

TL:DR: Vamos a aprender cómo construir un raspador de Yahoo Finanzas con el propósito de extraer datos de valores para realizar análisis financieros para el comercio y la inversión.
Este tutorial cubrirá:
- ¿Por qué raspar datos financieros de la Web?
- Bibliotecas y herramientas de raspado financiero
- Raspado de datos bursátiles de Yahoo Finanzas con Selenium
¿Por qué raspar datos financieros de la Web?
El raspado de datos financieros de la Web ofrece información valiosa que resulta útil en varios escenarios, entre ellos:
- Comercio automatizado: mediante la recopilación de datos de mercado históricos o en tiempo real, como los precios de las acciones y el volumen, los desarrolladores pueden crear estrategias de negociación automatizadas.
- Análisis técnico: los datos e indicadores históricos del mercado son muy importantes para los analistas técnicos. Les permiten identificar patrones y tendencias, lo que les ayuda a tomar decisiones de inversión.
- Modelización financiera: los investigadores y analistas pueden recopilar datos relevantes como estados financieros e indicadores económicos para construir modelos complejos que permitan evaluar el rendimiento de las empresas, prever beneficios y valorar oportunidades de inversión.
- Estudios de mercado: los datos financieros proporcionan gran cantidad de información sobre acciones, índices de mercado y materias primas. El análisis de estos datos ayuda a los investigadores a comprender las tendencias del mercado, el sentimiento y la salud del sector para tomar decisiones de inversión con conocimiento de causa.
Cuando se trata de seguir el mercado, Yahoo Finanzas es uno de los sitios web financieros más populares. Ofrece una amplia gama de información y herramientas a inversores y operadores, como datos históricos y en tiempo real sobre acciones, bonos, fondos de inversión, materias primas, divisas e índices de mercado. Además, ofrece artículos de noticias, estados financieros, estimaciones de analistas, gráficos y otros recursos valiosos.
Al raspar Yahoo Finanzas, puede acceder a una gran cantidad de información para apoyar su análisis financiero, la investigación y los procesos de toma de decisiones.
Bibliotecas y herramientas de raspado financiero
Python se considera uno de los mejores lenguajes para raspado web gracias a su sintaxis, facilidad de uso y ecosistema rico de bibliotecas. Consulte nuestra guía sobre raspado web con Python.
Para elegir las bibliotecas de raspado adecuadas entre las muchas disponibles, explore Yahoo Finanzas en su navegador. Observará que la mayoría de los datos del sitio se actualizan en tiempo real o cambian tras una interacción. Esto significa que el sitio depende en gran medida de AJAX para cargar y actualizar los datos de manera dinámica, sin necesidad de recargar la página. En otras palabras, se requiere una herramienta capaz de ejecutar JavaScript.
Selenium permite raspar sitios web dinámicos en Python. Renderiza el sitio en los navegadores web, realizando programáticamente operaciones en ellos aunque utilicen JavaScript para renderizar o recuperar datos.
Gracias a Selenium, es posible raspar datos del sitio de destino con Python. ¡Veamos cómo!
Raspado de datos bursátiles de Yahoo Finanzas con Selenium
Siga este tutorial paso a paso y aprenda a construir un script Python de raspado web de Yahoo Finance.
Paso 1: Configuración
Antes de sumergirse en el raspado de datos financieros, asegúrese de cumplir con los siguientes requisitos previos:
- Python 3+ instalado en su máquina: Descargue el instalador, haga doble clic en él y siga el asistente de instalación.
- Un IDE de Python de su elección: PyCharm Community Edition o Visual Studio Code con la extensión Python.
A continuación, utilice los siguientes comandos para configurar un proyecto Python con un entorno virtual:
nmkdir yahoo-finance-scraperncd yahoo-finance-scrapernpython -m venv env
Esto inicializará la carpeta del proyecto yahoo-finance-scraper. Dentro de ella, se añade un archivo scraper.py como se indica a continuación:
print('Hello, World!')
Aquí se añadirá la lógica para raspar Yahoo Finanzas. Ahora mismo, es un script de ejemplo que sólo imprime “¡Hola, Mundo!”.
Ejecútelo para verificar que funciona:
python scraper.py
En el terminal, se debe ver:
Hello, World!
Genial, ya tiene un proyecto Python para su raspador de finanzas. Sólo queda añadir las dependencias del proyecto. Instale Selenium y el Webdriver Manager con el siguiente comando de terminal:
pip install selenium webdriver-manager
Esto puede tardar un poco, así que es importante tener paciencia.
webdriver-manager no es estrictamente necesario. Sin embargo, es muy recomendable, ya que hace que la gestión de los controladores web en Selenium sea mucho más fácil. Gracias a él, no es necesario descargar, configurar e importar manualmente el controlador web.
Actualizar scraper.py
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))nn# scraping logic...nn# close the browser and free up the resourcesndriver.quit()
Este script simplemente instanciará una instancia de ChromeWebDriver. Lo utilizaremos próximamente para implementar la lógica de extracción de datos.
Paso 2: Conectarse a la página web de destino
Este es el aspecto de la URL de una página de bolsa de Yahoo Finanzas:
https://finance.yahoo.com/quote/AMZN
Como puede ver, se trata de una URL dinámica que cambia en función del símbolo del ticker. Si no se conoce el concepto, se trata de una abreviatura de cadena que se utiliza para identificar de forma exclusiva las acciones que cotizan en bolsa. Por ejemplo, “AMZN” es el símbolo de las acciones de Amazon.
Modifiquemos el script para que lea el ticker desde un argumento de la línea de comandos.
nimport sysnn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nn# read the ticker from the CLI argumentnticker_symbol = sys.argv[1]nn# build the URL of the target pagenurl = f'https://finance.yahoo.com/quote/{ticker_symbol}'
sys es una biblioteca estándar de Python que proporciona acceso a los argumentos de la línea de comandos. No olvidemos que el argumento con índice 0 es el nombre de nuestro script. Por lo tanto, es necesario tener como objetivo el argumento con el índice 1.
Después de leer el ticker de la CLI, se utiliza en una cadena f para producir la URL de destino para raspar.
Por ejemplo, supongamos que lanzamos el raspador web con el ticker de Tesla “TSLA:”
python scraper.py TSLAn
url contendrá:
https://finance.yahoo.com/quote/TSLA
Si olvida el símbolo del ticker en el CLI, el programa fallará con el siguiente error:
Ticker symbol CLI argument missing!
Antes de abrir cualquier página en Selenium, se recomienda establecer el tamaño de la ventana para asegurarse de que todos los elementos son visibles:
driver.set_window_size(1920, 1080)
Ahora puede usar Selenium para conectarse a la página de destino con:
driver.get(url)
La función get() indica al navegador que visite la página deseada.
Este es el aspecto que tiene hasta ahora su script de raspado de datos financieros de Yahoo:
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernimport sysnn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nn# read the ticker from the CLI argumentnticker_symbol = sys.argv[1]nn# build the URL of the target pagenurl = f'https://finance.yahoo.com/quote/{ticker_symbol}'nn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))n# set up the window size of the controlled browserndriver.set_window_size(1920, 1080)n# visit the target pagendriver.get(url)nn# scraping logic...nn# close the browser and free up the resourcesndriver.quit()
Si se ejecuta, se abrirá esta ventana durante una fracción de segundo antes de terminar:
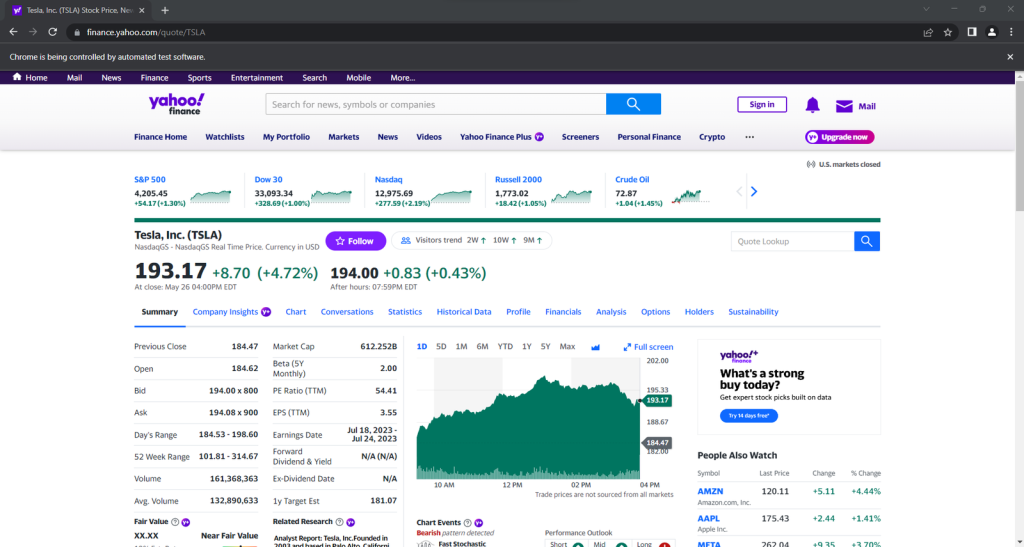
Iniciar el navegador con la interfaz de usuario es útil para la depuración mediante la supervisión de lo que el raspador está haciendo en la página web. Al mismo tiempo, consume muchos recursos. Para evitarlo, hay que configurar Chrome para que se ejecute en modo headless (sin interfaz gráfica) con:
nfrom selenium.webdriver.chrome.options import Optionsn# ...nnoptions = Options()noptions.add_argument('u002du002dheadless=new')nndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)
El navegador controlado se iniciará ahora detrás de la escena, sin interfaz de usuario.
Paso 3: Inspeccionar la página de destino
Si desea estructurar una estrategia de minería de datos eficaz, primero debe analizar la página web de destino. Abra su navegador y visite la página de acciones de Yahoo.
Si se encuentra en Europa, primero verá un modal pidiéndole que acepte las cookies:
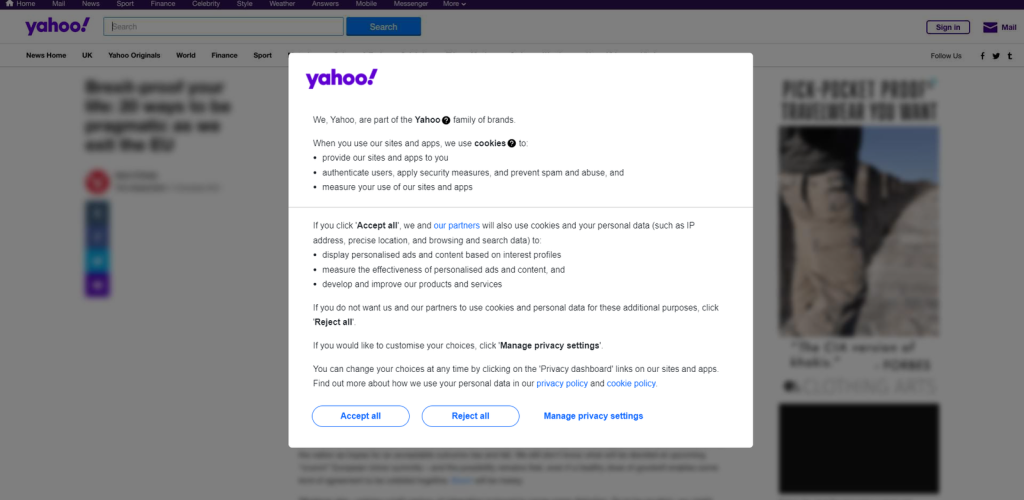
Para cerrarlo y seguir visitando la página deseada, debe hacer clic en “Aceptar todas” o “Rechazar todas”. Haga clic con el botón derecho del ratón en el primer botón y seleccione la opción “Inspeccionar” para abrir las DevTools de su navegador:

Aquí, se observa que se puede seleccionar ese botón con el siguiente selector CSS:
.consent-overlay .accept-all
Utilice estas líneas de hielo para tratar con el modal de consentimiento en Selenium:
ntry:n # wait up to 3 seconds for the consent modal to show upn consent_overlay = WebDriverWait(driver, 3).until(n EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))nn # click the u0022Accept allu0022 buttonn accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')n accept_all_button.click()nexcept TimeoutException:n print('Cookie consent overlay missing')
WebDriverWait permite esperar a que ocurra una condición esperada en la página. Si no ocurre nada en el tiempo de espera especificado, lanza una TimeoutException. Dado que la cookie superpuesta sólo se muestra cuando su IP de salida es europea, puede manejar la excepción con una instrucción try-catch. De esta forma, el script seguirá ejecutándose cuando el modal de consentimiento no esté presente.
Para que el script funcione, deberá añadir las siguientes importaciones:
nfrom selenium.webdriver.support.ui import WebDriverWaitnfrom selenium.webdriver.support import expected_conditions as ECnfrom selenium.webdriver.common.by import Bynfrom selenium.common import TimeoutException
Ahora, siga inspeccionando el sitio de destino en las DevTools y familiarícese con su estructura DOM.
Paso 4: Extraer los datos de stock
Como habrá notado en el paso anterior, parte de la información más interesante se encuentra en esta sección:
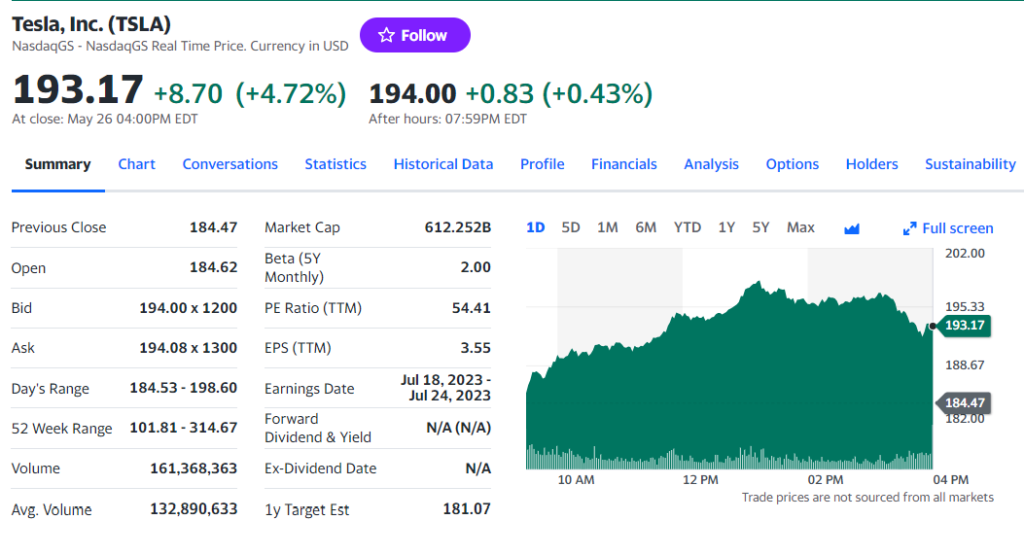
Inspeccione el elemento HTML indicador de precios:
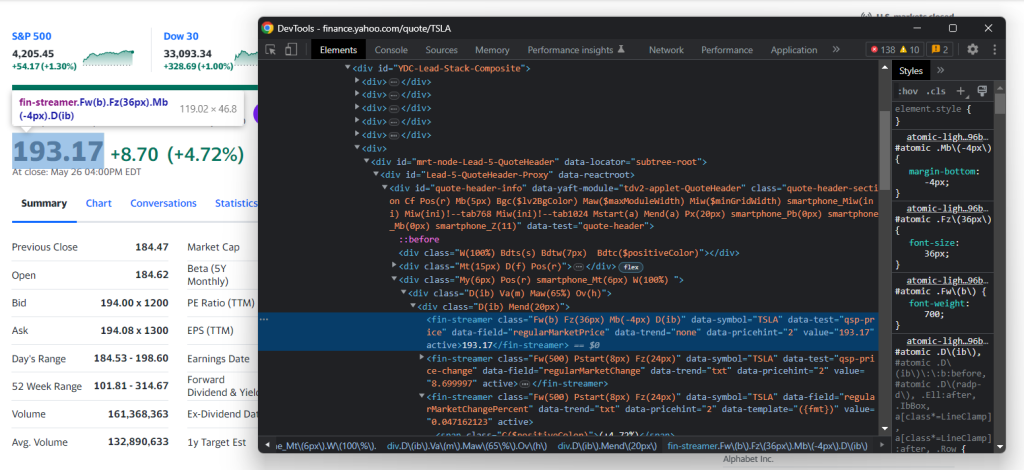
Tenga en cuenta que las clases CSS no son útiles para definir selectores adecuados en Yahoo Finanzas. Parecen seguir una sintaxis especial para un marco de estilo. En su lugar, céntrese en los demás atributos HTML. Por ejemplo, puede obtener el precio de las acciones con el selector CSS siguiente:
[data-symbol=u0022TSLAu0022][data-field=u0022regularMarketPriceu0022]
Siguiendo un enfoque similar, extraiga todos los datos bursátiles de los indicadores de precios con:
nregular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketPriceu0022]')
.textnregular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangeu0022]')
.textnregular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangePercentu0022]')
.text
.replace('(', '').replace(')', '')n npost_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketPriceu0022]')
.textnpost_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangeu0022]')
.textnpost_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangePercentu0022]')
.text
.replace('(', '').replace(')', '')n
Después de seleccionar un elemento HTML mediante la estrategia específica del selector CSS, puede extraer su contenido con el campo de texto. Dado que los campos de porcentaje implican paréntesis redondos, éstos se eliminan con replace().
Se añaden a un diccionario de valores stock y se imprimen para verificar que el proceso de raspado de datos financieros funciona como se espera:
n# initialize the dictionarynstock = {}nn# stock price scraping logic omitted for brevity...nn# add the scraped data to the dictionarynstock['regular_market_price'] = regular_market_pricenstock['regular_market_change'] = regular_market_changenstock['regular_market_change_percent'] = regular_market_change_percentnstock['post_market_price'] = post_market_pricenstock['post_market_change'] = post_market_changenstock['post_market_change_percent'] = post_market_change_percentnnprint(stock)
Ejecute el script en el valor que desea raspar y debería ver algo como:
{'regular_market_price': '193.17', 'regular_market_change': '+8.70', 'regular_market_change_percent': '+4.72%', 'post_market_price': '194.00', 'post_market_change': '+0.83', 'post_market_change_percent': '+0.43%'}
Puede encontrar más información útil en la tabla #quote-summary:
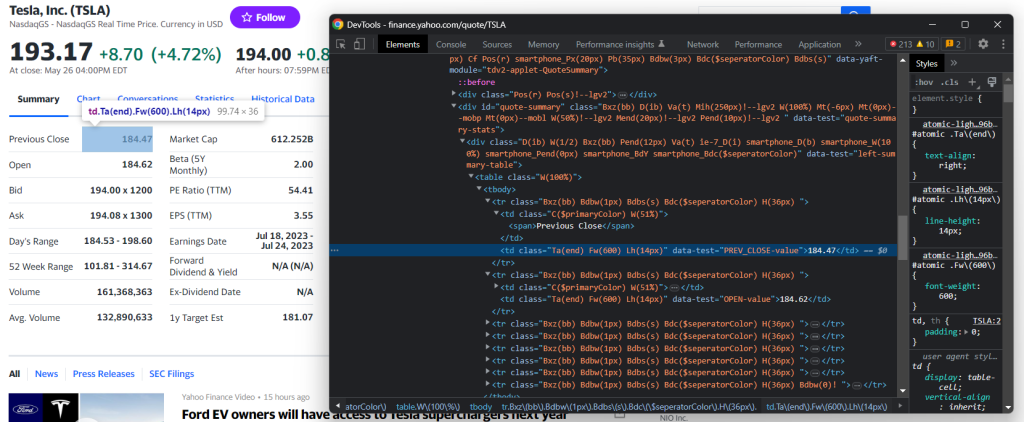
En este caso, se puede extraer cada campo de datos gracias al atributo data-test como en el selector CSS de abajo:
#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]
Raspe todos ellos con:
nprevious_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]').textnopen_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022OPEN-valueu0022]').textnbid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BID-valueu0022]').textnask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ASK-valueu0022]').textndays_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DAYS_RANGE-valueu0022]').textnweek_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022FIFTY_TWO_WK_RANGE-valueu0022]').textnvolume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022TD_VOLUME-valueu0022]').textnavg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022AVERAGE_VOLUME_3MONTH-valueu0022]').textnmarket_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022MARKET_CAP-valueu0022]').textnbeta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BETA_5Y-valueu0022]').textnpe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PE_RATIO-valueu0022]').textneps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EPS_RATIO-valueu0022]').textnearnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EARNINGS_DATE-valueu0022]').textndividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DIVIDEND_AND_YIELD-valueu0022]').textnex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EX_DIVIDEND_DATE-valueu0022]').textnyear_target_est = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ONE_YEAR_TARGET_PRICE-valueu0022]').text
A continuación, se añaden al inventario (stock):
nstock['previous_close'] = previous_closenstock['open_value'] = open_valuenstock['bid'] = bidnstock['ask'] = asknstock['days_range'] = days_rangenstock['week_range'] = week_rangenstock['volume'] = volumenstock['avg_volume'] = avg_volumenstock['market_cap'] = market_capnstock['beta'] = betanstock['pe_ratio'] = pe_rationstock['eps'] = epsnstock['earnings_date'] = earnings_datenstock['dividend_yield'] = dividend_yieldnstock['ex_dividend_date'] = ex_dividend_datenstock['year_target_est'] = year_target_est
¡Fantástico! ¡Realizó raspado financiero de la web con Python!
Paso 5: Raspar diversos valores
Una cartera de inversión diversificada consta de más de un valor. Para recuperar los datos de todos ellos, es necesario ampliar el script para raspar múltiples tickers.
En primer lugar, encapsule la lógica de raspado en una función:
ndef scrape_stock(driver, ticker_symbol):n url = f'https://finance.yahoo.com/quote/{ticker_symbol}'n driver.get(url)nn # deal with the consent modal...nn # initialize the stock dictionary with then # ticker symboln stock = { 'ticker': ticker_symbol }nn # scraping the desired data and populate n # the stock dictionary...nn return stock
A continuación, itere sobre los argumentos del ticker CLI y aplique la función de raspado:
nif len(sys.argv) u003c= 1:n print('Ticker symbol CLI arguments missing!')n sys.exit(2)nn# initialize a Chrome instance with the rightn# configsnoptions = Options()noptions.add_argument('u002du002dheadless=new')ndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)ndriver.set_window_size(1150, 1000)nn# the array containing all scraped datanstocks = []nn# scraping all market securitiesnfor ticker_symbol in sys.argv[1:]:n stocks.append(scrape_stock(driver, ticker_symbol))
Al final del ciclo for, la lista de diccionarios Python stocks contendrá todos los datos bursátiles.
Paso 6: Exportar los datos raspados a CSV
Es posible exportar los datos recopilados a CSV con unas pocas líneas de código:
nimport csvnn# ...nn# extract the name of the dictionary fieldsn# to use it as the header of the output CSV filencsv_header = stocks[0].keys()nn# export the scraped data to CSVnwith open('stocks.csv', 'w', newline='') as output_file:n dict_writer = csv.DictWriter(output_file, csv_header)n dict_writer.writeheader()n dict_writer.writerows(stocks)
Este fragmento crea un archivo stocks.csv con open(), lo inicializa con una fila de encabezado y lo rellena. En concreto, DictWriter.writerows() convierte cada diccionario en un registro CSV y lo añade al archivo de salida.
Dado que csv proviene de Python Standard Library, ni siquiera es necesario instalar una dependencia adicional para lograr el objetivo deseado.
Ha partido de datos brutos contenidos en una página web y tiene datos semiestructurados almacenados en un archivo CSV. Es hora de echar un vistazo a todo el raspador de Yahoo Finanzas.
Paso 7: Conjuntarlo todo
Aquí está el archivo scraper.py completo:
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernfrom selenium.webdriver.chrome.options import Optionsnfrom selenium.webdriver.support.ui import WebDriverWaitnfrom selenium.webdriver.support import expected_conditions as ECnfrom selenium.webdriver.common.by import Bynfrom selenium.common import TimeoutExceptionnimport sysnimport csvnndef scrape_stock(driver, ticker_symbol):n # build the URL of the target pagen url = f'https://finance.yahoo.com/quote/{ticker_symbol}'nn # visit the target pagen driver.get(url)nn try:n # wait up to 3 seconds for the consent modal to show upn consent_overlay = WebDriverWait(driver, 3).until(n EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))nn # click the 'Accept all' buttonn accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')n accept_all_button.click()n except TimeoutException:n print('Cookie consent overlay missing')nn # initialize the dictionary that will containn # the data collected from the target pagen stock = { 'ticker': ticker_symbol }nn # scraping the stock data from the price indicatorsn regular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketPriceu0022]')
.textn regular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangeu0022]')
.textn regular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangePercentu0022]')
.text
.replace('(', '').replace(')', '')nn post_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketPriceu0022]')
.textn post_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangeu0022]')
.textn post_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangePercentu0022]')
.text
.replace('(', '').replace(')', '')nn stock['regular_market_price'] = regular_market_pricen stock['regular_market_change'] = regular_market_changen stock['regular_market_change_percent'] = regular_market_change_percentn stock['post_market_price'] = post_market_pricen stock['post_market_change'] = post_market_changen stock['post_market_change_percent'] = post_market_change_percentnn # scraping the stock data from the u0022Summaryu0022 tablen previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]').textn open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022OPEN-valueu0022]').textn bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BID-valueu0022]').textn ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ASK-valueu0022]').textn days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DAYS_RANGE-valueu0022]').textn week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022FIFTY_TWO_WK_RANGE-valueu0022]').textn volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022TD_VOLUME-valueu0022]').textn avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022AVERAGE_VOLUME_3MONTH-valueu0022]').textn market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022MARKET_CAP-valueu0022]').textn beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BETA_5Y-valueu0022]').textn pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PE_RATIO-valueu0022]').textn eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EPS_RATIO-valueu0022]').textn earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EARNINGS_DATE-valueu0022]').textn dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DIVIDEND_AND_YIELD-valueu0022]').textn ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EX_DIVIDEND_DATE-valueu0022]').textn year_target_est = driver.find_element(By.CSS_SELECTOR,n '#quote-summary [data-test=u0022ONE_YEAR_TARGET_PRICE-valueu0022]').textnn stock['previous_close'] = previous_closen stock['open_value'] = open_valuen stock['bid'] = bidn stock['ask'] = askn stock['days_range'] = days_rangen stock['week_range'] = week_rangen stock['volume'] = volumen stock['avg_volume'] = avg_volumen stock['market_cap'] = market_capn stock['beta'] = betan stock['pe_ratio'] = pe_ration stock['eps'] = epsn stock['earnings_date'] = earnings_daten stock['dividend_yield'] = dividend_yieldn stock['ex_dividend_date'] = ex_dividend_daten stock['year_target_est'] = year_target_estnn return stocknn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nnoptions = Options()noptions.add_argument('u002du002dheadless=new')nn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)nn# set up the window size of the controlled browserndriver.set_window_size(1150, 1000)nn# the array containing all scraped datanstocks = []nn# scraping all market securitiesnfor ticker_symbol in sys.argv[1:]:n stocks.append(scrape_stock(driver, ticker_symbol))nn# close the browser and free up the resourcesndriver.quit()nn# extract the name of the dictionary fieldsn# to use it as the header of the output CSV filencsv_header = stocks[0].keys()nn# export the scraped data to CSVnwith open('stocks.csv', 'w', newline='') as output_file:n dict_writer = csv.DictWriter(output_file, csv_header)n dict_writer.writeheader()n dict_writer.writerows(stocks)
En menos de 150 líneas de código, ha construido un raspador web con todas las funciones para recuperar datos de Yahoo Finanzas.
Ejecútelo contra sus acciones objetivo como en el ejemplo siguiente:
python scraper.py TSLA AMZN AAPL META NFLX GOOG
Al final del proceso de raspado, este archivo stocks.csv aparecerá en la carpeta raíz de su proyecto:

Conclusión
En este tutorial, hemos demostrado por qué Yahoo Finanzas es uno de los mejores portales financieros de la web y cómo extraer datos de él. En particular, abordamos cómo construir un raspador de Python que puede recuperar datos de valores de la misma. Como se muestra aquí, no es complejo y sólo requiere unas pocas líneas de código.
Al mismo tiempo, Yahoo Finanzas es un sitio dinámico que depende en gran medida de JavaScript. Cuando se trata de este tipo de sitios, un enfoque tradicional basado en una biblioteca HTTP y un analizador HTML no es suficiente. Además, estos sitios tan populares suelen aplicar tecnologías avanzadas de protección de datos. Para rasparlos necesita un navegador controlable que sea capaz de gestionar automáticamente CAPTCHAs, huellas digitales, reintentos automáticos y mucho más por usted. Esto es exactamente lo que hace nuestra nueva solución, Scraping Browser.
¿No quiere ocuparse en absoluto del raspado web pero le interesan los datos financieros? Explore nuestro mercado de conjuntos de datos.





