorrerá automáticamente todas las páginas de paginación.
Paso 8: Exportar los datos raspados a CSV
El último paso es hacer que los datos recopilados sean más fáciles de compartir y leer. La mejor manera de hacerlo es exportarlos a un formato legible por humanos, como CSV:
import csvnn# ...nn# initialize the .csv output filennwith open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:nn writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)nn writer.writeheader()nn # populate the CSV filenn for item in items:nn # transform array fields from u0022['element1', 'element2', ...]u0022nn # to u0022element1; element2; ...u0022nn csv_item = {}nn for key, value in item.items():nn if isinstance(value, list):nn csv_item[key] = '; '.join(str(e) for e in value)nn else:nn csv_item[key] = valuenn # add a new recordnn writer.writerow(csv_item)
Cree un archivo restaurants.csv con open(). A continuación, utilice DictWriter y alguna lógica personalizada para rellenarlo. Como el paquete csv viene de la Python Standard Library, no es necesario instalar dependencias adicionales.
¡Genial! Ha empezado a partir de datos sin procesar contenidos en una página web y ahora tiene datos CSV semiestructurados. Es hora de echar un vistazo a todo el raspador Yelp Python.
Paso 9: Conjuntando todo
Este es el aspecto del script scraper.py completo:
import requestsnnfrom bs4 import BeautifulSoupnnimport csvnn# support data structures to implement thenn# crawling logicnnvisited_pages = []nnpages_to_scrape = ['https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY']nn# to store the scraped datannitems = []nn# to avoid overwhelming Yelp's servers with requestsnnlimit = 5nni = 0nn# until all pagination pages have been visitednn# or the page limit is hitnnwhile len(pages_to_scrape) != 0 and i u003c limit:nn # extract the first page from the arraynn url = pages_to_scrape.pop(0)nn # mark it as u0022visitedu0022nn visited_pages.append(url)nn # download and parse the pagenn page = requests.get(url)nn soup = BeautifulSoup(page.text, 'html.parser')nn # select all item cardnn html_item_cards = soup.select('[data-testid=u0022serp-ia-cardu0022]')nn for html_item_card in html_item_cards:nn # scraping logicnn item = {}nn image = html_item_card.select_one('[data-lcp-target-id=u0022SCROLLABLE_PHOTO_BOXu0022] img').attrs['src']nn name = html_item_card.select_one('h3 a').textnn url = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']nn html_stars_element = html_item_card.select_one('[class^=u0022five-starsu0022]')nn stars = html_stars_element.attrs['aria-label'].replace(' star rating', '')nn reviews = html_stars_element.parent.parent.next_sibling.textnn tags = []nn html_tag_elements = html_item_card.select('[class^=u0022priceCategoryu0022] button')nn for html_tag_element in html_tag_elements:nn tag = html_tag_element.textnn tags.append(tag)nn price_range_html = html_item_card.select_one('[class^=u0022priceRangeu0022]')nn # this HTML element is optionalnn if price_range_html is not None:nn price_range = price_range_html.textnn services = []nn html_service_elements = html_item_card.select('[data-testid=u0022services-actions-componentu0022] p[class^=u0022tagTextu0022]')nn for html_service_element in html_service_elements:nn service = html_service_element.textnn services.append(service)nn # add the scraped data to the objectnn # and then the object to the arraynn item['name'] = namenn item['image'] = imagenn item['url'] = urlnn item['stars'] = starsnn item['reviews'] = reviewsnn item['tags'] = tagsnn item['price_range'] = price_rangenn item['services'] = servicesnn items.append(item)nn # discover new pagination pages and add them to the queuenn pagination_link_elements = soup.select('[class^=u0022pagination-linksu0022] a')nn for pagination_link_element in pagination_link_elements:nn pagination_url = pagination_link_element.attrs['href']nn # if the discovered URL is newnn if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:nn pages_to_scrape.append(pagination_url)nn # increment the page counternn i += 1nn# extract the keys from the first object in the arraynn# to use them as headers of the CSVnnheaders = items[0].keys()nn# initialize the .csv output filennwith open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:nn writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)nn writer.writeheader()nn # populate the CSV filenn for item in items:
# transform array fields from u0022['element1', 'element2', ...]u0022nn # to u0022element1; element2; ...u0022nn csv_item = {}nn for key, value in item.items():nn if isinstance(value, list):nn csv_item[key] = '; '.join(str(e) for e in value)nn else:nn csv_item[key] = valuenn # add a new recordnn writer.writerow(csv_item)
En unas 100 líneas de código, se puede construir un web spider para extraer datos de negocios de Yelp.
Ejecute el raspador con:
python scraper.pypython scraper.py
Espere a que se complete la ejecución, y encontrará el archivo restaurants.csv a continuación en la carpeta raíz de su proyecto:
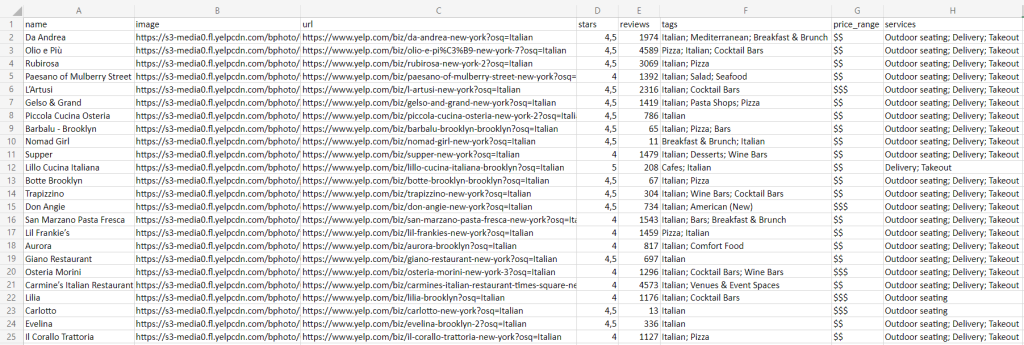
¡Enhorabuena! Así es como se raspa Yelp en Python.
Conclusión
En esta guía paso a paso, hemos explicado por qué Yelp es uno de los mejores objetivos de raspado para obtener datos de usuarios sobre negocios locales. En detalle, aprendió a construir un raspador Python que puede recuperar datos de Yelp. Como se muestra aquí, sólo se necesitan unas pocas líneas de código.
Al mismo tiempo, los sitios siguen evolucionando y adaptando su interfaz de usuario y su estructura a las expectativas siempre cambiantes de los usuarios. El raspador construido aquí funciona hoy, pero puede dejar de ser eficaz mañana. Evite gastar tiempo y dinero en mantenimiento, ¡pruebe nuestro raspador de Yelp!
Además, siga teniendo en cuenta que la mayoría de los sitios dependen en gran medida de JavaScript. En estos casos, un enfoque tradicional basado en un analizador HTML no funcionará. En su lugar, tendrá que utilizar una herramienta que pueda procesar JavaScript y gestionar las huellas dactilares, los CAPTCHA y los reintentos automáticos. En eso consiste exactamente nuestra nueva solución Scraping Browser.
¿No quiere ocuparse del raspado web de Yelp y sólo quiere datos? Adquirir conjuntos de datos de Yelp.




