

Resumiendo: este tutorial mostrará cómo extraer datos de un sitio web en C++ y por qué es uno de los lenguajes más eficaces para el raspado web.
Esta guía cubrirá:
- ¿Es C++ un buen lenguaje para el raspado web?
- Las mejores bibliotecas de raspado web de C++
- Cómo crear un raspador web en C++
¿Es C++ un buen lenguaje para el raspado web?
C++ es un lenguaje de programación de tipado estático que se usa ampliamente para desarrollar aplicaciones de alto rendimiento. Esto se debe a que es bien conocido por su velocidad, eficiencia y capacidades de administración de memoria. C++ es un lenguaje versátil que resulta útil en una amplia gama de usos, incluido el raspado web.
C++ es un lenguaje compilado y es intrínsecamente más rápido que los lenguajes interpretados, como Python. Esto lo convierte en una excelente opción para crear raspadores rápidos. Sin embargo, C++ no está diseñado para el desarrollo web y no hay muchas bibliotecas disponibles para el raspado web. Si bien hay algunos paquetes de terceros, las opciones no son tan amplias como en Python, Ruby o Java.
En resumen, el raspado web en C++ es posible y eficiente, pero requiere más programación de bajo nivel en comparación con otros lenguajes. ¡Averigüemos qué herramientas pueden facilitar este proceso!
Las mejores bibliotecas de raspado web de C++
Estas son algunas bibliotecas populares de raspado web para C++:
- CPR: una biblioteca de cliente HTTP moderna de C++ inspirada en el proyecto Python Requests. Es un envoltorio de libcurl que proporciona una interfaz fácil de entender, capacidades de autenticación integradas y soporte para llamadas asincrónicas.
- libxml2: una biblioteca potente y con todas las funciones para analizar documentos XML y HTML desarrollada originalmente para Gnome. Es compatible con la manipulación del DOM mediante selectores XPath.
- Lexbor: una biblioteca de análisis de HTML rápida y ligera escrita completamente en C con soporte para selectores CSS. Solo está disponible para Linux.
Durante años, el analizador de HTML más utilizado para C++ fue Gumbo. Esto no se ha mantenido desde 2016 e incluso el archivo LÉAME oficial ahora desaconseja su uso.
Requisitos previos
Antes de sumergirte en la programación, debes:
Sigue la guía que aparece a continuación para tu sistema operativo y aprende a cumplir esos requisitos previos.
Configurar C++ en macOS
En macOS, el compilador de C, C++ y Objective-C más popular es Clang. Ten en cuenta que muchos Mac vienen con Clang preinstalado. Para verificarlo, abre una terminal y ejecuta el siguiente comando:
clang --version
Si recibes el error command not found: clang, significa que Clang no está instalado o configurado correctamente. En ese caso, puedes instalarlo mediante las herramientas de línea de comandos de Xcode:
xcode-select --install
Esto puede llevar un tiempo, así que ten paciencia.
Para configurar vcpkg, primero necesitarás las herramientas de desarrollo de macOS. Añádelas a tu Mac con:
xcode-select --install
Después, debes instalar vcpkg de forma global. Crea una carpeta /dev, introdúcela en la terminal y ejecuta:
git clone https://github.com/microsoft/vcpkg
El directorio ahora contendrá el código fuente. Crea el administrador de paquetes con:
./vcpkg/bootstrap-vcpkg.sh
Para ejecutar este comando, es posible que necesites privilegios elevados.
Por último, añade /dev/vcpkg a tu $PATH siguiendo esta guía.
Para instalar CMake, descarga el instalador del sitio oficial, ejecútalo y sigue las instrucciones del asistente de instalación.
Configurar C++ en Windows
Descarga el instalador MinGW-x64 desde MSYS2, ejecútalo y sigue las instrucciones. Este paquete proporciona compilaciones nativas actualizadas de GCC, Mingw-w64 y otras herramientas y bibliotecas útiles de C++.
En la terminal MSYS2 abierta al final del proceso de instalación, ejecuta el siguiente comando para instalar la cadena de herramientas Mingw-w64:
pacman -S --needed base-devel mingw-w64-x86_64-toolchain
Espera a que finalice el proceso y, a continuación, añade MinGW al entorno PATH, como se explica aquí.
A continuación, debes instalar vcpkg de forma global. Crea una carpeta C:/dev, ábrela en PowerShell y ejecuta:
git clone https://github.com/microsoft/vcpkg
Crea el código fuente del administrador de paquetes contenido en la subcarpeta vcpkg con:
./vcpkg/bootstrap-vcpkg.bat
Ahora, añade C:/dev/vcpkg a tu PATH como lo hiciste antes.
Solo queda instalar CMake. Descarga el instalador, haz doble clic en él y asegúrate de marcar la siguiente opción durante la configuración.

Configurar C++ en Linux
En distribuciones basadas en Debian, instala GCC (GNU Compiler Collection), CMake y otros paquetes útiles para el desarrollo con:
sudo apt install build-essential cmake
Esto puede llevar algún tiempo, así que ten paciencia.
A continuación, debes instalar vcpkg de forma global. Crea un directorio /dev, ábrelo en la terminal y escribe:
git clone https://github.com/microsoft/vcpkg
El subdirectorio vcpkg ahora contendrá el código fuente del administrador de paquetes. Crea la herramienta con:
./vcpkg/bootstrap-vcpkg.sh
Ten en cuenta que este comando puede requerir privilegios de administrador.
A continuación, añade /dev/vcpkg a tu variable de entorno $PATH siguiendo esta guía.
¡Perfecto! ¡Ahora tienes todo lo que necesitas para empezar con el raspado web en C++!
Cómo crear un raspador web en C++
En este capítulo, aprenderás a programar una araña web en C++. El sitio de destino será la página de inicio de Bright Data y la secuencia de comandos se ocupará de:
- Conexión a la página web
- Selección de los elementos HTML de interés del DOM
- Recuperar datos de ellos
- Exportación de los datos extraídos a CSV
En este momento, esto es lo que ven los visitantes cuando exploran la página de destino:

Recuerda que la página de inicio de BrightData cambia con frecuencia. Por lo tanto, es posible que haya cambiado cuando leas este artículo.
Algunos datos interesantes que se pueden extraer de la página son la información sobre la industria contenida en estas tarjetas:
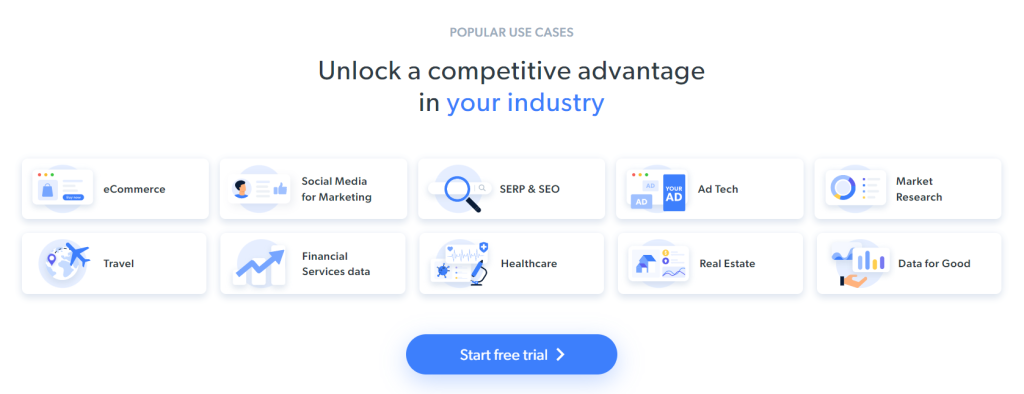
Se ha definido el objetivo de raspado de este tutorial paso a paso. ¡Veamos cómo hacer raspado web con C++!
Paso 1: iniciar un proyecto de raspado de C++
Primero, necesitas una carpeta donde colocar tu proyecto de C++. Abre la terminal y crea el directorio del proyecto con:
mkdir c++-web-scraper
Esto contendrá tu secuencia de comandos de raspado.
Al crear software en C++, debes optar por un IDE de Visual Studio. En detalle, estás a punto de ver cómo configurar Visual Studio Code (VS Code) para el desarrollo en C++ con vcpkg como administrador de paquetes. Ten en cuenta que se pueden aplicar procedimientos similares a otros IDE de C++.
VS Code no ofrece soporte integrado para C++, por lo que primero debes añadir el complemento C/C++. Ejecuta Visual Studio Code, haz clic en el icono «Extensiones» de la barra izquierda y escribe «C++» en el campo de búsqueda de la parte superior.
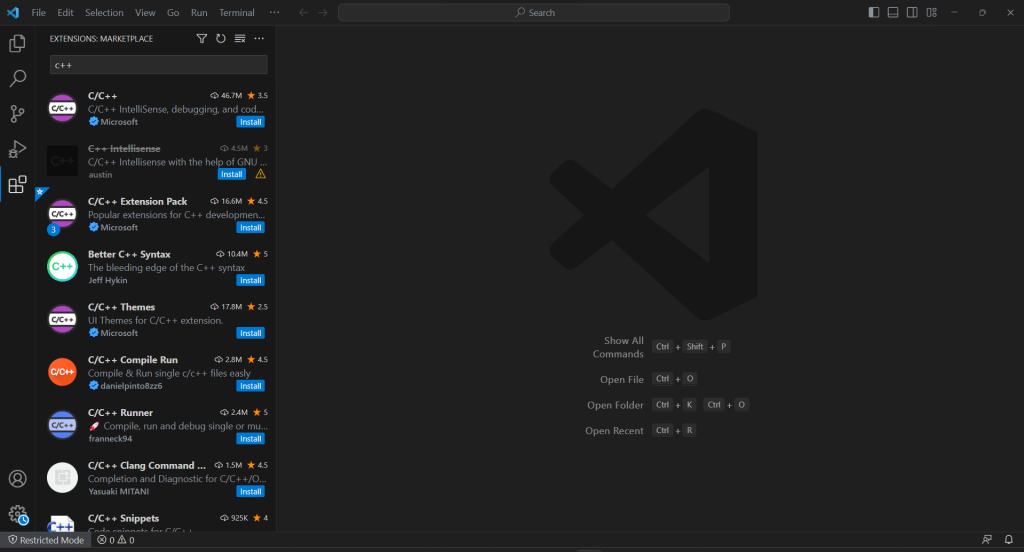
Haz clic en el botón «Instalar» del primer elemento para añadir la funcionalidad de desarrollo de C++ a VS Code. Espera a que la extensión esté configurada y abre la carpeta c++-web-scraper con "``File``" > "``Open Folder...``".
Haz clic con el botón derecho en la sección «EXPLORADOR», selecciona «Nuevo archivo…» e inicia un archivo scraper.cpp de la siguiente manera:
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}
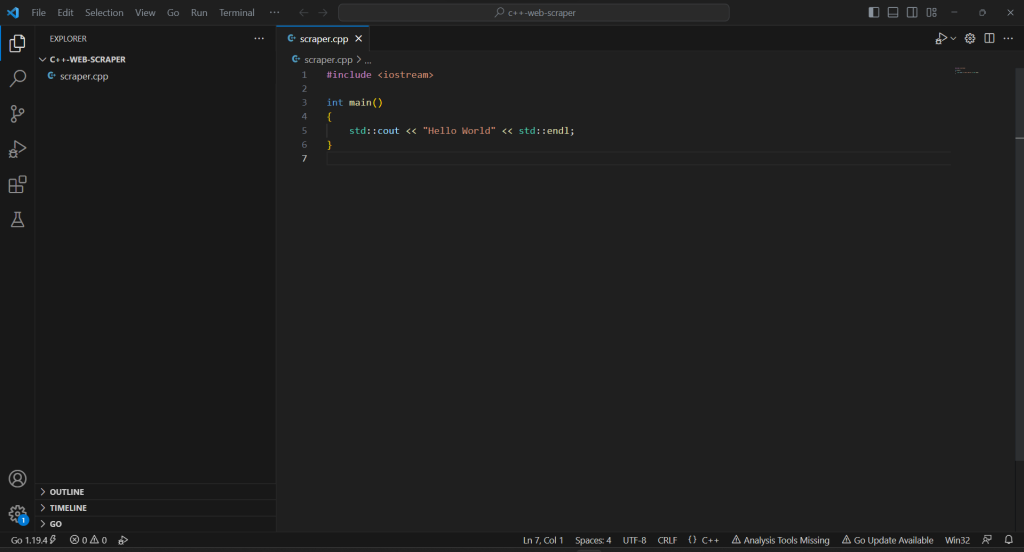
¡Ahora tienes un proyecto de C++!
Paso 2: instalar las bibliotecas de raspado
La complicada sintaxis de C++ y sus limitadas capacidades web pueden ser un obstáculo a la hora de crear un raspador web. Para que todo sea más fácil, deberías aprovechar algunas bibliotecas de C++ de raspado web. Como se mencionó anteriormente, la elección es bastante limitada. Por lo tanto, deberías elegir las más populares: cpr y libxml2.
Puedes instalarlas en Windows a través de vcpkg con:
vcpkg install cpr libxml2 --triplet=x64-windows
En macOS, reemplaza la opción de tripletas por x64-osx. En Linux, utiliza x64-linux.
En la terminal de Visual Studio Code, también debes ejecutar el siguiente comando en el directorio raíz de tu proyecto:
vcpkg integrate install
Esto permitirá vincular los paquetes vcpkg al proyecto.
Reinicia VS Code y ahora podrás importar cualquier biblioteca instalada con #include. Por lo tanto, añade las siguientes tres líneas en la parte superior de tu archivo scraper.cpp:
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
Asegúrate de que el IDE no notifique ningún error.
Paso 3: finalizar la inicialización del proyecto en C++
Para crear la secuencia de comandos de raspado de C++ y completar el proceso de inicialización del proyecto, debes añadir la extensión CMake Tools a VS Code:
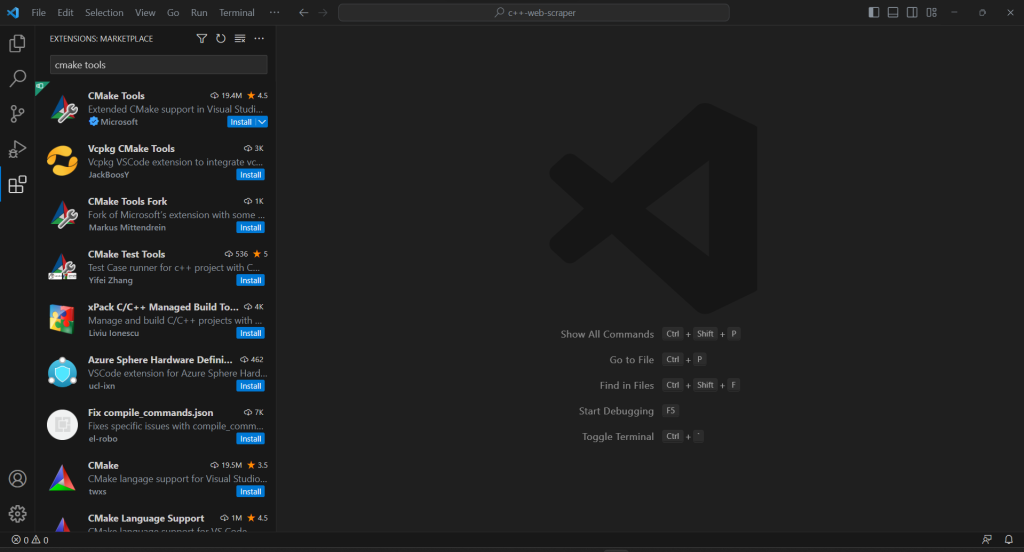
Si tu proyecto no tiene una carpeta .vscode, créala. Ahí es donde VS Code busca configuraciones relacionadas con el proyecto actual.
Configura CMake Tools para que use vcpkg como una cadena de herramientas creando un archivo settings.json dentro de la carpeta .vscode de la siguiente manera:
{
"cmake.configureSettings": {
"CMAKE_TOOLCHAIN_FILE": "c:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake"
}
}
En macOS y Linux, corrige el campo CMAKE_TOOLCHAIN_FILE de acuerdo con la ruta en la que instalaste vcpkg. Si has seguido la guía de configuración anterior, debería ser /dev/vcpkg/scripts/buildsystems/vcpkg.cmake.
En la barra de búsqueda principal de VS Code, escribe «>cmake» y selecciona la opción «CMake: Configurar»:

Esto te permitirá seleccionar la plataforma de compilación de destino. En Windows, elige «Versión de Visual Studio Build Tools 2019 – x86_amd64»:

Añade el archivo CMakeLists.txt a la carpeta raíz de tu proyecto para configurar CMake:
cmake_minimum_required(VERSION 3.0.0)
project(main VERSION 0.1.0)
INCLUDE_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/include
)
LINK_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/lib
)
add_executable(main scraper.cpp)
target_compile_features(main PRIVATE cxx_std_20)
find_package(cpr CONFIG REQUIRED)
target_link_libraries(main PRIVATE cpr::cpr)
find_package(LibXml2 REQUIRED)
target_link_libraries(main PRIVATE LibXml2::LibXml2)
Ten en cuenta que se trata de los dos paquetes instalados anteriormente. Asegúrate de actualizar INCLUDE_DIRECTORIES y LINK_DIRECTORIES de acuerdo con tu carpeta de instalación de vcpkg.
Para permitir que Visual Studio Code ejecute el programa C++, necesitas un archivo de configuración de ejecución. En la carpeta .vscode, inicia launch.json como se muestra a continuación:
{
"configurations": [
{
"name": "C++ Launch (Windows)",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceFolder}/build/Debug/main.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": []
}
]
}
Al iniciar el comando de ejecución o depuración, VS Code ahora ejecutará el archivo en la ruta program producida por CMake. Ten en cuenta que en macOS y Linux no será un archivo .exe.
¡La configuración está lista!
Cada vez que quieras depurar o compilar tu aplicación, escribe «>cmake: Build» en el campo de entrada superior y selecciona la opción «CMake: Build».

Espera a que finalice el proceso de compilación y ejecuta el programa compilado desde la sección «Ejecutar y depurar» o pulsando F5. Verás el resultado de tu aplicación en la consola de depuración de VSC.
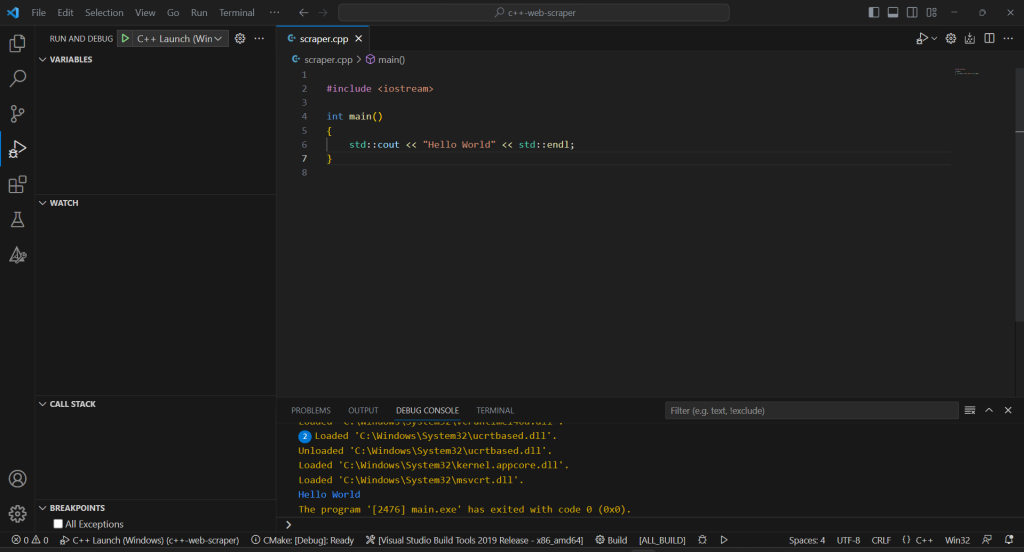
¡Genial! ¡Es hora de empezar a raspar algunos datos en C++!
Paso 4: descargar la página de destino con CPR
Si quieres extraer datos de una página, primero tienes que recuperar su documento HTML mediante una solicitud HTTP GET.
Usa CPR para descargar la página de destino con:
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"});
Entre bastidores, el método Get() ejecuta una solicitud GET a la URL pasada como parámetro. response.text contendrá la representación en cadena del código HTML devuelto por el servidor.
Ten en cuenta que la realización de solicitudes HTTP automatizadas puede activar tecnologías antibot. Estas pueden interceptar tus solicitudes e impedir que tu secuencia de comandos acceda al sitio de destino. En concreto, las soluciones antirraspado más básicas bloquean las solicitudes entrantes sin un encabezado HTTP User-Agent válido. Obtén más información en nuestra guía sobre User-Agents para el raspado web.
Al igual que cualquier otro cliente HTTP, CPR usa un valor de marcador de posición para User-Agent. Dado que esto es muy diferente de los agentes utilizados por los navegadores populares, los sistemas antibot pueden detectarte con facilidad. Para evitar que te bloqueen por ese motivo, puedes configurar un User-Agent válido en CPR con:
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/121.21.21.da/31/3das/32/1"}, headers);
La solicitud HTTP realizada a través de ese Get() ahora aparecerá como procedente de Google Chrome 113.
Esto es lo que contiene actualmente scraper.cpp:
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make the HTTP request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// scraping logic...
}
Paso 5: analizar contenido HTML con libxml2
Para que el documento HTML devuelto por el servidor pueda explorarse fácilmente, primero debes analizarlo.
Pasa su representación de cadena C a la función libxml2 htmlReadMemory() para conseguirlo:
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
La variable doc ahora expone la API de exploración del DOM que ofrece libxml2. En detalle, puedes recuperar los elementos HTML de la página mediante los selectores XPath. En el momento de escribir este artículo, libxml2 no es compatible con los selectores CSS.
Paso 6: definir los selectores XPath para obtener los elementos HTML deseados
Para definir una estrategia de selección de XPath eficaz para los nodos HTML de interés, debes analizar el DOM de la página de destino. Abre la página de inicio de Bright Data en el navegador, haz clic con el botón derecho en una de las tarjetas industrial y selecciona «Inspeccionar». Esto abrirá la sección de DevTools:
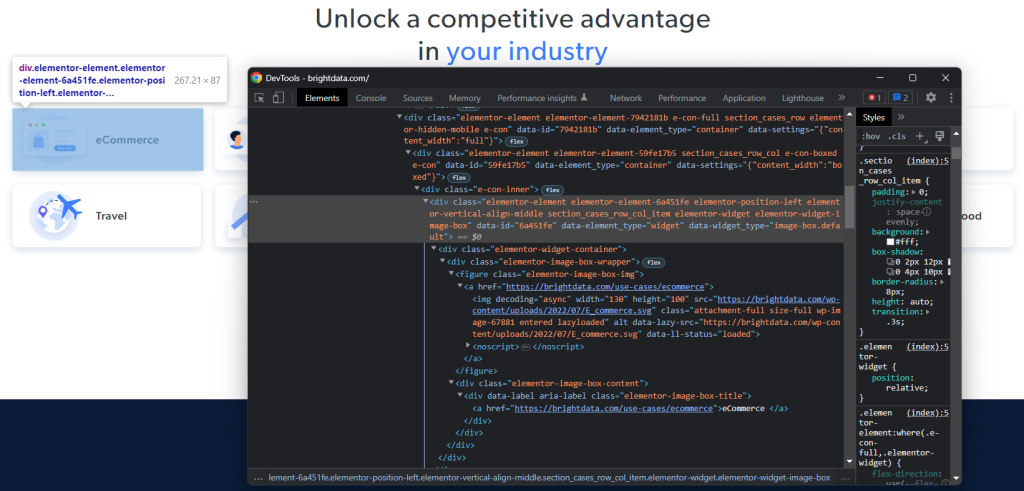
Explora el código HTML y verás que cada tarjeta industrial es un elemento <div> que contiene:
- Un elemento
<figure>con un<img>que representa la imagen de la industria y un<a>que contiene la URL de la página de la industria. - Un elemento HTML
<div>que almacena el nombre de la industria en un<a>.
Para cada tarjeta, el objetivo del raspador de C++ es extraer:
- La URL de la imagen de la industria
- La URL de la página de la industria
- El nombre de la industria
Para definir los selectores XPath adecuados, centra tu atención en la estructura del DOM de los elementos de interés. Verás que puedes obtener todas las tarjetas industriales con el siguiente selector XPath:
//div[contains(@class, 'section_cases_row_col_item')]
Si tienes alguna duda, prueba las instrucciones de XPath en la consola del navegador con $x():
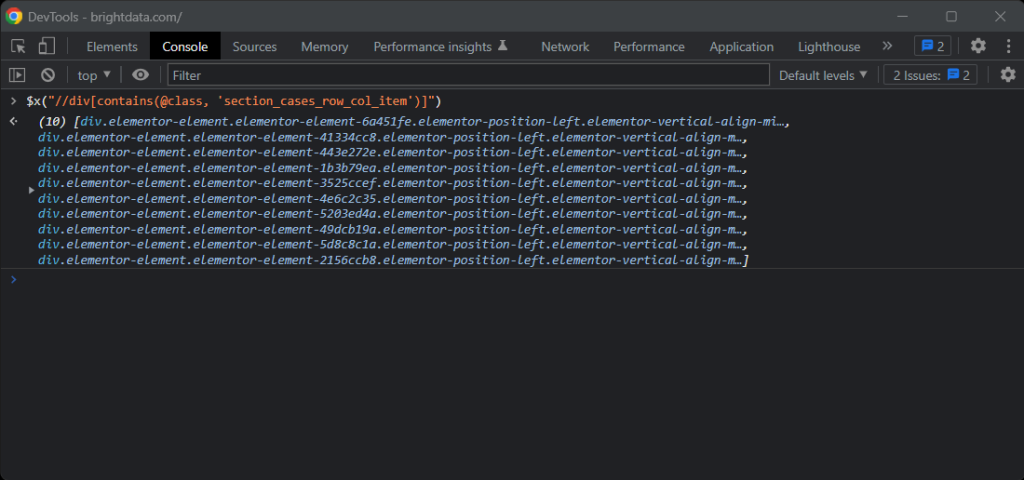
Si recibes una tarjeta, puedes obtener los nodos deseados con:
.//figure/a/img.//figure/a.//div[contains(@class, 'elementor-image-box-title')]/a
Paso 7: extraer datos de una página web con libxml2
Ahora puedes usar libxml2 para aplicar los selectores XPath definidos anteriormente y obtener los datos deseados de la página web HTML de destino.
Primero, necesitas una estructura de datos cuyas instancias almacenen los datos raspados:
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
En C++, un struct te permite agrupar varios atributos de datos con el mismo nombre en un bloque de memoria.
A continuación, inicia una matriz de IndustryCards en la función main():
std::vector<IndustryCard> industry_cards;
Esto almacenará todos los objetos de datos extraídos.
Rellena este vector con la siguiente lógica de raspado web de C++:
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
El segmento de código anterior selecciona las tarjetas industriales aplicando el selector XPath definido anteriormente con xmlXPathEvalExpression(). Después, itera sobre ellas e implementa un enfoque similar para obtener los elementos secundarios de interés de cada tarjeta. A continuación, extrae de ellas la URL de la imagen de la industria, la URL de la página y el nombre. Por último, libera los recursos asignados por libxml2.
Como puedes ver, el raspado web usando C++ con libxml2 no es tan complejo. Gracias a xmlGetProp() y xmlNodeGetContent() puedes obtener el valor de un atributo HTML y el contenido de un nodo, respectivamente.
Ahora que sabes cómo funciona el raspado de datos en C++, tienes las herramientas para ir un paso más allá y raspar también las páginas de la industria. Solo tienes que seguir los enlaces descubiertos aquí e idear una nueva lógica de raspado. ¡En esto consisten el rastreo y el raspado web!
¡Increíble! Acabas de lograr tus objetivos. Sin embargo, el tutorial aún no ha terminado.
Paso 7: exportar los datos raspados a CSV
Al final del bucle for(), industry_cards almacenará los datos raspados en instancias struct. Como puedes imaginar, ese no es el mejor formato para proporcionar datos a otros equipos. Esta es la razón por la que debes convertir los datos recuperados a CSV.
Puedes exportar un vector a un archivo CSV con funciones de C++ integradas de la siguiente manera:
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
El código anterior crea un archivo output.csv y lo inicia con el registro de encabezado. A continuación, itera sobre la matriz industry_cards, convierte cada elemento en una cadena en formato CSV y lo añade al archivo resultante.
Crea tu secuencia de comandos de raspado de C++, ejecútala y verás el siguiente archivo output.csv en el directorio raíz de tu proyecto:
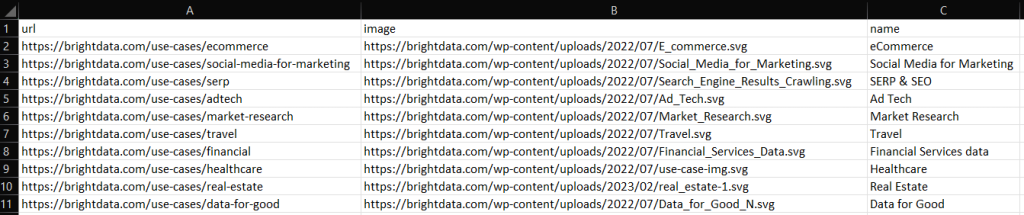
¡Bien hecho! ¡Ahora sabes cómo exportar datos raspados a CSV en C++!
Paso 8: juntarlo todo
Aquí está todo el raspador de C++:
// scraper.cpp
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
#include <vector>
// define a struct where to store the scraped data
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make an HTTP GET request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// parse the HTML document returned by the server
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
return 0;
}
¡Ya está! ¡Con alrededor de 80 líneas de código, puedes crear una secuencia de comandos de raspado de datos en C++!
Conclusión
En este tutorial, hemos aprendido por qué C++ es un lenguaje eficiente para el raspado web. Aunque no hay tantas bibliotecas de raspado como en otros idiomas, sí hay algunas. Y aquí tuviste la oportunidad de ver cuáles son las más populares. A continuación, analizaste cómo usar CPR y libxml2 para crear una araña en C++ que pueda recopilar datos de un objetivo real.
Sin embargo, el raspado webconlleva muchos desafíos. De hecho, un número cada vez mayor de sitios han estado implementando tecnologías antibot y antirraspado para proteger sus datos. Estas herramientas pueden detectar las solicitudes automatizadas realizadas por tu secuencia de comandos de raspado de C++ y prohibirlas. Afortunadamente, existen muchas soluciones automatizadas para tus necesidades de recopilación de datos. Ponte en contacto con nosotros para saber cuál es la mejor solución para tu caso de uso.
¿No te interesa para nada el raspado web, pero sí los datos web? Echa un vistazo a nuestros conjuntos de datos listos para usar.






