

En este artículo, analizamos estas cuestiones:
- Raspado web con JavaScript de frontend
- Requisitos previos
- Bibliotecas de raspado web para Node.js
- Conclusión
Raspado web con JavaScript de frontend
Respecto al raspado web, el JavaScript de frontend es una solución limitada. Primero, porque tendrías que ejecutar tu script de raspado web de JavaScript directamente desde la consola del navegador. Esta no es una operación que se pueda realizar mediante programación.
En concreto, puedes raspar los datos de una página de la consola de la siguiente manera:

En segundo lugar, si querías raspar datos de otras páginas web, tendrías que descargarlos a través de AJAX. En cualquier caso, no olvides que los navegadores web aplican una política de igual origen a AJAX. Por tanto, con el frontend de JavaScript, solo puedes acceder a páginas web que tengan el mismo origen.
Vamos a ver lo que esto significa con un ejemplo sencillo. Supongamos que visitas una página de brightdata.com. Entonces, tu script de raspado web de JavaScript para frontend solo podría descargar páginas web del dominio brightdata.com.
Esto no significa en absoluto que JavaScript no sea una buena tecnología para el rastreo web. En realidad, Node.js permite ejecutar JavaScript en servidores y evitar las dos limitaciones presentadas anteriormente.
Vamos a ver ahora cómo se puede crear un raspador web de JavaScript con Node.js.
Requisitos previos
Antes de empezar a trabajar en la aplicación de raspado web Node.js, debes cumplir la siguiente lista de requisitos previos:
- Node.js 18+ con npm 8+: cualquier versión LTS (soporte a largo plazo, por sus siglas en inglés) de Node.js 18+, incluido npm, funcionará bien. Este tutorial se basa en Node.js 18.12 con npm 8.19, que representa la última versión LTS de Node.js en el momento de redactar este artículo.
- Un IDE compatible con JavaScript: la edición comunitaria de IntelliJ IDEA es el IDE elegido para este tutorial, pero cualquier otro IDE compatible con JavaScript y Node.js también servirá.
Haz clic en los enlaces anteriores y sigue los asistentes de instalación para configurar todo lo que necesitas. Para comprobar que Node.js se ha instalado correctamente, ejecuta el siguiente comando en tu terminal:
node -vEsta acción debería devolver algo como:
v18.12.1Del mismo modo, verifica que npm se haya instalado correctamente con
npm -v Esta acción debería devolver una cadena como:
8.19.2Ambos comandos indican la versión de Node.js y npm disponible globalmente en tu máquina, respectivamente.
¡Fantástico! ¡Ya estás listo para ver cómo realizar el raspado web de JavaScript en Node.js!
Las mejores bibliotecas de raspado web de JavaScript para Node.js
Exploremos las mejores bibliotecas de JavaScript para el raspado web en Node.js:
- Axios: una biblioteca intuitiva que te ayuda a realizar solicitudes HTTP en JavaScript. Puedes usar Axios tanto en el navegador como en Node.js, y representa uno de los clientes HTTP de JavaScript más populares disponibles.
- Cheerio: una biblioteca ligera que proporciona una API similar a la de jQuery para explorar documentos HTML y XML. Puedes usar Cheerio para analizar un documento HTML, seleccionar elementos HTML y extraer datos de ellos. Es decir, Cheerio ofrece una API avanzada de raspado web.
- Selenium: una biblioteca compatible con varios lenguajes de programación que puedes usar para crear pruebas automatizadas para aplicaciones web. También puedes usarla para el raspado web dadas sus funciones de navegador sin interfaz gráfica.
- Playwright: una herramienta para crear scripts de prueba automatizados para aplicaciones web desarrolladas por Microsoft. Ofrece una forma de indicar al navegador que realice acciones concretas. Por tanto, puedes usar Playwright para el raspado web como una solución de navegador sin interfaz gráfica.
- Puppeteer: una herramienta para automatizar las pruebas de aplicaciones web desarrolladas por Google. Puppeteer se basa en el protocolo DevTools de Chrome. Al igual que Selenium y Playwright, te permite interactuar programáticamente con el navegador como lo haría un usuario humano. Obtén más información sobre las diferencias entre Selenium y Puppeteer.
Creación de un raspador web de JavaScript en Node.js
Aquí vas a aprender a crear un raspador web de JavaScript en Node.js que pueda extraer datos automáticamente de un sitio web. En concreto, la página web de destino será la página de inicio de Bright Data. El objetivo del proceso de raspado web de Node.js será seleccionar los elementos HTML de interés de la página, recuperar datos de ellos y convertir los datos raspados a un formato más práctico.
En el momento de redactar este artículo, la página de inicio de Bright Data tiene este aspecto:

Como puedes ver, la página de inicio de Bright Data contiene una gran cantidad de datos e información en diferentes formatos, desde descripciones de texto hasta imágenes. Además, contiene una gran cantidad de enlaces prácticos. Aprenderás a recuperar todos estos datos.
¡Veamos ahora cómo raspar datos con Node.js en un tutorial paso a paso!
Paso 1: configura un proyecto de Node.js
Primero, crea la carpeta que contendrá tu proyecto de raspado web de Node.js con:
mkdir web-scraper-nodejsAhora deberías tener un directorio web-scraper-nodejs vacío. Puedes darle a la carpeta del proyecto el nombre que quieras. Entra en la carpeta con:
cd web-scraper-nodejsAhora, inicializa un proyecto npm con:
npm init -yEste comando configurará un nuevo proyecto de npm. Ten en cuenta que el indicador -y es necesario para que npm inicialice un proyecto predeterminado sin pasar por un proceso interactivo. Si omites el indicador -y, se te harán unas preguntas en la terminal.
web-scraper-nodejs ahora debería contener un package.json con el siguiente aspecto:
{
"name": "web-scraper-nodejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}A continuación, crea un archivo index.js en la carpeta raíz de tu proyecto e inicialízalo de la siguiente manera:
// index.js
console.log("Hello, World!")Este archivo JavaScript contendrá la lógica de raspado web de Node.js.
Abre tu archivo package.json y añade el siguiente script en la sección scripts:
"start": "node index.js"Ahora puedes ejecutar el siguiente comando en tu terminal para iniciar tu script Node.js:
npm run startEsta acción debería devolver:
Hello, World!Esto significa que la aplicación Node.js funciona correctamente. Ahora, abre el proyecto en tu IDE y prepárate para escribir una lógica de raspado en Node.js.
Si eres usuario de IntelliJ IDEA, verás lo siguiente:

Paso 2: instala Axios y Cheerio
Es hora de instalar las dependencias necesarias para implementar el raspador web en Node.js. Para saber qué bibliotecas de raspado web de JavaScript debes adoptar, visita la página web de destino, haz clic con el botón derecho en una sección en blanco y selecciona la opción «Inspeccionar». Esta acción abrirá la ventana DevTools de tu navegador. En la pestaña Red, echa un vistazo a la sección Fetch/XHR.

Arriba, puedes ver las solicitudes AJAX realizadas por la página web de destino. Si abres las tres solicitudes XHR ejecutadas por el sitio web, verás que no devuelven datos interesantes. Es decir, los datos deseados se incrustan directamente en el código fuente de la página web. He aquí lo que suele ocurrir con los sitios web renderizados en el servidor.
La página web de destino no depende de JavaScript para recuperar datos ni para la renderización. Por tanto, no necesitas una herramienta que pueda ejecutar JavaScript en el navegador. Es decir, no es necesario utilizar una biblioteca de navegador sin frontend para extraer datos de la página web de destino. Puedes usar una biblioteca de este tipo, pero no es necesaria.
Dado que las bibliotecas que ofrecen funciones de navegación sin interfaz gráfica abren páginas web en un navegador, esto supone una sobrecarga. Ello se debe a que los navegadores son aplicaciones pesadas. Pero puedes evitar fácilmente esta sobrecarga si optas por Cheerio junto con Axios.
Por tanto, instala cheerio y axios con:
npm install cheerio axiosLuego, importa cheerio y axios añadiendo las dos líneas de código siguientes a index.js:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")¡Vamos a programar ahora un script de raspado web Node.js que realice el raspado web con Cheerio y Axios!
Paso 3: descarga tu sitio web objetivo
Usa Axios para conectarte a tu sitio web objetivo con las siguientes líneas de código:
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
})Gracias al método request() de Axios, puedes ejecutar cualquier solicitud HTTP. En concreto, si quieres descargar el código fuente de una página web, tienes que realizar una petición HTTP GET a su URL. Normalmente, Axios devolverá de inmediato una promesa. Puedes esperar a que llegue una promesa y obtener su valor de forma sincrónica con la palabra clave await.
Ten en cuenta que si request() falla, se generará un error. Esto puede ocurrir por varios motivos, desde una URL no válida hasta un servidor no disponible temporalmente. Además, no hay que olvidar que muchos sitios web implementan medidas antiraspado. Una de las más populares consiste en bloquear las solicitudes que no tienen un encabezado HTTP User-Agent válido. Obtén más información sobre User-Agents para el raspado web.
De forma predeterminada, Axios utiliza el siguiente User-Agent:
axios <axios_version>Este no es el aspecto del User-Agent que utiliza un navegador. Por tanto, las tecnologías antiraspado pueden detectar y bloquear tu raspador web Node.js.
Establece un encabezado User-Agent válido en Axios añadiendo el siguiente atributo al objeto pasado a request():
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}El atributo headers te permite configurar cualquier encabezado HTTP en Axios.
Tu archivo index.js ahora debería tener el siguiente aspecto:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
}
performScraping()Ten en cuenta que solo puedes usar await en funciones marcadas con async. Por eso tienes que incrustar tu lógica de raspado web de JavaScript en la función async performScraping().
Ahora dediquemos un momento a analizar la página web de destino para definir una estrategia de raspado web.
Paso 4: inspecciona la página HTML
Si echas un vistazo a la página principal de Bright Data, verás una lista de sectores en los que puedes usar Bright Data. Es interesante raspar estos datos.
Haz clic con el botón derecho en uno de estos elementos HTML y selecciona «Inspeccionar»:
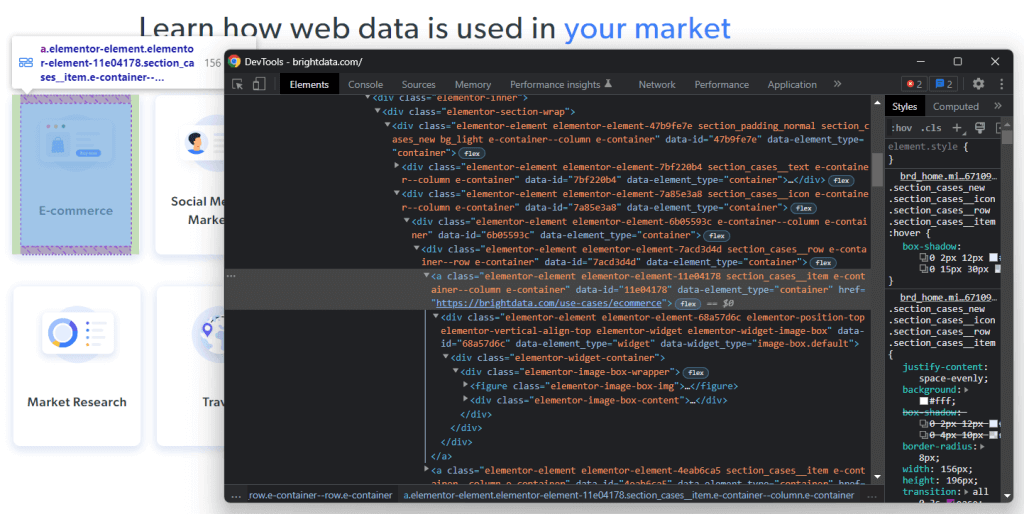
Al analizar el código HTML del nodo seleccionado, verás que la tarjeta es un elemento HTML<a>. En concreto, este <a> contiene:
- Un elemento HTML
<figure>que contiene la imagen asociada al campo del sector. - Un elemento HTML
<div>que contiene el nombre del campo del sector.
Ahora, observa las clases CSS que caracterizan esos elementos HTML. Al utilizarlos, podrás definir los selectores CSS necesarios para seleccionar esos elementos HTML del DOM. En concreto, observa que las tarjetas .e-container se encuentran en el .elementor-element-7a85e3a8 <div>. A continuación, a partir de una tarjeta, puedes extraer todos sus datos relevantes con los siguientes selectores CSS:
.elementor-image-box-img img.elementor-image-box-content .elementor-image-box-title
Del mismo modo, puedes aplicar la misma lógica para definir los selectores de CSS necesarios para:
- Extraer las razones por las que Bright Data es el líder del sector.
- Seleccionar las razones que hacen que la experiencia de cliente que ofrece Bright Data sea la mejor del mercado.
Es decir, la página web de destino tiene tres objetivos de raspado:
- Datos sobre los sectores en los que puedes aprovechar Bright Data.
- Datos sobre las razones por las que Bright Data es el líder del sector.
- Datos sobre por qué Bright Data ofrece la mejor experiencia de cliente del sector.
Paso 5: selecciona elementos HTML con Cheerio
Cheerio ofrece varias formas de seleccionar elementos HTML de una página web. Pero primero, tienes que inicializar Cheerio con:
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)El método Cheerio load() acepta contenido HTML en forma de cadena. Ten en cuenta que el objeto de respuesta de Axios contiene los datos devueltos por la solicitud HTTP en el atributo data. En este caso, data almacenará el código fuente HTML de la página web devuelta por el servidor. Por tanto, pasas axiosResponse.data a load() para inicializar Cheerio.
Debes llamar a la variable Cheerio $ porque Cheerio comparte básicamente la misma sintaxis que jQuery. De esta forma, podrás copiar fragmentos de jQuery de Internet.
Puedes seleccionar un elemento HTML con Cheerio usando su clase con:
const htmlElement = $(".elementClass")Del mismo modo, puedes recuperar un elemento HTML por ID con:
const htmlElement = $("#elementId")En concreto, puedes seleccionar elementos HTML pasando a $ cualquier selector CSS válido, tal como lo harías en jQuery. También puedes concatenar la lógica de selección con el método find():
// retrieving the list of industry cards
const industryCards = $(".elementor-element-7a85e3a8").find(".e-container")find() te da acceso a los descendientes del elemento HTML actual filtrados por un selector de CSS. Luego puedes iterar en una lista de nodos de Cheerio con el método each() de la siguiente manera:
// iterating over the list of industry cards
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// scraping logic...
})Ahora aprenderemos a usar Cheerio para extraer datos de los elementos HTML de interés.
Paso 6: raspa datos de una página web de destino con Cheerio
Puedes ampliar la lógica mostrada anteriormente para extraer los datos deseados de los elementos HTML seleccionados de la siguiente manera:
// initializing the data structure
// that will contain the scraped data
const industries = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})Este fragmento de Node.js de raspado web selecciona todas las tarjetas del sector de la página de inicio de Bright Data. Luego, itera sobre todos los elementos de la tarjeta HTML. Para cada tarjeta, raspa la URL de la página web asociada a la tarjeta, la imagen y el nombre de la industria. Gracias a los métodos attr() y text() de Cheerio, puedes recuperar el valor y el texto del atributo HTML, respectivamente. Por último, almacena los datos raspados en un objeto y los añade a la matriz industries.
Al final del ciclo each(), industries contendrá todos los datos de interés relacionados con el primer objetivo de raspado. Veamos ahora cómo lograr también los otros dos objetivos.
Del mismo modo, puedes raspar los datos para corroborar por qué Bright Data es el líder del sector de la siguiente manera:
const marketLeaderReasons = []
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
marketLeaderReasons.push(marketLeaderReason)
})Por último, puedes recopilar los datos sobre por qué Bright Data ofrece una excelente experiencia al cliente con:
const customerExperienceReasons = []
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
const customerExperienceReason = {
title: title,
description: description,
}
customerExperienceReasons.push(customerExperienceReason)
})¡Enhorabuena! ¡Acabas de aprender a lograr tus tres objetivos de raspado web de Node.js!
Ten en cuenta que puedes raspar datos de otras páginas web siguiendo los enlaces que descubriste en la página actual. En eso consiste el rastreo web. Por lo tanto, también puedes definir una lógica de raspado web para extraer datos de esas páginas.
industries, MarketLeaderReasons y CustomerExperienceReasons almacenarán todos los datos raspados en objetos de JavaScript. Ahora, vamos a aprender a convertirlo a un formato más práctico.
Paso 7: convierte los datos extraídos a JSON
JSON es uno de los mejores formatos de datos en lo que respecta a JavaScript. Esto se debe a que JSON se deriva de JavaScript y es el formato que suele utilizar la API para aceptar o devolver datos. Por tanto, es probable que tengas que convertir tus datos de raspado de JavaScript a JSON. Puedes lograrlo fácilmente con la siguiente lógica:
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)Primero, tienes que crear un objeto de JavaScript que contenga todos los datos raspados. Luego, puedes transformar ese objeto de JavaScript en JSON con JSON.stringify().
scrapedDataJSON contendrá los siguientes datos JSON:
{
"industries": [
{
"url": "https://brightdata.com/use-cases/ecommerce",
"image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "E-commerce"
},
// ...
{
"url": "https://brightdata.com/use-cases/data-for-good",
"image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
],
"marketLeader": [
{
"title": "Most reliable",
"image": "https://brightdata.com/wp-content/uploads/2022/01/reliable.svg",
"description": "Highest quality data, best network uptime, fastest output "
},
// ...
{
"title": "Most efficient",
"image": "https://brightdata.com/wp-content/uploads/2022/01/efficient.svg",
"description": "Minimum in-house resources needed"
}
],
"customerExperience": [
{
"title": "You ask, we develop",
"description": "New feature releases every day"
},
// ...
{
"title": "Tailored solutions",
"description": "To meet your data collection goals"
}
]
}¡Enhorabuena! Empezaste conectándote a un sitio web y ahora puedes raspar sus datos y convertirlos a JSON. Ya estás listo para echar un vistazo al script Node.js completo de raspado web.
Puesta en común
Este es el aspecto del raspador web Node.js:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com/",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)
// initializing the data structures
// that will contain the scraped data
const industries = []
const marketLeaderReasons = []
const customerExperienceReasons = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
// extracting the data of interest
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
// converting the data extracted into a more
// readable object
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
// adding the object containing the scraped data
// to the marketLeaderReasons array
marketLeaderReasons.push(marketLeaderReason)
})
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
// extracting the data of interest
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
// converting the data extracted into a more
// readable object
const customerExperienceReason = {
title: title,
description: description,
}
// adding the object containing the scraped data
// to the customerExperienceReasons array
customerExperienceReasons.push(customerExperienceReason)
})
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)
// storing scrapedDataJSON in a database via an API call...
}
performScraping()Como se muestra aquí, puedes crear un raspador web en Node.js en menos de 100 líneas de código. Con Cheerio y Axios, puedes descargar una página web HTML, analizarla y recuperar automáticamente todos sus datos. Luego, puedes convertir fácilmente los datos raspados a JSON. En eso consiste el raspado web de Node.js.
Lanza tu raspador web en Node.js con:
npm run start¡Ya está! ¡Acabas de aprender a realizar el raspado web de JavaScript en Node.js!
Conclusión
En este tutorial, has visto por qué el raspado web en el frontend con JavaScript es una solución limitada y por qué Node.js es una mejor opción. Además, has visto lo que necesitas para crear un script de raspado web Node.js y cómo raspar datos de la web en JavaScript. Concretamente, has aprendido a usar Cheerio y Axios para crear una aplicación de raspado web de JavaScript en Node.js basada en un ejemplo real. Como has aprendido, el raspado web con Node.js solo requiere unas pocas líneas de código.
Pero ten en cuenta que el raspado web puede no ser tan fácil. Esto se debe a que son muchas las dificultades que puedes tener que afrontar. En concreto, las soluciones antiraspado y antibots son cada vez más comunes. Por suerte, puedes evitar todo esto fácilmente con una herramienta de raspado web avanzada y de última generación proporcionada por Bright Data. ¿No quieres ocuparte del raspado web? Explora nuestros conjuntos de datos.
Si quieres obtener más información sobre cómo evitar que te bloqueen, adopta un proxy web de uno de los servicios de proxy disponibles o empieza a usar nuestro avanzado Web Unlocker.
¿No sabes qué producto elegir? Contacta con el Dpto. de Ventas para encontrar la solución de raspado web adecuada para ti.




