

Esta guía, cubrirá los siguientes temas:
- ¿Qué es Jsoup?
- Requisitos previos
- Cómo construir un raspador web usando Jsoup
- Conclusión
¿Qué es Jsoup?
Jsoup es un analizador HTML de Java. En otras palabras, Jsoup es una librería Java que permite analizar cualquier documento HTML. Con Jsoup, puede analizar un archivo HTML local o descargar un documento HTML remoto desde una URL.
Jsoup también ofrece una amplia gama de métodos para tratar con el DOM. En concreto, puede utilizar selectores CSS y métodos similares a Jquery para seleccionar elementos HTML y extraer datos de ellos. Esto hace de Jsoup una biblioteca Java de raspado web eficaz para principiantes y profesionales.
Tenga en cuenta que Jsoup no es la única biblioteca para realizar raspado web en Java. HtmlUnit es otra popular librería Java de raspado web. Eche un vistazo a nuestra guía de HtmlUnit sobre raspado web en Java.
Requisitos previos
Antes de escribir la primera línea de código, es necesario cumplir los siguientes requisitos previos:
- Java >= 8: cualquier versión de Java mayor o igual a 8 servirá. Se recomienda descargar e instalar una versión LTS (Long Term Support) de Java. En concreto, este tutorial se basa en Java 17. En el momento de escribir estas líneas, Java 17 es la última versión LTS.
- Maven o Gradle: puede elegir la herramienta de automatización de construcción Java que prefiera. Específicamente, necesitarás Maven o Gradle por su funcionalidad de gestión de dependencias.
- Un IDE avanzado que soporte Java: cualquier IDE que soporte Java con Maven o Gradle está bien. Este tutorial se basa en IntelliJ IDEA, que es probablemente el mejor IDE Java disponible.
Siga los enlaces de arriba para descargar e instalar todo lo necesario para cumplir con todos los requisitos previos. En orden, instale Java, Maven o Gradle, y un IDE para Java. Siga las guías de instalación oficiales para evitar problemas y cuestiones comunes.
Verifiquemos ahora que cumple todos los requisitos previos.
Compruebe que Java está configurado correctamente
Abra su terminal. Puede verificar que ha instalado Java y configurado el PATH de Java correctamente con el siguiente comando:
java -versionEste comando debe imprimir algo similar a lo que se muestra a continuación:
java version "17.0.5" 2022-10-18 LTS
Java(TM) SE Runtime Environment (build 17.0.5+9-LTS-191)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.5+9-LTS-191, mixed mode, sharing)Compruebe que Maven o Gradle está instalado
Si ha elegido Maven, ejecute el siguiente comando en su terminal:
mvn -vA continuación, debería recibir información sobre la versión de Maven que ha configurado:
Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63)
Maven home: C:Mavenapache-maven-3.8.6
Java version: 17.0.5, vendor: Oracle Corporation, runtime: C:Program FilesJavajdk-17.0.5
Default locale: en_US, platform encoding: Cp1252
OS name: "windows 11", version: "10.0", arch: "amd64", family: "windows"Si se optó por Gradle, ejecute en su terminal:
gradle -vDe manera similar, esto debería imprimir alguna información sobre la versión de Gradle que se instaló, como a continuación:
------------------------------------------------------------
Gradle 7.5.1
------------------------------------------------------------
Build time: 2022-08-05 21:17:56 UTC
Revision: d1daa0cbf1a0103000b71484e1dbfe096e095918
Kotlin: 1.6.21
Groovy: 3.0.10
Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021
JVM: 17.0.5 (Oracle Corporation 17.0.5+9-LTS-191)
OS: Windows 11 10.0 amd64¡Genial! ¡Ahora puede comenzar a aprender cómo realizar raspado web con Jsoup en Java!
Cómo construir un raspador web usando Jsoup
Aquí, le mostraremos cómo construir un script para raspado web con Jsoup. Este script será capaz de extraer automáticamente los datos de un sitio web. En detalle, el sitio web de destino es Quotes to Scrape. Si no conoce este proyecto, no es más que un sandbox para raspado web.
Este es el aspecto de Quotes to Scrape:

Como puede ver, el sitio web de destino contiene simplemente una lista paginada de citas. El objetivo del raspador web Jsoup es recorrer cada página, recuperar todas las citas y devolver estos datos en formato CSV.
Siga paso a paso este tutorial de Jsoup y aprenda a crear un sencillo raspador web.
Paso 1: Configurar un proyecto Java
Aquí, se mostrará cómo se puede inicializar un proyecto Java en IntelliJ IDEA 2022.2.3. Tenga en cuenta que cualquier otro IDE estará bien. En IntelliJ IDEA, sólo se necesitan un puñado de clics para inicializar un proyecto Java. Inicie IntelliJ IDEA y espere a que se cargue. A continuación, seleccione la opción File > New > Project…en el menú superior.

Ahora, inicialice su proyecto Java en la ventana emergente New Project:

Asigne un nombre y una ubicación a su proyecto, seleccione Java como lenguaje de programación y elija entre Maven o Gradle dependiendo de la herramienta de compilación que haya instalado. Haga clic en el botón Crear y espere a que IntelliJ IDEA inicialice su proyecto Java. Ahora debería mostrarse el siguiente proyecto Java vacío:

Ahora es el momento de instalar Jsoup y empezar a extraer datos de la Web.
Paso 2: Instalar Jsoup
Si es usuario de Maven, añada las siguientes líneas dentro de la etiqueta dependencies de su archivo pom.xml:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>El archivo pom.xml de Maven debería tener el siguiente aspecto:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.brightdata</groupId>
<artifactId>web-scraper-jsoup</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
</dependencies>
</project>Alternativamente, si es usuario de Gradle, añada esta línea al objeto dependencies de su archivo build.gradle:
implementation "org.jsoup:jsoup:1.15.3"Acaba de añadir jsoup a las dependencias de su proyecto. Ahora es el momento de instalarlo. En IntelliJ IDEA, haga clic en el botón de recarga de Gradle/Maven:

Esto instalará la dependencia jsoup. Espere a que finalice el proceso de instalación. Ahora tiene acceso a todas las funciones de Jsoup. Puede verificar que Jsoup se instaló correctamente añadiendo esta línea de importación en la parte superior de su archivo Main.java:
import org.jsoup.*;Si IntelliJ IDEA no informa de ningún error, significa que ya puede utilizar Jsoup en su script Java de raspado web.
Ahora vamos a codificar un raspador web con Jsoup.
Paso 3: Conectarse a la página web de destino
Puede utilizar Jsoup para conectarse a su sitio web de destino en una sola línea de código:
// downloading the target website with an HTTP GET request
Document doc = Jsoup.connect("https://quotes.toscrape.com/").get();Puede conectarse a un sitio web con el método connect() de Jsoup,. Lo que ocurre detrás de escena es que Jsoup realiza una petición HTTP GET a la URL especificada como parámetro, obtiene el documento HTML devuelto por el servidor de destino, y lo almacena en el objeto Document doc de Jsoup.
Considere que si connect() falla, Jsoup lanzará una IOException. Esto puede ocurrir por varias razones. Sin embargo, debe tener en cuenta que muchos sitios web bloquean las peticiones que no incluyen una cabecera User-Agent válida. Si no está familiarizado con esto, la cabecera User-Agent es un valor de cadena que identifica la aplicación y la versión del SO desde la que se origina una petición. Más información sobre User-Agent para raspado web.
Puede especificar una cabecera User-Agent en Jsoup como se indica a continuación:
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();En concreto, el método Jsoup userAgent() permite establecer la cabecera the User-Agent. Considere que puede establecer cualquier otra cabecera HTTP a través del método header().
Su clase Main.java debería tener ahora el siguiente aspecto:
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
}
}Empecemos a analizar la página web objetivo para aprender a extraer datos de ella.
Paso 4: Inspeccionar la página HTML
Si quiere extraer datos de un documento HTML, primero será necesario analizar el código HTML de la página web. En primer lugar, se debe identificar los elementos que contienen los datos que desea extraer. Después, tiene que encontrar la manera de seleccionar estos elementos HTML.
Puede conseguir todo esto a través de las herramientas para desarrolladores de su navegador. En Google Chrome o en cualquier navegador basado en Chromium, haga clic con el botón derecho en un elemento HTML que contenga datos de interés. A continuación, seleccione Inspeccionar.
Esto es lo que debería mostrarse ahora
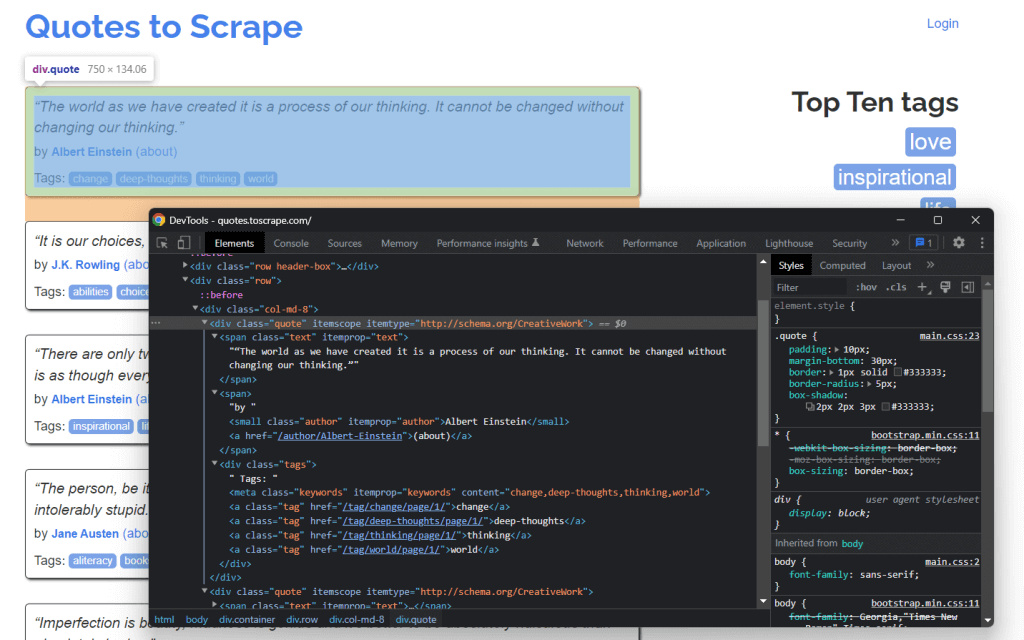
Profundizando en el código HTML, se puede ver que cada cita está envuelta en un elemento HTML <div>. En detalle, este elemento <div> contiene
- Un elemento HTML
<span>que contiene el texto de la cita - Un elemento HTML
<small>que contiene el nombre del autor - Un elemento
<div>con una lista de elementos HTML<a>que contienen las etiquetas asociadas a la cita.
Ahora, observe las clases CSS utilizadas por estos elementos HTML. Gracias a ellas, puede definir los selectores CSS que necesita para extraer esos elementos HTML del DOM. En concreto, puede recuperar todos los datos asociados con una cita aplicando los selectores CSS en .quote que aparecen a continuación:
.text.author.tags .tag
Aprendamos cómo hacerlo en Jsoup
Paso 5: Seleccionar elementos HTML con Jsoup
La clase Document de Jsoup ofrece varias formas de seleccionar elementos HTML del DOM. Veamos las más importantes:
Jsoup permite extraer elementos HTML basándose en sus etiquetas:
// selecting all <div> HTML elements
Elements divs = doc.getElementsByTag("div");Esto devolverá la lista de elementos HTML <div> contenidos en el DOM.
Del mismo modo, puede seleccionar elementos HTML por clase:
// getting the ".quote" HTML element
Elements quotes = doc.getElementsByClass("quote");Si desea recuperar un único elemento HTML basándose en su atributo id, puede utilizar:
// getting the "#quote-1" HTML element
Element div = doc.getElementById("quote-1");También puede seleccionar elementos HTML por un atributo:
// selecting all HTML elements that have the "value" attribute
Elements htmlElements = doc.getElementsByAttribute("value");O que contenga un determinado fragmento de texto:
// selecting all HTML elements that contain the word "for"
Elements htmlElements = doc.getElementsContainingText("for");Estos son sólo algunos ejemplos. Considere que Jsoup viene con más de 20 enfoques diferentes para seleccionar elementos HTML de una página web. Observe todos.
Como hemos aprendido antes, los selectores CSS son una forma eficaz de seleccionar elementos HTML. Puede aplicar un selector CSS para recuperar elementos en Jsoup a través del método select():
// selecting all quote HTML elements
Elements quoteElements = doc.getElementsByClass(".quote");Dado que Elements extiende ArrayList, puede iterar sobre él para obtener cada elemento Element de Jsoup. Considere que puede aplicar todos los métodos de selección HTML también a un único Elemento. Esto restringirá la lógica de selección a los hijos del elemento HTML seleccionado.
Así, puede seleccionar los elementos HTML deseados en cada .quote como se muestra a continuación:
for (Element quoteElement: quoteElements) {
Element text = quoteElement.select(".text").first();
Element author = quoteElement.select(".author").first();
Elements tags = quoteElement.select(".tag");
}Aprendamos ahora a extraer datos de estos elementos HTML.
Paso 6: Extraer datos de una página web con Jsoup
Primero, se necesita una clase Java donde sea posible almacenar los datos extraídos. Cree un archivo Quote.java en el paquete principal e inicialícelo:
package com.brightdata;
package com.brightdata;
public class Quote {
private String text;
private String author;
private String tags;
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
}Ahora, ampliemos el fragmento presentado al final de la sección anterior. Extraiga los datos deseados de los elementos HTML seleccionados y almacénelos en objetos Quote como sigue:
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text()
.replace("“", "")
.replace("”", "");
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A, B, ..., Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}Como cada cita puede tener más de una etiqueta, puede almacenarlas todas en una List Java. A continuación, puede utilizar el método String.join()para reducir la lista de cadenas a una sola cadena. Finalmente, puede almacenar esta quote en el objeto.
Al final del bucle for, quotes almacenará todos los datos de citas extraídos de la página de inicio del sitio web de destino. Pero el sitio web de destino consta de muchas páginas.
Aprendamos a utilizar Jsoup para rastrear un sitio web completo.
Paso 7: Cómo rastrear todo el sitio web con Jsoup
Si mira atentamente la página de inicio de Quotes to Scrape, observará un botón “Next →”. Inspeccione este elemento HTML con las herramientas de desarrollo de su navegador. Haga clic con el botón derecho y seleccione Inspeccionar.
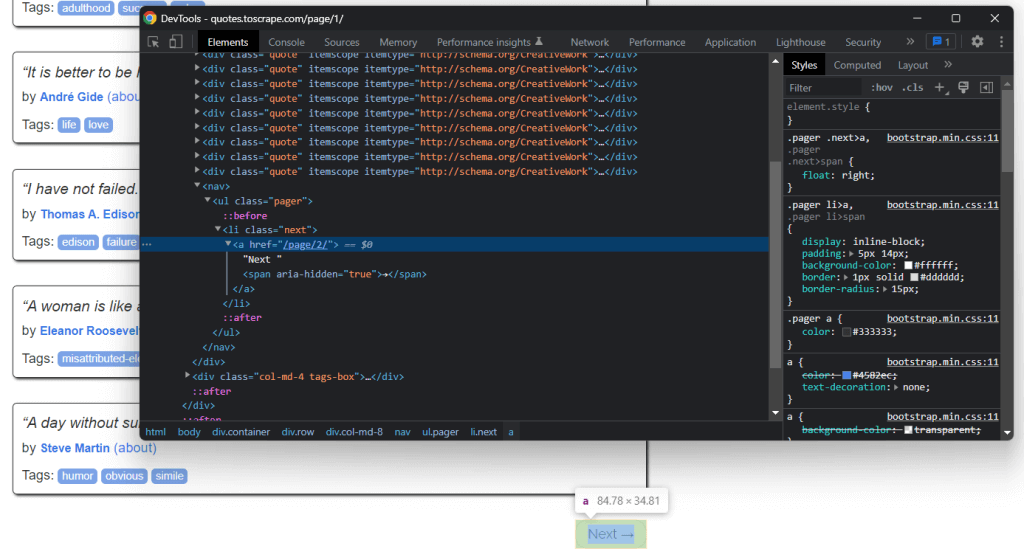
Aquí puede observar que el botón “Next →” es un elemento HTML <li>. Contiene un elemento HTML que almacena la URL relativa a la página siguiente. Observe que puede encontrar el botón en todas las páginas del sitio web de destino, excepto en la última. La mayoría de los sitios web paginados funcionan así.
Al extraer el enlace almacenado en ese elemento HTML, puede obtener la siguiente página a raspar. Por tanto, si se desea raspar datos de todo el sitio web, es necesario seguir la lógica a continuación:
- Buscar el elemento HTML
.next- si está presente, extrae la URL relativa contenida en su hijo
<a>y pasa al punto 2. - Si no está presente, esta es la última página y puedes detenerte aquí.
- si está presente, extrae la URL relativa contenida en su hijo
- Concatenar la URL relativa extraída por el elemento HTML
<a>con la URL base del sitio web. - Utilice la URL completa para conectarse a la nueva página
- Extraiga los datos de la nueva página
- Pasar a 1.
En esto consiste el rastreo web. Puede rastrear un sitio web paginado con Jsoup de la siguiente manera:
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the home page...
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// scraping logic...
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}Como se puede ver, se puede implementar la lógica de rastreo explicada anteriormente con un simple ciclo while. Requiere solo unas cuantas líneas de código. En particular, es necesario seguir un enfoque do ... while.
¡Felicidades! Ahora es capaz de rastrear un sitio entero. Todo lo que queda es aprender a convertir los datos raspados en un formato más útil.
Paso 8: Exportar los datos raspados a CSV
Puede convertir los datos raspados en un archivo CSV de la siguiente manera:
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile)) {
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}Este snippet convierte la quote a formato CSV y la almacena en un archivo output.csv. Como se observa, no se necesita una dependencia adicional para lograrlo. Todo lo que se debe hacer es inicializar un archivo CSV con File. Luego, puede rellenarlo con un PrintWriter imprimiendo cada quote como una fila con formato CSV en el archivo output.csv.
Tenga en cuenta que siempre debe cerrar un PrintWriter cuando ya no lo necesite. En detalle, el try-with-resources anterior asegurará que la instancia PrintWriter se cierre al final de try.
Empezó navegando por un sitio web y ahora puede raspar todos sus datos para almacenarlos en un archivo CSV. Ahora es el momento de echar un vistazo al Jsoup raspador web completo.
Conjuntando todo
Este es el aspecto del script completo de Jsoup en Java:
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect(baseUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text();
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A; B; ...; Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile, StandardCharsets.UTF_8)) {
// to handle BOM
printWriter.write('ufeff');
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}
}
}Como se muestra aquí, puede implementar un raspador web en Java en menos de 100 líneas de código. Gracias a Jsoup, puede conectarse a un sitio web, rastrearlo por completo y extraer automáticamente todos sus datos. A continuación, puede escribir los datos raspados en un archivo CSV. De esto trata este raspador web Jsoup.
En IntelliJ IDEA, ejecute el script de Jsoup haciendo clic en el botón de abajo:

IntelliJ IDEA compilará el archivo Main.java y ejecutará la clase Main. Al final del proceso de raspado, encontrará un archivo output.csv en el directorio raíz del proyecto. Ábralo y debería contener estos datos:
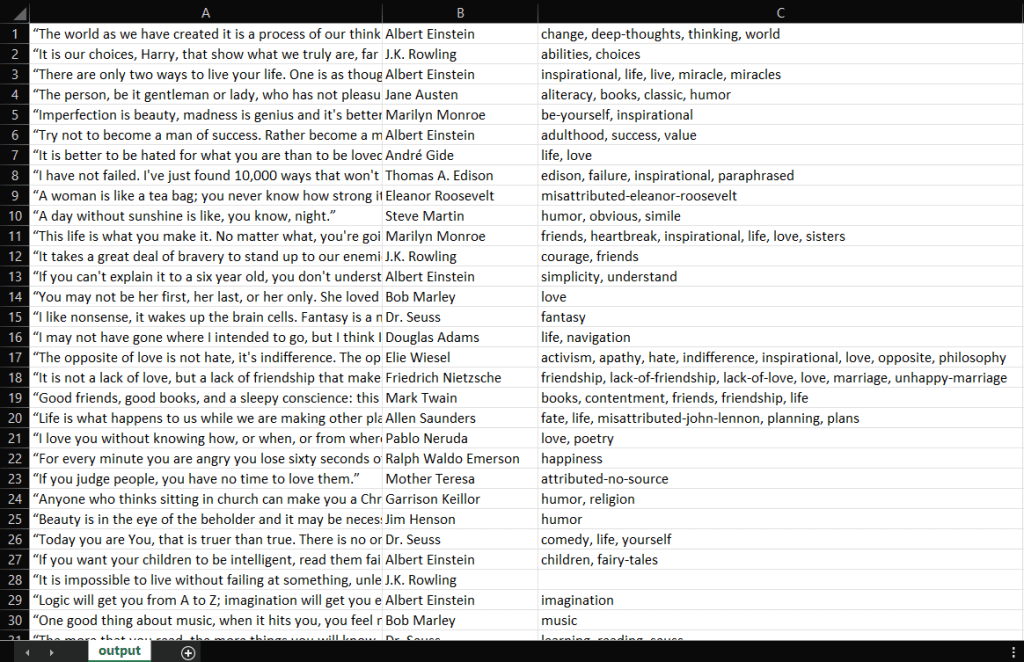
Ya está. Ya tiene un archivo CSV con las 100 citas de Quotes to Scrape. ¡Esto significa que acaba de aprender a construir un raspador web con Jsoup!
Conclusión
En este tutorial, ha aprendido lo que se necesita para empezar a construir un raspador web, qué es Jsoup, y cómo puede usarlo para raspar datos de la Web. En detalle, se mostró cómo utilizar Jsoup para construir una aplicación de raspado web a través de un ejemplo del mundo real. Como se ha demostrado, el raspado web con Jsoup en Java implica sólo un puñado de líneas de código.
Sin embargo, el raspado web no es tan fácil. Esto se debe a que hay varios desafíos que tiene que enfrentar. No olvide que las tecnologías antibot y antiscraping son ahora más populares que nunca. Todo lo que necesita es una herramienta de raspado web potente y con todas las funciones, proporcionada por Bright Data. ¿No quiere ocuparse en absoluto del raspado de datos? Eche un vistazo a nuestros conjuntos de datos.
Si desea obtener más información sobre cómo evitar bloqueos, puede adoptar un proxy basado en su caso de uso de uno de los muchos servicios de proxy disponibles en Bright Data.





