

En este artículo aprenderás
- Qué es la herramienta Anthropic web fetch y sus principales limitaciones.
- Cómo funciona.
- Cómo utilizarla en cURL y Python.
- Qué ofrece Bright Data para lograr objetivos similares.
- Comparación entre la herramienta de búsqueda web de Anthropic y las herramientas de datos web de Bright Data.
- Una tabla resumen para una comparación rápida.
Entremos en materia.
¿Qué es la herramienta Anthropic Web Fetch?
La herramienta Anthropic Web Fetch permite a los modelos de Claude recuperar contenidos de páginas web y documentos PDF. Esta herramienta se introdujo de forma gratuita en la versión beta de Claude el 2026-09-10.
Incluyendo esta herramienta en una petición API de Claude, el LLM configurado puede obtener y analizar el texto completo de una página web o de una URL PDF especificadas. Esto permite a Claude acceder a información actualizada y basada en fuentes para respuestas fundamentadas.
Notas y limitaciones
Éstas son las principales notas y limitaciones asociadas a la herramienta de obtención web de Anthropic:
- Disponible en la API de Claude sin coste adicional. Sólo pagas los tokens estándar por el contenido obtenido que se incluye en el contexto de tu conversación.
- Recupera el contenido completo de páginas web y documentos PDF especificados.
- Actualmente en fase beta y requiere la cabecera beta
web-fetch-2026-09-10. - Claude no puede construir URL dinámicamente. Debe proporcionar explícitamente las URL completas, o bien sólo puede utilizar las URL obtenidas de búsquedas web anteriores o de resultados de obtención.
- Sólo puede obtener URL que ya hayan aparecido en el contexto de la conversación. Esto incluye URL de mensajes de usuario, resultados de herramientas del lado del cliente o resultados de búsquedas y búsquedas web anteriores.
- Sólo funciona con los siguientes modelos: Claude Opus 4.1
(claude-opus-4-1-20260805), Claude Opus 4(claude-opus-4-20260514), Claude Sonnet 4.5(claude-sonnet-4-5-20260929), Claude Sonnet 4(claude-sonnet-4-20260514), Claude Sonnet 3.7(claude-3-7-sonnet-20260219), Claude Sonnet 3.5 v2 (deprecated)(claude-3-5-sonnet-latest), y Claude Haiku 3.5(claude-3-5-haiku-latest). - No admite sitios web con JavaScript renderizado dinámicamente.
- Puede incluir citas opcionales para el contenido obtenido.
- Funciona con caché de consulta, de modo que los resultados almacenados en caché pueden reutilizarse en los distintos turnos de conversación.
- Admite los parámetros
max_uses,allowed_domains,blocked_domainsymax_content_tokens. - Los códigos de error más comunes son:
invalid_input,url_too_long,url_not_allowed,url_not_accessible,too_many_requests,unsupported_content_type,max_uses_exceededyunavailable.
Cómo funciona Web Fetch en los modelos Claude
Esto es lo que ocurre entre bastidores cuando añades la herramienta de obtención web de Anthropic a tu solicitud de API:
- Claude determina cuándo recuperar el contenido basándose en la solicitud y en las URL proporcionadas.
- La API recupera el contenido de texto completo de la URL especificada.
- En el caso de los PDF, se realiza una extracción automática del texto.
- Claude analiza el contenido obtenido y genera una respuesta, que puede incluir citas.
La respuesta resultante se devuelve al usuario o se añade al contexto de la conversación para su posterior análisis.
Cómo utilizar la herramienta Anthropic Web Fetch
Las dos formas principales de utilizar la herramienta Web Fetch consisten en activarla en una petición a uno de los modelos de Claude compatibles. Esto puede hacerse de cualquiera de las siguientes maneras:
- A través de una llamada directa a la API de Anthropic.
- A través de uno de los SDK de cliente de Claude, como la biblioteca API Python de Anthropic.
¡Vea cómo en las siguientes secciones!
En ambos casos, vamos a demostrar cómo utilizar la herramienta web fetch para scrapear la página de inicio de Anthropic, que se muestra a continuación:

Requisitos previos
El principal requisito para utilizar la herramienta de búsqueda web de Anthropic es tener acceso a una clave API de Anthropic. Supongamos que dispone de una cuenta de Anthropic con una clave API.
A través de una llamada directa a la API
Utilice la herramienta web fetch haciendo una llamada directa a la API de Anthropic con uno de los modelos soportados, como se muestra a continuación en una petición cURL POST:
curl https://api.anthropic.com/v1/messages API
--header "x-api-key: <SU_API_ANTHROPIC_KEY>"
--header "anthropic-version: 2023-06-01"
--header "anthropic-beta: web-fetch-2026-09-10"
--header "content-type: application/json"
--data '{
"model": "claude-sonnet-4-5-20260929",
"max_tokens": 1024,
"mensajes": [
{
"rol": "user",
"contenido": "Raspar el contenido de 'https://www.anthropic.com/'"
}
],
"tools": [{
"tipo": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}]
}'Observa que claude-sonnet-4-5-20260929 es uno de los modelos soportados por la herramienta web fetch.
Fíjate también en que las dos cabeceras especiales, anthropic-version y anthropic-beta, son necesarias.
Para habilitar la herramienta web fetch en el modelo configurado, debe añadir el siguiente elemento al array tools en el cuerpo de la petición:
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}Los campos type y name son los que importan, mientras que max_uses es opcional y define cuántas veces se puede llamar a la herramienta en una sola iteración.
Sustituya el marcador de posición <YOUR_ANTHROPIC_API_KEY> por su clave real de la API de Anthropic. A continuación, ejecute la solicitud y debería obtener algo como esto:
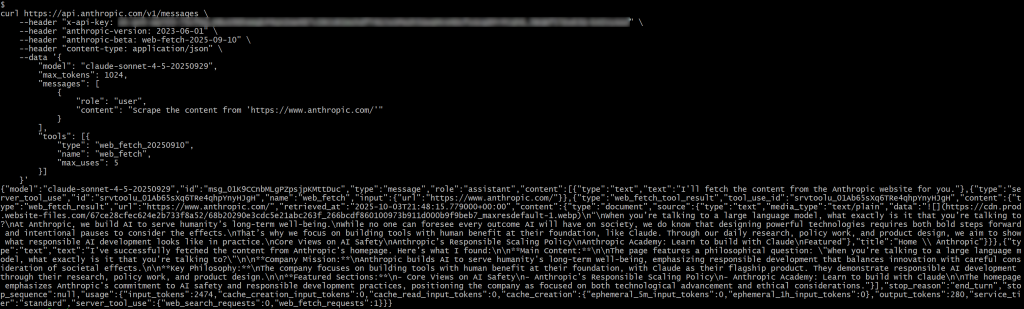
En la respuesta, usted debe ver:
{"type": "server_tool_use", "id": "srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH", "name": "web_fetch", "input":{"url": "https://www.anthropic.com/"}}Especifica que el LLM ha ejecutado una llamada a la herramienta web_fetch.
Específicamente, el resultado producido por la herramienta sería algo como:

"Cuando hablas con un gran modelo lingüístico, ¿con qué estás hablando exactamente?
En Anthropic construimos IA al servicio del bienestar de la humanidad a largo plazo.
Aunque nadie puede prever todas las consecuencias que la IA tendrá en la sociedad, sabemos que el diseño de tecnologías potentes requiere tanto pasos audaces como pausas intencionadas para considerar sus efectos.
Por eso nos centramos en crear herramientas cuya base sea el beneficio humano, como Claude. A través de nuestra investigación diaria, nuestra labor política y el diseño de nuestros productos, pretendemos mostrar cómo es en la práctica el desarrollo responsable de la IA.
Puntos de vista fundamentales sobre la seguridad de la IA
Política de escalado responsable de Anthropic
Academia Anthropic: Aprende a construir con Claude
Destacado
Representa una especie de versión Markdown de la página de inicio de la URL de entrada especificada. Es una “especie” de Markdown, ya que se omiten algunos enlaces y, aparte de la primera imagen, la salida se centra principalmente en el texto, que es exactamente para lo que está diseñada la herramienta de búsqueda web.
Nota: En general, el resultado es preciso, pero no cabe duda de que falta algo de contenido, que puede haberse perdido durante el procesamiento por parte de la herramienta. De hecho, la página original contiene más texto que el recuperado.
Uso de la biblioteca API de Anthropic Python
Alternativamente, puede llamar a la herramienta web fetch utilizando la biblioteca API Python de Anthropic con:
# pip install anthropic
importar anthropic
# Sustitúyala por su clave API de Anthropic
ANTHROPIC_API_KEY = "<SU_CLAVE_API_ANTROPIC>"
# Inicializar el cliente de la API de Anthropic
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Realiza una petición a Claude con la herramienta web fetch activada
response = client.messages.create(
model="claude-sonnet-4-5-20260929",
max_tokens=1024,
mensajes=[
{
"rol": "usuario",
"contenido": "Raspa el contenido de 'https://www.anthropic.com/'"
}
],
herramientas=[
{
"tipo": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
# Imprime el resultado producido por la IA en el terminal
print(respuesta.contenido)
Esta vez, el resultado será
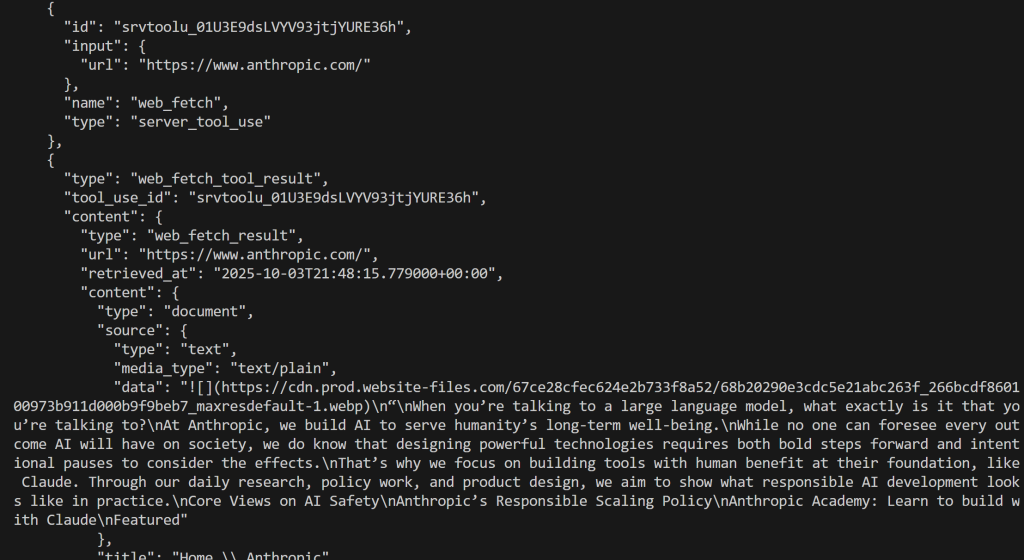
¡Genial! Esto es equivalente a lo que vimos anteriormente.
Introducción a las herramientas de datos web de Bright Data
La infraestructura Bright Data IA ofrece un rico conjunto de soluciones para que su IA busque, rastree y navegue libremente por la web. Esto incluye
- API de desbloqueo: Obtenga contenido de forma fiable desde cualquier URL pública, evitando automáticamente bloqueos y resolviendo CAPTCHAs.
- API de rastreo: Rastree y extraiga sin esfuerzo sitios web enteros, con resultados en formatos preparados para LLM para una inferencia y un razonamiento eficaces.
- API SERP: Recopile en tiempo real los resultados de motores de búsqueda geoespecíficos para descubrir fuentes de datos relevantes para una consulta específica.
- API de navegador: Permita que su IA interactúe con sitios dinámicos y automatice los flujos de trabajo agénticos a escala utilizando navegadores remotos invisibles.
Entre las muchas herramientas, servicios y productos para la recuperación de datos web en la infraestructura de Bright Data, nos centraremos en Web MCP. Ofrece herramientas preparadas para la integración de IA construidas sobre los productos de Bright Data que son directamente comparables a las ofrecidas por Anthropic. Tenga en cuenta que Web MCP también funciona como Claude MCP, integrándose plenamente con cualquier modelo de Anthropic.
De todas las más de 60 herramientas disponibles, la herramienta scrape_as_markdown es la más adecuada para la comparación. Permite raspar una única URL de página web con opciones avanzadas para la extracción de contenidos y devuelve los resultados en formato Markdown. Esta herramienta puede acceder a cualquier página web, incluso a las que utilizan detección de bots o CAPTCHA.
Es importante destacar que esta herramienta está disponible en Web MCP incluso en el nivel gratuito, lo que significa que puedes utilizarla sin coste alguno. Por tanto, consigue una funcionalidad de recuperación de datos web similar a la herramienta de obtención web de Anthropic, lo que hace que Web MCP sea ideal para una comparación directa.
Anthropic Web Fetch Tool vs Bright Data Web Data Tools
En esta sección, crearemos un proceso para comparar la herramienta de obtención web de Anthropic con las herramientas de datos web de Bright Data. En concreto
- Utilizar la herramienta de búsqueda web a través de la biblioteca API Python de Anthropic.
- Conectaremos con el MCP Web de Bright Data utilizando adaptadores MCP de LangChain (pero cualquier otra integración soportada es válida).
Ejecutaremos ambos enfoques utilizando el mismo prompt y el mismo modelo Claude a través de las siguientes cuatro URL de entrada:
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/"https://it.linkedin.com/in/antonello-zanini
Se trata de una buena combinación de páginas reales de las que una IA podría obtener contenido automáticamente: la página de inicio de un sitio web, una página de producto de G2, una página de producto de Amazon y un perfil público de LinkedIn. Tenga en cuenta que G2 es notoriamente difícil de raspar debido a la protección de Cloudflare, razón por la cual se incluyó intencionalmente en la comparación.
Veamos cómo funcionan las dos herramientas.
Requisitos previos
Antes de seguir esta sección, deberías tener
- Python instalado localmente.
- Una clave API de Anthropic.
- Una cuenta de Bright Data con una clave API.
Para configurar una cuenta de Bright Data y generar su clave API, siga la guía oficial. También se recomienda revisar la documentación oficial de Web MCP.
Además, será útil conocer cómo funciona la integración de LangChain y estar familiarizado con las herramientas proporcionadas por Web M CP.
Script de integración de la herramienta Web Fetch
Para ejecutar la herramienta Anthropic Web Fetch a través de las URL de entrada seleccionadas, puede escribir la lógica de Python de la siguiente manera:
# pip install anthropic
importar anthropic
Sustitúyala por su clave API de Anthropic
ANTHROPIC_API_KEY = ""
Inicializar el cliente de la API de Anthropic
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url):
return client.messages.create( model="claude-sonnet-4-5-20260929",
max_tokens=1024,
mensajes=[
{
"rol": "user",
"content": f "Raspa el contenido de '{url}'"
}
],
herramientas=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
A continuación, puede llamar a esta función en una URL de entrada de la siguiente manera:
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")
Script de integración de herramientas de datos web de Bright Data
Web MCP puede integrarse con una amplia gama de tecnologías, como se describe en nuestro blog. Aquí, demostraremos la integración con LangChain, ya que es una de las opciones más fáciles y populares.
Antes de empezar, se recomienda consultar la guía “Adaptadores MCP de LangChain con Web MCP de Bright Data“.
En este caso, debería terminar con un fragmento de Python como este
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
import asyncio
from langchain_anthropic import ChatAnthropic
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
import json
# Reemplace con sus claves API
ANTHROPIC_API_KEY = "<SU_CLAVE_API_ANTHROPIC>"
BRIGHT_DATA_API_KEY = "<SU_BRIGHT_DATA_API_KEY>"
async def scrape_content_with_bright_data_web_mcp_tools(agente, url):
# Descripción de la tarea del agente
input_prompt = f "Extrae el contenido de '{url}'"
# Ejecuta la petición en el agente, transmite la respuesta y la devuelve como cadena
output = []
async for step in agent.astream({"mensajes": [input_prompt]}, stream_mode="valores"):
content = paso["mensajes"][-1].content
if isinstance(contenido, lista):
output.append(json.dumps(content))
else:
output.append(content)
return "".join(salida)
async def main():
# Inicializar el motor LLM
llm = ChatAnthropic(
model="claude-sonnet-4-5-20260929",
api_key=ANTHROPIC_API_KEY
)
# Configuración para conectarse a una instancia local del servidor MCP de Bright Data Web
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "false" # Establecer opcionalmente a "true" para el modo Pro.
}
)
# Conectar con el servidor MCP
async con stdio_client(server_params) como (read, write):
async with ClientSession(read, write) as session:
# Inicializar la sesión cliente MCP
await session.initialize()
# Obtener las herramientas Web MCP
tools = await load_mcp_tools(session)
# Crear el agente ReAct con integración Web MCP
agente = create_react_agent(llm, herramientas)
# scrape_content_with_bright_data_web_mcp_tools(agente, "https://www.anthropic.com/")
if __name__ == "__main__":
asyncio.run(main())
Esto define un agente ReAct que tiene acceso a las herramientas Web MCP.
Recuerda: Web MCP ofrece un modo Pro, que proporciona acceso a herramientas premium. El uso del modo Pro no es estrictamente necesario en este caso. Por lo tanto, puede confiar únicamente en las herramientas disponibles en el nivel gratuito. Las herramientas gratuitas incluyen scrape_as_markdown, que es suficiente para este benchmark.
En términos más sencillos, desde una perspectiva de costes, utilizar Web MCP en modo gratuito no costará más que el uso de tokens para el propio modelo Claude (que es el mismo en ambos escenarios). Esencialmente, la estructura de costes para esta configuración es la misma que cuando se conecta directamente a Claude a través de la API.
Resultados de la prueba
Ahora, ejecute las dos funciones que representan los dos métodos de recuperación de Datos para IA utilizando la lógica siguiente:
# Dónde almacenar los resultados del benchmark
benchmark_results = []
# Las URL de entrada para probar los dos métodos
urls = [
"https://www.anthropic.com/",
"https://www.g2.com/products/bright-data/reviews",
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/",
"https://it.linkedin.com/in/antonello-zanini"
]
# Probar cada URL
for url in urls:
print(f "Probando los dos enfoques en la siguiente URL: {url}")
anthropic_start_time = time.time()
anthropic_response = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agente, url)
bright_data_end_time = time.time()
benchmark_entry = {
"url": url
"antrópico": {
"tiempo_ejecución": tiempo_final_antrópico - tiempo_inicial_antrópico,
"output": anthropic_response.to_json()
},
"bright_data": {
"execution_time": bright_data_end_time - bright_data_start_time,
"salida": bright_data_response
}
}
benchmark_results.append(benchmark_entry)
# Exportar los datos de referencia
with open("benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)
Los resultados pueden resumirse en la siguiente tabla:
| Herramienta Anthropic Web Fetch | Bright Data Web Data Tools | |
|---|---|---|
| Página principal de Anthropic | ✔️ (información parcial en texto) | ✔️ (información completa en Markdown) |
| Página de revisión de G2 | ❌ (la herramienta falló después de ~10 segundos) | ✔️ (versión completa de la página en Markdown) |
| Página de producto de Amazon | ✔️ (información parcial en texto) | ✔️ (versión Markdown completa de la página o datos de producto JSON estructurados en modo Pro) |
| Página de perfil de LinkedIn | ❌ (la herramienta falló inmediatamente) | ✔️ (versión Markdown completa de la página o datos de perfil JSON estructurados en modo Pro) |
Como puede ver, la herramienta de obtención de datos web de Anthropic no sólo es menos eficaz que las herramientas de obtención de datos web de Bright Data, sino que incluso cuando funciona, produce resultados menos completos.
La herramienta Anthropic se centra principalmente en el texto, mientras que las herramientas Web MCP como scrape_as_markdown devuelven la versión Markdown completa de una página. Además, con herramientas Pro como web_data_amazon_product, puede obtener feeds de datos estructurados de sitios populares como Amazon.
En general, las herramientas de datos web de Bright Data son las claras vencedoras en términos de precisión y tiempo de ejecución.
Resumen: Tabla comparativa
| Herramienta Anthropic Web Fetch | Herramientas de datos web de Bright Data | |
|---|---|---|
| Tipos de contenido | Páginas web, PDF | Páginas web |
| Capacidades | Extracción de texto | Extracción de contenidos, Scraping web, rastreo web, etc. |
| Salida | Principalmente texto plano | Markdown, JSON y otros formatos compatibles con LLM |
| Integración de modelos | Sólo funciona con modelos Claude específicos | Se integra totalmente con cualquier LLM y más de 70 tecnologías |
| Compatibilidad con sitios renderizados en JavaScript | ❌ | ✔️ |
| Anulación de robots y gestión de CAPTCHA | ❌ | ✔️ |
| Robustez | Beta | Listo para producción |
| Soporte para solicitudes por lotes | ✔️ | ✔️ |
| Integración de agentes | Sólo en soluciones Claude | ✔️ (en cualquier solución de creación de agentes de IA que admita MCP o herramientas oficiales de Bright Data) |
| Fiabilidad e integridad | Contenido parcial; puede fallar en páginas complejas | Extracción de contenido completo; gestiona sitios y páginas complejas con protección contra bots |
| Coste | Sólo uso de token estándar | Sólo uso de token estándar en modo gratuito; costes adicionales en modo Pro |
Para integrar Web MCP con tecnologías antrópicas y modelos Claude, consulte las siguientes guías:
- Integración de Claude Code con Web MCP de Bright Data
- Scraping web con Claude: Parseo potenciado por IA en Python
- Cómo utilizar Bright Data con Pica MCP en Claude Desktop
Conclusión
En esta entrada de blog comparativa, ha visto cómo la herramienta de obtención web de Anthropic se compara con las capacidades de recuperación e interacción de datos web que ofrece Bright Data. En concreto, ha aprendido a utilizar la herramienta de Anthropic en ejemplos reales, seguidos de una comparación comparativa utilizando un agente LangChain equivalente que interactúa con el MCP Web de Bright Data.
El claro ganador fueron las herramientas de Bright Data, que incluyen una gama de productos y servicios preparados para IA capaces de soportar una amplia variedad de casos y escenarios de uso.
Cree una cuenta gratuita en Bright Data hoy mismo y empiece a explorar nuestras herramientas de datos web preparadas para IA.





