

La extracción de datos web («web scraping»), una técnica de recopilación de datos, suele verse obstaculizada por varios obstáculos, como la prohibición de la propiedad intelectual, el bloqueo geográfico y los problemas de privacidad. Por suerte, los servidores proxy pueden ayudarte a superar estos escollos. Sirven como intermediarios entre tu ordenador e Internet y gestionan las solicitudes con sus propias direcciones IP. Esta funcionalidad no solo ayuda a eludir las restricciones y prohibiciones relacionadas con la IP, sino que además facilita el acceso a contenido restringido geográficamente. Además, los servidores proxy son fundamentales para mantener el anonimato durante la extracción de datos web y proteger tu privacidad.
Utilizar servidores proxy también puede mejorar el rendimiento y la fiabilidad de las tareas de extracción de datos web. Al distribuir las solicitudes entre varios servidores, se aseguran de que ningún servidor soporte una carga excesiva, lo que optimiza el proceso.
En este tutorial, aprenderás a usar un servidor proxy en Node.js para tus proyectos de extracción de datos web.
Requisitos previos
Antes de empezar este tutorial, es recomendable que tengas ciertos conocimientos de JavaScript y Node.js. Si aún no tienes instalado Node.js en tu ordenador, debes instalarlo ahora.
También necesitas un editor de texto apto. Dispones de varias opciones, como Sublime Text. Este tutorial utiliza Visual Studio Code (VS Code). Es fácil de usar y está repleto de funciones que facilitan la codificación.
Para empezar, crea un nuevo directorio llamado web-scraping-proxy y, a continuación, inicializa tu proyecto Node.js. Abre tu terminal o intérprete de comandos («shell») y navega hasta tu nuevo directorio con los siguientes comandos:
cd web-scraping-proxy
npm init -y
A continuación, debes instalar varios paquetes de Node.js para gestionar las solicitudes HTTP y analizar el HTML.
Asegúrate de estar en el directorio de tu proyecto y, a continuación, ejecuta lo siguiente:
npm install axios playwright puppeteer http-proxy-agent
npx playwright install
Axios se usa para realizar solicitudes HTTP a fin de recuperar contenido web. Playwright y Puppeteer automatizan las interacciones del navegador, lo cual es esencial para la extracción de datos de sitios web dinámicos. Playwright es compatible con varios navegadores, mientras que Puppeteer se centra en Chrome o Chromium. Se utilizará la biblioteca http-proxy-agent para crear un agente proxy para las solicitudes HTTP.
El npx playwright install es necesario para instalar los controladores necesarios que utilizará la biblioteca playwright.
Una vez que hayas completado estos pasos, ya podrás sumergirte en el mundo de la extracción de datos web con Node.js.
Configurar un proxy local para la extracción de datos web
Un primer paso esencial en la extracción de datos web es establecer un servidor proxy y, con este tutorial, utilizarás la herramienta de código abierto mitmproxy.
Para empezar, ve a la página de descargas de mitmproxy y descarga la versión 10.1.6 adaptada a tu sistema operativo. Si necesitas ayuda durante la instalación, la guía de instalación de mitmproxy es un recurso práctico.
Tras instalar mitmproxy, ejecútalo introduciendo el siguiente comando en tu terminal:
mitmproxy
Este comando abre una ventana en tu terminal que sirve de interfaz para mitmproxy:
Para asegurarte de que el proxy está configurado correctamente, prueba a ejecutar una prueba. Abre una nueva ventana de terminal y ejecuta el siguiente comando:
curl --proxy http://localhost:8080 "http://wttr.in/Paris?0"
Este comando obtiene el parte meteorológico de París. El resultado debería ser el siguiente:
Weather report: Paris
Overcast
.--. -2(-6) °C
.-( ). ↙ 11 km/h
(___.__)__) 10 km
0.0 mm
Al volver a la ventana de mitmproxy, observarás que ha capturado la petición, lo que indica que tu proxy local funciona correctamente:

Implementa un proxy en Node.js para la extracción de datos web
Ahora es el momento de pasar a las cuestiones prácticas de la extracción de datos web con Node.js. En esta sección, escribirás un script que extrae datos de un sitio web enviando solicitudes a través del servidor proxy local.
Extrae datos de un sitio web con el método Fetch
Crea un nuevo archivo llamado fetchScraping.js en el directorio raíz de tu proyecto. Este archivo contendrá el código para extraer contenido de un sitio web, que en este caso es https://toscrape.com/.
En tu fetchScraping.js, introduce el siguiente código JavaScript. Este script usa el método Fetch para enviar solicitudes a través de tu servidor proxy:
const fetch = require("node-fetch");
const HttpProxyAgent = require("http-proxy-agent");
async function fetchData(url) {
try {
const proxyAgent = new HttpProxyAgent.HttpProxyAgent(
"http://localhost:8080"
);
const response = await fetch(url, { agent: proxyAgent });
const data = await response.text();
console.log(data); // Outputs the fetched data
} catch (error) {
console.error("Error fetching data:", error);
}
}
fetchData("http://toscrape.com/");
Este fragmento de código define una función asincrónica fetchData que toma una URL y envía una solicitud a esa URL mediante Fetch mientras la enruta a través del proxy local. A continuación, imprime los datos de respuesta.
Para ejecutar tu script de extracción de datos web, abre tu terminal o intérprete de comandos («shell») y navega hasta el directorio raíz de tu proyecto, donde se encuentra el archivo fetchScraping.js. Ejecuta el script con este comando:
node fetchScraping.js
Deberías ver el siguiente resultado en el terminal:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Este resultado es el contenido HTML de la página web http://toscrape.com. La visualización correcta de estos datos indica que tu script de extracción de datos web, enrutado a través del proxy local, funciona correctamente.
Ahora, vuelve a la ventana de mitmproxy y verás que la solicitud se ha registrado, lo que significa que tu solicitud pasó por tu proxy local:
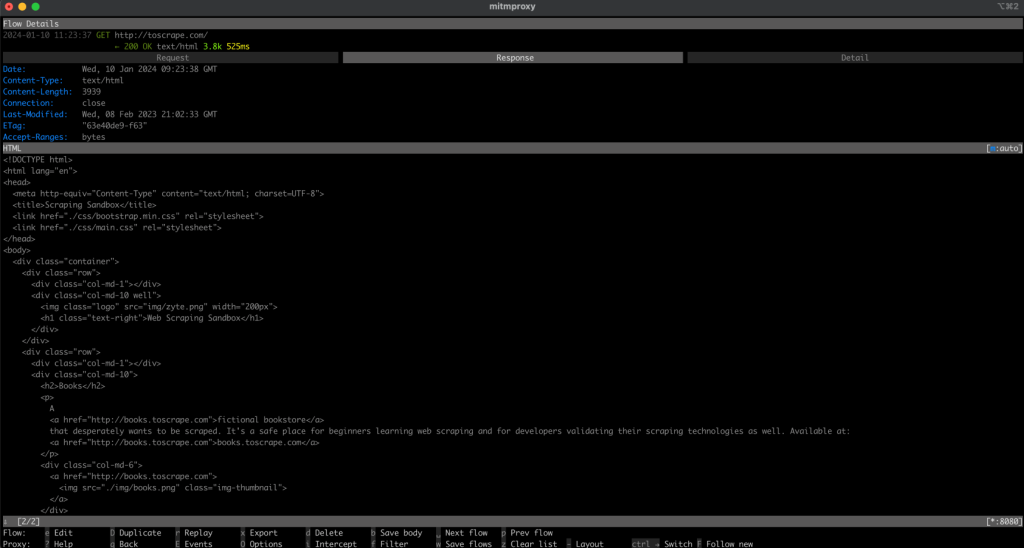
Extrae datos de un sitio web con Playwright
En comparación con Fetch, Playwright es una herramienta avanzada que permite tener interacciones más dinámicas con las páginas web. Para usarlo, debes crear un nuevo archivo llamado playwrightScraping.js en tu proyecto. En este archivo, introduce el siguiente código JavaScript:
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch({
proxy: {
server: "http://localhost:8080",
},
});
const page = await browser.newPage();
await page.goto("http://toscrape.com/");
// Extract and log the entire HTML content
const content = await page.content();
console.log(content);
await browser.close();
})();
Este código usa Playwright para lanzar una instancia del navegador Chromium configurada para usar tu servidor proxy local. A continuación, abre una nueva página en el navegador, navega hasta http://toscrape.com y espera a que se cargue la página. Tras extraer los datos necesarios, el navegador se cerrará.
Para ejecutar este script, asegúrate de estar en el directorio que contiene playwrightScraping.js. Abre tu terminal o intérprete de comandos («shell») y ejecuta el script de la siguiente manera:
node playwrightScraping.js
Cuando ejecutes el script, Playwright iniciará un navegador Chromium, navegará hasta la URL especificada y ejecutará cualquier otro comando de extracción de datos web que hayas añadido. Este proceso utiliza el servidor proxy local, lo que te ayuda a evitar exponer tu dirección IP y a eludir posibles restricciones.
El resultado esperado será similar al anterior:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Como antes, verás que tu petición se registra en la ventana de mitmproxy.
Extrae datos de un sitio web con Puppeteer
A continuación, extrae datos un sitio web con Puppeteer. Puppeteer es una potente herramienta que proporciona un alto nivel de control sobre un navegador Chrome o Chromium sin memoria. Este método es especialmente práctico para extraer datos de sitios web dinámicos que requieren renderizar en JavaScript.
Para empezar, crea un nuevo archivo en tu proyecto llamado puppeteerScraping.js. Este archivo contendrá el código Puppeteer para extraer datos de un sitio web utilizando el servidor proxy para las solicitudes.
Abre el archivo puppeteerScraping.js que acabas de crear e inserta el siguiente código JavaScript:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
args: ['--proxy-server=http://localhost:8080']
});
const page = await browser.newPage();
await page.goto('http://toscrape.com/');
const content = await page.content();
console.log(content); // Outputs the page HTML
await browser.close();
})();
En este código, inicializas Puppeteer para lanzar un navegador sin interfaz y especificas que debe usar tu servidor proxy local. El navegador abre una página nueva, navega hasta http://toscrape.comy, a continuación, recupera el contenido HTML de la página. Una vez que el contenido se haya registrado en la consola, se cierra la sesión del navegador.
Para ejecutar el script, navega hasta la carpeta que contiene puppeteerScraping.js en tu terminal o intérprete de comandos («shell»). Ejecuta el script con el siguiente comando:
node puppeteerScraping.js
Tras ejecutar el script, Puppeteer abre la URL http://toscrape.com/ a través del servidor proxy. Verás el contenido HTML de la página impresa en tu terminal. Esto indica que tu script de Puppeteer extrae datos correctamente la página web a través del proxy local.
Se espera obtener un resultado similar al de los anteriores y verás tu solicitud registrada en la ventana mitmproxy:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Una mejor alternativa: el servidor proxy de Bright Data
Si quieres mejorar tus capacidades de extracción de datos web, prueba a usar Bright Data. El servidor proxy de Bright Data ofrece una solución avanzada para administrar tus solicitudes web.
Bright Data ofrece varios servidores proxy, como proxies residenciales, de ISP, de centros de datos y móviles, que te permiten acceder a cualquier sitio web desde diferentes ubicaciones geográficas. Asimismo, te permite emular diferentes agentes de usuario y mantener el anonimato.
Bright Data también ofrece la rotación de proxies, lo que mejora la eficiencia y el anonimato de tus actividades de extracción de datos web al cambiar automáticamente entre diferentes proxies para evitar que bloqueen tu IP.
Además, puedes usar el navegador Scraping de Bright Data, que es un navegador automático con funciones de desbloqueo integradas de elementos como CAPTCHA, cookies y huellas dactilares del navegador. También puedes aprovechar el Web Unlocker de Bright Data, que incluye algoritmos de aprendizaje automático para evitar bloqueos en los sitios web de destino y te permite recopilar datos sin que te bloqueen.
Implementa Bright Data Proxy en un proyecto de Node.js
Para integrar un proxy de Bright Data en tu proyecto Node.js, debes registrarte para obtener una prueba gratuita. Cuando tu cuenta esté activa, inicia sesión, navega hasta Proxies & Scraping Infrastructure y añade un nuevo proxy seleccionando Residential Proxies:
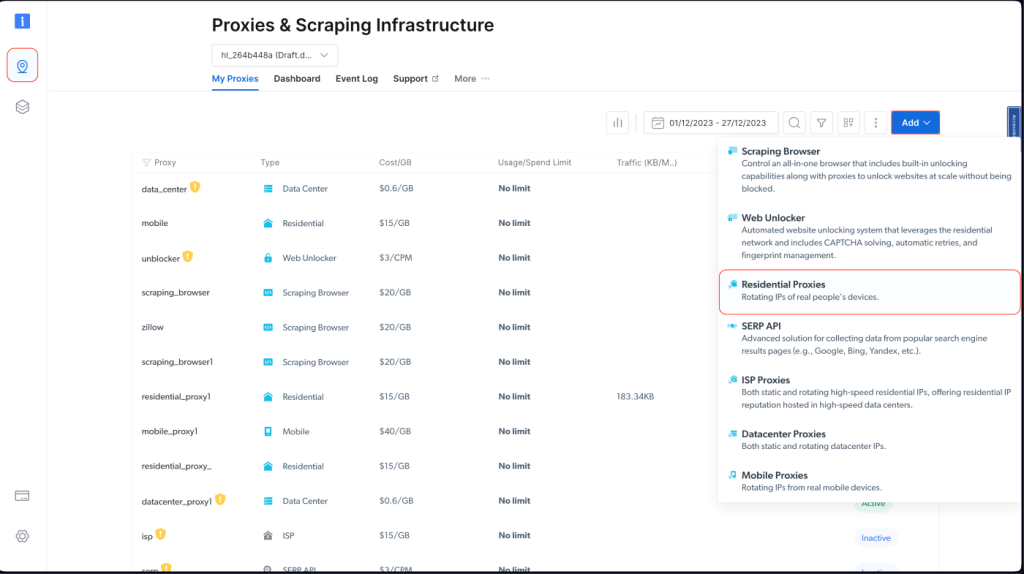
Conserva la configuración predeterminada y finaliza la creación de tu proxy residencial:
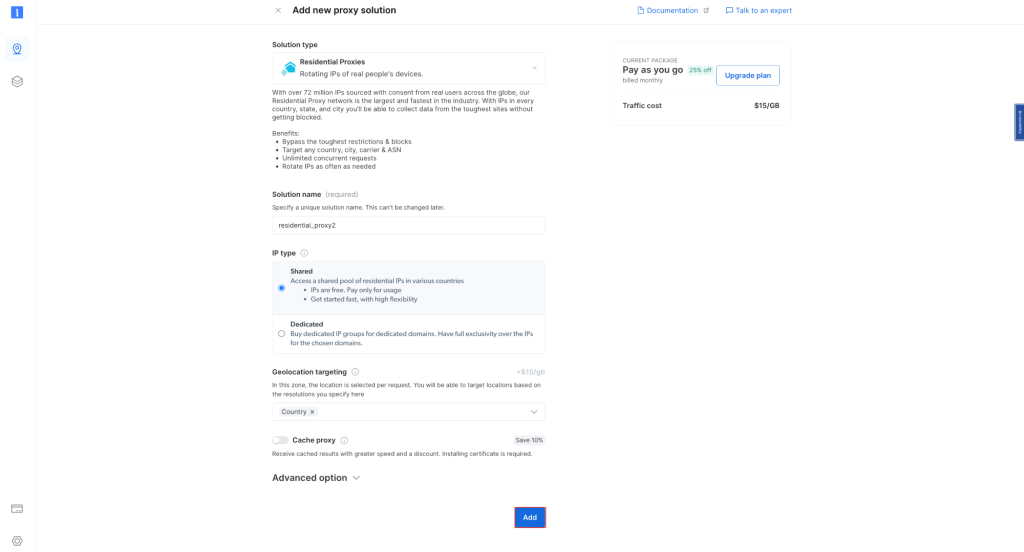
Una vez creado, toma nota de las credenciales del proxy, incluidos el host, el puerto, el nombre de usuario y la contraseña. Las necesitarás en el siguiente paso:
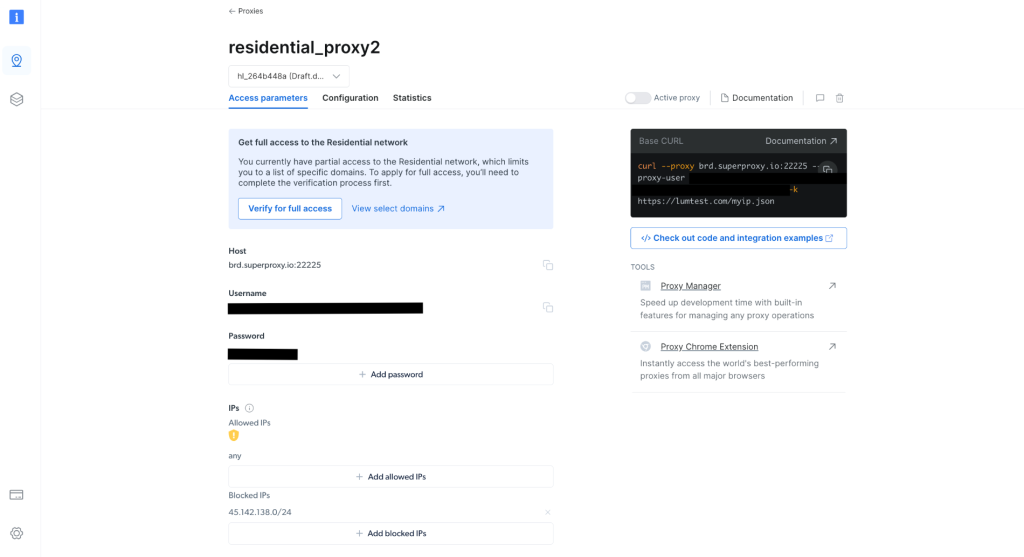
En tu proyecto, crea un archivo scrapingWithBrightData.js y añade el siguiente snippet, asegurándate de reemplazar el texto del marcador de posición por tus credenciales de proxy de Bright Data:
const axios = require('axios');
async function fetchDataWithBrightData(url) {
const proxyOptions = {
proxy: {
host: 'YOUR_BRIGHTDATA_PROXY_HOST',
port: YOUR_BRIGHTDATA_PROXY_PORT,
auth: {
username: 'YOUR_BRIGHTDATA_USERNAME',
password: 'YOUR_BRIGHTDATA_PASSWORD'
}
}
};
try {
const response = await axios.get(url, proxyOptions);
console.log(response.data); // Outputs the fetched data
} catch (error) {
console.error('Error:', error);
}
}
fetchDataWithBrightData('http://lumtest.com/myip.json');
Este script configura axios para enrutar las solicitudes HTTP a través de tu proxy de Bright Data. Obtiene datos de una URL especificada mediante esta configuración de proxy. En este ejemplo, te diriges a http://lumtest.com/myip.json para ver las diferentes fuentes de servidores proxy según tu configuración de Bright Data.
Para ejecutar el script, navega hasta la carpeta que contiene scrapingWithBrightData.js en tu terminal o intérprete de comandos («shell»). A continuación, ejecuta el script con el siguiente comando:
node scrapingWithBrightData.js
Una vez que ejecutes el comando, obtendrás la ubicación de tu dirección IP en la consola, que está relacionada principalmente con el servidor proxy de Bright Data.
El resultado previsto es similar al siguiente:
{
ip: '108.53.191.230',
country: 'US',
asn: { asnum: 701, org_name: 'UUNET' },
geo: {
city: 'Jersey City',
region: 'NJ',
region_name: 'New Jersey',
postal_code: '07302',
latitude: 40.7182,
longitude: -74.0476,
tz: 'America/New_York',
lum_city: 'jerseycity',
lum_region: 'nj'
}
}
A continuación, si vuelves a ejecutar el script con Node.js scrapingWithBrightData.js, observarás que el servidor proxy de Bright Data utiliza una ubicación de dirección IP diferente. Esto confirma que Bright Data utiliza diferentes ubicaciones e IP cada vez que ejecutas tu script de extracción de datos web, lo que te permite eludir cualquier bloqueo o prohibición de IP de los sitios web objetivo.
El resultado será algo así:
{
ip: '93.85.111.202',
country: 'BY',
asn: {
asnum: 6697,
org_name: 'Republican Unitary Telecommunication Enterprise Beltelecom'
},
geo: {
city: 'Orsha',
region: 'VI',
region_name: 'Vitebsk',
postal_code: '211030',
latitude: 54.5081,
longitude: 30.4172,
tz: 'Europe/Minsk',
lum_city: 'orsha',
lum_region: 'vi'
}
}
La interfaz y la configuración sencillas de Bright Data facilitan el uso eficaz de sus potentes funciones de gestión de proxy, incluso para principiantes.
Conclusión
En este artículo, has aprendido a usar proxies con Node.js. Sin soluciones de gestión de proxy adecuadas como Bright Data, es posible que te topes con problemas como prohibiciones de IP y acceso limitado a los sitios web de destino, lo que puede obstaculizar las tareas de extracción de datos web. También has aprendido lo fácil que es usar los proxies de Bright Data para mejorar las tareas de extracción de datos web. Estos servidores no solo aportan solidez y eficacia a tu proceso de recopilación de datos, sino que también brindan la versatilidad requerida para diversos casos de extracción de datos.
Al poner en práctica estas habilidades, recuerda la importancia de operar dentro de los límites de las condiciones del sitio web y las leyes de privacidad de datos. Es fundamental extraer datos de manera responsable, respetando las reglas establecidas por los sitios web. Con los conocimientos que has adquirido, en particular las capacidades que ofrecen los proxies de Bright Data, ya estás listo para realizar una extracción de datos web ética y con éxito. ¡Feliz extracción de datos web!
Todo el código de este tutorial está disponible en este repositorio de GitHub.



