

HtmlUnit es un navegador sin interfaz gráfica que permite modelar páginas HTML. Después de modelar la página mediante programación, es posible interactuar con ella realizando tareas como rellenar formularios, enviarlos y navegar entre páginas. Puede utilizarse para el raspado web con el fin de extraer datos para su posterior manipulación, así como para crear pruebas automatizadas que verifiquen que su programa crea páginas web según lo esperado.
Raspado web con HtmlUnit
Para implementar el raspado web utilizando HtmlUnit y Gradle, se utilizará el IDE IntelliJ IDEA; sin embargo, se puede utilizar cualquier IDE o editor de código que se prefiera.
IntelliJ soporta una integración totalmente funcional con Gradle y puede descargarse en el sitio de JetBrains. Gradle es una herramienta de automatización de construcción que soporta la construcción y creación de paquetes para su aplicación. También hace posible añadir y gestionar dependencias sin problemas. Gradle y las extensiones de Gradle se instalan y habilitan por defecto en las últimas versiones de IntelliJ IDEA.
Todo el código para este tutorial se puede encontrar en este repositorio de GitHub.
Crear un proyecto Gradle
Para crear un nuevo proyecto Gradle en IntelliJ IDEA, seleccione Archivo > Nuevo > Proyecto en las opciones del menú, y se abrirá un nuevo asistente de proyecto. Introduzca el nombre del proyecto y seleccione la ubicación deseada:

Es necesario seleccionar el lenguaje Java ya que se creará una aplicación de raspado web en Java utilizando HtmlUnit. Además, seleccione el sistema de construcción Gradle. A continuación, haga clic en Crear. Esto creará un proyecto Gradle con una estructura predeterminada y todos los archivos necesarios. Por ejemplo, el archivo build.gradle contiene todas las dependencias necesarias para construir este proyecto:
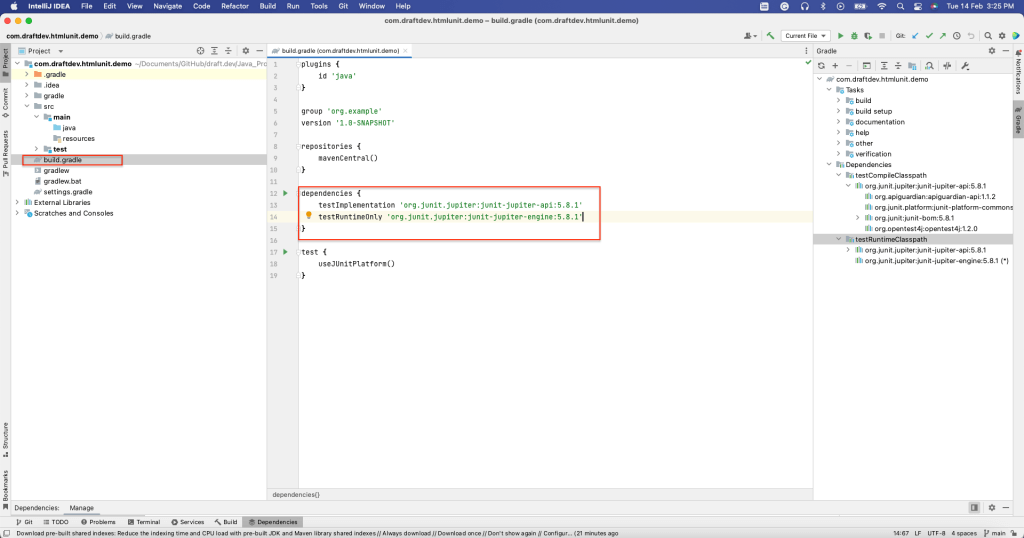
Se instala HtmlUnit
Para instalar HtmlUnit como dependencia, abra la ventana de Dependencias seleccionando Ver > Ventanas de Herramientas > Dependencias.
A continuación, busque “htmlunit” y seleccione Añadir:
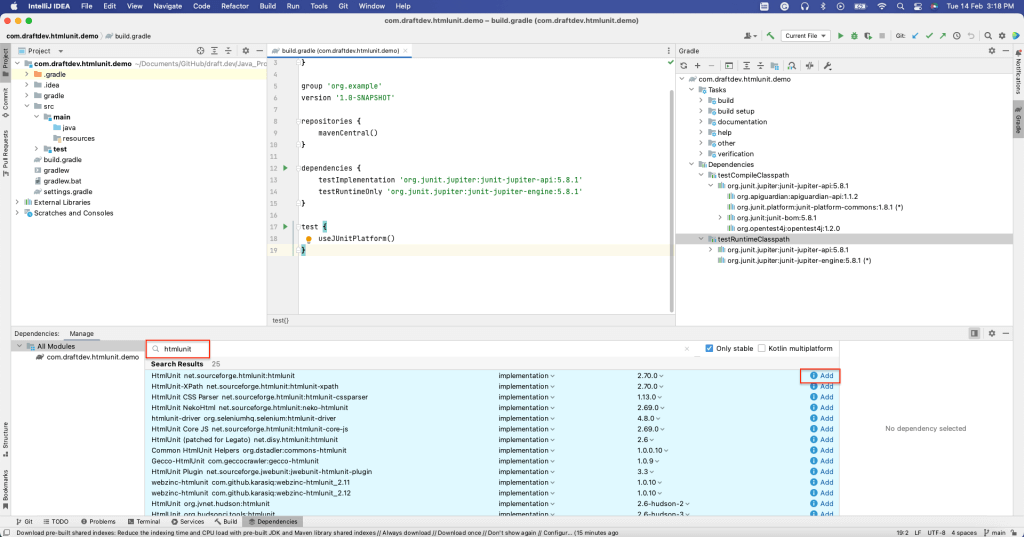
Se debería poder ver que HtmlUnit se ha instalado en la sección de dependencias del archivo build.gradle:

Ahora que se ha instalado HtmlUnit, es el momento de raspar datos de páginas web estáticas y dinámicas.
Raspado de una página estática
En esta sección, se explica cómo raspar HtmlUnit Wiki, una página web estática. Esta página web contiene elementos como el título, la tabla de contenidos, la lista de subtítulos y el contenido de cada subtítulo.
Cada elemento de una página web HTML tiene atributos. Por ejemplo, ID es un atributo que identifica de forma única a un elemento en el documento HTML completo, y Name es un atributo que identifica a ese elemento. El atributo Name no es único, y más de un elemento del documento HTML puede tener el mismo nombre. Los elementos de una página web pueden identificarse utilizando cualquiera de los atributos.
Alternativamente, también puede identificar elementos utilizando su XPath. XPath utiliza una sintaxis similar a la de las rutas para identificar y navegar por los elementos en el HTML de la página web.
En los siguientes ejemplos, se utilizarán ambos métodos para identificar los elementos de la página HTML.
Para raspar una página web, necesita crear un WebClient HtmlUnit. El WebClient representa un navegador dentro de su aplicación Java. Inicializar un WebClient es similar a iniciar un navegador para ver la página web.
Para inicializar un WebClient, utilice el siguiente código:
WebClient webClient = new WebClient(BrowserVersion.CHROME);
Este código inicializa el navegador Chrome. Otros navegadores también son compatibles.
Se puede obtener la página web utilizando el método getPage() disponible en el objeto webClient. Una vez que se tiene la página web, se pueden raspar los datos de la página web utilizando varios métodos.
Para obtener el título de la página, utilice el método getTitleText(), como se muestra en el siguiente código:
String webPageURl = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;n try {nn HtmlPage page = webClient.getPage(webPageURl);n n System.out.println(page.getTitleText());n n } catch (FailingHttpStatusCodeException | IOException e) {n n e.printStackTrace();n n }
Se imprimirá el título de la página:
HtmlUnit - Wikipedia
Para ir un paso más allá, obtendremos todos los elementos H2 disponibles en la página web. En este caso, los H2 están disponibles en dos secciones de la página:
- En la barra lateral izquierda, donde se muestran los contenidos: Como puede ver, el encabezado de la sección Contenidos es un elemento H2.
- En el cuerpo principal de la página: Todos los subtítulos son elementos H2.
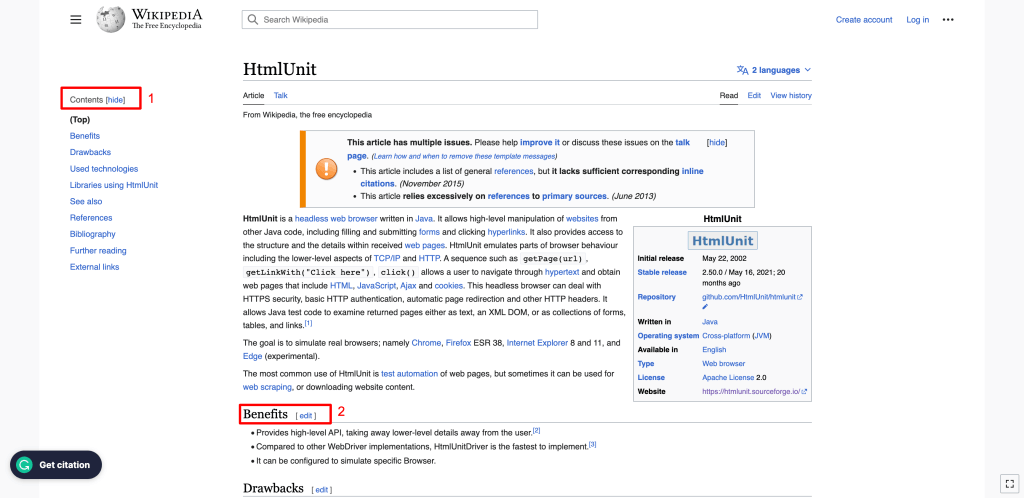
Para obtener todos los H2 en el cuerpo del contenido, puede utilizar el XPath de los elementos H2. Para encontrar el XPath, haga clic con el botón derecho en cualquier elemento H2 y seleccione Inspeccionar. Luego haga clic derecho en el elemento resaltado y seleccione Copiar > Copiar XPath completo:
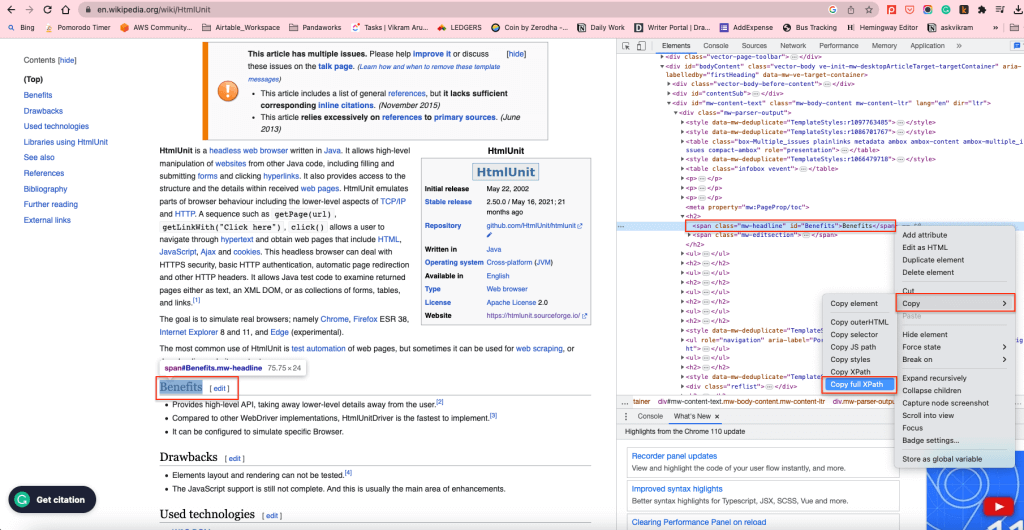
Esto copiará el XPath al portapapeles. Por ejemplo, el elemento XPath de los H2 en el cuerpo del contenido es /html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2.
Para obtener todos los elementos H2 utilizando su XPath, puede utilizar el método getByXpath():
String xPath = u0022/html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2u0022;nn String webPageURL = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;n n try {n HtmlPage page = webClient.getPage(webPageURL);nn //Get all the headings using its XPath+n Listu003cHtmlHeading2u003e h2 = (Listu003cHtmlHeading2u003e)(Object) page.getByXPath(xPath);n n //print the first heading text contentn System.out.println((h2.get(0)).getTextContent());nn } catch (FailingHttpStatusCodeException | IOException e) {n n e.printStackTrace();n n }
El contenido de texto del primer elemento H2 se imprimirá como sigue:
Benefits[edit]
De forma similar, es posible obtener los elementos a través de su ID mediante el método getElementById(), y es posible obtener los elementos a través de su nombre mediante el método getElementByName().
En la siguiente sección, se utilizarán estos métodos para raspar una página web dinámica.
Raspado de una página web dinámica mediante HtmlUnit
En esta sección, se mostrarán las funciones de rellenado de formularios y pulsación de botones de HtmlUnit rellenando el formulario de inicio de sesión y enviándolo. También se explicará cómo navegar por páginas web utilizando el navegador headless.
Para ayudar a demostrar el raspado web dinámico, vamos a utilizar el sitio web de Hacker News. Este es el aspecto de la página de inicio de sesión:

El siguiente código es el código HTML del formulario de la página anterior. Se puede obtener este código haciendo clic con el botón derecho en la etiqueta de inicio de sesión y haciendo clic en Inspeccionar:
u003cform action=u0022loginu0022 method=u0022postu0022u003enu003cinput type=u0022hiddenu0022 name=u0022gotou0022 value=u0022newsu0022u003enu003ctable border=u00220u0022u003enu003ctbodyu003enu003ctru003eu003ctdu003eusername:u003c/tdu003eu003ctdu003eu003cinput type=u0022textu0022 name=u0022acctu0022 size=u002220u0022 autocorrect=u0022offu0022 spellcheck=u0022falseu0022 autocapitalize=u0022offu0022 autofocus=u0022trueu0022u003eu003c/tdu003eu003c/tru003enu003ctru003eu003ctdu003epassword:u003c/tdu003eu003ctdu003eu003cinput type=u0022passwordu0022 name=u0022pwu0022 size=u002220u0022u003eu003c/tdu003eu003c/tru003eu003c/tbodyu003eu003c/tableu003eu003cbru003enu003cinput type=u0022submitu0022 value=u0022loginu0022u003eu003c/formu003e
Para rellenar el formulario usando HtmlUnit, se obtiene la página web usando el objeto webClient. La página contiene dos formularios: Login y Crear Cuenta. Es posible obtener el formulario de inicio de sesión utilizando el método getForms().get(0). Alternativamente, puede utilizar el método getFormByName() si los formularios tienen un nombre único.
A continuación, es necesario obtener las entradas del formulario (es decir, los campos de nombre de usuario y contraseña) utilizando el método getInputByName() y el atributo name.
Establezca el valor del nombre de usuario y la contraseña en los campos de entrada utilizando el método setValueAttribute() y obtenga el botón Enviar utilizando el método getInputByValue(). También puede hacer clic en el botón utilizando el método click().
Una vez que se presiona el botón, si el login es exitoso, la página de destino del botón Submit se devolverá como el objeto HTMLPage, que puede ser utilizado para operaciones posteriores.
El siguiente código muestra cómo obtener el formulario, rellenarlo y enviarlo:
HtmlPage page = null;nnString webPageURl = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;nn try {n // Get the first pagenn HtmlPage signUpPage = webClient.getPage(webPageURL);nn // Get the form using its index. 0 returns the first form.n HtmlForm form = signUpPage.getForms().get(0);nn //Get the Username and Password field using its namen HtmlTextInput userField = form.getInputByName(u0022acctu0022);n HtmlInput pwField = form.getInputByName(u0022pwu0022);n n //Set the User name and Password in the appropriate fieldsn userField.setValueAttribute(u0022draftdemoacctu0022);n pwField.setValueAttribute(u0022test@12345u0022);nn //Get the submit button using its Valuen HtmlSubmitInput submitButton = form.getInputByValue(u0022loginu0022);nn //Click the submit button, and it'll return the target page of the submit buttonn page = submitButton.click();nnn } catch (FailingHttpStatusCodeException | IOException e) {n e.printStackTrace();n }
Una vez que se envía el formulario y el login exitoso, se le llevará a la página de inicio del usuario, donde se muestra el nombre de usuario en la esquina derecha:
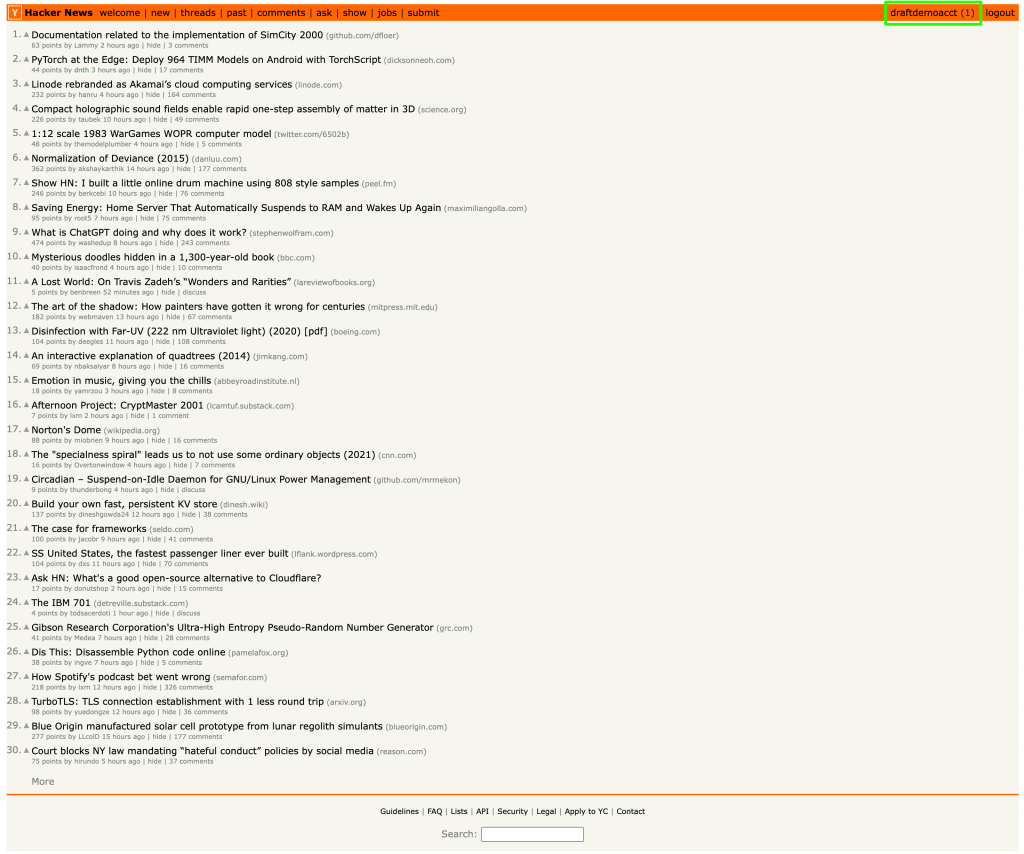
El elemento nombre de usuario tiene el ID “me”. Se puede obtener el nombre de usuario utilizando el método getElementById() y pasar el ID “me” como se demuestra en el siguiente código:
System.out.println(page.getElementById(u0022meu0022).getTextContent());
El nombre de usuario de la página web es raspado y mostrado como salida:
draftdemoacct
A continuación, es necesario navegar a la segunda página del sitio Hacker News haciendo clic en el botón de hipervínculo Más al final de la página:

Para obtener el objeto del botón Más, obtenga el XPath del botón Más utilizando la opción Inspeccionar y obtenga el primer objeto de enlace utilizando el índice 0:
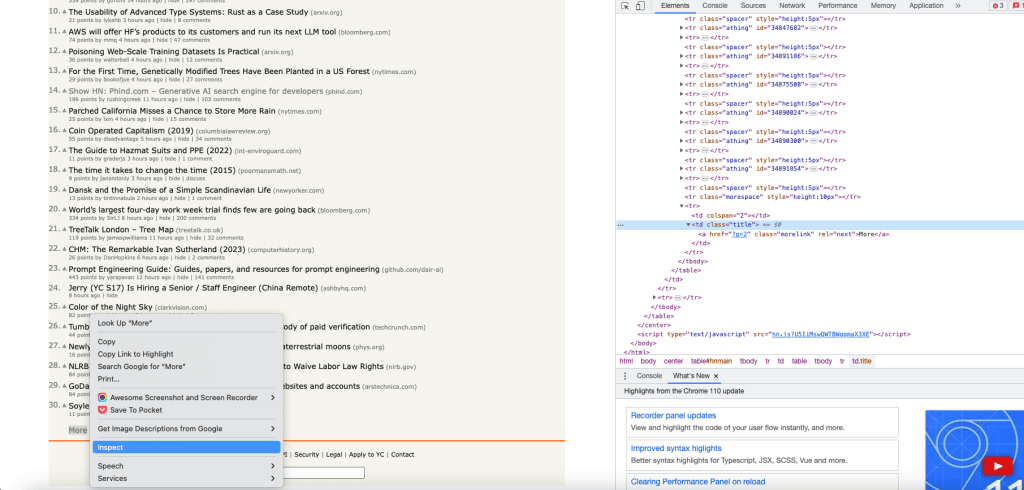
Haga clic en el enlace Más utilizando el método click(). Se presiona el enlace y la página de destino del enlace se devolverá como un objeto HtmlPage:
HtmlPage nextPage = null;nn try {n Listu003cHtmlAnchoru003e links = (Listu003cHtmlAnchoru003e)(Object)page.getByXPath(u0022html/body/center/table/tbody/tr[3]/td/table/tbody/tr[92]/td[2]/au0022);n n HtmlAnchor anchor = links.get(0);n n nextPage = anchor.click();nn } catch (IOException e) {n throw new RuntimeException(e);n }
En este punto, debería tener la segunda página en el objeto HtmlPage.
Puede imprimir la URL de la HtmlPage para comprobar si la segunda página se ha cargado correctamente:
System.out.println(nextPage.getUrl().toString());
A continuación se muestra la URL de la segunda página:
https://news.ycombinator.com/news?p=2
Cada página del sitio Hacker News tiene treinta entradas. Por eso, las entradas de la segunda página empiezan por el número de serie 31.
Recuperaremos la ID de la primer entrada en la segunda página y corroboremos si es igual a 31.
Igual que anteriormente, obtenga el XPath de la primera entrada usando la opción Inspeccionar. A continuación, obtenga la primera entrada de la lista y muestre su contenido de texto:
String firstItemId = null;nn Listu003cObjectu003e entries = nextPage.getByXPath(u0022/html/body/center/table/tbody/tr[3]/td/table/tbody/tr[1]/td[1]/spanu0022);nn HtmlSpan span = (HtmlSpan) (entries.get(0));nn firstItemId = span.getTextContent();n n System.out.println(firstItemId);
Ahora se muestra el ID de la primera entrada:
31.
Este código muestra cómo rellenar el formulario, hacer clic en los botones y navegar por las páginas web utilizando HtmlUnit.
Conclusión
En este artículo, hemos demostrado cómo raspar sitios web estáticos y dinámicos con HtmlUnit. También se mostraron algunas capacidades avanzadas de HtmlUnit raspando páginas web y convirtiéndolas en datos estructurados.
Al hacer esto con un IDE como IntelliJ IDEA, es necesario encontrar los atributos de los elementos inspeccionándolos manualmente y escribir funciones de raspado desde cero utilizando los atributos de los elementos.
Por su parte, el IDE Web Scraper de Bright Data proporciona una infraestructuctura sólida de proxy de desbloqueo, funciones prácticas de raspado y plantillas de código para sitios web populares. Una infraestructura de proxy eficaz es necesaria cuando se trata de raspar una página web sin problemas de bloqueo de IP y limitación de velocidad. El proxy también ayuda a emular a un usuario de una geolocalización diferente.
Talk to one of Bright Data’s experts and find the right solution for your business.





